ABSTRACT
MIRANSHAH, SAHIBI. Integrating a Path Operator in Apache Jena for Generalized Graph Pattern Matching. (Under the direction of Dr. Kemafor Anyanwu Ogan.)
The emergence of large heterogeneous networks largely driven by the W3C standards for representing metadata and relationships on the Web has introduced the need for more flexible querying methods that the standard pattern matching paradigm. For such large graphs, it will be common for users to only know a part of the structure they are interested in finding in a large network. In some cases, finding the structure would in fact be the goal of the query. For such scenarios, it is necessary to have flexible matching paradigms where it is possible to match both fixed structure patterns as well as variable structure patterns. The present infrastructure for supporting such generalized queries exists in a very limited form. In this thesis we explore some approaches for achieving this.
The two common approaches to implement generalized graph pattern matching queries, i.e. queries that can match not just edges but paths between source and destination node bindings, would be either to use the traditional graph pattern matching approach which roughly compares to relational query processing and evaluates the query by using relational join expressions. The other approach would be to use the graph traversal algorithms which convert the graph pattern to a regular expression, and execute its finite automata on the dataset graph. Both these approaches are limited in terms of expressiveness of queries and their performance on large and diverse datasets as the Semantic Web.
Integrating a Path Operator in Apache Jena for Generalized Graph Pattern Matching
by
Sahibi Miranshah
A thesis submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Master of Science
Computer Science
Raleigh, North Carolina 2016
APPROVED BY:
Dr. Raju Vatsavai Dr. Guoliang Jin
DEDICATION
BIOGRAPHY
ACKNOWLEDGEMENTS
I would like to thank my advisor Dr. Kemafor Anyanwu Ogan for her guidance in my thesis work. Her knowledge, consistent motivation, humble attitude and passion for research and innovation made my first steps in academic research an exciting and fulfilling experience.
I would like to thank Dr. Raju Vatsavai and Dr. Guoliang Jin for being part of my graduate committee.
I would like to thank my colleagues in the semantic computing research lab - Sidan Gao, HyeongSik Kim, Shalki Shrivastava and Avimanyu Mukhopadhyay for their support. I would like to thank Sidan for her invaluable suggestions and feedback and fruitful research oriented discussions.
TABLE OF CONTENTS
LIST OF TABLES . . . vii
LIST OF FIGURES. . . viii
Chapter 1 INTRODUCTION. . . 1
1.1 Structure of the Thesis . . . 3
Chapter 2 BACKGROUND . . . 4
2.1 RDF . . . 5
2.1.1 RDF Model . . . 6
2.1.2 RDF Serialization Formats . . . 7
2.2 Sparql . . . 10
2.2.1 Querying Data With Sparql . . . 12
2.3 Graph Pattern Matching . . . 15
2.3.1 General Definition of Graph Pattern Matching . . . 16
2.3.2 Types of Graph Patterns . . . 17
2.3.3 Data Models and Graph Pattern Matching . . . 19
2.3.4 Systems supporting the Graph Pattern Matching problem . . . 20
2.4 Generalized Graph Pattern Matching . . . 21
2.4.1 SPARQ2L . . . 23
2.5 Solve Algorithm . . . 31
2.6 Apache Jena . . . 34
2.6.1 Jena Architecture . . . 34
Chapter 3 APPROACH. . . 37
3.1 Generic Sparql Query Engine . . . 41
3.2 Extending Jena . . . 43
3.2.1 ARQ Query Processing . . . 44
3.2.2 Main Query Engine . . . 46
3.2.3 Custom Query Engine . . . 48
3.2.4 Algebra Extensions . . . 49
3.2.5 Expression Functions and Property Functions . . . 49
3.3 Query Plan Generation . . . 50
3.4 Architecture of Extended Jena . . . 53
3.5 Integrating the Path Operator . . . 56
3.5.1 Path Operator ’OpFindAllPaths’ . . . 56
3.5.2 Integration of the Path Operator . . . 57
3.5.3 User Workflow . . . 58
3.7 Related Work . . . 62
Chapter 4 EVALUATION . . . 63
4.1 Query Compilation Time . . . 64
4.2 Query Execution Time . . . 65
4.3 Usability . . . 67
4.4 List of Queries . . . 69
Chapter 5 CONCLUSION AND FUTURE WORK . . . 73
BIBLIOGRAPHY . . . 74
APPENDIX . . . 77
LIST OF TABLES
LIST OF FIGURES
Figure 2.1 The graph describes two people, and each one has properties name, gender and knows. . . 7 Figure 2.2 The graph uses the FOAF ontology, describes two people, and each
one has properties name, gender and knows. . . 13 Figure 2.3 The algorithm SOLVE to solve single source path expression
prob-lem.[Tar81] . . . 32 Figure 2.4 The algorithm ELIMINATE is used to pre-compute the path sequence
for an input graph G whose vertices are numbered from 1 to n.[Tar81] 33 Figure 2.5 The Jena architecture illustrating interaction between the APIs.[Arc] 35 Figure 3.1 Data graph to illustrate query types. . . 39 Figure 3.2 The intuition behind the integration of the path operator is to
decom-pose the path query and use the existing Jena framework to execute graph pattern matching, and use a path algebraic approach to extract paths. . . 40 Figure 3.3 A generic SPARQL Query processing, optimization and execution
framework. . . 42 Figure 3.4 Phases of ARQ query processing. . . 47 Figure 3.5 Query plan for a simple example query without path operator
inte-grated into the query engine. . . 51 Figure 3.6 Query plan for the example query after integrating the path operator
into the query engine. . . 52 Figure 3.7 Query plan for the example query after integrating the path operator
into the query engine. . . 54 Figure 3.8 The diagram shows the architecture of the Path-Extraction Enhanced
Jena API. . . 55 Figure 3.9 The flowchart shows how the Jena API can be used to execute SPARQL
queries with or without path computation, by using the object of class ’ExtendedModel’ and by specifying boolean arguments that reflect
the user’s choice of whether to compute paths or not. . . 59 Figure 4.1 Graph to illustrate the comparison of compile time in queries with
and without path computations. . . 65 Figure 4.2 Graph to illustrate the comparison of execution time in queries with
CHAPTER
1
INTRODUCTION
With the exponential growth in data being contributed to the Semantic Web and its repre-sentation as large heterogeneous graphs, and the reliance of a large number of applications on the ability to query the unstructured data, there is an urgent need to introduce flexible querying paradigms. Traditional graph pattern matching infrastructure does not allow path extraction queries with variable structure patterns. In circumstances like intelligence anal-ysis, crime investigations and social network analanal-ysis, there is need to find the connections between certain groups of entities.
For example, a query that asks for bindings of the variable ?edge in a graph pattern
"PersonX" ?edge "NC State"
can match the edge variable for the triple
"PersonX" "worksIn" "NC State" .
CHAPTER 1. INTRODUCTION
for the relation between a PersonX on the FBI watchlist and JFK airport, which would be represented by thepath pattern:
"PersonX" ??path "JFK" .
This path query would look for paths like this:
"PersonX" "passengerIn" "Flight D143" . "Flight D143" "arrivesAt" "JFK" .
Or
"PersonX" "passengerIn" "Flight D143". "Flight D143" "departsFrom" "JFK" .
Path queries might also contain constraints, for example, the above query might have a constraint that the path should contain the edge label "arrivesAt", in which case the second path would not be a valid result.
