3290
A Non-Linear Chaotic Based PSO Feature
Selection Approach For High Dimensional Data
Classification
Shaik Mahaboob Basha, Dr.D.Nagaraju
Abstract: Recently, advances in bioinformatics leads to microarray high dimensional datasets. These kind of datasets are still challenging for researchers in the area of machine learning since they suffer from small sample size and extremely large number of features. Therefore, feature selection is the problem of interesting the learning process in this area. Due to the large number of features in microarray datasets, feature selection and classification are even more challenging for such datasets. Not all of these numerous features contribute to the classification task, and some even impede performance. Through feature selection, a feature subset that contains only a small quantity of essential features can be generated to increase the classification accuracy and significantly reduce the time consumption. In this paper, chaotic based particle swarm optimization(PSO) technique is proposed for data classification. The proposed CPSO method is effective way to reducing dimensionality, removing irrelevant data, increasing learning accuracy, and improving result comprehensibility. In this paper, a hybrid chaotic feature selection based classification model is proposed for high dimensional datasets. Experimental results proved that the present model is better than the traditional models in terms of true positive rate and accuracy.
Keywords:Particle swarm Optimization, Data classification , Optimization based feature selection.
————————————————————
1.
INTRODUCTION
By using the growth of technology, the vast amount of data is being created and that can be stored on a dataset in global level which is inconceivable and keeps growing. The data has grown exponentially which is produced from the last few years [1]. In real life applications, systems based on human analysis are unpractical. Therefore, the need of reliable and precise information is given in a short period of time has become a mandatory process. The extraction of relevant information from raw big data sets by robust and fast computational techniques automatically [2]. The important task of the data mining is a classification process that has been extensively used by a number of researchers. The classification methods is used for many real time application areas, such as bioinformatics data and text application [3]. Data classification allows partitioning of the large database into smaller databases for improving the data mining. Data mining aims to retrieve, modify, and process a large amount of information available in the database [4, 5]. With the help of data classification method reduce the computational complexity and overhead. In order to achieve this objective different algorithms are continuously developed in the data mining field for classification such as FCM, K-means, and so on [6]. In recent decades, data classification plays the key role in different fields of science and engineering, such as data analysis, pattern recognition, machine learning, image segmentation, error detection and so on. The selection and extraction of set of features for representing the data objects in each application, data classification is used [7]. Nowdays, researchers shows much interest in dealing with the problems of data classification that is inspired by different approaches [8].
The representation of large datasets into a few number of prototypes or classifications that brings simplicity in modeling data which is the main aim of data classification . The classification process plays an important role in the process of knowledge discovery and data mining [9]. In data classification , the main motivation of the optimization approach is minimizing the time of execution and to optimize the best classification for the different sizes of dataset [10]. In this paper, chaotic PSO technique is implemented for data classification .The CPSO framework is an effective tool to remove the irrelevant data and the learning accuracy is increased. The method also improves the result comprehensibility and reduces the dimensionality. The rest of the paper is organized as follows: In Section 2 introduces the literature survey of the optimization based data classification . In Section 3 describes the proposed research work of chaotic particle swarm optimization based data classification . The experimental results will be listed and discussed in Section 4. Finally, conclude the paper in Section 5.
2.
LITERATURE REVIEW
Chaghari, et al. [11] data classification using fuzzy technique and Forest optimization is proposed. For classification one of the local search methods called gradient method are used to perform fuzzy classification . The purpose of applying the gradient method is accelerating the convergence of the used optimization algorithm. The Forest algorithm and combine it with a local search optimization method as gradient method, to improve the FCM algorithm. Optimization algorithm may not reach to the optimal value of fitness function of the FCM algorithm in low number of iterations alone. Therefore, a local search method called gradient method was used to increase the speed of convergence of the optimization algorithm. For the FCM algorithm and its improved versions, it is assumed that all the features of the samples in a given data set make equal contribution when constructing the optimal classifications. Alok, et al. [12] proposed a framework called Multi-Objective Optimization (MOO) which is an
_________________________________
Shaik Mahaboob Basha, Dr.D.Nagaraju Computer Science and Engineering, Research Scholar, Acharya Nagarjuna University, Guntur, India.
