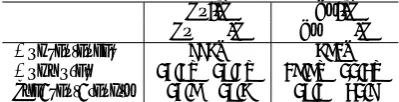Bayesian Subtree Alignment Model based on Dependency Trees
Toshiaki Nakazawa Sadao Kurohashi Graduate School of Informatics, Kyoto University
Yoshida-honmachi, Sakyo-ku Kyoto, 606-8501, Japan
[email protected] [email protected]
Abstract
Word sequential alignment models work well for similar language pairs, but they are quite inadequate for distant language pairs. It is difficult to align words or phrases of distant languages with high ac-curacy without structural information of the sentences. In this paper, we pro- pose a Bayesian subtree alignment model that in-corporates dependency relations be- tween subtrees in dependency tree struc- tures on both sides. The dependency re- la-tion model is a kind of tree-based re- or-dering model, and can handle non-local reorderings, which sequential word-based models often cannot handle properly. The model is also capable of handling multi-level structures, making it possible to find many-to-many correspondences automat-ically without any heuristic rules. The size of the structures is controlled by non-parametric Bayesian priors. Experimen-tal alignment results show that our model achieves 3.5 points better alignment error rate for English-Japanese than the word sequential alignment model, thereby ver-ifying that the use of dependency informa-tion is effective for structurally different language pairs.
1 Introduction
Alignment accuracy is crucial for providing high quality corpus-based machine translation systems because translation knowledge is acquired from an aligned training corpus. For similar language pairs, alignment accuracy is high, and the state-of-the-art word alignment tool GIZA++ has a smaller than 10% alignment error rate (AER) for French-English. GIZA++ is an implementation of the alignment models called the IBM models (Brown
et al., 1993), which handle sentences as sequences of words, usually followed by some heuristic sym-metrization rules to combine the alignment results in both directions. Since the accuracy is to some extent good for some language pairs, many re-searchers focus not on alignment, but on transla-tion with more linguistic informatransla-tion incorporated in the models. Phrase-based SMT (Koehn et al., 2003) uses units larger than words, whereas Hi-ero (Chiang, 2005) used a kind of sentence struc-ture. Various other studies tried incorporating additional linguistic knowledge such as syntactic trees (Chiang, 2010), dependency trees (Menezes and Quirk, 2008), or packed-forests (Tu et al., 2010) in their translation models. Note that all these works are based on the word sequential alignment models.
However, for distant language pairs such as English-Japanese or Chinese-Japanese, the word sequential model is quite inadequate (about 20 to 30 % AER), and therefore it is important to im-prove the alignment accuracy itself. The differ-ences between languages can be seen in Figure 1, which shows an example of English-Japanese. The word or phrase order is quite different for these languages. Another important point is that there are often many-to-one or many-to-many cor-respondences. For example, the Japanese noun phrase “ ” is composed of three words, whereas the corresponding English phrase consists of only one word “photodetector”, and the English function word “for” corresponds to two Japanese function words “ ”. In addition, there are ba-sically no counterparts for the English articles (a, an, the). Figure 2 shows the alignment results from bi-directional GIZA++ together with a combina-tion heuristic called grow-diag-final-and1 for the same sentence pair given in Figure 1. The system failed to align some words in the Japanese noun
1This is trained on the same corpus used in Section 4.
phrase, and incorrectly aligned “the↔ “. The word sequential model is prone to many such er-rors even for short simple sentences of a distant language pair.
Even if the word order differs greatly between languages, phrase dependencies tend to hold be-tween languages. This is also true in Figure 1. Therefore, incorporating dependency analysis into the alignment model is useful for distant language pairs. Cherry and Lin (2003) proposed a model that uses a source side dependency tree structure and constructs a discriminative model. However, the drawback is that the alignment unit is the word, and thus, it can only find one-to-one alignments. The capability of generating many-to-many corre-spondences is also important because one or more words often correspond to more than one word on the other side.
Nakazawa and Kurohashi (2009) also proposed a model focusing on dependency relations. They modeled phrase dependency relations in depen-dency trees on both sides. The model is also capa-ble of estimating many-to-many correspondences automatically without any heuristics through max-imum likelihood estimation. One serious draw-back of their model is that it tends to acquire in-correct larger subtrees. For models that can han-dle multiple levels (or sizes) of structures, larger structures always defeat smaller ones in maximum likelihood estimation, and the best solution is to align one sentence as a structure with the other for all sentence pairs. Although Denero et al. (2008) solved this degeneracy by placing a Dirich-let process prior over the parameters that can con-trol the size of phrases properly, their Bayesian model again only handles sentences as sequences of words. In this paper, we take advantage of the two studies by Nakazawa et al. and Denero et al., and propose a Bayesian subtree alignment model based on dependency trees to improve alignment accuracy for distant language pairs.