RDF (Resource Description Framework), a collection of W3C specifications, is a popular data model used to represent data in the Semantic Web. SPARQL, the official W3C recom-mendation for querying RDF graphs, does not contain the path extraction capability. The aim of our research is to integrate a path operator in the existing open source Apache Jena framework and the ARQ query engine for SPARQL.
There are a few common approaches that could have been used to implement the generalized graph pattern matching paradigm. The traditional graph pattern matching approach that roughly compares to relational query processing would use joins to execute path queries, but this approach would have high overheads, recursion would be limited and querying would be cumbersome. The other approach would be to specify the path query using a regular expression, which can be compiled into a deterministic finite automaton by the compiler and executed to find the path bindings. These approaches are limited in terms of their expressiveness, efficiency and performance on large disk resident graphs.
1.1. STRUCTURE OF THE THESIS CHAPTER 1. INTRODUCTION
1.1
Structure of the Thesis
The thesis document has been structured into five chapters, where Chapter 2 discusses the background of the research, comprising the RDF data model, SPARQL querying language, the traditional graph pattern matching paradigm and what generalized graph pattern matching implies. It also introduces the popular open source Apache Jena framework for SPARQL query processing and its architecture. The chapter points out to the SPARQ2L research publication that proposes a grammar extension that enables generalized graph pattern matching. It also talks about the Solve algorithm[Tar81]given by Tarjan that we use as a basis to implement our path operator and the prefix-solve algorithm[GA13]which is the implementation framework that allows to efficiently query graphs on disk.
Chapter 3 discusses the approach used for the integration of the path operator, the extension points used in the existing Jena ARQ query engine and the implementation details. It also talks about how compilation of the path queries takes place, the path query syntax that we use and comparison with existing related work.
CHAPTER
2
BACKGROUND
With the evolution of technology and the exponential growth of the World-Wide-Web, there is a huge volume of data being generated from social media, news, research data, repositories etc. A huge amount of it is stored as graphs, including hypertext data, data from social networking sites, unstructured and semi-structured data, especially because of the high expressive power of graphs to represent complex structures of data and its interconnections.
2.1. RDF CHAPTER 2. BACKGROUND
blogs) data arises.
Unstructured data refers to the information that is not organized in a pre-defined manner. The irregularity and ambiguity in the data makes it difficult to understand and process using traditional programs and techniques as compared to relational data. There are several techniques such as data mining and natural language processing to find patterns in, or interpret unstructured data. Some structure can be imparted to the data by using tags or metadata making it semi-structured data. Unstructured data can be stored in document databases (for example-MongoDB), graph databases (for example-Neo4j) or key-value stores.
2.1
RDF
[W3c]The World Wide Web was originally built for human usage and consumption, and even though everything on it is machine-readable, this data is not machine-understandable. Due to the sheer volume of the information on the Web, it is not possible to manage it manually. But at the same time it is hard to automate anything on the Web. The solution here is to use metadata to describe the data contained on the Web. Metadata is "data about data" or in the context of this specification "data describing Web resources".
Resource Description Framework (RDF) is a foundation for processing metadata, formal-ized by the World Wide Web Consortium. It provides interoperability between applications that use and exchange machine-understandable information on the Web. RDF enables the automated processing of Web resources. RDF can be used in a vast number of application areas, for example - in resource discovery to implement better search engine capabilities, in cataloging for listing the content and content relationships available at a particular Web site, by intelligent software agents to aid knowledge sharing and exchange, in content rating, for characterizing intellectual property rights of Web pages, and for describing the privacy preferences of a user and the privacy policies of a website. RDF with digital signatures is the foundation to building the "Web of Trust" for electronic commerce, collaboration, and other applications.
meta-2.1. RDF CHAPTER 2. BACKGROUND
data. A collection of classes is called a schema. Classes are systematized in a hierarchy, and offer extensibility through subclass refinement.
2.1.1
RDF Model
The base of RDF is a model for representing named properties and property values. The RDF model is based on well-established principles from various data representation communi-ties. RDF properties are essentially attributes of resources and correspond to traditional attribute-value pairs. RDF properties represent relationships between resources. An RDF model can therefore resemble an entity-relationship diagram. In terms of object-oriented design, resources correspond to objects and properties correspond to instance variables.
The RDF data model is a syntax-neutral representation of RDF expressions. Two RDF expressions are equivalent if and only if their data model representations match.
The basic data model consists of three object types:
• Resources: All things being described by RDF expressions are resources. A resource may be an entire webpage, a part of a webpage, a whole collection of pages or an object that is not directly accessible via the web. Resources are always named by URIs (Uniform Resource Identifier) plus optional anchor IDs.
• Properties: A property is a specific feature, characteristic, attribute, or relation used to describe a resource. Each property has a definitive meaning, defines its acceptable values, the types of resources it can describe, and its relationship with other properties. • Statements: A particular resource together with a named property and the value of
that property for that resource is an RDF statement. These three individual parts of a statement are called, respectively, the subject, the predicate, and the object; also known as a subject-predicate-object triple. The object of a statement can be another resource or a literal.
2.1. RDF CHAPTER 2. BACKGROUND
applications. An RDF database is basically a collection of triples or statements that rep-resent a labeled, directed multi-graph. For example, below is a graph[converted using http://www.easyrdf.org/converter]
Figure 2.1The graph describes two people, and each one has properties name, gender and knows.
2.1.2
RDF Serialization Formats
Following are the popular RDF Serialization Formats[W3c]:
• Turtle: Terse RDF Triple Language is a compact, human friendly and concrete syntax for RDF defined by the W3C. Turtle is an extension of N-Triples which includes the most useful and appropriate things from Notation 3 while keeping it in the RDF model. The recommended XML syntax for RDF, RDF/XML has certain constraints imposed by XML and the use of XML Namespaces that prevent it encoding all RDF graphs. These constraints do not apply to Turtle.
2.1. RDF CHAPTER 2. BACKGROUND
• N-Triples: It is an easy, simple to parse, line based, and plain text format for repre-senting the correct answers for parsing RDF/XML test cases as part of the RDF Core working group. It was designed to be a fixed subset of N3 and hence N3 tools such as cwm and Euler can be used to read and process it. It is simpler than Notation3 and Turtle, hence easier for software to parse and generate. It is recommended, but not required, that N-Triples content is stored in files with an ’.nt’ suffix to distinguish them from N3.
For example, the graph in Fig () can be represented in N-Triples format as:
_:genid1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person> .
_:genid1 <http://xmlns.com/foaf/0.1/name> "Emma" .
_:genid1 <http://xmlns.com/foaf/0.1/gender> "Female" .
_:genid1 <http://xmlns.com/foaf/0.1/knows> _:genid2 .
_:genid2 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person> .
_:genid2 <http://xmlns.com/foaf/0.1/name> "Rachel" .
_:genid3 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person> .
_:genid3 <http://xmlns.com/foaf/0.1/name> "Rachel" .
_:genid3 <http://xmlns.com/foaf/0.1/gender> "Female" .
_:genid3 <http://xmlns.com/foaf/0.1/knows> _:genid4 .
_:genid4 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person> .
_:genid4 <http://xmlns.com/foaf/0.1/name> "Emma" .
2.1. RDF CHAPTER 2. BACKGROUND
• JSON-LD: JSON-LD is a JSON-based format to serialize Linked Data. The syntax was designed to easily integrate into deployed systems that already use JSON, and supplies a smooth upgrade path from JSON to JSON-LD. It is mainly intended to be a way to use Linked Data in Web-based programming environments, to build interoperable Web services, and to store Linked Data in JSON-based storage engines.