3291 approach based on semi-supervised classification . The
multi-objective simulated annealing based technique, AMOSA is optimized the four objective functions by using their search capability. These objective functions may contain some unsupervised and supervised information. The experimental results proves that the MOO techniques can detect the number of classifications as well as the partition of either well-separated classifications of any shape or symmetrical classifications with or without overlaps from the data sets. Wan, M., et al. [13] implemented a mechanism of Bacterial Foraging (BF) analysis which is based on classification algorithm. The group of bacteria forage are considered as a final classification centers by converging the certain positions by minimizing the fitness function which is new optimization methodology for classification problem. The experimental comparisons results proved that the method BF is used to achieve high quality on multi-dimensional real data sets and this appraoch quality is examined on several well-known benchmark data sets. The framework of BF algorithm is also used to detect classifications with different densities and shapes, multi-classifications or isolated points with encouraging results. Wang, et al. [14] proposed a MinimaxFCM by using Minimax Optimization (MO) based on well-known Fuzzy c means (FCM), which is a new multi-view fuzzy classification approach. The consensus classification results are generated in MinimaxFCM which is based on MO. The different weighted views of maximum disagreements are minimized in the process of MO. Automatically, each view's weight can be learned in the process of classification , moreover the only one parameter need to be set besides the fuzzifier. The experiments on MinimaxFCM method is evaluated by using nine real world data sets including image and document datasets. The outcome of the experimental results shows that the proposed method achieves better classification performance than the existing classification approaches. Zhang, Q. H., et al. [15] implemented a Multi-variant Optimization Algorithm (MOA) as a classification method which is based on heuristic optimization algorithm. The MOA framework used to locate the optimal solution automatically through alternating search. The global exploration group and several local exploitation groups presented these global and local alternating search. The method searching the solution space through alternating global-local search iterations and these search individuals are known as an atom. The whole solution space is explored by the global exploration atoms to locate potential areas. The local exploitation is conducted by these potential areas which are allocated with multiple local exploitation group with different population.
3.
PROPOSED RESEARCH WORK
The process of sorting from large data sets for identifying patterns and establishing relationships to solve problems through data analysis is called data mining process. The one of the greatest challenges of the data mining is handling large volumes of data in the information age. The intelligent information systems design is vital due to the need of record, characterize and organize data. Data repositories of highly various natures should be summarized by information systems for providing relevant and timely information to their users.The classification
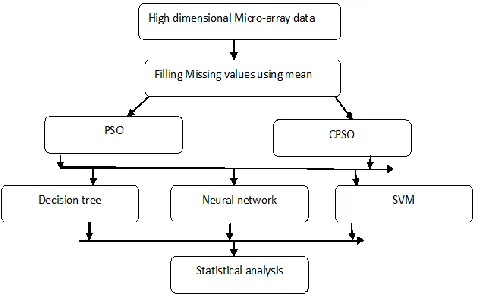
process allows similar objects to be organized into groups. For this reason, in the design of information system classification is a common task. So, in this research work, chaotic PSO algorithm is proposed for data classification. The proposed architecture of PSO is shown in the figure.1. In this section, an input data is taken from microarray database. Different types of cancer datasets are used to evaluate the performance of the proposed model to the traditional feature selection based classification models. In the proposed approach, a non-linear chaotic polynomial map is used to enhance the security parameters in the key generation process. The basic recursion relation for the non-linear equation is given as
n n 2
0
2 1
T
kx T
T
1
T
k(1
)
Where
is the randomized security parameter taken from2
Z(n ,*)
The pseudo code of chaotic PSO is given as
Step 1: Initializing particles with cloud services, number of iterations, velocity, number of particles etc.
