1569
Learning Representations from Imperfect Time Series Data
via Tensor Rank Regularization
Paul Pu Liang♣∗, Zhun Liu♢∗, Yao-Hung Hubert Tsai♣
Qibin Zhao♡, Ruslan Salakhutdinov♣, Louis-Philippe Morency♢
♣Machine Learning Department, Carnegie Mellon University, USA
♢Language Technologies Institute, Carnegie Mellon University, USA
♡Tensor Learning Unit, RIKEN Center for Artificial Intelligence Project, Japan
{pliang,zhunl,yaohungt,rsalakhu,morency}@cs.cmu.edu
Abstract
There has been an increased interest in mul-timodal language processing including multi-modal dialog, question answering, sentiment analysis, and speech recognition. However, naturally occurring multimodal data is often
imperfectas a result of imperfect modalities,
missing entries or noise corruption. To ad-dress these concerns, we present a regulariza-tion method based ontensor rank minimiza-tion. Our method is based on the observation that high-dimensional multimodal time series data often exhibit correlations across time and modalities which leads to low-rank tensor rep-resentations. However, the presence of noise or incomplete values breaks these correlations and results in tensor representations of higher rank. We design a model to learn such ten-sor representations and effectively regularize their rank. Experiments on multimodal lan-guage data show that our model achieves good results across various levels of imperfection.
1 Introduction
Analyzing multimodal language sequences spans various fields including multimodal dialog (Das
et al., 2017; Rudnicky, 2005), question
answer-ing (Antol et al., 2015; Tapaswi et al., 2015;
Das et al., 2018), sentiment analysis (Morency
et al., 2011), and speech recognition (Palaskar
et al., 2018). Generally, these multimodal
se-quences contain heterogeneous sources of infor-mation across the language, visual and
acous-tic modalities. For example, when instructing
robots, these machines have to comprehend our verbal instructions and interpret our nonverbal be-haviors while grounding these inputs in their
vi-sual sensors (Schmerling et al., 2017; Iba et al.,
2005). Likewise, comprehending human inten-tions requires integrating human language, speech,
∗
first two authors contributed equally
clean multimodal data
<latexit sha1_base64="h1pzHCMMRR0RKSBQVEr4zlmGh8c=">AAACBXicbVA9SwNBEN3z2/gVtdRiMQhW4U4FLYM2lgomCskR5vY2yeLu3rE7J4YjjY1/xcZCEVv/g53/xk1yhSY+GHi8N8PMvCiVwqLvf3szs3PzC4tLy6WV1bX1jfLmVsMmmWG8zhKZmNsILJdC8zoKlPw2NRxUJPlNdHc+9G/uubEi0dfYT3mooKtFRzBAJ7XLuy3kD5gzyUFTlUkUKolB0hgQBu1yxa/6I9BpEhSkQgpctstfrThhmeIamQRrm4GfYpiDQeE2DEqtzPIU2B10edNRDYrbMB99MaD7TolpJzGuNNKR+nsiB2VtX0WuUwH27KQ3FP/zmhl2TsNc6DRDrtl4USeTFBM6jITGwnCGsu8IMCPcrZT1wABDF1zJhRBMvjxNGofV4KjqXx1XamdFHEtkh+yRAxKQE1IjF+SS1Akjj+SZvJI378l78d69j3HrjFfMbJM/8D5/AB0omPM=</latexit>
imperfect multimodal data
<latexit sha1_base64="I3wmMCkkoG+gn08puQZqeM8eRbQ=">AAACCXicbVC7SgNBFJ31GeMramkzGASrsKuClkEbywhGhSSEu7N34+DM7jJzVwxLWht/xcZCEVv/wM6/cfIo1Hhg4HDOvdw5J8yUtOT7X97M7Nz8wmJpqby8srq2XtnYvLRpbgQ2RapScx2CRSUTbJIkhdeZQdChwqvw9nToX92hsTJNLqifYUdDL5GxFEBO6lZ4m/CeCqkzNDEK4jpXJHUageIREAy6lapf80fg0ySYkCqboNGtfLajVOQaExIKrG0FfkadAgxJoXBQbucWMxC30MOWowlotJ1ilGTAd50S8Tg17iXER+rPjQK0tX0dukkNdGP/ekPxP6+VU3zcKWSS5YSJGB+Kc8Up5cNaeCSNS6/6joAw0v2VixswIMiVV3YlBH8jT5PL/VpwUPPPD6v1k0kdJbbNdtgeC9gRq7Mz1mBNJtgDe2Iv7NV79J69N+99PDrjTXa22C94H9+GKZrX</latexit>
tensor rank regularization<latexit sha1_base64="qWvflx4gMMCU5rXKIOGbeflghyQ=">AAACDHicbVC7TgJBFJ3FF+ILtbSZSEysyK6aaEm0scREHgkQMjvchQmzs5uZu0bc8AE2/oqNhcbY+gF2/o3DQqHgrU7OOTf3nuPHUhh03W8nt7S8srqWXy9sbG5t7xR39+omSjSHGo9kpJs+MyCFghoKlNCMNbDQl9Dwh1cTvXEH2ohI3eIohk7I+koEgjO0VLdYaiPcox+kCMpEmmqmhlRDP5FMi4fMNLYut+xmQxeBNwMlMptqt/jV7kU8CUEhl8yYlufG2EmZRsEljAvtxEDM+JD1oWWhYiGYTpqFGdMjy/RoYH8JIoU0Y39vpCw0ZhT61hkyHJh5bUL+p7USDC46qVBxYrPy6aEgkRQjOmmG9oQGjnJkAeNa2F8pHzDNONr+CrYEbz7yIqiflL3TsntzVqpczurIkwNySI6JR85JhVyTKqkRTh7JM3klb86T8+K8Ox9Ta86Z7eyTP+N8/gBHLZxj</latexit>
clean entries<latexit sha1_base64="wuMzvz1f+N4dxLXkrZwJSF97FMk=">AAAB/XicbVDLSgMxFM3UV62v+ti5CRbBVZlRQZdFNy4r2Ae0Q8mkt21oJjMkd8Q6FH/FjQtF3Pof7vwb03YW2nogcDjnvnKCWAqDrvvt5JaWV1bX8uuFjc2t7Z3i7l7dRInmUOORjHQzYAakUFBDgRKasQYWBhIawfB64jfuQRsRqTscxeCHrK9ET3CGVuoUD9oID5hyCUxRUKgFmHGnWHLL7hR0kXgZKZEM1U7xq92NeBLaAVwyY1qeG6OfMo3CTh4X2omBmPEh60PLUsVCMH46vX5Mj63Spb1I26eQTtXfHSkLjRmFga0MGQ7MvDcR//NaCfYu/VSoOEFQfLaol0iKEZ1EQbtCA0c5soRxLeytlA+YZhxtYAUbgjf/5UVSPy17Z2X39rxUucriyJNDckROiEcuSIXckCqpEU4eyTN5JW/Ok/PivDsfs9Kck/Xskz9wPn8AKAWVqw==</latexit> imperfect entries
[image:1.595.315.522.230.366.2]<latexit sha1_base64="uEy9xlvD1dXmU2/rxG3w4dCph+Q=">AAACAXicbVDLSgMxFM3UV62vUTeCm2ARXJUZFXRZdOOygn1AO5RMeqcNzTxI7ohlqBt/xY0LRdz6F+78G9N2Ftp6IHA4594k5/iJFBod59sqLC2vrK4V10sbm1vbO/buXkPHqeJQ57GMVctnGqSIoI4CJbQSBSz0JTT94fXEb96D0iKO7nCUgBeyfiQCwRkaqWsfdBAeMBNhAioAjhQiVAL0uGuXnYozBV0kbk7KJEeta391ejFPQ3MBl0zrtusk6GVMoeASxqVOqiFhfMj60DY0YiFoL5smGNNjo/RoECtzIqRT9fdGxkKtR6FvJkOGAz3vTcT/vHaKwaWXiShJESI+eyhIJcWYTuqgPaFMajkyhHElzF8pHzDFOJrSSqYEdz7yImmcVtyzinN7Xq5e5XUUySE5IifEJRekSm5IjdQJJ4/kmbySN+vJerHerY/ZaMHKd/bJH1ifP4Lml48=</latexit>