• Notation 3: It is a non-standard serialization which is a compact and readable alter-native to RDF’s XML syntax, but also is extended to allow greater expressiveness. It is a superset of Turtle with additional features, such as support for RDF based rules. N3 extends the RDF data model by adding formulae, variables, logical implication, functional predicates, and providing a textual syntax alternative to RDF/XML. • RDF/XML: It is an XML based syntax defined by W3C. This format was the first
stan-dard serialization format for RDF. The RDF graph has nodes and labeled directed arcs that link pairs of nodes. This graph is represented as a set of RDF triples where each triple contains a subject node, predicate and object node. Nodes can be IRIs, literals, or blank nodes. Predicates are IRIs and can be interpreted as either a relationship between the two nodes or as defining an attribute value for some subject node. To encode the graph in XML, the nodes and predicates have to be represented in XML terms i.e. element names, attribute names, element contents and attribute values. For example, the graph in Fig () can be represented in RDF/XML format as:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<foaf:Person>
<foaf:name>Emma</foaf:name>
<foaf:gender>Female</foaf:gender>
<foaf:knows>
<foaf:Person>
<foaf:name>Rachel</foaf:name>
</foaf:Person>
2.2. SPARQL CHAPTER 2. BACKGROUND
</foaf:Person>
<foaf:Person>
<foaf:name>Rachel</foaf:name>
<foaf:gender>Female</foaf:gender>
<foaf:knows>
<foaf:Person>
<foaf:name>Emma</foaf:name>
</foaf:Person>
</foaf:knows>
</foaf:Person>
</rdf:RDF>
2.2
Sparql
SPARQL is the query language for the Semantic Web. "Trying to use the Semantic Web without SPARQL is like trying to use a relational database without SQL", explained Tim Berners-Lee, W3C Director. SPARQL can be used to articulate queries across diverse data sources, whether the data is stored natively as RDF or viewed as RDF via middleware. SPARQL queries hide the details of data management, which results in lower costs and increased robustness of data integration on the Web.[Jen][W3c]
SPARQL was standardized by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium (W3C), and is one of the fundamental technologies of the semantic web. SPARQL queries can comprise triple patterns, optional patterns, conjunctions and disjunctions. SPARQL also supports extensible value testing and constraining queries by source RDF graph. The results of SPARQL queries can be results sets or RDF graphs. SPARQL has been implemented for multiple programming languages. There exist tools like ViziQuer that allow semi-automatic construction of SPARQL queries for a SPARQL endpoint. There also exist tools that translate SPARQL queries to other query languages like SQL and XQuery.
2.2. SPARQL CHAPTER 2. BACKGROUND
or what can loosely be called "key-value" data. The database is essentially a set of "subject-predicate-object" triples. SPARQL is a "data-oriented" query language, in that it only queries the information held in the models. There is no inference in the query language itself. SPARQL takes the description of what the application wants, in the form of a query, and returns the results of the query in the form of a set of bindings or an RDF graph.
In terms of SQL relational database, RDF data can be considered as a table with three columns i.e. the subject, the predicate and the object column. Unlike relational databases, the data type of the column values is not required to be homogenous. The object column is heterogeneous. The data type of each cell value is implied, or specified in the ontology, by the predicate value. Again comparing to SQL relations, the RDF data would be a table with all triples for a given subject represented as a row, with the subject as the primary key and each possible predicate as a column and the object being the value in the cell. However, SPARQL/RDF becomes easier and more powerful for columns that could contain multiple values (for example-email ids) for the same key, and where the column itself could be a joinable variable in the query, rather than directly specified.
SPARQL provides a full set of analytic query operations such as JOIN, SORT, and AG-GREGATE for data that does not require a separate schema definition, but whose schema is intrinsically part of the data. The schema information is often provided externally to allow different datasets to be joined in an unambiguous manner. Additionally, SPARQL provides specific graph traversal syntax for data that can be thought of as a graph.
Below is an example that demonstrates a simple query that leverages the ontology definition "foaf", also called the "friend-of-a-friend" ontology. The query returns names and emails of every person in the dataset.
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name ?homepage
WHERE {
?person a foaf:Person.
?person foaf:name ?name.
?person foaf:homepage ?homepage.
}
2.2. SPARQL CHAPTER 2. BACKGROUND
predicate ("a") is a person (foaf:Person) and the person has one or more names (foaf:name) and homepages (foaf:homepages).
The result of the join is a set of rows with bindings for variables ?person, ?name, ?home-page. This query returns the ?name and ?homepage, and we chose not to return ?person also because ?person is often a complex URI rather than a human-friendly string. Some of the ?people may have multiple homepages, so in the returned set, a ?name row may appear multiple times, once for each homepage.
This query can be called a federated query if distributed to multiple SPARQL endpoints, (i.e. services that accept SPARQL queries and return results), computed, and results gath-ered.
In either case of a federated or a local query, additional triple definitions in the query could allow joins to different subject types, such as cars. For example, we could use such a query to return a list of names and homepages for people who drive cars with high fuel efficiency.
2.2.1
Querying Data With Sparql
SPARQL queries RDF graphs which are essentially sets of triples, but can be serialized in any format, for example, RDF/XML, Turtle, N-Triples. The example graph given below uses the FOAF ontology, describes two people, and each one has properties name, gender and knows.
As triples, the graph would be represented like this:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
2.2. SPARQL CHAPTER 2. BACKGROUND
Figure 2.2The graph uses the FOAF ontology, describes two people, and each one has properties name, gender and knows.
_:genid3 foaf:name "Rachel" .
_:genid3 foaf:gender "Female" .
_:genid3 foaf:knows _:genid4 .
_:genid4 rdf:type foaf:Person .
_:genid4 foaf:name "Emma" .
2.2.1.0.1 Basic Patterns
A basic pattern is a set of triple patterns that is obtained when the triple patterns all match with the same value used each time the variable with the same name is used. The following query involves two triple patterns, each ending in a ’.’. The variable x has to be the same for each triple pattern match.
SELECT ?name
WHERE
{ ?x <http://xmlns.com/foaf/0.1/gender> "Female" .
?x <http://xmlns.com/foaf/0.1/name> ?name .
}
The solutions are:
2.2. SPARQL CHAPTER 2. BACKGROUND
"Emma"
"Rachel"
2.2.1.0.2 Filters
Graph matching allows finding patterns in the graph. Filters allow the values in a solution to be restricted. Following are a few comparisons with filters.
• String Matching: SPARQL provides an operation based on regular expressions to test strings, this includes the SQL "LIKE" style tests.
The syntax is:
regex(?y, "pattern" [, "flags"])
The flags argument is optional. The flag "i" indicates a case-insensitive pattern match needs to be done.
For example, the following query finds names with "E" or "e".
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?b
WHERE
{ ?a foaf:name ?b .
FILTER regex(?b, "e", "i") }
with the results
b
"Emma"
"Rachel"
2.3. GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
<http://abc/Rachel/> a foaf:Person ;
foaf:name "Rachel" ;
foaf:age 35 ;
foaf:gender "Female" ;
foaf:knows ( <http://abc/Emma/> [ foaf:name "Emma" ] ) .
