Management and Research
Available online at: www.ijstmr.com
IJSTMR
©
2017 | All Rights Reserved 6Behavioral Mining of Micro-Blogging Content
Propagation
Neha Vinod Jain
1P.G. Student Computer Engineering S.S.V.P.S. B.S.D. C.O.E
Dhule, India
B. S. Chordia
2Associate Professor Computer Engineering S.S.V.P.S. B.S.D. C.O.E
Dhule, India
Abstract: Conceptual There is numerous essential applications for displaying of powerlessness and virality. To augment organization is reach comparably; popular client may employed by organizations to the promotion with viral substance or to proliferate positive substance about items. To direct crusading or to scatter lawmaker's messages generally they use on viral clients. We were geting a kick out of the chance to fuse even more fine-grained factors influencing the proliferation. At the point when open are confronting the social concentration, for mirroring the assessment of open fine-grained estimation is better. What's more, one may identify occasions by following those said by non-powerless clients and recognize bits of gossip in view of vulnerable client's connections with the substance. We rank clients by their virality (weakness) scores created by a virality demonstrate, select the best scored 1% clients as the anticipated viral (defenseless) clients, and signify the set by UPV (UPS). We adjust the V2s system by including one more feeling based factor of client conduct. This changed V2S joins the every single behavioural factor in one system, which mines the smaller scale blogging content, upgraded way. According to the outcome, investigation and execution result, our framework gives the 90 to 95 % of precise outcomes.
Keywords: Predictive models, Receivers, Tensile Stress, Numerical models, Twitter, Data models, Micro-blogging.
I. INTRODUCTION
Miniaturized scale blogging content are engendered by connect which clients are take after from their followees with the goal that assistance to discover the client behavioral variables. Framework address the main test by deriving client content introduction in view of the sequential request in smaller scale blogging client's course of events and their following system. To address the second test, we devise a multi-step heuristic technique for expelling clamor and distinguishing points of the substance, coupling with the innovative subject model for smaller scale blogging content.
We change a spread tensor speaking to senders content beneficiaries relationship, and propose a factorization system on this tensor to synchronous infer the three subject particular behavioral components.
Topic virality alludes to the inclination of a point in being spread. Since small scale blogging has indicate preferably a data source than an informal communication benefit [9], in this paper we expect that most connections among clients in a miniaturized scale blogging webpage are easygoing and indistinguishable in quality. We along these lines concentrate on demonstrating the client and substance factors that drive content proliferation without considering the combine insightful connections among clients.
The demonstrating of the virality and weakness factors has numerous essential applications. In ad and promoting, organizations may enlist viral clients to engender positive substance about their items or to the notice with viral substance to amplify their range [10]. So also, lawmakers may use on viral clients to scatter their messages generally or to lead battling [11], [12]. What's more, one may distinguish occasions by following those specified by no defenseless clients [13], and recognize gossipy tidbits in view of helpless client's connections with the substance [14], [15].
IJSTMR
©
2017 | All Rights Reserved 7 virality of points of tweets proliferated to her and the virality of clients spreading the tweets. The same can be saying in regards to the estimation of client virality and subject virality.Existing models however measure the three behavioral factors independently. That is they measure a clients virality of substance and weakness of the collectors. Once more, comparative comments are material to existing works that measure client's helplessness and themes virality.
II. LITERATURE SURVEY
Eytan Bakshy! Jake M. Hofman, Winter A. Craftsman, Duncan J. Watts "Everyone's an Influencer: Quantifying Influence on Twitter" WSDM'11, February 912, 2011, In light of the complement put on prominent individuals as perfect vehicles for spreading information [20], the probability that "standard influencers"- individuals who apply typical, or even not as much as would be expected effect are under various conditions more viable, is intriguing.
Sofus Macskassy and Matthew Michelson said that "Why Do People Retweet? Against Homophily Wins the Day!" AAAI Conference 2011, in this paper setting is fundamentally vital when one needs to dive into the details [2]. Not all connections made equivalent, not all individuals are the same, and not all bits of substance are intriguing. On the off chance that one can label individuals, connections and substance with semantically significant classifications, at that point one prescient model to comprehend the elements of these online networking networks[2]. Specifically, we here attempt to comprehend the logical elements, which make a man retweet a specific snippet of data.
