© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 461
Survey on Software Data Reduction Techniques accomplishing Bug
Triage
Renu Jaiswal
1, Prof. Mahendra Sahare
2, Dr. Umesh lilhore
31
M.Tech. Scholar
Department of computer science and engineering NIIST Bhopal
2Prof.
Department of computer science and engineering NIIST Bhopal
3
Dr.
Department of computer science and engineering NIIST Bhopal
---***---Abstract -
With the tremendous increase in softwaredevelopment, Bug triage has become a essential and helpful step in the stage of bug handling. Bug triage is a strategy to manage the unfixed bug which will get relegated to a right designer for additionally settling a bug. In this paper a detailed discussion was done for the identification of bugs into their respective class. For the identification SVM, ANN, Decision tree, etc are explained. Here features related to bug are described such as terms, pattern, etc. Various approaches of classification was also list in the paper as well.
Key Words:
Bug Reports, Data Reduction, Bug Triage,Software Maintenance.
1.INTRODUCTION
A huge amount is required in handling the software bugs in a software company. Bug triage presents a process of evaluating defect reports to determine their impact of action. In the context of software testing, it is used to define the severity and priority for new defects and mostly suitable for large project where large number of major defects comes into picture.
Software repositories maintains the output of development process of any software like bug reports, source code, mails etc. A bug repositories will have an open bug report for which, a developer and a user publish or deal with the issues, present in the software, fix the issue with some enhancement and mark the current bug report. Challenge of bug
Triage is to manage the extensive scale bug information and low quality information. Manual bug triage isn't easy because of time utilization and less accuracy outcomes. A programmed bug triage is an option and better approach which deals with the cost and precision gets expanded. Programming examination is mind boggling for huge scale information and complex information exhibit in the storehouses. To diminish the time cost in manual undertaking, content order systems are connected for programmed bug triage.
Here, information decrease for bug triage is manage with to such an extent that the quality upgrades the bug triage work while cost is diminished. Assessment is done on the size of
the informational index and precision of bug triage process. Qualities from chronicled bug informational indexes are removed and helps in building a prescient model for another bug informational index. Bug reports from two expansive open source ventures, Eclipse and Mozilla are gathered and examined for the execution of information diminishment. This thought comes about the information decrease to proficiently limit the information scale and overhaul the precision of bug triage.
Here, objective is, to diminish the bug measurement and word measurement which will thusly lessen the size of the information alongside increment in the nature of the information. To encourage the bug triage process, thought is to raise the informational collection to set up a preprocessing model, to be connected before the real bug triage process which tends to improve the aftereffects of information diminishment. Assist it can be utilized as an overview the choices of creating the great quality bug informational collection and handle certain area determined programming work.
2. Literature Survey
In the paper [2] the author recommended that the web content accidents and misshapen progressively produced website pages are normal blunders, and they genuinely affect the convenience of Web applications. It gives a dynamic test age procedure for the area of dynamic Web applications. The system uses both joined concrete and emblematic execution and express state demonstrate checking. The procedure creates tests consequently, runs the tests catching intelligent limitations on inputs, and limits the conditions on the contributions to coming up short tests so the subsequent bug reports are little and valuable in finding and settling the basic deficiencies.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 462 revelation from content which isn't conceivable with the
utilization of an unadulterated vector-space portrayal, since it loses considerably less data about the requesting of the fundamental words.
In the paper [5] the author recommended that hunting an association's report archives down specialists gives a inexpensive answer for the undertaking of master finding. Author show two general procedures to master seeking given a report accumulation. The first of these specifically models a specialist's information in light of the records that they are related with, while the second finds archives on subject, and after that finds the related master. Shaping solid associations is critical to the execution of master discovering frameworks.
In the paper [6] the author recommended that the unsupervised methods like grouping might be utilized for blame expectation in programming modules, where fault are not accessible. In this paper a Quad Tree-based K-Means calculation has been connected for foreseeing shortcomings in program modules.
In the paper [7] the author suggested that the essential closest neighbor classifier experiences the unpredictable stockpiling of all displayed preparing cases. With an extensive database of cases characterization reaction time can be moderate. At the point when boisterous occurrences are available, grouping exactness can endure. By erasing occasions, the two issues can be reduced. Taking this into issue calculation is produced that adversaries the best existing calculation.
