John Kuriakose SET Labs, Infosys Technologies
Pune, Maharashtra, India
Software Engineering involves the representation and translation (concretization) of knowledge from mental models to executable language elements.
In this paper we report specific problems of semantic scatter and references within software engineering. The former occurs when a concept in the problem domain is represented in multiple artifacts and the latter occurs when attributes of one program element refer to the value space defined by some other element typically across artifacts. The presence of these semantic dependencies across artifacts within a software system complicates comprehension and requires special treatment. We describe semantic technology infrastructure that we developed comprising of iLLumina semantic repository, link definition concept language and PredQL query and rules language to express and reason over cross-artifact relations.
1.
INTRODUCTION
Software Engineering today is characterized today by a manifold increase in the size and scope of programs developed, geographically distributed teams and heavy use of platforms, frameworks. A software solution may have requirement documents, design artifacts, project planning artifacts, software source artifacts, test artifacts and deployment artifacts in the course of its lifecycle. Software engineering activity today also relies heavily on XML artifacts over and above the regular programming / modeling language artifacts.
In this paper we present our approach in using a description logic knowledge base to create an explicit and comprehensive representation of dependencies across software artifacts. In this process we highlight major challenges in designing and populating a comprehensive knowledge base for software engineering systems. We design the repository for generic use using a Relational database. The repository would need to reify relations, express transitive relations, n-Ary Relations and semantic links between multiple artifacts. We specifically show that certain expressive features in our syntax are not supported by standard languages like OWL for semantic / ontology descriptions. We describe our concept language - the link definition language (LDL) along with a notion of a concept selector and query language called PredQL that together define our solution to capture and analyze semantic links across software engineering artifacts. Capturing these links has a variety of applications ranging from providing active change guidance for a novice programmer, to enforcing semantic consistency across artifacts and cross artifact impact and traceability analysis.
2.
Semantic links in Software Engineering
As diverse kinds of artifacts are introduced into software systems, the problems of concept scattering and semantic cross references manifests and aggravates as the size and scope of the system increases.
2.1 Semantic Scatter
Concept or semantic scattering in simple words occurs when some concept in the knowledge realm (from problem or business domain) is represented in multiple artifacts using multiple languages. For example: An Account is a concept in banking, but within software solution there exists Account.c or Account.java, an Account.xsd, Account.xml and an Account Table. The same concept is now scattered across representations in artifacts. This problem has been referred to as feature de-localization in [7].
2.2 Semantic Attribute references
Semantic cross referencing occurs when some data-element (attribute) of an element in one artifact shares the same the same value space with some concept attribute defined in some other artifact. This is a special case of the def-use relation prevalent in software engineering – the problem here is that the definition and the reference or the use are in two separate artifacts most often in multiple languages.
The concept languages of the Kb need to support the precise formal description of these semantic attribute references.
2.3 Consequence of Semantic links
Semantic scatter and semantic references between program elements or lifecycle objects are additional form of dependencies between software elements. We further postulate that understanding software systems (program comprehension) is heavily influenced by the ability to identify the semantic links between various artifacts often in multiple languages. − These semantic links must be understood and preserved during maintenance. This is
known as preserving semantic integrity during change and is a cause for many simple yet subtle defects in software.
− Semantic links cause traditional impact analysis [11] [12] to report incomplete results of consequence since artifacts and elements affected through semantic links are missing from impact analysis tools.
− These links constitutes the implicit body of knowledge that an experienced person possesses for effective usage and maintenance of software systems. The presence of these links increases the learning complexity associated with reuse of frameworks and components. The lack of this knowledge while modifying these artifacts reduces productivity and also affects quality when a change breaks the semantic link.
3.
Key features for a Software Engineering Knowledge base
Applying semantic technology to Software engineering primarily differs from the semantic web research due to the dominating presence of structured languages and data within Software Engineering. These include Programming languages (C, C++, Java, C#, VB.Net), XML, RDBMS languages for data definition (DDL) and Query (SQL) and modeling languages like the Unified Modeling Language (UML), Business Process Modeling Notation (BPMN).
