Integrated Real-time Systems
M. Tech First Stage Report
Submitted in partial fulfillment of the requirements
for the degree of
Master of Technology
by
Vibhooti Verma
Roll No: 05305016
under the guidance of
Prof. Krithi Ramamritham
Department of Computer Science and Engineering
Indian Institute of Technology, Bombay
Acknowledgment
I am extremely thankful to my guide Prof. Krithi Ramamritham for his constant encouragement and invaluable guidance.
Declaration
All the writing in this report is mine. Wherever I have borrowed the material from some other source I have cited the source.
Vibhooti Verma IIT Bombay
Abstract
Integrated Real-time Systems are systems in which applications with different levels of criticality, co-exist. These systems must support strong partitioning concept, temporal and spatial both, at its core design. Scheduling applications in such systems requires two level hierarchical scheduling to satisfy tem-poral constraints and a secure memory management technique to satisfy spatial constraints. Two such systems, Open System Architecture and Strongly Partitioned Integrated Real-time Systems, are dis-cussed. Algorithms to schedule soft aperiodic tasks without affecting scheduling of hard real-time tasks are overviewed. A minimal second generation kernel is required on top of which, different operating systems can run efficiently for different applications. Microkernels which have spatial partitioning and protected communication mechanism, such as SPIRIT microkernel, L4 and fiasco are described in detail. Strong partitioning in reservation based system is analyzed to a small extent.
Contents
1 Integrated Real-time Systems 5
1.1 Introduction to Integrated Real-time Systems . . . 5
1.2 Challenges in Scheduling of Real-time Tasks . . . 5
2 Scheduling Algorithms for Mixed Real-time Tasks 7 2.1 Fixed Priority Servers . . . 7
2.2 Dynamic Priority Servers . . . 8
2.3 Comparisons of Various Scheduling Algorithms for Scheduling Mixed Tasks . . . 9
3 Study of Integrated Real-time System Implementations 10 3.1 A Dynamic-Priority-Driven Open Environment for Real-Time Application . . . 10
3.1.1 Scheduling Hierarchy . . . 10
3.1.2 Constant Bandwidth Server(CBS) . . . 10
3.1.3 Concept of Slow Virtual Processor . . . 12
3.1.4 Predictable Versus Nonpredictable Applications . . . 12
3.1.5 Admission of New Real Time Application . . . 14
3.1.6 Server Maintenance . . . 14
3.1.7 System Service Provider . . . 15
3.2 A Fixed-Priority-Driven Open Environment for Real-Time Applications . . . 15
3.2.1 Operations of OS Scheduler . . . 16
3.2.2 Scheduling and Admission Control . . . 17
3.2.3 Independent Application over Sporadic Servers . . . 17
3.3 SPIRIT (Strongly partitioned Integrated Real-time System) . . . 19
3.3.1 Design Concept . . . 19
3.3.2 Schedulability Conditions . . . 21
3.3.3 Determining Partition Size . . . 22
3.4 Comparison of Algorithm for Scheduling Tasks in Open System Architecture . . . 22
4 Microkernels 23 4.1 SPIRIT Microkernel . . . 23
4.1.1 Model and Design Concept of SPIRIT . . . 23
4.1.2 SPIRIT Architecture . . . 24
4.1.3 Generic RTOS Port Interface(RPI) . . . 25
4.2 L4 Architecture . . . 27
4.2.1 Threads . . . 27
4.2.2 Inter-process communication (IPC) . . . 27
4.2.3 Clans and Chiefs . . . 28
4.2.4 Flexibility . . . 28
4.3 Fiasco . . . 29
4.4 Comaprison of Various Real-time Microkernel . . . 31
5 Strong Partitioning in Reservation Based System 32 5.1 Resource Kernels . . . 32
5.2 Policy Decisions and Comparison Metrics . . . 33
5.3 Various Techniques . . . 33
5.3.1 Simple Priority inheritance . . . 33
5.3.2 Priority Ceiling Protocol with Reservation . . . 33
5.3.3 Reserve Inheritance(RI) . . . 34
5.3.4 Priority Inheritance with Priority Inversion Enforcement (PIPIE) . . . 34
5.4 Summary and Comparison of Inheritance-Based Schemes . . . 35
Chapter 1
Integrated Real-time Systems
1.1
Introduction to Integrated Real-time Systems
Integrated Real-time Systems are systems having various application with different levels of criticality. Modern systems are frequently called upon to support mixes of applications with different types of timeliness requirements. To achieve reliability, reusability, and cost reduction, a significant trend in building large complex real-time systems is to integrate separate application modules of different criticality in a common hardware platform. An essential requirement of integrated real-time systems is to guarantee spatial and temporal partitioning among applications in order to ensure an exclusive access of physical and temporal resources to the applications while sharing computing and communication resources. Temporal partitioning ensures that execution time and communication bandwidth reserved to an application, would not be changed either by overrun or by hazardous events of other applications. Spatial partitioning guarantees that physical resources, such as memory and I/O space of an application, are protected from illegal accesses attempted by other applications.
In this report, I have studied how to build an integrated real time system on top of a minimal microkernel which provides basic functionalities like scheduling, basic memory management, interrupt dispatch, inter process communication. Integrated real-time system should support any number of Real-time Operating Systems on top of microkernel, which can run with their own scheduling mechanisms which is most suited to application depending on their level of criticality.
1.2
Challenges in Scheduling of Real-time Tasks
The basic scheduling entities of integrated real-time systems are partitions and channels. A partition represents a real-time application that is protected from potential interference by means of temporal and spatial partitioning schemes. Multiple cooperating tasks are scheduled by a partition server within partition. To facilitate communications among applications, each partition can be assigned one or more communication channels. An application can transmit messages using its channel, and can access the channel buffers exclusively. In this sense, a channel is a spatial and temporal partition of a communication resource and is dedicated to a message-sending application.
Scheduling of an open system of complex independently developed real-time and non real-time tasks in Integrated Real-time Systems is a big challenge. Any scheduling algorithm must satisfy following objectives [6]
.
• It should allow each real-time application to validate the schedulability of the tasks in application in isolation from other application.
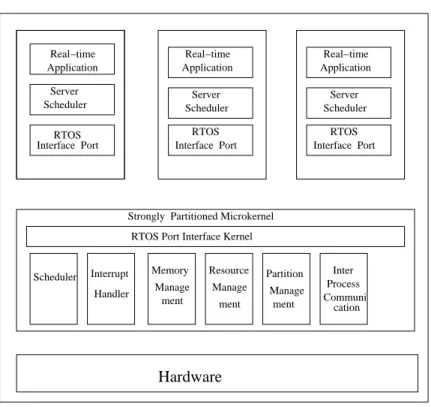
Figure 1.1: Integrated Real-time System Architecture
Hardware
Scheduler Application
Real−time Real−time Application
Real−time Application Server
Scheduler SchedulerServer SchedulerServer RTOS Interface Port RTOS Interface Port RTOS Interface Port Interrupt Handler Memory Resource Manage ment Partition Manage ment Inter Process Communi cation Strongly Partitioned Microkernel
RTOS Port Interface Kernel Manage
ment
• Once a task is admitted by real time application in system, schedulability of that task should be guaranteed.
• It should provide certain level of responsiveness to non real-time tasks.
• It should do the above without relying on fixed allocation of time.
Algorithms discussed in the next section, use two level hierarchal scheduling. On top level,there is an OS scheduler whose task is to allocates processors to the application server, setting their budget and deadline. Algorithm applied on OS scheduler depends on the system, it can be earliest deadline first,rate monotonic or simple cyclic scheduling. On bottom level, Application server scheduler’s responsibility is to schedule tasks with in the application. Any priority driven algorithm(either pre-emptive or non pre-emptive) suitable to the application is applied. Two level hierarchical scheduler achieves temporal partitioning. A fixed fraction of time is allocated to a particular partition, so even if a tasks starts misbehaving in an application, it can not take time given to other application. Thus the fault containment is ensured.
