Modeling and Enforcement of Cloud Computing Service
Level Agreements
Abdel-Rahman Al-Ghuwairi
Jonathan Cook
New Mexico State University
Las Cruces, NM 88003
[email protected]
ABSTRACT
A Service Level Agreement (SLA) defines the contract be-tween a cloud provider and a cloud customer, detailing the resources being provided, the price the user will pay, and the quality of service (QoS) guarantees that the cloud provider ensures for the customer. If the QoS guarantees are not up-held, typically the cloud provider is assessed some penalties, such as payment credit for the customer.
Monitoring and enforcing the SLA is an area of open re-search, and in this paper we present the foundations towards a full realization of an SLA monitoring infrastructure. We begin by presenting a formal model that can precisely de-scribe both the SLA QoS guarantees and the penalties as-sessed for violation, and also describe how this model will be used for automatic SLA enforcement.
1.
INTRODUCTION
Service Level Agreements (SLAs) embody the con-tract between the cloud computing provider and the customer. The provider must be concerned with provid-ing a valuable service to the customer but also within cost constraints that make their business viable in a competitive market. The customer simply wants the best computing resource availability and capacity at the cheapest price. The SLA forms the agreement between the customer and the provider as to what will be pro-vided at the price the customer pays. This includes the quality of service (QoS) guarantees that the provide will ensure for the customer.
If the QoS guarantees are not met, some sort of settle-ment must ensue. For example, with an IaaS compute resource (i.e., a virtual machine), the SLA might say that the VM will be available 99.9% of the time, and if during a billing cycle the availability is below this, then the customer receives some discounts on the resource price. In essence, the provider promises some level of availability at the agreed upon price, but then since real-world events can interrupt the virtualized resources it is providing, the provider agrees to a penalty assessment if the availability drops below what was promised.
The main question when it comes to SLAs is: who
monitors and enforces them? There are at least three possible answers—the provider, the customer, or some trusted third party. Each has its own benefits and con-cerns.
If the provider monitors itself, then what reason does the customer have to trust what it reports? It is in the provider’s interest not to report SLA violations. In addition, if for example there was no attempted cus-tomer interaction with a cloud resource during a period where it was unavailable, should such a period truly be considered as unavailable time? As far as the customer is concerned, each use of the resource (before and af-ter the period of unavailability) was successful, so there was 100% availability.
If the customer must monitor the SLA, then the cus-tomer must become (or hire) an expert in setting up a monitoring infrastructure in addition to their cloud ap-plications, and be able to properly detect when some-thing has violated the SLA. This may be a large burden on the customer, and may preclude their desire to use the cloud provider.
Some third party SLA monitors are being deployed, and this seems to be a good approach [16, 4]; how-ever, most of them are typically contracted by the cloud provider, and thus they engender some of the same trust issues that provider self-monitoring encompasses.
To further complicate matters, cloud SLAs are typi-cally natural language documents rather than some for-mal specification of the agreement. Although this does not mean that they are necessarily ambiguous, it can be a barrier to moving towards any type of automated SLA enforcement.
In reality, the current practice is that cloud providers typically do not want to encourage extremely tight mon-itoring of cloud resources, and generally require cus-tomers to report an issue with a cloud resource that the SLA might cover. For example, for availability calcula-tions most IaaS providers require a customer to report a resource as unavailable, and the “unavailable clock” does not start counting until the customer report is filed [2]. Because of this, we are beginning on a research path
towards efficient customer-oriented IaaS cloud SLA mon-itoring. Our goal is to create an easy-to-use monitoring package for customers to deploy that will monitor the cloud resource they are purchasing and automatically detect whether any SLA parameters become in viola-tion of the agreement, and then what penalties might be enforced.
In this paper we present the formal foundations of our approach, since an automated system is first going to need a formal description of the SLA it is monitor-ing. A key part and an important novel aspect in our approach is including the penalty assessments in the formal specification.
The rest of the paper is organized as follows: Sec-tion 2 presents background in cloud monitoring and in cloud SLA agreements. In Section 3 we present our for-mal SLA model and monitoring ideas, and Section 4 elucidates the model with a full example. Section 5 describes related work, and finally Section 6 concludes with directions for the future of this work.
2.
IAAS CLOUD SERVICE LEVEL
AGREE-MENTS
In this section we discuss the basic purposes and con-tent of Infrastructure-as-a-Service (IaaS) service-level agreements (SLAs).