3.1 Programming Language Ontologies
Formal languages used in Software Engineering are described using a grammar that describes the structure and rules for creating valid statements in the language. The set of grammar tokens that define a language are treated as language concepts in the Ontology for that language with precise meaning.
Based on our analysis we derive a fairly comprehensive Ontology for the Java language. The next step is to transform the programs into a triple based representation integrated with the Ontological language concepts to create a knowledge base. Programs statements will be translated using instances of language concepts in the Ontology.
3.2 Knowledge Concepts within Software Engineering
Knowledge concepts represent abstract entities in the underlying business domain or the technology domain (the domain of software design and architecture). For example the notion of ‘Customer’ or ‘Account’ is required to understand the banking domain. In the technology domain we use knowledge concepts like ‘Type’ or ‘Component’ in generic sense without reference to the underlying language.
Knowledge concepts and their relations form the basis for abstract knowledge that is informally understood as expertise in some domain.
3.3 N-Ary Relations support
A knowledge base for Software engineering must have the expressivity to accurately and precisely describe the definition, decomposition and references of program elements. Some of these relations have arity greater than two and have been described by graph structures developed for representation and analysis of programs. Building a semantic store for software engineering involves translating these graphs into expressions in Ontology languages.
3.4 Transitive Role support
Most of the Java language constructs treated as Relations in the Ontology require transitive Roles support in the underlying concept language in order to express common idioms familiar to a software engineer. The ontology roles that require transitive support for
example are ‘calls’ for Method calls, ‘extends’ for Class inheritance, ‘implements’ for Interface inheritance ‘member-Of’ for describing part-Of Relations.
3.5 Partial facts and incremental knowledge
It is not always expected to have complete information in a program extracted into a knowledge base. A ‘language extractor’ is the component in our architecture performs the task of identifying and transforming program statements into facts and adding them (or updating) to the knowledge base (kb). The knowledge base is built from many extractors that are designed to identify and extract various levels of detail for a given language. One extractor may only identify the ‘caller’ and ‘callee’ in a ‘calls’ relation for performance reasons while another extractor extracts additional information like the instance objects and the named arguments for previously extracted ‘calls’ relations. The point here is that depending on the level of analysis the knowledge base could be incrementally updated with more terms on existing Relations.
4.
Previous work
Software Engineering has been a fertile ground for applying and validating semantic technology research [3] [4] [5] [6]. There have also been many previous attempts to design a Relational database schema to store RDF/Owl data [14] [15].
An important issue in applying Ontologies to software engineering is establishing the mapping from the ontological concepts and axioms to the underlying elements in the program artifacts. A previous approach [2] relies on manual annotation by a user to explicitly associate instance elements in software artifacts with concepts in the ontology. By itself this is not a viable technique considering the large number of software engineering elements.
Eichberg, Mezini et. al [1] have previously studied cross-artifact complexity within software engineering. However, they do not consider semantic technology and do not deal with semantic links. The importance of explicitly capturing links between various modeling methods (or languages in our context) for effectiveness in design of complex systems has been studied in a limited context earlier [9]. Semantic scatter is covered under previous work in semantic integration and interoperability [13]. Previous work in software engineering does not address the problems of semantic scatter and cross-references across multiple artifacts.
5.
Our Approach
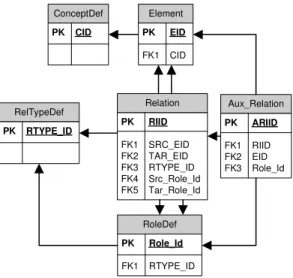
‘iLLumina’ is our knowledge base based on description logic [8]. The actual semantic store for Ontology Concepts and Instances are implemented using a Relational Database primarily for scalability reasons. Illumina may therefore be classified as an Ontology Based Database [10]. A simplified schema used within illumina is shown in Figure 1.
5.1 Role Terms in the Concept Language
Concept, Relation Type and Role (ConceptDef, RelTypeDef, RoleDef) define the Terminology Box or TBox in the knowledge base while Element and Relation describe the individuals or instances of Concepts and the corresponding Relations between these individuals in the Assertional Box or ABox.