Step 2: Compute hybrid velocity and position for each particle in ‘d’ dimensions using the following equations.
chaos1 i chaos2 i
c1 2 2
c1 c2 c1 c2 c1 c2
c1 c2
v(d 1,i) .[ (d,i).v(d,i). (pBest X(d,i)) (gBest X(d,i))] X(d 1,i) X(d,i) v(d 1,i)
is the convergence factor computed as 2*( )
| 2 ( ) ( ) 4( ) | where , rand
om numbers
In this optimized model, inertia weight is computed as
max current max max min
max
min
max
(d,i)
(I
/ I
).(
)
: max inertia
: min inertia
I
: max iteration
Step 3: Computing fitness value using ortho chaotic gauss randomization measure. In this proposed PSO model, a random value between 0 to 1 is selected using the following equation as 2 X 2 X (X ) i X 1 R e 2
K 1, 2...iterations
3292 Figure 1: Proposed feature selection based
classification model
The basic workflow of the proposed framework is represented in figure 1. In this figure, initially data is preprocessed to remove the missing values. The sparsity problem of the data is eliminated by filling the missing values or noisy attributes. Since, the input data contain a large number of features, it is necessary to find the relevant or essential subset of features for data classification and classification problem. In the proposed model, PSO andCPSO feature selection approaches are designed and implemented to improve the classification rate of the proposed model on high dimensional features set. Finally, SVM, neural network and decision tree classifiers are used to test the classification accuracy on the selected features.
4.
EXPERIMENTAL RESULTS
The data feature selection based classification method based on chaotic PSO technique is implemented in java netbeans IDE (8.2). The method conducted all the experiments in Windows 7 on Desktop PC which is having Intel core i5, procressor of 2.4 GHz and real memory as 4 GB. In experimental analysis the input data are taken from https://ico2s.org/datasets/microarray.html. .The proposed CPSO result is compare to the existing methods PSO, PCA, and CPSO. The evaluation metrics are described in below sections.
Accuracy: The intuitive performance measure is accuracy which is calculated as a ratio of correctly predicted observation to the total observations of predicted values. The accuracy is directly proportional to true results, consider both true positives and true negatives among the total number of cases scrutinized. The parameter of accuracy is calculated in equation (6),
Precision:The proportion of the examples that have class x among all those examples which are determined as class x is known as Precision. This is defined in equation (8),
Recall: Sensitivity is the other name of Recall and the ability of a prediction model is measured to select instances
of a certain class which is corresponds to the true positive rate. It is defined in equation (9),
F-Measure:The harmonic mean of precision and recall is measured by using F-Measure which gives the relations between precision and recall. F-Measure is defined by as mentioned in Equation (10),
The process of categorizing an unlabeled dataset into similar objects classifications which is called data classification and may be recognized as one of the most and popular data analysis techniques. The classifications which are having similar objects are formed as one group and those who are having dissmiliar objects are grouped as other classifications. To measure the performance of the proposed CPSO classification method various parameters are employed such as accuracy , runtime with respect to the different dataset which is described as before in database description. The table.1 represents the performance evaluation of the proposed and existing methodology on microarray datasets.
Here, random forest approach is used to generate the decision patterns and its performance measures. These decision patterns are used to predict the new class label of the test instance.