2.1
Service Level Agreement Overview
Cloud computing entails an environment that creates a relationship between the cloud provider and the cloud user. This relationship between the two parties is usu-ally embodied in an agreement or contract called a Ser-vice Level Agreement (SLA). This SLA contains the Quality of Service (QoS) parameters or guarantees that the cloud resources will provide, and both parties should agree upon these guarantees prior to the beginning of the service. There are many parameters that the SLA may cover, such as performance metrics, including in-frastructure and applications, availability (uptime and downtime), response time, scalability, and many other features or constraints. Even if the cloud provider and cloud users are part of the same organization (i.e., a private cloud), an SLA can still be used to assess the effectiveness of the cloud provider department and to give the cloud user departments a basis for business planning.
Public cloud users desire a suitable cloud provider who can satisfy their requirements and needs at an at-tractive cost. On the other hand, cloud providers desire SLAs containing QoS guarantees that can be satisfied cost-effectively while meeting the users’ requirements to keep their business and trust. The cloud provider and a significant cloud user may have a negotiation process about each part of the SLA, and then after they reach an agreement, the cloud provider will commit to provide
and maintain the QoS guarantees that are the main component of the SLA. Should the SLA be violated, agreed-upon penalties will be incurred by the provider. Users may also agree that they should be aware of and report any violation that occurred from the provider side, and claim the refund for such violation in a timely manner.
The QoS guarantees in an SLA must be normally achievable to maintain the trust of cloud users. It may be tempting for a cloud provider to assert very strong QoS guarantees, such as 99.999% availability, and just accept the penalties when the service fails to meet the guarantee. However, these highly optimistic guarantees will cause lack of credibility and trust between the user and the provider [7].
2.2
Service Level Agreement Examples
Here we present examples of the QoS guarantees found in current SLAs.
Rackspace [2] is a cloud provider which offers cloud servers (VMs), cloud sites, and cloud files. It also of-fers an SLA for each cloud type, and because we are interested in the infrastructure’s SLAs, we will address their cloud server SLA as an example in this paper. The SLA of cloud servers in Rackspace covers four main ser-vices or parameters: network, data center infrastruc-ture, cloud server hosts, and migration. In the net-work, Rackspace offers 100% availability for their data-center network excluding the scheduled maintenance. The penalty will be a credit of 5% refund to the user for each 30 minutes downtime up to 100% of the monthly fee. In data center infrastructure, Rackspace ensures that the data-center power functioning 100% of the time in any given monthly billing cycle. They will credit the customer’s account with 5% of the monthly fee for each 30 minutes of downtime up to 100% of the monthly fee in case of any violation occurs in this service. The third service is the server hosts in which they ensure that all server hosts are functioning and restore any failure within one hour of the problem notification. If Rackspace fails to meet this QoS guarantee, then they will credit the customer with 5 % of the fees for each additional hour of downtime up to 100% of the monthly fee. The last service is the migration where Rackspace informs the customer if any cloud server migration is needed at least 24 hours prior to the beginning of that migration. They will credit the customer with 5% of the fees for each additional hour of downtime up to 100% of the monthly fee. We can summarize this example on Table 1 below.
Another example of an SLA is the one offered by Amazon EC2 [3]. In this SLA, Amazon ensures 99.95% service availability yearly. Amazon EC2 considers the service and the uptime yearly, and the service year is the proceeding 365 days before an SLA claim. If the
Table 1: Rackspace SLA example
QoS Credit Credit Time Attribute Guar. Value Unit (min) Network Avail 100% 5% 30 Data-center Power 100% 5% 30 Host Repair ≤ 5% 60 Time 1hr Migration 24hr in 5% 60 Notification advance
customer use the service less than 365 days, then the service year is the proceeding 365 days but the uptime in all days prior to the use of the service can be consid-ered 100%. In the event of failing to achieve this uptime percentage, the customer will receive a credit of 10% of the bill excluding one-time payment for initiating the service. In Amazon Simple Storage Services (S3), the SLA offers 99.9% uptime. In case of violation the cus-tomer will receive a credit of 10% if the availability is greater than or equal to 99% and less than 99.9% and a credit of 25% if the availability is less than 99%. Table 2 shows the SLA of Amazon S3.