If C represents the set of concepts and CH the subsumption hierarchy of concepts and E represents the set of individuals where each element e in E is the instance of some concept c in C. Then the set of Relations R = En where n is the order of the Cartesian product or the arity of the Relation. A relation r in R is then a tuple represented by (e0, e1, e2, ... en). T is the set of Relation Type concepts in the Ontology and TH is the subsumption Hierarchy of Relation Types such that every r is the instances of some Relation Type t.
The distinguishing feature in iLLumina is the notion of a Role Term (RoleDef) li that we introduce in order to define Relations more precisely. If r = (e0, e1, e2 , ... en ) is some relation in R, then we say that each element ei in the tuple satisfies some Role Term li. The Relation Type t is now defined in terms of Role terms as t = (l0, l1, l2, ... ln) in the Ontology. The number of Role terms in Relation Type depends on the arity of the Relation Type. Each Relation Type is now defined in terms of an ordered set of Role terms. Fig. 1. Simplified illumina Schema
tx : (l0, l1, l2, l3) - (TBOX Relation Type definition) Role terms in tx l0(c0) - (TBOX Role Policy) permits Concept c0 to fill Role l0 ex :: cx - (Instantiation) ex is a Element of some Concept cx rx :: tx - (Instantiation) rx is a Relation of some Relation type tx rx = (e0, e1, e2, e3) - (ABOX Relation) Elements e0.. e3 in rx
l0(e0) - (ABOX Role Filler) e0 fills Role l0
c1.r.c2 expresses a binary ‘R2’ relation where c1 is the domain and c2 is the range, then r is a binary relation defined as tr: (l0, l1) – here l0 and l1 are the role terms or slots for the binary relation R. Each term is assigned a name that is defined in the Ontology. Accordingly r is now expressed as R2 (“l0”, “l1”) where l0 and l1 are the names for the two Role terms in R. Role filler constraints are now defined at the Role term specifying what Concepts in the TBox are permitted to occupy or fill that Role term. N-Ary relations are also expressed in a uniform way as Rn (r0,r1,..,rn).
5.2 Modeling Attributes
Simple attributes on concept instances are now modeled as Role terms using ‘hasAttribute’ relation in Illumina. Integer, Decimal, String and Boolean are (subsumed concepts of SIMPLE_DATATYPE) Ontology concepts permitted to fill Attribute Roles.
Relation PK RIID FK1 SRC_EID FK2 TAR_EID FK3 RTYPE_ID FK4 Src_Role_Id FK5 Tar_Role_Id Element PK EID FK1 CID ConceptDef PK CID RelTypeDef PK RTYPE_ID Aux_Relation PK ARIID FK1 RIID FK2 EID FK3 Role_Id RoleDef PK Role_Id FK1 RTYPE_ID
5.3 Predicate Query Language (PredQL)
PredQL is our query language for enabling human interaction with a Ontology Based Database [10]. PredQL relies on a syntax familiar in Logic Programming where C(x) represents a unknown variable x bound to some known unary predicate C. Concepts and Roles from the iLLumina TBox form atomic unary predicates. Therefore C(x) could either represent a Concept or a Role name in the TBox. Relations translate into n-Ary atomic predicates in PredQL A binary Relation r2 is represented as r(x,y) and a ternary Relation r3 as r(x,y,z). Transitive relations are denoted by a ‘+’ suffix on the relation name.
R+(x,z) = (R(x,y) | R+(x,y) ) & R(y,z)
PredQL expressions are created by combining basic predicates in Illumina using standard logic operators ‘&’ for conjunction and ‘|’ for disjunction. We currently do not support negation. PredQL also doubles up as rule language that permits the definition of composite or derived predicates of the form Head(X) Body(X,Y) where X represents variables that are present in the head and Y represents additional variables that are present in the body. These derived predicates can be used in PredQL expressions.