In the paper [9] the author recommended that with the appearance of high dimensionality, sufficient ID of applicable highlights of the information has turned out to be troublesome in certifiable situations. With such a tremendous assemblage of calculations accessible, picking the sufficient element choice technique isn't a simple to-comprehend question and it is important to check their adequacy on various circumstances. In this paper, a few engineered datasets are utilized for this reason, going for surveying the execution of highlight determination strategies within the sight of a bow number or unimportant highlights, commotion in the information, repetition and communication between properties, and in addition a little proportion between number of tests and number of highlights.
In the paper [12] the authors suggest that in information mining applications, information occasions are normally portrayed by an immense number of highlights. The greater part of these highlights are unimportant or repetitive, which adversely influences the proficiency and adequacy of various learning calculations. The choice of significant highlights is a urgent errand which can be utilized to permit a superior comprehension of information or enhance the execution of
other learning undertakings. The paper initially characterizes a successful model for unsupervised component choice which measures the remaking blunder of the information network in light of the chose subset of highlights. The paper at that point shows a novel calculation for voraciously limiting the recreation mistake in view of the highlights chose up until this point.
3. Features of Text Mining
Content mining strategies depends on how message report are dissected. In these strategies for content mining content archive dissected on the premise of term, expression, idea and example. In light of the data recovery there are four strategies, 1) Term Based Method (TBM). 2) Phrase Based Method (PBM). 3) Concept Based Method (CBM). 4) Pattern Taxonomy Method (PTM).
A. Term Based Method: Term in archive is utilized to decide substance of content. In Term Based Method each term in archive is related with esteem known as weight, which measure significance of term i.e. terms commitment in archive. Word having semantic importance is known as term and accumulation of such terms contributes significance to report. Term based strategies experience the ill effects of the issues of polysemy and synonymy. Polysemy implies a word has numerous implications and synonymy is different words having a similar importance. The semantic importance of many found terms is dubious for noting what clients need. Data recovery gave many term-based strategies like directed and conventional term weighting techniques to fathom this test.
B. Expression Based Method: Phrases are not so much equivocal but rather more discriminative than singular term so in state construct strategy report is dissected with respect to express premise. In procedure of investigation of record phrases are profile descriptor of archive. Expressions are accumulation of semantic terms so conveys more data than single term. Over numerous years this is speculation that expression based approach performs superior to anything term based approach, as expression may convey more semantic than term. Utilizing information mining calculations it is unequivocal to acquire different expressions yet it is hard to utilize these expressions viably to answer what client need. It is troublesome on the grounds that expressions have less events in record and expressions include vast number of loud with excess terms. As expressions are gathering of terms those can be considered as succession of terms and consequently to discover arrangement of terms consecutive example mining calculation is utilized. Calculation separates visit consecutive examples, here example utilized as words or expression which is extricated from record.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 463 content. It is imperative to discover term that contributes
more semantic significance to record this idea is known as idea based strategy. Just the significance of term inside archive is caught in factual examination of term based strategy. In idea based strategy the term which adds to sentence semantic is investigated as for its significance at sentence and record levels. The model tries to examine term at sentence and report level by effectively finding critical coordinating term instead of single term examination.
D. Example Based Model: In design construct show report is examined in light of example premise i.e. example of report is shaped by dissecting is-a connection between terms to frame scientific classification. Scientific classification is tree like structure The example based approach can enhance the exactness of framework for assessing term weights on the grounds that found examples are more particular than entire archives. To create PTM record split into passages. In design scientific categorization the hubs speak to visit designs and their covering sets. The edges are "is-a" connection. Smaller example in scientific categorization are normally more broad since they could be utilized as a part of both positive and negative archives. Bigger examples in scientific categorization are typically more particular since they might be utilized as a part of positive reports. The semantic data will be utilized as a part of the example scientific classification to enhance the execution of utilizing shut examples in content mining.
4. Background
A. Information Reduction: Data decrease is a procedure of changing numerical or in order computerized data into a lessened information keeping up the trustworthiness of the first information. Mining on a less volume information should deliver practically a similar outcome yet being more proficient.
B. Advantage Of Data Reduction: Applying information diminishment with the plan to decrease the information scale and enhance the exactness of bug triage. Diminished information scale will in the end spare the work cost of designer in settling the bug. Exactness of bug triage is inspected by expelling boisterous, copy and insignificant reports from the informational index. Unique informational index gets supplanted with the diminished informational index for bug triage.