2 Dependency Tree-based Alignment Model
Our model is an extension of the one proposed by Denero et al. (2008). Two main drawbacks of the previous model are the lack of structural informa-tion and a naive distorinforma-tion model. For similar lan-guage pairs such as French-English (Marcu and Wong, 2002) or Spanish-English (DeNero et al., 2008), even a simple model that handles sentences
ཷ
ග
⣲Ꮚ
䛻
䛿
䝣䜷䝖
䝀䞊䝖
䜢
⏝䛔䛯
A
photogate
is
used
for
the
photodetector
(accept) (light) (device)
(photo) (gate)
(used) (ni) (ha)
(wo)
Figure 1: Example of dependency trees and align-ment of subtrees. The root of the tree is placed at the extreme left and words are placed from top to bottom.
Figure 2: Alignment results from bi-directional GIZA++. Black boxes depict the system output, while dark (Sure) and light (Possible) gray cells denote gold-standard alignments.
as a sequence of words works adequately. This does not hold for distant language pairs such as English-Japanese or Chinese-Japanese, in which word orders differ greatly. We incorporate de-pendency relations of words into the alignment model and define the reorderings on the word de-pendency trees. Figure 1 shows an example of the dependency trees for Japanese and English.
2.1 Generative Story Description
Similar to the previous works (Marcu and Wong, 2002; DeNero et al., 2008), we first describe the generative story for the joint alignment model.
1. Generate`concepts from which subtree pairs
are generated independently.
Here, subtrees are equivalent to phrases in the pre-vious works. One subtree in a concept can be NULL, which represents an unaligned subtree. We restrict the unaligned subtrees to be composed of exactly one word, because of our model simplicity (NULL-alignment restriction).
The number of concepts`is parameterized
us-ing a geometric distribution:
P(`) =pc·(1−pc)`−1. (1)
Each concept ci generates a subtree pair hei, fii
from an unknown distribution θT, and then they
are combined in each language. We denote the combinations of subtrees in English as DE =
{(j→k)}, where(j→k)denotes that subtreeej
depends on subtreeek, and in the foreign language
asDF.Drefers toDE andDF as a whole.
With these notations, the joint probability for a sentence pair is defined as:
P({he, fi}, D) =P(`)·P(D|{he, fi})· ∏
he,fi
θT(he, fi).
(2) 2.2 Subtree Generation
When generating subtrees, we first decide whether to generate an unaligned subtree (with probabil-itypφ) or an aligned subtree pair (with probability
1−pφ). DeNero et al. (2008) used pφ = 10−10
to strongly discourage NULL alignment, but this is not reasonable for some language pairs. Tak-ing Japanese and English as an example, English determiners (a, an, the) and Japanese case mark-ers (ha,ga,wo, etc.) rarely have counterparts. In addition, if the corpus is less clean and sentence pairs often contain a different amount of informa-tion, the strict restriction may lead to alignment errors. Therefore, we usepφ= 0.33.
Aligned subtree pairs are generated from an un-known probability distribution θA, which obeys
the Dirichlet process (DP):
θA(he, fi) ∼ DP(MA, αA), (3)
whereMAis the base distribution andαAis a
con-centration parameter. The base distribution is de-fined as:
wherePW Ais the IBM model1 likelihood (Brown
et al., 1993), and nf and ne are the numbers of
word types in each language. θAgives a non-zero
weight to aligned subtree pairs only.
Unaligned subtrees are generated from another unknown probability distributionθN:
θN(he, fi) ∼ DP(MN, αN)
θN gives a non-zero weight to unaligned subtrees
only. Note that unaligned subtrees are always composed of only one word in our model. Finally,
θT can be decomposed as:
θT(he, fi) =pφθN(he, fi) + (1−pφ)θA(he, fi).