Table 2: SLA of Amazon S3
Uptime % Credit% 99.0≤U <99.9 10
U ≤99.0 25
In Google App [1] cloud services, the SLA ensures a service availability of at least 99.9% monthly. On the other hand, the customer will receive a different amount of credit for each violation. Table 3 shows the amount of credits for each level of availability in Google’s App SLA.
Table 3: SLA of Google App
Monthly Uptime % Free days added 99.0≤U <99.9 3 95.0≤U <99.9 7
U <95.0 15
Many SLAs have a similar approach to the tabu-lar Google SLA shown above: they offer a graduated penalty based on which level their SLA QoS violation falls in. A flat penalty is modeled with just one row in the table.
3.
MONITORING AND MODELING SLAS
3.1
SLA Monitoring Framework
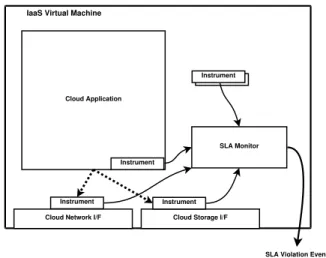
Figure 1 depicts our architecture for monitoring and enforcing an SLA. The figure centers the architecture around an IaaS virtual machine, although we envision
Cloud Application
IaaS Virtual Machine
SLA Monitor
Cloud Storage I/F Cloud Network I/F
Instrument Instrument
Instrument
Instrument
Instrument
SLA Violation Events
Figure 1: SLA Monitoring Architecture.
that it could be reconfigured to, for example, monitor only IaaS storage resources by deploying the framework on a customer’s machine that uses the storage resource. In addition to the customer’s cloud application, we have the customer deploy anSLA Monitor component onto its cloud VM whose responsibility is to perform the SLA monitoring and report any violations. It receives measurement data from various Instruments that are also installed on the VM and perform individual low-level monitoring and data gathering for the IaaS re-sources that the SLA encompasses.
Instruments might sometimes intercept actual cloud application operations and perform some measurement on them, such as the measuring the time it takes to complete storage requests in order to calculate storage bandwidth and latency performance. Such instruments might be placed outside or inside the cloud application, as the figure shows, depending on what is easier. Since this may interfere with application performance, an in-strument could perform sampling and only occasionally incur such cost.
Instruments might also actively perform their own ex-ercise of a resource in order to measure its current per-formance; for example, communicating with an external known host in order to measure the network bandwidth and latency. Such active resource exercising must of course be kept to a minimum in order to not incur both cost and application degradation. The figure shows some instruments residing simply in the VM itself— such instruments might monitor VM performance, ap-plication VM usage, and other O/S-level measurements that can help inform the SLA Monitor on the current status of the cloud resource.
In the figure, the SLA Monitor then sends notifica-tion events in case the SLA has been violated. These might be received by some customer host, but since the point of cloud computing is that the customer no longer
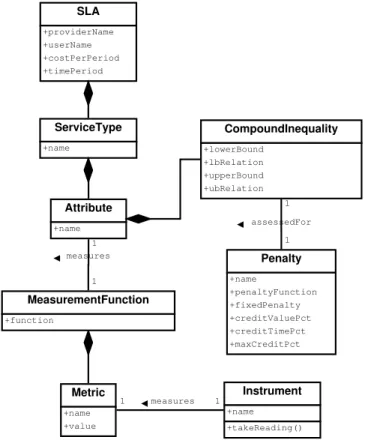
SLA +providerName +userName +costPerPeriod +timePeriod ServiceType +name Attribute +name Instrument +name +takeReading() Metric +name +value measures 1 1 CompoundInequality +lowerBound +lbRelation +upperBound +ubRelation Penalty +name +penaltyFunction +fixedPenalty +creditValuePct +creditTimePct +maxCreditPct assessedFor 1 1 MeasurementFunction +function measures 1 1
Figure 2: SLA Domain Model.
needs to run and maintain their own hosts, the notifica-tion events will likely be sent elsewhere or in some other fashion. Possibilities include: send notifications to an-other cloud VM of the customer that is running anSLA Violation Reporter component (it might even be on the same VM), to a multi-customer trusted 3rd party vi-olation reporter, or even through an email report to the customer, who will manually report the violation to the cloud provider. Ultimately, the violation reporter should, either automatically or manually, report the vi-olation to the cloud provider using the provider’s viola-tion reporting interfaces.
