Collaborative Open Market to Place
Objects at your Service
D5.2.1
Prototype providing identity management and
provenance in COMPOSE
Project Acronym COMPOSE
Project Title Collaborative Open Market to Place Objects at your Service
Project Number 317862
Work Package WP5 Information and service security Lead Beneficiary UNI PASSAU
Editor Juan David Parra UNI PASSAU
Reviewer David Carrera BSC
Reviewer Alessio Gugliotta INNOVA
Dissemination Level PU
Contractual Delivery Date 30/04/2014 Actual Delivery Date 30/04/2014
Abstract
With this document, we provide a description of the identity management system and the gathering of provenance data.The description includes the goals of these modules in COM-POSE and how they are archived. The document will not only describe the internal structure of these security components, but also sketch their interactions with other COMPOSE com-ponents, their functionalities, and a short description of what is being demonstrated in this deliverable.
This document is divided in three main parts discussing Identity Management, Data Provenance, and future directions for both tasks. For the first two mentioned chapters, the main design decisions and architecture of the developed prototypes are also shown.
Document History
Version Date Comments
V0.1 01/04/14 Initial document structure
V0.4 07/04/14 Draft on Identity Management and
Prove-nance
V0.5 16/04/14 Revised version with respect to consistency of the document
V0.6 17/04/14 First full version
V0.7 28/04/14 Revised version based on comments from in-ternal reviewers
V0.8 28/04/04 Internal PASSAU review
V0.9 29/04/04 Revised version based on comments from In-ternal PASSAU review
V1.0 30/04/04 Final version
Authors
Author Partner
Wolfram Gottschlich UNI PASSAU
Juan David Parra Daniel Schreckling
Contents
1 Introduction 9
2 Identity Management 10
2.1 The Goal of Identity Management . . . 10
2.2 Main Design Choices . . . 10
2.3 Entities . . . 11
2.3.1 Attributes . . . 11
2.3.2 Authorities . . . 12
2.4 Access Control . . . 12
Creation of Users . . . 14
Creation of other Entities . . . 14
Update Entities . . . 14
Getting information for specific Entities . . . 15
2.5 Architecture . . . 15
2.5.1 Integration with Cloud Foundry . . . 15
Confidentiality of communications in Cloud Foundry . . . 16
2.5.2 Integration with COMPOSE components . . . 17
Service Object Registry . . . 17
2.5.3 Interaction with COMPOSE Entities . . . 18
2.6 Functionalities . . . 20
2.7 What is being demonstrated . . . 21
2.8 Interfaces . . . 22
3 Provenance 23 3.1 Data Management Layer . . . 23
3.2 The Goal for Provenance in COMPOSE . . . 23
3.3 Design . . . 24
Instrumentation . . . 24
Modifying the runtime environment . . . 25
Static Analysis . . . 25
Design choice . . . 26
3.4 Approach . . . 26
3.4.1 Overall architecture . . . 27
3.4.2 Provenance data representation . . . 27
JSON Attributes . . . 28
Example . . . 30
3.4.3 Rhino . . . 31
3.4.4 Integration . . . 32
3.4.5 Interfaces . . . 34
4 Future directions 36 4.1 Additional attributes . . . 36 4.2 Provenance . . . 36
List of Figures
1 Interaction between IDM and Cloud Foundry . . . 17
2 Interaction between IDM and Service Object Registry . . . 18
3 Interaction between entities and Identity Managment . . . 20
4 Architecture to gather provenance information for SU . . . 28
5 Different representations for provenance data . . . 29
List of Tables
Acronym
Acronym Meaning
API Application programming interface
COMPOSE Collaborative Open Market to Place Objects at your Service
IDM Identity Management
JSON JavaScript Object Notation
SO Service Objects
SU Sensor Update
WP2 Work package 2: Objects as a service
Terminology
Term Description
entity entities can be services, service object, applications, users, or service source codes in COMPOSE.
service source code
Source code for a service which can be potentially run in COM-POSE.
Service instance a service running in COMPOSE platform.
Web Object Real world object as that provides information about (via sen-sors), or initiates changes in its environment (via actuators), and communicates with COMPOSE platform via the Web Streams Model defined in D2.1.1 [1].
Service Object Standard internal COMPOSE representations in the data man-agement layer for of Web Objects.
1
Introduction
When designing a Market-place for the Internet of things many security challenges arise; for example, how to define and enforce policies that let users have control over data generated by their devices, how to authenticate the different actors in the Marketplace, or how to let users decide which services should they use depending on the previous behaviour of them. As result, security is a subject that requires attention for such systems.
In order to empower users to control where their data is flowing, first the groundings for identifying and authenticating different users and actors in COMPOSE are required. This is covered by the COMPOSE Identity Management component. On the other hand, additional support for security mechanisms can be provided by collecting and storing the history of data in COMPOSE. This will be achieved through the Data Provenance component. The results of the development of these two components is described in the following sections.
For Identity Management, several changes have been made since the first version of the security architecture described in D5.1.1 [2]. This was done, in order to mitigate the negative impact on performance that the original mechanisms would have had on the runtime of ser-vices, and service objects running within COMPOSE. These modifications include, reduction of HTTP messages among entities, as well as replication between Identity Management and the Data Management Layer (WP2). In the case of Data provenance collection, different representation formats where discussed with other project partners in order to find a suitable starting point for data provenance storage and collection. Furthermore, a modification of the runtime environment used in the Data Management Layer was performed, in order to access runtime dependent information. This information will reveal information flows, and basic operations on the data. In addition to the data provenance module described here, inter- and intra-service information flow analysis will be performed in task 5.4 in the future.
2
Identity Management
Identity Management covers the administration of identities, as well as their authentica-tion. Furthermore, Identity Management needs to enforce access control policies in order to prevent unauthorized modification to identities. In the following sections, the different aspects mentioned above will be addressed to show the functionality of Identity Manage-ment in COMPOSE, as well as how Identity ManageManage-ment fits in the overall architecture of COMPOSE.
