2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
Research on Resource Scheduling Optimization
Method of Hadoop Yarn
Peng-fei YANG
1, Xin CHEN
1,a*and Zhuo LI
11 School of Computer Science, Beijing Information Science & Technology University,
Beijing, China
*Corresponding author
Keywords: Hadoop, Yarn, Resource scheduling, Ant colony algorithm, Simulated Annealing algorithm.
Abstract. In order to solve the Hadoop Yarn scheduling problem, improve the
efficiency of cluster job, by considering the advantages of ant colony algorithm and simulated annealing algorithm; we proposed a Hadoop resource scheduling algorithm ACOSA. In ACOSA, we initialize the pheromone matrix of ACOSA by using the attribute information of load, memory, and CPU speed obtained through the heartbeat message transfer mechanism. After getting a group of optimal solution, the path was optimized, and the pheromone of solution was updated by the simulated annealing algorithm. Finally, the simulation experiment on CloudSim platform shows that the efficiency of job execution is improved by adopting ACOSA algorithm for resource scheduling.
Introduction
With the rapid development of the Internet and the rise of the era of big data [1], Hadoop [2] has been widely used in the field of data processing. As the Hadoop cluster size increases, resource scheduling becomes an important factor that affects the performance of cluster. In order to improve the resource utilization, scalability and reliability of Hadoop cluster, Hadoop 2 proposed an independent and universal resource management system (Yarn [3]). This system can separate resource management and task lifecycle management. The Resource Manager (RM) of Yarn is responsible for the entire cluster resource management; while the core of RM is the resource scheduler (RS). Yarn has implemented three scheduling strategies: FIFO, Capacity Scheduler [4] and Fair Scheduler [5]. However, there are many problems while in the specific scheduling process, such as waste of resources and long response time, which cannot meet the needs of the users.
convergence speed of ACA and low precision of SA, and improves the quality of the solution.
Hadoop Scheduling Problem
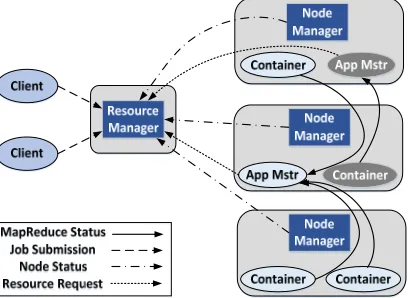
[image:2.612.206.411.203.352.2]Fig. 1 shows the Hadoop (Yarn) architecture. Node Manager (NM) uses the periodic heartbeat to report the node information to the RM and release the resource according to the heartbeat response. Meanwhile, resource scheduler allocates node resource to other applications according to a certain strategy to the application. Application Master (AM) receives allocated resources by sending periodic heartbeat to RM.
Figure 1. Hadoop (Yarn) Architecture.
Resource Manager schedules jobs according to the needs of operating resources. And resource types include: CPU, memory, disk, network, etc. Because of the different types and quantity of the resource requirements for the operation of each job, the required container types are different. Therefore, in order to allocate the jobs reasonably, to ensure the load balancing and the shortest completion time of each node, and it is the problem which needs to be solved in Hadoop cluster.
This paper defines the Hadoop cluster environment as follows:
Definition 1: = { , , ⋯ , } represents a collection of n jobs. =
{ , , }is the job i. is the amount of resources needs,
is the actual amount of resources allocated to , represents the progress of .
Definition 2: = { , , ⋯ , } is a collection of m nodes, =
, , , , , , means the resource of node j:
the number of CPU is denoted by , is the rate of CPU on node j,
is the IO rate of the disk, indicates the bandwidth, is the load, the total amount of resource in node j is denoted by , and the idle resource is denoted
by , ≤ .
Definition 3: = { , , ⋯ , } is a collection of s containers. = , ,
is the container k. , is the job that belongs to, is the applied resources of
.
Definition 4: the goal of task scheduling in Hadoop environment is to achieve the optimal scheduling and progress accelerating of the jobs submitted by users. Therefore, the subject function is defined as Eq. 1.
=
∑ (2)
is the progress weight of job i. The equation of calculation is shown as Eq. 2
Simulated Annealing -Ant Colony Scheduling Algorithm
Ant colony algorithm (ACA) is a heuristic bionic optimization algorithm, which was simulated by Italy scholar M. Dorigo and others in 1990s [16]. Ant colony algorithm is used to simulate the real ant to communicate with the ants and the path by releasing pheromone. The algorithm has the advantages of distributed parallel computer system and strong robustness. It is also easy to combine with other methods.