Our monitoring framework must be very low over-head, since it is consuming cloud resources alongside the cloud application. We envision that data from the instruments is low frequency, and that evaluating new data to check for violations is not computationally in-tensive. Our goal is that the framework consumes less than 1% of the cloud resources, assuming a relatively active cloud application; if the cloud application is very quiescent then monitoring cost relative to the applica-tion might be significant, though in absolute terms still be very small.
3.2
Modeling the SLA
Our SLA model is defined in this section using dis-crete math notation, with the UML domain model shown
in Figure 2 also providing a graphical depiction of the relationships of the parts of the domain model.
The entire SLA model is defined as a five-tuple, specif-ically SLA={P, U, C,[t1, t2], s [ i=1 {Si, n [ j=1 Aj}} (1)
where P is the provider, U represents the user , C is the cost of the service over the period [t1, t2],Si is the
service type or resource type such as system, and Aj
is a measurable attribute that the SLA specifies con-straints over. The time period [t1, t2] is the contract
period over which the SLA is evaluated. In current SLAs this is typically the one-month billing period; for any SLA violations during that period the provider may incur a penalty (such as a discount), but then the next billing period starts from a clean slate as far as SLA enforcement is concerned.
Attributes are considered to be classified into service type categories, as shown in Figure 2, thus Equation 1 shows the attributes collected and associated with a ser-vice typeSi. For example, network availability is within
the service type “network”, while storage response time is within the service type “storage”. This hierarchy is defined mostly for practical organization.
Although commodity cloud providers generally have one SLA that they require their customers to agree with, our model defines the SLA as per user, so that a cloud provider might negotiate a unique SLA for each cus-tomer.
The union overAjrepresents the set of attributes
un-der the service typeSi and its corresponding relations,
and is defined by the formula:
Aj={a, ME, c
[
k=1
{LVk, LRk, U Vk, URk, PEk}}. (2)
Where a is the attribute name under the service type
Si such as “network availability” under the service type
“network”, ME is a measurement function for the at-tribute, and the union represents the compound in-equality that captures the SLA constraints on the at-tribute (see Figure 2). This compound inequality is intended to capture constraints such as those found in Table 3.
Each tuple in the union models one row in the table.
LVk is the lower bound value of thekthcompound
in-equality for the attribute (i.e., thekthrow),LRk is the
relational operator for the lower bound,U Vk is the
up-per bound value andURk is the relational operator for
the upper bound. The relational operators are defined as
LRk, URk ∈ {>,≥, <,≤,6=,=}
An example of a full relation, for total system memory: (2G≤ME(“total memory”)<4G)
whereLVk = 2G, LRk = “≤”, U Vk = 4G, and URk =
“<”, and the attributea=“total memory”.
PEk is the penalty function for the attribute if a
vi-olation occurs in the kth compound inequality. This
is capturing the different penalties associated with the rows in Table 3, which cannot be reduced to some sin-gle function and are thus modeled independently. Sec-tion 3.3 discusses the penalty calculaSec-tion in depth.
The measurement function ME of the attribute Aj
can be calculated as
ME(Aj) =F(m1, ..., mq) (3)
whereF(m1, ..., mq) is a variable function that defines
the attribute’s value to be that computed by the func-tion over possibly multiple metrics (see Figure 2). The idea here is that our monitoring instruments will col-lect fundamental base metrics which can then be used to compute higher-level attributes such as availability. The metrics will correspond to and be produced by the framework’s monitoring instruments. These will then be combined into high level SLA attributes and evalu-ated according to our model. For example the two met-rics:“memory in use”and“free memory”are considered metrics of the attribute“total memory.” While,“total service hours”and“server downtime”are considered the metrics of the“server availability”attribute. To evalu-ate the functionF(m1, ..., mq), the provider will follow
certain mapping rules between each attribute and its corresponding valuation function.
For example, if we denote the service type“hardware”
by S1, and suppose we have the following attributes
under this service, a1 =“total memory,” a2 = “disk
storage,”and a3 =“server availability.” Suppose that
we can measure the attribute“total memory”a1by the
metrics“memory in use”(m1), and“free memory”(m2).
Also we can measure the second attribute“disk storage” a2 by the two metrics“used disk space”(m1) and“free
disk space”(m2).