2.1
The Goal of Identity Management
Identity Management is the cornerstone for security mechanisms in COMPOSE. It adminis-ters identities for every actor in COMPOSE, such as service objects, applications, users, etc. Once there is a service to manage identities and authenticate principals in COMPOSE (i.e. Identity Management component), it is possible to start defining security policies for them, as well as defining the access control mechanisms required to enforce those policies within the platform.
An important part of the research and innovation from the security perspective in COM-POSE is the definition of data-centric security policies in the Marketplace environment, as well as proper access control mechanisms to enforce them. As a result, Identity Management must not only handle simple constructs such as groups of entities, but also must provide mechanisms for more fined grained mechanisms
2.2
Main Design Choices
To keep Identity Management as simple as possible for new users,they will be able to define groups. COMPOSE groups can be comprised of different kind of entities at the same time, such as services, users, and service objects; as a result, they can be used to define policies. However, in COMPOSE Identity Management, there needs to be additional support for other attributes related to identities which enable more fine grained security policies and enforcement mechanisms.Due to the reasons exposed previously, Identity Management is based in Attribute Access Control since it is the most general model which covers Role Based Access Control model (RBAC) among others1 .
There are a number of definitions for Attribute Based Access Control [4] [5] [6]. Luckily there is a fairly recent effort leaded by the National Institute of Standards and Technology (NIST) [3] that describes Attribute Based Access Control as follows:
Attribute Based Access Control: An access control method where subject requests to perform operations on objects are granted or denied based on assigned attributes of the subject, assigned attributes of the object, environment conditions, and a set of policies that are specified in terms of those attributes and conditions
1ACLs and RBAC are in some ways special cases of ABAC in terms of the attributes used. ACLs work
Attributes constitute the basis for defining security policies in a flexible manner. For example, with attribute based access control it would be possible for a user to define a policy enabling services to act on his behalf only when they have a reputation value higher than a certain threshold, and they belong to a group, and they are accessible in a URI that starts with a certain domain. On the other hand, very simple policies could also be represented; for instance, it could also be possible to do access control decisions by just checking one attribute (e.g. group) and grant access depending on the value of only one attribute.
As always, the complexity and expressiveness for policies downgrades the runtime per-formance, and makes enforcement mechanisms harder to implement. The previous examples of policies are mentioned to illustrate the potential achieved when representing identities as Entities with their own attributes; however, the different kinds of policies that users will define in COMPOSE as well as the language used for this purpose is still under investigation. Another advantage of attributes is that they can offer support for the definition of poten-tially very fined grained access control mechanisms, such as paralocks, which are a promising mechanism for information flow policy enforcement [7].
2.3
Entities
Entities in COMPOSE will have a fixed set of attributes representing them, and in the future additional attributes may be supported in a generic manner (see subsection 4.1). The list of entities and their attributes is show in Table 1.
2.3.1 Attributes
As mentioned before attributes represent values for each entity. Those values are protected by predefined Access Control mechanisms, and therefore can be used for security related decisions such as access control among entities principals in COMPOSE.
In COMPOSE there is a dedicated attribute to represent groups. They are non-hierarchical, and therefore every user can create new groups. For every entity, the groups to which it belongs constitutes another attribute. This attribute must be approved by a group adminis-trator, and by the owner of the entity. Additionally, a user can have different memberships. Each membership represents a pair of (role, group) to specify that this user has a specific role, in a specific group. Roles assigned to the user must be one of the following: developer, service provider, object provider, admin, end-user. This attribute requires mutual agreement between the admin of the group where the user has the membership, and the user which includes this membership value among his attribute values.
Service Objects have an API TOKEN (if they receive data from outside of COMPOSE). This token will be used to authenticate the Web Object from which the Service Object is receiving data. As a result, whenever the COMPOSE data layer receives data from outside of COMPOSE, it is possible to verify that the API TOKEN corresponds to the token for the given service object. The Identity Management API only reveal this token to the data layer component in COMPOSE, or to the Service Object owner.
Additionally, there is a boolean attribute dedicated to payment (in case COMPOSE covers payment mechanisms within it’s lifespan). This attribute is not meant to be used to implement the payment functionality, but instead to serve as a flag that would trigger additional interactions with components that could handle these functionalities in the future. The Type column describes the data type of the attribute. In case the attribute is a reference to another entity, the type of the entity is stated.
2.3.2 Authorities
It is recommended as best practice to ensure that attributes are provisioned by attribute authorities [3]. This proves to be essential in order to ensure the effectiveness of the Access control mechanisms. As a result, for every (modifiable) attribute mentioned in 1, a given authority is stated in the ”Authority” column.
The authority column specifies the context and the privileges required to modify the value. For example, when authority is blank this means the field cannot be changed after creation; when the authority column statesruntime, reputation, or Identity Mgmt this means that this attribute can changed only by those COMPOSE components. Whenever the term
m. agreement is displayed in authorities, this implies that mutual agreement is required; that is to say, the owner of the attribute (such as the owner of the group), and the entity for which the attribute is set need to agree to setting the value. This is required to prevent users from adding themselves to groups without the owner of the group permission, or to prevent group owners adding users to groups without their knowledge. Finally, for attributes that are only valid during a specific execution scope (request, thread, etc.) and are not persisted, a special authority is required. Such attributes are marked with the authority namedtransient, which represents that the attribute is determined during execution and it is only valid during the scope of the request or the thread execution in a service or a service object.
2.4
Access Control
To protect the integrity of identities managed within COMPOSE, suitable Access Control mechanisms need to be defined. But in order to describe such mechanisms, proper termi-nology is required. For this purpose, a well established definition of the Fundamental Model for Access Control is taken from [8].
The very nature of ”access” suggests that there is an active entity, asubjector a prin-cipal, accessing passive object with some specific access operation, while a reference monitor grants or denies access.
