Technological University Dublin
Technological University Dublin
ARROW@TU Dublin
ARROW@TU Dublin
Dissertations
School of Computing
2018
Supervised Learning Models to Predict Stock Direction Within
Supervised Learning Models to Predict Stock Direction Within
Different Sectors in a Bull and Bear Market
Different Sectors in a Bull and Bear Market
Tiffany Razy
[email protected]
Follow this and additional works at:
https://arrow.tudublin.ie/scschcomdis
Part of the
Computer Engineering Commons
Recommended Citation
Recommended Citation
Razy, Tiffany (2018). Stock direction within different sectors in a bull and bear market. Masters
dissertation, DIT, 2018.
This Dissertation is brought to you for free and open access by the School of Computing at ARROW@TU Dublin. It has been accepted for inclusion in Dissertations by an authorized administrator of ARROW@TU Dublin. For more information, please contact
Supervised
Learning Models to Predict
Stock Direction Within Different Sectors
in a Bull and Bear Market
Tiffany Razy
A dissertation submitted in partial fulfilment of the requirements of
Dublin Institute of Technology for the degree of
M.Sc. in Computing (Data Analytics)
January 2018
I certify that this dissertation which I now submit for examination for the award of MSc
in Computing (Knowledge Management), is entirely my own work and has not been
taken from the work of others save and to the extent that such work has been cited and
acknowledged within the test of my work.
This dissertation was prepared according to the regulations for postgraduate study of the
Dublin Institute of Technology and has not been submitted in whole or part for an award
in any other Institute or University.
The work reported on in this dissertation conforms to the principles and requirements of
the Institute’s guidelines for ethics in research.
Signed: Tiffany Sara Razy
ABST
RACT
Forecasting stock market price movement is a well researched and an alluring topic
within the machine learning and financial realm. Supervised machine learning
algorithms such as Random Forest (RF) and Support Vector Machines (SVM) have been
used independently to gain insight on the market. With such volatility in the market the
scope of this study will utilized the RF and SVM in a very volatility market to determine
if these models will perform at a high level or outperform each other in both markets.
This relative study is performed on 16 stocks in 4 different sectors over the bear market
”housing crash” of 2008
. The model utilized technical indicators as the respective
parameters to assist in predicting the stock price movement when determining the
performance of each model. Despite the No Free Lunch Theorem stating one model can
not out perform another model, the study displayed higher accuracy for the RF model.
Each model was evaluated using the confusion metrics to calculate the precision, recall,
and F1 score.
Key words: Support Vector Machines, Random Forest, Bull and Bear Market, Stock
Price Forecasting, Technical Indicators
ACKNOWLEDGEMENTS
I would like to express my sincere thanks to my supervisor Andre Rios for his assistance,
patience, guidance, and constant support through the course of this dissertation.
I’d
like to thank
Sarah Jane Delany, Luca Longo, and Matthew Morey for their
unconditional support, advice, and patience.
I also appreciate all my DIT lectures for assisting me in gaining the knowledge to be
able to complete this dissertation.
I would like to thank my parents, siblings, and boyfriend for encouraging me to continue
working hard, providing unconditional love, and for supporting me.
I would like to immensely thank Angie Hayes, and Roxanne Chenette for proofreading
my proposal, dissertation, and for their enormous amount of kindness.
TABLE OF CONTENTS
ABSTRACT ... II
TABLE OF FIGURES
...
VII
1
INTRODUCTION
... 1
1.1
BACKGROUND
... 1
1.2
RESEARCH PROJECT/PROBLEM
... 1
1.3
RESEARCH OBJECTIVES
... 3
1.4
R
ESEARCHM
ETHODOLOGIES... 4
1.5
SCOPE AND LIMITATIONS
... 5
1.6
D
OCUMENTO
UTLINE... 6
2
LITERATURE REVIEW
...
8
2.1
TRADING STRATEGIES ... 9
2.1.1
TECHNICAL ANALYSIS ... 9
2.1.2
F
UNDAMENTALA
NALYSIS... 12
2.2
MARKET TRENDS AND BEHAVIOURAL INVESTMENT ... 12
2.2.1
BULL AND BEAR MARKET
... 13
2.3
MACHINE LEARNING ... 13
2.3.1
S
UPPORTV
ECTORM
ACHINES... 14
2.3.2
RANDOM FOREST
... 15
2.4
EVALUATION
... 15
2.4.1
CONFUSION MATRIX
... 16
2.5
OVERVIEW ... 18
3
DESIGN AND METHODOLOGY
... 19
3.1
I
NTRODUCTION... 19
3.2
BUSINESS UNDERSTANDING
... 20
3.2.1
BUSINESS GOAL ... 21
3.3
DATA UNDERSTANDING ... 21
3.3.1
C
OMPANYS
ELECTION... 22
3.3.2
COMPANY STOCK CRITERIA
... 22
3.3.3
COMPANY STOCK DATA
... 23
3.4.1
E
XPONENTIALS
MOOTHINGA
VERAGE... 25
3.4.2
AVERAGE DIRECTIONAL INDEX ... 26
3.4.3
BOLLINGER BAND
... 27
3.4.4
CHAIKIN MONEY FLOW ... 28
3.4.5
C
OMMODITYC
HANNELI
NDEX... 28
3.4.6
RELATIVE STRENGTH INDEX
... 29
3.5
MODELLING ... 30
3.6
EVALUATION
... 31
3.6.1
C
ONFUSIONM
ATRIX... 31
3.7
DEPLOYMENT ... 32
3.8
STRENGTHS AND LIMITATIONS
... 32
3.9
OVERVIEW ... 33
4
IMPLEMENTATION AND R
ESULTS
...