To evaluate the measurement function ME(Aj) of
the first two attributes, we have to specify a valua-tion funcvalua-tion F. By applying the mapping rules for the attributes a1 and a2 with its corresponding
valua-tion funcvalua-tion, we can define the valuavalua-tion funcvalua-tion of these attributes as:
ME(a) =F(m1, m2) =V(m1) +V(m2) =v1+v2.
where V(m1) and V(m2) are the measurement values
of the metricsm1 andm2, respectively of the attribute
a1, and v1 is the value obtained byV(m1) and it
rep-resents the amount of used memory or used disk, and
v2is the value obtained byV(m2) and it represents the
amount of free memory or free disk space. These values can be obtained directly from the monitoring tool that measures these attributes.
To measure the value of the third attribute“server availability”a3, we need to have two metrics. The first
one is“total service hours”m1 and the second one is
“server downtime”m2. The value of the“total service
hours”V(m1) can be obtained by subtracting the start
date and time of the service from the end date and time of the servicet2−t1, while the value of the“server
downtime”V(m2) can be obtained from the monitoring
tool. Then we can measure the“server availability”by
ME(a) = F(m1, m2)). Then after the mapping which
can be done by the provider, we can define the valuation function of this attribute as
F(m1, m2) = V(m1)−V(m2) V(m1) ×100 = (v1−v2) v1 ×100 where v1 is the value obtained byV(m1) which
repre-sents the total service hours, and v2 is the value
ob-tained byV(m2) which represents the server downtime.
3.3
The Penalty Function
If one of the compound inequalities associated with an attribute is found to be satisfied—e.g., a row in Ta-ble 3 is matched because availability has dropped into that range—then the penalty associated with that row must be applied. Although the table shows simple con-stant penalties, current SLAs can have quite complex penalty functions, and so we model penalties as a piece-wise function, described in this section.
PEk is a function which represents the kth penalty
in case of any violation occurred in the kth compound inequality of the attributea. The penalty functionPEk
can be defined as a five-tuple by the formula:
PEk={VPEk, dk, CRVk, CRTk, MCRk} (4)
whereVPEkis the valuation function of thekthpenalty. dk is a typed constant value that denote different kinds
of penalties such as “total number of days added to the service with no cost,” as in the SLA of Google App shown in Table 3 above. This constant also may de-note a fixed amount of money, or any other constraint or value which may depend on the service type and the attribute. This constant value or constraint should be defined clearly in the SLA if there is any need for it.
CRVk is the credit value (percentage) corresponding to
thekthcompound inequality of the attributea. CRT kis
the credit time factor which associated with the credit value in the SLA.MCRkis the maximum value of credit
that allowed to be given to the user, which is most of the time 100% of the monthly cost or fees.
If a violation occurred in the attributeaand thekth
compound inequality is true, then the provider must credit the customer’s account with the specified amount of credit for that violation as stated in the SLA. Viola-tion means that the quality of service guarantee is not satisfied or met.
The valuation function of the penalty is defined in a piece-wise function as described in Figure 3. The
val-VPEk= dk : if CRTk = 0 CRVk = 0 where dk is a typed constant CRVk×C : if CRTk = 0 CRVk >0 min(T,(G×(h)) : if CRTk >0 CRVk >0 where h=bVIM CTPkc T =MCRk×C G=CRVk×C VIM = 1−ME(a) CTPk= CRTk TMB TMB is total billing minutes (5)
Figure 3: Penalty Function
uation function of the penalty has three pieces, each of which captures a common penalty formulation. The first is a simple constant, and is what is shown in our ex-ample in Table 3. The second piece captures the penalty as a fraction of the costCof the service. The third cap-tures the penalty as a function of the timeTk that the
SLA has been in violation.
In case of non-temporal attributes, the first and the second piece of the valuation function is used. On the other hand the third piece will be used in case of tem-poral attribute such as “availability”. The particular values within theP Ek tuple determine which piece to
apply.
In the first piece the value of the function will be the constant dk as explained above; since only dk is
used, both the credit time CRTk and the credit value CRVkare equal to zero. The value of the function in the
second piece will be a fraction of the cost of the service, i.e., the product of the credit valueCRVk multiplied by
the costC; it is applied when the credit time CRTk is
equal to zero, and the credit valueCRVkis greater than
zero.