<http://abc/Emma/> a foaf:Person ;
foaf:name "Emma" ;
foaf:age 5 ;
foaf:gender "Female" ;
foaf:knows ( <http://abc/Rachel/> [ foaf:name "Rachel" ] ) .
A query to find the names of people who are younger than 40 is:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?var
WHERE
{
?var foaf:age ?age .
FILTER (?age < 40)
}
The solution is:
Var
<http://abc/Emma/>
<http://abc/Rachel/>
2.3
Graph Pattern Matching
2.3. GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
edge exists from the subject to the object for every subject-predicate-object triple in the data.
With the increase in size of the database, the size and complexity of this graph increases and it becomes inefficient to find patterns in the data by visualizing it. Graph Pattern Matching refers to the problem of finding specific patterns in a given graph. The problem is popular in graph processing simply because it has widespread application in plagiarism detection, intelligence analysis, social networking, biology, chemistry, knowledge discovery and numerous other areas. The graph pattern matching problem can be implemented in various data models including the Resource Description Framework (RDF), Property Graphs or the Relational data model.
2.3.1
General Definition of Graph Pattern Matching
Graph pattern matching is also referred to as sub-graph isomorphism, which is an NP complete problem. The inputs of the subgraph pattern matching problem are:
• a graph G with nodes V and edges E, where nodes and edges are labeled with strings. The label of a node is label(v) and the label of an edge e is label(e).
• a query pattern, which can also be viewed as a graph P=(Vp;Ep). The nodes and
edges of graph P describe conditions that a subgraph of G must satisfy in order to be a match. Generally, the query pattern P is a conjunction of smaller patterns that together impose requirements on nodes and their neighborhoods in the data graph G.
The graph pattern matching problem is to find all possible subgraphs of the given graph G that match a given pattern P. More precisely, the match can be defined as:
• structural match or isomorphism between P and a candidate solution, and • conditions on labels of specific nodes and edges in a candidate solution
2.3. GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
(relational, RDF, property graph), and execute the benchmark queries on the corresponding systems. The systems were evaluated using a large data instance on a single machine (the largest dataset being LUBM-8000, which contains over 1 billion RDF triples). The paper concluded that the graph pattern matching problem can be expressed in the different data models such as the Resource Description Framework, property graphs and the relational model and can be evaluated using systems using all these data models; but contrary to popular belief and various vendors’ claims, modern native graph stores do not necessarily offer a competitive advantage over traditional relational and RDF stores, even for the graph-specific problem of pattern matching.
2.3.2
Types of Graph Patterns
• Nodes and Edges: This is the most basic graph pattern and consists of a single triple pattern that satisfies given conditions. No join is necessary in this case. An example query given below requests for all undergraduate students. Query:
select ?x
where {
?x isA "UndergraduateStudent" }
• Neighborhoods and Stars: Neighborhoods are the second most important type of graph patterns. Neighbors match on the nodes which are adjacent and edges that are incident to a given node. The example query to find neighbors could ask for all graduate students that attend a certain course. Here, all the nodes that are adjacent to the two nodes labeled ’GraduateStudent’ and ’GraduateCourse0’ would be answers to the query. Star patterns are neighborhoods with multiple patterns around a central node. Query:
select ?name ?email ?telephone
where {
2.3. GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
?x email ?email .
?x telephone ?telephone }
• Triangles: Triangle patterns look for three nodes adjacent to each other. An example is the following query:
select ?x ?y ?z where {
?x undergraduateDegreeFrom ?y.
?x memberOf ?z.
?z subOrganizationOf ?y }
Matching triangles is specially challenging from the point of view of query optimiza-tion as potentially many intermediate results need to be processed.
• Fixed and Variable Length Paths: Paths of fixed or variable length are a special case of graph patterns. Paths of fixed length occur for example when the names of students who attend a given course are queried. Variable length paths are commonly used to match hierarchical relationships. In the example query given below, all direct and transitive paths between variables y and z with edge label ’sub-organizationOf’ must be matched. Answering a path query requires a series of joins (in triple stores or RDBMS) or some form of breadth-first expansion on the graph (in native graph stores) depending on the internal graph representation of a particular system. SPARQL supports path queries through property paths. Property paths can represent paths between two graph nodes, which may be a trivial single edge path of length 1, or an arbitrary length path. SPARQL uses property path expressions to represent paths, which are similar to regular expressions. During query execution, matches for the path expression are evaluated. The limitation of property paths is that they do not return the paths themselves, but only bindings for source and destination nodes can be obtained using them.
Example Query:
2.3. GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
?x worksFor ?y .
?y isA Department .
?y sub-organizationOf* ?z }
2.3.3
Data Models and Graph Pattern Matching
• RDF: RDF and the SPARQL query language are the typical data representation and querying format in the domain of Semantic Web. It views the data as a collection of triples, each describing a statement using a subject-predicate-object format. An object can either be a literal value, or a URI which refers to a subject. The RDF representation naturally describes a graph where subject and object are nodes, and the predicate is the label of an edge between them.
• Property Graph: The property graph model extends the RDF concept and allows nodes and edges in the graph to have an arbitrary number of properties or key/value pairs, in addition to labels. The study conducted in the research paper[GT14]uses a natural mapping between the RDF and PG models. Whenever a subject-predicate-object triple has a literal value for subject-predicate-object, the predicate and subject-predicate-object are modeled as a property-value pair of the subject node. If the object is a URI, the triple describes an edge between subject and object nodes with the label on the predicate edges. This way, not all the triples in the RDF graph become edges in the PG model, which makes it a conceptually less verbose model.
– Cypher Query Language: Neo4j’s Cypher is a declarative query language to query data in the property graph model. A cypher query allows specifying a subgraph in the MATCH clause with constants and variables in place of nodes and edges to be matched, like in a SPARQL query. Similar to SPARQL’s FILTER clause, ad-ditional constraints on properties of nodes and edges can be expressed in the WHERE clause. Unlike SPARQL, relationships between nodes can have multiple properties. It is also possible to query the paths between nodes.
2.3. GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
triangles, paths, are performed via multiple calls of API functions that return nodes/edges of a given label and immediate neighbors of a given node.
• Relational Model: Graphs and pattern matching problems can arise and can be solved in the relational domain as well. In case of the relational data model, it is assumed that every node belongs to one particular type (e.g., Student) with a fixed set of stati-cally determined properties. These node types are translated into relations and the relationships between nodes are stored in mapping tables. After the schema for the entire dataset is defined, indexes can be created to speed up lookups and joins. SQL queries for graph pattern matching are very verbose due to the fact that relationships are stored as separate tables. This means that a single hop lookup in the graph concep-tually decodes into two joins. The advantage of using SQL and the relational model for graph pattern matching is that it allows us to leverage decades of development in transactional processing, query optimization and system tuning. Relational database management systems (RDBMS) can become an especially lucrative option for "hy-brid" datasets, in which only part of the data is a graph, while some information comes in tables.
Above stated are the ways to conceptually model graph pattern matching problems in different areas.
2.3.4
Systems supporting the Graph Pattern Matching problem
• RDF Databases:
– Virtuoso: Virtuoso is an existing relational store that models RDF graph as a single table and translates SPARQL queries into SQL.
– TripleRush: TripleRush is a research RDF database that represents the triple data as partially evaluated read-optimized patterns, matches a given query’s graph pattern against those in parallel and then builds the results from the matched parts. This can be correlated to join indices.
