153 | International Journal of Computer Systems, ISSN-(2394-1065), Vol. 03, Issue 02, February, 2016 Available at http://www.ijcsonline.com/
Multi Keyword Ranked Search Enabled Encryption on Cloud Data
Vishnuprasad T., Ajith Kumar K. and Abhiram C. M.
Department of CSE, Nehru College of Engineering and Research Centre, Pampady, Thrissur, India
Abstract
Since the growth of internet technology become explosive, so does the growth of cloud technology. Virtually the cloud technology is improving every day in these days. Along with this rapid improvement, cloud computing is also having great flexibility and cost effectiveness. These features of cloud lure every data owners to share and upload the data and information into a cloud network. But for privacy and security needs, they encrypt it before uploading. Hence searching for the encrypted data in the cloud is necessary in these days. There exist techniques for searching encrypted data, namely single keyword and Boolean keyword search. But as there is large number of data in the cloud and the number of users using it is also large, these techniques for searching and retrieving encrypted cloud data aren’t sufficient. Because the result obtained through these techniques can’t satisfy a hungry user. For these reasons the need of introducing new searching scheme called multi keyword ranked searching is necessary. The multi keyword searching scheme establishes a set of strict privacy requirement for a secure cloud data utilization system. It also ensures that the proposed scheme surely bring in reduced overhead on communication as well as in computation.
Keywords: Multi keyword search, ranked search, cloud computing, searchable encryption, ranked search
I. INTRODUCTION
One of the most innovative internet technology in the twenty first century is cloud computing. This is because of the reason that it realizes the vision of computing as a utility. It allows customers to stores the data in the cloud so as to enjoy the on-demand high quality applications from a shared pool of configurable virtualized resources. The driving force for both individuals and enterprises to outsource their local complex data management system into the cloud is because of its flexibility and economic saving feature. All organisations have the responsibility to provide security to its user‟s data, and for privacy they will have to block unsolicited accesses to the cloud. For this the sensitive data have to be encrypted by data owners before outsourcing to the commercial public cloud. This, however, obsoletes the traditional data utilization service based on plaintext keyword search. Downloading all data and decrypting locally is a trivial solution and is highly impractical. All these reasons sum up the want for a scheme that allow multi keyword search on encrypted cloud data along with essential data secrecy features.
Since the user‟s requirement is to get the data that they request as fast as possible and as accurately as possible, it demands the cloud server to perform result relevance ranking, instead of returning undifferentiated results [2]. It not only retrieves the data that user desires quickly but can also eliminate unnecessary network traffic. This because the cloud is based on the concept of „pay as you use‟ and hence nobody wants to waste the money unnecessarily. For the ranking of result to be effective, it solidifies the need for multi keyword searching schemes. However, how to apply it in the encrypted cloud data search system remains a very challenging task because of inherent security and privacy obstacles, including various strict requirements like the data privacy, the index privacy, the keyword privacy, and many others.
For encrypted data in cloud, searchable encryption is a helpful technique that treats encrypted data as documents. This allows a user to easily and securely search by using a single keyword and retrieve documents of interest [3].But since they are developed as cryptoprimitives and cannot accommodate high service-level requirements like system usability, efficient user searching experience and easy information retrieval. To improve the search flexibility, some recent designs have been proposed to support Boolean keyword search [4]. But they are still not enough to provide users with acceptable result ranking functionality. Having said all this, the new scheme of multi keyword searching on an encrypted data is still a major challenge.
In this paper, the scheme named multi keyword ranked search (MKRS) enabled encryption on cloud data is specified and resolved. In the several semantics available for multi keyword searching “co-ordinate matching” is used here. When the index construction is carried out, each document is associated with a binary vector as a sub-index where each bit represents whether corresponding keyword is contained in the document. The search query is also described as a binary vector where each bit means whether corresponding keyword appears in this search request, so the similarity could be exactly measured by the inner product of the query vector with the data vector. But outsourcing of the data vector or the query vector directly will violate the index privacy or the search privacy. For taking on challenges of supporting such multikeyword semantic without privacy breaches, a basic idea for the MKRS using secure inner product computation is considered. This is adapted from secure k-nearest neighbour (kNN) technique [5].