Algorithm Implementation 1)Initialization Pheromone
In Figure 1, in the Hadoop framework, Resource Manager can obtain the node through the heartbeat mechanism of Node Manager CPU speed, memory capacity, disk IO speed, network bandwidth, load and operation failure records etc. The expression of initial pheromone ℎ , is shown in Eq. 3
ℎ, = ∗ ∗
∑ ∗
+ b ∗
∑ + c ∗∑ + ∗∑ + ∗ , ∗ 1 − (3)
,indicates the failure record of the job i which belongs to container k on
node j. a, b, c, d, e are constants, corresponding to the weight of the node CPU rate, disk
IO, bandwidth, memory and the record of the failure of the operation, and + + + + = 1.
2)State Transition Rule
During the iterative process, the allocation of resources is accomplished by a number of node container operations for several times. The transfer probability of antlselects
container kat time t is show as Eq. 4:
, =
, ( ) [ ( ) ( )]
∑ , ( ) [ ( ) ( )] , ∈
0 , (4)
= { − } indicates the resource nodes ant l can select in the + 1 moment,
is the tabu table which saves the resources the ant l has been searching for and
represent the importance of pheromone concentrations and matching factors, respectively.
3)Update Pheromone
After calculating the load balance and the objective function value and recording the ant colony optimal solution X. It is necessary to use simulated annealing algorithm to optimize path and update pheromone because that the traditional ant colony algorithm (ACO) algorithm for each ant generation sequence traversal without any processing loops until the final convergence or maximum ant algebra, exit and return the results of the algorithm, which reduces the search performance.
which is defined as X’. Then, it needs to calculate the optimal solution and local search
of the value of the objective function, respectively F(X) and F(X’), and accept the new X’ for the current optimal solution with the probability shown as Eq. 5:
( → ) = 1 , ( ) ≤ ( ’)
exp ( ) ( ’) , ( ) > ( ’) (5)
T is the temperature control parameter as Eq. 6: represents the initial temperature,
is an adjustment parameter for adjusting the rate of temperature drop.
( ) = (6)
IfT < , simulate annealing continues iteratively, otherwise it ends. The optimal solution of the simulated annealing algorithm is updated, and the pheromone formula is released as Eq. 7:
ℎ , ( + 1) = (1 − ) ℎ , ( ) + ∆ ℎ( ) (7)
∆ ℎ( ) =∑ (8)
is the pheromone evaporation coefficient. ∆ ℎ( )is the pheromone increment, and it represents the amount of information left by ants in the resource allocation in this iterative search.
Simulation Experiment
In this paper, an extended cloud computing simulation platform(CloudSim) is used to validate the algorithm, and the scheduling strategy proposed in this paper is compared with the scheduling strategy based on the basic ant colony system (ACO) and Capacity algorithm.
Parameter Setting
In the algorithm, , , , and indicates the impact of different resource types on node performance. According to different influence, these weights are set to 0.3, 0.2, 0.2, 0.2, and 0.1. In this paper; we consider the global search ability and convergence speed of two indexes and the pheromone volatilization coefficient as 0.5. The number of ants is 20, pheromone influence factor = 1 and heuristic pheromone influencing factor = 2. The task execution failure factor on the node indicates the failure of the task in the same job, which is limited by the number of tasks and the number of attempts to start, we set = 10.
Experimental Results and Analysis
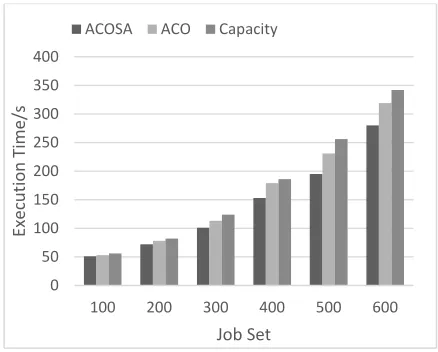
The experimental evaluation is performed with Matrix Multiplication and the Sort Benchmark from Hadoop distribution. Fig.2 and Fig. 3 shows job execution time for different types of job based on simulated annealing ant colony algorithm, ant colony algorithm and Capacity algorithm separately.
Figure 2. Execution time of Sort.
Figure 3. Execution time of MM.
The performance comparison of Sort and MM is shown in Fig. 2 and Fig. 3. Compared with ACO and Capacity algorithm, the execution time of each type of job set with ACOSA is shorter. When the workload is small, the difference between ACOSA and ACO and Capacity is not significant. This is because the small job execution time is short, and in this case, the cluster memory is not completely consumed. However, with the increase in the amount of tasks, the advantage of ACOSA is gradually reflected. At the same time, the load of the cluster is over state, and the competition of the cluster resources is intense, and the reasonable allocation strategy can effectively reduce the execution time of the work.
