Ensemble-based Document Summarization
Girish Keshav Palshikar, Shailesh Deshpande, G. Athiappan
Tata Research Development and Design Centre (TRDDC), Tata Consultancy Services Limited,
54B, Hadapsar Industrial Estate, Pune 411013, India.
{gk.palshikar, shailesh.deshpande, athiappan.g}@tcs.com
Abstract
We examine the problem of combining multiple summaries of a given document into a summary considering their individual strengths. Treating sentences in the docu-ment as candidates and summarization al-gorithm asvoters, we formulate this prob-lem as determining thewinnersin an elec-tion where each voter selects and ranks k candidates in order of its preference. We propose the use of well-known Condorcet methodology, including a new variation to improve its suitability. As voters, we include some summarization algorithms from litera-ture and two new ones proposed here. The first is based on identifying keywords in the given document and then selecting sentences which arerichin keywords. The second is a variant of the lexical-chain based algorithm in (Stokes, 2004). We demonstrate the use-fulness of the proposed ensemble methodol-ogy through experiments, using kappa statis-tic and a new positional measure of similar-ity between summaries.
1 Introduction
The Web, digital libraries, online newspapers and enterprise document repositories all provide easy ac-cess to enormous information. Document summary is an important method which people use to deal with this information overload. Hence automatic techniques for document summarization are receiv-ing increasreceiv-ing attention from researchers. Docu-ment summarization is a highly complex task. We
focus on single document extract summarization which identifies the most informative (important) sentences in a given document.
The information in a summary should be (a) com-plete (should cover all important topics discussed in the document); (b) correctly ordered (c) coher-ent and consistcoher-ent (e.g., must not include any ambi-guities or redundancies); and (d) understandable for humans. Given such nebulous goals, it is not sur-prising that summary evaluationis also a complex task, difficult even for expert humans. There are considerable differences and disagreements among experts about what sentences in any given docu-ment are important enough to be included in a sum-mary and why. For example, (van Halteren and Teufel, 2003) report an average correlation of 0.2 between two randomly chosen summaries from 50 summaries of the same document. The average over-lap for the 542 single document summary pairs in DUC-2002 was only about 47%. (Jing et al., 1998) report a much higher level of agreement of news-like documents, though even then the agreement level decreases for longer summaries. We empir-ically demonstrate that there are considerable dis-agreements even among different summarization al-gorithms (not just humans).
effec-tively combined to produce another summary which is demonstrably better than the constituent sum-maries. Such expert advice combination is well-accepted in many fields, including classification, for which many classifier ensemble methods (such as bagging and boosting) are developed; see (Rokach, 2010) for a survey. Informally, an ensemble based summarization method should combine the ”best” parts of the constituent summaries, thus leveraging strengths of the corresponding summarizations algo-rithms.
The contributions of this paper are as follows. First, we propose two new algorithms for single-document extract summarization. The first is based on identifyingkeywordsin the given document and then selecting sentences which arerichin keywords. Using the number of keywords present in a sentence as a simple measure of the sentence’s importance, the algorithm selects the most important sentences as the summary. The second summarization rithm is a variant on the lexical-chain based algo-rithm in (Stokes, 2004). Next, we select a set of summarization algorithms from the literature (in-cluding the above two) and propose an ensemble method to produce a combined summary from the individual summaries produced by these algorithms. Treating sentences in the document ascandidatesin an election and summarization algorithms asvoters, we formulate this problem as determining the win-nersin this election where each voter selectsk can-didates and ranks them in order of its preference. Here, k is the user-defined fixed summary length (number of sentences). We propose the use of Con-dorcet methodology (well-known in politics and so-ciology) for this task. We also propose a variation on the standard Condorcet methodology to improve its suitability for the task of summary combination. We experimentally demonstrate the usefulness of the proposed summarization algorithms and summary combination methodology, using kappa statistic and a new positional measure of similarity between sum-maries.
This paper is organized as follows. Section 2 out-lines the related work. Section 3 contains our vari-ant of the lexical-chain based summarization algo-rithm. Section 4 contains a keyword-based approach to summarization. In section 5, we discuss the use of Condorcet methodology to combine multiple
sum-maries into a winner summary. Section 6 discusses some evaluation of the proposed algorithms. Section 7 contains conclusions and outlines further work.
2 Related Work
Many different approaches for text summarization have been proposed for single document extract summarization - see (Hovy, 2005) for an overview - we review only some relevant ones. Some algo-rithms (Teufel and Moens, 1997), (Kupiec et al., 1995), (Hovy and Lin, 1999) use the presence of cue phrases, such as significantly, as an in-dication that the sentence may be important. (Ku-piec et al., 1995) train a Bayesian classifier from a corpus of documents and associated summaries, us-ing sentence position and cue phrases (among oth-ers) as features. Presence of words which are some-what frequent is also a characteristic of important sentences (Edmundson, 1968). Our keyword-based summarization algorithm can use any suitable tech-nique for identifying keywords (Matsumura et al., 2002), (Matsuo and Ishizuka, 2004), (Ohsawa et al., 1998); we used (Palshikar, 2007). (Bouras et al., 2008) presents a keyword-based summariza-tion algorithm that uses a sentence-score based on the number and percentage of keywords in a sen-tence. (Zha, 2002) represent a document as a bi-partite graph and combine keyphrase extraction and summarization using the principle of mutual rein-forcement and sentence clustering.