Principals are subjects previously authenticated by Identity Management that can either store, read, update or delete objects representing identities in COMPOSE. On the other hand, The passive objects on which the access operations are taking place are namedEntities
from now on, and they are all the identities that exist in COMPOSE. Entities are described in more detail in the Table 1. However, the reader should keep in mind that there are
2Only in these cases, there can be more than one attribute with the same name, but they are interpreted
Entity Attribute Type Authority Group group id id
-owner - -name string owner
Application application id id -owner user
-group2 group m. agreement
name string owner acting on behalf user transient
Service instance service id id -URI String runtime owner user
-group2 group m. agreement
service source code service source code
-reputation integer reputation collect provenance boolean owner
payment boolean owner acting on behalf user transient
Service Composition service id id -owner user
-group2 group m. agreement
service source code service source code id id -name string owner version string owner developer user
-group2 group m. agreement
reputation integer reputation payment boolean owner
service object service object id id -owner user:object provider
-group2 group m. agreement
reputation integer reputation collect provenance boolean
-payment boolean owner acting on behalf user transient
api token string Identity Mgmt.
User user id id -username string this
membership2 membership m. agreement
reputation integer reputation
certain operations, such as reading information for an entity, which are not subject to access control at the moment; therefore, it is not required that the access operation (reading data in this particular case) is executed by a principal, but instead they can be executed by any subject capable of communicating with the API. To conclude the terminology definition, the reference monitor mentioned in the previous definition is located inside the Identity Management system, and it implements the Access Control mechanisms described in this section ensuring that only principals with sufficient permissions can execute access operations (subject to access control) on COMPOSE entities.
Many of the functionalities of Identity Management will be executed by COMPOSE components on behalf of a certain user. As a result, in many cases there will be two different credentials to authenticate the Principals on behalf of which the request should be processed, namely the authentication credentials for the COMPOSE entity, and the credentials for the user on behalf of whom the action is being executed. Once principals have been authenticated (it is ensured that they are who they claim to be), the decision on whether or not the principal should be authorised to execute certain action is taken.
The following sections define the access control mechanisms enforced by the Identity Management component in COMPOSE.
Creation of Users
Creation of users is authorised for certain COMPOSE components; especially those facing users which are two COMPOSE components: the meta-marketplace, and the developers portal [9]. On the one hand there is the meta-marketplace; it is the component gathering applications hosted in different Marketplaces such as Android Google Play, Apple iTunes App Store, etc. On the other hand there is the developers portal; which is where developers will create applications. Those two COMPOSE Components will require interaction with Identity Management since they need to register new users.
Creation of other Entities
Every authenticated user is able to create Groups, Applications, Service compositions, Ser-vice instances, SerSer-vice’s source code, and SerSer-vice Objects.
Update Entities
Whenever an entity is updated, their attributes are changed; since both operations are equivalent this section will explain the access control mechanisms for modifying attributes. Before changing an attribute value, it is verified that the proper Authority is part of the principals executing the action (See Table 1). Additionally, whenever a user wants to add an entity (owned by him) to a group, an administrator (or the owner) of the group must approve this action; this is part of the mutual agreement defined for COMPOSE groups.
Getting information for specific Entities
For now, access to information about every entity and its attributes (except tokens) will be granted to every entity deployed in COMPOSE. This approach is followed for a simple reason: If access is restricted to specific entities, this can be harmful for some functionalities of the marketplace; for example, if COMPOSE Identity Management would only enable developers to query identity information for services that they can access, this would prevent developers from creating service compositions which may not be run by them, but could be executed by their clients (who have the proper rights for execution). Additionally, for policy evaluation, information about entities needs to be queried fairly often; as a result, limiting access to attributes or entities would only make the policy decision error-prone, and harder to debug for the users and developers. In the future, some additional support to include access control rules for reading entity’s information could be implemented, if necessary.
Since the querying of entities and attributes is open at the moment, COMPOSE Identity Management doesn’t require any information that uniquely identifies a user, such as names, identification number, address of residence, etc.
2.5
Architecture
Identity Management will be queried by different Compose components or entities in COM-POSE. This section covers interactions of Identity Management with Cloud Foundry com-ponents, Compose comcom-ponents, and Compose entities.
2.5.1 Integration with Cloud Foundry
Cloud Foundry offers a centralised User Authentication and Authorisation Server (UAA [10]). It is mainly implemented as an OAuth2 [11] token provider, with additional extensions to support OpenId connect [12] endpoints, as well as The System for Cross-Domain Identity Management (SCIM) specification [13] for user management.
Since every COMPOSE Service instance will be deployed in Cloud Foundry, achieving in-tegration with Cloud Foundry’s Identity Management will smooth inin-tegrations in the future. Therefore, the authentication endpoint from COMPOSE Identity Management piggybacks on UAA to manage Oauth2 tokens. Additionally, it also uses the OpenId endpoints to get user information from Oauth2 tokens, and it is using the SCIM endpoints to create users in the UAA whenever a user is registered in COMPOSE Identity Management.
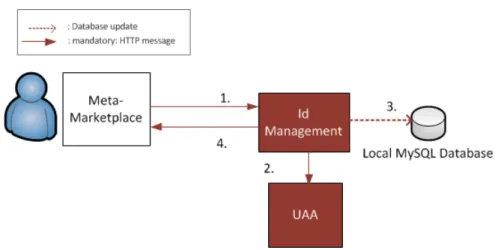
In figure 1 it is shown an example of how COMPOSE Meta-marketplace will communicate with COMPOSE Identity Management, and also the corresponding message flow between the different components, including the UAA Server from Cloud Foundry:
1. Some person interacts with the Marketplace, in order to register himself (this could happen through a different COMPOSE component too).
2. The credentials to authenticate the COMPOSE component creating the user are sent (credentials for the Marketplace). The username, and password for the user to be created are sent to the Identity Managment.