C. Bug Or Defect Lifecycle In Software Testing: Bugs may show up at any stage like planning stage, improvement arrange, testing stage and so on in a framework advancement lifecycle (SDLC).When the bug is seen, its status given is "NEW". After the advancement group approves and acknowledges, it is "Appointed" to the designer. At the point when the bug is "Settled", it is checked for the acknowledgment by the testing group. Contingent on the impacts its status will be either "Confirmed" or
"Revived". Some extra audit should be possible to make the status of the bug as "Shut". Testing group may revive the bug if any lethal impact is watched once more. Members in the process may incorporate bug journalist, bug following device, bug gathering and bug proprietor.
5. Techniques of Classification
A. Decision tree
Decision tree grouping is the taking in of decision trees from class named preparing tuples [2]. A decision tree is a flowchart like tree structures, where each inside node indicates a test on a characteristic, each branch speaks to a result of the test, and each leaf node holds a class mark.[2]. Points of interest: Amongst other information mining strategies, decision trees have different focal points [1]. Decision trees are easy to comprehend and decipher. They require little information and can deal with both numerical and clear cut information. It is conceivable to approve a model utilizing factual tests. They are strong in nature, in this way, they perform well regardless of the possibility that its suppositions are to some degree disregarded by the genuine model from which the information were produced. Decision trees perform well with extensive information in a brief span. A lot of information can be broke down utilizing computers in a period sufficiently short to empower partners to take decisions in view of its investigation.
B. Limitations:
The issue of taking in an ideal decision tree is known to be NP-finished. Thus, functional decision tree learning calculations depend on heuristic calculations, for example, the covetous calculation where locally ideal decisions are made at every node. Such calculations can't ensure to restore the all around ideal decision tree. Decision tree students make over-complex trees that don't sum up the information well. This is brought over fitting. Components, for example, pruning are important to keep away from this issue.
C. Nearest neighbor classifier
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 464 example, the cover metric (or Hamming separation) can be
utilized.
D. Artificial neural network
Neural Networks are expository methods demonstrated after the procedures of learning in the psychological framework and the neurological elements of the cerebrum and equipped for anticipating new perceptions (on particular factors) from different perceptions (on the same or different factors) in the wake of executing a procedure of socalled gaining from existing information. Neural Networks is one of the Data Mining methods. The initial step is to plan a particular system design (that incorporates a particular number of "layers" each comprising of a specific number of "neurons"). System is then subjected to the way toward "preparing." In that stage, neurons apply an iterative procedure to the quantity of contributions to modify the weights of the system keeping in mind the end goal to ideally foresee the specimen information on which the "preparation" is performed. After the period of gaining from a current informational index, the new system is prepared and it would then be able to be utilized to produce forecasts. The subsequent "system" created during the time spent "learning" speaks to an example recognized in the information.
E. D. Support vector machines
Support Vector Machines were first acquainted with solve the pattern and regression issues by Vapnik and his partners [8]. Support vector machines (SVMs) are an arrangement of related regulated learning techniques utilized for grouping and relapse [2]. Survey input information as two arrangements of vectors in a ndimensional space, a SVM will build an isolating hyper-plane in that space, one which expands the edge between the two informational collections [2]. To figure the edge, two parallel hyper-planes are developed, one on each side of the isolating hyper-plane, which are "pushed up against" the two informational collections [2]. A decent partition is accomplished by the hyper-plane that has the biggest separation to the neighboring information purposes of the two classes, since by and large the bigger the edge the lower the speculation mistake of the classifier [2]. This hyperplane is found by utilizing the help vectors and edges.
6. PROBLEM FORMULATION
In base paper binary classifier was used for bug triage. As in case of multiclass bugs this approach is not feasible.
Training of the classifier is required, so adoption of new bug need prior or human involvement.
Execution time for the comparison of words are quite large as this required each characters.
Accuracy of classifier need to be improved.
7. PROPOSED WORK
Multiclass classifier should be used.
Unsupervised model for the classification should be need.
Comparison should be done in numeric for reducing the execution time.
Genetic algorithm such as TLBO (Teacher learning based optimization)
8. CONCLUSIONS
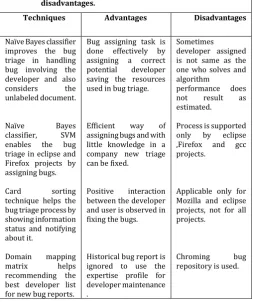
Software development venture generally gets influenced while managing the bugs. Along these lines, the point is to lessen the scale and enhancing the nature of bug information for bug triage process. Above perceptions reason that the information decrease for bug triage in vast bug archives when examined, this approach gives a decent method on information preprocessing to come about a diminished and superb bug information. Since, bug triage is a costly undertaking of programming upkeep and advancement in both, time and work cost, our work lessens the size of bug informational index and enhance the bug information quality. In this paper, a point by point discourse of the different highlights and characterization strategies are Table 1 Comparison of Various techniques advantages and
disadvantages.
