International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2018 IJSRCSEIT | Volume 3 | Issue 4 | ISSN : 2456-3307
Modern Hierarchical, Agglomerative Clustering Algorithm Based
on Various - Widths
M. Srilekha, K. Harish, B. Phani Krishna
Department of MCA Narayana Engineering College Nellore, India
ABSTRACT
Hierarchicalclusteringalgorithms are either top-down or base up. Base up algorithms regard each document as a singleton cluster. In this paper proposed a tentatively assess the execution of various worldwide standard capacities with regards to hierarchical agglomerative clusteringalgorithms and think about the clustering aftereffects of segment algorithms for every last one of the measure capacities The proposed strategy fabricates the arrangement by at first allotting every point to its own particular cluster and afterward more than once choosing and merging pairs of clusters, to acquire a solitary comprehensive cluster. The key parameter in agglomerative algorithms is the strategy used to decide the match of clusters to be converged at each progression. Exploratory outcomes acquired on manufactured and genuine datasets show the adequacy of the proposed different width cluster strategy.
Keywords: Change detection (CD), hierarchical clustering, hyperspectral (HS) images, multiple changes, multitemporalanalysis, remote sensing.
I.
INTRODUCTIONClusteranalysis separates information into gatherings (clusters) that are significant, helpful, or both. On the off chance that significant gatherings are the objective, at that point the clusters should catch the normal structure of the information. Now and again, notwithstanding, cluster examination is just a helpful beginning stage for different purposes, for example, information synopsis. Regardless of whether for understanding or utility, cluster examination has since a long time ago assumed a vital part in a wide assortment of fields: brain research and other sociologies, science, insights, design acknowledgment, data recovery, machine learning, and information mining. Clusteranalysis gives a reflection from singular information articles to the clusters in which those information objects live. Furthermore, some clustering procedures describe each cluster regarding
amongst q and each protest in O. These outcomes in high computational cost. To address this, an expansive collection of research has concentrated on pre-preparing the informational index (i.e., building a list) with an intend to figure k-NNs by getting to just a piece of the informational collection. The methods can be inexactly ordered into two classifications: i) tree-based lists; ii) level records.
II.
Related WorkAuthors proposed a novel separation based anomaly location algorithm, named DOLPHIN, taking a shot at plate inhabitant datasets and whose I/O cost relates to the cost of successively perusing the info dataset record twice, is displayed. It is both hypothetically and exactly demonstrated that the primary memory use of DOLPHIN adds up to a little part of the dataset and that DOLPHIN has direct time execution as for the dataset estimate. DOLPHIN picks up proficiency by normally consolidating in a bound together composition three systems, to be specific the choice arrangement of articles to be kept up in fundamental memory, utilization of pruning tenets, and similitude look strategies. Authors examined a separation based exception location strategy that finds the best anomalies in an unlabelled informational collection and gives a subset of it, called anomaly discovery settling set, that can be utilized to foresee the outlines of new inconspicuous articles, is proposed. The understanding set incorporates an adequate number of focuses that allows the recognition of the best anomalies by considering just a subset of all the combine insightful separations from the informational index. Authors characterizing anomalies by their separation to neighbouring information indicates has been demonstrated be a viable non-parametric way to deal with exception location. As of late, numerous examination endeavours have taken a gander at growing quick separation based anomaly discovery algorithms. A few of the current separation based exception location algorithms report log-straight time
execution as an element of the quantity of information focuses on numerous genuine low-dimensional datasets. In any case, these algorithms can't convey a similar level of execution on high-dimensional datasets, since their scaling conduct is exponential in the quantity of measurements. The authors exhibited a RBRP quick algorithm for mining separation based anomalies, especially focused at high-dimensional datasets. RBRP scales log-directly as a component of the quantity of information focuses and straight as an element of the quantity of measurements. Authors proposed a straightforward settled circle algorithm that in the most pessimistic scenario is quadratic can give close direct time execution when the information is in irregular request and a basic pruning guideline is utilized. To test the algorithm on genuine high-dimensional informational indexes with a great many illustrations and demonstrate that the close direct scaling holds more than a few requests of extent. Authors had considered the methods for Nearest Neighbour order concentrating on; components for surveying comparability (separate), computational issues in recognizing nearestneighbours and instruments for decreasing the measurement of the information. Authors proposed two novel procedures: (i) a programmed distinguishing proof of reliable and conflicting conditions of SCADA information for any given framework, and (ii) a programmed extraction of vicinity identification rules from recognized states. Amid the ID stage, the thickness factor for the k-nearestneighbours’ of a perception is adjusted to process its irregularity score. At that point, an ideal irregularity limit is computed to isolate conflicting from reliable perceptions. Amid the extraction stage, the outstanding settled width clustering procedure is reached out to extricate vicinity recognition rules, which frames a little and most-illustrative informational index for both conflicting and reliable practices in the preparation informational collection.