3. Identity Management verifies with the UAA that username is free, and it creates it if possible. Once the user has been registered in the UAA, it is created in the local database.
4. Identity Management replies with a success code and points to the new user as a resource location with the Location HTTP header.
Confidentiality of communications in Cloud Foundry
At the moment, Cloud Foundry recommends the usage the Bosh release SSL Proxy [14] for authentication and confidentiality of information exchange between Cloud Foundry in-frastructure and information systems accessing the cloud components. The aforementioned proxy should be placed in front of the Cloud Foundry gorouter, which is the entry point for http messages to the cloud infrastructure. This tackles the confidentiality problem to-wards the outside world, therefore allowing users to communicate with the Cloud Foundry infrastructure through a single SSL channel (the SSL proxy) in a secure manner.
However, once the data reaches the cloud infrastructure, it is not common practice to add confidentiality measurements (protecting the data against eavesdroppers inside the in-frastructure of the cloud provider);notwithstanding, there was an attempt to enable SSL communication among components deployed within Cloud Foundry infrastructure in the past [15]. This proposed modification constituted a pull request to include in the github code repository the capability for SSL communication in the Cloud Foundry VCAP com-ponent, which is now deprecated [16]. Afterwards, some Cloud Foundry customers started requesting to be able to install their own digital certificates for applications deployed in Cloud Foundry. According to a support forum from pivotal [17] it is planned to let applications use SSL by letting them configure their own certificates in the future. Those approaches would solve the confidentiality problem within the cloud infrastructure. However, in contrast to the functionality provided by the SSL proxy that ensures communication confidentiality from the Cloud Foundry infrastructure towards the outside world (and vice versa), at the moment there are no publicly available implementations providing confidentiality between internal Cloud Foundry components yet.
Figure 1: Interaction between IDM and Cloud Foundry 2.5.2 Integration with COMPOSE components
There are different interactions between Identity Management and COMPOSE components, such as the Compose Controller (deployment component), the Service Object registry (data management layer), or the user interface components (Developers portal, Meta-marketplace). Service Object Registry
Service Object infrastructure will enforce access policies between Service Objects. As a result, Identity Management information is required during execution in order to take decisions; besides, The data management layer in COMPOSE faces big challenges in terms of scalability. As a result, a particularly tight integration is required between the Data Management layer and Identity Management, in order to mitigate the negative impact that security mechanisms, such as access control, might bring therein.
To achieve this tight integration, some replicated information will be kept in Identity Management and inside the Service Object Registry. Such information will include, but will not be limited to the attributes for the Service object (See step 4 in 2). Additionally, every change of Identity Management values will come through the Identity Management API, and will be then forwarded to the Service Object registry, therefore keeping consistency between the two repositories.
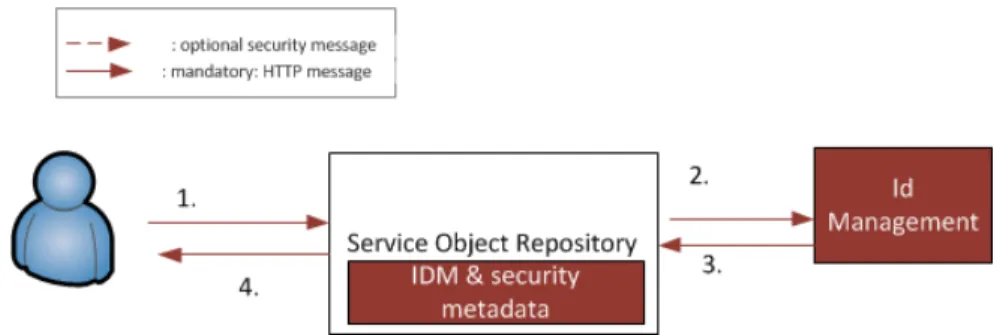
The messages represented in figure 2 are described in the following steps:
1. User (through some application, or COMPOSE Component) calls the Service Object Registry to register a new Service Object. Here the user must provide an authorization token which he obtained after authenticating himself with the COMPOSE Identity Management.
2. The Service Object Registry forwards the token, and the generated Id for the Identity Management.
3. Identity Management generates an API TOKEN, and the default attributes for the Service Object being registered and sends them back to the Service Object Registry. 4. The Service Object registry stores the Identity Management information (returned
in the security metadata JSON attribute in the response body), and forwards the API TOKEN to the user, so the Web Object using it can be properly configured.
Figure 2: Interaction between IDM and Service Object Registry
After the registration process, the Web Object can send data with the proper token and the corresponding Service Object id. Upon reception of data, the Service Object Registry will decide whether or not to accept this data by simply checking the API TOKEN provided by the Web Object against the API TOKEN stored in the Service Object registry.
It is expected that the usage of tokens in Web Objects facilitates the adoption of COM-POSE due to its simplicity, and the previous adoption of API tokens by big companies such as Google (API server keys) [18].
2.5.3 Interaction with COMPOSE Entities
Interaction between the Identity Management and COMPOSE Entities, such as service ob-jects, services, applications, is also required. In this section it will be shown how the different identities in COMPOSE will be able to query information about each other’s identities.
In COMPOSE, Services will be run with a modified runtime environment. This envi-ronment will inject attributes of the current service whenever communication is attempted between a service and another service, or a service object. Similarly, before data is delivered to a service, the attributes from the entity sending the request will be extracted, and this information will support the Policy decision Point when deciding whether or not the current request should be served.
The rationale for this Runtime Environment modification is grounded in several reasons. First, information flow mechanisms will also enforce policies for outgoing flows of informa-tion in spite of the original program implementainforma-tion; addiinforma-tionally, Attribute Based Access Control offers potential for considerable expressiveness, which in turn makes policy evalua-tion more complex, and therefore more pressing the necessity to bring such funcevalua-tionalities (when possible) close to the service functionality in order to avoid latency in remote calls.