(6)
2.3 Dependency Relation Probability
Instead of the naive reordering model in the pvious work, our model considers dependency re-lations between subtrees and assigns a weight to each relation. Suppose subtree fj depends on
subtree fk (parent subtree), which means (j → k) ∈ DF, and both fj and fk are aligned
sub-trees. Their counterparts, ej andek respectively,
are somewhere on the dependency tree of the other side. We can assume thatej tends to depend onek
because the dependencies between concepts hold across languages. The dependency relation proba-bility reflects this tendency.
Formally, we extract a tuple
(N(fj), rel(fj, fj0)) for subtree fj, and
as-sign the dependency relation probability to that tuple. For unaligned subtrees, the dependency relation probability is not taken into consideration. If the parent subtree is an unaligned subtree, we ascend the dependency tree to the root node until an aligned subtree is found. We call the nearest aligned subtree a pseudo parent. The pseudo parent for subtree fj is denoted as fj0, and the
number of unaligned subtrees from fj to fj0 is
denoted as N(fj). We consider an imaginary
root node as a pseudo parent for the root subtree. For example, the parent subtree of “
the other side. Therefore we introduce a pseudo parent to capture the relations.
Functionrel(fj, fj0))returns a dependency
re-lation between the counterparts of the two argu-ments. Note that the counterparts of fj and fj0
areej andej0, respectively. We express a
depen-dency relation as the shortest path from one sub-tree to another. For simplicity, we indicate the path with a pair of non-negative integers, where the first is the number of steps going up (U p) the
dependency tree and the other is the number going down (Down). It also requires one additional step
for going through unaligned subtrees. For exam-ple, in Figure 1, traveling from “A photogate” to “photodetector” requires 1 step going up (to reach “is used”) and 2 steps going down (via “for”), so the dependency relation is(U p, Down) = (1,2). Consequently, the tuple is represented as a triplet of non-negative integersRf = (N, U p, Down).
The dependency relation probabilities for the foreign language side are drawn from an unknown probability distribution θf e and for the English
side fromθef, with both obeying the DP:
θf e(Rf) ∼ DP(Mf e, αf e)
Mf e(Rf) = pf e·(1−pf e)N+U p+Down−1
θef(Re) ∼ DP(Mef, αef)
Mef(Re) = pef·(1−pef)N+U p+Down−1.
(7) Using the notations and definitions above, the dependency tree-based reordering model
P(D|{he, fi})is decomposed as:
P(D|{he, fi}) = ∏
he,fi
θf e(Rf)·θef(Re). (8)
3 Model Training
We train the model by means of a collapsed Gibbs sampling, which has been used in some recent NLP works (DeNero et al., 2008). In a Gibbs sam-pling, we first need to initialize the states of the training data, such as the boundaries between sub-trees and their alignments, and also initialize the latent variables according to the initial states of the data. Starting with the initial state, we gen-erate many samples in order from the last state by changing a small local point. Normalizing the counts in the samples yields the parameter estima-tions.
3.1 Initialization
We initialize the states of the training data by heuristically merging bi-directional alignment
re-sults of the standard word alignment tool GIZA++. Many machine translation studies use heuristics to combine the two alignment results, one of which is called grow-diag-final-and (Koehn et al., 2007). Our heuristic is similar to this, but the difference is that we combine the two results based on de-pendency trees, and not on word sequences. The initialization is carried out by the following steps:
1. Take the intersection of the two results.
2. Add alignment points connected to at least one accepted point in terms of the depen-dency tree (corresponds to grow-diag).
3. Add alignment points between two unaligned words (corresponds to final-and).
Initial boundaries of subtrees and their alignments, and also the counts of subtree pairs and depen-dency relations are thus acquired.
3.2 Sampling Operators
Our sampler uses three operators repeatedly to generate samples. The operators are illustrated in Figure 3. A solid circle represents a single word, while a subtree is depicted as the part surrounded by a dotted line. Alignment links between subtrees are represented by broken lines.
Each application of an operator generates one new sample, and of course we could use all the generated samples. However, successive samples are almost the same, except for one local part. It is no use keeping all the samples, so we keep only one sample, which is the final outcome after ap-plying all the operators to all the possible points in all the sentence pairs in the training corpus.
