TERADATA ASTER
DISCOVERY PLATFORM
CONTENTS
3
TERADATA ASTER DISCOVERY PLATFORM
3
Tabular and non-tabular data
3
What are the defining characteristics of this non-relational data?
3
Size
4
Structure and Defining “Multi-Structured” Data
4
Isn’t it really tabular?
4
So why is the world interested in storing and manipulating multi-structured data?
4
Integration with relational data
5
The historical solution
5
ROLAP
5
MOLAP
5
“History is bunk”
5
Design philosophy
6
How does it work?
6
The engine and the processing layer
6
So what is MapReduce?
7
The analytical function library
8
Using Aster for real
9
Summary
Teradata Aster Discovery Platform
Teradata specializes in storing and analyzing structured, relational data. It has recently purchased Aster Data Systems, Inc. in order to extend its platform to include the capability of handling what is often called ‘big’, ‘semi-structured’ or multi-structured (see below) data. This paper explains how the Teradata Aster solution works, specifically drilling into how its design philosophy enables it to cope not only with the myriad different types of big data that exist today, but how it is engineered to cope with those that will arise in the future.
TABULAR AND NON-TABULAR DATA
‘Structured’ data is a term that refers to data that fits neatly into tables. For instance an employee table has columns like date of birth, marital status and so on, and each row contains all the data about a single employee.
Table 1
Each table has a name and a number of rows and columns. Each column has a unique name and each row has a unique identifier. So, using the name of the table, the column name and the row ID we can reach any piece of data within the database. The data found there should be very simple – the term often used is ‘atomic’ which implies that the data is so simple it cannot be meaningfully sub-divided.
A great deal of business data is tabular and we frequently store it in relational databases so we often use the term ‘relational’ data to describe this kind of highly structured data.
However the world has become increasingly interested in storing and manipulating data that does not easily fit into relational tables – data such as images, text files, .PDFs, sensor data, Word documents, click-stream data, and so on.
WHAT ARE THE DEFINING CHARACTERISTICS OF THIS NON-RELATIONAL DATA?
STRUCTURE AND DEFINING “MULTI-STRUCTURED” DATA
People often refer to this kind of data as ‘semi-structured’ despite the fact that the term is really a misnomer. As described above, relational data is very precisely structured but then so is a .PDF file. In fact calling it semi-structured almost suggests that it is second class in some way and that it is only partially structured. And, indeed, text files have structure, as do .JPGs, they’re just different from relational data structures. The term ‘semi-structured’ also tends to imply that all non-relational data is the same and one of the defining characteristics of this semi-structured data is its diversity.
So a much better general term for all members of this new class of data is ‘multi-structured’. This name implies that which is true: there are many different classes of data, all of which are highly structured and their structure simply differs depending on the file type.
ISN’T IT REALLY TABULAR?
So why can’t we treat this data in the same way as tabular data? Well, in a sense, we can. Any and all digital data is stored as bits and bytes. If we are dogged enough we can break any data into a long string of bits/bytes and store these as one column in table with a huge number of rows. In that sense, all data can be tabular. We can also store data such as images in tables by creating specialized data types such as BLOBS (Binary Large Objects) – some relational database engines have been able to do this for years.
The problem is that while both of these solutions allow us to store the data, they both miss the point that our main interest in this data is to dig inside it and extract the useful information that it contains.
SO WHY IS THE WORLD INTERESTED IN STORING AND
MANIPULATING MULTI-STRUCTURED DATA?
This kind of data can have huge commercial value locked up within it. Think about a company like eBay. In many ways, when it started, eBay was simply a huge tabular database. You and I may buy and sell items on eBay, but the company itself never sees or handles the items or the cash; as far as it is concerned, we are simply carrying out transactions against a set of tabular data. But after a while eBay also became interested in the behavior of its customers. The tabular data was storing our purchases but our behavior (which buttons we clicked, in which order and when) was in the click-stream data - which is classic multi-structured data.
Then there is Google’s spell checker. Microsoft reportedly spent several million dollars over 20 years developing its spell checker. Google realized that if it tracked what users typed in:
“Ferari”
and what they ended up viewing: www.ferrari.com
then it could map the strings of characters that people actually typed to the strings they wanted. Not only did Google immediately gain a multi-lingual spell checker, it gained a very, very effective one. A spell checker that learns over time and is created effectively for free from the data that other people would throw away – so-called data exhaust. Now think about sensors in a factory – they might record noise and light levels, temperature, pressure and so on. Every now and then the production process produces a bad batch. Locked in the data from the sensors may be the information about the conditions that lead to failure.
INTEGRATION WITH RELATIONAL DATA
So, multi-structured data is here to stay, and we need a solution that can not only store it and manipulate it but also allows it to be analyzed seamlessly with the relational data. At first sight, and particularly from a technical point of view, this seems like an odd assertion. Multi-structured data is fundamentally different from relational, so surely it makes sense to query them independently. The problem with this line of argument is that it makes
differences in data structures, all they know is that there is a new source of data and they want to be able to understand it in relation (if you will pardon the pun) to their existing data. Whatever solution we adopt must allow analysis across not only all the different types of multi-structured data, but it must also include the relational data.
