International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
454
Ontology based Text Mining
Poonam. B. Kucheria
1, Prof Imran. R. Shaikh
21M.E. Student, 2Lecturer., Dept. of Computer Engg., SNDCOE & RC, Yeola, Savitribai Phule University, Pune, India
Abstract— Extracting information tends to recognize and
retrieve certain types of information from natural language
text. Fault dependency (D)-matrix is a systematic diagnostic
model which is used to capture the fault system information at the hierarchical system-level.
Whenever user type any query for searching any file or data, most probably all the files or data tries to match its search query with title of available data and constructs a D-matrix. It consist dependencies between observable symptoms and failure modes associated with a system. I have presented a new approach to extract information from unstructured documents which is based on an ontology application that describes a domain of interest. Starting with such ontology, I formulate rules to extract constants and context keywords from unstructured documents.
For each unstructured document of interest, system extracts its constants and keywords and applies a recognizer to organize extracted constants as attribute values of tuples in a generated database schema. To make my approach general, I have fixed all the processes and changed only the description of ontology for a different application domain. I have conducted on two different types of unstructured documents i.e. Weburl and another is PDF dataset.
Keywords — unstructured data, semi-structured data,
information extraction, information structuring, ontology.
I. INTRODUCTION
The evolution of internet is the purpose for sending information which led to the growth of on-line knowledge resources to the change of forms and formats used for their storage and transmission are text, data, video and audio. To maintain its performance, a complex system interacts with its surrounding to execute a set of tasks within an accepted range of tolerances. If anything goes wrong then it is considered as a fault. The fault detection and diagnosis (FDD) is done to detect the faults and then diagnose the root-causes to minimize the downtime of a system. To overwhelming size of the repair verbatim data restricts an ability of its effective utilization in the process of FDD. Text mining is gaining an attention due to its ability to automatically define the knowledge assets buried in unstructured text. Although storage space and transmission of data speed is no longer a problem, the text still remains in the most efficient form to present knowledge over the internet, compared to different audio, video and multimedia formats [2].
Users can retrieve data by browsing or keyword searching, which is useful or logical but limitation are there for access. Browsing is not suitable for locating particular items of data and also not cost effective as users to read the document to find the desired data. Keyword searching is better than browsing but in return it provides more amount of data which is not handled by user. To retrieve data efficiently from the web, researchers have taken ideas from database techniques where databases means structured data is required. Until now data available on the web is unstructured data. Various approaches have been suggested for querying the Web which falls into one of the two categories: generating wrappers for web pages and querying the web with web query languages
Clustering text documents is an important step. Mining text into different category groups in indexing, retrieval, management and mining of abundant text data on the Web. The challenging problems of text clustering are big volume, high dimensionality and complex semantics among others. [3].
Information extraction systems are different from information retrieval (IR) systems. The objective of information retrieval is finding documents that are relevant to a user’s needs from a collection of documents. Search engines of the Web generally function as information retrieval systems. Information extraction systems go one step further by extracting the information from the text and presenting them to the user instead of returning a link to a document and leaving the task of looking up and finding the information to the user.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
455
II. RELATED WORKRussell and Norvig, in their widely used textbook on artificial intelligence, state that information extraction aims to process natural language text to retrieve occurrences of a particular class of objects or events and occurrences of relationships among them. Presenting a similar view Riloof states that information extraction is a form of natural language processing in which certain types of information must be recognized and extracted from text. The focus of information extraction is natural language, as identified by these definitions, and as such it is seen as a subfield of natural language processing (NLP).
Attempts to annotate gene function automatically include statistical approaches, such as co-occurrence of biological entities with a keyword or Medical Subject Heading term (Stapley and Benoit 2000; Jenssen et al. 2001). These methods have high recall and low precision, as no effort is being made to identify the kind of relationship as it occurs in the literature.
Another approach has involved semantic and/or syntactic text-pattern recognition methods with a keyword representing an interaction (Sekimizu et al. 1998; Thomas et al. 2000; Friedman et al. 2001; Ono et al. 2001). They have high precision but low recall, because recognition patterns are usually too specific.
Other machine learning approaches have classified abstracts and sentences for relevant interactions, but have not extracted information (Marcotte et al. 2001; Donaldson et al. 2003).
