Willem Toorop and Arthur van Kleef
{wtoorop,akleef}@os3.nl March 29, 2010
Abstract
In this report the scalability issues of existing Software Distribu-tion methods are addressed. Gossiping protocols are examined as a potential means to overcome those issues. A case study for Ubuntu distributions is done by simulations.
The research question this report tries to answer is: “Can gossiping protocols be used in software deployment architectures in order make it more scalable and robust?”
Contents
1 Introduction 3 1.1 Deployment . . . 3 1.1.1 Replication . . . 3 1.1.2 Staging . . . 4 1.1.3 Directed broadcast . . . 4 1.2 P2P Deployment . . . 4 1.3 Other Issues. . . 5 1.3.1 NAT Traversal . . . 5 1.3.2 Notification Services . . . 5 2 Gossiping 6 2.1 Peer Sampling . . . 6 2.1.1 Cyclon . . . 7 2.1.2 PuppetCast . . . 72.1.3 Arrg & Nylon . . . 8
2.2 Semantic Proximity . . . 9
2.2.1 Vicinity . . . 9
2.2.2 T-MAN . . . 9
3 Contribution 10 3.1 The simulation . . . 10
3.1.1 Cyclon&Vicinity . . . 10
3.1.2 Ubuntu . . . 10
3.1.3 Distributing the Packages . . . 11
3.1.3.1 Using popcon statistics to distribute packages . . . 12
3.1.3.2 Distributing with sections . . . 13
3.2 Evaluation. . . 15
3.2.1 Proximity . . . 15
3.2.2 Disseminating packages . . . 15
3.2.3 Relative and absolute clustering . . . 20
3.2.3.1 Rarity based proximity . . . 21
3.2.3.2 Privacy . . . 23
4 Conclusion & discussion 25
5 Future research 26
1
Introduction
One of the important tasks in system administration is software deployment. Updates to solve security vulnerabilities, updates to resolve reliability issues, new software packages, all of which need a solution to be deployed to mach-inces. Depending on the size of an organization, different solutions exist that aim to deliver the software to the machines needing them. However, a lot of these solutions have serious scaling issues and thereby delay the time it takes to deploy software. In this report we will will evaluate the different deployment solutions that exist today and discuss the complications each has (where applicable). After that we will present our motivation to inves-tigate the suitability of a gossiping protocol for software deployment and describe the research we conducted.
1.1 Deployment
Classic approaches in software deployment are based on the client- server model, in which a server runs a notification daemon informing clients, run-ning an agent, that new software is available. Depending on the implemen-tation, the software either is send to the client by the server, or it is retrieved from the server by the client. It is not hard to imagine that when the num-ber of clients increase, so does the load of the server that is serving all the clients. In order to handle the load in large installations different measures can be taken.
1.1.1 Replication
A simple measure to handle more clients is to make use of replicated deploy-ment servers. In this setup the replicated servers are located closer to the workstations that need service, thereby decreasing the load on the former central single deployment server as well as reducing upstream network link utilization.
While this does solve the issue described earlier, it also introduces a new issue. By adding more servers, the deployment architecture will in most cases become more complex and harder to operate. Different groups of workstations have to be configured to use a specific deployment server.
Another issue with this solution is that software is not deployed all the time, meaning that at moments when there is nothing to deploy, the de-ployment server will be wasting electricity and thus money. This is more commonly refered to as under utilization. Also, this solution is not very robust when sudden flash crowds occur. Although these are less likely to occur on an internal company network, it can happen that a large software package has to be deployed, for which the replicated server has not enough available resources.
1.1.2 Staging
Another situation we encountered had configured their deployment software to send out software packages to clients needing them in an delayed fash-ion. What they did was configure small groups, about 25 stations, and sequentially deploy the packages to all the configured groups.
Another approach is taken in Microsoft’s Windows Software Update Ser-vices deployment solution. Each Microsoft Windows PC runs an agent that contacts the deployment server at predetermined intervals. To prevent that in large installations all these agents contact the deployment server at the same time, the agent deviates to as much as 30 minutes from the configured interval.
The title of this approach already tells the main disadvantage of this solution, it can delay the deployment process considerably, certainly in large installations where thousands of clients need to be maintained.
1.1.3 Directed broadcast
A solution to make software deployment more decentralized is found in [1]. In this setup when a client needs a software package, it will send out a subnet-directed broadcast asking its neighbors if they have the required software package. If so, the neighbor will respond by sending an acknowledgement. After that the requesting client will open a connection and retrieve the package via unicast.
This solution assumes that clients residing on the same IP network are likely to have the same packages installed. If none of the clients has a requested package, it will be retrieved from a central deployment server. As the title already suggests, this solution only scales to the size of the IP subnet a client is participating in.
1.2 P2P Deployment
A step towards decentralization in software deployment was taken by Hogeschool InHolland [2]. Their solution incorporates the use of Bittorrent [3]. By mak-ing use of the aggregated resources that all clients in the network offer, they were abled to scale down from 20 deployment servers to only two and mini-mized deployment time to approximately 6.500 workstations from four days to only four hours.
On the global scale the APT-P2P[4] is a project that aims to reduce bandwidth cost of Debian’s package repositories by letting end users down-load packages from each other. In APT-P2P Debian’sAdvanced Packaging Tool program is extended with a proxy that intercepts requests to retrieve packages from a client and redirects these to a swarm of peers that partic-ipate in a Distributed Hash Table. DHTs require each data item to have a unique identifier, therefore all a peer needs to do to retrieve a data item is
lookup the hashed value of a file in DHT. After identifying the peers that are storing the requested file, the file is downloaded from them.
1.3 Other Issues
With the aforementioned solutions for software deployment, especially the P2P ones, overloading of central and replicated deployment servers can be prevented in most cases. However, there are still some outstanding issues that are not accounted for in these. We will briefly discuss them.
1.3.1 NAT Traversal
Clients working from home that are connected to the Internet through Net-work Address Translator (NAT) devices are often hard to manage for system administrators. It is hard to communicate with those clients without making configuration changes on the clients networking equipment.
In C/S architectures this issue is often tackled by letting the client open a connection towards a deployment server andpull data from the deployment server. In P2P each participating client is required to act as a server as well. This poses a threat to the success of P2P based deployment solutions running on the Internet.
1.3.2 Notification Services
How does a client know that it needs a new package, or how does a deploy-ment server know that its clients need a new package? The aforedeploy-mentioned solutions all rely on some entity that decides when a client is up-to-date. To determine if a client is up-to-date, interaction with a central (possibly replicated) server is required, either push or pull. In terms of bandwidth this is not likely to be a major outstanding issue. But to decide if a client needs a package, or which clients need a package, can become a daunting task that may overload a server.