Therefore, the use of ACOSA algorithm in Hadoop environment for task scheduling is more in line with the needs of large-scale Hadoop cluster. In order to make the optimal ant colony algorithm that solution is a global optimal solution, simulated annealing algorithm is combined with ant colony algorithm later. It effectively enhances the global search ability of the algorithm and avoids the shortcomings of ant colony algorithm.
0 50 100 150 200 250
100 200 300 400 500 600
Executi
o
n
Ti
m
e/s
Job Set
ACOSA ACO Capacity
0 50 100 150 200 250 300 350 400
100 200 300 400 500 600
Exec
utio
n
Ti
m
e/s
Job Set
[image:5.612.202.421.273.449.2]Conclusion
In order to overcome the disadvantage of ant colony algorithm in the large Hadoop cluster environment. Such as the task scheduling is slow and easy to fall into local optimal solution. This paper proposes a resource scheduling strategy based on ant colony simulated annealing algorithm (ACOSA). This algorithm optimizes the scheduling by improving the matching degree between the container and the optimizing the global optimal solution to ensure users to quickly find the appropriate node resources and assign jobs. The experimental results show that the improved algorithm has better performance than the basic ant colony algorithm (ACO) and Capacity algorithm in resource scheduling. In addition, the Hadoop resource scheduling goals also involve other aspects, such as such as reducing carbon dioxide emissions of clusters, which will be the direction of future research.
Acknowledgement
This work was partly supported by the National Natural Science Foundation of China (No. 61370065, 61502040), the National Key Technology Research and Development Program of the Ministry of Science and Technology of China (No. 2015BAK12B03-03) and the Program for Excellent Talents in Beijing Municipality (No. 2014000020124G099).
References
[1] Chen, M., Mao, S., Liu, Y. Big Data: A Survey[J]. Mobile Networks & Applications, 2014, 19(2):171-209.
[2] Apache Hadoop [EB/OL]. (2016-10-08). http://hadoop.apache.org/
[3] Vavilapalli, V. K., Murthy, A. C., Douglas, C., et al. Apache Hadoop YARN: yet another resource negotiator[C]// Symposium on Cloud Computing. 2013:1-16.
[4] Capacity scheduler guide. [EB/OL].(2016-10-09).[2013-06-15].
http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-site/CapacitySchedule r.html
[5] Fair scheduler guide. [EB/OL].(2016-10-09).[2013-06-15].
http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-site/FairScheduler.ht ml
[6] Cheng, D., Rao, J., Jiang, C., et al. Resource and Deadline-Aware Job Scheduling in Dynamic Hadoop Clusters[C]// Parallel and Distributed Processing Symposium. IEEE, 2015:956-965.
[7] Mashayekhy, L., Nejad, M., Grosu, D., et al. Energy-aware Scheduling of MapReduce Jobs for Big Data Applications[J]. IEEE Transactions on Parallel & Distributed Systems, 2015, 26(10):2720-2733.
[8] Zhang, X., Hu, B., Jiang, J. An Optimized Algorithm for Reduce Task Scheduling[J]. Journal of Computers, 2014, 9(4).
[9] Bousselmi, K., Brahmi, Z., Gammoudi, M. M. QoS-Aware Scheduling of Workflows in Cloud Computing Environments[C]// The, IEEE International Conference on Advanced Information NETWORKING and Applications. 2016:737-745
[11] Shen, H., Zhao, H.,, Yang, Z. Adaptive Resource Schedule Method in Cloud Computing System Based on Improved Artificial Fish Swarm[J]. Journal of Computational & Theoretical Nanoscience, 2016, 13(4):2556-2561
[12] Gupta, P., Ghrera, S. P. Trust and deadline aware scheduling algorithm for cloud infrastructure using ant colony optimization[C]//Innovation and Challenges in Cyber Security (ICICCS-INBUSH), 2016 International Conference on. IEEE, 2016: 187-191. [13] Pandit, D., Chattopadhyay, S., Chattopadhyay, M., et al. Resource allocation in cloud using simulated annealing[C]//Applications and Innovations in Mobile Computing (AIMoC), 2014. IEEE, 2014: 21-27.
[14] Xu, X., Hu, N., Ying, W. Q. Cloud task and virtual machine allocation strategy based on simulated annealing-genetic algorithm[C]//Applied Mechanics and Materials. Trans Tech Publications, 2014, 513: 391-394.
[15] Lin, J., Zhong, Y., Lin, X., et al. Hybrid Ant Colony Algorithm Clonal Selection in the Application of the Cloud's Resource Scheduling[J]. arXiv preprint arXiv:1411.2528, 2014.