Managing the Knowledge Contained in Electronic Documents: a Clustering
Method for Text Mining
♦S. Iiritano
Getronics S.p.A.
Rende (CS), Italy
M. Ruffolo
Intersiel S.p.A.
Via G. Rossini, 87030 Rende (CS),
Italy
Abstract
The huge amount of unstructured data available on the Web and the intranets creates today an information overloading problem. So, managing the knowledge contained in the textual documents is an important problem of Knowledge Management. Knowledge Extraction from collections of data is possible by Knowledge Discovery in Database (KDD), an interactive and iterative process focused on the exploration of data to discover new and interesting patterns within them. The fundamental phase of KDD process is Data Mining if data are in structured form and Text Mining when they are unstructured. This paper describes a prototype of a vertical corporate portal that implements a KDD process for knowledge extraction from unstructured data contained in textual documents. Text mining is realized through a clustering method that produces a partition of a set of documents on the basis of their contents characterized through the frequency of the words.
1. Introduction
Using Knowledge Discovery in Database (KDD), where the fundamental step is Data Mining, knowledge workers can obtain important strategic information for their business. KDD has deeply transformed the methods to interrogate traditional databases, where data are in structured form, by automatically finding new and unknown patterns in huge quantity of data. However, structured data represent only a little part of the overall organization knowledge; in fact the major part of this
knowledge is incorporated in textual documents. The amount of unstructured information in this form, accessible through the web, the intranets, the news groups etc. is enormously increased in last years.
In this scenario the development of techniques and instruments of Knowledge Extraction, that are able to manage the knowledge contained in electronic textual documents, is a necessary task. This is possible through a KDD process based on Text Mining.
A particular Text Mining approach is based on clustering techniques used to group documents according to their content. In this case the Knowledge extraction process is represented by the recognition of these groups.
In this paper we present, in Section 2, a prototype of a vertical corporate portal that implements a KDD process as described above, in which documents are grouped together on the basis of word frequencies. Section 4 contains the results of two experiments carried out on a test corpus composed by articles extracted from some American newspapers and web publications, evaluated using measures defined in Section 3.
2. A Vertical Corporate Portal for Clustering
Textual Documents
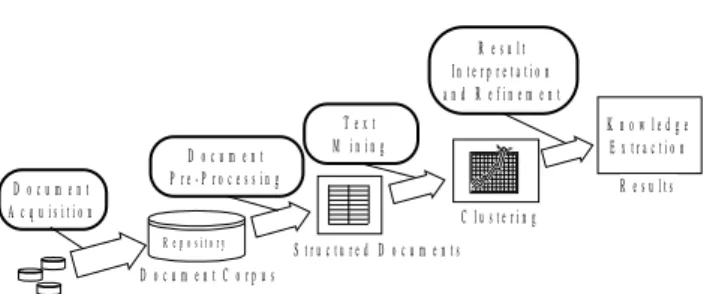
Clustering methods are techniques for partitioning a set of objects in non-overlapped groups (clusters) on the base of suitable similarity measures. In the literature numerous clustering algorithms can be found [6] as well as a wide variety of similarity coefficients [7]. These techniques can be used in a KDD process to extract knowledge contained in (textual) documents as shown in Fig. 1.
D o c u m e n t S o u r c e s D o c u m e n t A c q u i s i t i o n R e p o s i t o r y D o c u m e n t C o r p u s D o c u m e n t P r e - P r o c e s s i n g S t r u c t u r e d D o c u m e n t s T e x t M i n i n g C l u s t e r i n g R e s u l t I n t e r p r e t a t i o n a n d R e f i n e m e n t K n o w l e d g e E x t r a c t i o n R e s u l t s
Figure 1. The KDD process for unstructured data
The KDD process is composed by four phases:
• Document Acquisition Phase: a collection of documents coming from various sources (Internet, company intranet, e-mail, etc.) is stored in a repository;
• Document Pre-processing: documents are submitted to a linguistic pre-processing based on term filtering and context analysis, then an internal representation based on word frequencies is produced;
• Text Mining: documents are partitioned in clusters; • Results Interpretation and Refinement: clusters are
submitted to the interpretation and refinement of a human operator.