Tuan-Anh Hoang, William W. Cohen, Ee-Peng Lim, Doug Pierce, David P. Redlawsk "Legislative issues, Sharing and Emotion in Micro-web journals" 2012[4], In this paper think about the possibly complex communication between sharing, group enrollment, and feeling on the smaller scale blogging stage Twitter[4]. This framework creep a suitable subset of Twitter, and build up a high-accuracy classifier for politically arranged tweets.
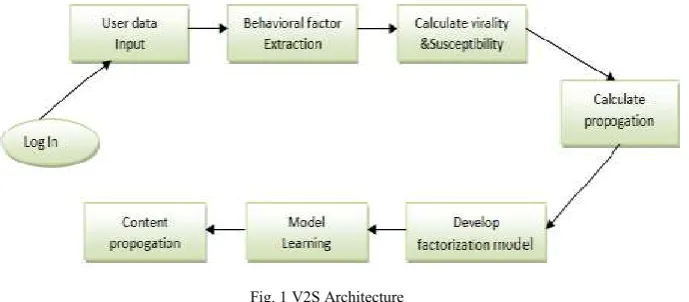
III. MODIFIEDV2SARCHITECTURE
We are changing a tensor factorization framework, calledV2S structure, to show a watched content inducing dataset using three behavioral factors, i.e. point virality, subject specific customer virality, and topic specific customer shortcoming.
Fig. 1 V2S Architecture
System architecture explains the different module and their working. It include the:
Login: It authenticates the users with username and password. It provides the security to the user.
User Data Input: It defines the user’s input. I.e. User’s tweet is micro-blogging content, which mine by using users behavioral. Behavioral Factor Extraction: It defines the how behavioral factors are extracts from the micro-blogging content. Then calculate virality on by applying these factors.
IJSTMR
©
2017 | All Rights Reserved 8 Develop factorization model: Within this framework, we develop two factorization methods: Numerical Factorization Method and Probabilistic Factorization Method to simultaneous measure topics’ virality as well as topic specific users’ virality and susceptibility.A. Factorization models
We portray two factorization models assembled.
1) Numerical factorization demonstrate:
In this model, I consider l (δuvm) as an estimate of δuvm, and f is the personality work. That is, δuvm ≈ Kk = 1[Dm, k.V u, k.Ik.Sv, k] (1)
Given the estimate in Equation 1, the misfortune work Rl, f (u, v, m) is then the squared misfortune, characterized as takes after. Rl, f(u, v
2) Probabilistic factorization demonstrate:
In this model, I consider l(δuvm) as the probability of δuvm, and f is a likelihood dispersion. Since δuvm € {0,1}I pick f to be the Bernoulli appropriation with mean
Kk = 1[Dm, k. Vu, k. Ik, Sv, k] (3) That is,
l (δuvm) = µ(u, v, m)_uvm.(1µ(u, v, m))(1_uvm) (4)
The misfortune work Rl,f (u, v,m) is presently the negative log probability of _uvm, characterized as takes after: Rl,f (u, v, m) = δuvm..ln(µ(u,v,m))- (1δuvm).ln(1µ(u; v;m)) (5)
IV. Performance Evaluation Criteria
Tweet topic discovery:
In this module, it finds the ubiquity of theme by using following formula Generating popularity:
Gk = 1
𝑀∑𝑚∈𝑀𝐷m,k (1)
Where, Gk is the generating popularity, which gives the virality of topic M is set of all content items
Dm,k is the Probability of topic k in content item m’s topic distribution Propagating Popularity:
Pk = 1
∑𝑚∈𝑀𝑝𝑚∑𝑚∈𝑀[𝑝𝑚. 𝐷m,k] (2)
Where Pk is the propagating popularity i.e. it find the user’s retweet count Pm is no of time content i.e. m successfully propagating
To discover the distinction between the prominence of tweet and theme, there is PRCC i.e. Pearson Rank Correlation coefficient.
