AN EVEN ODD MULTIPLE PATTERN
MATCHING ALGORITHM
Raju Bhukya, Assistant Professor
Department of Computer Science and Engineering National Institute of Technology, Warangal, A.P. India.
DVLN Somayajulu, Professor
Department of Computer Science and Engineering, National Institute of Technology, Warangal.A.P.India
Abstract :
Pattern matching plays an important role in various applications ranging from text searching in word processors to identification of functional and structural behavior in proteins and genes. Pattern matching is one of the fundamental areas in the field of computational biology. Currently research in life science area is producing large amount of genetic data. Due to this large and use full information can be gained by finding valuable information available from the genomic sequences. Many algorithms have been proposed but more efficient and robust methods are needed for the multiple pattern matching algorithms for better use. We introduce a new indexing technique called an Index based even odd multiple pattern matching, which gives very good performance when compared with some of the existing popular algorithms. The current technique avoids unnecessary DNA comparisons as a result the number of comparisons and CPC ratio gradually decreases and overall performance increases accordingly.
Keywords- Characters, matching, pattern, sequence.
1. Introduction
Pattern matching is an important and active research upcoming area in computational biology. It can be defined as finding the occurrences of a particular pattern from a large sequence. An exact pattern matching involves identification of all the occurrences of a given pattern of m characters (p=p1,p2,p3…pm) in a text of n characters (t=t1,t2,t3…tn) built over a finite alphabet set ∑ of size σ. Let P={p1,p2,p3..pm} be a set of patterns which are strings of nucleotide sequence characters from a fixed alphabet set ∑={A,C,G,T}. Let T be a large text consisting of characters in ∑. In other words T is an element of ∑*. String matching mainly deals with problem of finding all occurrences of a string in a given text. In most of the applications it is necessary to the user and the developer to locate the occurrences of specific pattern in a sequence. So a new indexing technique has been developed. In many cases most of the algorithm operates in two stages.
Pre-processing phase or study of the pattern Processing phase or searching phase.
The pre-processing phase collects the full information and is used to optimize the number of comparisons. Whereas searching phase finds the pattern by the information collected in pre-processing. Depending upon the algorithm some of the algorithm uses pre-processing phase and some algorithm will search without it. Many pattern matching algorithms are available with their own merits and demerits based upon the pattern length and the technique they use. These pattern matching algorithms have been extensively used in various applications like information retrieval, information security, searching nucleotide sequences, amino acid sequences, and pattern matching in biological databases.
single pattern matching algorithms. To determine the function of specific genes, scientists have learned to read the sequence of nucleotides comprising a DNA sequence in a process called DNA sequencing. DNA comparison, pattern recognition, similarity detection and phylogenetic trees construction in genome sequences are the most popular tasks. The process of sequence alignment allows the insertion, deletion and replacements of symbols that representing the nucleotides or amino acids sequences. From the biological point of view pattern comparison is motivated by the fact that all living organisms are related by evolution. This implies that the genes of species that are closer to each other should show signs of similarities at the DNA level. Pattern matching algorithms are reviewed and classified in two categories.
Exact string matching algorithm Inexact string matching algorithms.
Exact string matching algorithm is for finding one or all exact occurrences of a string in a sequence. Given a pattern p of length m and a string /Text T of length n (m ≤ n). Find all the occurrences of p in T. The matching needs to be exact, which means that the exact word or pattern is found. Some exact matching algorithms are Naïve Brute force algorithm, [Boyer-Moore algorithm(1977)], [Knuth-Morris-Pratt Algorithm(1977)]. Applications of exact pattern matching algorithms includes parsers, spam filters, digital libraries, screen scrapers, word processors, web search engines, natural language processing and computational biology.
Inexact pattern matching is sometimes referred as approximate pattern matching or matches with k mismatches/ differences. Given a pattern P of length m and string/text T of length n (m ≤ n). Find all the occurrences of sub string X in T that are similar to P, allowing a limited number, say k different characters in similar matches. The Edit/transformation operations are insertion, deletion and substitution. Some Inexact pattern matching algorithms are Dynamic programming approach, Automata approach, Bit-parallelism approach, Filtering and Automation Algorithms. Applications of inexact pattern matching algorithms includes signal processing, computational biology and text processing.