Techniques Advantages Disadvantages
Naïve Bayes classifier improves the bug triage in handling bug involving the developer and also considers the unlabeled document.
Naïve Bayes
classifier, SVM enables the bug triage in eclipse and Firefox projects by assigning bugs.
Card sorting technique helps the bug triage process by showing information status and notifying about it.
Domain mapping matrix helps recommending the best developer list for new bug reports.
Bug assigning task is done effectively by assigning a correct potential developer saving the resources used in bug triage.
Efficient way of assigning bugs and with little knowledge in a company new triage can be fixed.
Positive interaction between the developer and user is observed in fixing the bugs.
Historical bug report is ignored to use the expertise profile for developer maintenance .
Sometimes developer assigned is not same as the one who solves and algorithm
performance does not result as estimated.
Process is supported only by eclipse ,Firefox and gcc projects.
Applicable only for Mozilla and eclipse projects, not for all projects.
[image:4.595.31.285.149.452.2]© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 465 likewise done. Order methods are utilized to characterize
information into classes with the assistance of the acquired highlights from the datasets. In future an effective algorithm is required for the study and classification of bugs which have effective set of results.
REFERENCES
[1]. Jifeng Xuan, He Jiang, “Towards Effective Bug Triage with Software Data Reduction Techniques,” IEEE Trans. on Knowledge and Data Engineering, vol. 27, no. 1, Jan. 2015.
[2] J. Anvik, L. Hiew, and G. C. Murphy, “Who should fix this bug?” in Proc. 28th Int. Conf. Softw. Eng., May 2006, pp. 361– 370.
[3] S. Artzi, A. Kie_zun, J. Dolby, F. Tip, D. Dig, A. Paradkar, and M. D. Ernst, “Finding bugs in web applications using dynamic test generation and explicit-state model checking,” IEEE Softw., vol. 36,no. 4, pp. 474–494, Jul./Aug. 2010.
[4] J. Anvik and G. C. Murphy, “Reducing the effort of bug report triage: Recommenders for development-oriented decisions,” ACM Trans. Soft. Eng. Methodol., vol. 20, no. 3, Bugs 10, Aug. 2011.
[5] C. C. Aggarwal and P. Zhao, “Towards graphical models for text processing,” Knowl. Inform. Syst., vol. 36, no. 1, pp. 1–21, 2013.
[6] Bugzilla, (2014). [Online]. Avaialble: http://bugzilla.org/
[7] K. Balog, L. Azzopardi, and M. de Rijke, “Formal models for expert finding in enterprise corpora,” in Proc. 29th Annu. Int. ACM SIGIR Conf. Res. Develop. Inform. Retrieval, Aug. 2006, pp. 43–50.
[8] P. S. Bishnu and V. Bhattacherjee, “Software fault prediction using quad tree-based k-means clustering algorithm,” IEEE Trans. Knowl. Data Eng., vol. 24, no. 6, pp. 1146–1150, Jun. 2012.
[9] H. Brighton and C. Mellish, “Advances in instance selection for instance-based learning algorithms,” Data Mining Knowl. Discovery, vol. 6, no. 2, pp. 153–172, Apr. 2002.
[10] S. Breu, R. Premraj, J. Sillito, and T. Zimmermann, “Information needs in bug reports: Improving cooperation between developers and users,” in Proc. ACM Conf. Comput. Supported Cooperative Work, Feb. 2010, pp. 301–310.
[11] V. Bol_on-Canedo, N. S_anchez-Maro~no, and A. Alonso-Betanzos, “A Bug of feature selection methods on synthetic data,” Knowl.Inform. Syst., vol. 34, no. 3, pp. 483–519, 2013.
[12] D. _Cubrani_c and G. C. Murphy, “Automatic bug triage using text categorization,” in Proc. 16th Int. Conf. Softw. Eng. Knowl. Eng., Jun. 2004, pp. 92–97.
[13] Eclipse. (2014). [Online]. Available: http://eclipse.org/