Ensemble Learning Model ==========
Contig33938_RC < -0.18 : non-relapse (9/0) Contig33938_RC >= -0.18
| AL137656 < -0.11 : relapse (8/0) | AL137656 >= -0.11
| | Contig56670_RC < 0.24 | | | NM_005302 < 0.34 | | | | NM_014882 < 0.2 | | | | | NM_014659 < 0.26
| | | | | | Contig56276_RC < -0.43 : relapse (2/0) | | | | | | Contig56276_RC >= -0.43
| | | | | | | NM_013290 < -0.36 : relapse (1/0) | | | | | | | NM_013290 >= -0.36
| | | | | | | | NM_002688 < 0.27
| | | | | | | | | Contig8956_RC < -0.11 : relapse (2/0)
| | | | | | | | | Contig8956_RC >= -0.11 | | | | | | | | | | AL050107 < 0.24
| | | | | | | | | | | AF007131 < -0.15 : relapse (2/0) | | | | | | | | | | | AF007131 >= -0.15
| | | | | | | | | | | | AF201950 < 0.31 | | | | | | | | | | | | | NM_016017 < 0.19
| | | | | | | | | | | | | | NM_001024 < -0.34 : relapse (1/0)
| | | | | | | | | | | | | | NM_001024 >= -0.34 | | | | | | | | | | | | | | | Contig36880 < -0.25 | | | | | | | | | | | | | | | | AB033011 < -0.01 : non-relapse (1/0)
| | | | | | | | | | | | | | | | AB033011 >= -0.01 : relapse (1/0)
3293 | | | | | | | | | | | | | | | | Contig20623_RC <
-0.13
| | | | | | | | | | | | | | | | | NM_001619 < 0.07 : non-relapse (1/0)
| | | | | | | | | | | | | | | | | NM_001619 >= 0.07 : relapse (1/0)
| | | | | | | | | | | | | | | | Contig20623_RC >= -0.13
| | | | | | | | | | | | | | | | | Contig8909_RC < 0.25
| | | | | | | | | | | | | | | | | | NM_009585 < -0.75
| | | | | | | | | | | | | | | | | | | Contig35765 < 0.23 : relapse (1/0)
| | | | | | | | | | | | | | | | | | | Contig35765 >= 0.23 : non-relapse (1/0)
| | | | | | | | | | | | | | | | | | NM_009585 >= -0.75 : non-relapse (39/0)
| | | | | | | | | | | | | | | | | Contig8909_RC >= 0.25 : relapse (1/0)
| | | | | | | | | | | | | NM_016017 >= 0.19 : relapse (2/0)
| | | | | | | | | | | | AF201950 >= 0.31 : relapse (1/0)
| | | | | | | | | | AL050107 >= 0.24 : relapse (3/0) | | | | | | | | NM_002688 >= 0.27 : relapse (2/0) | | | | | NM_014659 >= 0.26 : relapse (4/0) | | | | NM_014882 >= 0.2 : relapse (3/0) | | | NM_005302 >= 0.34 : relapse (3/0) | | Contig56670_RC >= 0.24 : relapse (8/0)
Here, the Breast cancer dataset is used to find the patterns of various selected features. The chaotic particle swarm optimization scheme is used to find the optimal random values to the particle initialization and updating process.
NM_019116 < 0.3
| Contig8956_RC < -0.11 : relapse (5/0) | Contig8956_RC >= -0.11
| | Contig2313_RC < -0.09 : relapse (2/0) | | Contig2313_RC >= -0.09
| | | NM_000104 < 0.17 | | | | Contig28877_RC < 0.16 | | | | | NM_014902 < 0.27
| | | | | | AF159092 < -0.2 : relapse (5/0) | | | | | | AF159092 >= -0.2
| | | | | | | AL133027 < 0.42
| | | | | | | | NM_015916 < -0.1 : relapse (1/0) | | | | | | | | NM_015916 >= -0.1
| | | | | | | | | NM_000928 < -0.14 : relapse (1/0) | | | | | | | | | NM_000928 >= -0.14
| | | | | | | | | | Contig27338_RC < -0.05 | | | | | | | | | | | NM_001684 < 0.09 | | | | | | | | | | | | Contig50877_RC < 0.14 | | | | | | | | | | | | | NM_004830 < -0.2 : non-relapse (2/0)
| | | | | | | | | | | | | NM_004830 >= -0.2 : relapse (8/0)
| | | | | | | | | | | | Contig50877_RC >= 0.14 : non-relapse (3/0)
| | | | | | | | | | | NM_001684 >= 0.09 : non-relapse (11/0)
| | | | | | | | | | Contig27338_RC >= -0.05
| | | | | | | | | | | Contig34107 < -0.08 : relapse (1/0)
| | | | | | | | | | | Contig34107 >= -0.08