The rest of the paper is organized as follows. We briefly present the background and related work in section 2. Section 3 deals with proposed model i.e., IEOMPM algorithm for DNA sequence. Results and discussion are presented in Section 4 and we make some concluding remarks in Section 5.
2. Background and related work
Some of the pattern matching algorithm concentrates on pattern itself without using the preprocessing phase. Other algorithm compares the pattern and the text from left to the right. Some other algorithms perform comparison from right to left. The performance of the algorithm depends upon the order in which the comparison is done. Several pattern matching algorithms have been developed to minimize the number of comparisons. Brute-force algorithm compares the pattern with the text from left to right. After each attempt it shifts the pattern by exactly one position to right. The time complexity is O(mn) in worst case and the number of text character comparison is 2n. [Boyer-Moore algorithm(1977)] improves the performance by pre-processing the pattern by using two shift functions. The bad character shift and the good suffix shift. During the searching phase the pattern is aligned with the text and it is scanned from right to left. If a mismatch occurs the algorithm shifts the pattern with the maximum value taken between the two shift functions. The worst case complexity is O(mn).
starting index of the pattern or if any character mismatches then we will stop searching and then go to the next index stored in the index table of the same row which corresponds to the first character of the pattern P.
The [Knuth-Morris-Pratt algorithm(1977)]is based on the finite state machine automation. The pattern P is pre-processed to create a finite state machine M that accepts the transition. The finite state machine is usually represented as the transition table. The complexity of the algorithm for the average and the worst case performance is O(m+n). In approximate pattern matching method the oldest and most commonly used approach is dynamic programming. By using dynamic programming approach especially in DNA sequencing [Needleman-Wunsch(1970)] algorithm and [Smith-waterman algorithms(1981)] are more complex in finding exact pattern matching algorithm. By this method the worst case complexity is O(mn). The major advantage of this method is flexibility in adapting to different edit distance functions. The first bit-parallel method is known as “shift-or” which searches a pattern in a text by parallelizing operation of non deterministic finite automation. This automation has m+1 states and can be simulated in its non deterministic form in O(mn) time. [Ukkonen (1985)] proposed automation method for finding approximate patterns in strings. He proposed the idea using a DFA for solving the inexact matching problem. Though automata approach doesn’t offer time advantage over [Boyer-Moore algorithm(1977)] for exact pattern matching. The complexity of this algorithm in worst and average case is O(m+n).In this every row denotes number of errors and column represents matching a pattern prefix. Deterministic automata approach exhibits O(n) worst case time complexity. The main difficulty with this approach is construction of the DFA from NFA which takes exponential time and space. The [Knuth-Morris-Pratt algorithm(1977)]is based on the finite state machine automation. The pattern P is pre-processed to create a finite state machine M that accepts the transition. The finite state machine is usually represented as the transition table. The complexity of the algorithm for the average and the worst case performance is O(m+n).
3. An Index Based Even Odd Multiple Pattern Matching Algorithm(IEOMPM)
The proposed work use the indexes for the DNA sequence of character set ∑ to search a pattern in a string. Let S be a string of length n and the pattern P of length m. Let ∑* be the set of all possible strings with the alphabet set ∑. Then S, P∑*, |S| = nand |P| = m. Generally |P| ≤ |S| i.e., m ≤ n. Initially we need to build up a table called index table, which is useful to reduce the number of comparisons. We call this as the pre-processing phase, once the preprocessing phase is completed then searching phase starts. Initially index table is created for a given sequence as it scans the character from left to right according to the index subscript these characters are placed into their index. Once the index is created it can be used for all types of input patterns. After building the index table for each pattern P we need to check whether the pattern P occurs in the sequence or not. In the IEOMPM algorithm for each occurrence of the first character of the pattern the characters of the pattern are matched to the sequence in an even odd fashion. First it checks in an even number based form, if all the characters are matched then it checks for the odd number comparison. If there is a mismatch at any character in the pattern while it is comparing with the sequence then it stops the matching process. If all the characters matches then the pattern occurs in the sequence and prints the starting index of the pattern or if any character mismatches then we will stop searching and then go to the next index stored in the index table of the same row which corresponds to the first character of the pattern P.