The third piece of the penalty function calculates a penalty such as “5% of the service cost for each 30 min-utes of downtime, up to 100% of the service cost.” In this piece, T is the maximum allowed penalty (e.g., 100% of the service cost), G is the penalty for each time unit of violation (e.g., 5% of service cost), and h
is the number of time units of violation. We assume here that ME(a), the attribute metric is a percentage of time availability, thus 1−ME(a) is the percentage of time in violation, from which we can calculate the total number of time units in violation,h.
This proposed SLA model along with the penalty function described above captures most of services, at-tributes, and penalties that exist in the current real-world SLAs. It also can be extended easily to include any new QoS parameter or penalty which may be intro-duced in future SLAs.
4.
EXAMPLE OF THE PROPOSED MODEL
This section presents an example of how our model will be used to capture the SLA and then dynamically enforce the SLA agreement, in particular the penalty calculations.
Suppose that we have a cloud provider company called “Cloudspace”, and this provider offers a IaaS compute service (e.g., a VM) for $10 a month. This provider of-fers QoS guarantees for the system availability as shown in Table 4. The provider will credit the customer ac-count with $3 if the system availability (up-time) is be-tween 99.5% and 99.9% during the monthly billing cycle excluding scheduled maintenance. This provider also guarantees to credit the customer account with 5% of the monthly cost or fee for each 30 minutes of system downtime up to 100% of the monthly fee, if the up-time is less than 99.5%.
Table 4: SLA example
Monthly up-time Amount of credit 99.5≤U <99.9 $3
0≤U <99.5 5% of the cost
Suppose a user called “Mike” likes the services given by this provider and he wants to sign an SLA with this provider for the month of January in the year 2012. To apply this example in our proposed model we will start from the SLA formula, introduced above, in equation 1:
SLA={P, U, C,[t1, t2], s [ i=1 {Si, n [ j=1 Aj}}
Then we can substitute the SLA parameters as the following: P =“Cloudspace,” U =“Mike,”C =$10, and the billing cycle or the interval of the service is [t1, t2] = [1/1/2012,1/31/2012]. Si = S1 =“system,”
a1=“availability”.
Second, we will apply the attribute equation, intro-duced above, in Equation 2:
Aj ={a, ME, c
[
k=1
then we can rewrite the setA1 as
A1={“availability”, ME,{{99.5%,≤,99.9%, <, PE1}, {0%,≤,99.5%, <, PE2}}}.
The attribute“availability”a has two metrics“total service hours”m1 and“server downtime” m2. From
the example, the violation’s metricm2 =“server
down-time,”credit value isCRVk = 5%, credit time is CRTk
= 30 minutes, monthly cost isC= $10, and the maxi-mum credit percentage allowed isMCRk= 100%. Table
5 summarizes this SLA example.
Table 5: SLA summarized example
Si a LVk U Vk CRVk CRTk
VM Av. 99.5% 99.9% $3 0 VM Av. 0% 99.5% 5% 30 min To measure the attribute value we will use the mea-surement function, defined above, in Equation 3:
ME(Aj) =F(m1, ..., mq)
Then after the mapping we can define the valuation function of this attribute“system availability”as
ME(Aj) = V(m1)−V(m2) V(m1) ×100 = (v1−v2) v1 ×100 whereV(m1) is the total service time andV(m2) is
the system (VM) downtime.
Suppose that the service duration as agreed upon in the SLA was one month, then total hours per month = 24 hours × 7 days × 4.33 weeks per month = 720 hours/month approximately which isV(m1). If the
net-work was down for 5 hours in the month that means downtimeV(m2) = 5, then ME= (720−5) 720 ×100 = 99.31%.
We can see that this percentage falls in the second compound inequality because 0 ≤99.31% <99.5% as shown in Table 4. Now, we can check if the second compound inequality expression is true or not:
0%≤99.31%≤99.5%
As we can see, the result of this expression is true, this means that the user will be eligible for a credit and the provider will be charged for this amount of credit.
To calculate the amount of the credit we will use the penalty function PEk, declared above, in Equation 5.
As stated in the SLA, which is shown in Table 5 above, the credit value CRVk = 5% , and the monthly fee or
cost = $10, then
Gk =CRVk×C=
5
100×10 = $0.5
To calculate the value of the violation metric we will use the equation VIM = 1−ME(a) = 1−0.9931 = 0.0069. The billing cycle is one month, ThusTMB = 30∗24∗60 = 43200, then CTPk =
CRTk
TMB =
30 43200 =
0.00069. Now, the total number of violations is
h=bVIM
CTPk
c=b0.0069
0.00069c=b10c= 10
this means that the credit will be applied 9 times. In this case the mapping rule will use the third piece of the penalty function,introduced above, in Equation 5.
