2016 Joint International Conference on Artificial Intelligence and Computer Engineering (AICE 2016) and International Conference on Network and Communication Security (NCS 2016)
ISBN: 978-1-60595-362-5
A Two-way Hybrid Query Tree Anti-collision Algorithm
Hong-Wei DENG
1,2,a*, Hui WANG
1,b, Xiao-Man LIANG
1,c1School of Computer Science and Technology, Hengyang Normal University, Hengyang Hunan 421002, China
2School of Information Science and Engineering, Central South University, Changsha Hunan 410083, China
a[email protected], b[email protected], c[email protected]
*Corresponding author
Keywords: Two-way, Distance of Collision, Query Tree, Backward Search.
Abstract. Based on the Hybrid Query tree algorithm, this new algorithm compares the sums of collision distances: in forward direction, utilizing the combined information of the highest and the second highest bit of collision, categorizes the tags and decides gaps of delay to reduce collision; In reverse, utilizing collision template to form identification tree by using leaf nodes of electronic tags. The findings from the simulated experiments show that this proposed algorithm is superior to QT and HQT by decreasing the number of query and the traffic volume of system communication so that the efficiency of tag identification is greatly enhanced.
Introduction
RFID technology is the core one of the Internet of things application system, and RFID tag identification is a key technique which restricts the development of the RFID technology, as tag collision greatly reduces the tag identification speed and recognition rate of the reader. Therefore, the research on collision algorithm is of vital importance[1].
The anti-collision algorithm consists of two types of algorithms: uncertainty and certainty
[2].With uncertainty algorithm randomness is high, and channel utilization rate is low, there will be a
“starvation” phenomenon; with certainty algorithm tag recognition rate is high, but delay rate of identification is high. At present, the researchers combine with the characteristics of the two algorithms, and form some mixed anti-collision algorithm [3].
In this paper, based on the bidirectional query tree algorithm, according to the details of the highest and the second-highest bits of collision, dynamically generate query prefix, reversely introduce collision template, and decrease the number of queries for tag identification and traffic volume.
Theoretical Basis of Algorithm Query Tree Algorithm [4]
Hybrid Query Tree [5]
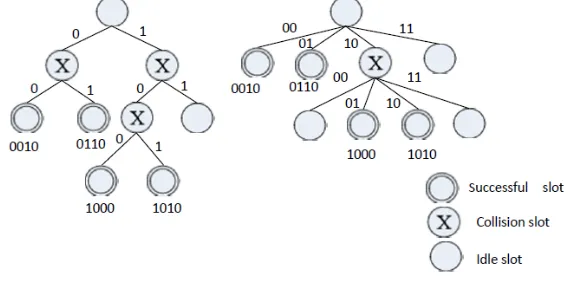
Hybrid Query Tree Algorithm refers to as the HQT algorithm. It is similar to the query tree algorithm. But when the collision happens, the reader adds two binary numbers, such as 00, 01, 10 and 11, behind the query prefix to generate a new query prefix and puts it to the query queue. Then constantly increase the prefix length until all tags are correctly identified. For example, there are four unidentified tag IDs: 0010, 0110, 1001, 1010, the recognition process is shown in figure 2.
Figure 1. QT Algorithm. Figure 2. HQT Algorithm.
Two-Way Hybrid Query Tree Anti-Collision Algorithm Algorithm Instruction Constraint
In order to make full use of the known information about the collisions and reduce the number of queries and traffic volume, the algorithm improves the instructions based on the original algorithm as follows:
(1) Collision Distance: the relative distance of collision of data bits and the center of the tag, DH
and DL respectively define as the distance of the sum of high and low collision. When the reader
receives the information of tags returned, it distinguishes the collision first. Then it calculates and compares the value of DH and DL. Finally, the reader retrieves from high to low if DH is greater than
DL, otherwise, from low to high. For example, the collision information is 1X01X1X0.So we can
know d1=3, d3=1, d6=3, then we need to choose reverse search method because DH (DH=3) is less
than DL (DL=4).