2
Gossiping
Gossiping (or epidemic) protocols[5, 6] are communication protocols that resemble the way rumours spread in real life, hence the name gossiping. The premise in these protocols is that when a process P hears news from Q, it will gossip this news on to process R. In its most basic form each client running the gossip protocol maintains complete knowledge of all other participating clients in a network. To disseminate data, a client periodically selects a client to exchange data. Because all clients in the network do the same thing, new data (information) can be disseminated with very high probability.
In large networks however, it can become infeasible for each participat-ing client to maintain information of each other client in the network. To overcome this issue, clients can be configured to maintain apartial view of the network, that is, each client has a set of neighbors (a subset of the total network). In this configuration besides disseminating data items, also links to neighbors are continuously and randomly exchanged between neighbors. Because each client has a continuously changing set of neighbors, there is no need anymore to maintain complete knowledge of the network.
Spyros Voulgaris presents in [7] a list of advantages of gossip protocols: Scalability Gossip protocols inherit scalability from the fact that each node
performs a fixed set of operations, at a fixed rate independent of the network’s size.
Fault-tolerance and robustness Gossip protocols are resilient against large-scale failures and node churn.
Symmetry Each node is equal, no single node failure can have a significant effect on the operation of the network.
Graceful degradation When large-scale failures occur, performance, func-tionality, and reliability do not drop rapidly.
Adaptability Gossiping overlay networks are very adaptable to network changes and dynamic environments.
Elasticity Since each participating node is both using and contributing resources, load and resources grow aside.
We believe that these characteristics are a perfect match in solving the earlier outlined issues in software deployment.
2.1 Peer Sampling
In an unstructured P2P network each client maintains a partial view of the network, one of the challenges is to keep the complete network of clients
connected. When a large set of clients suddenly leaves the network, there is a chance that parts of the remaining network become disconnected (clustered) from the rest of the network. To implement a network that continuously exchanges neighbors an effective algorithm is needed that keeps the network connected at all times.
2.1.1 Cyclon
The first gossip protocol we investigated is Cyclon[8]. Overlay networks
in which nodes are randomly connected have the property to be highly re-silient against large-scale failures. Cyclonis a gossiping protocol that aims
to organize overlay networks that resemble random connected networks. During gossipingCyclonimplements what is calledenhanced swapping,
this means that a node does not randomly select a peer from its partial view to gossip with, insteadCyclonimplements anage metric for each neighbor
that is in a node’s partial view. When selecting a neighbor to gossip with, the one having the highest age is chosen. This is done for two reasons, firstly it prevents that neighbors that were part of the network at some point, and later left the network, are not passed around as usable neighbors forever. Neighbors in a peers partial view are always to some degreefresh. Secondly, it makes sure that there is an even distribution of the number of links to every node in the network, every node is equally well connected.
2.1.2 PuppetCast
While the peer sampling service presented in Cyclon generates good
ran-dom overlay networks that are resilient against large-scale failures, it does not account for malicious nodes that willingly pollute the partial views of neighbors. Because of the very nature of a gossping protocol, it requires only a few malicious nodes sending the same partial view to neighbors, be-fore those neighbors will no longer receive random links to neighbors. This malicious behavior causes the overlay network to cluster into small disjoint networks.
PuppetCast[9] is a gossiping protocol that prevents that malicious
nodes can choose which links to neighbors to gossip. This is done by re-placing the singe view a node had in for exampleCyclon, with aninternal view that is used to select a neighbor to gossip with, and an external view
that is assigned by atrusted authority. The neighbors that a node receives during gossiping are only accepted when it can verify that the links were assigned to the sending peer by a trusted authority (by means of public key cryptography). This prevents that malicious nodes can choose for them-selves which (malicious) links to pass around.
are used by nodes that leave the network, to inform the trusted authority and neighbors from it external view, that it is no longer available. The neighbors that receive a DC include this in their external view and pass it further on to be included in the external views of other peers. By doing this, the trusted authority does not need to update the external view of each node every time a node leaves the network.
Each node is also required to periodically refresh its external view with the trusted authority, this prevents that links that were not removed by a DC exist too long in the network (i.e. a crashed node, or malicious peers not sending DCs).
2.1.3 Arrg & Nylon
Most gossip protocols assume each participating node in a network to be directly connectable. However, on the Internet a lot peers are connected through Network Address Translators (NAT). Because of this, networks that run gossip protocols that do not account for nodes that are connected through NAT devices, tend to cluster and do not preceive the complete network. We found two gossip protocols that each implement a different method to overcome the issue of non-connectable nodes in an overlay net-work,ARRG and Nylon.
ARRG (Actualized Robust Random Gossiping)[10] introduces the use of
aFallback Cache (FC). It serves as a backup for the normal cache each node maintains. At each successful gossip to another peer, this peer is added to a node’s FC. With this cache on its side, a node selects a target from its normal (partial) view to gossip with. If it fails to contact the selected node, it will fallback and select a target from its FC. Since it has successfully gos-siped with a peer from its FC before, chances are high it will be abled to do so again. The FC maintains a set ofreachable peers. In [10] it is shown that this approach turns out to be very robust in networks with lots of nodes connected through NAT devices.
Nylon[11] establishes connectivity between NAT nodes by creating chains
ofRendez-vous Peers (RVP) that forward OPEN HOLE messages to nodes behind NAT devices, this is only done for neighbors that are selected to gossip with. It works as follows:
1. P1 shuffles withP2, after hole punching to P2,P1 and P2 can directly
communicate with each other. And they also become RVP for each other.
2. P2 shuffles with P3, before it does it first performs hole punching
3. P3 shuffles with P4 in the same way as the other peers did, and passes
a reference toP1.
There now is a chain available that can be used by P4 to perform hole
punching towards P1. This is done by sending aOPEN HOLE message to
P3, which forwards it to P2, which forwards it to P1. Essentially each node
maintains a routing table that specifies through which RVP to send mes-sages to reach a Pi.
Destination RVP TTL
Pi Pj 100
Pi * 100
The routing table includes a Time To Live because with Nylon, RVPs
do not proactively refresh holes.
2.2 Semantic Proximity
In large-scale overlay networks there might be characteristics of a node, or similarities between nodes that make a neighborP favorable over neighborQ to gossip with. For example if nodesP andQhave a low latency connection to each other. In the case of software packages we imagine that it might be better to let a node P gossip with a node Q when the two have a lot packages in common.