III.
Proposed Algorithmpairs of clusters (in this way refreshing the between cluster separations) until the point that all focuses are a piece of one hierarchically built cluster. In this work incorporates three errands, for example, i) Data Cleaning; ii) Cluster-Width Learning; iii) Agglomerative Hierarchical clustering. The proposed stage engineering appears in beneath Fig. 1.
A. Data Cleaning: The information cleaning large measure of unimportant sections, which are required to be expelled from the web log for arrangement before information mining. To deficient the lacking property estimations, without specific qualities of intrigue, or containing just total information. The pre-handling strategy takes after the information transformation approach that encourages of information clustering. The unsupervised crude dataset is first apportioned into three gatherings: (1) a limited arrangement of items, (2) the arrangement of traits (highlights, factors) and (3) the area of quality.
Fig: 1 Proposed Architecture Flow diagram
For every gathering in the dataset, a choice framework is developed. Every choice framework is along these lines split into two sections: the preparation dataset and the testing dataset. Each preparation dataset utilizes the relating input highlights and fall into two classes: typical (+1) and abnormal (−1).
B. Cluster-Width LearningThe pre-processed information is the capacity of k-nearestneighbours for the protest Hi, clsWidth be the capacity registering the width (radius) of nearestneighbour’s esteem, where the width is the separation between
the query Hi and the most distant query among its neighbours. To locate the proper worldwide width approach haphazardly draw a couple of items from D, H={H1,H2,… ,Hr} and for each arbitrarily chose query, the range of its k-nearestneighbours is processed, and the normal is utilized as a worldwide width for D as follows:
The learning procedure segments an informational index into various clusters utilizing a vast width to determine the issue of clustering the meagrely circulated protests in n-dimensional space. In any case, vast clusters from thick zones will be made, for example, clusters C2 and C3. In this manner, every substantial cluster whose size surpasses a client characterized edge (most extreme cluster estimate) will be isolated into various clusters utilizing a width that suits the thickness of that cluster. This procedure proceeds until the point when the sizes of all clusters are not exactly or equivalent to the client characterized limit (Mean and Trail Error technique). C. Agglomerative Hierarchical clustering Agglomerative various levelledclustering is a base up clustering technique where clusters have sub-clusters, which thusly have sub-clusters, and so on. The great case of this is species scientific classification. Quality articulation information may likewise display this various levelled quality (e.g. neurotransmitter quality families). Agglomerative various levelledclustering begins with each and every protest (quality or test) in a solitary cluster. At that point, in each hierarchical cycle, it agglomerates (merges) the nearest match of clusters by fulfilling some comparability criteria, until the point when the greater part of the information is in one cluster. The order inside the last cluster has the accompanying properties:
Clusters created in beginning periods are settled in those produced in later stages. Clusters with various sizes in the tree can be
IV.
Pseudo CodeStep 1: Assign each object a different cluster.
Step 2: Calculate the different width cluster for each nearestneighbour utilizing eq. (1).
Step 3: Construct a separation network utilizing the separation esteems.
Step 4: Look for the combine of clusters with the most limited separation.
Step 5: Remove the combine from the framework and union them.
Step 6: Evaluate all separations from this new cluster to every single other cluster, and refresh the network. Step 7: End.
V.
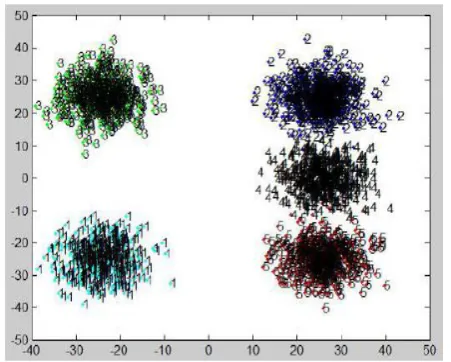
ResultsFor evaluating the proposed work, in Fig. 2, the cluster result of original DARPA data set [9]. This sample contains 52,488 objects. 241 objects are labelled as attacks while the rest are labelled as normal.
Fig 2: Agglomerative Hierarchical Cluster Result
VI.
ConclusionIn this paper, proposed an ideal Agglomerative Hierarchical Cluster approach in light of different widths clustering called AHWC. This approach can deliver minimized and all around isolated clusters from high dimensional information of different
circulations. The proposed technique is conceivable to find the distinction among covering clusters connecting among the information. Besides, the proposed approach is composed in an unsupervised route with distinction limitations. In future work, we mean to upgrade the Clustering algorithm to build up the exploratory strategies for non-direct advancement to control the development of tree traits of the outcome unsupervised data.