Chapter 2
Scheduling Algorithms for Mixed
Real-time Tasks
In this Chapter, we will overview both, static and dynamic algorithms for servicing soft aperiodic requests in real-time systems along with hard periodic tasks. In fixed priority servers, tasks are scheduled according to some fixed priority algorithm like rate monotonic, whereas a set of hard periodic tasks is scheduled using the Earliest Deadline First (EDF) algorithm in dynamic priority servers. All the proposed solutions can achieve full processor utilization and enhance aperiodic responsiveness, still guaranteeing the execution of the periodic tasks. Priority server are classified according to the priority scheme of the periodic scheduler [16].
2.1
Fixed Priority Servers
Background scheduler : Background scheduling is the simplest method for scheduling mix of periodic and aperiodic tasks. The strategy is to schedule aperiodic tasks in a background whenever the periodic tasks are not executing. The downside of the techniques is delayed response time for aperiodic task in high load times. This technique can be used only if aperiodic tasks are non critical, non real-time tasks.
Polling Server : In Polling Server, at the beginning of its period, it is charged at its full valueCs. Polling
Server becomes active and is ready to serve any pending aperiodic requests within the limits of its capacityCs. If no aperiodic request pending, Polling Server suspends itself until beginning of its
next period. Processor time is used for periodic tasks andCs is discharged to 0. If aperiodic task
arrives just after suspension of Polling Server, it is served in the next period. If there are aperiodic request pending, Polling Server serves them untilCs ≥0.
Deferrable Server : In Deferrable Server also, the basic approach is like Polling Server. However Deferrable Server preserves its capacity if no requests are pending at invocation of the server. Capacity is maintained until server period. Aperiodic requests arriving at any time are served as long as the capacity has not been exhausted. At the beginning of any server period, the capacity is replenished at its full value without any cumulation.
Priority Exchange Server(PE) : This is also a scheduling technique introduced for servicing set of soft aperiodic and hard periodic real-time tasks. This also provides high priority periodic server for servicing aperiodic requests. It preserves its high capacity by exchanging it for execution time of the lower priority periodic tasks. At beginning of its period, capacity is replenished at its full. If there is some aperiodic task in ready queue, they are served with the available capacity otherwise the
continues with some other low priority tasks until some aperiodic task arrives to use the capacity or it is degraded to priority level of background processing.
Sporadic Server(SS) : Sporadic server is another technique which allows to enhance the average re-sponse time of aperiodic tasks without degrading the utilization bounds of periodic task set. It creates high priority task for servicing aperiodic tasks and preserves the capacity at lower priority. Sporadic server replenishes its capacity only after it is consumed by aperiodic tasks.
Slack Stealing Server : This approach does not create a periodic server for aperiodic task servicing. Rather it creates a passive task, the slack stealer, which steals some processing time of periodic tasks (and consequently delays the periodic requests) for aperiodic tasks without causing hard deadline failures. The algorithm is divided in two phases, the computation of the slack time time which can be stolen to the periodic request and the slack stealer itself. This approach minimizes the response time of aperiodic tasks while preserving the schedulability of periodic tasks. However the time and the space complexities of this approach are generally proportional to the least common multiple of the periods of all periodic tasks, so that this approach is not adapted to most real-size systems.
2.2
Dynamic Priority Servers
Dynamic Priority Exchange Server(DPE) : DPE Server is an extension to priority exchange server for servicing aperiodic tasks, adapted to work with deadline based scheduling algorithm. The algorithm [2] lets the server trade its runtime with the runtime of a task with longer deadline in case there are no aperiodic task pending. In this way the server time is only exchanged with periodic tasks having longer deadline but never wasted. Aperiodic capacities receive priorities according to the deadline and the EDF algorithm like all other periodic tasks. The schedulability condition for DPS server isU+Us≤1.
Dynamic Deferrable Server : Dynamic Deferrable Server is dynamic version of Deferrable server adapted to earliest deadline first algorithm [2].
Dynamic Sporadic Server(DSS) : Dynamic Sporadic Server extends sporadic server to work under dynamic EDF scheduler. It is different from Sporadic Server in the way of assigning priority to the server. SS uses fixed priority based on Rate Monotonic algorithm whereas DSS has dynamic priority through a suitable deadline.Deadline assignment and capacity replenishment has some rules:
• When the server is created, its capacityCs in initialized at its maximum value.
• The next replenishment time RT and the current server deadlinedsare set as soon asCs≥0and
there is an aperiodic request pending.
• The replenishment amount RA to be done at RT is computed when the last aperiodic request is completed orCshas been exhausted.
Total Bandwidth Server(TBS) : As described in DSS [16] the execution of an aperiodic requests can be delayed significantly. The delays are mainly due to the fact that the server time, because of its long period is always scheduled with long deadline regardless of its longer period. To overcome this problem, Total Bandwidth Server assigns a possible earlier deadline to each task but the assignment should be done in such a away that overall processor utilization of the aperiodic tasks never exceeds the specified maximum valueUs. In TBS, each time an aperiodic tasks enters the system, the total
bandwidth of the server whereever possible is assigned to it. Task’s deadline is set to
dk =max(rk, dk−1) + CUk
k
So everytime the budget is exhausted, if there are some tasks at the head of the ready queue , it immediately replenishes the budget. Total bandwidth server is mostly used for non real-time applications.
Earliest Deadline Late Server(EDL) : EDL is dynamic version of slack stealing algorithm[2]. EDL’s basic principal is to use the available slack of periodic task for advancing the execution of aperiodic requests. Two version of EDF, EDS and EDL are proposed. In EDS, active tasks are processed as soon as possible whereas in EDL active tasks are processed as late as possible. So when there are no aperiodic tasks, periodic tasks are scheduled according to EDL algorithm. Whenever new aperiodic task enters the system, idle time of periodic tasks are computed and are used to schedule periodic tasks.
2.3
Comparisons of Various Scheduling Algorithms for
Schedul-ing Mixed Tasks
Comparison of above described algorithms is summarized as table.
Server Time Complexity Space Complexity Implementation work Static Dynamic
Background O(1) O(1) Obvious Yes Yes
Polling O(1) O(1) Simple Yes Yes
Deferrable O(1) O(1) Simple Yes Yes
Priority Exchange O(n) O(n) Hard Yes Yes Sporadic O(1) O(dTs/2e) Simple Yes Yes
Slack Stealer O(n) O(n) Hard Yes Yes
Chapter 3
Study of Integrated Real-time
System Implementations
3.1
A Dynamic-Priority-Driven Open Environment for
Real-Time Application
In the open system with EDF in OS scheduler, each real-time application is executed by a server. It applies two level hierarchal scheduling. At the lower level, the OS scheduler schedules all the servers on the EDF basis. At the upper level, the server scheduler of each server schedules the ready jobs of the application executed by the server according to the algorithm chosen for the application. Instead of doing global schedulability analysis based on timing attribute of all tasks in all applications in system, In an open environment, the developer of each realtime application can choose to schedule the tasks in the application according to an algorithm most suited for the application and validate the schedulability of the application independently of other applications that may run together with it. 3.1 shows architecture[7] of an open system with EDF OS scheduler A1, A2, ...An are real-time application in the system. A
resource is called global if it is accessed by more than one application where as it is called local if accessed exclusively by only one application.
3.1.1
Scheduling Hierarchy
In this architecture all non-real-time application are executed by serverS0and each real-time application
are executed on server Sk using scheduling algorithm σk. OS scheduler which runs on EDF basis,
maintains all the server. S0 is always total bandwidth server whereasSk can be either constant or total
bandwidth server depending on the type of tasks in the application. The difference between these two types of servers is that the budget of a total bandwidth server is replenished as soon as it is consumed when there are jobs ready to be executed by the server. In contrast, the budget of a constant utilization server is never replenished prior to its current deadline. Hence, a total bandwidth server is allowed to use background processor time while a constant utilization server is not. The open system uses constant utilization servers to execute hard real-time applications whenever it is possible so as to leave as much background processor time as possible to non-real-time applications. Each scheduling decision in the open system is made in two steps. The OS scheduler first finds the server at the head of its ready queue. In turn, that server executes the job at the head of the server’s ready queue.