THE HISTORICAL SOLUTION
Historically multi-structured data has been handled in one of two ways, neither of which is entirely satisfactory:
1. You can force it into a relational structure, either as a BLOB or by ‘shredding’ it into atomic data. These solutions have the advantage that you can store it in your existing relational engine and, if it is shredded, you can run SQL against it. The disadvantage is that this tends to be very inefficient, slow and unwieldy.
2. You can create a new database engine specifically for that class of multi-structured data and even develop a new language for querying and manipulating it. This gives very efficient storage and manipulation. The problem is that there are already many types of multi-structured data out there and, as we move forward, more will arise. We can’t go on and on creating new engines for each new type.
A good example of a type of multi-structured data that is handled in both of these ways is dimensional data. Dimensional data is primarily used for On-Line Analytical Processing (OLAP) and consists of a set of measures which can be sliced by a number of dimensions. It is traditionally handled either in a relational (ROLAP) or a dimensional (MOLAP) engine.
ROLAP
The dimensional data is essentially rendered down into two dimensional tables. The measures go into a fact table, the dimension data into dimension tables and thus you have a ROLAP solution (Relational On-Line Analytical Processing). The good news is that this utilized existing technology and skills, the bad is that it is inefficient.
MOLAP
The alternative is to create an entirely new class of database engine, in this case a multi-dimensional database engine in which to store the data. The advantage is that you can use an analytical language like MDX (Multi-Dimensional eXpressions) and run it natively against that engine. The downside is that you’ve had to create an entirely new engine and an entirely new language in order to handle just one of your many multi-structured flavors of data.
“HISTORY IS BUNK”
To paraphrase Henry Ford, the historical solutions to this problem are bunk; neither is realistically sustainable for multi-structured data. The former is always inefficient, the latter produces an ever-increasing set of database engines, which makes integrating the different types of multi-structured data a nightmare.
DESIGN PHILOSOPHY
HOW DOES IT WORK?
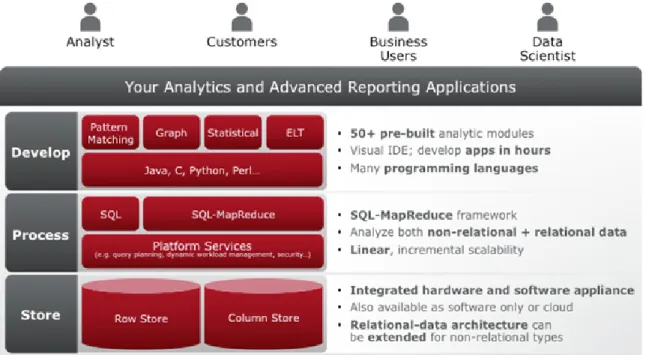
Aster is essentially comprised of three parts: the storage engine, a processing layer and an analytical function library.
Figure 1: Aster Discovery Platform
THE ENGINE AND THE PROCESSING LAYER
The storage engine holds the data as either relational tables (can be either relational row or relational column storage) or as de-serialized objects (you can think of these latter as BLOBs – Binary Large OBjects). In the processing layer there is an extended SQL engine, extended to include MapReduce functionality, known as SQL-MapReduce®. If your data is stored as relational tables, it can be queried using the SQL functions in the engine;
if it’s stored as BLOBs, it can be queried using the engine’s MapReduce functions.
SO WHAT IS MAPREDUCE?
Before we start on the functions, what is MapReduce itself? The name reflects the fact that it is built on two programming functions, Map and Reduce. Map applies a given function to every member of a list, Reduce can combine the results of Map output. So, if data to be analyzed can be rendered into a large number of list on different nodes, Map can process these in parallel and Reduce can pull the answers together. To put that another way, MapReduce is a programming model for writing applications that handle vast volumes of data and process it in parallel. It can run happily on a single server but because one of its major strengths is its ability to scale elegantly, it is usually implemented on large clusters of hardware which parallel process any MapReduce job. Many terabytes can be processed in a single job running on hundreds, if not thousands, of nodes.
What’s extraordinary, given that MapReduce is used with enormous data sets, is that it looks at everything (or almost everything) every time it is run. It hardly sounds like an optimal approach and indeed it isn’t for repetitive similar searches. Its strength is in letting us inspect huge data sets and see results in a realistic time, answering questions that were previously too time-consuming to even ask and enabling ‘train of thought’ analysis that can produce valuable information from acres of data.
THE ANALYTICAL FUNCTION LIBRARY
Above the processing layer is an analytical layer where you find a function library and it is in this layer that we find the adaptability that allows Aster to handle a myriad different data structures. Here we can write whatever functions we like, and as many as we like, to deal with any new structural data type. Any new data type will almost certainly be stored as a BLOB, queried using MapReduce and the capability to manipulate and analyze it will be manifest as one or more functions in the function library.
Now this may sound like technobabble but an example should make it clearer.
For example, suppose we want to store very simple .TXT files and we want to be able to query them and find particular strings within the text.