3.1 IEOMPM Algorithm
Input: String S of n characters and a pattern P of m characters, where S,P∑*. Output: The no. of occurrence and the positions of P in S.
Step1: Integer arrays indexTab[4][n], charIndex[4] Integer found:=1, n_occ:=0,n_cmp:=1,j Step2: FOR i:=0;i<n;i:=i+1
indexTab[(S[i]-64)%5][charIndex[(S[i]-64)%5]++]:=i
End FOR
Step 3: FOR i:=0;i<chatIndex[(P[0]-64)%5];i:=i+1 found:=1
IF i+m-1 > n-1 found:=0
SKIP the test, GOTO step 4.
End IF
FOR j:=0;j<m;j:=j+2 n_cmp:=n_cmp+1
IF S[i+j]≠P[j]
found:=0 SKIP the test, GOTO step 4.
End IF
End FOR
FOR j:=1;j<m;j:=j+2
IF S[i+j]≠P[j]
found:=0 SKIP the test, GOTO step 4.
End IF
End FOR
Step 4: IF found:=1
n_occ:=n_occ+1
PRINT “Pattern Found At Location i, Occurrence no is: n_occ”
End IF
End FOR
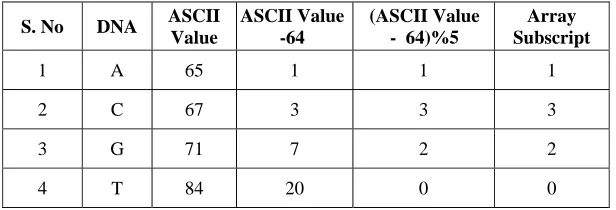
The index based algorithm for multiple pattern matching algorithm uses a table (2D vector) called index table. The basic idea used here is to store all the indexes of each character in its corresponding row in the 2D vector. Here we use a new technique called ASCII value based indexing technique, which is used to reduce the pre-processing time and due to this the number of comparisons gradually reduced. The subscript [(S[i]-64)%5] always returns a subscript value in the range 0,1,2,3 which is needed for subscripting 2D array of size [4][n]. The subscript values 0,1,2,3 represent the characters T, A, G, C respectively.
Table.1. Array subscript values for the DNA sequence
S. No DNA ASCII Value
ASCII Value -64
(ASCII Value - 64)%5
Array Subscript
1 A 65 1 1 1
2 C 67 3 3 3
3 G 71 7 2 2
4 T 84 20 0 0
So for each character in the string of the function (S[i]-64)%5) directly references to its corresponding row in the indexTable[ ][ ]. The vector charIndex[4] stores the counter value of each occurrence of each character with reference to [(S[i]-64)%5]. For each occurrence of the first character of the pattern, the proposed algorithm compares all the characters one by one from left to right in an even odd fashion, if all characters match with the pattern it prints pattern found from its starting index. If any character mismatches it skips the search and continues to search from the next index. Let S be the string of length n, P be the pattern of length m and S, P∑*, and i be the index of the first character of the pattern P in the string S. Let Xi denotes the character at the
ith location in the string X .Now for each value of i, First it compare all the characters located at even indexes, then after we compare the remaining characters (characters at odd indexes) sequentially. Any character mismatches at any time we skip the test and continues search of P from the next value of i.
i.e., Whether Pr = Si+r for r=0, 2, 4,…, where r≤m-1 Whether Pr = Si+r for r=1, 3, 5,…, where r≤m-1
If it is true for all values of r then it prints pattern found at the Location i and continues the search for next value of i.
