2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
A Method to Analyze
and Optimize Parallel Programs on
CPU/MIC Heterogeneous Architecture
Yun-chun LI and Tian-yuan WANG
a,*School of Computer Science and Engineering, Beihang University, Beijing, China
*Corresponding author
Keywords: CPU/MIC architecture, Performance analysis, Program optimization
Abstract. Cooperating with the Intel® Many Integrated Core Architecture which was announced in 2010 as a massively parallel coprocessor, heterogeneous node has been broadly applied in petascale supercomputers, such as TianHe-II. The performance analysis for massive parallel applications under the heterogeneous architecture is playing an important role for next generation exascale supercomputers. In this paper, we proposed a method to analyze and optimize parallel programs running on CPU/MIC heterogeneous computing node with offload programming mode. To monitor runtime behaviors in offload process, we used TAU to instrument the offload code region to collect performance events. Then we compared the performance of different programming modes with NAS Parallel Benchmarks. The results indicated that asynchronous offload mode performs better than synchronous offload mode.
Introduction
Along with the development of the high-performance computing, we have already stepped into the petascale era. Heterogeneous systems with CPUs and accelerators such as GPUs, FPGAs and Intel MIC have been broadly deployed in advanced supercomputers. According to the TOP500 list published in November 2016[1], especially top 10 supercomputers, most of them adopt these heterogeneous systems. The next generation supercomputers ——exascale computers are predicted to emerge by the end of this decade with millions of nodes and billions of concurrent cores/threads.
The Intel® Many Integrated Core Architecture [2] (Intel® MIC Architecture) which was announced in 2010 as a massively parallel coprocessor, has been broadly applied in petascale supercomputers, such as Tianhe-2. Based on Intel® MIC Architecture, Intel Xeon Phi was launched as the new coprocessor. Intel Xeon Phi coprocessor communicates with CPU via PCI-E. Intel Xeon Phi coprocessor has 60 cores, each core can support 4 hardware threads. The programming model between the Intel Xeon processor and the Intel Xeon Phi coprocessor is called "Neo-heterogeneous computing", that is, in a single computing node, adopting a uniform x86 programming model and standard program languages to realize collaborative parallel computing between host and coprocessor. The programming mode of MIC is very flexible, which benefit programmers to optimize the performance of parallel programs easily [3].
In this paper, we propose a method to analyze and optimize parallel programs running on CPU/MIC heterogeneous computing node with offload programming model. Then we use the NAS Parallel Benchmarks to conduct experiments and verify the effectiveness of this method.
The remainder of this paper is structured as follows: Section Motivation presents the MIC programming mode and introduces an inefficient behavior. Section Methodology describes the method for discovering this inefficient behavior and improving the performance of parallel program. In section Evaluation, we provide the experimental setup and performance comparison. Related work and conclusion are given in the last two sections.
Motivation
Since MIC adopts uniform x 86 instruction architecture and uOS operating system based Linux, the programming mode of MIC is very flexible. It can be used as a coprocessor, cooperated with CPU to execute compute task, or an independent compute node, the same as a CPU. As a result, there are several programming modes between CPU and MIC.
1) Native. The native model regards MIC as an independent compute node. It can
run applications on either CPU or MIC. This feature benefits from the uniform x86 instruction architecture and uOS operating system based Linux that MIC used, but this mode does not make full use of the computing power both in CPU and MIC.
2) Offload. This mode includes CPU hosted, MIC co-processed mode and MIC
hosted, CPU co-processed mode. As MIC owns higher concurrency than CPU, it is efficient to transplant higher concurrency codes, such as loop operation, to MIC to accelerate computation. The CPU hosted, MIC co-processed mode is the most common-used scenarios in this heterogeneous computing node. In this mode, CPU invokes MIC with offload statement, then move data to MIC to execute. When MIC accomplishes its task, the result returns to CPU, CPU receives the result and continues to execute its main task. Fig. 1 shows the timeline for CPU-MIC offload execution scenarios.
Figure 1. Timeline for CPU-MIC synchronous offload execution scenarios.
At the same time, the potential problem in this offload mode is that when CPU/MIC heterogeneous node enters into offload region, CPU exists a period of idle time before MIC returns the result. This kind of offload mode is called synchronous offload. As synchronous offload mode does not make full use of computation power of CPU, it leads to an inefficient behavior. Ideally, to accomplish the offload task, CPU and MIC can separately execute a sub-task in the mean time. Fig. 2 describes this offload mode. It is unnecessary for CPU to wait for the final result that MIC sends. The offload task is divided into two sub-tasks for CPU and MIC. After CPU moves data to MIC, both CPU and MIC can compute their own sub-task to complete the total offload task. This kind of offload mode can be called asynchronous offload mode. So it is significant to find out this inefficient behavior in CPU/MIC offload mode that parallel programs runs.
Methodology
To recognize the inefficient behavior in CPU/MIC offload mode mentioned above, we propose a method based on TAU Performance System [5]. TAU is a set of toolkits that provides scalable profile and trace measurement and analysis for high-performance parallel applications.
