1883
An Efficient Provenance Extension Relational
Model For Linked Data Storage
M SreeramaMurty, Dr.NNagamalleswaraRao,ABSTRACT: In the period of information impacting, examination into enormous information is expanding significant. We have an assortment new advances for information huge information executives, for example, NoSQL database, (for example MongoDB, Cassandra), analyzer s (for example MapReduce, Hive) and that's just beginning. This apparatus is done doesn't have SQL inquiry connector known to clients. At that point with Postgres 9.1 fashioners have been chosen for outside information wraps to control Postgres with information put away in another informatio n store might possibly be relationship. Utilize outside information bundles that we can connection to outer information stockpiling information for Postgres interface and information investigation who lives in database with SQL questions. Provence is a metadata which catches the connection between input information and yield. That is it exceptionally valuable in investigating troubleshooting. PERM is gadget created as an expansion to Postgres 8.3 to make nearness of Postgres. Inside this Our paper shows the augmentation of PERM gadgets to catch region information got to from outside information stockpiling through the remote information bundle. The PERM device leads PERM class on commitment to affect. We recommend that naming innovation be stretched out to the present gift utilized PERM, to catch 'when' and 'who' in it setting of Big Data Analytics.
Keywords —PERM, PostgreSQL, Foreign Data Wrappers, MongoDB, Provenance, Semantics, Big information, Context, Relationaldatabases, Standard
——————————
——————————
INTRODUCTION
1. Examination of Clustering in Data Mining
Bunching is errand of separating populace or information focuses into various gatherings to such an extent that information focuses in similar gatherings are progressively like other information focuses in similar gathering than those in different gatherings. In straightforward words, point is to isolate bunches with comparable characteristics and dole out them into groups. We should comprehend this with model. Assume, you are leader rental store and wish to comprehend inclinations your costumers to scale up your business. Is it workable for you to take gander at subtleties every costumer and devise novel business procedure for every last one of them? Unquestionably not. Be that as it may, what you can do is to bunch the entirety your costumers into state 10 gatherings dependent on their acquiring propensities utilize different system for costumers in every one of these 10 gatherings. What's more, this is thing that we call grouping.1.1 Types of Clustering
Hard Clustering: In hard bunching, every datum point either has place with group totally or not. For instance, in above model every client is placed into one gathering out of the 10 gatherings.
Soft Clustering: In delicate bunching, rather than putting every datum point into different group, likelihood or probability of that information point to be in those bunches is alloted. For instance, from the above situation every costumer is doled out likelihood to be in both of 10 bunches of the retail location.
1.2 K-means clustering algorithm
The Kmeans calculation is an iterative calculation that endeavors to part the dataset into non-bunches characterized by Kpre where every datum point has a place with just one gathering. It attempts to make information focuses between bunches however much as could be expected while likewise keeping up whatever number various groups as would be prudent. It gives information focuses to the gathering with goal that total of squared separations between the information focuses and the focused bunch (number juggling mean of the considerable number of information focuses contained in gathering) is negligible. The less variety we have in the
bunch, the more homogeneous (comparative) the information focuses are in a similar gathering.
The way the k-implies calculation works is as per the following:
Determine the quantity of gatherings K.
Initialize centroids by parsing first dataset and afterward haphazardly choosing K information point for centroid without substitution.
Make sure it is rehashed so no centroids change. for example the task of information focuses to bunches doesn't change.
Calculate total of squared separations between information focuses and all centroids.
Algorithm
1. Collects information into gatherings of k where k is characterized.
2. Select irregular k as focal point of the group.
3. Assign articles to closest group focus as per the Euclidean separation work.
4. Calculate centroid or mean considerable number of articles in each gathering.
5. Repeat stages 2, 3 and 4 until similar point is given to each gathering in back to back ROUNDS.
2. Relation with Different Databases
1884 additionally left that specific framework. Same applies to
business or association that would require helpful endeavors of various people. For this reason, organizations, enormous little, and associations like emergency clinics, schools, colleges use an exceptionally helpful technique for procuring, amassing, and sharing information in methodical 'Elements' that are put away inside various sorts of databases. By definition, database is "an organized arrangement of information held in PC, particularly one that is available in different manners." It helps in keeping the mountains of information gathered in a methodical way and effectively open to an approved client. Databases are broadly separated into two significant sorts, to be specific, Relational or Sequence Databases and Non-social or Non-grouping databases. These might be utilized by an association separately or consolidated, contingent upon the idea of the information and the usefulness required.