PRCC = ∑𝐾𝑘=1(𝑟𝐺(𝑘)−𝑟̅).(𝑟𝑝(𝑘)−𝑟̅) √∑𝐾 (𝑟𝐺(𝑘)−𝑟̅)2
𝑘=1 √∑𝐾𝑘=1(𝑟𝑝(𝑘)−𝑟̅)2
(3)
rG (k) is rank of generating popularity of topic k. i.e. it gives the topic popularity rank. rP (k) is rank of propagating popularity of tweet k i.e. it gives the retweet rank. 𝑟̅ Is mean rank of topics K+1/2
Receiver-side popularity:
This module defines the user virality, which is main behavioral factor among behavioral factors. It has two main basic formulas i.e. receiver side exposing popularity and receiver side adopting popularity.
Ev,k = 𝑀1 𝑢
𝑒 ∑𝑚∈𝑀𝑢𝑒𝐷𝑚,𝑘 (4)
𝑀𝑢𝑒 Is set of content that user u exposed. I.e. users exposed their tweets
Av,k = 𝑀1
𝑢𝑎 ∑𝑚∈𝑀𝑢𝐷𝑚,𝑘
𝑎 (5)
IJSTMR
©
2017 | All Rights Reserved 9 Tweet and User popularity:This module defines the combine result of tweet and topic popularity that defines the user’s susceptibility. Sender-specific-generating popularity:
Gu,k = 𝑀𝑢1 ∑𝑚∈𝑀𝐷m,k (6)
Gu,k is the generating popularity Mu is the set of content generated by u Sender-specific-propagating popularity:
Pu,k = 1
∑𝑚∈𝑀𝑝𝑚∑𝑚∈𝑀[𝑝𝑚. 𝐷m,k] (7)
Emotion-based virality:
This model incorporates the mining of substance in light of client's feeling factors. There are four distinct variables, which considered to mining the substance:
1) Joyful 2) Helpless 3) Tenderness 4) Defeated
V. EXPERIMENTAL SETUP
Dataset:
Dataset contains 4, 30,469 kb dataset having 17,600 records. Furthermore, gives the main user id, item id, Scrapping time, and Tweet data. Whereas tweet information again channel by evacuating stop words, slag words and non-English words. Dataset available on
https://github.com/sidooms/MovieTweetings#ratingsdat.
Based on experiment the following parameters are used:
We use FanOut and FanIn as baselines for user virality and susceptibility respectively, and use Tweet popularity, Retweet popularity, and viral coefficient as baselines for topic virality.
We generated synthetic datasets with different number of users N, number of topics K, and score width ' parameter settings, while fixing _ = 2.5, dimin = do min = 3, n tweet min = 10, n tweet min = 100, K dom = 3, K viral = 10% of K, N viral = 2% of N, and N susceptible = 10% of N.
For each dataset instance and each model, we rank topics by their virality scores produced by the model, select the top scored 10% topics as the predicted viral topics, and denote the set by Tp.
The precision 10% of the model for topic virality is then defined by STp \ TgS STgS where Tg is the set of viral topics in the ground truth. For each topic k, and for each user virality model, the model’s precision 2% of topic-specific user virality for topic k is similarly define, and its precision 2% across topics is computed by averaging the precision from all topics. Lastly, for each user susceptibility model, we compute the model’s precision 10% across topics in the similar way.
FanOut & Global popularity & FanIn:
The likelihood lg(u, v,m) that _uvm = 1 is defined as follows.
lg(u, v,m) = X .Kk = 1[Dm, k,fou, k,Gk,f iv, k] (1) FanOut & Propagation popularity & FanIn:
The Likelihood lp(u, v,m) that δuvm = 1 is defined as follows.
lp(u, v, m) = X Kk = 1[Dm, k,fou, kPkfiv, k] (2) FanOut & Viral coefficient & FanIn:
IJSTMR
©
2017 | All Rights Reserved 10 lvc(u, v, m) = X Kk = 1[Dm, k, fou, k, vck, f iv, k] (3)All models demonstrate decreasing precision as K increases. They however still outperform the random selection significantly and the V2S-based models significantly outperform other models.
VI. RESULT AND DISCUSSION
In the accompanying, we audit some current virality models that have been present in past works. A large portion of them covers just a single of the virality/susceptibility factors. The below result is comparison between the V2S framework and improved V2S framework.