To implement this KDD process we developed a prototype of a Vertical Corporate Portal (VCP), composed by six modules that interact as shown in Fig. 2. A c q u is i t i o n P r e - p r o c e s s i n g T e x t M i n i n g R e s u l t s I n t e r p r e t a t i o n a n d R e f i n e m e n t I n t r a n e t R e p o s i t o r y W E B C o r p u s S e l e c t o r C o r p u s T e x t C l a s s i f i e r C o r p u s P a r t i t i o n P a r t i t io n A n a l y z e r R e p o s i t o r y M a n a g e r C r a w l e r D o c u m e n t C o l l e c t o r
Figure 2. Architecture of the VCP
The Crawler and the Document Collector allow the document acquisition phase; the Repository Manager (RM) provides to document pre-processing phase; the Corpus Selector (CS) and Text Classifier (TC) realize the text mining phase; Partition Analyser (PA) makes possible to interpret and to refine the results of the document clustering.
2.1 Document Acquisition
VCP is designed to acquire documents internally or externally to the organization. Customer comments and communications, e-mail, news groups, manuals and program documentations, trade publications, internal search reports, know-how documents that are resident in the intranets can be submitted to the repository through the Document Collector that point to intranet site or directory to recognize them.
Web sites containing information on competitors, market, products, technologies etc. can be acquired with the Crawler, an automatic agent that explores, periodically, selected web sites.
2.2 Document Pre-Processing
The aim of this phase is to produce, for each input document, an internal representation suitable for text mining phase. The input is a set of m documents, and the output is a set of structured documents, one for each input document.
A Document ∆ is a sequence of n words (n is the length
of the document) and its vocabulary is the set of words V∆={w1,…,wλ} occurring in ∆; the structured version of ∆,
denoted as D, is a set of pairs (wj,fD(wj)) where, for each
j=1,…,λ, fD(wj) represents the (relative) frequency of the
word wj ∈ V∆ in the document ∆ (i.e. the number of times
that wj occurs in ∆ normalised w. r. t. the document
length).
In the VCP architecture the pre-processing phase is carried out by RM in three steps as shown in Fig. 3.
D o c u m e n t F i lt e r in g C o n t e x t A n a l y s i s S t r u c t u r in g S t r u c t u r e dD o c u m e n t
Figure 3. Document pre-processing phase
In particular:
• Filtering: discards from each document ∆ the additional words (articles, subjects, pronouns, prepositions) that are not interesting for the analysis; further, the remaining words are reduced to their stems excluding suffixes, prefixes, conjugations of the verbs, plurals. The result of this step is a Filtered document;
•
Normalization: given a filtered document a context analysis is performed by which a synonymous is assigned to each word. The result of this step is a Normalized document. Context analysis is performed, only for English documents, using WordNet [18], developed at Princeton University.WordNet is a lexical database that is able to individualize all meanings (senses) of a given English noun, adjective, verb or adverb finding its polysemies, antonyms, synonymies. The synonymous attributed to the term is the most close sense obtained considering the words in its around (context). However, to allow, also, the treatment of documents written in other languages, VCP is implemented so that context analysis can be excluded;
• Structuring: given a normalised document a Structured document is produced. At the end of this step RM updates two index files: Doc-Index which structure is (Cod_Doc, Reference, Number of words) and Word-Index which structure is (Word, Cod_Doc, Synonym, Synonym Frequency).
2.3 Text Mining
This phase is carried out in two steps, Corpus Selection and Clustering.
Corpus Selection. We call Corpus a set of structured
documents. It can be formed by all documents in the repository or by a sub set of them, selected through a query. This step is performed by the Corpus Selector using information retrieval techniques on the files produced by RM.
Clustering. The input to this phase is a corpus Ω and the output is a partition P = {Γ1,…,Γk} of Ω where each Γi term
is called cluster.
A cluster is a set of similar documents and, so, it’s the sequence of h (cluster length) words occurring in all documents contained in it.
As well as for documents the cluster vocabulary VΓ=
{w1,…,wη} is the set of words occurring in Γ and the
structured version C is the set of pairs (wj,fC(wj)), where,
for each j=1,…,η, fC(wj) represents the (relative) frequency
of the word wj∈VΓ in the cluster Γ (i.e. the number of times
wj occurs in Γ normalised w. r. t. the cluster length).
P is obtained through a clustering technique in which the similarity coefficient is evaluated on the basis of the structured representation of clusters and documents, considering the frequency of the words included both in the document vocabulary V∆ and in the cluster vocabulary
VΓ.
In the following we’ll describe in detail the similarity measure and the clustering algorithm implemented in VCP.
2.3.1 Similarity Measure. Let W = V∆∩ VΓ= {w1,…,wµ} be
the set of words present both in the document vocabulary V∆ and in the cluster vocabulary VΓ. The similarity
between the document D and the cluster C is measured as:
(
−
Θ
)
⋅
Φ
=
1
S
(1) Where2
)
(
)
(
1 1∑
∑
= =+
=
Φ
µ µ k k C k k Dw
f
w
f
measures thedegree of overlapping of document vocabulary and cluster
vocabulary, and
∑
=−
=
Θ
µµ
1|
)
(
)
(
|
k k C k Dw
f
w
f
measuresthe dissimilarity between common part of the document vocabulary and the cluster vocabulary.