2.1 Relational Databases
This kind of database executives framework DBMS utilizes composition, which is layout used to direct structure of information that will be put away inside the database. Like for an organization offering items to its clients, it is fundamental for them to have some type put away information with respect to where did these items go, to whom, and in what amount. There might be various tables utilized for each approach. For instance, one table can be utilized to show the fundamental data clients, second, utilized for data of the items that are sold and third table can be utilized to identify who acquired this item, how often and where. There are keys related with the tables in social database. They help in giving speedy access to the specific line or section that you should check. The tables, which are likewise called Entities, are all in connection to one another. The table with data about clients may give particular ID to every client that can just signify everything to think about that client like their location, name, and contact data. Additionally, table with item portrayal can dole out specific ID to every item. The table where every one requests are recorded would simply need to record these IDs and their amount. Any adjustment in any of these tables will influence every one of them however in an anticipated and efficient way. Information uprightness is guaranteed by imperatives Relational Database Management Systems (RDBMS). A RDBMS guarantees that the information that shows up is precise and can be depended upon. A few instances of these Structured Query Language (SQL) databases are:
2.1.1 Oracle
Prophet database framework, an Oracle Corporation item, fills in as a multimodal the board framework.
2.1.2 PostgreSQL
Additionally called Postgre, PostgreSQL underlines on standard consistence alongside extensibility and fills in as an article social database the executives framework.
2.1.3 MySQL
This specific open-source RDBMS runs on all the accessible stages, similar to, Windows, Linux, and UNIX.
2.1.4 SQL Server
A result of Microsoft, SQL Server is for the most part used to store and recover information to and from programming application frameworks.
2.1.5 Merits and Demerits of Relational Databases
Social databases have their own benefits and bad marks that merit considering before selecting putting resources into them:
Benefits
• Relational databases pursue are severe blueprint, implying that each new section must have various segments that make it fit in that preformed format. This empowers information to be unsurprising and effectively assessable.
• ACID-consistence is an unquestionable requirement for all RDBMS databases. This implies they should guarantee arrangement of Atomicity, Consistency, Isolation, and Durability.
• They are all around organized and offer next to zero space for any sort of mistake to happen.
Demerits
The fastidious nature, severe patterns, and limitations of social databases make it about difficult to be put away in the numbers that are a prerequisite for the present mammoth web information.
It's difficult to scale on a level plane as social databases pursue a specific diagram. Albeit vertical scaling appears the conspicuous answer, it's most certainly not. Vertical scaling has a breaking point and, in this time, and age, the information gathered by means of the web day by day is just too huge to even think about imagining that vertical scaling would work for long.
Schema limitations additionally hinder the relocation of information to and from various RDBMS. They should be indistinguishable or it won't just work.
2.2 Non-Relational Databases
Non-social databases are more lenient in their structure and structure than social databases. Rather than tables with segments and lines, they have assortments of various classifications like clients and requests, for instance. These assortments are represented by archives. In this way, there can be different reports in a single assortment and they can or can't pursue a specific example or pattern. A record can have a name, address, and item in an
assortment; simultaneously, another report can have only a name and item in a similar assortment as there are no specific construction to these archives. Likewise, various assortments may not really have relations among them.
The various kinds of non-social databases are:
2.2.1 Key-Value Stores
This sort just stores and gives snappy and basic information with respect to key-esteem sets. This is a straightforward and simple approach to store and access the information. A few models are Amazon DynamoDB and Redis.
2.2.2 Wide Column Stores
1885 can go about as a record. This aides in the scaling of
various petabytes of information. Remarkable models are Scylla, HBase, and Cassandra.
2.2.3 Document Stores
Here, the uniform structure isn't a need for records to have. They can have a wide cluster of types and qualities and every one of them can be settled. The information gets put away in JSON archives, and these reports look like those of key-esteem and wide-section. The absolute most popular NoSQL databases fall into this class, to be specific, Couchbase and MongoDB.