3.1.2
Constant Bandwidth Server(CBS)
A Constant utilization server behaves like a task with constant utilization U as if its ready queue is never empty. A constant utilization server is defined [6]by its server size U, which is the fractional processor utilization allocated to the server. Execution time of every job in every real-time application is known
after the job is released, and let the execution time of the jobJiin the ready queue of a server for a
real-time application beei. The execution times of jobs in non-realtime applications are unknown. These jobs
are scheduled among themselves on a round-robin basis, one time slice at a time. Each constant utilization server becomes eligible for execution when the operating system gives it some execution budget. The budget is consumed whenever the server executes. The server is no longer eligible for execution when its budget is exhausted. It becomes eligible for execution again when the operating system replenishes its budget. Specifically, the operating system replenishes the server budget and sets the server deadline of a constant utilization server of size U according to the following rules.
1. Initially, the budget and deadline of the server are zero.
2. When a jobJi with execution timeei arrives at time ri while the ready queue is empty,
• ifd≤ri, set the server budget to b and deadline d tori+ (b/U).
• otherwise do nothing. 3. At the deadline d of the server
• if a jobJi with execution timeeiis waiting at the head of the ready queue, set the budget to
b and move the deadline tod+ (b/U).
• otherwise do nothing.
3.1.3
Concept of Slow Virtual Processor
A discussed in [6] ,if an application is schedulable is on a processor with speed σk, according to some
algorithm PK where σk is always less than 1 then it is also schedulable on a fast processor with speed
one when executed on a constant bandwidth server if folowing conditions are true.
• The serverSk has server sizeαk and is schedulable in the open system.
• When the operating system sets the budget of the serverSk, the replenished budget never exceeds
the remaining execution time of the job at the head ofSk’s ready queue.
• During any interval (t, d) between the time instant t, when the operating system replenishes the budget of the serverSk and the corresponding deadline d of the server, there would be no context
switch among the jobs in the applicationAk ifAk were executed alone on the slow processor with
speedαk.
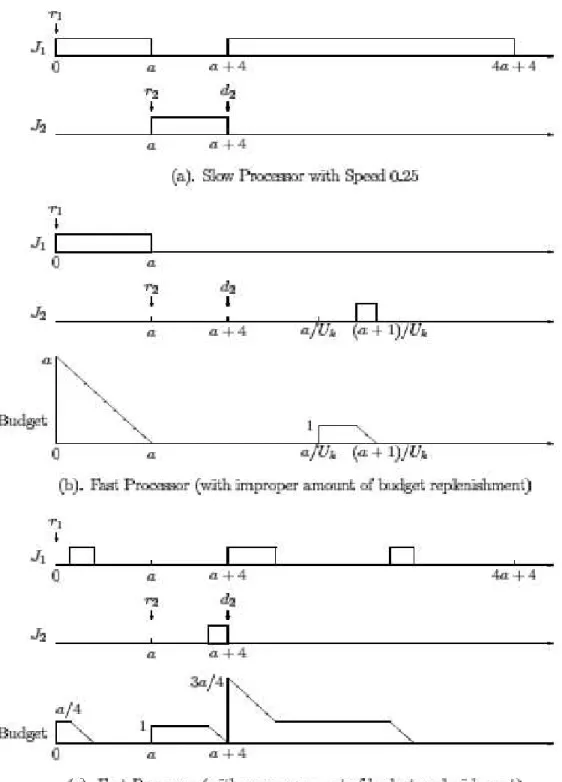
Example : LetAk uses the EDF algorithm to schedule its jobs, and Ak has two jobs,J1(0,a,10a + 4)
andJ2(a, 1, a + 4), (Three numbers in parenthesis represent release time, execution time and deadline of
the job, respectively.). So here in 3.1.3[6], we can see even if the jobs are schedulable on slower processor as shown in (a), if above mentioned rule are not followed then, second job misses its deadline when run on faster .
As shown in 3.1.3, deadline should be set equal to occurrence of next evenet in these system , so that if there is a context switch on slower processor, it also can happen in faster processor with fraction of time allocated to the application.
3.1.4
Predictable Versus Nonpredictable Applications
Application in integrated real-time systems are classified into two types:
Predictable Applications: Applications in which occurrence of next event is deterministic and can be known accurately. It includes all applications which are time driven and or whose release time of all Jobs are known in priori.
Nonpredictable Applications: Applications whose next occurrence of event is not known, have ape-riodic, sporadic or periodic tasks with release time jitter and scheduled according to preemptive, priority
driven algorithm.
A job in anonpreemptively scheduledapplication is never preempted by other jobs in the appli-cation, but may be preempted by jobs in other applications because the server of the application can be preempted by servers of other applications. In contrast, when a job is in a nonpreemptable section, it effectively executes at the highest priority and cannot be preempted by any job in the system.
3.1.5
Admission of New Real Time Application
Required Information for Acceptance TestWhen an applicationAk requests admission, it provides in its request the following information:
• Scheduling algorithmσk and the required capacityαk ofAk.
• Maximum execution time Lk of all nonpreemptable sections or critical sections guarding global
resources used byAk and jitter factor ∆k ofAk.
• Existence of aperiodic/sporadic tasks inAk, if any.
• Shortest relative deadline δk of all jobs with release time jitters in Ak and the shortest relative
deadline δk of all jobs in Ak if Ak is priority driven, or the shortest length δk between any two
consecutive events ofAk ifAk is time driven.
Algorithm for Acceptance Test
Algorithm for whether a task will be accepted or not, is describes [7] as follows: 1. Server Type and Size:
• Server Type: If some application in the system has nonpreemptable sections or uses global resources, and ifAkis scheduled by some preemptive algorithm,Skis a total bandwidth server.
Otherwise,Sk is a constant utilization server.
• Server SizeUk of Sk: IfAk is a predictable real-time application,
Uk =αk
Otherwise,
Uk =min{∆k, δ
0
k/(δ
0
k−q)}αk
where q is the length of scheduling quantum used in the open system.
2. IfUt+Uk+max1≤j≤N{Bj/δj} ≥1, whereBj=maxi6=j{Li}and N is the total number of
applica-tions in the system includingAk, reject Ak. Else, admitAk, and
• IfAkis the first application that has nonpreemptable sections or uses global resources admitted
into the system, change the server type of all servers that execute preemptive applications to total bandwidth server.
• IncreaseUt byUk.
• Create a serverSk of the specified type with sizeUk forAk.
• Set server budget and server deadline d to zero.
3.1.6
Server Maintenance
Maintenance of total bandwidth serverSk whose deadline is d [7] is as follows:
• Invoke the server scheduler ofSk to insertJi inSk’s ready queue.
• Update the latest release timer−1(j) of the taskTj to whichJi belongs.
• SetJi’s remaining execution timee
0
i toei.
• IfJi is the only job in the ready queue
(a) Invoke the server scheduler ofSk to estimate the occurrence time tk of the next event of
Ak.
(b) Set the server budget to(tk−max{t, d})Uk, and server deadline d totk.
2. When a job inAk completes at time t,
• ifSk’s ready queue is not empty and jobJiis at the head of the ready queue,
– If t ≥d and if a job in Ak with a higher priority than that of Ji will be released at time
d, do nothing.
– Otherwise,
∗ Invoke the server scheduler ofSk to estimate the occurrence timetk of the next event
ofAk after time d.