Several summarization approaches use some ex-plicit measure of coherence in the text, usually based on lexical chains. Alexical chain (Morris and Hirst, 1991) is a sequence of related words (usually nouns) occurring in a sequence of sentences in the docu-ment. Treating each chain as a concept or topic, one can compute importance of sentences based on the chains that pass through them, selecting the most im-portant ones as a summary; e.g., (Alam et al., 2003), (Barzilay and Elbadad, 1997), (Mani et al., 1998).
of distance between the two probability distribu-tions over words in the model and peer summaries. (Louis and Nenkova, 2008) extend this approach to evaluate a peer summary (without any model sum-mary) by comparing it with the input document. (Nenkova et al., 2007) automatically identify and use (for summary evaluation) summary content units (SCU) which are small sequences of words whose weights depends on the frequency of their appear-ance in multiple summaries; see (Hovy et al., 2006) for a similar approach called basic elements. (Radev and Tam, 2003) propose the relative utility method for summary evaluation, in which each sentence in a document is given a score by a set of human judges about including that sentence in a summary.
3 Keyword-based Summarization
In this section, we propose a new keywords-based method for single document summarization. Given a set of characteristic keywords for a document, the idea is to select those sentences which contain max-imum number of keywords. A document - e.g., an article, a research paper or a news item - is typically characterized by a set of keywords orkey phrases. Each keyword indicates an important aspect (e.g., concept or topic) of the subject matter discussed in a document. Typically, only a few keywords (≤ 20) are associated with a document, unlike the large number ofindex termsused in information retrieval to index a document in a collection. Moreover, the keywords are usuallyorderedin decreasing order of their importance, or in increasing order of their gen-erality (more specific keywords first).
Any keyword extraction algorithm can be used -we have used (Palshikar, 2007) - to extract a setW of m keywords from a given document D, where m is a user-specified positive integer. The idea is to represent the given document as an undirected graph, whose vertices are words in the document and the edges are labeled with a dissimilarity mea-sure between two words, derived from the frequency of their co-occurrence in the document. The cen-tral vertices in this graph, identified using cencen-trality measures such as eccentricity or betweenness, are returned as keywords. The following algorithm sim-ply ranks (in descending order) the sentences inD in terms of the number of keywords inW that they
1. Fire Disables Cruise Ship in Gulf of Mexico
2. An engine room fire Wednesday disabled a cruise ship off the Mexican coast, but the crew extinguished the blaze and the ship with 715 people aboard was towed to port.
3. The Navy cutter Vigilant escorted the 465-foot ship, the Scandinavian Star, as a precaution, according to Chief Petty Officer Luis Diaz of the U.S. Coast Guard in Miami.
4. “The fire is out and the ship is being towed by the Mexican navy to Cancun,” said Diaz. 5. There were no injuries from the fire, but a 71-year-old St. Petersburg man who suffered a heart attack was in stable condition and on his way home aboard a Coast Guard plane. 6. A second person who suffered a spinal cord injury was also evacuated with the heart attack victim, but Diaz said that injury also was apparently not related to the fire.
7. The ship was expected to arrive in Cancun late Wednesday or Thursday.
8. The 449 passengers will be flown to St. Petersburg, said Jill DeChello, spokesman for the ship’s owner, SeaEscape Ltd. of Miami.
9. The Scandinavian Star was on a 3-day cruise to Cozumel, Mexico, and was returning to St. Petersburg when the fire broke out about 1 a.m. EST Wednesday, she said.
10. The crew sealed off the engine room and pumped in carbon dioxide to put out the fire. 11. “They used all their CO2 and closed off the engine room,” said Diaz.
12. “Then they requested more assistance from the Coast Guard.”
13. The fire was already extinguished when the Vigilant arrived about 10 a.m., he added. 14. Ms. DeChello said the company did not know what sparked the fire.
15. “It will take a week before we know the cause and the extent of the damage,” said Ms. DeChello.
16. In August 1984, a fire struck the Star’s sister ship, the Scandinavian Sun, in the port of Miami, killing a passenger and a crewman.
17. “I feel they are two totally different incidents that are in no way related,” said Ms. DeChello. 18. She said the cruise line was inspected by the Coast Guard and rigorously enforced all safety rules.
Figure 1: Document D21d AP880316-0208.txt from DUC-2001 corpus.
contain and returns the firstksentences. In case of ties, the algorithm can be modified to apply a crite-rion such as sentence length or can choose the sen-tence having most different keywords than those in the sentences chosen so far. Since different key-words have different importance (i.e., the keykey-words can be ranked or weighted), the algorithm can be easily modified to use (as sentence score) the sum of the weights (or ranks) of the keywords occurring in a sentence.
