896 | P a g e
EFFICIENT CANCELLATION OF NOISY DATA IN
DATA MINING USING GENETIC ALGORITHM
M. Naveen Kumar
1, U Mahender
2 1,2Assistant Professor, TKRCET, HYD.
ABSTRACT
In today's current day web era people seeking the web and finding pertinent data on the web to be effective and quick. Be that as it may, customary web crawlers like Google assume to be more keen, still utilize the customary slithering calculations to discover information applicable to the inquiry question. In any case, the greater part of the circumstances it returns immaterial information too which gets to be distinctly befuddling for the client. In a typical XML information, the client inputs the hunt inquiry as far as a catchphrase or a question and the response to the pursuit question ought to be more exact and the sky is the limit from there important. In this way, utilizing the customary slithering calculations over XML information would prompt to superfluous outcomes. Hereditary calculations are the present day calculations which recreates the Darwinian hypothesis of the common development. The hereditary calculations are most appropriate for the conventional pursuit issue as the hereditary calculations constantly tend to return quality as answer for any area information. It would be a decent way to deal with research how the hereditary calculations would be reasonable for the pursuit over the XML information of various spaces. Along these lines, this framework actualizes an enduring state competition determination Microbial Genetic Algorithm over the XML information of the diverse spaces. This would be an examination of how the hereditary calculation would return exact outcomes over XML information of diverse areas.
Keywords: Data Mining, knowledge discovery, query processing, Data retrieval, Noise cancellation
in data.
I. INTRODUCTION
The watchword look model is well known today because of accomplishment of web indexes. Watchword
inquiry is proposed as an option implies of questioning the database. Catchphrase hunt is straightforward what's
more, natural to most web clients as it just requires the contribution of a few catchphrases. Watchword seek in
content records take the archives that are more applicable with the information catchphrases as the appropriate
responses. XML is turning into a standard arrangement of information portrayal, so it is alluring to bolster
catchphrase seek in XML database. XML is a client amicable and straightforward. Conventional approach to get
to XML databases is utilization of inquiry dialects. Be that as it may, this approach requires the information of
complex inquiry dialects and the database mapping. There are a few difficulties in Keyword seeking over XML.
To start with, the consequence of the catchphrase look question is not generally a whole archive, however it can
897 | P a g e
profound" hub containing the catchphrases. Second, the inquiry results can have positioned in various courses
for XML and HTML watchword seek. HTML web indexes, for example, Google normally rank archives in light
of their hyperlinked structure. Since XML watchword seek inquiries can return settled components, positioning
must be done at the granularity of XML components, instead of whole XML archives. Customary inquiry
handling approach on XML database is compelled by the question develops forced by the dialect, for example,
XQuery and XPath. Firstly, the inquiry dialect themselves are difficult to appreciate for non-database clients.
For instance, the XQuery is genuinely convoluted to get a handle on. Besides, these inquiry dialects require the
questions to be postured against the hidden structure and complex database constructions. These customary
questioning techniques are capable however disagreeable for everyday clients.
II. SURVEY
Albeit many research endeavors have led in XML watchword look. Fluffy Ahead [1] seek approach over a XML
information begins to figure the further some portion of the question that client may enter. It takes client
question as far as watchword to pursuit and returns the information coordinating the look question around. This
framework moreover executes powerful ordering and top-k calculation to accomplish higher exactness. In any
case, the real disadvantage of this framework would be that it might return extremely poor information as it
hunts the information by coordinating around. XSEarch [2] is a semantic internet searcher for XML. It returns
semantically related report parts that fulfill the user‟s question. Question answers are positioned utilizing
developed data recovery procedures and are produced in a request like the positioning. Propelled ordering
systems were produced to encourage proficient usage of XSEarch [2]. XRANK [3] has a positioning system
which returns report pieces as answers. There is no qualification amongst catchphrases and names also, every
catchphrase of a XRANK inquiry is coordinated against each expression of the record. XRANK positions the
components of a XML record by summing up the Page-Rank calculation. It positions the responses to a inquiry
by consolidating the positioning of components with catchphrase nearness. A response to a XSEarch [2] inquiry
is additionally an answer or some piece of a response to the XRANK question that comprises of the same
watchwords and marks, yet the opposite is most certainly not essentially genuine. Really, XRANK may return
answers with parts that are semantically disconnected. XRANK positions the components of a XML report by
summing up the Page-Rank calculation of Google. It positions the responses to a question by joining the
positioning of components with catchphrase nearness. The idea of nearness in XRANK implies that the
offspring of a component must be "organized appropriately" if that component ought to be positioned
exceedingly as an answer. In XSEarch [2], vicinity is incorporated into the positioning recipe as far as the
measure of the relationship tree what's more, therefore, it is not influenced by the request of youngsters.