Tk =MCRk×C= 100%×10 = $10
now, we will use the third part of Equation 5 to find the amount of penalty
PEk=min(Tk,(Gk×(hk)
=min(10,(0.5×10)) =min(10,5) = $5
Thus, the customer will be eligible for a $5 refund from the total monthly billing fees, and the provider will lose this amount of credit by paying it back to the customer.
5.
RELATED WORK
There is much research in cloud computing monitor-ing; this research focuses on the main objectives that users of the cloud are looking to achieve while using or buying cloud products. These factors include secu-rity issues, performance metrics, disk storage, availabil-ity, scalabilavailabil-ity, throughput, efficiency, and many others. Cloud computing monitoring mainly aims to help man-age these issues and ensure that the SLA covering them is maintained.
Motohari [15] suggests that a third party cloud mon-itor should be used, such as Red Hat command cen-ter, to monitor the user’s application and the provider’s infrastructure according to the (SLA). Monalytics [11] combines the ideas of monitoring and analysis, with the goal of monitoring a cloud and dynamically analyzing its performance in order to take corrective actions dur-ing runtime before detectdur-ing issues become larger prob-lems.
There has been significant work in this area of both formal modeling of SLAs and of monitoring cloud re-sources for SLA verification. Most of this work seems to be on the cloud infrastructure, or provider, side, with the goal of quickly detecting or even predictively avoid-ing SLA violations. As provider-side frameworks, these approaches can assume a far more intricate deployment, and e.g., some even work at the level of modified hyper-visors [11]. The paragraphs below detail representative examples of previous work.
A QoS model is proposed by [5] which states that the QoS model consists of service provider, services, and resources where the providers can offer one or more ser-vices and should support hosting environment on their resources. The service can be executed on more than one resource. They define the SLA for each client or user as SLAi = {Q(t)}, where t ∈ [t1, t2], and Q(t)
denotes the set of quality of service levels for each at-tribute Qi(t) = q1(t), q2(t), ...qn(t). Then they define
the SLA specifically as SLA ={R,(A, value)}, where
Ris the set of relations,Ais the set of attributes, and value is the value assigned to each attribute. Each re-lation must be verified and evaluated over a set of at-tributes.
With the goal of preventing SLA violations of QoS guarantees before they occur, the Foundation of Self-Governing ICT Infrastructure (FoSII) [8] is a proposed novel monitoring model for mapping low level resource metrics such as CPU, disk storage, and memory with high level SLAs and does the monitoring at the exe-cution time, which helps in achieving autonomic SLA management and prevents SLA violations. FoSII use a Low-level Metric to High-level SLA (LoM2HiS) frame-work, which works by monitoring infrastructure resources in the host monitoring stage and produces pair-metric values for each infrastructure component by using Gmond from Ganglia project and send them to the run-time monitoring stage, which can map each pair with the equivalent, predefined, high level SLA parameters.
A simulation engine was developed by [14] to evalu-ate Knowledge Management techniques (KM) to help in resource management and SLA enforcement by us-ing Case Based Reasonus-ing (CBR) and decision makus-ing . This simulation was part of the work done by (FoSII) [8] which uses the LoM2HiS framework to monitor the cloud infrastructure. Case based reasoning is a tech-nique used to solve a current case or problem by using solutions from similar cases that happened in the past. QoS guarantees in their work are represented by Ser-vice Level Objectives (SLOs) which are the component of the SLA.
A proposed algorithm by [9] solved the problem of SLA-based resource allocation and optimize the total expected profit. There are three main factors that af-fect the profit, SLA satisfaction, penalties in case of violations, and the cost of energy. Their model is based on the SLA guarantees parameters and the multi-tier applications.
An optimization algorithm proposed by [12] is used to prevent SLA violations and reduce the cost in case any violation occurs. Their research is an expansion of previous work about SLA conformance prediction and prevention based on event monitoring framework (PRE-vent). The main concern of the providers is to prevent SLA violations. Therefore they presented an approach
to achieve that by predicting the violation’s attribute at runtime.
6.
CONCLUSION
With the formal foundation of IaaS SLA modeling presented in this paper, our future work will involve building a framework that implements the vision in Fig-ure 1. With this framework we will be able to experi-ment and validate or invalidate our ideas.