A typical offload code region is described in Fig. 3. The offload task is migrated from CPU to MIC via offload pragma.
Figure 3. Typical offload code region.
To monitor the offload code region, we use TAU to instrument the offload code region, as shown in Fig. 4. TAU provide the function to set up user defined event. We defined TAU_EVENT(USER_EVENT_OFFLOAD, offload_id) for overall offload region, TAU_EVENT(USER_EVENT_OFFLOAD_MIC, offload_id) for MIC and TAU_EVENT(USER_EVENT_OFFLOAD_CPU, offload_id) for CPU to gather their runtime event informations.
Figure 4. Instrumented offload code region with TAU.
When the application runs into the offload region, these user defined events is triggered to collect runtime performance events. Once the application completes, we can get two event sequences corresponded to CPU and MIC, respectively.
behavior in CPU/MIC offload mode. The severity degree of this inefficient behavior is measured by the difference between the two timestamps. The greater the difference, the more severe of this inefficient behavior.
After recognizing this inefficient behavior, we can divide offload task into two sub-tasks by modifying offload code region and restart the application. So that CPU and MIC can separately execute a sub-task in the mean time to accomplish the whole offload task.
Evaluation
Experiment Setup
Our experimental heterogeneous node consists of two Intel Xeon E5-2609 CPUs and one Intel Xeon Phi. Every Intel Xeon E5-2609 has 4 cores and support 8 logical threads. Intel Xeon Phi coprocessor has 60 cores; each core can support 4 hardware threads, namely support 240 hardware threads at most.
NPB (NAS Parallel Benchmarks) is a set of benchmarks which was developed for the performance evaluation of highly parallel supercomputers. It consists of five parallel kernels and three simulated application benchmarks. In this paper, we chose two different type applications of eight, Embarrassingly Parallel (EP) and Integer Sort (IS) to conduct experiment. These applications are divided into Class A, B, C, D, E and F on the basis of problem scale. To get a reasonable application execution time, all the experiment results below are based on Class C scale.
Embarrassingly Parallel. This benchmark is designed for generating Gaussian random deviates using the Marsaglia polar method. It provides an estimate of the upper achievable limits for floating point performance. EP benchmark is a compute-intensive parallel program. It has a main loop without data dependency between every round of iteration. There is no communication among threads in the computation of this main loop. To take full advantage of high concurrency feature of MIC, MIC is skilled in computing this main loop.
Integer Sort. This benchmark is designed for sorting small integers using the bucket sort. It tests both integer computation speed and communication performance. IS benchmark is a communicate-intensive parallel program. Although there are many communications among threads, the process of bucket sort has no mass communication. Therefore, it is appropriate to transplant the segment of bucket sort to MIC.
The Choice of Thread per Core
Before conducting primary experiments, it is important to determine the maximum number of thread per core separately on CPU and MIC since their architecture differences.
We run original EP and IS with CPU native mode and MIC Native mode respectively. As the increase of threads, the CPU native mode runtime is shown in Table 1, and the MIC native mode runtime is shown in Table 2.
Table 1. CPU native mode runtime. CPU
native runtime (s)
Num of threads
1 2 4 8 16
EP 175.68 81.26 39.87 20.26 21.32
Table 2. MIC native mode runtime. MIC
native runtime (s)
Num of threads
1 2 4 8 16 32 60 120 240
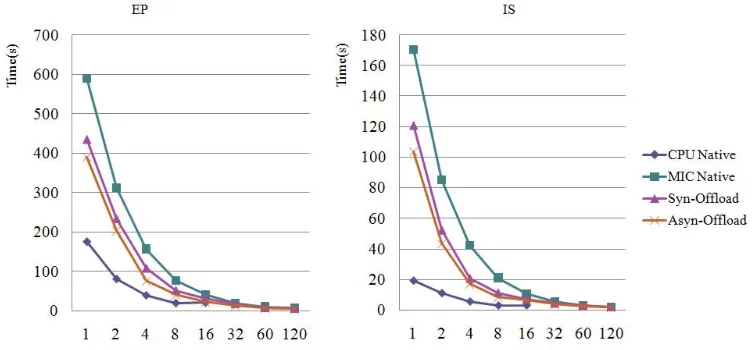
EP 589.67 312.43 157.29 76.8 41.36 20.58 11.19 8.39 8.28 IS 170.63 85.32 42.69 21.37 10.7 5.89 3.06 2.28 2.31 According to the result data, for CPU, when the num of threads increases from 1 to 8 (the number of CPU cores), the runtime decreases linearly. But when the num increases to 16 (double the number of CPU cores, 2 threads per CPU core), the runtime nearly unchanged and increased slightly. That's because an Intel Xeon E5 CPU support 2 logical threads at most through Hyper-Threading technology. The Hyper-Threading technology improves performance through pipeline technique, it is good at multiple application. So, our single application performs best when 1 thread per CPU core. For MIC, one MIC core support 4 hardware threads, 60 cores can support 240 threads at most. But we can find out from Table 2 that there is no distinct difference between 120 threads and 240 threads. That is when one MIC core owns 2 threads, the performance has already reached its peak.