XSEarch [2] utilizes more data recovery strategies than XRANK [3], specifically, tf-idf and likeness between
the question and the archive. One broadly received approach so far is to locate the Smallest Lowest Common
Ancestor (SLCA) of all watchwords. Each SLCA [4] aftereffect of a catchphrase question contains all inquiry
watchwords however has no subtree which additionally contains every one of the watchwords. SLCA-based
methodologies just take the tree structure of XML information into thought, without considering the semantics
of the inquiry and XML information. SLCA may present answers that are either unimportant to client seek
898 | P a g e
frameworks of watchword seek over XML databases experience the ill effects of two issues: 1. Meaningfulness
and culmination of answers, 2. The extent of the inquiry. The current methodologies, for example, SLCA [4]
and XRank [3], give back some unessential outcomes and furthermore miss a few comes about because of
answers. Existing framework give back the reply of catchphrase hunt by taking just LCAs as the appropriate
response of catchphrase hunt which will be incorrect. Moreover, XML reports include convoluted structures,
hence it is hard to locate the significant sought information, which still jelly the structure relationship and fits in
with the reports, for clients through constrained info watchwords. Existing reviews predominantly concentrate
on effectiveness of catchphrase inquiry on XML databases and normally prompts to low adequacy, and likewise,
the most effective method to find the structure intimation from the information catchphrases in order to enhance
the adequacy. Another data get to worldview for XML information, called "Inks" [5] was proposed which looks
on the hidden information "on the fly" as the client sorts in question watchwords. Inks broaden existing XML
watchword look techniques by intuitively noting watchword questions. Here compelling files, early-end
systems, and proficient pursuit calculations are proposed to accomplish a high intuitive speed. Profitable Lowest
Common Ancestor (VLCA) [6] was acquainted with precisely and viably answer watchword questions over
XML reports. A new idea of Compact VLCA (CVLCA) [6] is created which figure the significant conservative
associated trees established as CVLCAs as the appropriate responses of catchphrase inquiries. Along these lines,
this framework explores the execution of utilizing a developmental approach of Genetic Calculation on XML
Search for different datasets and its exactness will break down to legitimize whether it is great approach for
XML Search.
III. MICROBIAL ALGORITHM FOR DATA MINING NOISE CANCELLATION
Hereditary Algorithms are capable and broadly pertinent to inquiry and streamlining issues. Hereditary
Algorithms depend on the ideas of regular choice and development. One of the attempted and tried hereditary
calculations on pursuit issues is Microbial Genetic Algorithm [8] which has ideal time multifaceted nature and
in addition information quality. Nonetheless, no look framework utilizing Microbial Genetic Algorithm or
whatever other Genetic Algorithm Search frameworks execute XML Search. Consequently, it was chosen to
research the execution of Microbial Genetic Calculation [8] on XML information look. This calculation has a
few key segments, which play an essential part all the while. Genotype is the full arrangement of Genes that any
individual in Population has. Every quality has a esteem, which will be a piece of potential answer for given
issue. In this framework, the accentuation is given on catchphrase inquiry and the majority of the circumstances
the title of the report contains all the pivotal catchphrases of the report which pass on the focal thought. Hence,
taking this thought, the span of the genotype was kept to 10 so that every quality will hold a conceivable
watchword of the focal thought of the report Phenotype is singular answer for issue that Genotype encodes. For
this framework, it is important to encode every quality as far as its Part of Discourse sort. Consequently, every
token of the title was gone through a straightforward English dialect parser, which gives back the sort of the
token. On the off chance that the token is Thing or Proper Noun then it is encoded as 1 else it is encoded as 0. In
this manner, a conceivable arrangement will contain the majority of the things given in the hunt inquiry The
populace estimate directs the quantity of people in the populace. Bigger populace sizes increment the measure of
899 | P a g e
the best populace size is both applications subordinate and identified with the individual size. In this framework,
for the motivation behind examination the populace size is kept fluctuating Wellness Evaluation is the most
critical part of the Microbial GA as it assesses every part for its closeness to the ideal arrangement. In this
framework, the wellness capacity is painstakingly planned, as off-base assessment would prompt to poor and
misdirecting information extraction. This framework assesses every individual from the populace in view of
how much the information in the part is near the hunt question by client. Around the part 80% near hunt
question is considered as ideal arrangement. Hybrid rate decides the likelihood that hybrid will happen. The
hybrid will produce new people in the populace by joining parts of existing people. The hybrid rate is typically
high and „application dependent‟. Numerous analysts propose hybrid rate to be in the vicinity of 0.7 and 0.96.