Wimalasuriya and Dou describe a close relation between OBIE and the SemanticWeb. OBIE systems generate semantic content which is known as Semantic Annotation for the Web pages. Semantic agents can directly process semantic content for Information Retrieval. Information Extraction guided by Ontologies: Wimalasuriya and Dou believe that guide is a suitable word to describe the interaction between the ontology and the information extraction process in an OBIE system: in all OBIE systems, the information extraction process is guided by the ontology to extract things such as classes, properties and instances. This means that no new information extraction method is invented but an existing method is oriented to identify the components of ontology.
M. Schuh, J. W. Sheppard, S. Strasser, R. Angryk, and C. Izurieta, personalized search has been proposed for many years and many personalization strategies have been investigated, to remove Faults and provide ontology-guided data mining and data transformation but Discovery is loss because result is not in form of matrix. [26]
Harpreet singh and Renu Dhir also did study on transaction reduction for finding item sets based on tags and shows result in matrix but it does not give accurate result. Its search is only based on tags. There was no use of ontology. [29]
M. Gaeta, F. Orciuoli, S. Paolozzi, and S. Salerno, provide an easy to use interface that generates relevant sequences of data in meaningful context and retrieve and display similar information but it only shows similar information not accurate result in this form like D-MATRIX.[27]
Ching-AngWu,Wen-Yang Lin,Chang-long Jiang, has proposed which builds useful data mining models and it present prototype multidimensional mining system,but mining hundreds of thousands of repair verbatim (typically written in unstructured text).
Wen Zhang,Taketoshi,Xijin Tang,QingWang, proposed on text mining such as document clusterization and assign cluster topic but it only cluster the frequent data but not showing result in D-Matrix.[25]
III. OUR APPROACH
Information extraction has existed as a field for a few decades and has experienced a significant development since past partly due to the Message Understanding Conferences (MUC). These conferences have provided standard extraction tasks and evaluation criteria and have led to an objective evaluation of different information extraction techniques. As a result, researchers have concentrated on the promising information extraction techniques developing better systems over the years. Out of such research work, two techniques have emerged as the dominant techniques for information extraction, namely machine learning and extraction rules.
However, expected the approach to work well for unstructured documents if data rich and narrow in ontological breadth and containing information of multiple records for the ontology. A document is data rich set if it has a number of identifiable constants such as dates, names, ID numbers, currency values, and so on. A document is narrow in ontological breadth which describes its application domain with a relatively small ontological model.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
[image:3.612.53.289.138.297.2]456
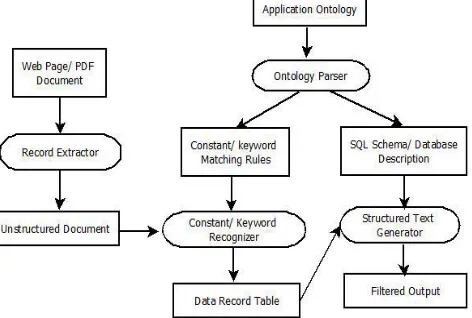
Figure 1.1: Extraction and Structuring Document Framework
The extraction and structuring data from an unstructured document is as shown in Figure1.1. Boxes are represented as a files and ovals as process. According to Figure 1.1, the input to approach is application ontology and an unstructured document, and the filtered and structured document whose data is in a database is provided as output. In advance all the processes and intermediate file formats are fixed. Figure1.1 depicts a general process that takes as input of declared ontology for an application domain of interest and an unstructured document within the applications domain and generates an output as structured data, filtered with respect to the ontology [1]. For human interfaces the important step required is the initial creation of application ontology.
As shown in Figure 7.1, there are four main processes in framework- an ontology parser, a constant/keyword recognizer, a structured text generator and a record extractor. The input is application ontology and unstructured document which is extracted through web page/PDF document and the output is filtered structured document. The main program invokes parser recognizer and generator sequentially. The ontology parser is invoked only once at the beginning of execution, whenever the recognizer and generator are invoked repeatedly in sequence for each unstructured document which to be processed. Constants are potential values i.e. lexical object sets while context keywords are associated with any object set either lexical or non-lexical so it is possible to present ontology textually.
Recently I am passing specific document or website manually to the record extractor which automatically removes the HTML tags and separates the input document into unstructured document.
Further ontology parser is invoked which creates an SQL schema as a sequence of create table statements for a given application ontology. All information is not needed to the structured-text generator, so parser can extracts only the relevant information like list of objects, constraints and relationships to be used by the generator.
A mapping is provided between the table declarations in the SQL schema and the relationships in the ontology. It also provides the cardinality relationship constraint which can be one-one, one-many, and many-many. And the parser also creates a file of constant/keyword matching rules which further passed to constant/keyword recognizer. Then data record table creates a data according to table and provided to structured-text generator. Finally, the structured-text generator process creates a structured file output.