2.2.1 Vicinity
Vicinity[12] is a gossip protocol that constructs an extra layer on top of an
unstructured layer, that preserves the randomness in the network and keeps everyone connected in an even distributed manner. Vicinity operates in
roughly the same way asCyclon, except for that it now also records aprofile
for each neighbor it comes across. It uses a selection function S(k, P, D) that is used when two peers exchange neighbors to each other. Each node P selects, based on the profile of each peer descriptorPjdesc in Dof P, the kbest neighbors to gossip on to Q. By performing this selection of peers, a new separate view is created on each node, that represent the peers a node P prefers to maintain a relationship with.
2.2.2 T-MAN
T-MAN[13] is another gossiping protocol that implements aRanking Method
to determine which peers are best to be included in a node’s view. It shows similarities toVicinity. The big differences are that inT-MANevery node
can help any other node to find its ideal neighbors. Vicinityis not abled to
do this and relies on a lower layer gossiping protocol that provides random links to neighbors. FurthermoreT-MAN somewhat converges into a static
state, it tries to find the best links for a given node, and once these are found they remain in a node’s view. InVicinity all links to neighbors are continuously refreshed, which results in relatively good links to neighbors, but not static.
3
Contribution
In this section a simulation of a gossiping overlay-network using the Cy-clonand Vicinityprotocols is presented to study how gossiping software
packages could operate in a real-world situation. Statistics of the Ubuntu popularity-contest are used to deploy simulated Ubuntu installations on the nodes in the overlay-network. The success of three different proximity func-tions are evaluated by analyzing how well all packages that were updated in 2009 would disseminate. The first function bases the proximity of the nodes on the software packages in common. The second function does the same, but gives rare packages a higher weight. The third function is not based on packages in common, but bases proximity on the “weighted” amount of packages on each node, giving rarer packages a higher weight.
3.1 The simulation
3.1.1 Cyclon & Vicinity
Cyclon & Vicinity offer a simple and easy way to build an
overlay-network for gossiping. The two-layer approach, whereCyclon guarantees
a randomly, well-connected (unpartitioned) overlay-network, greatly simpli-fies the construction of a proximity function inVicinity, the protocol that
is responsible for the structure in the network. Because of the simplicity of implementation, due to the modularity gained by the clear separation of concerns, we have chosenCyclon &Vicinityas the protocols to base our
simulations on. Besides the original papers[8,12] we highly recommend the academic dissertation[7] on the subject. It has functioned as more then a guideline to us.
3.1.2 Ubuntu
To better determine how gossiping would benefit software distribution, we have build a simulation of nodes with Ubuntu Linux installations. We have chosen Ubuntu installations for several reasons:
It uses the Advanced Packaging Tool Ubuntu, like most other Linux flavors, uses open source software for it package management and dis-tribution systems. Information on the workings and usage of those systems is, by nature of open source, very accessible.
It has already a peer-to-peer software distribution solution: Apt-P2P With normal APT, the list of available and update-able software pack-ages, as well as the packages themselves can be downloaded from repos-itories (and their mirrors) that are made available by the Linux dis-tribution maintainer. Apt-P2P takes the tracker-less BitTorrent ap-proach to relief those centralized repositories of the upload burden. The cost of uploading the packages is shared among the downloaders of those packages in a peer-to-peer fashion.
We envision that Apt-P2P could be extended with gossiping facilities for spreading the news of software updates; potentially spreading the actual software package along with the gossip.
Note that Apt-P2P is originally developed for Debian, but widely adapted by distributions based on Debian, such as Ubuntu.
Ubuntu has a big community Ubuntu is a very popular Linux distribu-tion. Gossiping protocols work good in large installations.
Statistics on what packages are installed are available Ubuntu has its own version of the Debian Package Popularity Contest. This system gathers statistics on the most used packages. The statistics are based on the anonymized reports send by users that chose to do so by in-stalling thepopularity-contestsoftware package.
Ubuntu makes it even more easy for users to participate by providing a check-box in the graphical interface for the management of software sources.1 This is reflected in the number of unique installations the Ubuntu popularity-contest has aggregated information on: 1,499,579 at the time of writing opposed to 91,084 installations in the Debian popularity-conteststatistics site.
We assume that the larger number of installations, but even more the easy manner in which one can participate with the popularity-contest with Ubuntu, would give the most realistic representation on the distribution of software packages installed world-wide. Therefore we have taken the data from the Ubuntu popularity-contest as the basis for distribution packages on the nodes in our simulations.
3.1.3 Distributing the Packages
Ideally we would have liked to have a sample of anonymized popularity-contest reports. But, even though anonymized2, the reports contain sensitive
1
From the “System” menu choose “Administration”→“Software Sources” and select the “Statistics” tab
2
Each popularity-contest host is identified by a random 128bit uuid (MY HOSTID in
data. The FAQ on the popularity-contest website clearly summarizes the issues:
1. Someone who knows that you are very likely to use a par-ticular package reported by only one person (e.g. you are the maintainer) might infer you are not at home when the package is not reported anymore.
2. Unofficial and local packages are reported. This can be an issue due to 1) above, especially for custom-build kernel packages.
For Debian, the individual reports are therefore only available to Debian developers3. For Ubuntu it is not clear to whom or where the reports are available.
The reports were not available to us during the course of the project. 3.1.3.1 Using popcon statistics to distribute packages The ag-gregated information contains, among other things4, on how many hosts the package is installed. Simply distributing packages according to these numbers over the nodes in the simulated overlay-network would be very naive; Packages are typically, but not always, dependent on other packages, which in turn might be dependent on other packages etc. Ignoring those dependencies would lead to impossible installations and a very unrealistic representation of a Ubuntu population.
We have made several attempts to extract realistic populations from the aggregated information, but none of them have been completely satisfying. We have tried sorting the packages by their occurrences, and started deploying the most common packages first. For each package, we then looked at the existing packages on a representation of a part of the population (The representation being a set of packages and a number indicating the size of the population that would have that set of packages installed). The idea was to see if a representation could accommodate a package - meaning that the for the package necessary dependencies were already available, or that the package had no dependencies and thus could be installed as well - and then create more possible representations based on the fit. It turned out that if every option is evaluated in this way, there is an exponential growth of possible representations, many of them very unrealistic.
We also tried ordering the packages by the amount of packages they depend on, starting with the packages that had the most dependencies, and evaluate which population representations could be constructed from the
3The popcon dataset is atgluck.debian.org:/org/popcon.debian.org/popcon-mail/popcon-entries 4
fits with existing representations. But it turned out impossible to determine how a new, on the dependencies based set of packages, should be divided over the existing representations.