algorithmKWSummary
inputdocumentD,k≥1
inputsetWcontainingm≥1keywords
outputSetAcontainingksentences ofD for eachsentenceSi∈Ddo
Compute numberg(Si)of keywords inW that occur inSi
end for
Order sentences inDin decreasing order of theirgscore Return setAcontaining firstksentences
Suppose the set ofm= 15keywords for the doc-ument in Figure 1 is W = {ship, fire, coast, guard, Diaz, cruise, port, Scandinavian, star, aboard, Miami, Wednesday, engine,
No. #Keywords Keywords
1 4 ship, fire, cruise, Mexico
2 9 ship, fire, coast, cruise, port, aboard, Wednesday, engine, room 3 7 ship, coast, guard, Diaz, scandinavian, star, Miami 4 3 ship, fire, Diaz
5 4 fire, coast, guard, aboard 6 2 fire, Diaz
7 2 ship, Wednesday 8 2 ship, Miami
9 6 fire, cruise, Scandinavian, star, Wednesday, Mexico 10 3 fire, engine, room
11 3 Diaz, engine, room 12 2 coast, guard 13 1 fire 14 1 fire
15 0 –
16 6 ship, fire, port, Scandinavian, star, Miami
17 0 –
18 3 coast, guard, cruise
Table 1: Keywords in sentences.
to be sensitive to (a) the set of keywords W; and (b) the number k of keywords used. While this is broadly true, experimentally, we found that the algorithm is quite robust to reasonable changes in both the set W and the number k. For example, for the same keyword extraction algorithm and the same set of documents, we found that the summary sentences chosen by KWSummary do not vary much over values ofkfrom 10 to 20.
4 Summarization using Lexical Chains
A lexical chain (Morris and Hirst, 1991) is a se-quence of related words that occurs across sentences in a given document. Two consecutive words in a chain may be related by the strong relationif both words are the same or related through synonymy, hypernymy, meronymy or holonymy; e.g.,fireand fire, fire andflame, or fire and blaze. They
have amedium-strength relationif they have a com-mon ancestor in WordNet hierarchy and the path be-tween them is at most of lengthK (for some con-stantK); e.g.,appleandorangehave the common
ancestoredible fruit and are connected through
the paths apple ISA edible fruit and orange ISA citrus fruit ISA edible fruit. Several
algorithms have been developed for identifying lex-ical chains in a given document; we use the one in (Stokes, 2004). Often, only nouns are included in a lexical chain, because the semantic hierarchy is much better developed for nouns. Several sum-marization algorithms are based on lexical chain-ing (Alam et al., 2003), (Barzilay and Elbadad, 1997), (Mani et al., 1998). The general idea is to compute the chains for the given document, score
the chains based on their cohesiveness, score the sentences based on the score of the chains passing through them, and then choose the most important sentences as the summary. We now discuss our al-gorithm for lexical chain based summarization.
Consider a chain C = {u1, u2, . . . , un}
consisting of m words. Let DOM(C) =
{w1, w2, . . . , wn} denote the set of n distinct
words in C (C may contain multiple occurrences of some words). The score Gi of thei-th wordwi
is computed as Gi = ni,1 ·a1 +ni,2 ·a2 + . . .
where ni,j denotes the number of words in
chain C that are related to wi by j-th relationship
(j= 1:repetition,j= 2:synonym,j= 3:hypernym, hyponym, meronym, holonym etc.) and aj is the
weight for j-th relationship (we use a1 = 1.0,
a2 = 0.9, a3 = 0.7). We have assumed that
medium strength relation is not used when forming lexical chains. Score of the entire chain is then defined as the sum of the scores of the words in it: HC = G1 +G2 + . . .+ Gn. The intuition
is that a chain that includes more occurrences of stronger bonds between two words should score more than a chain that has many weaker bonds. We do not consider the length of the chain explicitly as it is already taken into account when calculating the word scores. Higher chain score indicates a more important and more cohesive chain. As an example, consider the chain C = {wind, squall, wind, wind} (m = 4, DOM(C) = {wind, squall}, n = 2). The score for the wordwind in
the chain’s domain isG1 = number of repetitions
* 1.0 + number of synonyms * 0.9 + number of secondary relations * 0.7 = 2*1 + 0*0.9 + 1*0.7 = 2.7. Similarly, the score for the word squall
is G2 = 0∗ 1 + 0∗ 0.9 + 1∗ 0.7 = 0.7. The
score of the entire chain isHC = 2.7 + 0.7 = 3.4.
We treat chains as concepts and chain score as the importance of a particular concept in the given document. The score of a sentence is obtained by adding the scores of all chains passing through that sentence. We sort the sentences in descending order of their score and then select topksentence for the extract summary. The document in Figure 1 has the following 4 chains (sentence number is given as subscript for each word in the chain):
C1 : fire1, fire2, blaze2, fire4, fire5,
ID Method Sentences 1 Alphagreedy 3, 5, 2, 17 2 AlphaSVD 3, 5, 2, 17 3 LexRank 16, 15, 14, 8 4 Microsoft Word 2007 1, 2, 16, 3 5 Lexical Chains based 2, 9, 5, 3 6 KWSummary 2, 3, 16, 9
Table 2: Ranked output of summarization methods.