34
4.1
INTRODUCTION
...
... 34
4.2
D
ATAP
REPARATION ANDE
XPLORATION... 34
4.2.1
DATA
PREPARATION
... 34
4.2.2
FEATURE EXPLORATION
... 37
4.3
MODELLING ... 38
4.4
M
ODELE
VALUATION... 40
4.4.1
FINANCIAL S
ECTOR... 42
4.4.2
TECHNOLOGY SECTOR ... 43
4.4.3
HEALTHCARE
S
ECTOR... 44
4.4.4
I
NDUSTRIALS
ECTOR... 45
4.5
OVERVIEW
... 45
5
EVALUATION
...
...
47
5.1
RESULT EVALUATION
... 47
5.1.1
FINANCIAL SECTOR ...
47
5.1.2
TECHNOLOGY SECTOR ... 49
5.1.3
H
EALTHCARES
ECTOR...
51
5.1.4
INDUSTRIAL SECTOR
... 53
5.2
ANALYSIS OF R
ESULTS...
54
6
CHAPTER 6: CONCLUSION
... 57
6.1
RESEARCH OVERVIEW AND GAP
... 57
6.2
DESIGN
,
IMPLEMENTATION, AND EVALUATION... 58
6.3
CONTRIBUTIONS
... 59
6.4
F
UTUREW
ORK ANDR
ECOMMENDATIONS...
... 59
7
BIBLIOGRAPHY ... 61
TABLE OF FIGURES
FIGURE 2.1 LITERATURE REVIEW LAYOUT ... 8
FIGURE 3. 1 DESIGN AND METHODOLOGY LAYOUT. ... 19
FIGURE 3. 2 EBAY BOLLINGER BAND VISUAL. ... 28
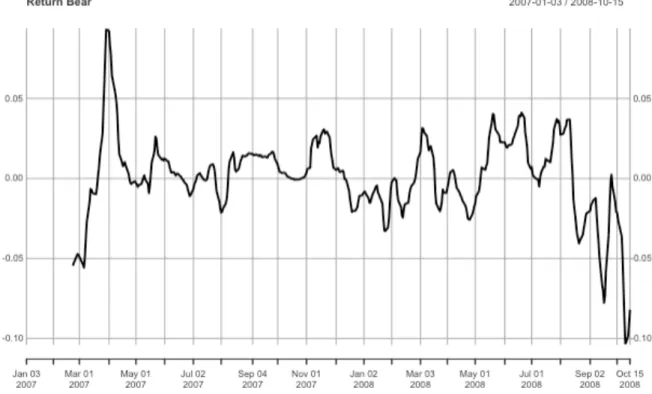
FIGURE 4. 1 BEAR MARKET OVERALL CLOSE PRICE ... 35
FIGURE 4. 2 INTEL RETURN VALUE CLOSE PRICE USING EMA. ... 36
FIGURE 4. 3 THREE M BULL MARKET CORRELATION MATRIX ... 37
FIGURE 4. 4 THREE M BEAR MARKET CORRELATION MATRIX . ... 38
FIGURE 4. 6 MTRY RANDOM FOREST ... 40
FIGURE 5. 1 SVM AND RF F1 SCORE BULL -‐ FINANCIAL SECTOR . ... 48
FIGURE 5. 2 SVM AND RF F1 SCORE BEAR -‐ FINANCIAL SECTOR ... 49
FIGURE 5. 3 SVM AND RF F1 SCORE BULL -‐ TECHNOLOGY SECTOR ... 50
FIGURE 5. 4 SVM AND RF F1 SCORE BEAR -‐ TECHNOLOGY SECTOR. ... 50
FIGURE 5. 5 SVM AND RF F1 SCORE BULL -‐ HEALTHCARE SECTOR. ... 52
FIGURE 5. 6 SVM AND RF F1 SCORE BEAR -‐ HEALTHCARE SECTOR . ... 52
FIGURE 5. 7 SVM AND RF F1 SCORE BULL -‐ INDUSTRIAL SECTOR. ... 53
TABLE OF TABLES
TABLE 2. 1 TECHNICAL INDICATORS ... 11
TABLE 2. 2 CONFUSION MATRIX . ... 16
TABLE 2. 3 CONFUSION MATRIX DEFINITIONS ... 17
TABLE 2. 4 PRECISION, RECALL, AND F1 ... 17
TABLE 3.1 STOCK LIST. ... 24
TABLE 4. 1 FINANCIAL SECTOR -‐ SVM AND RF RESULTS ... 42
TABLE 4. 2 TECHNOLOGY SECTOR -‐ SVM AND RF RESULTS ... 43
TABLE 4. 3 HEALTHCARE SECTOR -‐ SVM AND RF RESULTS ... 44
TABLE 4. 4 INDUSTRIAL SECTOR -‐ SVM AND RF RESULTS ... 45
TABLE 5. 1 RECALL SCORE FOR SVM AND RF ... 55