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
– Virtuoso: Virtuoso is an RDF as well as relational store. It can be used to find graph pattern matches by using SQL queries. SQL queries can be written using domain knowledge to simplify matching the variable length paths. But to avoid making such assumptions about the data, one would need to rely on recursive SQL features.
• Graph Databases:
– Neo4j: Neo4j is an open-source native graph database. It supports functionalities similar to traditional RDBMSs such as full transactional support, a declarative query language (Cypher), availability and scalability through a distributed ver-sion. A major advantage of Neo4j is its intuitive way of modeling and querying graph-shaped data. It stores edges as double linked lists and properties are stored separately, referencing the nodes with corresponding properties.
– Sparkshee: Sparksee is a proprietary native graph database. It is a disk-based system that depends on B+-trees and compressed bitmap indexes to store nodes and edges with their properties. Sparksee uses custom API functions to provide access to data. The API contains a set of primitive operations on nodes and edges like adding and deleting nodes or extracting neighborhoods. The system additionally provides native implementation of core graph algorithms such as connected component detection, shortest paths and different traversals. Some of the use-cases for Sparksee include various types of graph analysis such as cluster and outlier detection.
2.4
Generalized Graph Pattern Matching
We refer to the problem of generalized graph pattern matching as a general form of subgraph extraction query in which we are able to retrieve specific information about the structure of the data entities in the graph by involving variables and constraints in the query. Such functionality is of immense use as it provides a wider range of data exploration and querying.
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
queries with don’t care symbols, variables and constraints. The representation of relational data in a graph model enables to represent not only the values of the entities but also to explicitly model structural relations between different parts of an object. Typically, data mining aims to extract a subgraph of the underlying data graph and the concept of subgraph isomorphism is applied for such information retrieval. Subgraph isomorphism is a formal concept for checking subgraph equality, but it intuitively indicates that a smaller graph is part of a larger graph. Assuming that a query is represented by an attributed graph ’q’ (query graph), and the database graph is ’G’, the knowledge mining system gives the result of the query as a binary decision (true or false) depending on whether the query graph q is contained in the database graph G. This kind of subgraph isomorphism approach in data extraction has some limitations, some of which are relevant only to relational databases. Firstly, the database graph has a large number of attributes that might be irrelevant for a particular query. Secondly, the result of such a query is always a binary decision and cannot be used to extract data points or paths between the entities. Thirdly, this approach does not allow the query to impose constraints on the attributes of the query graph to model restrictions or dependencies. The generalized subgraph isomorphism approach discussed in[Brü08]overcomes these limitations. Thus[Brü08]uses a generalized graph pattern matching approach to enhance the querying capability leading to a powerful and flexible graph pattern matching framework apt for general graph based data mining.
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
few example analysis tasks that use such queries are given below:
Example 1: Flight and Airport Risk Assessment (adapted from[Any07]): To determine potential threats to flight and airport safety, security officials would query for and investigate all high risk passengers scheduled for the flight.
Find the relationships between passengers scheduled for flights to Washington DC, who purchased their tickets by cash or purchased their tickets less than a day before departure, and have links to flight training.
Example 2: Local Threat Assessment: To determine threats to local safety, for example, by civilians in the San Bernardino Shooting incident, the local security officials would like to regularly query and investigate high risk residents in the area.
Find the relationships between people who recently purchased weapons or are frequent visitors at a shooting range, and have been in touch with any person suspected of terrorism.
Example 3: Background check for potential hires: To determine whether a candidate is a potential risk to the organization, the management would want to perform a background check to find out any criminal behavior.
Find the relationships between candidates in the organization’s interview process, and entities in the government watchlist.
All the example queries aim to retrieve paths or subgraphs connecting specific nodes where the paths are subject to some constraints, for example, associated with flight training or have been in contact with potential terrorist suspects.
Such queries can have very important applications where network analysis plays a significant role, as in case of planning, anti-money laundering or detecting patent infringe-ments. Unfortunately, as per our knowledge, the existing Semantic Web query languages do not support the expression of such queries about constrained path relationships.
2.4.1
SPARQ2L
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
query languages, including SPARQL, do not support the ability to extract paths based on queries about arbitrary path structures in the data.
The SPARQ2L Language
SPARQ2L proposes a query language which extends SPARQL with path variables and path variable constraint expressions. The language supports three kinds of constraints:
• Constraints on Nodes and Edges: constrain paths based on presence or absence of specific nodes and edges.
• Cost-based constraints: constrain paths based on their cost, in weighted graphs. • Structure-based constraints: constrain paths depending on their structural properties,
for example, simple path, presence of pattern in path.
The SPARQ2L language introduces the concept of path variables and path filter expres-sions to be able to express generalized graph pattern matching queries. It extends the query patterns supported to include RDF path patterns which generalize standard SPARQL graph pattern expression to include triple patterns with path variables in the predicate positions.
A few terms used in SPARQ2L are:
• RDF Term: collectively refers toI,LandB, which are pairwise disjoint infinite sets of IRIs, literals and blank nodes respectively.
• RDF Triple: It is a 3-tuple(s,p,o)∈(I ∪B)×I×(I∪B∪L)wheresis the subject,p is the predicate ando is the object.
• Directed Edge-Labeled Graph: It is a graphG = (V,E,λ,Σ)such thatE ⊆V ×V, and
λis a function fromE to a set of labelsΣi.e.λ:E →Σ.
• RDF Triple Graph: It is a directed edge labeled graphG = (s,o,(s,o),λ,p)for an RDF triple(s,p,o).
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
• RDF Path: from node x to nodey in an RDF databaseG is a sequence of triples
〈(x,p1,o1),(s2,p2,o2), ,(sk,pk,y)〉such thatoi=si+1,i =1, 2, ,k−1.
• Simple RDF Path: is an RDF Path if for alli,j,i 6= j impliesoi 6=oj i.e., no node is
repeated on the path.
LetV N (regular variables) and V P (path variables) be two pairwise disjoint sets of variables that are also disjoint fromI ∪L∪B.
• Triple Pattern: It is a tuple in(I∪L∪V N)×(I∪V N)×(I∪L∪V N). The set of all triple patterns isT.
• Path Triple Pattern: It is a triple pattern with a path variable in the predicate position. • Path Pattern Expression: It is like a SPARQL triple pattern except that it can contain
path variables in the predicate position. It can consist of a SPARQL graph pattern, a path triple pattern and some built-in path filter conditions.
• Regular Expression over a setX: ifx∈X, thenx,(x)∗,(x)+,(x)? are regular expressions. Ifx andy are regular expressions, thenx·y,x|y are also regular expressions. • T-Regular Expression: It is a regular expression over a triple pattern or an extended
regular expression of the form([s,·],p,[·,o])+where(s,p,o)a triple pattern. An ex-tended regular expression matches a path such that the subject of the first triple in the path iss and object of last triple iso,·matches arbitrary intermediate nodes on the path and all the predicates on the path arep.R(T)is the set of regular and extended regular expressions overT.
SPARQ2L defines aPath Built-in Conditionas an expression built fromI∪V P∪L∪R(T), logical operators(¬,∧), comparison operators(=,≤)and path built-in functions where path built-in functions are:
• containsAny:(V P, 2I)→B o o l e a n
• containsAll:(V P, 2I)→B o o l e a n
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
• isSimple:V P →B o o l e a n
• cost :V P →R
Given a variable ??P ∈V P, a constantc,C ⊆I is a set of IRIs,T P is a T-regular expression, path built-in conditions are:
• cost(??P)=c,containsAny(??P, C),containsAll((??P, C),containsPattern(??P, TP), and
isSimple(??P).