3.2 This section describes different examples using the proposed approach (IEOMPM) for the DNA sequences.
Take a string S= ACTTAGGCTCAACGATGTTAGCATC of 25 characters and P=TTAG. The following index table stores all the indexes of each character A, C, G and T in its corresponding row. The 0th row stores the indexes of occurrences of the character T, 1st row for A, 2nd row for G and 3rd row for C. The first character in the pattern P is T so we start search for P from the 0th row (which stores the indexes of character T). The first index stored in 0th row is 2 so we start the algorithm from 2nd character in the string for matching process.
Table.2. Index values for A,C,G and T sequence characters
The algorithm first compares all the even located characters then after odd located characters. So the 0th character of the pattern is compared with the character of first index of the 0th row in table.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
The 0th character (first character) of the pattern matches with its corresponding character of S from 2nd location of string S, and then it compares the 2nd character of the pattern to the corresponding character in the string.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
The 2nd character is matched so we need to compare the 4th character in the pattern. Since 4th character is not present in the pattern, compare the characters which are located at odd places. The character at 1st index of pattern is compared with its corresponding character of S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
Again it continues matching for 3nd character of the pattern. A C T T A G G C T C A A C G A T G T T A G C A T C
T T A G
Now all the character matches it prints the starting location of the pattern of the string. The 2nd index stored in the 0th row of the table is 3, we start search again from the index 3 of the string.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
The 0th character of pattern is matched with the 3rd character of string S, so we will continue the for 2nd character of pattern P with its corresponding character of S from 3th location of S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
Since it was mismatched, so we stop the search from P for the 3rd index of S, and continues the next index stored in the 0th row of indexTab[4][n]. The third index stored in the 0th row is 8 so we start search from the index 8 of the string S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
The 0th character of pattern P (first character) is matched then it compares the 2nd character of P with its corresponding character of S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
It is matched so start the match for the odd characters of P. We compare the 1st character of P with its corresponding character of S from 8th location of S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
The match failed for the 1st character of P, so we skip the test from the starting index 8. The next index stored in the 0th row of the index table is 15 so we start search from 15.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
Clearly the 0th character of P is matched. So we compare the 2nd character of P with its corresponding character of S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
DNA Sequence Index value
T 0 2 3 8 15 17 18 23
A 1 0 4 10 11 14 19 22
G 2 5 6 13 16 20
The match failed at this point, so we skip the test from the index 15. Again continues from the next index stored in the 0th row of the index table which is 17.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
The first character of P is matched, and then we compare the 2nd character of P with its corresponding character of S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
It is also matched. All the characters located at even places of P are matched, so we compare the characters of P of odd indexes. i.e.,1st character of P with its corresponding character of S.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
It is also matched so compare the 3rd character of P with its corresponding character of S. A C T T A G G C T C A A C G A T G T T A G C A T C
T T A G
All the characters are matched from the location 17, so we print pattern found at the location 17, and continues the search for P from the next index18 in the 0th row of index table.
A C T T A G G C T C A A C G A T G T T A G C A T C T T A G
The 0th character of P is matched, so we compare the 2nd character of P with its corresponding character of S. A C T T A G G C T C A A C G A T G T T A G C A T C
T T A G
Since it is mismatched, here we stop the comparison. The last index stored in the 0th row of the index table is 23, we need to start the search for P from 23rd character in S, there is only one character after the 23rd character in the string, but the pattern has 3 characters more from the 23rd location. So it is impossible to occur the pattern starting from 23rd location in S. Finally the search for P in S is completed, P occurred two times in the string S.
3.3 The below DNA sequence dataset has been taken for the testing of IEOMPM algorithm .The DNA biological sequence S∑*of size n=1024 and pattern P∑*. Let S be the following DNA sequence.