IV. METHODOLOGY
Since ontology-based information extraction is new field, many interesting research directions related to it are yet to be explored. This paper explores two such research directions, which have the potential to make significant contributions towards improving the information extraction process carried out by ontology-based information extraction systems. Brief description on these two directions is presented below:
i) Designing a component-based approach for information extraction:
Domain ontology contains classes, which represent entity sets in the domain, and properties, which represent relationships between classes. Ontology-based information extraction systems can be designed in such a manner that they use independently deployable components with clear interfaces to make extractions with respect to specific classes and properties. These components are known as information extractors.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
457
This makes the reuse of components for information extraction structured and straight-forward.ii) Using multiple ontologies in information extraction:
Almost all previous ontology-based information
extraction systems make use of a single ontology although multiple ontologies are available for most domains. Such multiple ontologies either specialize on sub-domains or provide different perspectives on the same domain, which can be seen as two scenarios for having multiple ontologies for the same domain. By using more than one ontology in information extraction system is interesting because it has the potential to make more extractions and thus lead to an improvement in performance measures. In designing information extraction systems that use multiple ontologies, principles have to be developed to accommodate multiple ontologies and to facilitate interaction between them. The concept of information extractor, conceived under the component-based approach for information extraction.
V. SYSTEM IMPLEMENTATION
There are two modules in my system as follows: 1. Structuring of data from unstructured specific PDF file
First user passing pdf file path as an input parameter. After getting the path then it is validated. If the path is valid then data is fetched from pdf into text format, then the text data is transferred into XML. As per the requirement I am converting unstructured data into structured data. Then structured data is stored in the database for further operations like sorting, searching etc.
2. Get structured data from specific Social Websites
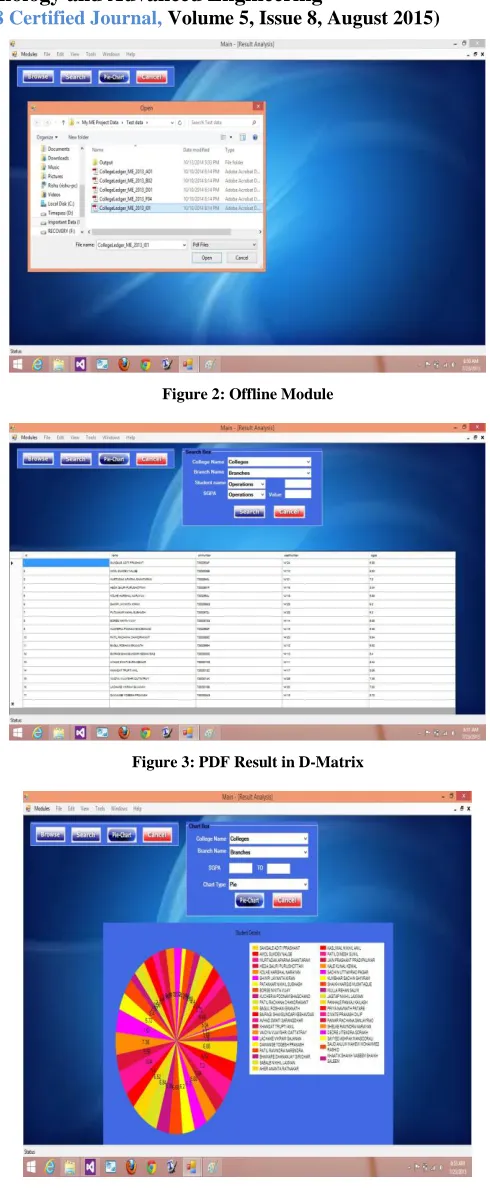
User passing web URL in text box as an input parameter. After getting URL we are validating URL with null URL or URL name which is passed. If the URL is valid then html contents are fetched of that URL. Further html contents are parsed into HTMLAgibility object. As per the requirement I am converting unstructured data into structured data. Then structured data is stored in the database for further operations like sorting, searching etc. Offline Module: In offline module, user browses the M.E mark-sheet PDF as shown in Figure 2. According to input, result is in D-Matrix form as shown in Figure 3 and also in Graph form as shown in Figure 4 i.e Pie Chart Graph.