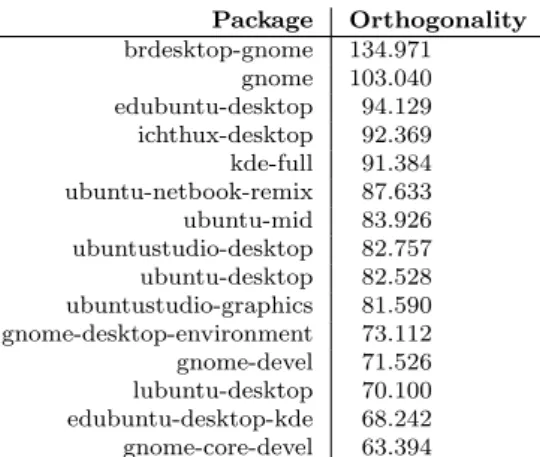
From these two attempts we learned that we had to have a way to de-termine how much a package (with all its dependencies) would overlap with other packages. For this reason we tried to find the packages that have the largest set of dependencies that are most orthogonal from other sets of pack-ages, meaning that the dependent packages are the least likely to occur in the dependency-trees of other packages. The most orthogonal packages should then be tried to deploy with the least overlap with other most orthogonal packages. Package Orthogonality brdesktop-gnome 134.971 gnome 103.040 edubuntu-desktop 94.129 ichthux-desktop 92.369 kde-full 91.384 ubuntu-netbook-remix 87.633 ubuntu-mid 83.926 ubuntustudio-desktop 82.757 ubuntu-desktop 82.528 ubuntustudio-graphics 81.590 gnome-desktop-environment 73.112 gnome-devel 71.526 lubuntu-desktop 70.100 edubuntu-desktop-kde 68.242 gnome-core-devel 63.394
Figure 1: Most orthogonal packages To determine what the most
or-thogonal packages are, we gave each package a value based on the num-ber of other packages that havethat
package in their dependency tree. A package that has no other package dependent on it would get a value of 11 = 1. A package with just one other package that depends on it, a value of 12. A package with two packages dependent on it 13 and so on. The most orthogonal packages could then be determined by taking the sum of those values of the pack-age plus all its dependencies. Al-though it still was impossible to find
the right fits in a way with which the possible representation would not grow exponentially, the outcome of what the most orthogonal packages are was quiet interesting.
In figure 1 the top fifteen most orthogonal packages are displayed. It is clear that the most orthogonal packages are the ones specifying the dif-ferent flavors of Ubuntu. More specifically, they mostly are the so called metapackages.
Metapackages are packages that do not themselves contain actual soft-ware, but simply depend on other packages. They allow to select the in-stallation of an entire family of software, by only selecting the appropriate metapackage. Metapackages are in the Ubuntu packaging system organized in a special section called metapackages.
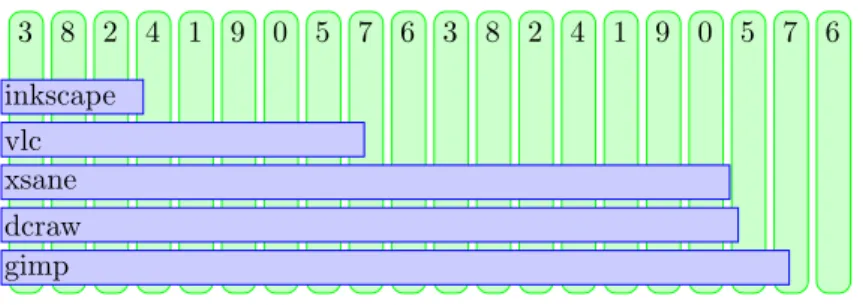
3.1.3.2 Distributing with sections Ubuntu packages (like Debian’s) are organized insections. Each section represents a set of software that serve a similar purpose. The metapackages, for example, are all in a separate
3 8 2 4 1 9 0 5 7 6 3 8 2 4 1 9 0 5 7 6 gimp dcraw xsane vlc inkscape
Figure 2: Deploying packages from section graphics on a randomly shuffled list of nodes
section. But also, packages for the Gnome Desktop Environment are placed in section gnome, packages for K Desktop Environment are in section kde, packages for TEX are in section tex, etc.
We assume that installations that have packages of a certain section are more likely to have other packages from that section as well. For example, people interested in the TEX typesetting software, are likely to have more or less packages from that section. But, the interest in TEX is probably not related to the interest in applications for handling audio.
To reflect this in the packages installed on the simulation population, we used the following approach:
We will deploy packages on a list of nodes of a certain size. For each section:
Randomly shuffle all nodes in the list
For each packages in the section, starting from the most common package until the least common package:
In case the package is not a metapackage:
Install the package and all its dependencies on the nodes in the list in sequential order starting from the first node. Otherwise:
Install the metapackage and all its dependencies in se-quential order starting from the position where the last package installation ended.
When using this approach, we ran out of packages deeper in the de-pendency tree. From this we can conclude that at least the metapackages are deployed too orthogonal. In real-life they would overlap more. The se-mantic diversity of software packages on the nodes in our simulation is thus larger than in real life. We should take that into account when evaluating proximity functions.
On the other hand, for example language-packs are very likely to be installed next to each other in the real world. With our method, some nodes having the least-common language pack installed (which happens to be the language pack for Inuktitut, the language spoken by the Inuit Eskimo’s in Canada), will also have all other language-packs from the same section installed; including the second least common language pack (Tswana, the language spoken by the people of Botswana). This is clearly not a very realistic situation. The same holds for other packages, like for example web-browsers; One would expect a preference for one or two, but not a preference for the most rare ones.
3.2 Evaluation
3.2.1 Proximity
With the nodes populated with the aforementioned method, we ranCyclon
and Vicinity with the proximity function: the amount of packages two
nodes have in common. With this function, theVicinityprotocol let nodes
select the nodes which have the most packages in common with them as their neighbors.