3. After a jobJi in Ak requests for or releases a local resource, invoke the server scheduler of Sk to
change the priorities of some jobs in its ready queue if necessary and move the job with the highest priority to the head of its ready queue.
Maintenance rules for constant utilization servers and servers of nonpreemptive application is similar to algorithm for total bandwidth server. Constant bandwidth server maintenance algorithm is slightly different, specifically, when the budget of the serverSk is exhausted before the current server deadline d,
the budget is not replenished immediately if a job J inAk with a higher priority than the jobJ0currently
at the head ofSk’s ready queue will be released at or before time d. This is so that the server cannot use
the budget reserved for J to execute J0. Budget is not replenished immediately in constant bandwidth
server so that unused time left in constant bandwidth server can be given to execute non-real-time or soft real time tasks being executed by total bandwidth server.
3.1.7
System Service Provider
In open system, system service provider such as network or file system are implemented as special purpose user-level server application. Each service is executed by a passive server of very small size. Budget to these passive servers are given as follows:
• Services which are for administrative purpose, OS scheduler replenishes its budget as it is a total bandwidth server.
• Passive servers are provided with execution budget and an associated deadline whenever an appli-cation requests service from service provider executed by that passive server.
Operating system creates a passive server to execute each service provider. System providers have responsibility to create new jobs in the address space of the service provider in response to request for its service from its client and to process incoming data to identify the receiver and notify the receiver.
3.2
A Fixed-Priority-Driven Open Environment for Real-Time
Applications
Real−time Application
Scheduler
RM
Time Sharing RMS+PCp
Non−Real−time
EDF+SRP EDF
Sporadic Server
Fixed Priority−Drivwn (RM)
Operating System
Sporadic Sporadic Sporadic Sporadic
Server Server Server Server
S1 S2 S3 S4 Sn
S0
Sporadic Server
Scheduler Scheduler Scheduler Scheduler SchedulerCyclic
Application ApplicationReal−time ApplicationReal−time ApplicationReal−time Real−timeApplication
Figure 3.3: Open System Architecture with Rate Monotonic Scheduler
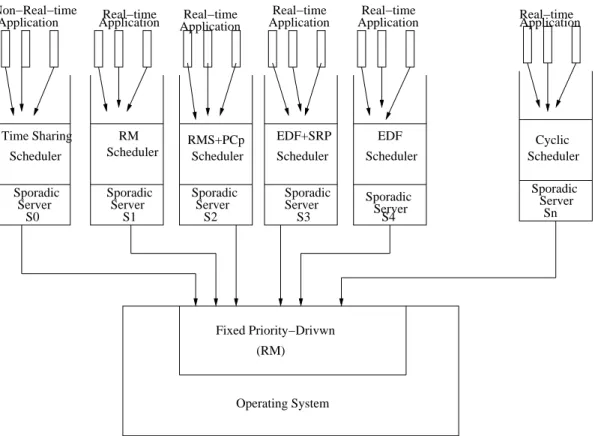
operating systems may not support the earliest deadline first scheduling very well. Concept of sporadic server is used to preserve CPU cycles for applications. Schedulability tests for real-time applications which adopt the rate monotonic scheduling algorithm, the earliest deadline first scheduling algorithm the priority ceiling protocol and the stack resource policy in application server, are developed. Open system architecture with rate monotonic OS scheduler is shown in 3.2.
3.2 provides the open system architecture supported by the two-level fixed-priority hierarchical scheme. The system has a single processor whose speed is one. There are real-time and non-real-time applications executing in the open environment. Each applicationAi is executed by a sporadic serverSiwith a CPU
budget ci and a periodpi. Each sporadic server is associated with a ready queue contains ready tasks
of the application executing on the server. Each server has a scheduler associated with it. The server scheduler uses the scheduling algorithmσi, such as EDF or RM, chosen for the applicationAito schedule
tasks and order tasks in the ready queue of sporadic server Si. 3.2 shows that server S0 uses a time
sharing algorithm to schedule tasks in application. The OS scheduler schedules all the ready servers according to a fixed- priority scheduling algorithm. Since the rate monotonic scheduling algorithm is an optimal fixed priority scheduling algorithm, RM is chosen as algorithm to be used in OS scheduler. Tasks of the scheduled ready server can execute until they run out of the budget of the server, or a higher-priority ready server arrives. Tasks of the scheduled ready server execute in the order defined by the chosen scheduling algorithm of the server.
3.2.1
Operations of OS Scheduler
The operations of the OS scheduler are defined as follows:
• Create a sporadic server Si with a CPU budgetCi and a periodσi for a new application Ai ifAi
• The budget replenishment mechanism is done according to the definitions of sporadic server.
• The scheduler of each serverSi schedules tasks according to the chosen algorithm Pi.
• The scheduled task of each serverSi executes under the CPU budget of Si .
• The OS scheduler schedules the ready server with the highest priority in the system.
• Destroy the corresponding sporadic server when the application terminates.
3.2.2
Scheduling and Admission Control
In this architecture,each server has a distinct priority.The priorities of servers are inversely proportional to their periods.When a sporadic server is used to execute a non-real-time application, the period and the CPU budget of the server can be set arbitrarily but the period is made a small number to make the application responsive to user requests.
When a sporadic server is used to execute a real-time application, the period of the server must be no larger thandi/(2 +dccie) for any taskτiwith CPU requirementciand relative deadlinediin the real-time
application, where c is the CPU budget of the server. It is because the sporadic server is only guaranteed to receive c units of CPU cycles within every p units of time. In order to better utilize the CPU cycles, we make the periods of all sporadic servers in the system are harmonically related to achieve 100 % cpu utilization. the admission control mechanism [11] is described as follows3.2.3:
Let U be the sum of utilization factors of all sporadic servers in the system, where the utilization factor of a server is the ratio of its CPU budget and period. A new application Ai with a sporadic server Si is
admitted to enter the system if U +Ui 100 %, where Ui is the utilization factor ofSi.
3.2.3
Independent Application over Sporadic Servers
In open systems with rate monotonic OS scheduler, schedulability of each applicationAi with a reserved
CPU capacity C/P can be validated independently of other applications, where the CPU budget and the period of the corresponding server Si are C and P, respectively and reserved capacity ofAi isC/P.
Period P of the server be the greatest common divisor of
all of the periods of tasks in the application, and the initial phase of each task occur at a time point which is a multiple of P. CPU requirements of each periodic task in Ai can still be much less than P.
Sufficient and necessary condition is derived for servers which adopt RM or EDF in 3.2.3.
RM Server Scheduler
A critical instant for a task is defined as an instant at which a request for the task will need to take the maximum number of sporadic server periods to complete. A critical instant for any task in Ai occurs
whenever the task is requested simultaneously with requests for all higher priority tasks in Ai. A real
number αis the achievable utilization factor of a scheduling algorithmP. If any task set with a utiliza-tion factor no larger than αis schedulable by P. the utilization bounds for RM scheduling is given in the following theorem.
Theorem: The achievable utilization factor of the RM scheduling algorithm for server Si is U =
C Pn(2
1/n−1).
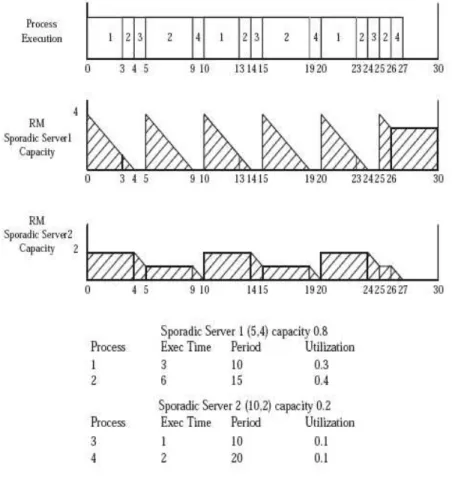
The concept will be more clear from following example [11]:
Example1: Let a system consist of two real-time applications which adopt a RM scheduler. The CPU budget and the period of the first sporadic server S1 are 4 and 5, respectively. Two periodic tasksτ1and
τ2execute on S1. The CPU requirements and the period ofτ1(/τ2) are 3 and 10 (6 and 15), respectively.