[image:4.612.320.565.114.710.2]Figure 2: Offline Module
Figure 3: PDF Result in D-Matrix
[image:4.612.328.558.472.702.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
[image:5.612.324.564.128.317.2]458
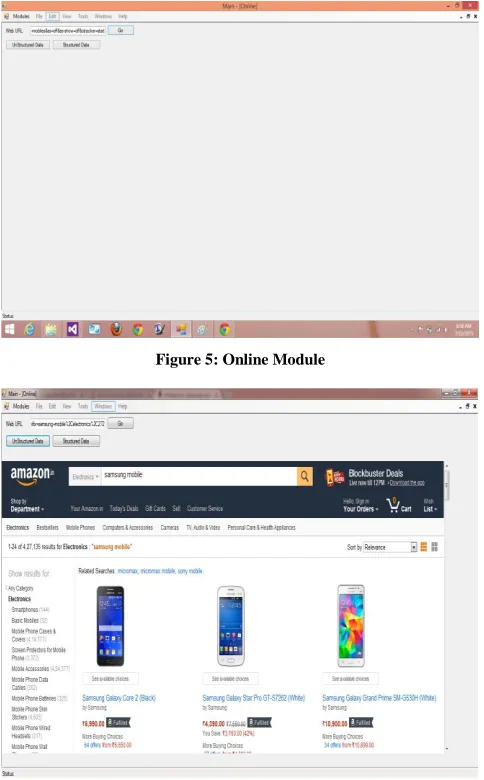
Online Module: In Online Module, user has to pass an WebURL of web- site as shown in Figure 5 and then click on UnStructured button so that unstructured data is retrieved as shown in Figure 6. Further click on Structured button so that result is displayed in structured form i.e in D-Matrix as shown in Figure 7.Figure 5: Online Module
Figure 6: UnStructured Data from Amazon URL
Figure 7: Structured Data of Amazon URL
VI. PERFORMANCE EVALUATION
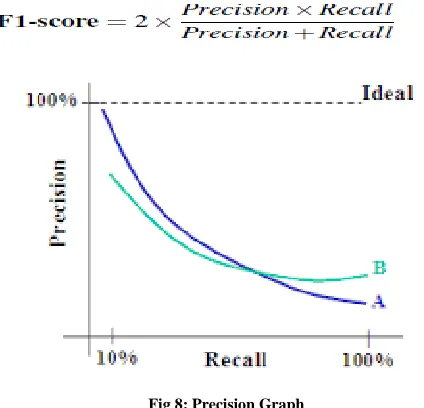
Using multiple ontologies in information extraction has the potential to extract more information from text and thus leads to an improvement in performance measures. The main performance measures used in information extraction, which are precision, recall and F1-measure. Precision shows the fraction of correct extractions out of all the extractions made whereas recall shows the fraction of correct extractions made out of all possible correct extractions. With {Relevant} and {Retrieved} representing the set of all possible correct extractions and the set of extractions made respectively, precision and recall are defined as follows:
[image:5.612.48.290.208.598.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
[image:6.612.55.267.256.460.2]459
It can be seen that a system can improve recall at the expense of precision by making many extractions. Similarly, precision can be improved at the expense of recall by making only few extractions that are highly likely to be accurate. Hence, a metric that takes both precision and recall into consideration is necessary to accurately evaluate the performance of an information extraction system. F1-score, which is the harmonic mean between precision and recall, is widely used for this purpose. It is defined as follows:Fig 8: Precision Graph
VII. CONCLUSIONS
In my paper, a ontology-based text mining methodology has been proposed to construct the D- matrices by automatically mining the unstructured repair verbatim data collected during fault diagnosis. In actual life, the manual construction of a D-matrix diagnostic model corresponding to the complex systems is not practical as it would involve significant effort to integrate the knowledge and represent it in a D-matrix.
I have provided a framework for converting data-rich unstructured documents into structured documents. In addition, I have implemented the procedures in my framework, and I have demonstrated that framework and implemented procedures achieve good results. However, much remains to be done.
In future, for online module, display comparison of websites product data.
REFERENCES
[1] Dnyanesh G. Rajpathak, Satnam Singh, “An Ontology-Based Text Mining Method to Develop D-Matrix from Unstructured Text, IEEE Transactions on System, Man and Cybernetics System, Vol.44,No.7, July 2013.
[2] David W. Embley,Douglas M. Campbell, Randy D. Smith, “Ontology-Based Extraction and Structuring of Information from Data-Rich Unstructured Documents,” Brigham Young University, Provo, Utah 84602, U.S.A.