Note that S∈[0,1]. In fact:
• if
V
∆≡V
Γ and fD(wk) = fC(wk) for any wk (k=1,…,µ),then Φ=1, Θ=0 and S=1;
• if
V
∆∩V
Γ=∅, then Φ=0 and S=0.2.3.2 Clustering Algorithm. The clustering method is
illustrated through the following algorithm, written in a C-like code, based on concepts defined above.
Input: A structured corpus Ω Output: A partition P of Ω Initialization:
Extracts a document D from Ω; Create a new cluster C1
containing document D;
P = C1;
Iteration:
while (Ω≠∅) do {
extracts document Di from Ω;
extracts cluster C1 from P;
maxSimilarity=Calculate_Similarity(Di, C1);
//CL is a temporary cluster list used during work
CL=P- C1 ;
while (CL≠∅)do {
extracts cluster Cj from cluster list CL;
maxSimilarity=max{maxSimilarity,
Calculate_Similarity(Di,Cj)};
}
if (maxSimilarity < α) {
create a new cluster C
that contains document Di;
P = P ∪C;
Re_Control_Clusters(); }
else {
j = index of cluster for which
maxSimilarity=Calculate_Similarity(Di, Cj)
Cj= Cj ∪Di;
} }
In the algorithm are used the following functions:
• Re_Control_Clusters(). It is performed only
when a new cluster is created. In this case all documents already assigned to the other clusters are re-controlled, and for each of them the similarity in comparison to the last produced cluster is determined. If it is greater than those in comparison to the cluster in which the document was assigned, the document is moved in the new cluster;
• Calculate_Similarity(Di, Cj). It receives in
input a structured document Di and a structured
cluster Cj and determines their similarity.
The threshold value α was experimentally determined as 0.125.
2.4 Result Interpretation and Refinement
This phase is realized by PA that shows for each cluster: • the cluster length;
• the number of contained documents;
• a list of hyperlinks to these documents;
• a list of most representative words in the cluster ordered by frequency.
PA, moreover, guides the user to explore more deeply the clusters and the documents contained for interpreting and refining the text mining results.
3. Measures of Performance: Precision,
Coverage, F-Measure
Performance evaluation of a clustering method is realized comparing the obtained (real) partition with the ideal one, manually recognized by a human operator that split documents in clusters on the basis of the homogeneity of their contents.
In this Section we present some general formulas for performance evaluation of all clustering method.
We consider measures referred to single clusters (comparative precision and comparative recall) and measures referred to the whole partition (total precision, total recall, F-Measure).
3.1 Comparative Precision and Comparative Recall
Let P = {Γ1,…, Γσ} be an ideal and P ’ = {Γ ’1,…, Γ ’ρ}
be a real partition of a corpus Ω.
Using the symbol |•| to denote the cardinality of a set, we can measure the comparative precision of the real cluster Γ ’j w. r. t. the ideal cluster Γi as:
|
|
|
|
' ' j i j ijp
Γ
Γ
∩
Γ
=
. (2)The comparative recall of the real cluster Γ 'j w.r.t. the
ideal cluster Γi is evaluated as:
|
|
|
|
' i i j ijr
Γ
Γ
∩
Γ
=
. (3)Comparative precision and comparative recall are used to evaluate total precision and total recall for the whole partition, comparing all real clusters with all ideal ones.
3.2 Total Precision and Total Recall
With total precision and total recall we can evaluate the goodness of obtained partition analysing the composition of the real clusters most close to those ideal.
Total precision is measured as:
{ }
)
,
max(
max
1 1,...,σ
ρ
σ ρ∑
= ==
i ij jp
P
(4)Total recall is measured as:
{ }
σ
σ ρ∑
= ==
1 1,...,max
i ij jr
R
(5)Maximum value of P and R is 1, whereas the minimum value depend of the distribution of objects in the real partition.
3.3 F-Measure
The F-Misure [22] is a standard metric that combines total precision and total recall into a number that represent the overall performance measure of the clustering method. It is equal to:
(
)
R
P
PR
F
+
+
=
1
2 2β
β
(6)So much more F tends to 1, and so much good is the classification.
The value of the parameter β establishes the relative importance of the recall in comparison to the precision. The importance of the recall is direcly proportional to the value assumed for β. Tipically performances are evaluated with different values of β; in our experiments we have assumed four values for this parameter: β=1.0 (P and R have the same importance); β=0.5 (R is half important than P); β=2 (R has a double weight than P);
σ
ρ
β =
(relative importance of R and P depends of the number of obtained clusters).