Figure 1: Clean multimodal time series data (in shades of green) exhibits correlations across time and across modalities, leading to redundancy in low rank tensor representations. On the other hand, the presence of imperfect entries (in gray, blue, and red) breaks these correlations and leads to higher rank tensors. In these scenarios, we usetensor rank regularization to learn tensors that more accurately represent the true correla-tions and latent structures in multimodal data.
facial behaviors, and body postures (Mihalcea,
2012;Rossiter,2011). However, as much as more
modalities are required for improved performance,
we now face a challenge ofimperfectdata where
data might be 1) incomplete due to mismatched modalities or sensor failure, or 2) corrupted with random or structured noise. As a result, an im-portant research question involves learning robust representations from imperfect multimodal data.
Recent research in both unimodal and multi-modal learning has investigated the use of tensors for representation learning (Anandkumar et al.,
2014). Given representationsh1, ...,hM fromM
modalities, the order-M outer product tensorT =
h1⊗h2⊗...⊗hM is a natural representation for
all possible interactions between the modality
di-mensions (Liu et al., 2018). In this paper, we
learns a tensor representation that captures mul-timodal interactions across time. A key
observa-tion is that clean data exhibits tensors that are
low-ranksince high-dimensional real-world data is
of-ten generated from lower dimensional laof-tent
struc-tures (Lakshmanan et al., 2015). Furthermore,
clean multimodal time series data exhibits corre-lations across time and across modalities (Yang
et al., 2017; Hidaka and Yu, 2010). This leads
to redundancy in these overparametrized tensors
which explains their low rank (Figure1). On the
other hand, the presence of noise or incomplete values breaks these natural correlations and leads to higher rank tensor representations. As a
re-sult, we can usetensor rank minimizationto learn
tensors that more accurately represent the true correlations and latent structures in multimodal data, thereby alleviating imperfection in the input. With these insights, we show how to integrate ten-sor rank minimization as a simple regularizer for training in the presence of imperfect data. As com-pared to previous work on imperfect data (Sohn
et al., 2014;Srivastava and Salakhutdinov,2014;
Pham et al., 2019), our model does not need to
know which of the entries or modalities are imper-fect beforehand. Our model combines the strength of temporal non-linear transformations of multi-modal data with a simple regularization technique on tensor structures. We perform experiments on multimodal video data consisting of humans ex-pressing their opinions using a combination of lan-guage and nonverbal behaviors. Our results back up our intuitions that imperfect data increases ten-sor rank. Finally, we show that our model achieves good results across various levels of imperfection.
2 Related Work
Tensor Methods: Tensor representations have been used for learning discriminative representa-tions in unimodal and multimodal tasks. Tensors are powerful because they can capture important higher order interactions across time, feature di-mensions, and multiple modalities (Kossaifi et al., 2017). For unimodal tasks, tensors have been used for part-of-speech tagging (Srikumar and
Man-ning,2014), dependency parsing (Lei et al.,2014),
word segmentation (Pei et al., 2014), question
answering (Qiu and Huang, 2015), and machine
translation (Setiawan et al.,2015). For multimodal
tasks,Huang et al.(2017) used tensor products
be-tween images and text features for image caption-ing. A similar approach was proposed to learn
representations across text, visual, and acoustic features to infer speaker sentiment (Liu et al.,
2018;Zadeh et al.,2017). Other applications
in-clude multimodal machine translation (Delbrouck
and Dupont, 2017), audio-visual speech
recogni-tion (Zhang et al.,2017), and video semantic
anal-ysis (Wu et al.,2009;Gao et al.,2009).
Imperfect Data: In order to account for imper-fect data, several works have proposed generative
approaches for multimodal data (Sohn et al.,2014;
Srivastava and Salakhutdinov, 2014). Recently,
neural models such as cascaded residual
autoen-coders (Tran et al.,2017), deep adversarial
learn-ing (Cai et al., 2018), or translation-based
learn-ing (Pham et al.,2019) have also been proposed.
However, these methods often require knowing which of the entries or modalities are imperfect beforehand. While there has been some work on using low-rank tensor representations for
imper-fect data (Chang et al., 2017; Fan et al., 2017;
Chen et al.,2017;Long et al.,2018;Nimishakavi
et al., 2018), our approach is the first to
inte-grate rank minimization with neural networks for multimodal language data, thereby combining the strength of non-linear transformations with the mathematical foundations of tensor structures.