Furthermore, the information passed between services (which is then extracted) can not be subject to any modifications, protecting the integrity of the data for the identities.
Since the proposed runtime modification is part of runtime enforcement instead of Identity Management, it is not yet implemented; however, it will be realised within Task 5.4 and will be reflected in the final COMPOSE Security framework.
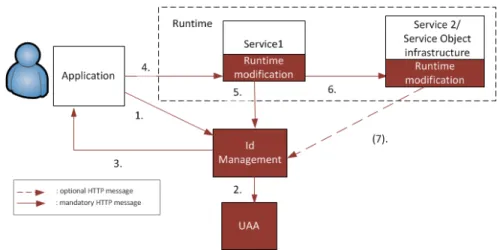
In Figure 3 it is shown the message flow to illustrate how Applications, and Services or the Service Object infrastructure will communicate among each other their own attributes:
1. A user sends his credentials to Identity Management through an application.
2. Identity Management verifies the credentials with the UAA, obtaining an access token for the user.
3. Identity Management replies to the application with the token.
4. The application sends the token to Service 1. Before giving the data to the service, the runtime modification intercepts the communication and collects the token, and invokes the Identity Management to query for additional information about the user (possibly). After this, the runtime determines whether or not to authorize the communication from Application to —Service 1 depending security policies that may apply.
5. The modification calls the Identity Management to exchange the user’s access token by information about the user’s attributes.
6. The runtime packs attributes for the current Service, plus attributes from the user (to specify on behalf of which user is the service acting), and sends this data to the next service (e.g. Service 2 or possibly Service Object infrastructure). This step will happen, only if the runtime modification grants permissions to Service 1 to communicate with Service 2/Service Object infrastructure.
7. Service 2, or the Service Object Infrastructure may need additional information from Identity Management to enforce a certain policy; therefore, this message is marked as a optional message. In order to decrease the amount of messages from Service Object towards Identity Management, all the service object identity information is cached locally.
Figure 3: Interaction between entities and Identity Managment
The flow of messages for authentication of entities has been significantly decreased since the first version of the COMPOSE security architecture , proposed in [2], in order to improve the performance of services running in COMPOSE.
2.6
Functionalities
Identity Management is implemented as a Java Spring application; as a result, it could either be deployed as a Cloud Foundry application or outside of the cloud infrastructure. Additionally, the Identity Management component is using a MySQL database to store information about the entities, and modification to those entities is achieved by calling a REST API exposed to COMPOSE components.
The functionalities provided by Identity Management are: • Creation of a user.
• Authentication of user.
• Creation of an entity (group, application, service instance, service composition, service source code, service Object).
• Get an entity by Id (group, application, service instance, service composition, service source code, service Object).
• Update attributes for entities (group, application, service instance, service composition, service source code, service Object).
• Attempt to add an entity to a group (group, application, service instance, service composition, service source code, service Object).
• Confirm a pending approval to add an entity in a group. • Attempt to add a membership (group,role pair) to a user. • List pending approvals for memberships for a given group • Confirm a pending approval to add a membership to a user.
2.7
What is being demonstrated
In the demo for the the Identity Management prototype the following functionalities are demonstrated:
• Creation of a user: During this step the following functionalities will be shown during the user creation.
– Access control mechanism: show that only authenticated COMPOSE components are able to create users.
– how the creation of a user in COMPOSE Identity management is reflected in the Cloud Foundry User Authentication and Authorisation Server.
– how Identity Management ensures that usernames are unique. • Getting information for a particular user by Id.
• Authentication of a user:
– Authentication by providing valid credentials for a user. – Attempt for authentication providing invalid credentials. • Creation of a group:
– Access control mechanism: show that a user is able to create a group.
– Show that when the group is created, it has the right owner (the user calling the API).
– Show that the system forbids a user from owning two groups with the same name. • Getting information for a particular group by Id.
• Adding a user to a group:
– Show how an user can attempt to add himself to a group.
– Show that after he attempts to add himself to a group, the membership is not displayed until it has been approved by an administrator of the group, or the owner.
• Authorisation of group membership:
– Access control mechanism: show that only the administrator of a group can ap-prove memberships related to his group.
– Show that after a membership is approved, it will appear through the API call that get data for a particular user information by id.
2.8
Interfaces
Given the size of the COMPOSE Identity Management API, and the fact that it might change in the future. It has been published in a website, to make it also available to the consortium partners, in the following URLS:
• API for Groups: http://docs.composeidentitymanagement.apiary.io/ • API for Applications: http://docs.composeidmapplications.apiary.io/ • API for Service instances: http://docs.composeidmservices.apiary.io/
• API for Service Compositions: http://docs.composeidmservicecompositions.apiary.io/ • API for Service Source Code: http://docs.composeidmservicesourcecode.apiary.io/ • API for Service Objects: http://docs.composeidmserviceobjects.apiary.io/
3
Provenance
Data Provenance is concerned with the origin, the creator and the history of data. It also can describe the history of an item’s ownership and of performed actions like creation, trans-formation and copying [19]. In short provenance data archives the intrans-formation about when, where, who, and how a data item has been used. In the following sections different ap-proaches to gather provenance data are mentioned and how they can and will be used in COMPOSE. Afterwards, the integration of the developed first prototype and the demon-stration of this prototype is described. This deliverable focusses on provenance in the Data Management Layer (WP2).
3.1
Data Management Layer
In the Data Management Layer Service Objects (SO), which are the standard internal COM-POSE representations of Web Objects, are the basic elements. New sensor values of those Service Objects are called sensor updates (SU), they are stored in the JavaScript Object Notation (JSON) format. Such sensor updates can come from outside of COMPOSE (Web Objects) or from service objects themselves. It is possible to build Service Objects which take inputs from several Service Objects [20]. To define the behaviour of service objects three options are provided:
• a pre-filter which returns a boolean value that indicates if the new input should trigger a new computation, which in turn generates new output
• the current-value computation which defines the output value to be computed for a given input
• a post-filer which returns a boolean value that indicates whether the new current-value will be stored as a new SU or not.