| | | | | | | | | | | | NM_003890 < -0.64 : relapse (1/0)
| | | | | | | | | | | | NM_003890 >= -0.64 : non-relapse (35/0)
| | | | | | | AL133027 >= 0.42 : relapse (1/0) | | | | | NM_014902 >= 0.27 : relapse (4/0) | | | | Contig28877_RC >= 0.16 : relapse (2/0) | | | NM_000104 >= 0.17 : relapse (10/0) NM_019116 >= 0.3 : relapse (5/0)
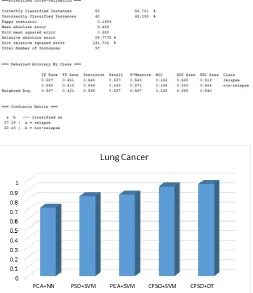
Figure 2: The performance analysis of proposed CPSO based classification approaches to the traditional PSO
3294 Figure 2, describes the comparative analysis of CPSO
based decision tree and SVM to the traditional PSO based SVM and neural network on lung cancer dataset.
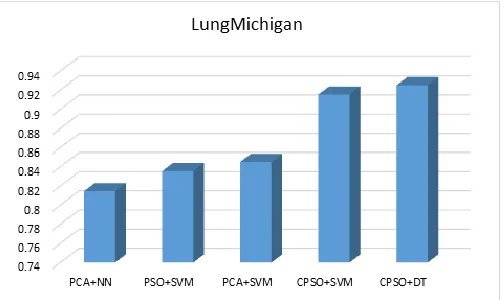
Figure 3: The performance analysis of proposed CPSO based classification approaches to the traditional PSO
based classifiers on lung michigan cancer.
Figure 3, describes the comparative analysis of CPSO based decision tree and SVM to the traditional PSO based SVM and neural network on lung Michigan cancer dataset.
Figure 4: The performance analysis of proposed CPSO based classification approaches to the traditional PSO
based classifiers on ovarian cancer dataset.
Figure 4, describes the comparative analysis of CPSO based decision tree and SVM to the traditional PSO based SVM and neural network on ovarian cancer dataset.
Figure 5: Performance of present approach to traditional approaches by using runtime(ms).
Figure 5, represent the average runtime(ms) of the proposed CPSO based classification model to the traditional feature selection-based classifiers on high dimensional datasets. As shown in the figure, it is clearly observed that the present feature selection based classification model has better runtime(ms) on high dimensional datasets .
5.
CONCLUSION
In this paper, a novel feature selection methodology based on CC concept for handling microarray high dimensional datasets is proposed. The proposed method uses the divide and conquer technique in order to split the search space and evolve each subspace cooperatively. According to the numerical outcomes, the proposed method is powerful enough to tackle feature selection problem. Relying on the obtained results characteristics of the proposed method are: 1) it can apply on extreme large datasets without any preprocessing. 2) It converges to near global optimum since it searches all the search space by cooperative coevolving technique. The experimental results on seven binary microarray high dimensional datasets with nine state-of-the-art algorithms reveal the significance of the proposed method. In this paper, chaotic PSO Optimization technique is proposed for data classification problem. The proposed CPSO method is effective way to reducing dimensionality, removing irrelevant data, increasing learning accuracy, and improving result comprehensibility. In this paper, a hybrid chaotic feature selection based classification model is proposed for high dimensional datasets. Experimental results proved that the present model is better than the traditional models in terms of true positive rate and accuracy.
6 REFERENCE
[1]. Dhote, C. A., Anuradha D. Thakare, and Shruti M. Chaudhari. "Data classification using particle
swarm optimization and bee
algorithm." Computing, Communications and Networking Technologies (ICCCNT), 2013 Fourth International Conference on. IEEE, 2013.