SWAP
The SWAP operator exchanges the counterparts of two subtrees with each other. Boundaries between subtrees and the number of aligned subtrees in the sentence pair are fixed. There are two cases for SWAP:
1. Both of the subtrees are aligned (SWAP-1).
2. One of the two subtrees is unaligned and the other is composed of only one word (SWAP-2).
NULL
NULL SWAP-1
SWAP-2
NULL NULL TOGGLE
NULL
NULL EXPAND-1
EXPAND-2
Figure 3: Illustration of the operators.
TOGGLE
The TOGGLE operator adds or removes an align-ment. If fj and ek are both unaligned subtrees,
TOGGLE links these two subtrees. Alternatively, iffjandejare aligned, TOGGLE cuts the link and
makes each of the subtrees unaligned. Because of the NULL-alignment restriction, TOGGLE does nothing iffj orej is composed of more than one
word. Boundaries between subtrees are fixed. An illustration of the TOGGLE operation is shown in the middle of Figure 3.
EXPAND
The EXPAND operator expands or contracts an aligned subtree. If an unaligned subtree is next to an aligned one, EXPAND tries to merge the un-aligned and un-aligned subtrees. It also tries to ex-clude a marginal node from a subtree, and to make the excluded node unaligned. There are two cases for EXPAND:
1. A node is added to a subtree as a new leaf node, or a leaf node of a subtree is excluded (EXPAND-1).
2. A node is added to a subtree as the new root node, or the root node of a subtree is excluded (EXPAND-2).
EXPAND-1 does not have any restrictions on its operation. However, for EXPAND-2, if the root
node has more than one child node inside the sub-tree, it cannot exclude the root node, because the subtree will be divided into two subtrees by the exclusion, and it is impossible to return to the pre-vious state. Operators in a Gibbs sampler must be able to return the same status by immediately re-applying the same operator to the same point. An illustration of the EXPAND operation is shown in Figure 3.
3.3 Computational Complexity and Parallel Sampling
The distortion model of the previous work does not consider any relations to neighboring phrases, so any operation does not affect the distortions of neighboring phrases. On the contrary, our pro-posed model considers the relations, and this leads to an increase in the computational complexity for one operation. For example, swapping two aligned subtree pairs requires re-calculation of the depen-dency relation probabilities for not only the four focused subtrees, but also subtrees whose pseudo parent is one of the focused subtrees. This is the same for the TOGGLE operation.
To make matters worse, the EXPAND opera-tor requires much more. All the subtrees that tra-verse the locally changed subtree, 1) in finding a pseudo parent, and 2) in finding the dependency relations, need re-calculation of the dependency relation probabilities, because the number of steps (N,U pandDown) will change.
This increase in computational complexity makes the training time much longer, so that it is impossible to train using a single CPU. To alle-viate this problem somewhat, we divide the train-ing data into several parts and execute sampltrain-ing in parallel. The overall flow of model training is summarized as follows:
1. Initialize the training corpus and current counts of subtree pairs and dependency rela-tions, and divide the corpus into several sec-tions.
2. Start sampling in parallel using the same cur-rent counts, and generate one sample from each section. A sample is the final state of the section.
4. Go back to step 2.
4 Alignment Experiments
We conducted alignment experiments on English-Japanese and Chinese-English-Japanese corpora to show the effectiveness of the proposed model.
4.1 Settings
For English-Japanese, the JST2paper abstract cor-pus was used. This corcor-pus was created by NICT3 from JST’s 2M English-Japanese paper abstract corpus using the method of Utiyama and Isahara (2007). For Chinese-Japanese, we used the pa-per abstract corpus provided by JST and NICT. This corpus was developed during a project in Japan called the “Development and Research of Chinese-Japanese Natural Language Processing Technology”. The statistics of these corpora are shown in Table 4.1. Unfortunately, these two cor-pora are not freely available now, but they will be-come available to everyone in near future.
As gold-standard data, we used 479 sentence pairs of English-Japanese and 510 sentence pairs of Chinese-Japanese. These were annotated by hand using two types of annotations: sure (S)
alignments and possible (P) alignments (Och and
Ney, 2003). The unit of evaluation was the word for all the languages. We used precision, recall, and alignment error rate (AER) as evaluation cri-teria. All the experiments were run on the origi-nal forms of words. The hyper parameters for our model used in the experiments are summarized in Table 4.1.