The evaluation and computation source code for these three steps can be defined by a single JavaScript statement. This code will be executed by a JavaScript engine within the the Data Management Layer (Java). In the case of COMPOSE this engine is Rhino.
3.2
The Goal for Provenance in COMPOSE
This section describes possible goals for provenance in COMPOSE. These goals lead to requirements for the provenance data. One goal of the generated and stored provenance information is to enable support for data-driven policy enforcement. The following simple example will show the benefit of provenance data. The user ”X” is allowed to accesses vari-able ”a” and ”c” but not ”b” or values that are derived from ”b”. The output value in the example is calculated by the following JavaScript statement: a > 1?b : c The code shows that only ”b” or ”c” are influencing the output, depending on the value of ”a”. To decide whether ”X” is allowed to access the result, provenance information is required. Without
such provenance information the most appropriated policy might not be enforceable for this example.
A second scenario where provenance information provides the possibility to enforce other kinds of policies is the ”Chinese wall policy” [21]. Without tracking read accesses it is not possible to support such policies. A third scenario is to enable the possibility for business policies that could be used for example for accounting purposes. For the sake of the argu-ment, the following example is considered: A user that has 10 different sensors connected to COMPOSE allows other users to access values provided by his sensors, as long as each user reads data only from at most two of his sensors. This policy would be particularly useful because it would allow the sensor owner to let users choose freely among his sensors, but still restricting the access to a certain amount of them.
Besides the support for the policy enforcement the provenance information can be used to support a reputation mechanisms, by providing information about the usage of Service Objects or services. Another possible goal of provenance information would be to provide the necessary data to detect when services could be building profile information about users in COMPOSE. Another goal, which comes from a different application area then the above mentioned, is to fulfil the legal requirements. In the European data protection law, everybody has the right to know where the organization accountable got his data from, what the data was used for, where it was transferred to and how long it is stored [22].
3.3
Design
This section explains different possible solutions for the challenges derived from data prove-nance collection; additionally, at the end of this section the design choices made are ex-plained. Precise provenance information is often runtime dependent (see Section 3.2). In this case this means that the information depends on the execution of a program with a certain input value. There are several possibilities to get such runtime information. The two main approaches are: instrumenting the program under supervision, or modifying the runtime environment. These two dynamic1 approaches are described further in the following
sections; afterwards, a description of static2 analysis is given. The aforementioned dynamic
solutions could potentially be combined in a hybrid approach. Instrumentation
Instrumentation could be done in two different levels: source code instrumentation, or binary instrumentation. The former consists of including additional instructions within the source code of the program under test, the latter consists of including additional binary instructions within the binary file of the program under test. Since the programming language used to compute the new sensor updates (SU) of service objects (SO) is JavaScript, and this is an interpreted language, the source code instrumentation would be more suitable in comparison to the binary instrumentation.
1During execution of the program
The main advantage of the source code instrumentation approach is that it provides the possibility to develop a portable solution, it would not depend on the runtime environment. However, a disadvantage of instrumentation is that the analysis part has no control over the actual execution; therefore, it is difficult to deal with self-modifying code. With respect to security another disadvantage is that protection mechanisms are required to ensure that the instrumented code is neither changed nor replaced before the actual execution.
For source code instrumentation it is beneficial to use a framework. The framework should parse the program to instrument; afterwards, it should generate the instrumented code that can be compiled or executed. For this purpose, a possible candidate would be LLVM [23]. LLVM is a widely used and powerful framework, which allows source code instrumentation for multiple programming languages.
The support for different languages is implemented by different ends. Each front-end compiles the source code into an intermediate language (LLVM-IR), in order to instru-ment and compile tLLVM-IR to the final representation with the help of an LLVM-back-end [24]. An LLVM-back-LLVM-back-end for JavaScript is available [25]. Unfortunately, there is not a publicly available JavaScript front-end at the moment [23]. With the existing front-ends, it is possible however to use several steps to convert Javascript code into LLVM-IR (e.g. JavaScript to Java, and then Java to LLVM-IR). These steps decrease the runtime perfor-mance, and increase the compilation time, not to mention they make the whole process error-prone.
Modifying the runtime environment
By modifying the runtime environment the analysis part has full control during the actual execution of the program under test. Besides this advantage, no separate instrumentation step has to be performed. Therefore, it is not required to protect the instrumented code from being changed or replaced before the actual execution. Furthermore, from a runtime point of view, modifying the runtime environment has several benefits. First of all, the code has only to be parsed once (to compile/interpret); moreover, the analysis overhead is only spent on analysing the code which is actually being executed, instead of spending time by analysing code which might not be executed (as it usually happens with Instrumentation frameworks).
A general disadvantage of modifying the runtime environment is that it is not portable. As a result, the modification has to be performed in all runtime environments separately. Static Analysis
With Static analysis it is possible to build a complete control flow graph, enabling the analysis framework to detect branches in the code, which are potentially harmful. Those branches would not be detected until their execution is actually attempted if only dynamic analysis would be performed (input sensitivity).
Most static analysis approaches have also a runtime advantage in comparison to dynamic analysis approaches since they are dependent on the length of source code (of the program under test) and not on the runtime (of the program under test). This is especially an
advantage for programs that contain many repetitions of code sections like loops or recurrent function calls.
On the other hand, with static analysis it is not manageable to gather all kinds of runtime dependent information, especially for pointer operations or self-modifying code.
Design choice
Since ensuring integrity of the instrumented code in JavaScript is a complex task, given the properties of the language. Also, due to the lack of availability of mature instrumentation frameworks a runtime environment modification is chosen for the current prototype.