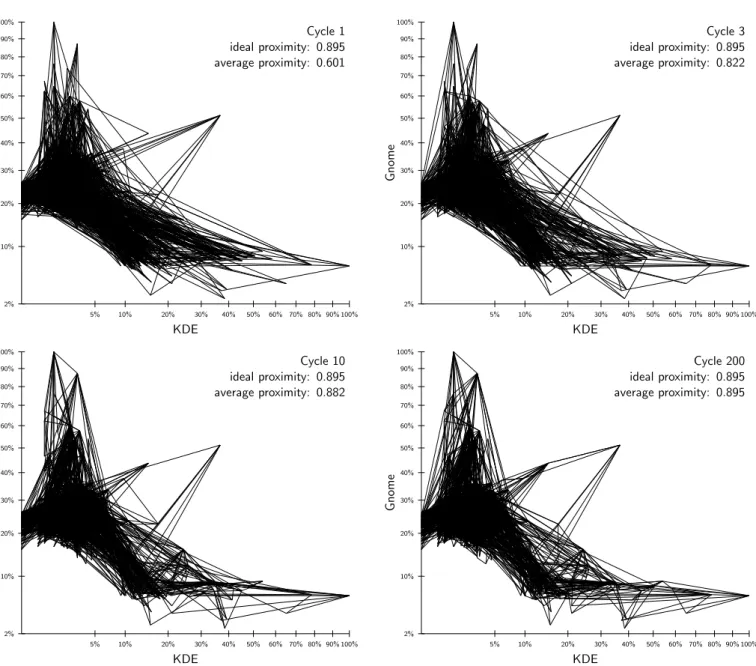
The effect is visualized in figure 3. The picture shows 1000 nodes build-ing semantic clusters by runnbuild-ing Vicinity. Each vertex represents a node
having a certain percentage of the available KDE packages (determining its position on the X-axis) and a certain percentage of the available Gnome packages (on the Y-axis). The edges are the links to the three best neighbors from theVicinity view. We have tried stretching out the lower left corner
of the graph by using a square-root scale, because the large amount of nodes having the more common Gnome and KDE packages. It can clearly be seen that Vicinity structures the overlay network, at least for the nodes with
the more rare KDE and Gnome packages in respectively the lower-right and the upper-left corner of the graph.
3.2.2 Disseminating packages
Disseminating information is the classic gossiping application. It is a form of group communication that is not dependent on the type of network used, un-like ethernet broadcasting, and does not require functionality embedded in the equipment that makes out the network, like IP-Multicasting. It is more similar to the application level broadcasting technique: flooding, but allevi-ates the demand on the network by not sending a message to all neighbors immediately, but to a randomly selected subset of neighbors periodically. With gossiping, hosts only need a partial view on the network they wish to broadcast a message to making them highly scalable. However, due to the probabilistic nature of gossiping, a message may fail to reach the complete
2% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 5% KDE Gnome Cycle 1 ideal proximity: 0.895 average proximity: 0.601 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 2% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 5% KDE Gnome Cycle 3 ideal proximity: 0.895 average proximity: 0.822 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 2% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 5% KDE Gnome Cycle 10 ideal proximity: 0.895 average proximity: 0.882 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 2% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 5% KDE Gnome Cycle 200 ideal proximity: 0.895 average proximity: 0.895 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
network. The first description of disseminating information using gossiping techniques was for distributed database replication[14].
The development of building structured overlay-networks from unstruc-tured ones - likeVicinitydoes - makes gossiping also suitable for
application-level multicasting that does not require multicasting-functionality in the routers.
We envision the gossiping approach for disseminating software packages as follows: A package maintainer has a new version of the package he main-tains and wants to distribute it to all hosts that have that package installed. He signs the package and does an official installation of the update on his own host. The host now starts to disseminate the news of the update (and possibly the update itself) in the following way:
1. The host selects all the peers from the proximity (Vicinity) view (that are likely to be interested in the update) and just a few peers from its random (Cyclon) view.
2. The host starts a gossip transaction with the selected peers, telling them there is a new version of the package, and that it has the package available.
3. The contacted peers will download the package from the host if they were interested and start gossiping themselves in the way described by steps 1 and 2.
In a real world situation: It is possible that a peer receives information on an update of a software package that it has installed, but that the peer that initiated the gossip doesn’t have the package itself. In that case the peer will wait a random amount of time, before it will try downloading the package in another way, after which it will start spreading news on the update as described in the steps above.
We have simulated this scenario with static already converged overlay-network. We did not keep the network running Cyclon and Vicinity
exchanging links, but simply let the disseminating process described run on an already converged network. We can do this because the overall properties of the network will remain the same, as also is argued in Section 6.6 of Spyros his dissertation[7]. Note, that this would not hold if we would have a prox-imity function which outcome would change with the news spread. If, for example, a package would be weighted according to the frequency it changed in the past, this approach would not work. After each dissemination, the network would have to be reconverged.
In our simulation, we also did not perform the actions described in the “real world situation” case. We wish to evaluate the effectiveness of the algorithm which can be measured by evaluating the received software
package interested downloaded waiting % reached hops overhead azureus 70 69 1 99.800 6 12471 perl 988 986 0 99.800 6 66 opencity 11 11 0 99.800 8 13804 wesnoth 31 31 0 99.800 6 13410 gwc 5 5 0 99.900 7 13859 geany 30 29 1 99.700 6 13305 synce-trayicon 4 4 0 99.800 6 13933 mpd 9 9 0 99.700 6 13708 linux 7 5 2 99.800 7 13825 kubuntu-default-settings 140 139 0 99.900 6 12615
Figure 4: The first few lines of the gossiping log. n= 1000, `vic = 10, `cyc= 5
packages by hosts interested in them. In the “real world situation” case, all peers interested would eventually have the package installed. Therefore, in our simulation, we alter this course of action into the following:
In the simulation: It is possible that a peer receives information on an update of a software package that it has installed, but that the peer that initiated the gossip doesn’t have the package itself. In that case the peer will continue spreading the news on the update. The host might contact a peer thatdoes have the update available, or the host might be contacted again by a host that has the update available. In both cases the host will then download it from that peer.
The simulation was run by replaying all updates that took place in 2009. To realize this the changelogs of all packages were downloaded from
http://changelogs.ubuntu.com. The changelogs are formated in a well
definedstandardwhich enabled us to automatically parse the changelogs to generate the distribution-wide changelog for the year 2009.