The .TXT files are clearly not relational so they will be stored as a BLOB and they will be queried using MapReduce. What we have to do in the top layer is to write a function that searches for specific strings within longer strings. If we want other functions, perhaps to count the occurrences of particular words, we write them as well.
At that point, Teradata Aster is fulfilling one of its promises – it is storing multi-structured data and allowing us to query it. So far, so good.
Now further suppose we want to work with .PDFs. They will be stored as BLOBs and manipulated with the MapReduce engine (just like the .TXT files) and we write functions to do whatever we require, maybe one will extract the text from the .PDF, another will count the number of pages and so on.
So, Teradata Aster’s architecture has already addressed the broad question of how to store multiple structural types but there is another hugely important implication of this approach which makes the Teradata Aster solution incredibly versatile.
Most traditional relational engines are basically built to perform queries: a query is sent to the engine, it runs and produces an answer. As we’ve said above, a fundamental principle of the relational model, called closure, says the output of a query is an answer table and that table must look, feel and smell just like any other table in the database. Closure provides the capability to chain queries together. In Aster the principal of closure is very important and an absolutely fundamental part of the whole philosophy is that the output from every single function is a table. No matter how the data is originally stored (BLOB or table) the output from every function has to be a table. And, just as with closure in the relational world, the output from one function can act as the input to another. In other words, all Aster functions have to be able to accept a table as input.
The implications of these simple concepts are highly significant. For a start it means that functions written for one type of multi-structured data can be used for another. Take our TXT and PDF examples. Remember that text string finding function? Suppose we want to use it against a .PDF. We already have a function that extracts the text from a .PDF. The output from that function has to be a table, maybe with one column called EntireTextOfPDF which has a row for every .PDF file. We can pass this output table to the string-finding function we wrote for text files: that function will accept a table as its input and is therefore entirely happy.
This means we can query across all the different data structures by chaining functions because the Teradata Aster solution elegantly uses the table structure as the lingua franca at the top end. Whatever you do, you get a table and you can continue to do table stuff with it.
USING ASTER FOR REAL
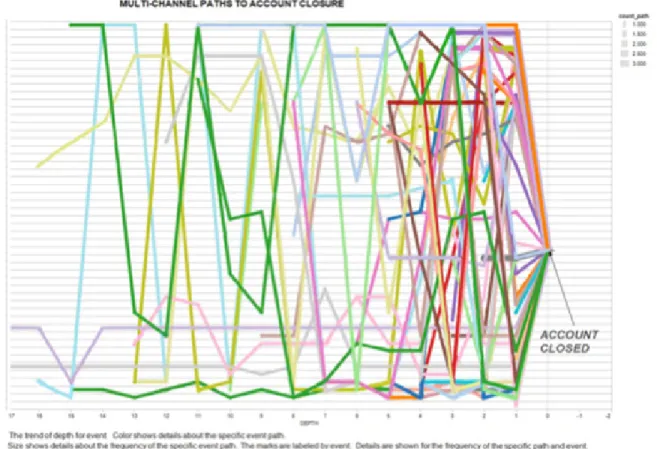
This new way of analyzing data has the potential to be incredibly powerful, and Teradata Aster is already unlocking that power to analyze click-stream data. Click-stream data is increasingly seen as a source of valuable information about the behavior of web site visitors – which pages hold their attention, which do they skip through, is there a page where they stall and then fail to purchase? Teradata Aster is addressing this need with its Apache web log parser and some clever built-in functions.
Raw click-stream log data can be imported (very rapidly given Teradata’s parallel processing architecture) and re-structured for analytical purposes by the parser. It is then ready for analysis using several specific SQL-MapReduce functions, one of which is Aster nPath. Using nPath it is possible to frame questions like “How many users start at the home page, click on a hotel, read the reviews and book a stay”. The query is answered in a single pass and the results are returned blisteringly fast.
This function is ideal for complex sequential analysis on time-series data and for behavioral pattern analysis: click-stream data is one such source; financial transaction and market basket data are others.
SUMMARY
Traditional solutions are always caught on the horns of the dilemma – do you want inefficiency or huge complexity? The Teradata Aster solution slips elegantly between the horns; solves the problem in a totally novel way and provides very high efficiency very simply and, as a bonus, is precisely engineered so that integration of the different types of multi-structured data with relational data is a natural outcome of the solution.
Learn More
For more information about how the Teradata Aster Big Analytics Appliance can bring value to your organization, contact your Teradata or Teradata Aster representative or visit us on the web at:
http://www.asterdata.com/product/index.php
ABOUT TERADATA ASTER
Teradata Aster, a division of Teradata, is a market leader in big data analytics, enabling advanced analytics on big data with richer, deeper data processing at ultra-fast speeds, massive but cost-effective scaling, and the ability to seamlessly manage diverse workloads. From applications like fraud detection, customer intelligence, trending & forecasting to scenario modeling, customer personalization and targeting, and click stream analysis – it is evident that enabling big analytics and discovery has a material impact on the business. The Teradata Aster MapReduce Platform utilizes Aster’s patented SQL-MapReduce® to parallelize the processing of data and applications and deliver rich analytic insights at scale.