(2) Query Instruction--REQUEST: in this instruction there are three types of parameters: REQUEST (#), REQUEST (Ht, Hr) and REQUEST (p, Ht, Hr). The first instruction is the original
query instruction, it requests all the tags response; The second instruction requests tags calculate the decimal value of Ht and Hr. Then put it into the accumulator C; The parameter p in the last
instruction means the known prefix, the parameter Ht and Hr represent the highest and the second
highest bit of collision.
(3) Selection Instruction--SELECT. This instruction chooses the tags which number is selected in preparation for reading or writing data.
(4) Read Instruction--READ. This instruction will read the date of the tag which is selected. (5) Shielding Instruction--UNSELECT. This instruction makes the tag which number is selected inactive and does not response for the REQUEST instruction.
(6) Collision Template--CID. This instruction is the same bit as the tag. It will get the collision bit and make the collision set 0 and doesn’t change other bit.
Algorithm Description
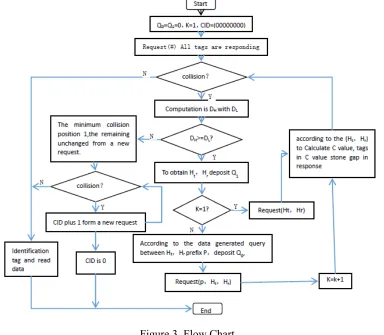
[image:2.612.163.449.158.301.2]DH≥DL. (1) A new query combination (Ht, Hr) of the highest and the second highest collisions will be inserted into the end of the queue Q1. An accumulator K, with original value 1, is to set up to
count the number of the REQUEST instructions. Then the reader gets the combination value of Ht
and Hr from the queue Q1 and generates the REQUEST (Ht,Hr) instruction and send to the tags. The
decimal value of Xt and Xr will be calculated and saved in its accumulator C, to which the tags will
respond in the corresponding time slot.
(2) The reader directly identifies the tag if it is the only one responding. READ instruction reads the data of the tag and shield it using UNSELECT instruction. If it is not the case, proceed with step 3.
(3) If multiple tags respond, the reader can calculate the value of Xt…Xr between the highest collision bit Ht and second highest collision bit Hr. Then, the value can be used as a new query prefix p and inserted in turn into the end of the queue Q0. At the same time, a new query
combination (Ht, Hr) after p is inserted into the end of the queue Q1.
(4) The reader generates a new query instruction REQUEST(p, Ht, Hr) from the query prefix p
and the combination of parameters (Ht, Hr) taken from the first part Q0 and Q1, and then sends the
instruction to the tags to instruct the response of the prefix p tags to re-identify the collision information.
(5) Algorithm is finished if Q0 and Q1 are empty, which indicates all the N tags are identified,
otherwise, return to step 2.
[image:3.612.116.500.331.666.2]DH<DL. (1)Reader receives the tag collision information and adds 1 to CID bit the lowest collision and sends a new REQUEST.
Figure 3. Flow Chart..
(2)The tags are identified if they respond to the REQUEST instruction sent by the readers. The instructions of selection, Read and Shielding will be continually sent in turn to the identified tags. Return to the step 1 until no tags responding.
Algorithm Example
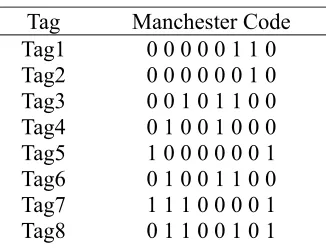
[image:4.612.224.387.143.269.2]Assume that the reader has 8 identification tags within the scope of the reader's identification.The tag's ID number is 8 bits.As shown in Table1.
Table 1. Manchester Code. Tag Manchester Code Tag1
Tag2 Tag3 Tag4 Tag5 Tag6 Tag7 Tag8
0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1 0 0 0 1 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 1 0 0 1 1 0 0 1 1 1 0 0 0 0 1 0 1 1 0 0 1 0 1
The realization process of the algorithm is as follows:
(1)Reader initializes query queues Q0 and Q1, the initial value is null and the CID is (00000000),
initialize the k=1.
(2)As is shown in Table 2, the decoding information, based on Manchester coding principle, is XXX0XXXX when all tags within the scope of the identification respond to REQUEST (#). The collision distance DH and DL is calculated: if DH<DL, tags are to be searched reversely. The collision
does not alter if it is REQUEST (00000000) with no tags responding. And it is the same with REQUEST (00000001). With REQUEST (00000010), Tag 2 responds and is identified, collision does not change. And so on until REQUEST (00000110), the collision changes when Tag 1 responds and is identified.