3 Proposed Method
In this section, we present our method for learning representations from imperfect human language across the language, visual, and acoustic modal-ities. In §3.1, we discuss some background on tensor ranks. We outline our method for learn-ing tensor representations via a model called Tem-poral Tensor Fusion Network (T2FN) in §3.2. In §3.3, we investigate the relationship between ten-sor rank and imperfect data. Finally, in §3.4, we show how to regularize our model using tensor rank minimization.
We use lowercase letters x ∈ R to denote
scalars, boldface lowercase letters x ∈ Rd to
de-note vectors, and boldface capital letters X ∈
Rd1×d2 to denote matrices. Tensors, which we
de-note by calligraphic lettersX, are generalizations
of matrices to multidimensional arrays. An
order-M tensor hasM dimensions,X ∈Rd1×...×dM. We
use⊗to denote outer product between vectors.
3.1 Background: Tensor Rank
h1
ℓ h2ℓ hTℓ
h1 a h2 a hT a . . . .. . h3 ℓ h3 a .. . h1 v h2 v h3 v hT v ...
[x1 ℓ, . . .xTℓ]
[
x
1,...a
x
T a]
[
x
1,...v
x
T v]
y Mt=ht
`⌦htv⌦hta
[image:3.595.73.292.59.279.2]<latexit sha1_base64="c6ZUwHfEASXn8HdFB5sLByT5Xx8=">AAACPnicdVC7SgNBFJ2Nrxhfq5Y2g0GwCrsqaCMEbWyECOYB2RhmJ7PJkNkHM3cDYdkvs/Eb7CxtLBSxtXR2k8IkemDgzDn3cu89biS4Ast6MQpLyyura8X10sbm1vaOubvXUGEsKavTUISy5RLFBA9YHTgI1ookI74rWNMdXmd+c8Sk4mFwD+OIdXzSD7jHKQEtdc264xMYUCKS2/QB8CXO/66XDNJu4jAhMtUJgftMzXij/wyija5ZtipWDrxI7CkpoylqXfPZ6YU09lkAVBCl2rYVQSchEjgVLC05sWIRoUPSZ21NA6KndpL8/BQfaaWHvVDqFwDO1d8dCfGVGvuursz2VPNeJv7ltWPwLjoJD6IYWEAng7xYYAhxliXucckoiLEmhEqud8V0QCShoBMv6RDs+ZMXSeOkYp9WrLuzcvVqGkcRHaBDdIxsdI6q6AbVUB1R9Ihe0Tv6MJ6MN+PT+JqUFoxpzz6agfH9A0UUsZg=</latexit> M= T X t=1 Mt <latexit sha1_base64="a1jY5th1Xy+fYanMukUdv4ksWM4=">AAACEXicbVC7SgNBFJ2Nrxhfq5Y2g0FIFXZV0CYQtLERIuQF2U2YnUySIbMPZu4KYckv2PgrNhaK2NrZ+TfOJlvExAMXDufcy733eJHgCizrx8itrW9sbuW3Czu7e/sH5uFRU4WxpKxBQxHKtkcUEzxgDeAgWDuSjPieYC1vfJv6rUcmFQ+DOkwi5vpkGPABpwS01DNLjk9gRIlI7qe4gh0V+70EKva0W8cLVhd6ZtEqWzPgVWJnpIgy1Hrmt9MPaeyzAKggSnVsKwI3IRI4FWxacGLFIkLHZMg6mgbEZ8pNZh9N8ZlW+ngQSl0B4Jm6OJEQX6mJ7+nO9Ei17KXif14nhsG1m/AgioEFdL5oEAsMIU7jwX0uGQUx0YRQyfWtmI6IJBR0iAUdgr388ippnpfti7L1cFms3mRx5NEJOkUlZKMrVEV3qIYaiKIn9ILe0LvxbLwaH8bnvDVnZDPH6A+Mr18w0J0+</latexit> M <latexit sha1_base64="uZvzERQPKMMR9NiLGAcS/T5qG+0=">AAAB8nicbVBNS8NAFHypX7V+VT16WSyCp5KooMeiFy9CBWsLaSib7bZdutmE3RehhP4MLx4U8eqv8ea/cdPmoK0DC8PMe+y8CRMpDLrut1NaWV1b3yhvVra2d3b3qvsHjyZONeMtFstYd0JquBSKt1Cg5J1EcxqFkrfD8U3ut5+4NiJWDzhJeBDRoRIDwShaye9GFEeMyuxu2qvW3Lo7A1kmXkFqUKDZq351+zFLI66QSWqM77kJBhnVKJjk00o3NTyhbEyH3LdU0YibIJtFnpITq/TJINb2KSQz9fdGRiNjJlFoJ/OIZtHLxf88P8XBVZAJlaTIFZt/NEglwZjk95O+0JyhnFhCmRY2K2EjqilD21LFluAtnrxMHs/q3nndvb+oNa6LOspwBMdwCh5cQgNuoQktYBDDM7zCm4POi/PufMxHS06xcwh/4Hz+AIM0kWU=</latexit> MT <latexit sha1_base64="8QgwEIjtHbIpE/ny7x/TC5TA1HM=">AAAB9HicbVDLSgMxFL3xWeur6tJNsAiuyowKuiy6cSNU6AvasWTSTBuayYxJplCGfocbF4q49WPc+Tdm2llo64HA4Zx7uSfHjwXXxnG+0crq2vrGZmGruL2zu7dfOjhs6ihRlDVoJCLV9olmgkvWMNwI1o4VI6EvWMsf3WZ+a8yU5pGsm0nMvJAMJA84JcZKXjckZkiJSO+nj/VeqexUnBnwMnFzUoYctV7pq9uPaBIyaaggWndcJzZeSpThVLBpsZtoFhM6IgPWsVSSkGkvnYWe4lOr9HEQKfukwTP190ZKQq0noW8ns5B60cvE/7xOYoJrL+UyTgyTdH4oSAQ2Ec4awH2uGDViYgmhitusmA6JItTYnoq2BHfxy8ukeV5xLyrOw2W5epPXUYBjOIEzcOEKqnAHNWgAhSd4hld4Q2P0gt7Rx3x0BeU7R/AH6PMH5FGSKw==</latexit> M1 <latexit