[3] Ms. Madhuri M. Varma., Prof. Jyoti Nandimath, “An Ontology-Based Text Mining Method To Construct D-Matrix For Fault Detection And Diagnosis Using Graph Comparison Algorithm,” International Journal Of Innovative Research in Information Security (IJIRIS), Issue 2, Volume 5 (May 2015)
[4] Ayaz Ahmed Shariff K, Mohammed Ali Hussain , Sambath Kumar, “Leveraging Unstructured Data into Intelligent Information Analysis Evaluation,” International Conference on Information and Network Technology IACSIT Press, Singapore vol.4 (2011)
[5] Tinal R. Thombare, Lalit Dole, “D-Matrix: Fault Diagnosis Framework,” International Journal of Innovative Research in Computer and Communication Engineering, Vol. 3, Issue 3, March 2015
[6] Raghu Anantharangachar, Srinivasan Ramani, S Rajagopalan,“Ontology Guided Information Extraction from Unstructured Text, International Journal of Web Semantic Technology (IJWesT) Vol.4, No.1, January 2013
[7] E. Riloff., “Information extraction as a stepping stone toward story understanding”. Understanding language understanding: computational models of reading, pages 435460, 1999.
[8] Kanagaraj.S and Dr.Sunitha Abburu,, ”Converting Relational Database into Xml Document”, IJCSI International Journal of Computer Science Issues, Vol. 9, Issue 2, No 1, March 2012. [9] Swati S Hinge, B. R. Nandwalkar. “A Survey on Mining of
Unstructured Text for Development of D-Matrix”, Int.J.Computer Technology Applications,Vol 5,Nov-Dec 2014.
[10] Vishal Gupta andGurpreet S. Lehal. “ A Survey of Text Mining Techniques and Applications”. Journal of Emerging Technologies In Web Intelligence, Vol. 1, No. 1, August 2009.
[11] Jionghua Ji“Semi-Automatic Ontology-Based Knowledge Extraction And Verification From Unstructured Document”,University Of Florida 2000.
[12] Xing Jiang and Ah-Hwee Tan. “Mining Ontological Knowledge from Domain- Specific Text Documents” , Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM05)1550-4786/05 ,2005 IEEE.
[13] Nesrine Ben Mustapha, Hajer Baazaoui, Marie-Aude Aufaure, Henda Ben Ghezala. “Survey on ontology learning from Web and open issues”,HAL Id: hal-00831675 https://hal-ecp.archives-ouvertes.fr/hal-00831675 , 7 Jun 2013.
[14] Ritesh Shah and Suresh Jain, “Ontology-based Information Extraction: An Overview and a Study of different Approaches”,International Journal of Computer Applications (0975 8887) Volume 87 No.4, February 2014.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
460
[16] Yihong Ding.“Semiautomatic Generation of Data-Extraction Ontologies. Department of Computer Science, Brigham Young University, July 3, 2001.
[17] Daya Chinthana Wimalasuriya. “Use Of Ontologies In Information Extraction” Department Of Computer And Information Science, University of Oregon,March 2011.
[18] Jan Paralic and ,Ivan Kostial “Ontology-based Information Retrieval” Department of Cybernetics and AI, Technical University of Kosice, Letna 9, 040 11 Kosice, Slovakia.
[19] Paul Buitelaar, Philipp Cimiano, Anette Frank, Matthias Hartung, Stefania Racioppa “Ontology-based information extraction and integration from heterogeneous data sources.”,Int. J. Human-Computer Studies 66 (2008) 759788.
[20] Stuart J. Russell and Peter Norvig.“Artificial Intelligence A Modern Approach.” Prentice-Hall, Inc. A Simon Schuster Company Englewood Cliffs, New Jersey 07632.
[21] Martin Labsky, Vojtech Svatek, and Marek Nekvasil. “Information Extraction Based on Extraction Ontologies:Design, Deployment and Evaluation.” University of Economics, Prague, Dept. Information and Knowledge Engineering, Winston Churchill Sq. 4, 130 67 Praha 3, Prague, Czech Republic.
[22] Hicham Snoussi, Laurent Magnin and Jian-Yun Nie “Toward an Ontology based Web Data Extraction.Centre de recherche informatique deMontral Sherbrooke, suite 100, Montral, Canada. [23] Alan Wessman,Stephen W. Liddle, David W. Embley.“A
Generalized Framework for an Ontology-Based Data-Extraction System”,Brigham Young University Provo, UT 84602, USA. [24] David M. Blei,Andrew Y. Ng,Michael I. Jordan “Latent Dirichlet
Allocation”, Journal of Machine Learning Research 3 (2003).