2.2.4 Search Engines
They are recognized from record stores such that they help in making the information accessible by basic content based ventures. A few models are Solr, Splunk, and Exasticsearch.
2.2.5 Graph Databases
These show the associations between various information focuses. They are utilized for the most part when there is a prerequisite of investigating various sorts of information and their association with one another. These are spoken to as a system of articles or hubs that are connected. Models are Datastax Enterprise Graph and Neo4J.
2.2.6 Merits and Demerits of Non-Relational Databases
Like everything else, non-social databases are not great and have a few points of interest yet in addition a few restrictions. These include:
Benefits
Their outline free nature makes them simpler to oversee and store immense volumes of information. They can likewise be effectively scaled on a level plane.
Data isn't excessively intricate and can be dispersed among various recognized hubs for better openness. Negative marks
Since they have no particular structure or mapping for the information put away, you can't depend on your information for a specific field since it probably won't have it.
Having no relations makes it difficult to refresh the information as you should refresh each and every detail independently
3. Aspctes of Linking Storages
3.1 Self-describing nature of a database system
A database framework is alluded to as self-depicting since it contains the database itself, yet in addition metadata which characterizes and portrays the information and connections between tables in the database. This data is utilized by the DBMS programming or database clients if necessary. This partition of information and data about the information makes a database framework entirely unexpected from the customary record based framework in which the information definition is a piece of the application programs.
3.2 Insulation among program and information
In the document based framework, structure information records is characterized in application programs so if client needs to change structure document, every one projects that entrance that document may should be changed also. Then again, in database approach, the information structure is put away in framework inventory not in projects. In this way, one change is all that is expected to change structure record. This protection between projects and information is likewise called program-information autonomy.
3.3 Support for various perspectives on information
A database bolsters different perspectives on information. A view is subset of the database, which is characterized and committed for specific clients of the framework. Various clients in framework may have various perspectives on the framework. Each view may contain just the information important to client or gathering of clients.
3.4 Sharing of information and multiuser framework
Current database frameworks are intended for different clients. That is, they enable numerous clients to get to similar database simultaneously. This entrance is accomplished through highlights called simultaneousness control systems. These procedures guarantee that the information got to are constantly right and that information uprightness is kept up. The plan of present day multiuser database frameworks is an extraordinary improvement from those in the past which confined use to each individual in turn.
3.5 Control of information excess
In the database approach, in perfect world, every datum thing is put away in just one spot in database. At times, information repetition still exists to improve framework execution, yet such excess is constrained by application programming and kept to least by presenting as meager redudancy as conceivable when planning the database.
3.6 Data sharing
The combination of the considerable number of information, for an association, inside a database framework has numerous points of interest. To start with, it takes into account information sharing among representatives and other people who approach the framework. Second, it enables clients to produce more data from a given measure of information than would be conceivable without the coordination.
3.7 Enforcement of integrity constraints
1886 3.8 Restriction of unapproved get to
Not all clients database framework will have equivalent getting to benefits. For instance, one client may have perused just access (i.e., capacity to peruse record yet not make changes), while another might have peruse and compose benefits, which is capacity to both peruse and adjust document. Hence, database the board framework ought to give security subsystem to make and control various kinds of client accounts and confine unapproved get to.
3.9 Data autonomy
Another favorable position database executives framework is way it takes into account information autonomy. As it were, framework information depictions or information portraying information (metadata) are isolated from application programs. This is conceivable in light fact that changes to information structure are taken care by database the executives framework and are not installed in the program itself.
3.10 Transaction handling
A database the board framework must incorporate simultaneousness control subsystems. This element guarantees that information stays steady and legitimate during exchange preparing regardless of whether few clients update a similar data.
3.11 Provision for various perspectives on information
By its very nature, DBMS licenses numerous clients to approach its database either independently or all while. It isn't significant for clients to know about how and where the information they get to is put away
3.12 Backup and recuperation offices
Reinforcement and recuperation are techniques that enable you to shield your information from misfortune. The database framework gives different procedure, from that system reinforcement, for support up and recouping information. In the event that hard drive comes up short and the database put away on hard drive isn't available, best way to recuperate database is from a reinforcement. On the off chance that a PC framework bombs in an intricate update process, the recuperation subsystem is liable for ensuring that the database is reestablished to its unique state. These are two additional advantages of a database the board framework
4. Study of Existing Model
This segment examines the provenance the executives frameworks which oversee information provenance.