fire13, fire14, fire16
C2:ship1, ship2, ship2, ship4, ship7, ship8
C3:coast2, coast3, coast5, coast12, coast18 C4:guard3, guard5, guard18, safety18
The scores for these 4 chains are 12.8, 6, 5, 4.4 (the seed word of the chain - e.g., ship in C2
- is treated as an instance of the extra-strong relation). The sentence scores can now be eas-ily computed; e.g., the score for sentence 2 is 13.8 + 6 + 5 + 4.4 +. . . = 41.8sinceC1,C2,C4
andC4 (among others) pass through it. This
algo-rithm chooses sentences 2, 9, 5, 3 as the summary. Our algorithm for finding lexical chains is very similar to that used by (Stokes, 2004) with following differences. We do not consider medium strength relations while forming lexical chains, because such relations tend to form spurious chains and thereby dilute the unity of a concept. We also do not consider co-occurrence relations for reducing com-putational complexity of the chaining algorithm. We do not consider the sentence distance constraint as well. Sentence constraints are useful in finding topics boundaries or intentional reoccurrence of the topics. For summarization, we do not want to split the chains (concepts) into multiple chains because we want to find a concept spans multiple regions (segments) in the document. If we use sentences boundaries, we need to combine similar chains again which is wasteful for summarization. (Barzilay and Elbadad, 1997) has also shown that chaining improves when the entire document is considered, rather than document segments. Our chain scoring mechanism is almost the same as the one in (Kang, 2003), except that we do not consider the penaly part when computing the sentence score.
5 Combining Summaries
Given a documentDandMextract summaries for it (each containingksentences) produced byM
sum-marization algorithms, we now consider the problem of systematically and effectively combining theseM summaries to produce a final summary forD.
Definition 1 Let a document D contain N sen-tences, numbered from 1 to N. Let σi =<
Si1, Si2, . . . , SiK > denote the ranked output of i−thsummarization method, where each1≤sik ≤
N denotes a sentence number. Therankof sentence number j inσi, denotedr(σi, j), is the position at
which that sentence occurs inσi. If sentence
num-ber j does not occur in σi then its rank is set to
some large number (say, 100). A methodi prefers sentence x over sentence y if r(σi, x) < r(σi, y)
i.e., x appears earlier than y in the ranked output of methodi. LetS = {σ1, σ2, . . . , σM}denote the
collection of the outputs ofM summarization algo-rithms.
Table 2 shows the k = 4 sentences selected by each of M = 6 summarization algorithms ap-plied to the example document in Figure 1 con-taining N = 18 sentences; σ1 =< 3,5,2,17 >,
σ3 =<16,15,14,8 >and so on. The rank of
sen-tence 5 inσ1 isr(σ1,5) = 2, since 5 occurs at
po-sition 2 inσ1. Method 1 prefers sentence 3 to
sen-tence 5. Note that several sensen-tences are identified by more than one method; e.g., sentences 2 and 3 are identified by 5 methods each, sentences 5 and 16 by 3 methods each and sentences 9 by 2 methods. Thus sentences 2 and 3 have a stronger claim to be-ing in the ”true” summary of the given document, over other sentences. The question now is: how do we systematically combine the sentences selected by these 6 summarization algorithms into a final ”win-ning” summary of 4 sentences?
5.1 Weighted Average Ranks
A simple way to combine the outputs of differ-ent summarization algorithms is based on comput-ing a weighted average rank for each sentences and then selecting the sentences with the highest average ranks. Letkdenote the number of sentences selected by each summarization algorithm (k= 4in Table 2). Consider a particular sentencej. For each ordered selection ofksentencesσi =< Si1, Si2, . . . , Sik >, compute the weighted rank of j in σi as wi,j =
k−r(σi, j) + 1ifjappears inσi and 0 otherwise.
rank is k, if it appears at rank 2 then its weighted rank is k−1and so on and if it appears at rankk then its weighted rank is 1. Ifj does not appear in σi then its weighted rank is 0. Each sentence has
Mranks and correspondingM weighted ranks. The average weighted rank aj of sentence numbered j
is the weighted average of its weighted ranks. For-mally,
aj =
PM
i=1wi,j
M×k×(k+12 )
Note that the sum of the weighted ranks of allN sentences is always 1. For example, the weighted average rank of sentencej = 2is a2 = (2 + 2 +
0 + 3 + 4 + 4)/(6×4×2.5) = 15/60 = 0.25. The weighted average ranks of the 18 sentences are: 1 : 0.067,2 : 0.25,3 : 0.217,4 : 0,5 : 0.13,6 : 0,7 : 0,8 : 0.017,9 : 0.067,10 : 0,11 : 0,12 : 0,13 : 0,14 : 0.033,15 : 0.05,16 : 0.13,17 : 0.03,18 : 0. The k = 4 sentences with highest weighted aver-age rank are 2, 3, 5, 16. For k = 5, there would have been a tie between sentences 1 and 9, which could be broken using some rule such as preferring the sentence having longer length (1 has length 8 and 9 has length 30) or having the lowest sentence num-ber i.e., closer to the beginning of the document (1 has a lower number than 9).
5.2 Condorcet Algorithm
As another ensemble method to combine outputs of different summarization algorithms, we propose to use a well-known method called theCondorcet al-gorithm, which is often used to decide winner in a poll or an election.