For example EJB is a design abstraction in the Enterprise Java platform. We describe EJB as
JavaEJB := JavaClass(x) & extends+(x,y) & NameOf(y,“javax.ejb.SessionBean”)
where JavaEJB is now a new derived concept in the Ontology and the RHS is a PredQL expression that described JavaEJB as being some Class x that transitively extends some instance y that has a name equal to “javax.ejb.SessionBean”.
A complete treatment of PredQL describing its syntax, semantics and runtime is beyond the scope of this paper.
5.4 Selector expressions in Intentional Concept Definitions
Vast amount of data already exist within Software engineering without ontological commitments. We embed PredQL / XPath expressions into intentional concept definition in LDL as a means to annotate concepts to instances in the Kb.
We use such intentional concept definitions to define high-level abstractions from low-level program elements. This provides us with a formal basis to define and reason over abstractions.
5.5 Link Definition Language
LDL is an XML based concept language that we defined to formally express semantic links. A semantic link is defined between one target attribute of some concept and one or more source attributes of concepts. This actually forms a def-use relation between the source and target concept attributes.
Figure 2 shows the listing of a LDL program to describe struts framework. The fragment defines StrutsConfig as a sub-concept of XMLArtifact (which itself extends Artifact) and then defines ActionXML as a a partOf StrutsConfig. The shaded portions in LDL program represent semantic reference in concept attributes. It states that the ‘type’ attribute of concept ‘ActionXML’ refers to the ‘qname’ attribute of ‘ StrutsAction’ concept.
<Define concept=”StrutsAction” extends=”#Java_Class” selector=”subTypeOf+(‘org.struts.Action’)” lang=”PredQL”/> <Define concept=”StrutsConfig” extends=”#XMLArtifact”/>
<Has>
<Define concept=”ActionXML” extends=”#XMLElement” selector=”/action-mapping/struts-action” lang=”XPath” /> <Has> <Attribute name="type"> <Link><SourceDef><Attribute name=”qname” concept=”#StrutsAction” /></SourceDef> </Link> </Attribute> <Attribute name="path“/>
<Define concept="StrutsForward" selector="/forward" queryLang="xpath"> <Has> <Attribute name="path"> <Link> <MatchOne> <SourceDef> <Attribute concept="#StrutsAction" name="path"/> <Attribute concept="#TileDefinition" name="name"/> </SourceDef> </MatchOne> </Link> </Attribute> </Has> </Define> </Has> </Define> </Has> </Define>
<Define concept=”StrutsAction” extends=”#Java_Class” selector=”subTypeOf+(‘org.struts.Action’)” lang=”PredQL”/> <Define concept=”StrutsConfig” extends=”#XMLArtifact”/>
<Has>
<Define concept=”ActionXML” extends=”#XMLElement” selector=”/action-mapping/struts-action” lang=”XPath” /> <Has> <Attribute name="type"> <Link><SourceDef><Attribute name=”qname” concept=”#StrutsAction” /></SourceDef> </Link> </Attribute> <Attribute name="path“/>
<Define concept="StrutsForward" selector="/forward" queryLang="xpath"> <Has> <Attribute name="path"> <Link> <MatchOne> <SourceDef> <Attribute concept="#StrutsAction" name="path"/> <Attribute concept="#TileDefinition" name="name"/> </SourceDef> </MatchOne> </Link> </Attribute> </Has> </Define> </Has> </Define> </Has> </Define>
Fig. 2. Concrete LDL program listing for struts framework
5.6 Limitations
We do not currently deal with the problem of correctness and completeness of the link relations. These have to be manually verified. Also we understand the importance of learning from existing data in order to build the underlying domain ontology and its axioms – however this task of knowledge acquisition specifically by learning from data is not the scope of this paper. That is something we would definitely explore in the future.
The knowledge base will need to include multiple ontologies and also import existing ontologies especially existing business ontologies. This raises issues related to Ontology Merging and alignment that is also addressed manually at present.
6.