In figure 4 the log of the dissemination of the first ten packages of a simulation with 1000 nodes is shown. AVicinitygossip length of 10 and a Cyclongossip length of 5 were used. The proximity function is the number
of packages two nodes have in common. Each log-line shows the results when the dissemination is completed, meaning that all nodes that have heard the news on the update, have gossiped it to their neighbors. The meaning of the columns is as follows:
package The package that is updated.
interested The peers that have the package installed and are interested in acquiring the update.
downloaded The peers that received the package during the gossip. waiting The peers that have heard the news, but have not gossiped with a
package interested downloaded waiting % reached hops overhead linux 7 5 2 100.00 5 18822 nspluginwrapper 115 114 1 100.00 5 15747 smplayer-themes 36 35 1 100.00 5 17470 praat 4 2 2 100.00 5 18954 blender 79 78 1 100.00 5 16563 qemu 39 38 1 100.00 5 17610 virtualbox-ose 66 65 1 100.00 5 17396 asterisk 4 2 2 100.00 5 18967 doxygen 24 23 1 100.00 5 18274 zsh 13 7 6 100.00 5 18806
Figure 5: Gossips in partitioned clusters. n= 1000, `vic = 10, `cyc= 10
% reached The percentage of the total overlay-network that has received the message.
hops The number of hops it took to complete the dissemination. On the first hop only one node (the initiator of the update) gossips to exactly `vic+`cycof his neighbors. The second hop all those neighbors in turn gossip the information to at most `vic+`cyc of their neighbors from which the node has not heard the news. And so on.
overhead The number of times, the news was gossiped to a node that was already aware of the update.
Analysis of the “% reached”, “hops” and “overhead” columns is not in the scope of this report and has already exhaustively done in previous research[7].
Looking at the “interested”, “downloaded” and “waiting” columns, a few things stand out. The dissemination process is quite successful, but not always. Sometimes the package is not downloaded by all nodes that were interested in it. As all nodes gossip to all their neighbors in the Vicinity
view (Vvic =`vic), the only explanation is thatVicinity’s neighbor selection - that is based on the proximity function - resulted in more than one cluster for the package.
For the packages where waiting=interested − downloaded, we know for sure that theVicinityoverlay-network is partitioned.
But whenwaiting < interested − downloaded, as is the case with packages perl and kubuntu-default-settings we can not be sure; The news did not reach the complete network. The nodes that did not show up “waiting” alsohave to be the of the “unreached” nodes. Those nodes might well have links to the nodes in the “interested” cluster in their Vicinityviews.
In figure 5, a selection of log-lines of a new simulation are shown. In the new simulation the `cyc was increased to 10 to make it highly prob-able that disseminate would reach the whole network. Only log-lines where downloaded < interested are shown. We can see that indeed now
waiting=interested − downloaded holds for all disseminations and that in those casesVicinitylinks form at least two clusters.
With those result in mind, we can conclude that the success of the gos-siping software packages concept can be determined upon two different ways the semantic clustering could be partitioned: relative and absolute. Relative The gossiping protocol evaluated so far creates directed graphs.
When a node P has another node Q in its Vicinity view, this does
not mean that the other node Q has node P in its Vicinity view
as well. More generally, breath-first traversing the neighbors (with a package in common) from a single node, does not necessarily reach all nodes with the package, even though those nodes could be part of the cluster because they link to it with nodes intheir Vicinity view.
The nodes that make up a semantic cluster from the viewpoint of a single node, is thusrelative to the perspective of that node.
With our dissemination algorithm, nodes that are not in the relative
perceived cluster of the node initiating the dissemination, but whose nodes have links pointing to that cluster, will eventually download the package in a gossiping transaction when contacting one of the nodes in the cluster that was perceived by the initiator. But, it is very much dependent on the news reaching the complete overlay-network (and thus on the quality of Cyclon), otherwise such a node might not
even hear about the update.
Absolute When the semantic overlay is partitioned, butall nodes in a sin-gle cluster see only nodes fromthatcluster in theirrelativeperspective, we will call the partitioningabsolute.
All nodes in the separate clusters in theabsolute partitioned semantic overlay have only links to nodes in their own cluster.
For the dissemination process this means that a node in a absolute
cluster will never download a package gossiping with a neighbor, if the initiator of the dissemination is not also in the sameabsolute cluster. 3.2.3 Relative and absolute clustering
When we have insight in how the overlay network for different proximity functions are relatively and absolutely clustered, we will be able to evaluate the success of the proximity function. To do this, we looked at each package in the change-log for updates with Ubuntu in 2009, and for each package we evaluated what nodes are in the relative cluster for each node that is “interested” in the package. The averagerelative cluster size divided by the total number of nodes “interested” in the package is the chance a node can download a package receiving the news on the update.
Then, for each package, we merged the relative clusters with nodes in common, as such producing the set of absolute clusters. The length of those clusters divided by the total “interested” nodes give the chance for each individual peer to be able to download the package during gossiping (directly or not). The average of those chances is then the changeanynode on average has on downloading the package in a gossiping transaction for that package.
It made sense to us that those values for a package relate to the number of nodes interested in the package. For rare packages the clustering plays a more important role than for packages that are more commenly deployed.
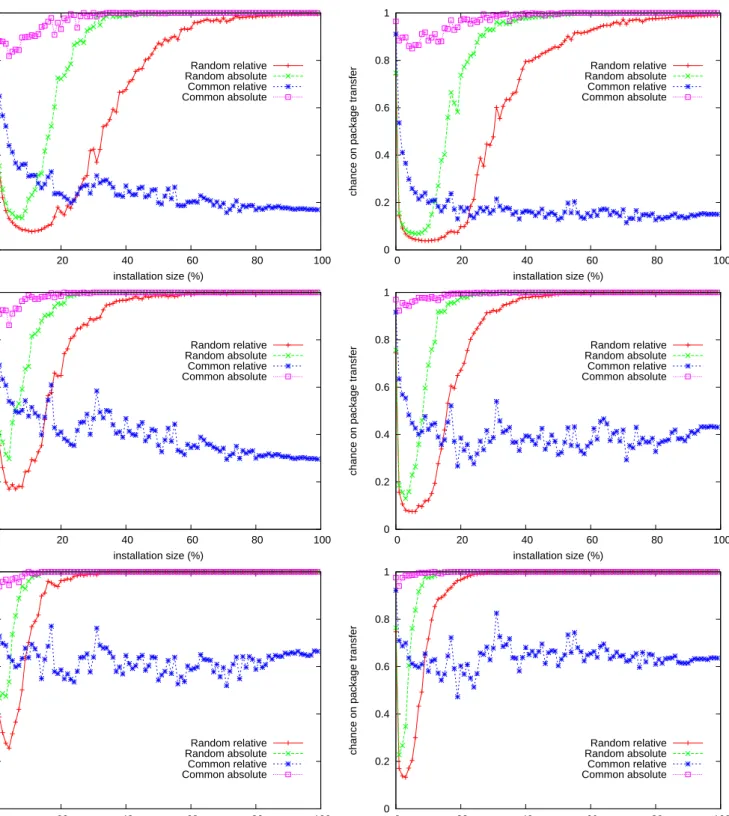
In figure6is shown how the relative and absolute chances on download-ing a package directly usdownload-ing gossipdownload-ing are distributed among the occurrences of packages for different population sizes and gossiping lengths. The “Ran-dom” relative and absolute lines show how the distribution would be without using a proximity function at all. The “Common” lines show how it turns out for links that are clustered by using the proximity function based on packages in common.