• IfB C1andB C2are path built-in conditions, then(¬B C1)and(B C1∧B C2)are path
built-in conditions.
SPARQ2L defines aPath Pattern Expressionrecursively as:
• a 3-tupleq ∈(I ∪V N ∪L)×V P×(I ∪V N ∪L)called a path triple pattern is a path pattern.
• if GP is a SPARQL graph pattern and PP is a path pattern then (PP AND GP) is a path pattern.
• if PP is an path pattern and F is a path built-in condition then (PP PATHFILTER F) is a path pattern.
A SPARQL graph pattern can be semantically defined as a function[[·]]where input is a pattern expression and output is a set of ’mappings’ where a ’mapping’µis a partial function fromV N toR D F T,R D F T =I∪L∪B.d o m(µ)is the subset ofV N in whichµis defined. 2R D F T is the set of possible tuples fromR D F T. SPARQ2L defines a ’pmapping’ω as a
partial function from(V P∪V N)to(2R D F T ∪R D F T)such thatω(v p ∈V P) =p∈2R D F T
andω(v n ∈ V N) =R D F T. For a path triple patternt p,ω(t p)is the tuple formed by substituting any variables v n ∈ V N ∪v p ∈ V P in t p according toω.d o m(ω) is the domain ofωand is the subset ofV P ∪V N. A mappingµis compatible with a pmapping
ωif whenx ∈d o m(µ)∩d o m(ω), thenµ(x)∈ω(x). The join of a set of mappingsΩand a set of pmappingsΘis defined asΩ. /Θ=µ∪ω|µ∈Ω,ω∈Θare compatible.
APath Pattern Solutionis the solution of a path pattern PP over D and denoted by
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
• [[t p]]D =ω|d o m(ω) =v a r(t p)andω(t p)forms a path in D
• [[(P P AN D G P)]]D= [[P P]]D. /[[G P]]D
A pmappingωsatisfies a built-in conditionF orω|=F for path patterns with PATH-FILTER expressions.I0is a subset of the set of IRIs andt r is a tp-regular expression.
• F is containsAny(??P, I’) and ??P∈dom(ω) and I’∩ω(??P)6=;. • F is containsAll(??P, I’) and ??P∈dom(ω) and I’⊆ω(??P).
• F is containsPattern(??P, tr) and ??P∈dom(ω) and ground(tr) is a subpath ofω(??P) . • F is isSimple (??P’) and ??P∈dom(ω) and for x, y∈ω(??P), x6=y.
• F is(¬F1),F1is a built-in condition,ω| 6=F1
• F is(F1F2),F1andF2are built-in conditions,ω|=F1andω|=F2
A few example queries using the SPARQ2L grammar are:Non-Simple Path QueryFind any feedback loops that involve the compound Methionine.
SELECT ??p
WHERE { ?x ??p ?x .
?z compound:name "Methionine" .
PathFilter(containsAny(??p, ?z))}
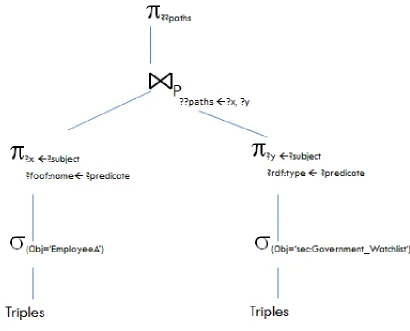
Path Query with Terminal Node Constraints Is EmployeeA connected in anyway to entities on the Government watchlist?
SELECT ??p
WHERE { ?x ??p ?y .
?x foaf:name "EmployeeA" .
?y rdf:type sec:Government_Watchlist . }
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
SELECT ??p
WHERE { ?x ??p ?y .
?x bio:name "MTB Surface Molecule" .
?y rdf:type bio:Cellular_Response_Event .
?z rdf:type bio:PI3K_Enzyme .
PathFilter(containsAny(??p, ?z))}
Path Query with Path Length ConstraintFind all close connections (<4 hops) between SalesPersonA and CIO-Y.
SELECT ??p
WHERE { ?x ??p ?y .
?x foaf:name "salesPersonA".
?y company:is_CIO ?z.
?z company:name "CompanyY" .
PathFilter( cost(??p) < 4 )}
Path query with path pattern constraint Find social relationships between potential jurors and a defendant.
SELECT ??p
WHERE { ?x ??p ?y .
?x foaf:name "defendantX" .
?y foaf:name "jurorY" .
PathFilter( containsPattern (??p, [?a, .]
foaf:knows [., ?b])+ )}
The SPARQ2L Query Evaluation Framework
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
the system of linear equations Mx=b is decomposed into two triangular matrices L and U. The system Ly=b (frontsolving) is solved first and then y is substituted in Ux=y to solve for vector x. The triangular systems L and U can be used to solve for different values of b. This allows for the computationally dominant LU decomposition phase to be reused for different problem instances. A variety of path problems can be solved by interpreting the sum and product operations appropriately. Solving a path problem instance using the triangular matrices involves processing each triangular matrix in a specific order. The SPARQ2L framework focuses on indexing and storing the contents of these matrices so that the system can skip processing submatrices that are irrelevant to a query.
The SPARQ2L system for multi-paradigm RDF querying includes support for pattern matching queries, path queries and keyword queries. The first step is to load RDF Schema and data documents into internal graph data structures. Then different preprocessing steps are performed on the data which produce relevant indexes on the data for each of the querying paradigms, for example, Pattern Matching Indexes stored in the Pattern Match Store and Path Index stored in the Path Store. The Query Processor Module comprises three different kinds of query processors for processing each type of query. A query, however, may be processed by multiple processors. For example, a path query may have some constraints that involve standard graph pattern matching.
The data preprocessing phase for path query processing involves construction, labeling and indexing of a graph’s path sequence. The LU decomposition phase is used to compute partial path summaries, which means that for certain pairs of nodes, some of the paths connecting the nodes are computed at this phase. The path summaries are a concise representation of path information as opposed to an enumerated listing of paths. Assuming that we have the following triples (x, p1, y), (x, p2, y), (y, p3, z) represented as labeled edges in an RDF graph, Paths from x to z can be summarized as (p1∪p2·p3). A triple of such a regular expression and the source and destination nodes can be referred as a P-Expression e.g. ((p1∪p2·p3), x, z). These p-expressions can be treated as strings for discussion purposes, but the SPARQ2L approach uses a more efficient implementation where p-expressions are represented using a binary encoding scheme that enables the path filtering step for path constraint evaluation to be performed efficiently using bit operations.
2.4. GENERALIZED GRAPH PATTERN MATCHING CHAPTER 2. BACKGROUND
v ∈V(G). Conversely,α−1(v)maps a node in G to an integer between 1 and N. At the end
of the LU decomposition, the elements of M satisfy one of the following conditions, for
u,v∈V(G):
• M[−1(u),−1(v)]for−1(u)≥−1(v)contains a p-expression representing exactly the paths
from u to v that do not contain any intermediate vertexw such that−1(w)>−1(v).
• M[−1(u),−1(v)]for−1(u)<−1(v)contains a p-expression representing exactly the paths
from u to v that do not contain any intermediate vertex w such that−1(w)<−1(u).