The CPU budget and the period of the second sporadic serverS2are 2 and 10, respectively. Two periodic
of τ2, and the priority of τ3 is higher than the priority of τ4. 3.2.3 shows the executions of all tasks on
serversS1 andS2 from time 0 to time 30. At time 0, all tasks arrives. τ1 on serverS1 starts execution.
Since the priority levels P1 and P2 both become active, the replenishment time RT1 of S1 is set as 5,
and the replenishment time RT2 ofS2 is set as 14. Since the CPU budget ofS1is 4,τ2 starts execution
at time 3 after τ1 finishes its execution. At time 4, the CPU bud- get ofS1 is exhausted, and τ3 onS2
starts execution. At time 4, the priority level P1 becomes idle, and the priority level P2 becomes active. The replenishment amount of S1 is set as 4. At time 5, the CPU budget of S1 is replenished such that
S1preemptsS2. τ2 onS1resumes its execution. The replenishment time RT1 ofS1is set as 10. At time
9, the CPU budget ofS1 is exhausted again. Althoughτ2 has not finished its execution,τ2 must stop.
τ4 on S2 starts its execution. At time 10, the CPU budget of S1 is replenished such that S1 preempts
S2. Since the second request ofτ1arrives,τ1 starts its execution at time 10 althoughS2has not finished
its execution.
EDF Server Scheduler
In this section, we will derive schedulability conditions for scheduling tasks in EDF server scheduler when OS scheduler is rate monotonic. An overflow is said to occur at time t if there exists a task which misses its deadline at time t whereas a server is said to be idle when idle at time t if the priority level of the server is idle, and the CPU budget of the server is not exhausted. It is proved that when EDF is used to schedule tasks in applicationAi, there is no idle time for serverSi prior to an overflow.
Schedulability condition is defined in following theorem for EDF Server Scheduler.
Theorem: For the set of n periodic tasks serviced by a sporadic server Si with a period P and a
CPU budget C, EDF is feasible if and only if Pci
pi ≤
C P.
Example2: Let us take the same example, except that the first application now adopts an EDF server scheduler.The execution of all the task is shown in 3.2.3. The is self explanatory and it can be observed that according theorem the achievable utilization bound of the first application is 4/5 = 0.8. Since the total utilization factor of the first application is (0.3+0.4) = 0.7, the first application is schedulable.
3.3
SPIRIT (Strongly partitioned Integrated Real-time System)
The strongly partitioned real time system provides temporal and spatial partitioning for its integrated real time applications. The SPIRTS architecture [8] adopts a two-level hierarchical scheduling mechanism. In the lower level, multiple partitions are dispatched under a cyclic scheduling, whereas, in the higher level, multiple periodic tasks of each partition are scheduled according to a fixed priority algorithm.
3.3.1
Design Concept
To achieve scheduling independence in run time between periodic tasks and their partitions, a cyclic scheduler guarantees distance constraint characteristics of all partitions. Provided distance constraint in cyclic schedule, periodic task will be guaranteed to meet its deadline regardless of its arrival time. Soft and hard aperiodic tasks are also supported efficiently by reclaiming unused processor capacities with a distance-constrained cyclic scheduling approach.
Aperiodic tasks are served by the aperiodic task server which belongs to the same partition as the aperiodic task. To ensure the schedulability of the periodic tasks, the server would not consume any processing capacity allocated to the periodic tasks in the partition. Nevertheless, there exists available processing capacity such as unused capacity at the partition level that can be allocated to the aperiodic task servers. Also there exists pre-allocated processing capacity for aperiodic tasks, which can be shared by partitions. SPIRIT utilizes the available capacity to maximize the performance of aperiodic tasks while meeting the distance and capacity constraints for each partition. The Distance Constraint guaranteed
• Left Sliding (LS): The LS(x) operation slides the current phase of the cyclic schedule left by x units of time in O(1) time. There are two situations at which LS(x) will be applied. One is when the current partition server has finished x units of time earlier than the allocated capacity. The other case is when the scheduler invokes a partition server with an allocated capacity of x, but finds no pending periodic task or aperiodic task, respectively. Left sliding is used too reduce the average response time of aperiodic tasks, by eliminating idle processing during assigned slots.
• Right Putting(RP): RP operation exchanges the remaining allocation of the current partition server with a future MPAS(Multi Period Aperiodic Server) of the same period. It is initiated when either an aperiodic task arrives or there is still a pending aperiodic task after the completion of a partition server.
• Compacting: The operation delays a MAPS entry and exchanges it with the entry of a future partition server. A heuristic selection is performed in a Compacting operation such that the neigh-boring entries that belong to the same server can then be merged in the scheduling table.
Dynamic applications of these operations do not violate the distance constraint characteristics of a parti-tion cyclic schedule. SPIRIT also uses a heuristic deadline decomposiparti-tion and channelcombining algorithm to schedule both partitions and communication channels concurrently. This way message communication is also taken into account.
3.3.2
Schedulability Conditions
Based on the necessary and sufficient condition of schedulability, taskti is schedulable if there exists a
tHi ={lTj|j= 1,2, ...i;l= 1,2, ...bDj/Tjc}S{Di}, such that
Wi(αk, t) =Pij=1
Cj
αkd
t Tje ≤t
where theWi(αk, t) shows worst cumulative execution demand made on the processor by the tasks
with a priority higher than or equal to ti during the interval [0,t].
Bi(αk) =maxtHi{t−W(αk, t)},
represents the total period in the interval [0, Di] that the processor is not running any tasks with a priority higher than or equal to that of ti. It is equivalent to the level-i inactivity period in the interval [0, Di].
B0(αk) is defined as minimum ofBi(αk) of all the tasks in a particular application. So it is nothing but
least period which is inactive in the time allocated to that partition.
Schedulability Conditions.
The applicationAk is schedulable at serverSk that has a partition cyclehk [8] and a partition capacity
Ak, if
• Ak is schedulable at a dedicated processor of speedAk.
• ηk ≤B0(αk)/(1−αk).
Above mentioned condition essentially says that, time given to run other applications should be les than equal to inactivity period of that application.
• During each partition , the server runs forαk∗ηk
• it gets blocked for ( 1-αk )ηk.
• If there is no active tasks in partition, the processor remains idle and can not run any other active task of other application.
3.3.3
Determining Partition Size
It is observed [8] that if αk is slightly greater than utilization then tasks have small inactivity period.
Whenαkis much greater than utilization of partition, the inactivity period is bounded to the smallest task
period in each period due to the fact that the tasks with a short period cannot accumulate more inactivity period before their deadlines. Feasible capacity and partition size is found out for every application in the system and then a common partition size which satisfies requirements of every partition, is computed. The execution period allocated to the partition needs to be not continuous, or to be restricted at any specific instance of a scheduling cycle. Making use of this property cycle scheduling can be done in two ways.
Unique partition cycle approach : OS schedules every partition in a cyclic period equal to the min-imum ofηk and each partition is allocated an amount of processor capacity that is proportional to
αk.
Harmonic partition cycle approach : When partition cycles are substantially different,adjust them to form a set of harmonic cycles in whichηj is a multiple ofηi, ifηi≤ηj for all i and j.