sha1_base64="kEkwVroTad49Yl6qxE3XJxZ+nes=">AAAB9HicbVDLSgMxFL2pr1pfVZdugkVwVWZU0GXRjRuhgn1AO5ZMmmlDM5kxyRTK0O9w40IRt36MO//GTDsLbT0QOJxzL/fk+LHg2jjONyqsrK6tbxQ3S1vbO7t75f2Dpo4SRVmDRiJSbZ9oJrhkDcONYO1YMRL6grX80U3mt8ZMaR7JBzOJmReSgeQBp8RYyeuGxAwpEend9NHtlStO1ZkBLxM3JxXIUe+Vv7r9iCYhk4YKonXHdWLjpUQZTgWblrqJZjGhIzJgHUslCZn20lnoKT6xSh8HkbJPGjxTf2+kJNR6Evp2MgupF71M/M/rJCa48lIu48QwSeeHgkRgE+GsAdznilEjJpYQqrjNiumQKEKN7alkS3AXv7xMmmdV97zq3F9Uatd5HUU4gmM4BRcuoQa3UIcGUHiCZ3iFNzRGL+gdfcxHCyjfOYQ/QJ8/r0WSCA==</latexit> M2 <latexit sha1_base64="zcVGz7+t4ZIbw5VqiTiAzOeOQvE=">AAAB9HicbVDLSgMxFL3js9ZX1aWbYBFclZkq6LLoxo1QwT6gHUsmzbShmWRMMoUy9DvcuFDErR/jzr8x085CWw8EDufcyz05QcyZNq777aysrq1vbBa2its7u3v7pYPDppaJIrRBJJeqHWBNORO0YZjhtB0riqOA01Ywusn81pgqzaR4MJOY+hEeCBYygo2V/G6EzZBgnt5NH6u9UtmtuDOgZeLlpAw56r3SV7cvSRJRYQjHWnc8NzZ+ipVhhNNpsZtoGmMywgPasVTgiGo/nYWeolOr9FEolX3CoJn6eyPFkdaTKLCTWUi96GXif14nMeGVnzIRJ4YKMj8UJhwZibIGUJ8pSgyfWIKJYjYrIkOsMDG2p6ItwVv88jJpViveecW9vyjXrvM6CnAMJ3AGHlxCDW6hDg0g8ATP8Apvzth5cd6dj/noipPvHMEfOJ8/sMmSCQ==</latexit> M3 <latexit sha1_base64="UTWzPLBL6vIDwYDXR4ODZOrB8sY=">AAAB9HicbVDLSgMxFL1TX7W+qi7dBIvgqsyooMuiGzdCBfuAdiyZNNOGZpIxyRTK0O9w40IRt36MO//GTDsLbT0QOJxzL/fkBDFn2rjut1NYWV1b3yhulra2d3b3yvsHTS0TRWiDSC5VO8CaciZowzDDaTtWFEcBp61gdJP5rTFVmknxYCYx9SM8ECxkBBsr+d0ImyHBPL2bPp73yhW36s6AlomXkwrkqPfKX92+JElEhSEca93x3Nj4KVaGEU6npW6iaYzJCA9ox1KBI6r9dBZ6ik6s0kehVPYJg2bq740UR1pPosBOZiH1opeJ/3mdxIRXfspEnBgqyPxQmHBkJMoaQH2mKDF8YgkmitmsiAyxwsTYnkq2BG/xy8ukeVb1zqvu/UWldp3XUYQjOIZT8OASanALdWgAgSd4hld4c8bOi/PufMxHC06+cwh/4Hz+ALJNkgo=</latexit> language LSTM <latexit sha1_base64="4wOX6NYqLG9nll+8bFLf3vGko/o=">AAAB/XicbVDLSsNAFJ3UV62v+Ni5GSyCq5KooMuiGxcKFfuCNpTJdNIOnUzCzI1YQ/FX3LhQxK3/4c6/cdpmoa0HLhzOuZd77/FjwTU4zreVW1hcWl7JrxbW1jc2t+ztnbqOEkVZjUYiUk2faCa4ZDXgIFgzVoyEvmANf3A59hv3TGkeySoMY+aFpCd5wCkBI3XsvTawB0gFkb2E9Bi+vqvejDp20Sk5E+B54makiDJUOvZXuxvRJGQSqCBat1wnBi8lCjgVbFRoJ5rFhA7MhpahkoRMe+nk+hE+NEoXB5EyJQFP1N8TKQm1Hoa+6QwJ9PWsNxb/81oJBOdeymWcAJN0uihIBIYIj6PAXa4YBTE0hFDFza2Y9okiFExgBROCO/vyPKkfl9yTknN7WixfZHHk0T46QEfIRWeojK5QBdUQRY/oGb2iN+vJerHerY9pa87KZnbRH1ifP3B7lTI=</latexit> v is u al LS T M <latexit sha1_base64="PkdTAP5iIoRE3tOjUNsjVhu5mek=">AAAB+3icbVBNS8NAEN3Ur1q/Yj16WSyCp5KooMeiFw8KFfsFbSib7bZdutmE3UlpCfkrXjwo4tU/4s1/47bNQVsfDDzem2Fmnh8JrsFxvq3c2vrG5lZ+u7Czu7d/YB8WGzqMFWV1GopQtXyimeCS1YGDYK1IMRL4gjX90e3Mb46Z0jyUNZhGzAvIQPI+pwSM1LWLHWATSMZcx0Tg+6faQ9q1S07ZmQOvEjcjJZSh2rW/Or2QxgGTQAXRuu06EXgJUcCpYGmhE2sWEToiA9Y2VJKAaS+Z357iU6P0cD9UpiTgufp7IiGB1tPAN50BgaFe9mbif147hv61l3AZxcAkXSzqxwJDiGdB4B5XjIKYGkKo4uZWTIdEEQomroIJwV1+eZU0zsvuRdl5vCxVbrI48ugYnaAz5KIrVEF3qIrqiKIJekav6M1KrRfr3fpYtOasbOYI/YH1+QMNGpRu</latexit> ac ou st ic LS T M <latexit sha1_base64="x1Fk1eUX+Il9eXi9bofgql+EJEs=">AAAB/XicbVDLSgMxFM3UV62v8bFzEyyCqzKjgi6LblwoVOwL2qFk0kwbmskMyR2xDsVfceNCEbf+hzv/xkzbhbYeuHA4597k3uPHgmtwnG8rt7C4tLySXy2srW9sbtnbO3UdJYqyGo1EpJo+0UxwyWrAQbBmrBgJfcEa/uAy8xv3TGkeySoMY+aFpCd5wCkBI3XsvTawB0gJjRINnOLru+rNqGMXnZIzBp4n7pQU0RSVjv3V7kY0CZkEKojWLdeJwUuJMk8KNiq0E81iQgekx1qGShIy7aXj7Uf40ChdHETKlAQ8Vn9PpCTUehj6pjMk0NezXib+57USCM69lMs4ASbp5KMgERginEWBu1wxCmJoCKGKZ+fTPlGEggmsYEJwZ0+eJ/XjkntScm5Pi+WLaRx5tI8O0BFy0RkqoytUQTVE0SN6Rq/ozXqyXqx362PSmrOmM7voD6zPH5P/lUk=</latexit>
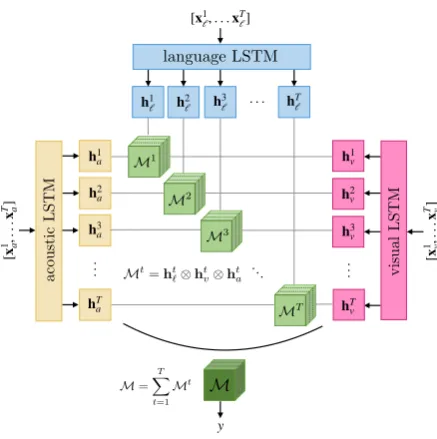
Figure 2: The Temporal Tensor Fusion Network (T2FN) creates a tensorMfrom temporal data. The rank ofMincreases with imperfection in data so we regularize our model by minimizing an upper bound on the rank ofM.
vectors have lower rank, while complex tensors have higher rank. To be more precise, we de-fine the rank of a tensor using Canonical Polyadic