AGAACGCAGAGACAAGGTTCTCATTGTGTCTCGCAATAGTGTTACCAACTCGGGTGCCTATTGGCCTCCA AAAAAGGCTGTTCAACGCTCCAAGCTCGTGACCTCGTCACTACGACGGCGAGTAAGAACGCCGAGAAGG TAAGGGAACTAATGACGCGTGGTGAATCCTATGGGTTAGGATCGTGTCTACCCCAAATTCTTAATAAAAA ACCTAGGACCCCCTTCGACCTAGACTATCGTATTATGGACAAGCTTTAACTGTCGTACTGTGGAGGCTTC AAAACGGAGGGACCAAAAAATTTGCTTCTAGCGTCAATGAAAAGAAGTCGGGTGTATGCCCCAATTCCTT GCTGCCCGGACGGCCAGGCTTATGTACAATCCACGCGGTACTACATCTTGTCTCTTATGTAGGGTTCAGT TCTTCGCGCAATCATAGCGGTACTTCATAATGGGACACAACGAATCGCGGCCGGATATCACATCTGCTCC TGTGATGGAATTGCTGAATGCGCAGGTGTGAATACTGCGGCTCCATTCGTTTTGCCGTGTTGATCGGGA ATGCACCTCGGGGACTGTTCGATACGACCTGGGATTTGGCTATACTCCATTCCTCGCGAGTTTTCGATTG CTCATTAGGCTTTGCGGTAAGTAAGTTCTGGCCACCCACTTCGAGAAGTGAATGGCTGGCTCCTGAGCG CGTCCTCCGTACAATGAAGACCGGTCTCGCGCTAAATTTCCCCCAGCTTGTACAATAGTCCAGTTTATTAT CAAAGATGCGACAAATAAATTGATCAGCATAATCGAAGATTGCGGAGCATAAGTTTGGAAAACTGGGAGG TTGCCAGAAAACTCCGCGCCTACTTTCGTCAGGATGATTAAGAGTATCGAGGCCCCGCCGTCAATACCG ATGTTCTTCGAGCGAATAAGTACTGCTATTTTGCAGACCCTTTGCCAGGCCTTGTCTAAAGGTATGTTACT TAATATTGACAATACATGCGTATGGCCTTTTCCGGTTAACTCCCTG.
The index table for the above DNA sequence S is very large to show with different patterns sizes .We have randomly selected some different pattern ranging from 1-20 in size from the above DNA dataset and compared with the sequence. The analysis of the experimental results has been given in the below table. For different patterns P’s the number of occurrences and the pattern size of DNA sequence, number of comparisons and CPC ratio is shown in the Table.3. The Comparisons when compared with some of the existing different popular techniques has been compared. The result shows that there is lot of improvement in the proposed technique as shown in the Table 4.
4. Experimental Results
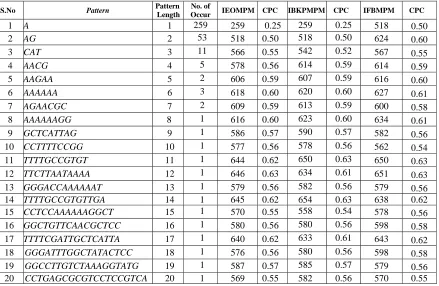
existing techniques with the proposed scheme and the experimental results are shown in Table.3. The below table compares two different algorithms with the proposed technique. Each time sample pattern is searched on the DNA data set of different patterns length randomly. The experiment is repeated several times with different pattern length also. It is observed that the gain is more significant on DNA sequences, as with sizes of patterns up to length 20, matching via even odd method and is much faster when compared with the best performing classical algorithms included in this study. To check whether the given pattern presents in the sequence or not we need an efficient algorithm with less comparison time and complexity. In general algorithms like Brute Force or other conventional algorithms will take much time to do the searching process. The proposed IEOMPM technique is one solution which gives better performance. This algorithm can be appreciated for decreasing the number of comparisons as well as CPC ratio compared with some of the popular algorithms as shown in the next section. Table.3. shows three different algorithms like IEOMPM, IBKMPM, IFBMPM and the number of comparisons of these algorithms with the CPC ratio.