As mentioned previously it is possible to combine static analysis with instrumentation or with a runtime environment modification in order to combine the advantages of a static and dynamic analysis. This could be done for example by performing a static analysis and only analyse dynamically the parts that could not be determined by the static analysis. This would reduce the runtime overhead during execution, and it would still be possible to gather runtime dependent information. Such an hybrid approach can be implemented in a future prototype.
3.4
Approach
This section describes the approach to gather and store provenance information for SU generated by SO since this is the place where data is processed in the Data Management Layer (WP2). Moreover, the concept of this approach is applicable for COMPOSE services. Runtime dependent provenance information is produced at three points in the case of SU generated SO (see Section 3.1):
• During the calculation of the new ”current-value” • During the evaluation of the ”pre-filter”
• During the evaluation of the ”post-filter”
Currently, the evaluation of a pre-filter, and a post-filter, as well as the calculation of the current-value in a Service Object, is described by a single JavaScript statement. However, in order to execute this single statement, declaration and initialisation for all used variables is required, and therefore needs to be included in the JavaScript code that is actually executed by the underlying JavaScript engine (Rhino).
In order to gather provenance data, the JavaScript code is executed in a modified Rhino version in order to return provenance data with the actual result of the JavaScript compu-tation. This Rhino version is part of the provenance module inside the Data Management Layer, and will be explained in more detail in the following section.
This Rhino version monitors the execution to track all variable accesses. This includes storing all read and write accesses of variables during the execution (excluding the added
initialisations). This provides the necessary information to fulfil the goals described in Sec-tion 3.2. The returned provenance informaSec-tion contains only informaSec-tion about the rele-vant variables which are the variables actually used to compute the pre-filter, post-filer and current-value. Also the performed operations like sqrt or addition will be retuned for variable accesses.
The provenance module is designed stateless to reduce dependencies with respect to integra-tion purposes and performance (possible parallelisaintegra-tion of the analysis for pre-filter, post-filter and current-value computation). The data model described in Subsection 3.4.2 for the provenance information is not only suitable for SU but also for other entities like services. Therefore, the data-model does not have to be changed to represent service’s provenance information.
Since the gathering of provenance has to be done at least partially during runtime, it is necessary to make similar modifications, like the one performed on Rhino, to the runtime environment for services to extract the required information. In the case of Services another difference is that the JavaScript code that can be used to calculate the output is not restricted to a single JavaScript statement. This enables for example the opportunity to define loops and the declaration of additional variables.
In the case of a single JavaScript statement all accessed variables have either direct or indirect influence on the actual result. On the contrary, when analysing more complex JavaScript code sections, it would be necessary to build a data structure that enables the possibility to unroll which variables actually had influence on the returned value. Since the return value is not available until the end of the execution, this data structure is required. 3.4.1 Overall architecture
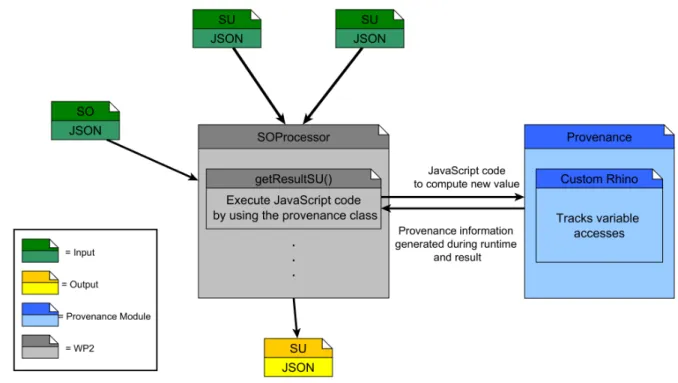
The overall architecture to gather provenance information for SU is shown in the flowing figure 3.4.1. The architecture to gather provenance information for services will look similar. The class in the Data Management Layer to compute new SU of a SO gets a JSON file of the SO and the JSON file(s) of the required SU as input to generate the resulting new SU. This class then calls the modified Rhino implementation to execute the JavaScript code to calculate the pre-filer, current-value or post-filer. The result of this calculation contains provenance information and the actual result. With this provenance information the JSON file for the new SU is generated. For integration details and interfaces see Section 3.4.4. 3.4.2 Provenance data representation
This section describes the how provenance data is represented and stored. The provenance data is stored in the JSON file of its corresponding SU. The reader should keep in mind that in this section the term entity is used for all data items containing provenance information.
Figure 4: Architecture to gather provenance information for SU JSON Attributes
The provenance data consists of the following attributes: • provenance.agent: (SO|service)
Contains the type of the provenance.entity.
• provenance.type: (sensor update|file|service object update etc)
Represents the type of the current object to which the provenance data belongs.
• provenance.entity: (sensor update unique id|path of file|location of the actual data. . . ) This contains a reference to the corresponding entity. This is not necessary for SO since this id is available in the JSON document containing the provenance info. However, for provenance in services this is different.
• provenance.activity: (creation|derived from| etc.)
Describes how the current object is generated from the sources. • provenance.timestamp: (time in ms)
Contains the time when the current object is created.
• provenance.accessed: {[userid|groupid|other entities with delegation, time in ms]} Map that contains the id of the entity that accessed the current object with the time of its first access of this object.
• provenance.onbehalf of: (user)
The id of the user, on-behalf of whom this object is created.
• provenance.sources: (if activity == creation − > web object id. If activity == derived from−> list of data items)
List of all sources that were used to create the current object, represented by there provenance data. The sources are stored in a tree structure.
For the data representation of the source attribute multiple possibilities are suitable. There are basically two main approaches for its representation:
• storing references or coping the provenance data of the source(s)
• storing only information to the direct sources or storing information to all sources (in for example a tree structure)
Figure 3.4.2 illustrates how for the two approaches would represent provenance informa-tion. In the figure, it is assumed that the first sensor update (ID=1) is used to generate the second sensor update (ID=2), and so on.