Japanese sentences were converted into depen-dency structures using the morphological analyzer JUMAN (Kurohashi et al., 1994), and the depen-dency analyzer KNP (Kawahara and Kurohashi, 2006). For English sentences, Charniak’s nlparser was used to convert them into phrase structures (Charniak and Johnson, 2005), and then they were transformed into dependency structures by rules defining head words for phrases. Chinese sen-tences were converted into dependency trees us-ing the word segmentation and POS-taggus-ing tool by Canasai et al. (2009) and the dependency ana-lyzer CNP (Chen et al., 2008).
For comparison, we used GIZA++ (Och and Ney, 2003) which implements the prominent se-quential word-based statistical alignment model
2http://www.jst.go.jp/ 3http://www.nict.go.jp/
En-Ja Zh-Ja
En Ja Zh Ja
# of sentences 996K 680K
# of words 24.7M 27.5M 18.8M 22.3M ave. sent. length 24.8 27.6 27.7 32.9
Table 1: Statistics of the training corpus.
αA αN pt αf e, αef pf e, pef
En-Ja 100 100 0.8 100 0.5
Zh-Ja 10 100 0.8 100 0.5
Table 2: Hyper parameters used in experiments.
of the IBM Models. We conducted word align-ment bidirectionally with the default parameters and merged them using the grow-diag-final-and heuristic (Koehn et al., 2003). Furthermore, we used the BerkeleyAligner4 (DeNero and Klein, 2007) with default settings for unsupervised train-ing. Experimental results for English-Japanese are shown in Table 4.1, and those for Chinese-Japanese are shown in Table 4.1. The alignment accuracy of the initialization described in Section 3.1 is indicated as “Initialization”, while the accu-racy after conducting Gibbs sampling is indicated as “Proposed”.
4.2 Discussion
For English-Japanese, our proposed model achieved reasonably high alignment accuracy compared with that of GIZA++ and the Berke-leyAligner. Using tree structures combined with the bi-directional alignment results leads to better accuracy than the original sequential heuristic (indicated as Initialization). We also give the alignment accuracy obtained by Nakazawa and Kurohashi (2009) (indicated as Nakazawa+ in Table 4.1, and applicable only to the English-Japanese corpus)5. Their model suffered from a degeneracy in acquiring larger phrases caused by maximum likelihood estimation, and this led to low precision and high recall. Compared with their model, our proposed model overcomes the degeneracy and outperforms in terms of both pre-cision and recall. Figure 4 shows an example of the improvement in alignment. GIZA++ aligned function words incorrectly because of the lack of structural information. For example, GIZA++ aligned the English “of” and the Japanese “ ”
4http://code.google.com/p/berkeleyaligner/
5They used 475 sentence pairs instead of 479 sentence
Pre. Rec. AER grow-diag-final-and 81.17 62.19 29.25 BerkeleyAligner 85.00 53.82 33.72 Nakazawa+ 80.28 63.85 28.67 Initialization 82.39 61.82 28.99 Proposed 85.93 64.71 25.73
Table 3: Results of English-Japanese alignment experiments.
Pre. Rec. AER grow-diag-final-and 83.77 75.38 20.39 BerkeleyAligner 88.43 69.77 21.60 Initialization 84.71 75.46 19.90 Proposed 85.52 74.71 19.89
Table 4: Results of Chinese-Japanese alignment experiments.
in the third word. This was incorrectly derived from the combination heuristic: English posterior word “other” and Japanese prior word “
” are aligned by intersection, and thus, “of ↔ ” is also aligned through the grow-diag heuristic. This could be avoided by introducing dependency trees: the English words “of” and “other” are not contiguous in the dependency tree. In addition, there is no correspondence between “ ↔ of”. This is a rare translation for “of”, which is most frequently translated as “ ”, so GIZA++ aligned “ ↔ of” only. A nonparametric Bayesian model is capable of finding the correct alignment with the support of occurrences of the subtree pair elsewhere in the training corpus.
The reasons for recall being significantly lower than precision in all the models are summarized in the two points. One is the separation between gold-standard criteria and system output. In Fig-ure 4, “are described” and “ ” are aligned in their entirety, but the system found one-to-one alignments, which are also acceptable. The other is that it is sometimes hard to align part of a sentence in a smaller unit for distant language pairs, because the expressions are quite different. In such cases, the system is obliged to align ex-pressions enmasse, which leads to low recall.