Table.3.Experimental Results comparison with proposed Even-Odd algorithm
The second experiment in Table.4. evaluates the different algorithms with the proposed technique. We conducted different experiments to evaluate the performance of the proposed pattern matching technique. Table.4. summarizes our experimental results of the proposed algorithm and are executed with DNA data which is used in the above DNA dataset for the comparison of the results. In the simulation of the results we have tested by taking different pattern sizes ranging from 1 to 20. The below graph shows that the index based algorithm gives very good performance related to the number of comparisons and CPC ratio when compared with some of the existing pattern matching techniques. For different patterns P’s the number of occurrences and the number of comparisons of the proposed algorithms IEOMPM is shown in the Table.3. From the below experimental results, improvement can be seen that IEOMPM algorithm gives good performance compared to the some of the popular methods. Here the number of comparisons and CPC ratio gradually decreases and is less than 1 in case of proposed method where as the CPC ratio is greater than 1 in the existing models.
S.No Pattern Pattern
Length No. of
Occur IEOMPM CPC IBKPMPM CPC IFBMPM CPC
1 A 1 259 259 0.25 259 0.25 518 0.50
2 AG 2 53 518 0.50 518 0.50 624 0.60
3 CAT 3 11 566 0.55 542 0.52 567 0.55
4 AACG 4 5 578 0.56 614 0.59 614 0.59
5 AAGAA 5 2 606 0.59 607 0.59 616 0.60
6 AAAAAA 6 3 618 0.60 620 0.60 627 0.61
7 AGAACGC 7 2 609 0.59 613 0.59 600 0.58
8 AAAAAAGG 8 1 616 0.60 623 0.60 634 0.61
9 GCTCATTAG 9 1 586 0.57 590 0.57 582 0.56
10 CCTTTTCCGG 10 1 577 0.56 578 0.56 562 0.54
11 TTTTGCCGTGT 11 1 644 0.62 650 0.63 650 0.63
12 TTCTTAATAAAA 12 1 646 0.63 634 0.61 651 0.63
13 GGGACCAAAAAAT 13 1 579 0.56 582 0.56 579 0.56
14 TTTTGCCGTGTTGA 14 1 645 0.62 654 0.63 638 0.62
15 CCTCCAAAAAAGGCT 15 1 570 0.55 558 0.54 578 0.56
16 GGCTGTTCAACGCTCC 16 1 580 0.56 580 0.56 598 0.58
17 TTTTCGATTGCTCATTA 17 1 640 0.62 633 0.61 643 0.62
18 GGGATTTGGCTATACTCC 18 1 576 0.56 580 0.56 598 0.58
19 GGCCTTGTCTAAAGGTATG 19 1 587 0.57 585 0.57 579 0.56
Table.4. Comparison OF different pattern matching algorithms
Pattern
No of occu
IEOMPM Tri-
Match
Naïve
String MSMPMA Brute- Force
No.of Com CPC
No.of Com CPC
No.of Com CPC
No.of Com CPC
No.of Com CPC
A 259 259 0.2 1025 1.0 1024 1.0 1024 1.0 1024 1.0
AG 53 518 0.5 1284 1.2 1281 1.2 1230 1.2 1282 1.2
CAT 11 566 0.5 1321 1.2 1310 1.2 1298 1.2 1318 1.2
AACG 5 578 0.5 1380 1.3 1376 1.3 1359 1.3 1376 1.3
AAGAA 2 606 0.5 1393 1.3 1387 1.3 1375 1.3 1388 1.3
AAAAAAGG 1 616 0.6 1417 1.3 1407 1.3 1394 1.3 1409 1.3
TTCTTAATAAAA 1 646 0.6 1402 1.3 1399 1.3 1390 1.3 1390 1.3
GGCTGTTCAACGCTCC 1 580 0.5 1365 1.3 1349 1.3 1349 1.3 1349 1.3
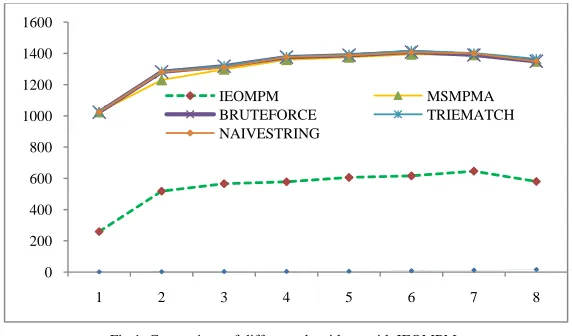
In the simulation experiment, the testing for pattern matching shown in Table.4 of different algorithms like MSMPMA, Brute-Force, Trie-Match, naïve string matching have been used for the comparison of the results with the IEOMPM algorithm. The performance of IEOMPM is observed with two parameters namely number of comparisons and comparisons per character ratio (CPC). The results shows that IEOMPM provides best performance and reduces gradually in CPC over other methods. It can be concluded that index based algorithm possesses outstanding performance related to the number of comparisons and CPC ratio. The experiment is tested for different