As the first step, we form an N ×N matrix R, where N is the number of sentences in the given document D (N = 18in the example). The i-th row ofRcorresponds to thei-th sentence inD. We consider each of theM = 6summarization methods as a voter. EntryRi,j inRindicates the total
num-ber of voters (out ofM) who prefer sentenceiover sentencej. The matrixRfor the example document is shown in Table 3. For example,R9,5 = 2since 2
methods (5 and 6) prefer sentence 9 over sentence 5. Condorcet method analyzes the votes ofM sum-marization methods, as represented in the matrixR, to decide the winner among the N candidate
sen-tences. For this purpose, it considersN ×N imagi-nary contests, pitting every sentenceiagainst every other sentencej. Sentenceiis a winner of this con-test if the number of voters that preferi is greater than the number of voters that prefer j. In the ex-ample, sentence 2 wins against sentence 5 because R(2,5) > R(5,2). When all possible pairings of the sentences are considered, we pick up thek sen-tences that have won the maximum number of con-tests. In the example, the number of wins for each sentence are as follows:1:8 2:17 3:16 4:0 5:13 6:0 7:0 8:8 9:12 10:0 11:0 12:0 13:0 14:9 15:10 16:14 17:12 18:0. Thus sentence 9 wins against 12 sentences, viz., 1, 4, 6, 7, 8, 10, 11, 12, 13, 14, 15, 18. Sentences 2, 3, 16 and 5 constitute a winning summary according to this method. Note that fork= 5, there would have been a tie for sentences 9 and 17, as both won against 12 sentences each. Ties can be broken by means of well-known variations of the Condorcet method; e.g., ranked pairs or Schulze method.
6 Evaluation
We used DUC 2001 dataset of 100 news articles. We selectedN = 100documents for which model summaries were available in this repository. These 100 documents are news stories related to natural hazards, politics, financial results and so on. The average number of sentences in these documents is 34. For each of these N = 100 documents, we created extract summaries with different number of sentences (k = 3,4, . . . ,10), using the follow-ing summarization methods: IBM’s Many Aspects Alfa-Greedy, IBM’s Alfa-SVD (Liu et al., 2008)1, LexRank (Erkan and Radev, 2004), Microsoft Word 20072, the lexical chain based and keyword-based summarization algorithm in this paper.
Then for each document and each summary length (k= 3,4, . . . ,10), we created two additional summaries by combining the 5 summaries gener-ated by the above 5 summarization algorithms, one using Condorcet and the other using the Weighted Rank method. The main question is: are these two ensemble-based summaries ”better” than the 5 peer summaries on which they are based? Among
vari-1
http://www.alphaworks.ibm.com/tech/manyaspects
2
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2 4 0 3 5 3 5 5 5 5 5 5 5 5 5 5 5 5 5
3 4 2 0 5 4 5 5 5 4 5 5 5 5 5 5 4 5 5
4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 3 2 1 3 0 3 3 3 2 3 3 3 3 3 3 3 3 3
6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
8 1 1 1 1 1 1 1 0 1 1 1 1 1 0 0 0 1 1
9 2 0 1 2 2 2 2 2 0 2 2 2 2 2 2 1 2 2
10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
12 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
13 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
14 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1
15 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1
16 2 1 2 3 3 3 3 3 3 3 3 3 3 3 3 0 3 3
17 2 0 0 2 0 2 2 2 2 2 2 2 2 2 2 2 0 2
18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Table 3: Rank matrix for 6 methods and 18 sentences.
ous possibilities, we adopt the following simple way to answer this question: we say that one summary is better than another if it iscloser(i.e., more similar) to the model (reference) summary.
6.1 Proximity-based Similarity
It is a common observation that sentences which are near each other in a document can often be considered similar, because they tend to belong to the same topic. Of course, such a simple-minded and purely positional sentence similarity measure will fail for ill-structured documents or those con-taining randomly ordered sentences. Nevertheless, we found that such a measure works reasonably well on real documents. Given a positive integer constantk0, similarity between sentences numbered
1 ≤ i, j ≤ N is defined (in terms of their proxim-ity) asprox(i, j) = 1− |i−kj|
0 if|i−j| ≤k0 and 0 otherwise. Thus given k0 = 3, similarity between
sentences numbered 15 and 17 is prox(15,17) = 1−|15−317| = 0.33. Given two sets containingk sen-tence numbers each A = {i1, i2, . . . , ik} andB = {j1, j2, . . . , jk}, amatchingbetweenAandBis any
one-to-one onto (bijection) function f : A → B. The proximitybetweenA andB (k = |A| = |B|) based on such a given bijectionf is defined as the average of proximities between each element ia in
Aand its imagef(ia)inB underf:
proxf(A, B) =
P
ia∈Aprox(ia, f(ia))
k
The proximity between A and B, denoted simprox(A, B), is then the maximum
prox-imity achieved by any matching function be-tween A and B. Let fmax be a bijection
between A and B that achieves the maximum proximity: fmax = arg maxfproxf(A, B).
Then simprox(A, B) = proxfmax(A, B).
As an example, suppose k0 = 3, A =
{5,10,16,20} and B = {7,10,15,18}, f1 = {(5,10),(10,7),(16,18),(20,15)},
f2 = {(5,7),(10,10),(16,15),(20,18)}.
Then proxf1(A, B) = prox(5,10) + prox(10,7) + prox(16,18) + prox(20,15) =
0+0+0.33+0
4 = 0.0825, whereas proxf2(A, B) =
0.33+1+0.67+0.33
4 = 0.5825.
Consider the sentences inAandBas vertices of a bipartite graph, where eachi∈Ais connected to ev-eryj ∈Band this edge has weightprox(i, j). Each perfect matching of this weighted bipartite graph ex-actly corresponds to the matching function defined above. The maximum weighted bipartite matching is a perfect matching where the sum of the weights of the edges included in the matching is maximum. Finding such a matching is the well-known assign-ment problem and can be solved efficiently using the Hugarian algorithm in timeO(V2E), which is O(k4)in our case (|A|=|B|=k).