4.1) Trio: Trio utilizes anxious way to deal with process provenance. Mapping between input tuple identifiers and yield tuple identifiers are put away in different table called genealogy tables. These heredity tables are produced excitedly in every calculation. Trio bolster set questions and total inquiries with certain restrictions. Trio doesn't permit sub questions in FROM condition. We can't utilize collection with set inquiry or join question in this apparatus and just one set oparation is permitted here.
4.2) WHIPS: Whips information distribution center model figures provenance in lethargic methodology. It utilizes 'why provenance' commitment semantics. There are calculations
which recursively follow back set-ASPJ question and register provenance result tuples each in turn. In this model every provenance calculation requires execution few client characterized capacities and it doesn't misuse enhancement strategies fundamental database. The relationship among result and its provenance is confounding as in portrayal utilized in Whips provenance lot tuples and solitary tuple is spoken to similarly.
4.3) DBNotes:DBNotes utilizes anxious way to deal with figure provenance and 'where provenance' commitment semantics is applied here. Provenance is figured by commenting on each trait esteem with special identifier. These comments are put away as plain messages. Calculation provenance in DBNotes causes immense stockpiling overhead since comments must be copied if characteristic is related with more than one explanations.
4.4) PERM:PERM(Provenance Extension Of Relational Model) is provenance board framework which is fit for catching, putting away questioning provenance in social databases is fit for registering provenance for the total arrangement of SQL gauges. PERM is worked as an expansion of PostgreSQL. Since PERM is absolutely social, that is information and yield to PERM module is social, it abuses all improvement capability of PostgreSQL database. PERM utilizes inquiry revamp instrument to change typical question Q into provenance question Q+ that registers provenance Q. PERM utilizes mix of duplicate and provenance impact semantics and utilizations non comment based methodology and figures provenance alongside inquiry and speaks to it feature outcome. All the above existing frameworks manage provenance in single database it were. With the approach of large information advancements, we have necessities of dissecting high volume, differing assortment unstructured information which don't fit into social model databases. There are numerous systematic structures like MapReduce deal with dissecting such information. SQL has been reached out to another standard called SQL/MED (Management of External Data) to take into account this necessity.
5 Implementation and Evaluation
In this work we have actualized PI-CS (Provenance Influence commitment semantics)- commitment semantics embraced from unique PERM execution just as new commitment semantics we proposed "When provenance". So as to include new commitment semantics the accompanying changes should be made to lexer, parser, analyzer and provenance rewriter.
5.1 Lexer and Parser
Another hub type pick provenance is included and PROVENANCE is remembered for rundown of catchphrase tokens. PROVENANCE is included held watchword with goal that it can't be utilized an identifier. New linguistic structure rules are applied for select proclamation to incorporate
catchphrase provenance. SELECT
1887 altered and new fields 'Hub *provenanceClause' and 'Hub
*provInfo' were included.
5.2 Analyzer
Analyzer takes parse tree made in parser arrange and does semantic check expected to get tables and characteristics referenced by inquiry. The information structure that is worked to speak to this data is known as question tree. The capacity transform Select Stmt() is altered to manage provenance and data in provenance Clause field of Select Stmt hub is duplicated into provInfo field of inquiry hub. In unique Perm execution, provenance credits were added to target list in this stage. Be that as it may, as something very similar is done in provenance rewriter, we skirted this excess advance.
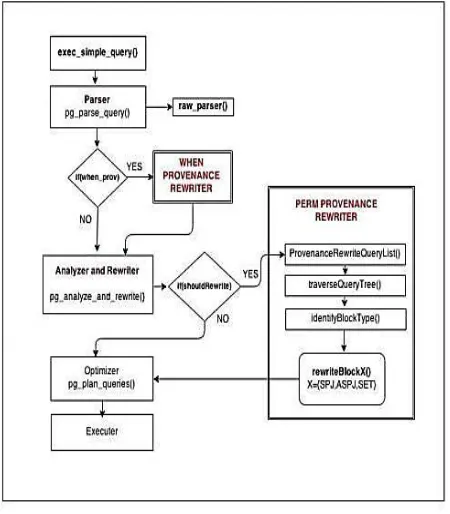
5.3 Provenance Rewriter
Dissected question is passed to Postgres rewriter for definite revising step. Passage work provenance Rewrite Query List() must be called before analyzer and after Postgres rewriter. In event that it's anything but provenance question, this module restores similar inquiry tree back and on off chance that it is provenance inquiry, it is sustained to comparing calculations relying upon sort of question. These calculations were received from the first PERM
Fig1: Implementation of PREM
6.