[2]. Pacifico, Luciano DS, and Teresa B. Ludermir. "Data Classification Using Group Search Optimization with Alternative Fitness Functions." Intelligent Systems (BRACIS), 2016 5th Brazilian Conference on. IEEE, 2016.
[3]. Esmin, Ahmed AA, and Stan Matwin. "Data classification using hybrid particle swarm optimization." International Conference on Intelligent Data Engineering and Automated Learning. Springer, Berlin, Heidelberg, 2012. [4]. Youssef, Sherin M. "A new hybrid
evolutionary-based data classification using fuzzy particle swarm optimization." Tools with Artificial Intelligence (ICTAI), 2011 23rd IEEE International Conference on. IEEE, 2011.
3295 ." Information Systems Design and Intelligent
Applications. Springer, New Delhi, 2016. 199-208. [6]. Kharche, Dipali, and Anuradha Thakare. "ACPSO:
Hybridization of ant colony and particle swarm algorithm for optimization in data classification using multiple objective functions." Communication Technologies (GCCT), 2015 Global Conference on. IEEE, 2015.
[7]. Saida, Ishak Boushaki, Kamel Nadjet, and Bendjeghaba Omar. "A new algorithm for data classification based on cuckoo search optimization." Genetic and Evolutionary Computing. Springer, Cham, 2014. 55-64.
[8]. Sumangala, K., and K. Papitha. "Impact of Bio-inspired metaheuristics in the data classification problem." International Journal of Computer Applications Technology and Research3.2: 93-99. [9]. Han, X., Quan, L., Xiong, X., Almeter, M., Xiang, J.
and Lan, Y., 2017. A novel data classification algorithm based on modified gravitational search algorithm. Engineering Applications of Artificial Intelligence, 61, pp.1-7.
[10]. Ilango, S.S., Vimal, S., Kaliappan, M. and Subbulakshmi, P., 2018. Optimization using Artificial Bee Colony based classification approach for big data. Classification Computing, pp.1-9. [11]. Chaghari, Arash, Mohammad-Reza
Feizi-Derakhshi, and Mohammad-Ali Balafar. "Fuzzy classification based on Forest optimization algorithm." Journal of King Saud University-Computer and Information Sciences (2016). [12]. Alok, Abhay Kumar, Sriparna Saha, and Asif Ekbal.
"A new semi-supervised classification technique using multi-objective optimization." Applied Intelligence 43.3 (2015): 633-661.
[13]. Wan, M., Li, L., Xiao, J., Wang, C. and Yang, Y., 2012. Data classification using bacterial foraging optimization. Journal of Intelligent Information Systems, 38(2), pp.321-341.
[14]. Wang, Yangtao, and Lihui Chen. "Multi-view fuzzy classification with minimax optimization for effective classification of data from multiple sources." Expert Systems with Applications 72 (2017): 457-466.
[15]. Zhang, Q. H., Li, B. L., Liu, Y. J., Gao, L., Liu, L. J., & Shi, X. L. (2016). Data classification using multivariant optimization algorithm. International Journal of Machine Learning and Cybernetics, 7(5), 773-782.
[16]. Amiri, Ehsan, and Shadi Mahmoudi. "Efficient protocol for data classification by fuzzy Cuckoo Optimization Algorithm." Applied Soft Computing 41 (2016): 15-21.
[17]. Alam, Shafiq, Gillian Dobbie, and Saeed Ur Rehman. "Analysis of particle swarm optimization based hierarchical data classification approaches." Swarm and Evolutionary Computation 25 (2015): 36-51.
[18]. Masoud, H., Jalili, S. and Hasheminejad, S.M.H., 2013. Dynamic classification using combinatorial
particle swarm optimization. Applied
intelligence, 38(3), pp.289-314.
[19]. Kushwaha, N., Pant, M., Kant, S. and Jain, V.K., 2017. Magnetic optimization algorithm for data classification . Pattern Recognition Letters.