6.2 Similarity with Reference Summary
summaries (prepared by the summarization algo-rithms) with the model summary for that document using the following 4 similarity measures: Prox-imity score, Dice, Jaccard and cosine. For sum-maries of lengthk, we retained only the firstk sen-tences in the model summary. LetPi,j,k denote the
peer summary of a particular document 1 ≤ i ≤
N (N = 100 here), produced by the summariza-tion method 1 ≤ j ≤ 7 having summary length 3 ≤ k ≤ 10. Let Mi,j,k denote the
correspond-ing model summary. Let simprox(Pi,j,k, Mi,j,k),
simdice(Pi,j,k, Mi,j,k), simjacc(Pi,j,k, Mi,j,k) and
simcos(Pi,j,k, Mi,j,k)denote the similarity between
Pi,j,kandMi,j,kcomputed using the above
similar-ity measures. The performance of a particular sum-marization method (for a particular summary length) is measured by the average similarity between the model summaries and the summaries produced by that method. Note that this performance measure depends on the similarity method used.
aprox(j, k) =
PN
i=1simprox(Pi,j,k, Mi,j,k)
N
adice(j, k) =
PN
i=1simdice(Pi,j,k, Mi,j,k)
N
ajacc(j, k) =
PN
i=1simjacc(Pi,j,k, Mi,j,k)
N
acos(j, k) =
PN
i=1simcos(Pi,j,k, Mi,j,k)
N
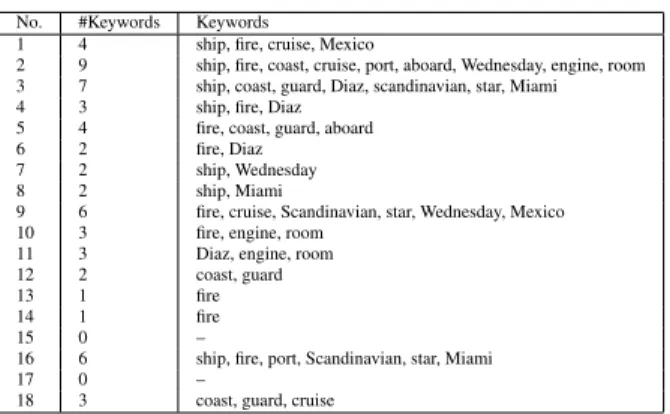
Fig. 2 shows how the average performance of each of the 7 summarization methods (as computed using a particular similarity measure) varies with the sum-mary length3 ≤ k ≤ 10. For most summarization methods, the performance improves with the sum-mary length. Alfa-Greedy and Alfa-SVD show a slower increase in their performance. On the other hand, Condorcet and Weighted Rank methods show steep rise in performance. Both these voting meth-ods show consistently higher performance compared to other methods for summary lengths 5 or more. The next best performance is shown by the Lexical Chaining algorithm.
6.3 Counts of Best Summary
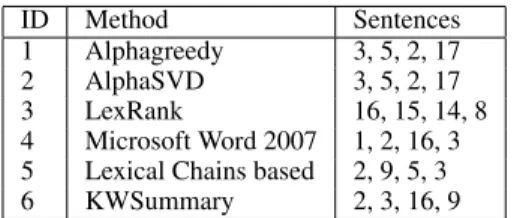
We have compared the performance of these 7 summarization algorithms using another measure.
Figure 2: Performance of the various summarization methods using different similarity measures - part I.
As earlier, let Pi,j,k denote the peer summary of
a particular document 1 ≤ i ≤ N (N = 100here), produced by the summarization method 1 ≤ j ≤ 7 having summary length 3 ≤
k ≤ 10. Let Mi,j,k denote the
correspond-ing model summary. Let simprox(Pi,j,k, Mi,j,k),
simdice(Pi,j,k, Mi,j,k), simjacc(Pi,j,k, Mi,j,k) and
simcos(Pi,j,k, Mi,j,k)denote the similarity between
Pi,j,k andMi,j,k computed using the above
similar-ity measures. For a particular document, the best summarization method is one which has the highest similarity with that document’s reference summary, computed using a specific similarity method. Let Bi,j,k,prox denote a Boolean indicator variable that
is 1 if thek-sentence summary of theithdocument as produced by thejth-summarization method has
the highest similarity with that document’s model summary, as computed using the Proximity score. The indicator variables Bi,j,k,dice, Bi,j,k,jacc and
Bi,j,k,cos are defined analogously for the Dice,
Figure 3: Performance of the various summarization methods using different similarity measures - part II.
summary. Note that this performance measure de-pends on the similarity method used.