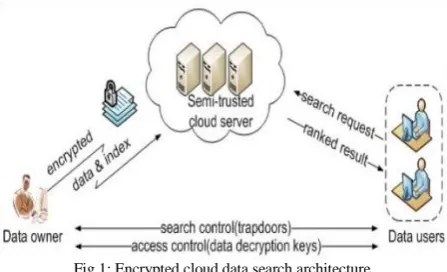
Fig 1: Encrypted cloud data search architecture
II. PROBLEM STATEMENT
A. The System Model
The system model can be considered as a cloud data hosting service involving three different entities which is illustrated in Fig 1.these entities are named as the data owner, the data user, and the cloud server. This means the system design uses the three-tier architecture. 'Three-tier' is a client-server architecture in which the user interfaces, functional process logic ("business rules"), computer data storage and data access are developed and maintained as independent modules, most often on separate platforms. The three-tier model is considered to be software architecture and a software design pattern.
The data owner has a set of data documents F to be uploaded to the cloud server in the encrypted form C. To enable the searching efficiency over C for adequate data utilization, the data owner will first build an encrypted searchable index I from F, and then outsource both the index I and the encrypted document collection C to the cloud server. To search the document collection for t given keywords, an authorized user acquires a corresponding trapdoor T through search control mechanisms. Upon receiving T from a data user, the cloud server is obliged to search the index I and return the corresponding set of encrypted documents. To improve the document retrieval accuracy, the search result should be ranked by the cloud server according to any available ranking criteria.
B. Threat Models
We consider an “honest-but-curious” server in our model, which is consistent with most of the previous searchable encryption schemes [ ]. In most realistic scenario the cloud server will act in “honest” manner. It will also follow the designated protocols specified correctly. But the concern for a semi-trusted server like this is that, the server is always “curious” to infer and analyze the message flow received during the protocol so as to learn additional information. Specifically, the server, by no means, has any willful intention to actively modify the message flow or disrupt any other kind of services. By these conclusions we have the following attacking models.
Known cipher text model. In this model, the cloud server is supposed to only know encrypted data set C and searchable index I, both of which are outsourced from the data owner.
Chosen-cipher text model. By this model it means that, as the cloud server knows encrypted data set C and index I, the cloud server because of its “curious” nature can choose arbitrary cipher text and have access to plaintext decrypted from it.
Known background model. In this stronger model, the cloud server is supposed to possess more knowledge than what can be accessed in the known cipher text model. Such information may include the correlation relationship of given search requests (trapdoors), as well as the data set related statistical information.
C. Design Goals
To enable ranked searchable symmetric encryption for effective utilization of outsourced cloud data under the aforementioned model, the design is intended to achieve data secrecy and improved data retrieval. The goals are as follows.
Multi-keyword ranked search. To design schemes which allow multi-keyword query and provide result similarity ranking for effective data retrieval, instead of returning undifferentiated results.
Data secrecy. To keep the server from exposing supplementary information from the data set and the index, and to meet privacy requirements.
Performance. The precedent design goals are expected to be achieved without diminishing the performance of the system.
III. LITERATURE SURVEY
Because of the large number of data users and documents in the cloud, it has become a necessary to allow multiple keywords in the search request and return documents in the order of their relevance to these keywords. The problem of multi keyword ranked search over encrypted cloud data is explored, and then the proposed system establishes a set of strict privacy requirements for such a secure cloud data utilization system. Experiments on the real-world data set further shows that multi keyword ranked schemes indeed introduce low overhead on computation and communication.
A. Towards a Cloud Definition,
Cloud Computing is associated with a new paradigm for the provision of computing infrastructure [6]. This paradigm shifts the location of this infrastructure to the network to reduce the costs associated with the management of hardware and software resources. Depending on the type of provided capability, there are three scenarios where Clouds are used: Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS).
made in a transparent manner. This is denoted as Platform as a Service. There are services of potential interest to a wide variety of users hosted in Cloud systems. This is an alternative to locally run applications. This scenario is called Software as a Service.