Figure 2. Comparison of system based on topic
As per the above figure, explain the modified V2S give results that are more reliable at the topic level as compared to V2S framework. The table contain 3 rows first one contain the no of topics and second column contain previous V2S system reading and third column contains modified V2S framework which required less time as compared to previous V2S framework. In graph Y-axis shows the running time in seconds and X-axis shows no. of topics
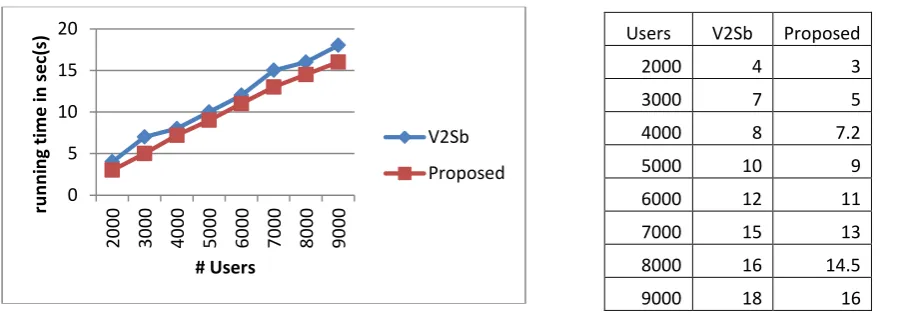
Figure 3. Comparison of system based on user
As per the above figure, explain the modified V2S give results that are more reliable at the user level as compared
to V2S framework. The table contain 3 rows first one contain the no of users and second column contain previous
0 5 10 15 20
20 30 40 50 60 70 80 90 100
ru n n in g tim e in se c(s) # Topics V2Sb Proposed 0 5 10 15 20 20 00 30 00 40 00 50 00 60 00 70 00 80 00 90 00 ru n n in g tim e in se c(s) # Users V2Sb Proposed
Topics V2Sb Proposed
20 14.2 13
30 15 13.8
40 16 14.5
50 16 14.6
60 16 14.6
70 17.5 16.2
80 18 17.1
90 19 17.9
100 19 18.2
Users V2Sb Proposed
2000 4 3
3000 7 5
4000 8 7.2
5000 10 9
6000 12 11
7000 15 13
8000 16 14.5
IJSTMR
©
2017 | All Rights Reserved 11V2S system reading and third column contains modified V2S framework which required less time as compared to
previous V2S framework. In graph Y-axis shows the running time in seconds and X-axis shows no. of users
Figure 4. Comparison of system based on Retweet
As per the above figure, explain the system modified V2S give results that are more reliable at the retweet level as compared to V2S framework. The table contain 3 rows first one contain the no of retweet and second column contain previous V2S system reading and third column contains modified V2S framework which required less time as compared to previous V2S framework. In graph Y-axis, shows the running time in seconds and X-axis shows no. of retweet observation
For each dataset example, we rank clients by their virality (defenselessness) scores delivered by a virality show, select the best scored 1% clients as the anticipated viral (vulnerable) clients, and mean the set by UPV (UPS). The exactness 1% of client virality (defenselessness) is then characterize
|Ups ⌒ Uv|/Uv((|Ups ⌒Us|)/Us)
Uv and Us mean the viral clients and helpless clients in the ground truth separately. The exactness 10% of substance virality correspondingly characterized. Demonstrate the exactness 10% of substance virality and accuracy 1% of client virality and helplessness for the diverse models as we set N = 1000, 10K, 20K and 50K keeping M = 500 and βu = βi = 0.3.