(CP)-decomposition (Carroll and Chang, 1970).
For an order-MtensorX ∈Rd1×...×dM, there exists
an exact decomposition into vectorsw:
X =∑r
i=1
M
⊗
m=1
wmi . (1)
The minimalr for exact decomposition is called
therankof the tensor. The vectors{{wmi }Mm=1}
r i=1
are called the rankrdecomposition factors ofX.
3.2 Multimodal Tensor Representations
Our model for creating tensor representations is called the Temporal Tensor Fusion Network
(T2FN), which extends the model inZadeh et al.
(2017) to include a temporal component. We
show that T2FN increases the capacity of TFN to capture high-rank tensor representations, which itself leads to improved prediction performance. More importantly, our knowledge about tensor rank properties allows us to regularize our model effectively for imperfect data.
We begin with time series data from the lan-guage, visual and acoustic modalities, denoted
as [x1
`, ...,xT`], [x1v, ...,xTv], and [x1a, ...,xTa]
re-spectively. We first use Long Short-term Mem-ory (LSTM) networks (Hochreiter and
Schmid-huber, 1997) to encode the temporal information
from each modality, resulting in a sequence of
hid-den representations[h1`, ...,hT`],[h1v, ...,hTv], and
[h1
a, ...,hTa]. Similar to prior work which found
tensor representations to capture higher-order
in-teractions from multimodal data (Liu et al.,2018;
Zadeh et al., 2017; Fukui et al., 2016), we form
tensors via outer products of the individual
repre-sentations through time (as shown in Figure2):
M =∑T
t=1
[ht`
1] ⊗ [
ht v
1] ⊗ [
ht a
1] (2)
where we append a 1 so that unimodal, bimodal, and trimodal interactions are all captured as
de-scribed in Zadeh et al.(2017). M is our
multi-modal representation which can then be used to
predict the labely using a fully connected layer.
Observe how the construction of M closely
re-sembles equation (1) as the sum of vector outer products. As compared to TFN which uses a sin-gle outer product to obtain a multimodal tensor of rank one, T2FN creates a tensor of high rank
(up-per bounded byT). As a result, the notion ofrank
naturally emerges when we reason about the
prop-erties ofM.
3.3 How Does Imperfection Affect Rank?
We first state several observations about the rank
of multimodal representationM:
1)rnoisy: The rank ofMis maximized when data
entries are sampled from i.i.d. noise (e.g. Gaus-sian distributions). This is because this setting leads to no redundancy at all between the feature dimensions across time steps.
2) rclean < rnoisy: Clean real-world data is
of-ten generated from lower dimensional laof-tent
struc-tures (Lakshmanan et al., 2015). Furthermore,
multimodal time series data exhibits correlations across time and across modalities (Yang et al.,
2017; Hidaka and Yu, 2010). This redundancy
leads to low-rank tensor representations.
3)rclean <rimperf ect < rnoisy: If the data is
im-perfect, the presence of noise or incomplete val-ues breaks these natural correlations and leads to higher rank tensor representations.
These intuitions are also backed up by several experimental results which are presented in §4.2.
3.4 Tensor Rank Regularization
Given our intuitions above, it would then seem natural to augment the discriminative objective
In practice, the rank of an order-Mtensor is
com-puted using the nuclear norm∥X ∥∗ which is
de-fined as (Friedland and Lim,2014),
∥X ∥∗=inf{
r
∑
i=1
∣λi∣ ∶ X =
r
∑
i=1
λi(
M
⊗
m=1
wim),∥wmi ∥ =1, r∈N}.
