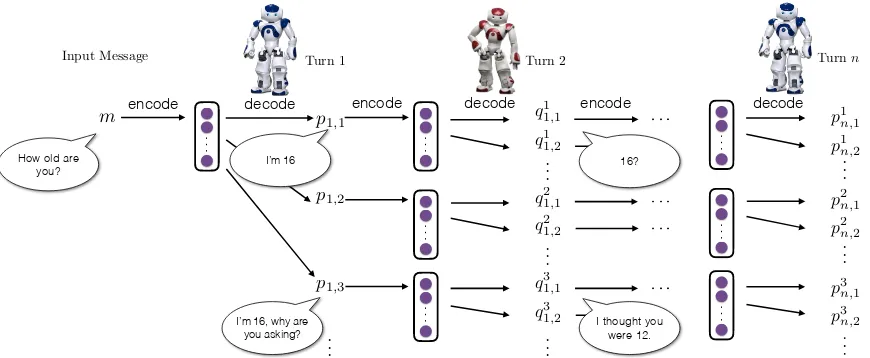
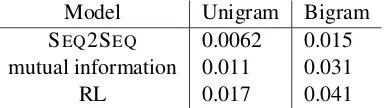
Deep Reinforcement Learning for Dialogue Generation
Full text
Figure


Related documents
The ESUKOM approach fo- cuses on the integration of available and widely deployed security measures (both commercial and open source) based upon the Trusted Computing Group’s
This prospective study of patients with chronic non-spe- cific spinal pain involving the cervical, thoracic and lum- bar regions, alone or in combination, demonstrated by spinal
employed an evidence-based practice diabetic flow sheet (EBPDFS) for staff that care for the adult type II diabetic patients at Samaritan House clinics in California.. The goal of
Water interaction with surfaces that determine partitioning of water and dissolved salts at membrane interfaces, nucleation of mineral scale formation on membrane or heat
they used for [ 14 C]DMO determinations of pHi in fish. E .) of plasma pH (A) and of intracellular pH of red blood corpuscles (RBCs) obtained by the freeze/thaw (B) and DMO
I read with interest the recent article by Good and Gur [1 ), who used computer simulations to evaluate the accuracy of cerebral blood flow (CBF) measurements made
Relative sound pressure levels (A), and phases (B), recorded internal ( ) and external ( ) to the tympanic membrane at a frequency of i-6 kHz as the sound source was rotated
The value functions that we considered character- ize the system state with respect to the service fees and vir- tual waiting time, and also enable the policy iteration step