RESULTS AND DISCUSSION
To test the execution we planned remote information wrapper for Mongo DB and got to Mongo DB assortments through outside information wrappers. We utilized changed PERM ported to postgres 9.3 to show provenance inquiries. We effectively showed outcome tuples alongside their provenance. For instance consider assortments Seller1, Seller2, Counts and Sales in Mongo DB. Assortments 'Seller1' and 'Seller2' catches data about business made by relating merchant. Assortment 'Checks' records stock 'Deals' record data of clearance various things. Remote tables were made for these assortments and different SQL questions
were applied. The accompanying figures shows aftereffect of different provenance questions.
Fig 2: provenance query with external data
7. Analysis
Examination of provenance inquiry execution on Mongo DB assortment is appeared in accompanying charts. For testing, database cases were made with sizes 1MB, 10MB and 100MB. It is obvious from chart that distinction in question execution time for ordinary inquiry and provenance inquiry is immaterial. Be that may, it takes an excessive amount effort for joining outside tables in any event, when info size is 1MB. In any case, this issue is because of structure of remote table and not because expansion of provenance.
Fig 3: Provenance query analysis
8. CONCLUSION & FUTURE SCOPE
1888 occurrence 'when provenance' inquiries . Thus to be valuable
in evident 'huge information' investigation terabytes information, remote table usage Postgres database should be upgraded. Our work gives proof of idea about productive component to catch provenance when large information stores are broke down through SQL interface. For this work to be genuinely helpful in huge information region further work should be done to upgrade productive dealing with huge volume of information in remote tables and improve perception of inquiry results.
REFERENCES (APA Style)
[1] J. Cheney, L. Chiticariu, and W. . . Tan. Provenance in databases: Why, how, and where. Foundations and Trends in Databases, 1(4):379–474, 2007. Cited By :99. [2] Ronan Dunklau. Multicorn: writing forein data wrappers in
python. PGC on 2014, The PostgreSQL Conference,jan2014.http://www.pgcon.org/2014/schedule /events/655.en.html.
[3] B. Glavic and G. Alonso. Perm: Processing provenance and data on the same data model through query rewriting. In Proceedings - International Conference on Data Engineering, pages 174–185, 2009. Cited By :19. [4] B. Glavic and G. Alonso. The perm provenance
management system in action. In SIGMOD-PODS’09 - Proceedings of the International Conference on Management of Data and 28th Symposium on Principles of Database Systems, pages 1055–1057, 2009. Cited By :7.
[5] Boris Glavic. Perm: Efficient Provenance Support for Relational Databases. PhD thesis, University of Zurich, 2010.
[6] The Postgre SQL Global Development Group. Postgresql documentation.jan 2015. http://www.postgresql.org/docs/. [7] Inc. MongoDB. The mongodb 3.0 manual.jan 2011-2015.
http://docs.mongodb.org/manual/.
[8] A Kozea Project. Multicorn :implementor’s guide. feb 2014. http://multicorn.org/.
[9] Florian Schwendener. Sql/med and more, management of external data in postgresql and micro softsql server. dec 2011. http://wiki.hsr.ch/Datenbanken/files/SQLMED and More Schwendener Paper.pdf.
[10]Pat Shaughnessy. Following a select statement through postgres internals. 20,000 Leagues UnderActiveRecord, Barcelona Ruby Conference, oct 2014. http://patshaughnessy.net/2014/10/13/following-a-select-statementthrough-postgres-internals.
About the Authors
M.Sreerama Murthy pursuing Ph.D in Acharya Nagarjuna University,Guntur.M.Tech in Computer Scince and Engineering from University College of Engineering ,JNTU,Kakinada.B.Tech in Information Technology from JNTU,Hyderabad. His research areas includes Data Mining and Big Data