For Chinese-Japanese, we failed to improve alignment accuracy greatly. A major cause of this undesirable result could be the accuracy of the Chinese parser. Both the English and Japanese
Figure 4: Alignment results from bi-directional GIZA++ (top) and proposed model (bottom).
parsers used in the experiments can analyze sen-tences with over 90% accuracy, whereas the ac-curacy of the Chinese parser is less than 80% de-spite it being state-of-the-art in the world (Chen et al., 2008). The parsing accuracy reported in this paper was obtained from an experiment us-ing gold-standard word segmentation and POS-tags. Starting with raw sentences results in about 77.4% accuracy. This information was obtained from communication with the authors. Fundamen-tal NLP technologies in each language must be im-proved in the long term, and sophisticated models, which use deeper analysis of sentences like our model, should become effective in the near future. One possible short-term solution for the parsing problem is to use the n-best parsing results in the model. Another kind of solution was proposed by Burkett et al. (2010), who described a joint pars-ing and alignment model that can exchange useful information between the parser and aligner.
im-BLEU grow-diag-final-and 24.59 Initialization 25.33
Proposed 24.50
Table 5: BLEU results for Japanese-to-English translation experiments.
portant than recall. The BerkeleyAligner showed much higher precision than GIZA++ and, in Chinese-Japanese alignment, than our model as well. However, recall was quite low compared with all the other models. Lower recall results in a large translation table because the phrase extrac-tion heuristics ’grow’ over each unaligned word.
5 Translation Experiments
We conducted Japanese-to-English translation ex-periments on the same corpus used in the align-ment experialign-ment. We translated 500 paper ab-stract sentences from the JST corpus. Note that these sentences were not included in the training corpus. We used the state-of-the-art phrase-based SMT toolkit Moses(Koehn et al., 2007) with de-fault options, except for the distortion limit (6→ 20). It was tuned by MERT using another 500 de-velopment sentence pairs.
Table 5 shows the BLEU scores for the transla-tions. Although the difference in alignment accu-racy between grow-diag-final-and and Initializa-tion is small, the BLEU score was improved by 0.74 point. This is because syntactic information reduced incorrect alignment points and the qual-ity of translation table becomes better. This result provided evidence that syntactic knowledge is use-ful for distant language pairs. However, the BLEU score decreased after iterations of our alignment model. The main reason is that the alignment re-sult of our model is not compatible with Phrase-based SMT. Our model often output sequentially discontiguous alignments which are harmful for PSMT to create fine-grained phrase table. We need to use other decoders which is compatible with our alignment model (Nakazawa and Kuro-hashi, 2010), and we believe that our model leads to better translation quality.
6 Conclusion
In this paper, we proposed a linguistically-motivated nonparametric Bayesian subtree align-ment model based on dependency tree structures
for distant language pairs. The model incorporates the tree-based reordering model. It also solves the degeneracy of the maximum likelihood estimation for models capable of handling multiple levels of structures by placing a Dirichlet process prior over parameters. Experimental results show that a word sequential model does not work well for distant language pairs, but that this can be addressed by using syntactic information. Our proposed model achieved a lower AER by about 3.5 points com-pared with GIZA++.
To support allegation that syntactic information is important for distant language pairs, it is neces-sary to compare our model with the original word sequential study (DeNero et al., 2008), which was consulted often. It is also important to apply our model not only to other distant language pairs, but also to similar language pairs, and to investigate the results. We are planning to use standard data set such as NIST or IWSLT. Also, we could use the n-best parsing results in our model to alleviate the error propagation from parsing, especially for Chinese.
References
Peter F. Brown, Stephen A. Della Pietra, Vincent J. Della Pietra, and Robert L. Mercer. 1993. The mathematics of statistical machine translation: Pa-rameter estimation. Association for Computational Linguistics, 19(2):263–312.
David Burkett, John Blitzer, and Dan Klein. 2010. Joint parsing and alignment with weakly synchro-nized grammars. In Human Language Technolo-gies: The 2010 Annual Conference of the North American Chapter of the Association for Compu-tational Linguistics, pages 127–135, Los Ange-les, California, June. Association for Computational Linguistics.
Eugene Charniak and Mark Johnson. 2005. Coarse-to-fine n-best parsing and maxent discriminative reranking. InProceedings of the 43rd Annual Meet-ing of the Association for Computational LMeet-inguistics (ACL’05), pages 173–180.