Taking these features into account an encompassing definition of the Cloud can be stated as follows: Clouds are a large pool of easily usable and accessible virtualized resources (such as hardware, development platforms and/or services). These resources can be dynamically reconfigured to adjust to a variable load (scale), allowing also for an optimum resource utilization. This pool of resources is typically exploited by a pay per-use model in which guarantees are offered by the Infrastructure Provider by means of customized SLAs (Service-Level Agreement). B. Cryptographic Cloud Storage
Cloud infrastructures can be roughly categorized as either private or public. [7] In a private cloud, the infrastructure is managed and owned by the customer and located on-premise. In particular, this means that access to customer data is under its control and is only granted to parties it trusts. In a public cloud the infrastructure is owned and managed by a cloud service provider and is located off-premise. This means that customer data is outside its control and could potentially be granted to untrusted parties. By moving their data to the cloud customers can avoid the costs of building and maintaining a private storage infrastructure, opting instead to pay a service provider as a function of its needs. For most customers, this provides several benefits including availability and reliability at a relatively low cost. While the benefits of using a public cloud infrastructure are clear, it introduces significant security and privacy risks. In fact, it seems that the biggest hurdle to the adoption of cloud computing, in general, is the concern over the confidentiality and integrity of data. Thus, unless the issues of confidentiality and integrity are addressed, many potential customers will be reluctant to make the move.
The core components of a cryptographic storage service can be implemented using a variety of techniques, some of which were developed specifically for cloud storage. When preparing data for storage in the cloud, the data processor begins by indexing it and encrypting it with a symmetric encryption scheme under a unique key. It then encrypts the index using a searchable encryption scheme and encrypts the unique key with an attribute-based encryption scheme under an appropriate policy. Finally, it encodes the encrypted data and index in such a way that the data verifier can later verify their integrity using a proof of storage. A proof of storage is a protocol executed between a client and a server with which the server can prove to the client that it did not tamper with its data. Proofs of storage can be either privately or publicly verifiable. Privately verifiable proofs of storage only allow the client (i.e., the party that encoded the file) to verify the integrity of the data. With a publicly verifiable proof of storage, on the other hand, anyone that possesses the client‟s public key can verify the data‟s integrity.
C. Modern Information Retrieval
With the advent of computers, it became possible to store large amounts of information [8]; and finding useful information from such collections became a necessity. The
need to store and retrieve written information became increasingly important over the years and thus many modes of data retrievals thus emerged. Various models for doing document retrieval were developed and advances were made along all dimensions of the retrieval process. However, due to lack of availability of large text collections, the question whether these models and techniques would scale to larger corpora remained unanswered. This changed with the inception of Text Retrieval Conference, or TREC. With large text collections available under TREC, many old techniques were modified, and many new techniques were developed to do effective retrieval over large collections. The algorithms developed in IR were the first ones to be employed for searching the World Wide Web.
Early IR systems were boolean systems which allowed users to specify their information need using a complex combination of boolean ANDs, ORs and NOTs. Boolean systems have several shortcomings and it is very hard for a user to form a good search request using such techniques. Most everyday users of IR systems expect IR systems to do ranked retrieval. Thus IR systems rank documents by their estimation of the usefulness of a document for a user query. Most IR systems assign a numeric score to every document and rank documents by this score. Several models have been proposed for this process. The three most used models in IR research are the vector space model, the probabilistic models, and the inference network model.
IR systems are based on the inverted list data structure. This enables fast access to a list of documents that contain a term along with other information. Inverted lists exploit the fact that given a user query, most IR systems are only interested in scoring a small number of documents that contain some query term. This allows the system to only score documents that will have a non-zero numeric score. Most systems maintain the scores for documents in a heap (or another similar data structure) and at the end of processing return the top scoring documents for a query. The two desired properties for the measurement of search effectiveness are recall: the proportion of relevant documents retrieved by the system; and precision: the proportion of retrieved documents that are relevant.
of information available, information retrieval will play an increasingly important role in future.
D. Secure Ranked Keyword Search
A ranked searchable encryption scheme consists of four algorithms (KeyGen, BuildIndex, TrapdoorGen, SearchIndex) [9]. A ranked searchable symmetric encryption system can be constructed from these four algorithms in two phases - Setup and Retrieval.
Setup: The data owner initializes the public and secret parameters of the system by executing KeyGen, and pre-processes the data file collection C by using BuildIndex to generate the searchable index from the unique words extracted from C. The owner then encrypts the data file collection C, and publishes the index including the keyword frequency based relevance scores in some encrypted form, together with the encrypted collection C to the Cloud.