VII.
REFERENCES
[1]. P. Cunningham and S. J. Delany, “k-nearest neighbour classifiers,” Multiple Classifier Systems, pp. 1–17, 2007.
[2]. A. Almalawi, X. Yu, Z. Tari, A. Fahad, and I. Khalil, “An unsupervised anomaly-based detection approach for integrity attacks onscadasystems,” Comput. Security, vol. 46, pp. 94–110, 2014.
[3]. A. Shintemirov,W. Tang, and Q. H. Wu, “Power transformer fault classification based on dissolved gas analysis byimplementingbootstrap and genetic programming,” IEEE Trans. Syst., Man Cybern. C, Appl. Rev., vol. 39, no. 1, pp. 69–79, 2009. [4]. M. V. Mahoney and P. K. Chan, “An analysis of
the 1999 darpa/lincoln laboratory evaluation data for network anomaly detection,” inProc. 6th Int. Symp. Recent Adv. Intrusion Detection, 2003, pp. 220–237
[5]. B. S. Kim and S. B. Park, “A fast k nearest neighbour finding algorithm based on the ordered partition,” IEEE Trans. Pattern Anal. Mach.Intell., vol. TPAMI-8, no. 6, pp. 761–766, Jun. 1986.
[6]. G. Shakhnarovich, T. Darrell, and P. Indyk, “Nearest-neighbour methods in learning and vision,” IEEE Trans. Neural Netw.,vol. 19, no. 2,p. 377, Feb. 2008.
[7]. F. Angiulli and F. Fassetti, “DOLPHIN: An efficient algorithm for mining distance-based outliers in very large datasets,” ACMTrans.Knowl. Discovery Data, vol. 3, no. 1, p. 4, 2009.
IEEE Trans. Knowl. Data Eng., vol. 18, no. 2,pp. 145–160, Feb. 2006.
[9]. A. Ghoting, S. Parthasarathy, and M. E. Otey, “Fast mining of distance-based outliers in high-dimensional datasets,” DataMining Knowl.Discovery, vol. 16, no. 3, pp. 349–364, 2008.
[10]. S. D. Bay and M. Schwabacher, “Mining distance-based outliers in near linear time with randomization and a simple pruning rule,”inProc. 9th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2003, pp. 29– 38.
[11]. M. V. Mahoney and P. K. Chan, “An analysis of the 1999 darpa/lincoln laboratory evaluation data for network anomaly detection,” in Proc. 6th Int. Symp. Recent Adv. Intrusion Detection, 2003, pp. 220–237.
[12]. N. Roussopoulos, S. Kelley, and F. Vincent, “Nearest neighbour queries,” in Proc. ACM SIGMOD Int. Conf. Manage. Data, San Jose, CA, USA, May. 22–25, 1995, pp. 71–79.
[13]. G. R. Hjaltason and H. Samet, “Distance browsing in spatial databases,” ACM Trans. Database Syst., vol. 24, no. 2, pp. 265–318, 1999.
[14]. R. Kohavi, “A study of cross-validation and bootstrap for accuracy estimation and model selection,” in Proc. Int. Joint Conf. Artif. Intell., 1995, vol. 14. pp. 1137–1145.
[15]. A. Frank and A. Asuncion. (2013). UCI machine learning repository [Online]. Available: http://archive.ics.uci.edu/ml
[16]. A. Almalawi, Z. Tari, I. Khalil, and A. Fahad, “SCADAVT-a framework for SCADA security testbed based on virtualization technology,” in Proc. IEEE 38th Conf. Local Comput. Netw., 2013, pp. 639–646.
[17]. A. Vergara, S. Vembu, T. Ayhan, M. A. Ryan, M. L. Homer, and R. Huerta, “Chemical gas sensor drift compensation using classifier ensembles,” Sens. Actuators B: Chemical, vol. 166, pp. 320–329, 2012.
[18]. I. Rodriguez-Lujan, J. Fonollosa, A. Vergara, M. Homer, and R. Huerta, “On the calibration of sensor arrays for pattern recognition using the minimal number of experiments,” Chemometrics Intell. Laboratory Syst., vol. 130, pp. 123–134, 2014.
Authors
M.Srilekha is currently pursuing
her post graduation (Master of
computer applications) in
Narayana Engineering college
affiliated to JNTUA University
india. she had a membership in CSI(Computer
Society of India)
K.Harish is currently pursuing his post graduation (Master of
computer applications) in
Narayana Engineering college affiliated to JNTUA University india. He had a membership in CSI(Computer Society of India)