3.4
Comparison of Algorithm for Scheduling Tasks in Open
Sys-tem Architecture
Dynamic Priority Based Static Priority Based SPIRIT Open Environment Open Environment
Partition Scheduling Dynamic Static Static Scheduling Hierarchy Two-level Two-Level Two-Level OS Scheduler EDF Based Rate Monotonic Cyclic
Application Server Any RM,EDF Any
Overhead Large Medium Least
Efficiency Less High High
Soft Aperiodic Task Total Bandwidth Server Tasks with Large Period Server with Less Priority System Resources Passive Server Special Mechanism for Not Specified
Local and Global synchronization
Guarantees Strict Strict Strict
Flexibility High Medium Low
Execution time Non-continuous Non-continuous In Chunks in Partitions
Chapter 4
Microkernels
A microkernel is a minimal form of computer operating system kernel providing a set of primitives, or system calls, to implement basic operating system services such as address space management, thread management, and inter-process communication. All other services, those normally provided by the kernel such as networking, are implemented in user-space programs referred to as servers. A concept is tolerated inside the microkernel only if moving it outside the kernel, permitting competing implementations, would prevent the implementation of the system’s required functionality.
4.1
SPIRIT Microkernel
SPIRIT [10] is a second generation microkernel specially designed for supporting strong partitioning concept using protected memory manager and cyclic partition manager. It provides dependable inte-gration of real-time applications, flexibility in migrating operating system personalities from kernel to user applications, including transparent support of heterogeneous RTOS on top of the kernel, high per-formance, and real-time feasibility. A variety of operating system personalities, such as task scheduling policy, exception-handling policy and inter-task communication, can be implemented within the partition according to individual requirements of partition RTOS.
4.1.1
Model and Design Concept of SPIRIT
The SPIRIT is composed of multiple communicating partitions in which there are also multiple interacting tasks as introduced in [8]. The SPIRIT uses the two-level hierarchical scheduling policy in which partitions are scheduled by the SPIRIT microkernel’s partition scheduler, and the tasks of a partition are scheduled by the fixed-priority driven local task scheduler of each partition.
SPIRIT being the strongly partitioned integrated real-time systems, it has the following design con-cepts at its core:
Strong temporal partitioning : It ensures temporal partitioning by using hierarchical scheduler par-titioning whereas Application scheduler based algorithm.
Supporting applications based on heterogeneous RTOS on top of the kernel : Spirit is designed to provide the flexibility of accommodating COTS real-time operating systems on top of the kernel. It helps in running various different operating system personalities on top of microkernel which is basic requirement for any integrated real-time systems.
Second-generation microkernel architectural concepts : It follows the principle of minimality and keeps minimal required functionalities such as process communication, address space management and scheduling. Since the SPIRIT supports different kinds of application environments in a shared
Figure 4.1: Cyclic Scheduler in SPIRIT Task Local−Priority Driven Task Scheduler Partition Task Local−Priority Driven Task Scheduler Partition Task Local−Priority Driven Task Scheduler Partition Task Task Task
1 2 n
Distance Constrained Cyclic Partition Scheduler
4.1.2
SPIRIT Architecture
The SPIRIT microkernel is a strongly partitioned operating environment to the partitions that can accommodate application specific operating system policies and specialties. A partition can have the flexibility of choosing its own operating system personalities, such as task scheduling policy, interrupt and exception handling policy, and inter-task communication, etc.
Memory management
Management of two-level hierarchy of address spaces, kernel and partition address spaces is implementa-tion of address space is implemented by a hardware protecimplementa-tion mechanism on the basis that optimizaimplementa-tion of address space management to the underlying processor architecture is the best solution to achieve both efficiency and deterministic access. Address space allocation and access policy are determined at system integration time and saved in a secure kernel area therefore therefore partition creation can be done in SPIRIT. Physical memory is divided into non overlapped regions that satisfies memory requirement of the partition. User application can have its own memory management scheme.
Partition Management
A partition represents Strongly protected entity in which different kinds of real-time operating systems and their applications can be implemented. All information regarding partitions such as time slices, memory allocations, etc, are stored in the partitions configuration area in kernel space which is made accessible only to kernel. Shared libraries are not allowed among partitions to make partitions fault contained. As discussed in previous section, distance-constrained cyclic partition scheduler is used to dispatch partitions.
Exception Management
Interrupts and exceptions are handled differently in SPIRIT microkernel. An interrupt is triggered from the external environment of the core processor, while an exception is triggered internally during the execution. Exceptions are usually processed in the context of their own partitions using the event delivery object and the event server. Thus any exception in a partition can not affect any other partition.
Kernel Primitives Interface
As the kernel primitives cannot be directly called from a partition because a partition runs in a different privilege mode, trap instruction is used to call kernel primitives. Information exchanged between the kernel and partitions is stored in generic object code that is independent of the object file format.
Figure 4.2: Event Delivery Object(EDO)
Inter-partition Communication
Publish-Subscribe model as the basic inter-partition communication architecture of SPIRIT microkernel which is designed to support a variety of communication models, fault tolerance, evolvability and strong partitioning.
4.1.3
Generic RTOS Port Interface(RPI)
The SPIRIT microkernel a generic RTOS Port Interface that can be used to port different kinds of COTS real-time operating systems on top of the kernel. Some important RPIs are described as following:
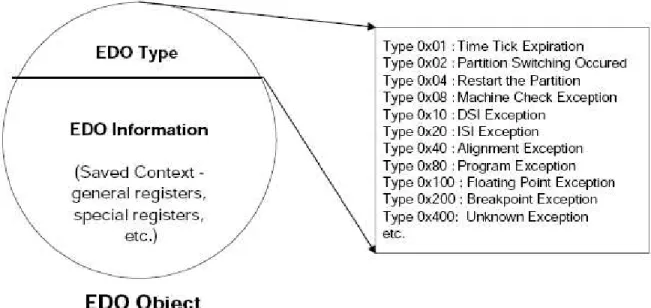
Event Delivery Object(EDO)
A partition is to be informed of hardware events, such as time tick expiration, processor exceptions, and interrupts. Since these event classes are caught by the SPIRIT microkernel in supervisor mode, secure and efficient delivery of an event from the kernel to a partition is necessary to be processed in the local event handling routine of a partition. SPIRIT can not run local event handler directly as it may violate the strong partitioning requirements of the system due to the possible corruption or overrun of the event handler. Another reason for keeping access to local event handler exclusive, is to reduce the complexity of microkernel by not keeping the detailed knowledge of the RTOS design which would have been needed if kernel accesses the local handlers. The EDO is physically located in the address space of a partition, so it can be accessed from both the kernel and its owner partition.
Event Server
Event server acts as a a mediator between the kernel and partition’s by executing partitions local interrupt and exception handling routines, and performing housekeeping jobs such as delivering local kernel events that occurred during the deactivation time of a partition. The implementation of an event server is
Figure 4.3: Functioning of Event Server Kernel Context Switch Request Kernel Context Switch Request Kernel Context Switch Request Kernel Context Switch Request Process Events Check the Exception Type Call proper local exception handler call local timer tick handler
(use EDO info while saving context,prepare resume data for kernel context switch request) House keep− Call local rescheduling routine info) (use EDO ing job
(timer tick value adjustment, delivery of info, message) Check Event Server Call from Kernel others Time Tick Expiration Exception Partition switching
An event server is user-mode-called from the SPIRIT microkernel, it checks the type of EDO and process the EDO properly. Generic Event server’s functionality is shown through the 4.1.3.
Kernel Context Switch Request (KCSR) Primitive
It delegates the kernel to perform a context loading job. The kernel is provided with the restoring context information with which the kernel loads and resumes a new task. The primitive is of two type, one is for loading privileged registers only, and the other for loading all registers. As registers are accessible by partitions, use of primitive will give better performance in terms of security.
User-mode Interrupt Enable/Disable Emulation
SPIRIT microkernel environment does not allow a partition to execute interrupt control functions. Dis-abling interrupts may block the SPIRIT microkernel for a significant amount of time. To solve this problem, it is required to re-write the original interrupt enable and disable functions, while guaranteeing its original intention of protecting critical sections from interrupts. Atomic set and reset instructions are used to implement replacements of the original interrupt enable and disable functions.