Transformation rate decides the likelihood that a transformation will happen. Transformation is utilized to give
new data to the populace and keeps the populace from getting to be distinctly immersed with comparative
chromosomes, just said to maintain a strategic distance from untimely merging. The best transformation rate is
„application dependent‟. For most applications, transformation rate is in the vicinity of 0.001 and 0.1, while for
robotized circuit outline issues, it is more often than not in the vicinity of 0.2 and 0.7.
IV. PROPOSED SYSTEM
As appeared in the Fig. the framework gives client confirmation, which keeps up scan history for each enlisted
client. Once, the client has signed in effectively, it is furnished with an interface, which makes a request to pick
the informational collection on which the pursuit ought to be executed and also the scan inquiry to be utilized
for seeking. Once, the dataset is chosen, every one of the information in the space is parsed and changed into the
procedure required structure. After the information is preprocessed, the number of inhabitants in the Microbial
GA is instated and the procedure of determination and advancement begins. The fundamental individuals near
arrangement are extricated and their wellness qualities are recorded. The information contained by these
individuals is come back to the client and the plot of the wellness for ebb and flow seek inquiry is introduced to
900 | P a g e
V. RESULTS
Since the system is in design and implementation phase it is assumed that the system will perform better than
the traditional tree based approaches for the XML Search. Any user within the system can monitor the
performance of the search on any dataset.
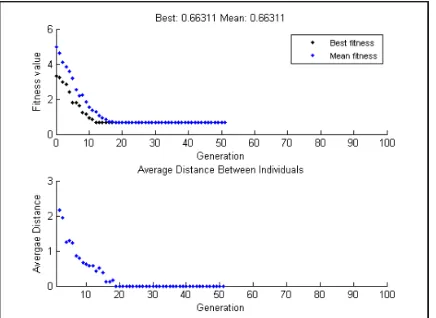
Fig above depicts the graph showing the fitness value in each generation of the search evolution. Average 65%
of the accuracy is assumed to get when XML search is performed using Microbial Genetic Algorithm.
VI. CONCLUSION
Genetic Algorithms (GAs) implement optimization strategies based on simulation of the natural law of
evolution of a species by natural selection. GAs have been applied to a variety of function optimization
problems, and have been shown to be highly effective in searching a large, poorly defined search space even in
the presence of difficulties such as high-dimensionality, multimodality, discontinuity and noise. Therefore,
Microbial Genetic algorithm may give optimum solution to user query for XML data retrieval. This system
implements a steady state tournament selection Microbial Genetic Algorithm over XML data set. This would be
an investigation of how the genetic algorithm would return accurate results over XML data of different domains.
ACKNOWLEDGEMENT AND REFERENCES
[1] Eirinaki M., Vazirgiannis M. (2003). Web mining for web personalization. ACM Transactions On Internet
Technology (TOIT), 3(1), 1-27.
[2] Agrawal R. and Srikant R. (2000). Privacy preserving data mining, In Proc. of the ACM SIGMOD
Conference on Management of Data, Dallas, Texas, 439- 450.
[3] Berendt B., Bamshad M, Spiliopoulou M., and Wiltshire J. (2001). Measuring the accuracy of sessionizers
for web usage analysis, In Workshop on Web Mining, at the First SIAM International Conference on Data
Mining, 7-14.
[4] Mobasher, B., Web Usage Mining and Personalization, in Practical Handbook of Internet Computing,
M.P. Singh, Editor. 2004, CRC Press. p. 15.1-37.
[5] Maier T. (2004). A Formal Model of the ETL Process for OLAP-Based Web Usage Analysis. In Proc. of
"WebKDD- 2004 workshop on Web Mining and WebUsage Analysis", part of the ACM KDD:
901 | P a g e
[6] Pierrakos, D., et al. Web Community Directories: A New Approach to Web Personalization. in Proceeding
of the 1st European Web Mining Forum (EWMF'03). 2003, p. 113-129, Cavtat-Dubrovnik, Croatia.
[7] Kargupta H., Datta S., Wang Q., and Sivakumar K. (2003). On the Privacy Preserving Properties of
Random Data Perturbation Techniques, In Proc. of the 3rd ICDM IEEE International Conference on Data
Mining (ICDM'03), Melbourne, FL.
[8] Linden G., Smith B., and York J. (2003). Amazon.com Recommendations Itemtoitemcollaborative
filtering, IEEE Internet Computing, 7(1), 76-80.
[9] Schafer J.B., Konstan J., and Reidel J. (1999). Recommender Systems in ECommerce, In Proc. ACM