(3)
When M = 2, this reduces to the matrix nuclear
norm (sum of singular values). However, com-puting the rank of a tensor or its nuclear norm is
NP-hard for tensors of order ≥ 3 (Friedland and
Lim, 2014). Fortunately, there exist efficiently
computable upper bounds on the nuclear norm and minimizing these upper bounds would also
mini-mize the nuclear norm∥M∥∗. We choose the
up-per bound as presented inHu(2014), which upper
bounds the nuclear norm with the tensor Frobenius norm scaled by the tensor dimensions:
∥M∥∗≤
¿ Á Á
À ∏M
i=1di
max{d1, ..., dM}
∥M∥F, (4)
where the Frobenius norm∥M∥F is defined as the
sum of squared entries inMwhich is easily
com-putable and convex. Since ∥M∥F is easily
com-putable and convex, including this term adds neg-ligible computational cost to the model. We will use this upper bound as a surrogate for the nu-clear norm in our objective function. Our objec-tive function is therefore a weighted combination of the prediction loss and the tensor rank regular-izer in equation (4).
4 Experiments
Our experiments are designed with two research questions in mind: 1) What is the effect of various levels of imperfect data on tensor rank in T2FN? 2) Does T2FN with rank regularization perform well on prediction with imperfect data? We
an-swer these questions in §4.2and §4.3respectively.
4.1 Datasets
We experiment with real video data consisting of humans expressing their opinions using a com-bination of language and nonverbal behaviors. We use the CMU-MOSI dataset which contains 2199 videos annotated for sentiment in the range
[−3,+3] (Zadeh et al., 2016). CMU-MOSI and
related multimodal language datasets have been
studied in the NLP community (Gu et al., 2018;
Liu et al., 2018; Liang et al., 2018) from fully
supervised settings but not from the perspective of supervised learning with imperfect data. We
use 52 segments for training, 10 for validation and 31 for testing. GloVe word embeddings
(Pen-nington et al.,2014), Facet (iMotions,2017), and
COVAREP (Degottex et al., 2014) features are
extracted for the language, visual and acoustic modalities respectively. Forced alignment is
per-formed using P2FA (Yuan and Liberman,2008) to
align visual and acoustic features to each word, re-sulting in a multimodal sequence. Our data splits, features, alignment, and preprocessing steps are consistent with prior work on the CMU-MOSI
dataset (Liu et al.,2018).
4.2 Rank Analysis
We first study the effect of imperfect data on the
rank of tensor M. We introduce the following
types of noises parametrized bynoise level=
[0.0,0.1, ...,1.0]. Higher noise levels implies
more imperfection: 1) clean: no imperfection,
2) random drop: each entry is dropped
inde-pendently with probability p ∈ noise level,
and 3) structured drop: independently for each
modality, each time step is chosen with probabil-ity p ∈ noise level. If a time step is cho-sen, all feature dimensions at that time step are dropped. For all imperfect settings, features are dropped during both training and testing.
We would like to show how the tensor ranks vary under different imperfection settings. How-ever, as is mentioned above, determining the exact rank of a tensor is an NP-hard problem (Friedland
and Lim,2014). In order to analyze the effect of
imperfections on tensor rank, we perform CP de-composition (equation (5)) on the tensor
represen-tations under different rank settingsrand measure
the reconstruction error,
=min
wi m
∥(∑r
i=1
M
⊗
m=1
wim) − X ∥ F
. (5)
Given the true rank r∗, will be high at ranks
r<r∗, whilewill be approximately zero at ranks
r≥r∗
(for example, a rank3tensor would display
a large reconstruction error with CP
decomposi-tion at rank 1, but would show almost zero error
with CP decomposition at rank3). By analyzing
the effect ofr on, we are then able to derive a
surrogater˜to the true rankr∗.
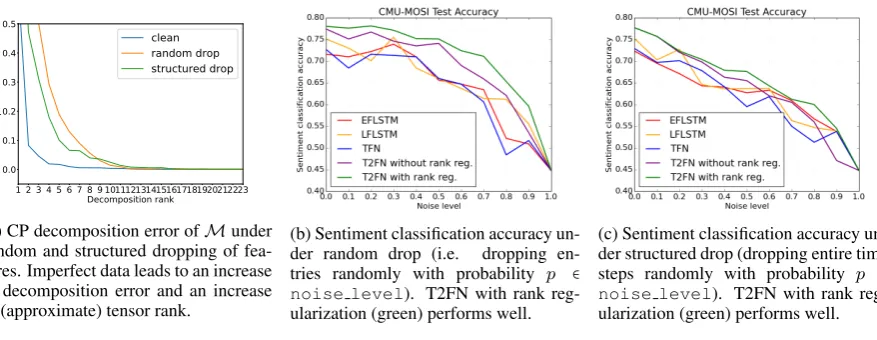
Using this approach, we experimented on CMU-MOSI and the results are shown in
Fig-ure3(a). We observe that imperfection leads to an
1 2 3 4 5 6 7 8 9 1011121314151617181920212223 Decomposition rank
0.0 0.1 0.2 0.3 0.4 0.5
Decomposition loss
clean random drop structured drop
(a) CP decomposition error ofMunder
random and structured dropping of fea-tures. Imperfect data leads to an increase in decomposition error and an increase in (approximate) tensor rank.
(b) Sentiment classification accuracy
un-der random drop (i.e. dropping
en-tries randomly with probability p ∈
noise level). T2FN with rank reg-ularization (green) performs well.
(c) Sentiment classification accuracy un-der structured drop (dropping entire time
steps randomly with probability p ∈
noise level). T2FN with rank reg-ularization (green) performs well.
Figure 3: (a) Effect of imperfect data on tensor rank. (b) and (c): CMU-MOSI test accuracy under imperfect data.
by reconstruction error (the graph shifts outwards and to the right), supporting our hypothesis that imperfect data increases tensor rank (§3.3).
4.3 Prediction Results
Our next experiment tests the ability of our model to learn robust representations despite data
im-perfections. We use the tensor M for
predic-tion and report binary classificapredic-tion accuracy on
CMU-MOSI test set. We compare to several
baselines: Early Fusion (EF)-LSTM, Late Fusion
(LF)-LSTM, TFN, and T2FNwithout rank
regu-larization. These results are shown in Figure3(b)
for random drop and Figure 3(c) for structured
drop. T2FN with rank regularization maintains
good performance despite imperfections in data. We also observe that our model’s improvement is more significant on random drop settings, which results in a higher tensor rank as compared to
structured drop settings (from Figure3(a)). This
supports our hypothesis that our model learns ro-bust representations when imperfections that in-crease tensor rank are introduced. On the other hand, the existing baselines suffer in the presence of imperfect data.