Conclusions and future work
In this paper we have described an application of semantic technology to express semantic links as relations in software engineering knowledge base. We describe a semantic repository in a relational database, a link definition language (LDL), the notion of a concept selector and our query language called PredQL that together define our unique and novel
solution to capture and analyze concept oriented relations and semantic links across software engineering artifacts.
Link relations in LDL capture semantic references between concept instances even when the underlying instances are expressed in multiple artifacts using different languages. Link relations thus address the problem of concept scatter and referencing by integrating elements across artifacts and languages within a semantic repository. They enable a level of semantic integration within existing software engineering languages and artifacts. The query language is a means to map intentional concept definition to their instances in the kb.
7.
REFERENCES
[1] Michael Eichberg, Mira Mezini, Klaus Ostermann, Thorsten Schäfer, "XIRC: A Kernel for Cross-Artifact Information Engineering in Software Development Environments," wcre, pp. 182-191, 11th Working Conference on Reverse Engineering (WCRE 2004), 2004
[2] Rodrigo Perozzo Noll, Marcelo Blois Ribeiro, “Enhancing traceability using ontologies” - Proceedings of the 2007 ACM symposium on Applied computing, Seoul, Korea, SESSION: Software engineering, Pontifical Catholic University of Rio Grande do Sul PUCRS, Porto Alegre - RS - CEP, Brazil
[3] H.-J. Happel, S. Seedorf, "Applications of Ontologies in Software Engineering", In Proc. of International Workshop on Semantic Web Enabled Software Engineering, 2006.
[4] Eberhart, A. and Argawal, S.: SmartAPI - Associating Ontologies and APIs for RAD. In: Proceedings of Modellierung (2004)
[5] P. Devanbu, R.J. Brachman, P.G. Selfridge, and B.W. Ballard, “LaSSIE - a Knowledge based Software Information System”, Comm. of the ACM, 34(5), pp. 36–49, 1991.
[6] René Witte, Yonggang Zhang, and Juergen Rilling. Empowering Software Maintainers with Semantic Web Technologies. 4th European Semantic Web Conference (ESWC 2007), June 3-7, 2007, Innsbruck, Austria. Springer LNCS 4519, pp.37-52.
[7] Greenfield Jack [et al.], Software Factories: Assembling Applications with Patterns, Models, Framework and Tools, Wiley Publishing Inc.(ISBN: 81-265-0553-2)
[8] Franz Baader, Diego Calvanese, Deborah McGuinness, Daniele Nardi, and Peter F. Patel-Schneider, editors. The Description Logic Handbook: Theory, Implementation and Applications. Cambridge University Press, 2003..
[9] Hai Wang. Semantic Web and Formal Design Methods. PhD thesis, Pg 94 National University of Singapore. 2004
[10]Stéphane Jean, Yamine Ait-Ameur and Guy Pierra, Ontologies, DataBases, and Applications of Semantics (ODBASE'2006) , Montpellier, France, Oct 31 - Nov 2, 2006.
[11] Bohner, S. A., and Arnold, R. S. An introduction to software change impact analysis. In Software Change Impact Analysis, S. A. Bohner and R. S.Arnold, Eds. IEEE Computer Society Press, 1996, pp. 1-26.
[12] “Chianti: A tool for change impact analysis of Java programs” by Xiaoxia Ren, Fenil Shah, Frank Tip, Barbara Ryder, and Ophelia Chesley. In Object-Oriented Programming Systems, Languages, and Applications (OOPSLA 2004), (Vancouver, BC, Canada), October 26-28, 2004, pp. 432-448. [13] Natalya F. Noy, Stanford University, Semantic integration: a survey of ontology-based
approaches, ACM SIGMOD Record archive Volume 33 , Issue 4 (December 2004): Special section on semantic integration
[14] Zhengxiang Pan, Jeff Heflin, DLDB: Extending Relational Databases to Support Semantic Web Queries, PSSS 2003
[15] Daniel J Abadi, Adam Marcus, Samuel R Madden, Kate Hollenbach, Scalable semantic web data management using vertical partitioning, Proceedings of the 33rd International conference on Very large databases, Vienna, Austria, 2007