Currently we are looking at the Policy Description Language (PDL, [13, 6]) to specify our SLA models in. PDL has a rich set of capabilities that allow one to describe constraint-based policies along with rules that define actions that are triggered on constraint violation. We can then build an automatic translator from PDL into an executable form. A good match for PDL is the “online” constraint solveroClingo[10], which allows new information to be entered (the online part) and a recomputation of the constraints to be undertaken au-tomatically. Our instruments that continually produce new measurements of the cloud resources will feed their data into the oClingo program that embodies the SLA, and SLA violations will produce actions that generate an external event that can then be acted upon by an-other component.
This is just one possible approach, and further re-search may lead us to build our SLA monitoring frame-work on other, more appropriate capabilities.
In this paper we presented our ideas for monitoring IaaS cloud SLAs for potential violations. We take the view of supporting the customer in detecting SLA vi-olations because many real SLAs require the customer to notify the provider that the SLA has been violated, and the customer will generally need an easy-to-deploy framework to do this with because they are not a cloud expert nor have low-level access to the cloud infrastruc-ture. Our formal model for capturing SLAs, along with the penalty calculations, is the first step towards real-izing this vision, and provides an important conceptual realization of cloud SLA ideas in its own right.
7.
REFERENCES
[1] SLA in Google application.
http://www.google.com/apps/. [Online; accessed 20-December-2011].
[2] Hosting Solutions in rackspace.
http://www.rackspace.com/cloud/legal/sla/, 1998. [Online; accessed 01-March-2011].
[3] SLA in amazon EC2 and Amazon S3.
http://www.amazon.com, 2003. [Online; accessed 20-December-2011].
[4] Nimsoft Monitoring Soultions.
http://www.nimsoft.com/solutions, 2011. [Online; accessed 20-April-2011].
[5] R. Al-Ali, O. Rana, G. Laszewski, et al. A model for quality-of-service provision in service oriented architectures.International Journal of Grid and Utility Computing, 2005.
[6] R. Bhatia, J. Lobo, and M. Kohli. Policy evaluation for network management. In
INFOCOM 2000. Nineteenth Annual Joint Conference of the IEEE Computer and
Communications Societies. Proceedings. IEEE, volume 3, pages 1107–1116. IEEE, 2000.
[7] D. Durkee. Why Cloud Computing Will Never Be Free.ACM Queue, 8(4):20, 2010.
[8] V. C. Emeakaroha, I. Brandic, M. Maurer, and S. Dustdar. Low level Metrics to High level SLAs - LoM2HiS framework: Bridging the gap between monitored metrics and SLA parameters in cloud environments. InHPCS, pages 48–54, 2010. [9] H. Goudarzi and M. Pedram. Multi-dimensional
SLA-Based Resource Allocation for Multi-tier Cloud Computing Systems. InIEEE CLOUD, pages 324–331, 2011.
[10] T. Grote, T. Schaub, and B. Schnor. A reactive system for declarative programming of dynamic applications. 2010.
[11] M. Kutare, G. Eisenhauer, C. Wang, K. Schwan, V. Talwar, and M. Wolf. Monalytics: online monitoring and analytics for managing large scale data centers. InICAC, pages 141–150, 2010. [12] P. Leitner, W. Hummer, and S. Dustdar.
Cost-Based Optimization of Service
Compositions.IEEE Transactions on Services Computing, pp(99), 2011.
[13] J. Lobo, R. Bhatia, and S. A. Naqvi. A Policy Description Language. InAAAI/IAAI, pages 291–298, 1999.
[14] M. Maurer, I. Brandic, and R. Sakellariou. Simulating Autonomic SLA Enactment in Clouds Using Case Based Reasoning. In E. D. Nitto and R. Yahyapour, editors,Towards a Service-Based Internet - Third European Conference,
ServiceWave, Ghent, Belgium, volume 6481 of
Lecture Notes in Computer Science, pages 25–36. Springer, 2010.
[15] H. Motahari-Nezhad, B. Stephenson, and S. Singhal. Outsourcing business to cloud
computing services: Opportunities and challenges.
IEEE IT Professional, Special Issue on Cloud Computing, 11(2), 2009.
[16] P. Patel, A. Ranabahu, and A. Sheth. Service Level Agreement in cloud computing.Cloud Workshops at OOPSLA, 2009.