5 Discussion and Future Work
We acknowledge that there are other alternative methods to upper bound the true rank of a
ten-sor (Alexeev et al., 2011; Atkinson and Lloyd,
1980;Ballico,2014). From a theoretical
perspec-tive, there exists a trade-off between the cost of computation and the tightness of approximation. In addition, the tensor rank can (far) exceed the maximum dimension, and a low-rank approxima-tion for tensors may not even exist (de Silva and
Lim, 2008). While our tensor rank
regulariza-tion method seems to work well empirically, there
is definitely room for a more thorough theoreti-cal analysis of constructing and regularizing ten-sor representations for multimodal learning.
6 Conclusion
This paper presented a regularization method
based on tensor rank minimization. We observe
that clean multimodal sequences often exhibit cor-relations across time and modalities which leads to low-rank tensors, while the presence of imper-fect data breaks these correlations and results in tensors of higher rank. We designed a model, the Temporal Tensor Fusion Network, to learn such tensor representations and effectively regularize their rank. Experiments on multimodal language data show that our model achieves good results across various levels of imperfections. We hope to inspire future work on regularizing tensor rep-resentations of multimodal data for robust predic-tion in the presence of imperfect data.
Acknowledgements
PPL, ZL, and LM are partially supported by the National Science Foundation (Award #1750439 and #1722822) and Samsung. Any opinions, find-ings, conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of Samsung and NSF, and no official endorsement should be
in-ferred. YHT and RS are supported in part by
DARPA HR00111990016, AFRL FA8750-18-C-0014, NSF IIS1763562, Apple, and Google
fo-cused award. QZ is supported by JSPS
[image:5.595.81.520.65.235.2]References
Boris Alexeev, Michael A. Forbes, and Jacob Tsimer-man. 2011. Tensor rank: Some lower and upper bounds.CoRR, abs/1102.0072.
Animashree Anandkumar, Rong Ge, Daniel Hsu, Sham M. Kakade, and Matus Telgarsky. 2014. Ten-sor decompositions for learning latent variable
mod-els.J. Mach. Learn. Res., 15(1):2773–2832.
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Mar-garet Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. 2015. VQA: Visual Question An-swering. InInternational Conference on Computer
Vision (ICCV).
M.D. Atkinson and S. Lloyd. 1980. Bounds on the ranks of some 3-tensors.Linear Algebra and its
Ap-plications, 31:19 – 31.
E. Ballico. 2014. An upper bound for the real tensor rank and the real symmetric tensor rank in terms of the complex ranks. Linear and Multilinear Algebra, 62(11):1546–1552.
Lei Cai, Zhengyang Wang, Hongyang Gao, Dinggang Shen, and Shuiwang Ji. 2018. Deep adversarial learning for multi-modality missing data comple-tion. InKDD ’18, pages 1158–1166.
J. Douglas Carroll and Jih-Jie Chang. 1970. Analysis of individual differences in multidimensional scal-ing via an n-way generalization of “eckart-young” decomposition.Psychometrika, 35(3):283–319.
Yi Chang, Luxin Yan, Houzhang Fang, Sheng Zhong, and Zhijun Zhang. 2017. Weighted low-rank tensor recovery for hyperspectral image restoration.CoRR, abs/1709.00192.
Xiai Chen, Zhi Han, Yao Wang, Qian Zhao, Deyu Meng, Lin Lin, and Yandong Tang. 2017. A general model for robust tensor factorization with unknown noise.CoRR, abs/1705.06755.
Abhishek Das, Samyak Datta, Georgia Gkioxari, Ste-fan Lee, Devi Parikh, and Dhruv Batra. 2018. Em-bodied Question Answering. InProceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR).
Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, Jos´e M.F. Moura, Devi Parikh, and Dhruv Batra. 2017. Visual Dialog. In
Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition (CVPR).
Gilles Degottex, John Kane, Thomas Drugman, Tuomo Raitio, and Stefan Scherer. 2014. Covarep - a col-laborative voice analysis repository for speech tech-nologies. InICASSP. IEEE.
Jean-Benoit Delbrouck and St´ephane Dupont. 2017. Multimodal compact bilinear pooling for mul-timodal neural machine translation. CoRR, abs/1703.08084.
Haiyan Fan, Yunjin Chen, Yulan Guo, Hongyan Zhang, and Gangyao Kuang. 2017. Hyperspectral image restoration using low-rank tensor recovery. IEEE Journal of Selected Topics in Applied Earth
Obser-vations and Remote Sensing, PP:1–16.
Shmuel Friedland and Lek-Heng Lim. 2014. Compu-tational complexity of tensor nuclear norm. CoRR, abs/1410.6072.
Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. 2016. Multimodal compact bilinear pooling for visual question answering and visual grounding.
arXiv preprint arXiv:1606.01847.
Xinbo Gao, Yimin Yang, Dacheng Tao, and Xuelong Li. 2009. Discriminative optical flow tensor for video semantic analysis. Computer Vision and
Im-age Understanding, 113(3):372 – 383. Special Issue
on Video Analysis.
Yue Gu, Kangning Yang, Shiyu Fu, Shuhong Chen, Xinyu Li, and Ivan Marsic. 2018. Multimodal af-fective analysis using hierarchical attention strategy with word-level alignment. InACL.
Shohei Hidaka and Chen Yu. 2010. Analyzing multi-modal time series as dynamical systems. In Interna-tional Conference on Multimodal Interfaces and the Workshop on Machine Learning for Multimodal
In-teraction, ICMI-MLMI ’10, pages 53:1–53:8, New
York, NY, USA. ACM.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780.
Shenglong Hu. 2014. Relations of the Nuclear Norms of a Tensor and its Matrix Flattenings. arXiv
e-prints, page arXiv:1412.2443.
Qiuyuan Huang, Paul Smolensky, Xiaodong He, Li Deng, and Dapeng Oliver Wu. 2017. Tensor product generation networks. CoRR, abs/1709.09118.
Soshi Iba, Christiaan J. J. Paredis, and Pradeep K. Khosla. 2005. Interactive multimodal robot pro-gramming. The International Journal of Robotics
Research, 24(1):83–104.
iMotions. 2017.Facial expression analysis.