pattern sizes and graph is plotted accordingly. Fig. 4 shows the reduction of number of comparisons with the existing techniques. In the final experiment we compare our algorithm with traditional existing traditional method under different pattern sizes ranging from 1 to 16 in size and graph is plotted accordingly with these results. Fig 1. Shows the graph comparison of different pattern matching algorithms with IEOMPM. From above graph it is clear that proposed (IEOMPM) algorithm outperforms when compared with all other algorithms. The dotted line shows the IEOMPM model where as MSMPMA, Brute-Force, Trie-matching and Naïve searching is shown by solid lines.
Fig 1. Comparison of different algorithms with IEOMPM.
4.1 The following are observed from the experimental results
From the above results the following are observed from the experimental results. The number of comparison gradually reduces and the CPC ratio decreases accordingly compared with the available techniques. The current algorithm works for the input file of any size. It gives good performance for DNA related sequence applications due to less number of characters.
0 200 400 600 800 1000 1200 1400 1600
5. Conclusion
We have presented a method to accelerate pattern matching using even odd technique. Our preliminary results shows the feasibility of this approach, which can significantly reduce the number of comparison with existing pattern matching methods. In this paper we proposed a new technique for multiple pattern matching algorithms. Many different patterns are verified by analyzing experimental results using different DNA sequence. The result shows that as size of the pattern increases the number of comparisons decreases and has better performance than other algorithm with the proposed algorithm. Therefore it is feasible and this method can be used in application related to approximate pattern matching in biological sequence data set for the future work. Finally, one other interesting aspect of our technique lies in the fact that the number of comparison decreases and is reduced to more than half compared to existing methods.
References
[1] Berry, T. and S. Ravindran,(1999) A fast string matching algorithm and experimental results. In: Proceedings of the Prague Stringology Club Workshop ’99, Liverpool John Moores University, pp: 16-28.
[2] Boyer R. S., and J. S. Moore,(1977) ‘‘A fast string searching algorithm‘ Communications of the ACM 20, 762- 772. [3] D.M. Sunday(1990), A very fast substring search algorithm, Comm. ACM 33 (8) 132–142.
[4] Horspool, R.N., 1980. Practical fast searching in strings. Software practice experience, 10:501-506
[5] Knuth D., Morris. J Pratt(1977).V Fast pattern matching in strings, SIAM Journal on Computing, Vol 6(1), 323-350.
[6] Needleman, S.B Wunsch, C.D(1970). “A general method applicable to the search for similarities in the amino acid sequence of two proteins.” J.Mol.Biol.48,443-453.
[7] Raju Bhukya, DVLN Somayajulu(2010),‘‘An Index Based Forward backward Multiple Pattern Matching Algorithm, ‘World Academy of Science and Technology..June , pp347-355.
[8] Raju Bhukya, DVLN Somayajulu(2010),” An Index Based K-Partition Multiple Pattern Matching Algorithm”, Proc. of International Conference on Advances in Computer Science pp 83-87.
[9] Smith,T.F and waterman, M (1981). Identification of common molecular subsequences T.mol.Biol.147,195-197. [10] Ukkonen,E.(1985), Finding approximate patterns in strings J.Algor. 6, 132-137.