4.2
L4 Architecture
L4 is a second generation microkernelintroduced in [1] which has concept of minimality. It implements only three concepts, address space management, threads and inter process communication in kernel. Everything other than these, like file system management, device driver and interrupt handling , are kept outside the kernel and they run in user mode as any other user application.
Address Space Management
Address space is defined as mapping which associates each virtual page to physical frame and marks it non accessible [13]. The mapping is implemented by TLB hardware and page tables. Microkernel L4 which is common sublayer to all subsystems abstract the hardware concept of the address space to implement protection. The basic idea is to support recursive construction of address spaces outside the kernel. There is one address spaceσ0which essentially represents the physical memory and is controlled
by the first subsystem S0. At system start time, all other address spaces are empty. For constructing
and maintaining further address spaces on top ofσ0, the microkernel provides following three operations: Map : The owner of an address space can map any of its pages into another address space, provided the recipient agrees. Afterwards, the page can be accessed in both address spaces. In contrast to granting, the page is not removed from the mapper’s address space. Comparable to the granting case, the mapper can only map pages which itself already can access.
Grant : The owner of an address space can grant any of its pages to another space, provided the recipient agrees. The granted page is removed from the granter’s address space and included into the grantee’s address space. The important restriction is that instead of physical page frames, the granter can only grant pages which are already accessible to itself. Granting is used when page mappings should be passed through a controlling subsystem without burdening the controller’s address space by all pages mapped through it.
Flush : The owner of an address space can flush any of its pages. The flushed page remains accessible in the flusher’s address space, but is removed from all other address spaces which had received the page directly or indirectly from the flusher. Although explicit consent of the affected address-space owners is not required, the operation is safe, since it is restricted to own pages. The users of these pages already agreed to accept a potential flushing, when they received the pages by mapping or granting.
Address space concept leaves memory management and paging outside the microkernelkernel. Only the grant, map and flush operations are retained inside the kernel. Mapping and flushing are required to implement memory managers and pagers on top of the microkernel.
4.2.1
Threads
A thread is an activity executing inside an address space. A thread is characterized by a set of registers, including at least an instruction pointer, a stack pointer and a state information. A thread’s state also includes the address space in which it currently executes. This dynamic or static association to address spaces is the decisive reason for including the thread concept in the microkernel. To prevent corruption of address spaces, all changes to a thread’s address space must be controlled by the kernel.
4.2.2
Inter-process communication (IPC)
Inter-process communication (IPC), must be supported by the microkernel. The classical method is transferring messages between threads by the microkernel. IPC always enforces a certain agreement between both parties of a communication: the sender decides to send information and determines its
Figure 4.4: Recursive address space construction
Initial space(Physical Memory)
Driver
Mem Server1 Mem Server2
Pager1
Pager2 Application
Application
Application
Application
Driver
but also, together with address spaces, the foundation of independence. Other forms of communication, remote procedure call (RPC) or controlled thread migration between address spaces, can be constructed from message-transfer based IPC. In L4 , grant and map operations also need IPC, since they require an agreement between granter/mapper and recipient of the mapping.
The natural abstraction for hardware interrupts is the IPC message. The hardware is regarded as a set of threads which have special thread ids and send empty messages to associated software threads. A receiving thread concludes from the message source id, whether the message comes from a hardware interrupt and from which interrupt.
4.2.3
Clans and Chiefs
L4 does not send message directly due to security concerns, therefore secure message communication among processes uses the concept of clans and chiefs. A clan is a set of tasks headed by a chief task. Inside the clan all messages are transferred freely and the kernel guarantees message integrity. But whenever a message tries to cross a clan’s borderline, regardless of whether it is outgoing or incoming, it is redirected to the clan’s chief. This chief may inspect the message and decide whether or not it should be passed to the destination to which it was addressed.
As shown in the 4.2.3, these rules apply to nested clans as well. Subject restrictions and local reference monitors can be implemented outside the kernel by means of clans. Since chiefs are tasks at user level, the clan concept allows more sophisticated and user definable checks as well as active control. Clan can be per machine, per system version, per user or per task.
4.2.4
Flexibility
L4 provides such a design that so that basic features provided by normal operating system can easily be implemented on top of the microkernel. Foe example memory manger and pagers , as the server manages initial address spaceσ0and then memory managers in different partition can be implemented using map,
Figure 4.5: Clans And Chiefs
Chief Chief
Chief Chief
Clan1
Clan2 Clan3
Clan4
grant, flush operation. As memory manger ensure a fixed amount of memory per application, multimedia resource allocation is easily supported. A device driver is a process which directly accesses hardware I/O ports mapped into its address space and receives messages from the hardware through the standard IPC mechanism. Similarly Remote procedure communication and kind of unix server be easily implemented using IPCs.
A small set of microkernel concepts lead to abstractions which stress flexibility, provided they perform well enough. The only thing which cannot be implemented on top of these abstractions is the processor architecture, registers, first-level caches and first-level TLBs.
4.3
Fiasco
Fiasco [3] is full reimplementation of L4 with non blocking synchronization which makes it most suitable for real time application. Fiasco’s main goal is to provide good real-time property. First is to avoid priority inversion and second is that short critical section should not cause overheads for synchronization.
4.3.1
Non Blocking Synchronization
Non blocking fiasco provides full pre-emptability and avoids priority inversions, allows multi-CPU con-currency, greater insulation from crashed processes and interrupts are almost never disabled. Thus non blocking property of fiasco makes it perfect for implementing real time systems on top of it.
Non-blocking synchronization are of two types[3]:
• Wait Free Synchronization: It is similar to simple priority inheritance in which, when a higher priority thread detects conflict in access of any shared resource with lower priority thread B, then A helps B to complete its critical section. During helping, A lets its priority to B to ensure that no other lower priority jobs can interfere. Wait free synchronizations not deadlocks free.
• Lock Free Synchronization: In this synchronization mechanism, locks are not used.Transactions prepare their results out of line and then try to commit them to the pool of shared kernel data using a single atomic CPU instruction like Compare-And-Swap. If committing a transaction fails, retry with backoff. It ensures that at least one transaction can complete in constant CPU time. Lock Free Synchronization has many advantages like fast synchronization algorithms for several data structures available, avoids deadlock, provides automatic multiprocessing. At the downside , it depends on instruction set and cannot be used as general synchronization mechanism.234473
4.3.2
Design Guidelines
• Classification a systems objects: Systems’s object are classified in local and global state. Local state consists of objects used only by related threads, that is, threads that cooperate on a given job or assignment. Global state consists of the objects shared by unrelated threads.
• Frequently-accessed global state should be implemented using data structures that can easily be accessed with lock-free synchronization.
• Global state not relevant for real-time computing, and local data can be accessed using wait-free synchronization.
Kernel Objects Local state
• Threads: The thread descriptors contain the complete context for thread execution, a kernel stack, areas for saving CPU registers, a reference to an address space, thread attributes IPC state, and infrastructure for locking .
• Address spaces: There exists one address space per task. Address spaces implement the x86 CPUs two-level page tables. They also contain the task number, and the number of the task that has the right to delete this address space.
• Hardware-interrupt descriptors: Each hardware interrupt can be attached to a user-level han-dler thread. The kernel sends this thread a message every time the interrupt occurs.
• Mapping trees: Like L4, the Fiasco microkernel allows transferring persistent virtual-to physical page mappings via IPC between tasks. The mapping in the receiving task is dependent on the sender such that when the mapping is flushed in the senders address space, mappings depending on it are recursively flushed as well . Mapping trees are objects to keep track of these dependencies. There is one mapping tree per physical page frame.
Global state
• Present list and ready list: These double-linked ring lists contain all threads that are currently known to the system, or ready-to-run, respectively. On both lists, the idle thread serves as start and end of the list.
• Array of address space references: This array is indexed by an address space number. It con-tains a reference for each existing address space; for nonexisting address spaces, the array concon-tains an address space index referring to the task that has a right to create the address space. The Fiasco microkernel uses this array for create-rights management, and to keep track of and look up created tasks.