Jean Kossaifi, Zachary C. Lipton, Aran Khanna, Tommaso Furlanello, and Anima Anandkumar. 2017. Tensor regression networks. CoRR, abs/1707.08308.
Karthik Lakshmanan, Patrick T. Sadtler, Elizabeth C. Tyler-Kabara, Aaron P. Batista, and Byron M. Yu. 2015. Extracting low-dimensional latent structure from time series in the presence of delays. Neural
Tao Lei, Yu Xin, Yuan Zhang, Regina Barzilay, and Tommi Jaakkola. 2014. Low-rank tensors for scor-ing dependency structures. In Proceedings of the 52nd Annual Meeting of the Association for
Compu-tational Linguistics (Volume 1: Long Papers),
vol-ume 1, pages 1381–1391.
Paul Pu Liang, Ziyin Liu, Amir Zadeh, and Louis-Philippe Morency. 2018. Multimodal language analysis with recurrent multistage fusion. EMNLP.
Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshmi-narasimhan, Paul Pu Liang, AmirAli Bagher Zadeh, and Louis-Philippe Morency. 2018. Efficient low-rank multimodal fusion with modality-specific fac-tors. InACL.
Zhen Long, Yipeng Liu, Longxi Chen, and Ce Zhu. 2018. Low rank tensor completion for multiway vi-sual data.CoRR, abs/1805.03967.
Rada Mihalcea. 2012. Multimodal sentiment analy-sis. InProceedings of the 3rd Workshop in Com-putational Approaches to Subjectivity and Sentiment
Analysis, WASSA ’12, pages 1–1, Stroudsburg, PA,
USA. Association for Computational Linguistics.
Louis-Philippe Morency, Rada Mihalcea, and Payal Doshi. 2011. Towards multimodal sentiment analy-sis: Harvesting opinions from the web. In Proceed-ings of the 13th international conference on
multi-modal interfaces, pages 169–176. ACM.
Madhav Nimishakavi, Pratik Kumar Jawanpuria, and Bamdev Mishra. 2018. A dual framework for low-rank tensor completion. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information
Processing Systems 31, pages 5484–5495. Curran
Associates, Inc.
Shruti Palaskar, Ramon Sanabria, and Florian Metze. 2018. End-to-end multimodal speech recognition.
In Proceedings of the IEEE International
Confer-ence on Acoustics, Speech, and Signal Processing
(ICASSP).
Wenzhe Pei, Tao Ge, and Baobao Chang. 2014. Max-margin tensor neural network for chinese word seg-mentation. InProceedings of the 52nd Annual Meet-ing of the Association for Computational LMeet-inguistics
(Volume 1: Long Papers), pages 293–303.
Associa-tion for ComputaAssocia-tional Linguistics.
Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. InEMNLP.
Hai Pham, Paul Pu Liang, Thomas Manzini, Louis-Philippe Morency, and Barnabas Poczos. 2019. Found in translation: Learning robust joint repre-sentations by cyclic translations between modalities.
AAAI.
Xipeng Qiu and Xuanjing Huang. 2015. Convolutional neural tensor network architecture for community-based question answering. In Proceedings of the 24th International Conference on Artificial
Intelli-gence, IJCAI’15, pages 1305–1311. AAAI Press.
James Rossiter. 2011. Multimodal intent recognition for natural human-robotic interaction.
Alexander I. Rudnicky. 2005. Multimodal Dialogue Systems, pages 3–11. Springer Netherlands, Dor-drecht.
Edward Schmerling, Karen Leung, Wolf Vollprecht, and Marco Pavone. 2017. Multimodal probabilistic model-based planning for human-robot interaction.
CoRR, abs/1710.09483.
Hendra Setiawan, Zhongqiang Huang, Jacob Devlin, Thomas Lamar, Rabih Zbib, Richard Schwartz, and John Makhoul. 2015. Statistical machine translation features with multitask tensor networks. In Proceed-ings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Interna-tional Joint Conference on Natural Language
Pro-cessing (Volume 1: Long Papers), pages 31–41.
As-sociation for Computational Linguistics.
Vin de Silva and Lek-Heng Lim. 2008.Tensor rank and the ill-posedness of the best low-rank approximation problem. SIAM J. Matrix Anal. Appl., 30(3):1084– 1127.
Kihyuk Sohn, Wenling Shang, and Honglak Lee. 2014. Improved multimodal deep learning with variation of information. InNIPS.
Vivek Srikumar and Christopher D Manning. 2014. Learning distributed representations for structured output prediction. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors,Advances in Neural Information Processing
Systems 27, pages 3266–3274. Curran Associates,
Inc.
Nitish Srivastava and Ruslan Salakhutdinov. 2014. Multimodal learning with deep boltzmann ma-chines. JMLR, 15.
Makarand Tapaswi, Yukun Zhu, Rainer Stiefelha-gen, Antonio Torralba, Raquel Urtasun, and Sanja Fidler. 2015. Movieqa: Understanding stories in movies through question-answering. CoRR, abs/1512.02902.
Luan Tran, Xiaoming Liu, Jiayu Zhou, and Rong Jin. 2017. Missing modalities imputation via cascaded residual autoencoder. InCVPR.
F. Wu, Y. Liu, and Y. Zhuang. 2009. Tensor-based transductive learning for multimodality video se-mantic concept detection. IEEE Transactions on
Xiao Yang, Ersin Yumer, Paul Asente, Mike Kraley, Daniel Kifer, and C. Lee Giles. 2017. Learning to extract semantic structure from documents using multimodal fully convolutional neural networks. In
The IEEE Conference on Computer Vision and
Pat-tern Recognition (CVPR).
Jiahong Yuan and Mark Liberman. 2008. Speaker identification on the scotus corpus. Journal of the
Acoustical Society of America.
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Ten-sor fusion network for multimodal sentiment analy-sis. InEMNLP, pages 1114–1125.
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. 2016. Mosi: Multimodal cor-pus of sentiment intensity and subjectivity anal-ysis in online opinion videos. arXiv preprint
arXiv:1606.06259.
Qingchen Zhang, Laurence T. Yang, Xingang Liu, Zhikui Chen, and Peng Li. 2017. A tucker deep computation model for mobile multimedia feature learning. ACM Trans. Multimedia Comput.