It is interesting to see that, completelyrandomgossiping turns out pretty good if a package is common enough. With a gossip length of 10, a package will almost certainly eventually be downloaded when the package is on at least 30% of the nodes. The relative dissemination is pretty good as well. With a gossip length of 10, all nodes will almost certainly receive the package together with the news on the update when the package is installed on at least 60% of the population.
The semantic proximity function becomes important for the more rare packages. The “relative” function is quickly outpaced by the one using no proximity function. At that point, it is as likely that the package is received through a random gossip as through a gossip from theVicinity view. The
chance on package transfer using gossiping (the absolute line) is already pretty good for all installation sizes.
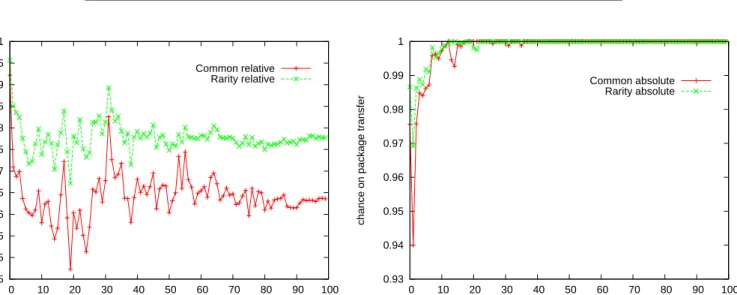
3.2.3.1 Rarity based proximity It is clear that the need for a cluster-ing service (and thus a proximity function) is for the packages with a small number of installations. Taking that into account, the clustering should concentrate on the more rare packages. To evaluate this we improved the proximity function by giving each package a weight based on its rarity. The weight of a package is 1 divided by the number of occurrences of that pack-age. The proximity function based on rarity then takes the set of common packages for two nodes (as before), but then results in the sum of the weight of those packages.
Figure 7 shows the success of this approach relative to the proximity function based just on the number of packages in common. Be aware that the plots are zoomed and do not start at zero chance on package transfer. It
0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
chance on package transfer
installation size (%) Random relative Random absolute Common relative Common absolute 0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
chance on package transfer
installation size (%) Random relative Random absolute Common relative Common absolute 0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
chance on package transfer
installation size (%) Random relative Random absolute Common relative Common absolute 0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
chance on package transfer
installation size (%) Random relative Random absolute Common relative Common absolute 0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
chance on package transfer
installation size (%) Random relative Random absolute Common relative Common absolute 0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
chance on package transfer
installation size (%)
Random relative Random absolute Common relative Common absolute
Figure 6: From left to right: a population size of respectively 200 and 500. From top to bottom: gossip lengths 5, 10 and 20
0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1 0 10 20 30 40 50 60 70 80 90 100
chance on package transfer
installation size (%) Common relative Rarity relative 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1 0 10 20 30 40 50 60 70 80 90 100
chance on package transfer
installation size (%)
Common absolute Rarity absolute
Figure 7: Rarity proximity with n= 500 and`= 20
is clear that the increase on the success rate is only marginally. The nodes that eventually download the package is in both cases very high. With the rarity case, the nodes just have to wait for it a little less.
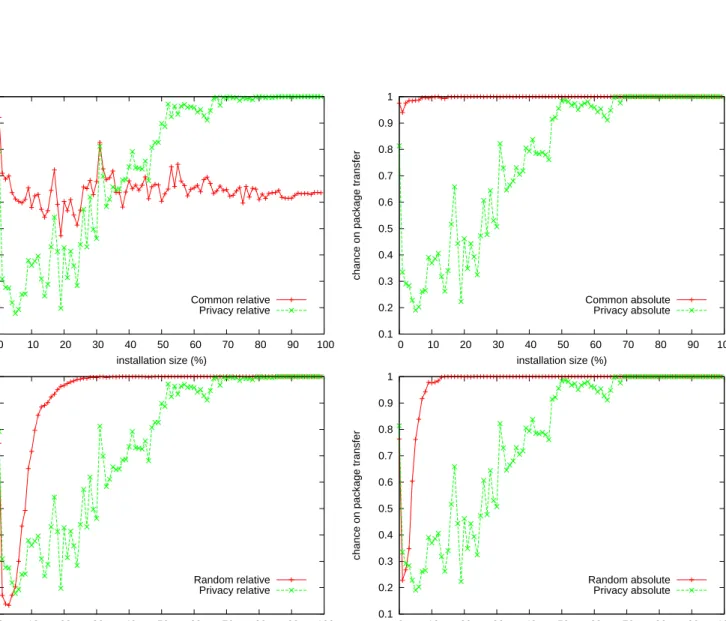
3.2.3.2 Privacy So far we have evaluated proximity functions in which nodes tell each other the packages they have installed. This is a very unde-sirable course of action in the real world, for the same privacy considerations as with the popularity-contest datasets (See3.1.3). To make gossiping soft-ware packages for APT just slightly feasible for application in the real world, we have to find a proximity function that does not directly use the set of installed packages on a peer in its evaluation.
Even then we have a privacy issue in our dissemination algorithm, be-cause a peer gossips if it has the updated package available for download. The package is only available on a peer if it is itself interested in the package, and thus reveals information about its installed packages. Still, considering that this issue also holds for Apt-P2P, it might still be worthwhile to have a privacy friendly proximity function.
Our evaluations show that peers in an overlay-network based on Ubuntu distributions, even with the unrealistic optimistic semantic diversity we cre-ated (See3.1.3.2), have many neighbors that have a lot of packages in mon. Dissemination packages already works pretty good even in the com-plete random case. We only have to try to cluster the nodes that have really rare packages.
We have designed the privacy friendly proximity function, as the function that gives the absolute difference in the rarity weights of the installations on the nodes. Figure 8 shows the result, the top two pictures comparing it to
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 10 20 30 40 50 60 70 80 90 100
chance on package transfer
installation size (%) Common relative Privacy relative 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 10 20 30 40 50 60 70 80 90 100
chance on package transfer
installation size (%) Common absolute Privacy absolute 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 10 20 30 40 50 60 70 80 90 100
chance on package transfer
installation size (%) Random relative Privacy relative 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 10 20 30 40 50 60 70 80 90 100
chance on package transfer
installation size (%)
Random absolute Privacy absolute
0 0.2 0.4 0.6 0.8 1 0 10 20 30 40 50 60 70 80 90 100 packages (%) installation size (%)
Figure 9: Number of packages per installation size
the proximity function: “packages in common.” Because of the particular bad performance of the privacy friendly proximity function, we also show how it compares to random gossiping. Only for exceptionally rare packages (with a distribution of less then 3%), the privacy friendly function raises the probability of a transfer with just 201.