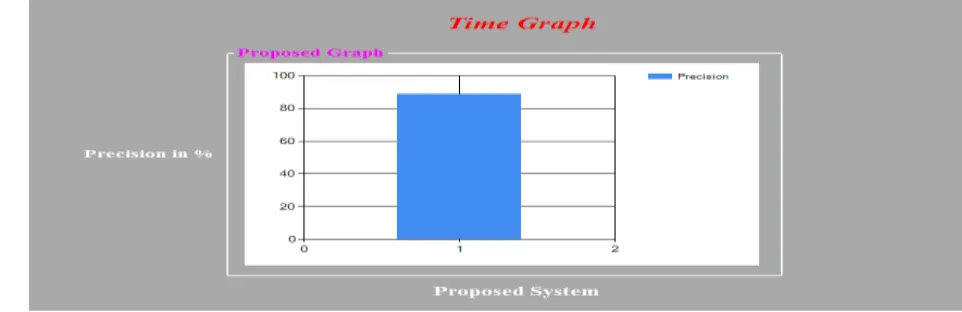
Figure 5. Accuracy checking of the system
System is 90%to 95% gives the accurate result. It is test for many topics. The graph shows for the one topic result which shows that the system gives the accurate rate result. On y-axis values are of precision in % and on x-axis are of no. of topic. It is result of single topic accuracy checking. On this result we can concluded the system gives the correct result as per the requirement.
0 5 10 15 20
1 2 3 4 5 6
ru
n
n
in
g
tim
e
in
se
c(s)
# Retweet Observations
V2Sb
Proposed
Retweet V2Sb Proposed
1 7 5.9
2 10 8.9
3 13 12
4 15 14.6
5 16 14.6
IJSTMR
©
2017 | All Rights Reserved 12 CONCLUSIONIn this paper, we learn about the extraction of client's behavioral variables and adequately mining of the smaller scale blogging content. We change the V2s system by including one more feeling based factor of client conduct. This changed V2S joins the every behavioral factor in one system, which mines the small-scale blogging content, advanced way. According to the outcome, investigation and execution result, our framework gives the 90 to 95 % of exact outcomes. According to contrasting and other framework, our framework gives result on less time and advanced outcome to client. Our future degree is to do mining of smaller scale blogging continuously.
REFERENCE
1. Tuan-Anh Hoang and Ee-Peng Lim “Microblogging Content Propagation Modeling Using Topic- specific Behavioral Factors”, in IEEE 2016
2. S. A.MacskassyandM. Michelson, “Why do people retweet? Antihomophily wins the day!” In ICWSM, 2011
3. Z. Liu, L. Liu, and H. Li, “Determinants of information retweeting in microblogging,” Internet Research, 2012.
4. S. Stieglitz and L. Dang-Xuan, “Political communication and influence through microbloggingan empirical analysis of sentiment in twitter messages and
retweet behavior,” in HICSS, 2012.
5. T.-A. Hoang, W. W. Cohen, E.-P.Lim, D. Pierce, and D.P.Redlawsk, “Politics, sharing and emotion in microblogs,” in ASONAM, 2013.
6. B. Suh, L. Hong, P. Pirolli, and E. H. Chi, “Want to be retweeted? large scale analytics on factors impacting retweet in twitter network,” in Social Com, 2010.
7. J. A. Berger and K. L. Milkman, “What makes online content viral?” Journal of Marketing Research, 2012.
8. E. Bakshy, I. Rosenn, C.Marlow, and L. Adamic, “The role of social networks in information diffusion,” in WWW, 2012.
9. H. Kwak, C. Lee, H. Park, and S. Moon, “What is twitter, a social network or a news media?” in WWW, 2010.
10. B. J. Jansen, M. Zhang, K. Sobel, and A. Chowdury, “Twitter power: Tweets as electronic word of mouth,” JASIST, 2009.
11. Z. Zhou, R. Bandari, J. Kong, H. Qian, and V. Roy chowdhury, “Information resonance on twitter: watching iran,” in SOMA,2010.
12. J. H. Parmelee and S. L. Bichard, Politics and the Twitter revolution: How tweets influence the relationship between political leaders and the public. Lexington
Books, 2011.
13. P.Achananuparp, E.-P.Lim, J. Jiang, and T.-A. Hoang, “Who is retweeting the tweeters? Modeling, originating, and promoting behaviors in the twitter
network,” ACM TMIS, 2012.
14. C. Castillo, M. Mendoza, and B. Poblete, “Information credibility on twitter,” in WWW, 2011.
15. J. Ratkiewicz, M. Conover, M. Meiss, B. Gonalves, A. Flammini, and F. Menczer, “Detecting and tracking political abuse in social media,” in ICWSM, 2011.
16. D. Gruhl, R. Guha, D. Liben-Nowell, and A. Tomkins, “Information diffusion through blog space,” in WWW, 2004.