Wenliang Chen, Daisuke Kawahara, Kiyotaka Uchi-moto, Yujie Zhang, and Hitoshi Isahara. 2008. De-pendency parsing with short deDe-pendency relations in unlabeled data. InIn Proceedings of the 3rd Interna-tional Joint Conference on Natural Language Pro-cessing (IJCNLP-08), pages 88–94.
David Chiang. 2005. A hierarchical phrase-based model for statistical machine translation. In Pro-ceedings of the 43rd Annual Meeting of the Associa-tion for ComputaAssocia-tional Linguistics (ACL’05), pages 263–270.
David Chiang. 2010. Learning to translate with source and target syntax. InProceedings of the 48th Annual Meeting of the Association for Computational Lin-guistics, pages 1443–1452, Uppsala, Sweden, July. Association for Computational Linguistics.
John DeNero and Dan Klein. 2007. Tailoring word alignments to syntactic machine translation. In Pro-ceedings of the 45th Annual Meeting of the Asso-ciation of Computational Linguistics, pages 17–24, Prague, Czech Republic, June. Association for Com-putational Linguistics.
John DeNero, Alexandre Bouchard-Cˆot´e, and Dan Klein. 2008. Sampling alignment structure un-der a Bayesian translation model. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, pages 314–323, Hon-olulu, Hawaii, October. Association for Computa-tional Linguistics.
Daisuke Kawahara and Sadao Kurohashi. 2006. A fully-lexicalized probabilistic model for japanese syntactic and case structure analysis. InProceedings of the Human Language Technology Conference of the NAACL, Main Conference, pages 176–183, New York City, USA, June. Association for Computa-tional Linguistics.
Philipp Koehn, Franz J. Och, and Daniel Marcu. 2003. Statistical phrase-based translation. InHLT-NAACL 2003: Main Proceedings, pages 127–133.
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar, Alexandra Constantin, and Evan Herbst. 2007. Moses: Open source toolkit for statistical machine translation. In
Annual Meeting of the Association for Computa-tional Linguistics (ACL), demonstration session.
Canasai Kruengkrai, Kiyotaka Uchimoto, Jun’ichi Kazama, Yiou Wang, Kentaro Torisawa, and Hitoshi Isahara. 2009. An error-driven word-character hy-brid model for joint chinese word segmentation and pos tagging. In Proceedings of the Joint Confer-ence of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Lan-guage Processing of the AFNLP, pages 513–521, Suntec, Singapore, August. Association for Compu-tational Linguistics.
Sadao Kurohashi, Toshihisa Nakamura, Yuji
Mat-sumoto, and Makoto Nagao. 1994.
Improve-ments of Japanese morphological analyzer JUMAN. In Proceedings of The International Workshop on Sharable Natural Language, pages 22–28.
Daniel Marcu and Daniel Wong. 2002. A phrase-based,joint probability model for statistical machine translation. InProceedings of the 2002 Conference on Empirical Methods in Natural Language Pro-cessing, pages 133–139. Association for Computa-tional Linguistics, July.
Arul Menezes and Chris Quirk. 2008. Syntactic mod-els for structural word insertion and deletion dur-ing translation. In Proceedings of the 2008 Con-ference on Empirical Methods in Natural Language Processing, pages 734–743, Honolulu, Hawaii, Oc-tober. Association for Computational Linguistics.
Toshiaki Nakazawa and Sadao Kurohashi. 2009. Sta-tistical phrase alignment model using dependency relation probability. InIn Proceedings of the third Workshop on Syntax and Structure in Statistical Translation (SSST-3), pages 10–18, Boulder, Col-orado, June.
Toshiaki Nakazawa and Sadao Kurohashi. 2010. Fully syntactic ebmt system of kyoto team in ntcir-8. In
In Proceedings of the 8th NTCIR Workshop Meeting on Evaluation of Information Access Technologies (NTCIR-8), pages 403–410.
Franz Josef Och and Hermann Ney. 2003. A sys-tematic comparison of various statistical alignment models. Association for Computational Linguistics, 29(1):19–51.
Zhaopeng Tu, Yang Liu, Young-Sook Hwang, Qun Liu, and Shouxun Lin. 2010. Dependency for-est for statistical machine translation. In Proceed-ings of the 23rd International Conference on Com-putational Linguistics (Coling 2010), pages 1092– 1100, Beijing, China, August. Coling 2010 Organiz-ing Committee.
Masao Utiyama and Hitoshi Isahara. 2007. A