BPprox(j, k) =
PN
i=1Bi,j,k,prox
N
BPdice(j, k) =
PN
i=1Bi,j,k,dice
N
BPjacc(j, k) =
PN
i=1Bi,j,k,jacc
N
BPcos(j, k) =
PN
i=1Bi,j,k,cos
N
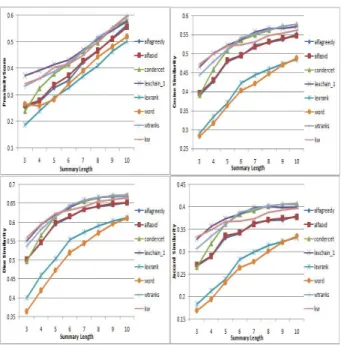
Fig. 3 shows how the performance (as measured using best summary counts) of each of the 7 sum-marization methods (as computed using a partic-ular similarity measure) varies with the summary length 3 ≤ k ≤ 10. For most summarization methods, the performance improves with the sum-mary length. Both the voting methods produce best or near best summaries according to dice similar-ity scores for summaries of all lengths, except that the Condorcet method works much better with sum-maries of length 5 or more. For other similarity measures, the lexical chaining based summarization method shows the best performance for summaries of all lengths. For these similarity measures, both
Figure 4: Performance of the various summarization methods using different similarity measures - part III.
the voting methods are by-and-large are at or near the second best method. An interesting observation is the sudden emergence of the weighted rank based voting method as the top method for summaries of length 8.
6.4 Kappa Statistic
Kappa statistic is a well-known way to measure agreement between two raters (or annotators), when they both qualitatively evaluate the same set of ob-jects. Suppose each object is given a rating 0 or 1 by each rater. Then the kappa statistic is computed as:
κ= P(a)−P(e) 1−P(e)
whereP(a)is the observed agreement level (i.e., the fraction of objects for which both raters gave the same rating) andP(e)is the hypothetical prob-ability of chance agreement. If both raters agree on all objects thenκ = 1. If the agreement between raters is as much as expected under chance then κ = 0. Higher values tend to indicate better agree-ment levels. We adapt the kappa statistic to com-pute the agreement between the model summaries and the summaries produced by a summarization al-gorithms. The goal is to investigate whether a com-bined summary produced by an ensemble method (such as Condorcet) has a better agreement with the model summary.
sen-tence in the summary. The model summary Ahas sentences 2, 3, 5, 9 whereas the Condorcet method’s summary B has sentences 2, 3, 5, 16. Since the two raters agree on 16 out of 18 sentences,P(a) = 16/18 = 0.89. Both raters assign 1 to 4 sentences and 0 to 14 sentences. Thus the probability that both raters assign 1 by chance is 184 × 4
18 = 0.049.
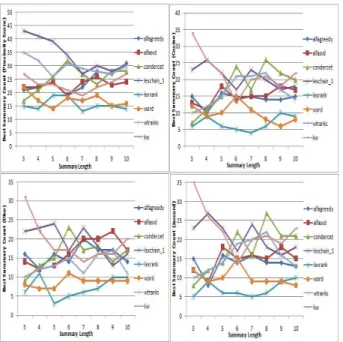
The probability that both raters assign 0 by chance is 1618×1618 = 0.605. ThenP(e) = 0.049 + 0.605 = 0.654. The kappa statistics for the agreement be-tween the model summary and the condorcet sum-mary for this document isκ= 0(1.89−−00.654).654) = 0.679. We can now get the kappa values for all 100 docu-ments and their average value indicates the average agreement level between the model summaries and the Condorcet summaries. Fig. 4 shows the average kappa statistic for all 7 summarization algorithms for different summary lengths (k = 3. . .10). Both ensemble-based summarization methods (weighted ranks and Condorcet) tend to have a better agree-ment with the model summary, with the exception of Lexical chain and KWSummary algorithms.
7 Conclusions and Further Work
This paper’s main contributions are as follows. First, we proposed two simple algorithms for single doc-ument extract summarization. The first is based on identifying keywords in the given document and then selecting sentences which arerichin keywords. The second summarization algorithm is a variant on the lexical-chain based algorithm in (Stokes, 2004). Our second contribution is initiating an investiga-tion into whether summaries produced by indivisual summarization algorithms can be combined system-atically and effectively using some kind of ensem-ble method to produce a summary which tends to be ”better” than the individual summaries, by combin-ing their strengths. Treatcombin-ing sentences in the docu-ment ascandidatesand summarization algorithm as voters, we formulated this problem as determining thewinnersin an election where each voter selects and rankskcandidates in order of its preference. We proposed the use of well-known Condorcet method-ology for this task, including a new variation to im-prove its suitability for this task. We demonstrated the usefulness of the proposed summary combina-tion methodology through experiments, including a
new positional measure of similarity between sum-maries. We also used the kappa statistic to compare the summaries with model summaries.
Experimentally, we found that both the new pro-posed summarization methods (keyword-based and lexical-chain based) tend to produce good sum-maries. Further, we found that both the ensem-ble methods (Condorcet and weighted rank) tend to produce good summaries, which are generally bet-ter than most of the individual summaries. These ensemble methods seem to work reasonably well for documents in a variety of domains. The pro-posed ensemble methods are inherently language-independent (do not use any language-specific knowledge) and hence more widely usable. For fur-ther work, we plan to use more voters (i.e., more summarization methods) in our ensemble methods. We are planning a more extensive validation with larger and more varied document repositories. An interesting alternative is to use another ensemble method, like Dempster-Schafer evidence combina-tion (Schafer, 1976). Another research direccombina-tion is to extend the use of ensemble methods for multi-document summarization.