In figure 9 we can see why. The picture shows the how many packages are installed on a certain part of the total population. To be able to see any distribution at all, the Y-axis had to be zoomed to 1%! The peek (not visible in the picture) is with 85% of the packages being deployed on 1% of to population. Rare packages seem to be the most common case.
4
Conclusion & discussion
To come back to our research question:
Can gossiping protocols be used in software deployment archi-tectures in order make it more scalable and robust?
Probably, but only in very specific cases.
Gossiping software packages work best in very large setups. We have taken Ubuntu installations on the Internet as a case-study. The main show-stopper-issues in that scenario are privacy concerns. We have not been able to cluster nodes based on packages in common without revealing the packages installed. The main reason for this is the vast amount of packages that are only installed on very few hosts. We have tried to use rarity as a clustering property, but this one-dimensional factor does not come close to
the many tiny application level multicast-groups (for each package one) that are evaluated when comparing packages in common.
Only in large environments where distributed administration of updates is desirable, and privacy is not an issue, gossiping software packages could be an interesting solution.
5
Future research
We are aware that in the field of multi-party security there is the concept of Symmetric Secure Function Evaluation[15] (SSFE). With SSFE two parties have inputx and y, and both learn the result of a functionf(x, y) without revealingxandy. It would be interesting to investigate if such a function ex-ists, or could be constructed, that can calculate the length of an intersection of two sets.
Also many improvements on the Random Peer Sampling Service Cy-clonhave been proposed.[9,10,11]
On top of that, when SSFE turns out realistic for an intersection length function, integration with Apt-P2P could be done with a composition of structured and unstructured peer-to-peer techniques that let both networks benefit from the properties of the other. It is for example possible to use a structured peer-to-peer service, like Kademlia[16] that is used in Apt-P2P, function as the Random Peer Sampling Service of the other[17]. Another approach could be the other way around and let the structured peer-to-peer network emerge from the unstructured one[18].
As an alternative, research has been done to base application level mul-ticasting on the structure of Distributed Hash Tables. Using this approach, the structure of the overlay-network the Kademlia protocol in Apt-P2P con-structs, might also be used to spread the news on software updates.[19,20]
References
[1] Leon Han LANDesk Software, Inc. How peer download works and how to stage a package, 2010.
[2] Tanja de Vrede. INHOLLAND centraliseert softwaredistributie met BitTorrent.
[3] Bram Cohen. Incentives build robustness in bittorrent, 2003.
[4] Cameron Dale and Jiangchuan Liu. apt-p2p: A Peer-to-Peer Distribu-tion System for Software Package Releases and Updates. In Interna-tional Conference on Computer Communications. IEEE, 2009.
[5] P.T. Eugster, R. Guerraoui, A.-M. Kermarrec, and L. Massoulie. Epi-demic information dissemination in distributed systems. Computer, 37(5):60 – 67, may 2004.
[6] Anne marie Kermarrec and Maarten Van Steen. Gossiping in Dis-tributed Systems, 2007.
[7] Spyros Voulgaris. Epidemic-Based Self-Organization in Peer-to-Peer Systems. PhD thesis, VU University, 2006.
[8] Spyros Voulgaris, Daniela Gavidia, and Maarten Van Steen. Cyclon: Inexpensive membership management for unstructured p2p overlays.
Journal of Network and Systems Management, 13:2005, 2005.
[9] Arno Bakker and Maarten van Steen. Puppetcast: A secure peer sam-pling protocol. In EC2ND ’08: Proceedings of the 2008 European Con-ference on Computer Network Defense, pages 3–10, Washington, DC, USA, 2008. IEEE Computer Society.
[10] Niels Drost, Elth Ogston, Rob V. van Nieuwpoort, and Henri E. Bal. Arrg: real-world gossiping. In HPDC ’07: Proceedings of the 16th international symposium on High performance distributed computing, pages 147–158, New York, NY, USA, 2007. ACM.
[11] Anne-Marie Kermarrec, Alessio Pace, Vivien Quema, and Valerio Schi-avoni. Nat-resilient gossip peer sampling. In ICDCS ’09: Proceedings of the 2009 29th IEEE International Conference on Distributed Com-puting Systems, pages 360–367, Washington, DC, USA, 2009. IEEE Computer Society.
[12] Spyros Voulgaris and Maarten Van Steen. Epidemic-style management of semantic overlays for content-based searching. In In EuroPar, pages 1143–1152. Springer, 2005.
[13] M´ark Jelasity, Alberto Montresor, and Ozalp Babaoglu. T-man: Gossip-based fast overlay topology construction. Comput. Netw., 53(13):2321–2339, 2009.
[14] Alan Demers, Dan Greene, Carl Hauser, Wes Irish, John Larson, Scott Shenker, Howard Sturgis, Dan Swinehart, and Doug Terry. Epidemic algorithms for replicated database maintenance. InPODC ’87: Proceed-ings of the sixth annual ACM Symposium on Principles of distributed computing, pages 1–12, New York, NY, USA, 1987. ACM.
[15] Hemanta K. Maji, Manoj Prabhakaran, and Mike Rosulek. Complexity of multi-party computation problems: The case of 2-party symmetric secure function evaluation. InTheory of Cryptography, volume 5444 of
Lecture Notes in Computer Science, pages 256–273. Springer Berlin / Heidelberg, 2009.
[16] Petar Maymounkov and David Mazires. Kademlia: A peer-to-peer in-formation system based on the xor metric, 2002.
[17] B. Maniymaran, M. Bertier, and A.-M. Kermarrec. Build one, get one free: Leveraging the coexistence of multiple p2p overlay networks. pages 33 –33, june 2007.
[18] Marin Bertier, Franois Bonnet, Anne-Marie Kermarrec, Vincent Leroy, Sathya Peri, and Michel Raynal. D2ht: the best of both worlds, inte-grating rps and dht. 2010.
[19] Miguel Castro, Peter Druschel, Y. Charlie Hu, and Antony Rowstron. Proximity neighbor selection in tree-based structured peer-to-peer over-lays. Technical report, 2003.
[20] Sameh El-ansary, Luc Onana Alima, Per Brand, and Seif Haridi. Effi-cient broadcast in structured p2p networks, 2003.