Retrieval: The user uses TrapdoorGen to generate a secure trapdoor corresponding to his interested keyword, and submits it to the cloud server. Upon receiving the trapdoor, the cloud server will derive a list of matched file IDs and their corresponding encrypted relevance scores by searching the index via SearchIndex. The matched files should be sent back in a ranked sequence based on the relevance scores. However, the server should learn nothing or little beyond the order of the relevance scores. Thus, search results can be accurately ranked based only on the term frequency and file length information contained within the single file.
E. Fuzzy Keyword Search
Although traditional searchable encryption schemes allow a user to securely search over encrypted data through keywords and selectively retrieve files of interest, these techniques support only exact keyword search. This is when an effective fuzzy keyword search over encrypted cloud data can be used.
The fuzzy keyword search scheme returns the search results according to the following rules: 1) if the user‟s searching input exactly matches the pre-set keyword, the server is expected to return the files containing the keyword. 2) if there exist typos and/or format inconsistencies in the searching input, the server will return the closest possible results based on pre-specified similarity semantics. There are several methods to quantitatively measure the string similarity. The three primitive operations used here are 1) Substitution: changing one character to another in a word. 2) Deletion: deleting one character from a word. 3) Insertion: inserting a single character into a word.
Fuzzy keyword search greatly enhances system usability by returning the matching files when users‟ searching inputs exactly match the predefined keywords or the closest possible matching files based on keyword similarity semantics, when exact match fails [10]. Here the technique of edit distance is used, in which keyword similarity is quantified and an advanced technique on constructing fuzzy keyword sets is developed, which greatly reduces the storage and representation overheads.
F. Secure kNN Computation on Encrypted Database Traditional encryption methods that aim at providing “unbreakable” protection are often not adequate because they do not support the execution of applications such as database queries on the encrypted data. However, the problem should be studied with respect to various security requirements, considering different attacker capabilities. Here the focus is on k-nearest neighbour (kNN) queries, and shows how various encryption schemes are designed to support secure kNN query processing under different attacker capabilities. The kNN query is an important database analysis operation, used as a standalone query or as a core module of common data mining tasks.
The general problem of secure computation on an encrypted database is discussed and a model named SCONEDB (Secure Computation ON an Encrypted Database) is proposed in this literature. The SCONEDB model captures the execution and security requirements. Here the main focus is on kNN queries. How an encryption scheme (which includes the above five components) can be developed to securely support kNN applications under the SCONEDB model is also illustrated here. A kNN query searches for k points in a database that are the nearest to a given query point q. One approach to securely support kNN is to use distance-preserving transformation (DPT) to encrypt data points. Given this property, kNN can be computed on the encrypted database. Unfortunately, such transformation is shown to be not secure in practice. If an attacker can access the DPT-encrypted database and knows a few points in the plain database DB, he can recover DB entirely.
The weakness of DPT comes from the fact that the attacker is able to recover distance information from the encrypted database. These distances allow the attacker to compute signatures and thus to apply the signature linking attack. Unfortunately, a scalar-product-preserving encryption is also distance-recoverable and hence is not secure against level-2 attacks. To resist level-2 attacks, we need an encryption function that does not reveal distance information. For kNN search, exact distance computation is not necessary. Rather, only a distance comparison operation is needed. The requirement that needed here is that the distance recovery of an encrypted database must not be possible. The experiments show that a scalar product preserving encryption is also distance recoverable and hence is not secure against level-2 attacks (Level-2 attack example : if the attacker observes the encrypted database of a bank and some of his sources are customers of the bank, he then knows the values of several tuples in the plain database.)
G. Zerber: r-Confidential Indexing for Distributed Documents
In larger enterprises employers often need to share data users need an indexing facility that can quickly locate relevant documents they are allowed to access, without
(1) Leaking information about the remaining documents
(2) Imposing a large management burden as users, groups, and documents evolve
(3) Requiring users to agree on a central completely trusted authority.
To address these problems, r-confidentiality is proposed. It is a measure of the degree of information that can leak from an index about inaccessible documents, given an adversary‟s background knowledge of the corpus or language statistics. Then an r-confidential global inverted index for sensitive documents, known as Zerber, is introduced [12].