Preprocessing begins by initializingM[i,j]for 1≤i,j ≤N with a p-expression repre-senting a union of the set of edges between the nodesα(i),α(j). This union p-expression is then systematically updated to represent other paths that satisfy the above constraints. A naive algorithm for the LU decomposition phase runs inO(N3). The path sequence for G is
the sequence of p-expressions(Xi,ui,vi)where−1(ui)≤−1(vi)in increasing order on−1(ui)
is followed by the sequence of p-expressions(Xi,ui,vi)for−1(ui)>−1(vi)in decreasing order
onα(ui).
2.5. SOLVE ALGORITHM CHAPTER 2. BACKGROUND
In the path query processing phase, the Path Finder evaluates a query by successively re-trieving the relevant p-expressions from disk and composing them into larger p-expressions that compose the solution. Path Finder achieves this using the Path-Solve algorithm which begins by initializing a matrix which keeps track of the composed p-expressions and is filled as the algorithm proceeds.
2.5
Solve Algorithm
To be able to implement the support for generalized graph pattern matching we need to implement physical and logical operators integrated as part of the Jena framework. The physical operator would comprise of the algorithm that works on the data graph and the query and extracts the required information. We refer to a graph theoretical framework
[Tar81], that has been extended in[GA13]to an implementation framework for databases that allows to efficiently query graphs on disk.
Tarjan introduces an algorithm [Tar81]to find single-source path expressions, i.e. a regular expression P(s, v) for each vertex v which represents the set of all paths in directed graph G(V,E) from source vertex s to v, such thatσ(P(s,v))contains all paths from s to v. The algorithm works by dividing G into components, computing path expressions on the components by Gaussian elimination, and combining the solutions. The algorithm’s time complexity isO(mαt(m,n)), plus time to compute path expressions within the components, where n is the number of vertices in G, m is the number of edges in G, andαis a functional inverse of Ackermann’s function. If G is a reducible flow graph and each component of G is a single vertex, then the method requiresO(mα(m,n))time total. Gaussian elimination method consists of two steps: LU decomposition where matrix A is decomposed into L(lower triangular) and U(upper triangular); and frontsolving (Ly=b) and backsolving (Ux=y) to solve the system of linear equations Ax=b.
Given a path sequence(P1,v1,w1),(P2,v2,w2), ...(Pl,vl,wl), the single-source path
expres-sion problem for any source s can be solved by using the following propagation algorithm
SOLVE, where a path sequence for a directed graph G is a sequence(P1,v1,w1),(P2,v2,w2), ...(Pl,vl,wl)
such that (i)Pi is an unambiguous path expression expressed as(vi,wi)for 1≤i ≤l (ii) if
2.5. SOLVE ALGORITHM CHAPTER 2. BACKGROUND
sequence of indices 1≤i1<i2<...<ik ≤l and a unique partition ofp into non-empty
pathsp=p1,p2, ...,pk such thatpj ∈σ(Pij)for 1≤ j≤k.
Figure 2.3The algorithm SOLVE to solve single source path expression problem.[Tar81]
SOLVE is a generalization of the frontsolving-backsolving step in Gaussian elimination and its running time isO(n+l). To solve a single-source path expression problem on a graph G, SOLVE is applied once after constructing the path sequence. To solve an all-pairs path expression problem, SOLVE is applied n times, once for each possible source after constructing the path sequence. Step 1 of Gaussian elimination method is used to construct the path sequence of a graph, by using algorithm ELIMINATE. For dense graphs the time complexity isO(n3+m)and the space complexity isO(n2).
2.5. SOLVE ALGORITHM CHAPTER 2. BACKGROUND
Figure 2.4The algorithm ELIMINATE is used to pre-compute the path sequence for an input graph G whose vertices are numbered from 1 to n.[Tar81]
better performance than current existing graph navigational techniques due to reduced I/O. The existing graph navigational techniques require the decomposition of MSMD queries into multiple single-source or destination path subqueries, each of which is solved independently, and typically generate very poor I/O access patterns for large, disk-resident graphs and for MSMD path queries, such poor access patterns may be repeated if common graph exploration steps exist across subqueries.
2.6. APACHE JENA CHAPTER 2. BACKGROUND
2.6
Apache Jena
[Arc] [Jen]Apache Jena is a free and open source Java framework composed of different APIs interacting together to process RDF data, for building semantic web and Linked Data applications. The Jena API enables developers to extract data from and write to RDF graphs, which are represented as an abstract "model". Jena supports the serialization of RDF graphs to:
• A relational database • RDF/XML
• Turtle • Notation 3
2.6.1
Jena Architecture
Jena, at its core, stores information as RDF triples in directed graphs, and allows the applica-tion code to add, remove, store, manipulate and publish that informaapplica-tion. Jena comprises of a number of major subsystems with clearly defined interfaces between them.
Jena’s RDF API is used to access RDF triples and graphs and their various components. The API has support for adding and removing triples to graphs and basic graph pattern matching. Jena allows the developer’s code to read in RDF from external sources, files or URLs, and serialize a graph in correctly-formatted text form. Input as well as output support most of the commonly-used RDF syntaxes. Typical abstractions in this API are:
• Resource representing an RDF resource • Literal representing data values
2.6. APACHE JENA CHAPTER 2. BACKGROUND
2.6. APACHE JENA CHAPTER 2. BACKGROUND
Jena supports a rich programming interface to Model, but internally it stores the RDF graph in a simpler abstraction named Graph. This allows Jena to use a variety of different storage strategies that conform to the Graph interface equivalently. Jena can store a graph as an in-memory store, as a persistent store using a custom disk-based tuple index, or in an SQL database. The graph interface can be extended to connect other stores like LDAP to Jena, by writing an adapter that allows the calls from the Graph API to work on that store. Jena’s inference API supports a vital feature of semantic web applications, which is that the semantic rules of RDF, RDFS and OWL can be used to infer information that is not explicitly stated in the graph. For example, if Z is a descendant of Y, and Y is a descendant of X, then by implication Z is a descendant of X. Jena’s inference API enables applications to add these entailed triples in the store just as if they had been added explicitly. The inference API provides various rule engines to perform this, either using the built-in rule sets for OWL and RDFS, or using application custom rules. The inference API can also be connected up to an external reasoner to perform inference with specialized reasoning algorithms.
The Jena SPARQL API handles SPARQL, the RDF query language, for both query and update. Jena conforms to all published standards, and tracks the revisions and updates in the under-development areas of the standard.
The Jena Ontology API supports both ontology languages for RDF, RDFS and OWL. Ontologies, which are formal logical descriptions or models of entities and interactions of some areas of real life, are essential to many semantic web applications. Ontologies can be shared with other developers and researchers, which makes it a good basis for building linked-data applications. The API supports methods that know about the richer representation forms available to applications through OWL and RDFS.
The Java API enables applications to access the above capabilities. Fuseki, a data pub-lishing server, can present and update RDF models over the web using SPARQL and HTTP, which is a common requirement of modern applications. Jena also has other components like command-line tools and specialized indexes for text-based lookup.