Finally, we choose to run 1 thread per CPU core and 2 threads per MIC core at most for next experiments. This native mode experiment also can be made comparison with the next offload mode experiment.
Experiment Result
After running the original EP and IS application in CPU/MIC native mode, we offload the main loop of EP and the bucket sort of IS to MIC by adding offload pragma. Then run the two modified applications in normal synchronous offload mode. Table 3 presents the result. (to reach the best performance, the number of threads on CPU is fixed with 8, the number of threads on MIC increases from 1 to 120).
Table 3. Synchronous offload mode runtime. Synchronous
offload runtime (s) 1 2 4 Num of threads on MIC 8 16 32 60 120 EP 436.27 234.6 108.94 52.65 32.34 18.76 8.94 6.59 IS 120.89 52.34 20.67 11.35 7.21 4.46 2.81 2.04 Then we use the method of inefficient behavior recognition to guide us to redistribute the offload task on CPU and MIC. We divide the offload task into two unequal sub-tasks according to their own computation power of CPU and MIC, and run the redistributed two applications in asynchronous offload mode, the runtime is given in Table 4.
Table 4. Asynchronous offload mode runtime. Asynchronous
improve more performance than synchronous offload mode, cause asynchronous offload mode can make full use of computation power of CPU and MIC in the meantime. Table 5 lists the speed-up ratio of synchronous offload mode and asynchronous offload mode compared to MIC native mode. According to Table 5, we can find out another conclusion, that is the speed-up ratio of EP benchmark is higher than the ratio of IS benchmark. As EP benchmark is a compute-intensive parallel program, there is no communication among threads in the computation. Unlike communicate-intensive parallel program, such as IS, compute-intensive parallel program can take full advantage of high concurrency feature of MIC.
[image:6.612.132.508.199.374.2]Figure 5. The comparison of different running modes.
Table 5. The speed-up ratio of runtime.
Threads 1 2 4 8 16 32 60 120
EP Syn 26.1% 24.8% 30.7% 31.4% 21.8% 15.3% 20.1% 21.4% Asyn 33.9% 34.9% 31.4% 36.5% 35.9% 35.6% 36.4% 36.0% IS Syn 24.1% 22.3% 18.9% 20.2% 19.3% 14.2% 8.2% 10.5% Asyn 26.3% 25.7% 22.4% 23.8% 24.3% 19.6% 20.5% 18.0%
Related Work
Conclusions
In this paper, we proposed a method to analyze and optimize parallel programs running on CPU/MIC heterogeneous computing node with offload programming model. Then we choose Embarrassingly Parallel (EP) kernel and Integer Sort (IS) kernel from NAS Parallel Benchmarks to conduct experiments. We compare the performance of CPU native mode, MIC native mode, synchronous offload mode and asynchronous offload mode. As the number of threads increases, the runtime of all the four different modes decreases. Besides, offload mode runs a better performance than native mode, which suggests the advantage of CPU/MIC heterogeneous node. Furthermore, asynchronous offload mode can improve more performance than synchronous offload mode, cause asynchronous offload mode can make full use of computation power of CPU and MIC in the meantime. Finally, according to the speed-up ratio, we conclude that compute-intensive parallel program can take full advantage of high concurrency feature of MIC to get a higher improvement than communicate-intensive parallel program.
Acknowledgement
This work was supported by the National Hitech R&D program of China (863 program) (Grant No.2015AA01A301).
References
[1] Information on https://www.top500.org/
[2] Sherlekar, S. Tutorial: Intel many integrated core (MIC) architecture[C]// IEEE, International Conference on Parallel and Distributed Systems. IEEE, 2012:947-947. [3] Jeffers, J., Reinders, J. Intel Xeon Phi coprocessor high-performance programming /[M]// Intel Xeon Phi Coprocessor High Performance Programming. Morgan Kaufmann Publishers Inc. 2013: xvii–xviii.
[4] Bailey, D. The NAS parallel benchmarks[J]. Proc Annu, 2009, 2(4):158 - 165. [5] Shende, S. S., Malony, A. D. The Tau Parallel Performance System[J]. International Journal of High Performance Computing Applications, 2006, 20(2):287-311.
[6] Rosales, C. Porting to the Intel Xeon Phi: Opportunities and Challenges[C]// Extreme Scaling Workshop. IEEE, 2013:1-7.
[7] Ramachandran, A., Vienne, J., Wijngaart, R. V. D., et al. Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi[C]// International Conference on Parallel Processing. IEEE, 2013:736-743.
[8] Hurson, A. R., Lim, J. T., Kavi, K. M., et al. Parallelization of DOALL and DOACROSS Loops—a Survey[J]. Advances in Computers, 1997, 45:53-103.
[9] Rinke, S., Prabhakaran, S., Wolf, F. Efficient Offloading of Parallel Kernels Using MPI_Comm_Spawn[J]. 2013, 46(1):877-884.