• Array of interrupt-descriptor references: In this array, the Fiasco microkernel stores assign-ments between user-level handler threads and hardware interrupts.
• Page allocator: This allocator manages the kernels private pool of page frames.
• Mapping-tree allocator: This allocator manages mapping trees. Whenever a mapping is flushed or transferred using IPC, the corresponding mapping tree grows or shrinks. Once certain thresholds are exceeded, a new (larger or smaller) mapping tree needs to be allocated; this behavior is an artifact of the Fiasco microkernels implementation of mapping trees.
4.4
Comaprison of Various Real-time Microkernel
L4 is a generic microkernel , on top of which any operating system can be ported. Fiasco is reimplemen-tation of l4 with non-blocking synchronization which makes it fully pre-emptive and suitable for real-time systems. Spirit microkernel is specially designed microkernel with spatial and temporal partitioning at its core design. Comparison of microkernels is summarized as following:
SPIRIT L4 Fiasco
Generation Second Second Second
Synchronization Non-blocking Blocking Non-Blocking Memory Management Partition Memory Recursive dynamic Same as L4
allocated statically partitioning(Grant, map, Unmap)
Task Creation Static Dynamic Dynamic
Task Deletion Partition size No effect No effect needs to be changed
Task Scheduling Cyclic Scheduling EDF Based Rate Monotonic Task Scheduling Small(One time overhead Large Medium
Overhead for cycle creation)
Task Scheduling O(1) O(n) O(1)
Complexity
Task Priority Static Dynamic Static
Timer Management Kernel Tick
Resource Reservation No Provision System Service Global and Local Provider resource synchronization
Chapter 5
Strong Partitioning in Reservation
Based System
In above discussed algorithms and systems, temporal constraint consideration for CPU is considered. In integrated real-time systems, strict temporal isolation and temporal containment for all the resources should be made. In integrated systems, different application(partition) will specify their resource required, budget constraints, and kernel should perform admission control, scheduling and enforcement to ensure that the temporal misbehavior of any application does not affect other application. Resource reservation should be done in such a way that operating systems mechanism do not become very complex , they provide acceptable temporal isolation and keep schedulabilility penalties to minimum. Reservation based system introduced in [5] do the following:
1. Admission control is performed online, forcing all applications to go through some form of schedu-lability analysis.
2. Stated resource and timing requirements are monitored and enforced by the operating system, ensuring temporal isolation between real-time tasks.
3. The tasks’s ability to meet their timing constraints remains the same, independent of the competing tasks in the environment.
4. Application developers do not need to worry about the correct priority assignment to their tasks, particularly when the task mix can change at run-time, even in unpredictable ways.
5. Aperiodic and non-real-time tasks can be guaranteed to make forward progress in such systems by assigning reservations to these applications.
Most reservation based operating systems, provide temporal isolation only if the application tasks are independent from one another but this assumption is highly unrealistic. Two approaches to achieve temporal isolation when applications do share common user-level services and resources, extensions to priority inheritance techniques as well as priority ceiling protocol techniques [5], are discussed.
5.1
Resource Kernels
A resource kernel [5] is a system which provides timely, guaranteed and protected access to system resources. Resource set is defined as aggregation of various reserved resources like CPU, disk bandwidth, network bandwidth etc. Four mechanisms ensure both that the applications bound to a resource set receive the amount of resource specified in the reservation, and that they do not consume more than this amount.
Admission control : Checks the schedulability of a reserve and that of existing reserves whenever a reserve is created.
Scheduling : Implements the dynamic allocation of the resources to give the tasks their reserves.
Enforcement : Limits the consumption of the resources to the reserved quantity.
Accounting : Supports the scheduler and enforcement mechanisms. Application tools could also use the accounting information to visualize the resource utilization or to tune it.
5.2
Policy Decisions and Comparison Metrics
In any reservation based system three policy decision must be taken when any resource R is to be accessed and those are prioritization policy, charging policy and enforcement policy. Different choice for the charging and enforcement policies will be compared on the basis of degree of isolation, that is what happens when a task misbehaves violating timing constraints and schedulability penalty incurred in terms of number of tasks being schedulable as compared to normal priority based systems.
All reservation based systems should satisfy strict temporal isolation i. e. timing behavior can not be affected by timing missbehavior of any other task and temporal containment i.e. if timing can not affect tasks with which it does not share any resource.
5.3
Various Techniques
Right combination of prioritization, enforcement and charging policies is very important to make any reservation based system successful.
5.3.1
Simple Priority inheritance
Simple priority inheritance suffers from two problems
• Lack of enforcement on the duration of priority inversion.
• Depletion of a lower priority task’s reservation while in a critical section.
From the temporal isolation point of view, the first problem is critical, because it can affect tasks that do not share any resource. The temporal isolation property offered by reservation based systems can become rather weak, if not completely broken.
5.3.2
Priority Ceiling Protocol with Reservation
To satisfy simple priority inheritance, common shared-server process can be given a reservation with a priority assignment equal to what would be the priority ceiling of the same server in a fixed-priority system. Since the server executes at ceiling priority, there can be at most one outstanding client request at any given time. As a result, the priority inversion encountered by any client task is bounded by the duration of one critical section. Size of the reservation that is assigned to the shared resource server is critical issue. There are two approaches. Let there are m periodic tasks τ1τ2...τn Each task o/i has a
period of Ti,1≤i≤m, and issues requests for a common server forCri.
• Single ReserveThe server itself is assigned a period of Ts=min(Ti) and a computation time of
Cs=C1r+C2r+....Cmr.
Example: Consider 3 tasks with (Ci
r,T) pair of (1, 10), (2, 20) and (3, 40) respectively.
The source of the pessimism of the above scheme is that we are constrained to the use of a single reservation, and the priority of the reservation must be the priority ceiling of the server, forcing the reservation period to be disproportionately small, relative to client task periods.
• Multi -reserve PCP: To overcome the above shortcomings, we can associate multiple reservations to the server process, with one reservation per client task. Each of these reservations is parameter-ized by a computation time ofCi
r, a period ofTiand the shortest deadline of tasks which share the
same resource. The deadline parameter ensures that the server is still assigned a priority equal to the priority ceiling of the server.
5.3.3
Reserve Inheritance(RI)
Basic RI is similar to priority inheritance in which each task can be attached to more than one cpu reserve. The task is scheduled according to the highest-priority reserve that it is attached to and that is eligible to execute. When a task blocks waiting for a shared resource, its reserve is inherited by the task owning the shared resource. The blocking task then uses the highest priority undepleted reserve for its execution and When a task releases a shared resource, any inherited reserve inherited through this shared resource is returned to the original task.
5.3.4
Priority Inheritance with Priority Inversion Enforcement (PIPIE)
Basic reserve inheritance introduces a schedulability penalty because the blocking time is added to computation time and is reserved. This schedulability penalty is the price that we pay to address the two problems, lack of enforcement and reservation depletion within a critical section. To overcome with this problem, blocking time accounting is used. which ensures that neither the high-priority task τi nor the low-priority task τj can use this additional reserved time if no priority inversion
occurs. The aim is to perform priority inversion enforcement.
Blocking time can directly be accounted the priority inversion time experienced by each periodic instance of a taskτi and enforce it to be less than or equal toBi. When taskτj inheritsτi priority,
τj’s execution time is charged to RSVj and to all the priority inversions encountered by reserves
Rj+1...Ri of the tasks that are directly or indirectly blocked by τj. When any one of these
blocking terms is exhausted, τj is forced to return to its own priority . Moreover,τj will also be
![Figure 3.1: Open System Architecture with EDF OS Scheduler [7]](https://thumb-us.123doks.com/thumbv2/123dok_us/8546263.2304663/12.918.151.847.278.839/figure-open-architecture-edf-os-scheduler.webp)