Table2. Collision Information. Table 3. Collision Information.
[image:4.612.143.281.444.591.2]
Table 4. Slot Information.
Table 5. Collision Information. Table 6. Collision Information.
(3) As is shown in Table 3, the remaining tags’ collision becomes XXX0XX0X as for the change of the collision. The collision distance DH and DL being calculated, DH>=DL, means the forward tag
searching. Insert (Ht, Hr) = (7, 6) (The highest collision bit Ht 7 and the second highest collision bit
Hr 6) into the end of the queue Q1. Counting the number of Request instruction, Reader collects (7,
6) from Q1 and generates a new query Request (7, 6) and sends it to the tags. The decimal value of (Xt Xr ) will be calculated and saved in its accumulator C, to which the tags will respond in the
corresponding time slot.Tag3’s XtXr = 00 means C = 0; Tag4,Tag6,Tag8’s XtXr = 01, C = 1; Tag5’s
XtXr =10,C =2; Tag7’s XtXr =11, C = 3. The tags will respond in the slot0, slot1, slot2, slot3
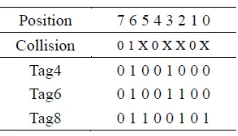
according to the different value of C, as is shown in Table 4. The collision information of Tag4,
Tag6 and Tag8 is shown in Table 5.
(3)From the table 5,we can calculate the value of DH and DL according to the collision
distance, we can know DH<DL, that is, reverse search tags. According to CID get REQUEST
(01000000), no tag response, the collision has not changed. According to CID get REQUEST (01000001), no tag response, the collision has not changed. And so on, According to CID get REQUEST (01001000), Tag 4 response and is identified, collision has changed. The collision information of Tag6 and Tag8 is shown in Table 6.
(4)From the table 6,we can calculate the value of DH and DL according to the collision
distance, we can know DH<DL, that is, reverse search tags.According to CID get REQUEST
(01000100), no tag response, the collision has not changed.CID’s lowest bit continues plus 1.According to CID get REQUEST (01001100), Tag 6 response and is identified, collision has not changed. According to CID get REQUEST (01100101), Tag 8 response and is identified. At this point, all the tags are identified, the algorithm is finished.
Algorithm Analysis
The definition of parameter names is as follows: K:Tag length
N:The total number of Query tags
Q: The total number of query instructions that Reader needs to transmit T:Transmission delay
Number of Query Instructions
In a practical application, Suppose number of unidentified tags is abundant, that is N→∞,Reader transmits the first time REQUEST(#) command, and can get to know tags owned by all K bit collision.
(1) In the stages of judging usage method
Reader needs to broadcast 1 query instruction REQUEST(#) to gain tag information. (2)DH≥DL
Given L bits are certain for the highest collision and the second-highest collision. There are N/4 tags for each collision slot time and one of collision slot-times is to be analyzed. The query process of every collision slot time can be demonstrated by a binary tree execute traverse operation and the number of query instruction is 2 node in the tree. Given the number of query instruction sent by Reader is Qe:
Corresponding to collision slot time there are 4 search trees, every last branch needs inquire time is Qe. Can get to know,DH≥DL average query instruction number is
Q1=4*Qe=4*(2K-L+1-1) =2 K-L+3-4 (2)
(3)DH<DL
Amount to face binary tree traverse, then query instruction number is number of binary tree leaf node. Then
Q2=2K-L (3)
From this can arrive at average query instruction time is:
Q=1+(Q1+Q2)/2 =2K-L+2+2K-L-1-1 (4)
Transmission Delay Analyze
(1)In judge method of application stages
Reader needs to broadcast 1 query instruction REQUEST (#) to gain tag information. Bit is:
T1=K (5)
(2)DH≥DL
Every time reader sends length of query instruction with tag reply sum of equal to tag ID sequence length, that is K. Therefore,in every collision slot time transmittal data bit length equals to reader send inquiry mandatory time with tag ID mark length product of sum, i.e.