Zerber relies on a centralized set of largely untrusted index servers that hold posting list elements encrypted with a „k‟ out of „n‟ secret sharing scheme, which provides complete resistance against inappropriate information disclosure regarding pre-existing documents even if k-1 index servers are compromised. To provide tunable resistance to statistical attacks, Zerber employs a novel term merging scheme that has minimal impact on index lookup costs. Zerber guarantees freshness of shared documents at low cost, makes economical use of network bandwidth, requires no key management, and answers most of the queries almost as fast as an ordinary inverted index.
Currently, Zerber returns all answers to a query, and ranking is performed on the client side. A challenging extension is to support top-K processing on the server side, while maintaining the confidentiality properties. Returning only top-K query answers will significantly reduce the network bandwidth and processing costs at user peers. Another interesting question is how to support query confidentiality, even when one server has been compromised and the adversary can view the incoming stream of requests for posting lists. BFM leaks probabilistic information in this situation, while the other merging heuristics are more robust.
IV. CONCLUSION
It is obvious that as the days go by the internet technology will improve. Along with that the data that will be uploaded in the cloud will also be greater. So in this document, for the primary occasion we term and crack the problem of multi-keyword ranked search in excess of encrypted cloud data, and institute a assortment of privacy necessities. in the midst of various multi-keyword semantics, we choose the efficient similarity measure of “coordinate matching,” i.e., as many matches as possible, to effectively capture the relevance of outsourced documents to the query keywords, and use “internal product similarity” to quantitatively evaluate such similarity measure. For meeting the challenge of supporting multi-keyword semantic without privacy breaches, we propose a basic idea of MKRS using secure inner product computation. Then, we give two improved MKRS schemes
to achieve various severe privacy requirements in different threat models.
ACKNOWLEDGMENT
The work was completed with support of our guides Prof. Vinit K. and Prof. Hafzal Rahman M. J. They are the force behind the completion of this paper. So we would like to express our thanks to them for their highly appreciable support and encouragement. We would also like to convey our gratitude to all who supported to make it possible.
REFERENCES
[1] N. Cao, C. Wang, M. Li, K. Ren, and W. Lou, “Privacy-Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data,” IEEE Computer Society, vol.25, Issue No.01 – January 2014, pp. 222-233,
[2] A. Singhal, “Modern information retrieval: A brief overview,” IEEE Data Engineering Bulletin, vol. 24, no. 4, 2001, pp. 35–43. [3] D. Song, D. Wagner, and A. Perrig, “Practical techniques for
searches on encrypted data,” in Proc. of S&P, 2000.
[4] J. Katz, A. Sahai, and B. Waters, “Predicate encryption supporting disjunctions, polynomial equations, and inner products,” in Proc. of EUROCRYPT, 2008.
[5] W. K. Wong, D. W. Cheung, B. Kao, and N. Mamoulis, “Secure knn computation on encrypted databases,” in Proceedings of the 35th SIGMOD international conference on Management of data, 2009, pp. 139–152.
[6] L. M. Vaquero, L. Rodero-Merino, J. Caceres, and M. Lindner, “A break in the clouds: towards a cloud definition,” ACM SIGCOMM Comput. Commun. Rev., vol. 39, no. 1, 2009, pp. 50–55.
[7] S. Kamara and K. Lauter, “Cryptographic cloud storage,” in RLCPS, January 2010, LNCS. Springer, Heidelberg.
[8] A. Singhal, “Modern information retrieval: A brief overview,” IEEE Data Engineering Bulletin, vol. 24, no. 4, 2001, pp. 35–43. [9] C. Wang, N. Cao, J. Li, K. Ren, and W. Lou, “Secure ranked
keyword search over encrypted cloud data,” in Proc. of ICDCS‟10, 2010.
[10] J. Li, Q. Wang, C. Wang, N. Cao, K. Ren, and W. Lou, “Fuzzy keyword search over encrypted data in cloud computing,” in Proc. of IEEE INFOCOM‟10 Mini-Conference, March 2010, San Diego, CA, USA.
[11] W. K. Wong, D. W. Cheung, B. Kao, and N. Mamoulis, “Secure knn computation on encrypted databases,” in Proceedings of the 35th SIGMOD international conference on Management of data, 2009, pp. 139–152.