References
H. Alam, A. Kumar, M. Nakamura, F. Rahman, Y. Tarnikova, and C. Wilcox. 2003. Structured and unstructured document summarization: Design of a commercial summarizer using lexical chains. InProc. Seventh Int. Conf. Document Analysis and Recognition (ICDAR 2003), pages 1147–1152.
R. Barzilay and M. Elbadad. 1997. Using lexical chains for text summarization. In Proceedings of the ACL Workshop on Intelligent Scalable Text Summarization, pages 10–17.
C. Bouras, V. Poulopoulos, and V. Tsogkas. 2008. Perssonal’s core functionality evaluation: Enhancing text labeling through personalized summaries. Data and Knowledge Engineering, 64(1):330 – 345.
H. P. Edmundson. 1968. New methods in automatic ex-traction. Journal of the ACM, 16(2):264–285.
G. Erkan and D. R. Radev. 2004. Lexrank: Graph-based lexical centrality as salience in text summariza-tion. Journal of AI Research, 22:457–479.
ed-itors,Advances in Automatic Text Summarization. MIT Press.
E. Hovy, C.-Y. Lin, L. Zhou, , and J. Fukumoto. 2006. Automated summarization evaluation with basic ele-ment. InProceedings of the Fifth Conference on Lan-guage Resources and Evaluation (LREC ’06).
E. H. Hovy. 2005. Automated text summarization. In R. Mitkov, editor,In The Oxford Handbook of Compu-tational Linguistics, pages 583–598.
H. Jing, R. Barzilay, K. Mckeown, and M. Elhadad. 1998. Summarization evaluation methods: Experi-ments and analysis. InIn AAAI Symposium on Intelli-gent Summarization, pages 60–68.
B.-Y. Kang. 2003. A novel approach to semantic index-ing based on concept. InProceedings of the 41st An-nual Meeting on Association for Computational Lin-guistics - Volume 2 (ACL-03), pages 44–49.
J. Kupiec, J. Pedersen, and F. Chen. 1995. A trainable document summarizer. InProc. 18th Int. ACM Conf. Research and Development in Information Retrieval (SIGIR), pages 68–73.
C.-Y. Lin, G. Cao, J. Gao, and J.-Y. Nie. 2006. An information-theoretic approach to automatic evalua-tion of summaries. In Proceedings of the main con-ference on Human Language Technology Concon-ference of the North American Chapter of the Association of Computational Linguistics (HLT-NAACL 06), pages 463–470.
Kun Liu, Evimaria Terzi, and Tyrone Grandison. 2008. Manyaspects: a system for highlighting diverse con-cepts in documents. In Proc. Int. Conf. Very Large Databases (VLDB), pages 1444–1447.
A. Louis and A. Nenkova. 2008. Automatic summary evaluation without human models. In Proc. of Text Analysis Conference (TAC).
I. Mani, E. Bloedorn, and B. Gates. 1998. Using cohe-sion and coherence models for text summarization. In Using Cohesion and Coherence Models for Text Sum-marization, pages 69–76.
N. Matsumura, Y. Ohsawa, and M. Ishizuka. 2002. Pai: Automatic indexing for extracting assorted keywords from a document. InProc. AAAI 2002.
Y. Matsuo and M. Ishizuka. 2004. Keyword extraction from a single document using word co-occurrence sta-tistical information. International Journal on AI Tools, 13(1):157–169.
J. Morris and G. Hirst. 1991. Lexical cohesion computed by thesaural relations as an indicator of the structure of text. Computational Linguistics, 17:21–48, March.
A. Nenkova, R. Passonneau, and K. McKeown. 2007. The pyramid method: Incorporating human content se-lection variation in summarization evaluation. ACM Trans. Speech Lang. Process., 4, May.
A. Nenkova. 2006. Summarization evaluation for text and speech: issues and approaches. In Ninth Inter-national Conference on Spoken Language Processing (INTERSPEECH 2006).
Y. Ohsawa, N. E. Benson, and M. Yachida. 1998. Key-graph: automatic indexing by co-occurrence graph based on building construction metaphor. In Proc. Advanced Digital Library Conference (ADL98), pages 12–18.
G.K. Palshikar. 2007. Keyword extraction from single document using centrality measures. InProc. 2nd Int. Conf. Pattern Recognition and Machine Intelligence (PReMI 2007), LNCS 4815, pages 503–510.
D. R. Radev and D. Tam. 2003. Summarization evalua-tion using relative utility. InProceedings of the twelfth international conference on Information and knowl-edge management (CIKM ’03), pages 508–511.
L. Rokach. 2010. Ensemble-based classifiers. Artificial Intelligence Review, 33:1–39.
G. Schafer. 1976. A Mathematical Theory of Evidence. Princeton University Press.
N. Stokes. 2004. Applications of Lexical Cohesion in the Topic Detection and Tracking Domain. Ph.D. thesis, National university of Ireland, Dublin.
S. Teufel and M. Moens. 1997. Sentence extraction as a classification task. In Proc. Workshop on Intelli-gent Scalable Summarization ACL/EACL Conference, pages 58–65.
H. van Halteren and S. Teufel. 2003. Examining the con-sensus between human summaries: initial experiments with factoid analysis. In Proceedings of the HLT-NAACL 03 on Text summarization workshop - Volume 5 (HLT-NAACL-DUC ’03), pages 57–64.