To=K*Qe= K*(2K-L+1-1) (6)
Accessibility search 4 times collision slot time, channel in all need passed bit sum is:
T2=4*To =4*K*(2K-L+1-1) (7)
(3)DH<DL
Average query instruction times is Q2=2K-L, form this can reach bit is:
T3=K*2K-L (8)
Channel need passed bit sum Ta is:
Ta=T1+T2+T3=K+4*K*(2K-L+1-1)+K*2K-L=K*2K-L+3+K*2K-L-3K (9)
Suppose channel message transmission rate is V bit/s, transmission delay is T=Ta/V. Arrive at
transmission delay is:
T=Ta/V =( K*2K-L+3+K*2K-L-3K)/V (10)
Throughput Rate Analysis
S=N/Q*100% (11)
Above calculate accessibility throughput rate expression S is:
S=N/(2K-L+2+2K-L-1-1)*100% (12)
It can be concluded from the above Algorithm that: BMQ is much more effective when the tag length is longer, such as, decrease in the number of query instruction and the transmission delay, especially in the case of uncontinuity of collision location. The following simulation illustrates the superiority of BMQ algorithm: greatly reduced recognition time by a sharp reduction in transmission delay.
Algorithm Emulation Proof
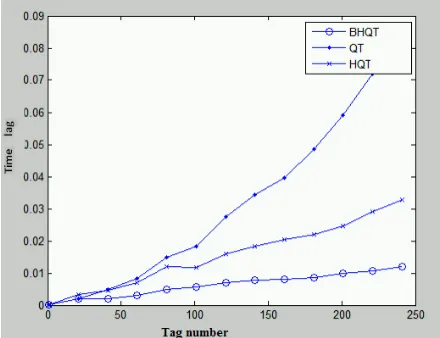
BHQT algorithm is verified by MATLAB simulation tool in this paper. The findings from the simulation show that in the same experimental condition, BHQT greatly improves the performance of recognition and data transmission etc., compared with QT and HQT, as is shown in figure 4.
[image:7.612.195.415.295.464.2]Figure 4. Comparison of BHQT, QT and HQT Algorithms.
Concluding Remarks
This paper, based on the hybrid query tree algorithm, puts forward an improved one. By comparing the sum of the collision distance, different queries are adopted: the quad-tree query for the positive search based on the specific information of the highest and the second highest collision bits to generate the dynamic query prefix; the basic binary algorithm query for the negative search. There is a sharp reduction in the number of interaction and the query of tag identification and the amount of communication.The findings of the simulation demonstrates that, compared with the basic binary algorithm, the dynamic binary, the basic query tree, the hybrid query tree, the performance of the proposed algorithm is significantly enhanced, which provides a promising future in the modern storehouse management.
Acknowledgement
References
[1]Joe I., Lee J. A novel anti-collision algorithm with optimal frame size for RFID system [C]. Proceedings of 5th IEEE International Conference on Software Engineering Research, Management and Applications, 2007: 424-428.
[2]Feng Dong-xu, Xia Zhe-lei, Ling Fang-hua.An Improved Anti-collision Algorithm in RFID System [J]. Journal of Hangzhou Dianzi University, 2010, 30(6): 109-112.
[3]Wang Chunhua, Xu Jing, Peng Guanchao, et al. Improved anti-collision algorithm for tag identification in RFID systems.Computer Engineering and Applications, 2011, 47(31): 104-107. [4]Choi J.H., Lee D., Lee H. Bi-Slotted tree based anti-collision protocols for fast tag identification in RFID systems [C]. IEEE Communications Letters, 2006: 861-863.
[5]Li Bingzhang, Jing Zhengjun, Luo Ye. A RFID anti-collision algorithm based on regressive-style binary system [J]. Computer Applications and Software, 2009, 26(12): 96-98.
[6]Myung J., Lee W. An adaptive memory less tag anti-collision protocol for RFID networks [C]. IEEEICC, 2005: 32-26.
[7]Hsu C.H., Chia Hao Yu, Yi Pin Huang, et al. An enhanced query tree (EQT) protocol for Memorylesstag anti-collision in RFID systems [J]. Second International Conference on Future Generation Communication and Networking FGCN '08, 2008: 427-432.