04. Experimental Results
In this section we show results of an experiment carried out on a test corpus composed by 146 documents that represent articles extracted from the principal American newspapers (Boston Globe, Baltimore Sun, Chicago Tribune, Dallas Morning News, Herlad Tribune, Los
Angeles Times, New York Times, Washington Post, New York Post, USA Today), and publications on various themes (astronomy, electricity, economy, aerodynamics, etc.) published on internet sites.
For this test set the ideal partition is formed by 20 clusters. The experiments was carried out with context analysis (AN-1) and without it (AN-2).
In Table 1 for each of experiment is shown the number of obtained clusters, the precision P, the recall R, and the F-measure for different values of β.
Test N° of cluster P R F-Measure β=1 β=0.5 β=2 β=ρ/σ AN-1 22 0,6 7 0,8 4 0,7 4 0,7 0,8 0,75 AN-2 24 0,6 6 0,7 5 0,7 0,68 0,73 0,712
Table 1. Experimental results
As expected, if the context analysis is performed we have better results.
5. Conclusion
In this work we shown that knowledge extraction from unstructured data contained in textual documents is possible with a clustering approach, and that the implementation of a web Portal for described KDD process allows to deal with the information overloading problem.
The context analysis step and the classification step are realized with heuristics and can be re-designed to improve performances of VCP, as well as it’s possible to extend the text mining phase integrating different techniques.
Measures proposed in Section 3 are general, and can be used for evaluate performance for all clustering techniques.
References
[1] “Text Mining and the Knowledge Management Space Version 2”, SEMIO Corporation, 1998, California. [2] M. Lenz, “Managing the Knowledge Contained in Technical Documents”, Proc. Of the Second Int. Conf. On Practical Aspects of Knowledge Management (PAKM98), Basel, Switzerland, 29-30 Oct. 1998.
[3] R. Feldman and Al. “Knowledge Management: a Text Mining Approach”, Proc. Of the Second Int. Conf. On Practical Aspects of Knowledge Management (PAKM98), Basel, Switzerland, 29-30 Oct. 1998.
[4] C. E. Shannon and W. Weaver, La Teoria Matematica delle Comunicazioni, Etas Kompass, 1949.
[5] B. Everitt, Cluster Analysis, Sage Publication Inc., Beverly Hills, 1984.
[6] J. A. Hartigan, Clustering Algorithms, John Wiley and Sons, USA, 1975.
[7] L. Kaufman, P. J. Rousseeuw, Finding Groups in Data, John Wiley and Sons, USA, 1989.
[8] Doerre, Gersl, Seiffert, “Text Mining Finding Nuggets in Mountains of Textual Data”, KDD99 proceedings ACM, 1999.
[9] L. Fahey, Competitors, John Wiley and Sons, USA, 1989.
[10] C. J. Van Risbergen, W. B. Groft, “Documents Clustering: an Evaluation of Some Experiments with the Cranfield Collection”, Information Processing and Management, 1975, pp. 171-182.
[11] A. Griffiths, H.C. Luckhurst, P. Willet, “Using inter-document Similarity Information in Document Retrieval System”, Journal of the American Society for Information Science, 1986, vol. 37 pp. 3-11.
[12] B. S. Duran, P.L. Odell, Cluster Analysis: a Survey -Springer-Verlag, Berlin, 1974.
[13] W. J. Frawley, G. Piatesky-Shapiro, C. Matheus, “Knowledge Discovery in Databases: an Overview”, AI Magazine, 1992, pp. 57-70.
[14] T. H. Davenport, L. Prusak, Working Knowledge, Boston Harvard Business School Press, 1998.
[15] W. Eckerson, Analyst Insight Business Portal, June 1999.
[16] P. D. Henig, Vertical Portals Aim for World Domination, Red Herring Online.
[17] D. Gilmore, Some timely guidelines for web design, Mercury News Technology.
[18] WordNet: An Electronic Lexical Database, MIT Press.
[19] M. Davidson, The Transformation of Management, Butterworth-Heinemann, 1996.
[20] I. Nonaka, “A Dynamic Theory of Organizational Knowledge Creation”, Organizational Science, February 1994, Vol. 5 n° 1.
[21] J. Duncan Davison, Java Servlet API Specification ver. 2.1, Public Review Draft, Sun Microsystem, October 1998.
[22] E. Riloff and W. Lehnert, “Information Extraction as a Basis for High-Precision Text Classification”, ACM
Transaction on Information System, July 1994, vol. 12, No. 3, pp. 296-333.