CHAPTER
3
APPROACH
CHAPTER 3. APPROACH
There are various possible approaches to execute generalized graph pattern matching queries on graph databases. Regular Path Queries (RPQs) are common in querying graphs where the user might want to find pairs(x,y)of nodes such that there exists a path fromx
to y whose sequence of edge labels matches some specified pattern in the query[Woo12]. An RPQ is a regular expression R on the node or edge labels of a graph G, whose result is the set of all acyclic paths in G and the concatenation of labels of the paths defines R. Evaluating regular path queries on graph databases is an NP hard problem, which can be illustrated by an example. Assume a graph of researchers, with nodes labeled P (Professor) or T (Student), and directed edges labeled S (Supervised work) or J (Joint work). The query
P(J P)(J P)? would find all paths between a professor and direct or indirect co-workers. The query(P S)(P S) + (P|T)would find all paths between a professor and his doctorate descendants. Assume a few more nodes labeled N (Nobel prize) and A (Sigmod award) and edges labeled H (Honored) to connect the researchers to the awards, then the query
(P S) +P H N would find doctorate predecessors of all Nobel prize winners, and the query
(P S) +P H(N|A)would find doctorate predecessors of any prize winner[KL12].
Path queries have been studied in detail for XML, where the predominant approach is to use automata. In this approach both the graph and the query are represented as automata, and the intersection automaton is the subgraph specified by the query. To harness this approach the graph needs to be translated into a DFA, which may need exponential construction time and can be of exponential space. Research shows that automata-based regular path query evaluation works well for XML trees but its space consumption is huge on general graphs. Moreover automata-based approaches do not use specific properties of the data graph to decrease query execution time[KL12]. This approach is used by many graph databases like Neo4j, but there are limitations of this approach, some being that it is not a very flexible solution and requires limitations to be imposed on the nodes and edges in the query. This methodology has also been extended in some research works[Bon15]to learn path queries on graphs defined by regular expressions based on user examples.
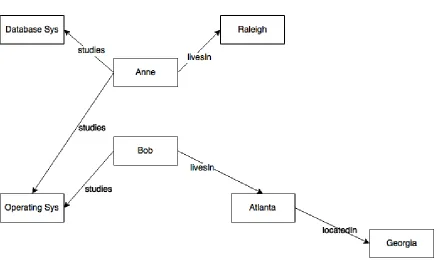
A typical query Q may want to find students who study bothDatabase Systemsand
Operating Systems. Such a query is a simple Conjunctive Query (CQ) that returns a set of nodes as the answer[Woo12]. Using the format illustrated in[Woo12], this query can be expressed as
CHAPTER 3. APPROACH
Figure 3.1Data graph to illustrate query types.
Where x is a variable andstudies,Database SysandOperating Sysare constants. An RPQ using the same graph could be a query to find pairs of student x and place y such that x lives in y or x lives in a place that is located in y. This query can be represented using the regular expressionlivesIn . locatedIn*.
Conjunctive Regular Path Queries (CRPQs) are a combination of CQs and RPQs, for example, the above two queries can be combined to form a query that is represented as follows
ans(x,y)<- (x, studies, Database Sys),(x, studies, Operating Sys),(x, (livesIn . locatedIn*), y)
CHAPTER 3. APPROACH
We propose the idea of generalized graph pattern matching as queries where specifying the edges is not required, and general queries like ?x??p?y would be able to find all paths between nodes x and y. Also, in path queries we would like include the paths themselves as output of the query. In our research, we address these issues.
Figure 3.2The intuition behind the integration of the path operator is to decompose the path query and use the existing Jena framework to execute graph pattern matching, and use a path algebraic approach to extract paths.
3.1. GENERIC SPARQL QUERY ENGINE CHAPTER 3. APPROACH
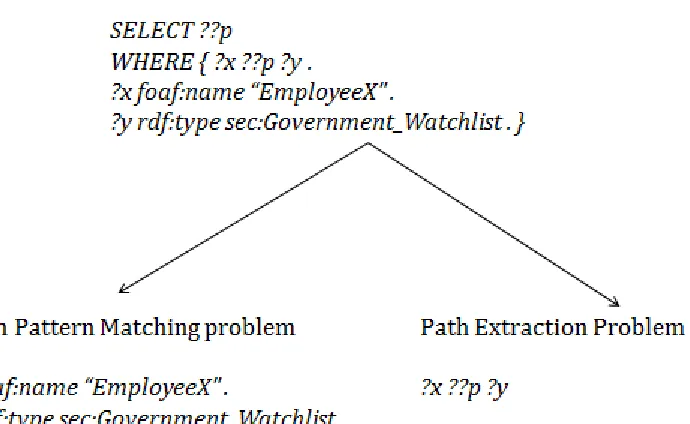
SELECT ??p
WHERE { ?x ??p ?y .
?x foaf:name "EmployeeA" .
?y rdf:type sec:Government_Watchlist . }
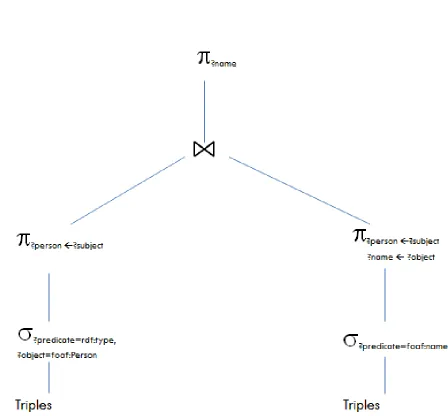
is decomposed into two parts. The left branch illustrates the triple patterns which are evaluated using the existing graph pattern matching support for SPARQL. The right branch illustrates the path pattern ?x ??p ?y for which we implement the path operator that uses a path algebraic algorithm to compute path expressions. The output of the query consists of all paths between bindings for variables ’x’ and ’y’.
In our research we explore how to use the relational query infrastructure that is sup-ported by the open source semantic web framework Jena, and extend it such that the traditional relational execution infrastructure can be used for the fixed conjunctive part of the query and integrate a new operator in the Jena API to evaluate navigational queries on disk resident databases. The significant advantage of this is that it uses the path aggregation mechanism as opposed to the path enumeration method i.e. explicitly enumerate paths, which is cumbersome in case of infinite length paths.
3.1
Generic Sparql Query Engine
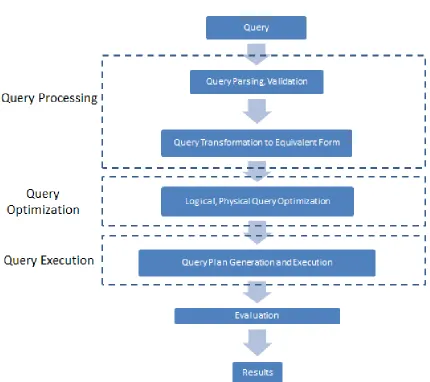
[MR12]A generic query engine would generally comprise of Query Processing, Optimization and Execution steps as illustrated by the following flowchart, which depicts the internal structure and transformation of the SPARQL query during the evaluation process.
Following are the steps taken by the query engine to evaluate the query:
3.1. GENERIC SPARQL QUERY ENGINE CHAPTER 3. APPROACH


![Figure 2.4 The algorithm ELIMINATE is used to pre-compute the path sequence for an inputgraph G whose vertices are numbered from 1 to n.[Tar81]](https://thumb-us.123doks.com/thumbv2/123dok_us/1520872.1186404/43.612.96.526.109.293/figure-algorithm-eliminate-compute-sequence-inputgraph-vertices-numbered.webp)
![Figure 2.5 The Jena architecture illustrating interaction between the APIs.[Arc]](https://thumb-us.123doks.com/thumbv2/123dok_us/1520872.1186404/45.612.81.537.148.594/figure-jena-architecture-illustrating-interaction-apis-arc.webp)