JSON files for objects of the data layer will be stored in a Couchbase database. This kind of database will perform better on a provenance representation without intensive use of references. Additionally, at the moment there is on-going research in WP2 considering the possibility to include ElasticSearch, and since ElasticSearch will perform better when search-ing within one ssearch-ingle file includsearch-ing provenance data, than when searchsearch-ing in multiple small files with several references among them. For the exposed reasons, the current prototype is storing the whole provenance data of all sources in a tree structure (see second example of Figure 3.4.2).
The impact of the current prototype on the Data Management Layer (WP2) has to be monitored.
The size of the JSON files has also to monitored to check if the current solution is also scalable in the sense of memory usage. This mainly regards thesource attributes in the JSON format for the current prototype. The size of this value heavily depends on the number of nodes contained in source tree. Depending on the measurements mentioned above, modifications in the representation and the collection of provenance will be made in order to find solutions which improve runtime and memory consumption for storing provenance data.
Example
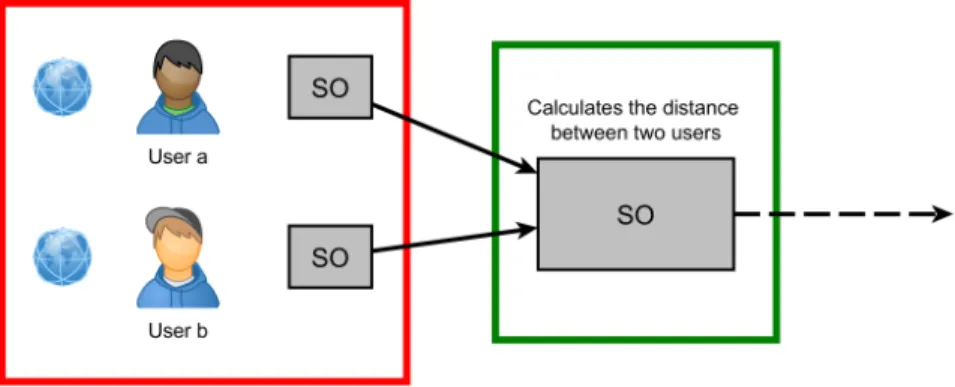
This paragraph illustrates the above described provenance data model by showing an exam-ple. Figure 6 shows structure of the examexam-ple. For the following example, two users want to
Figure 6: User close by each other example
meet each other, and each one of them has a service object (red) processing their location. There is another service object calculating the distance between the two users. The SO that is calculating the distance is highlighted in green. The Listing 1 shows the provenance information for a SU generated by the green SO. This provenance information would be part of the SU.
Listing 1: Example provenance data 1 "provenance":{
2 "agent" : location.distence.SO,
4 "entity" : userid_in_certain_location_id, 5 "activity" : [{ op:["Sqrt","+","Pow"], 6 var:["loc_data_id_user_a_1","loc_data_id_user_b_1"], 7 }] 8 "timestamp" : 1000009, 9 "accessed" : [], 10 "onbehalf_of" : user.location.distence, 11 "sources" : { [{ 12 "agent" : location.user.a.SO, 13 "type" : sensor_update, 14 "entity" : loc_data_id_user_a_1, 15 "activity" : creation, 16 "timestamp" : 1000000, 17 "accessed" : [], 18 "onbehalf_of" : user.a, 19 "sources" : web.object.id.loc.user.a 20 },{ 21 "agent" : location.user.b.SO, 22 "type" : sensor_update, 23 "entity" : loc_data_id_user_b_1, 24 "activity" : creation, 25 "timestamp" : 1000002, 26 "accessed" : [], 27 "onbehalf_of" : user.b, 28 "sources" : web.object.id.loc.user.b 29 }] 30 } } 3.4.3 Rhino
This section describes what changes where made to the original Rhino version (1.7R4), and additionally explains which classes were added to the original version in order to provide data provenance information. The three main classes added to the modified Rhino version are:
• ProvenanceAPIwhich provides the interface for the integration with the Data Man-agement Layer
• Provenance which is the main calls for gathering provenance data during runtime • Provelement which represent the gathered provenance information
Calls to the provenance classes are added at several positions inside Rhino. Additionally, there are several changes implemented within. The cornerstone for the Rhino modifications
is rooted in the ScriptableObject class, which represents the basic objects such as variables, and also some JavaScript native functions, such as Math.sqrt in Rhino. For additional information, the reader can review the Rhino architecture in [26]. Another fundamental change is the modification of theContext class, which is used in Rhino to execute JavaScript code, and therefore is the main entry point to the Rhino API(i.e. evaluateSring method which runs the JavaScript code). The Context class was modified to return a Provelement object instead of a java.util.Object.
3.4.4 Integration
The integration into the data layer consists basically of three steps: • Providing input data
• Calling the modified Rhino implementation
• Including the generated provenance data into the new SU
If no provenance data is gathered the variables in the source code to perform the calculations for new values are replaced by their values (see Listing 2).
Listing 2: Original input string 1 // Initial JavaScript code with replaced aliases
2 String computationCode1 = "Math.sqrt(channels$latitude$current-value)";
3 // JavaScript code with variables replaced by their values
4 // (values come form input SUs)
5 String computationCode2 =
6 computationCode1.replace("channels$latitude$current-value","42");
7 // Final result of computationCode2 is: "Math.sqrt(42)"
However to track the variables during runtime it is necessary that the JavaScript code still contains the variables and not only their values. Therefore, it is necessary to add a variable declaration with its initial value for each variable3 instead of replacing it with its value. Listing 3 shows a small example to illustrate this.
Listing 3: Requred input string 1 // Initial JavaScript code with replaced aliases
2 String computationCode1 = "Math.sqrt(channels$latitude$current-value)";
3 // Build map that maps variable names and there value
4 HashMap<String, String> inputVars = new HashMap();
5 inputVars.put("channels$latitude$current-value", "42"); 6 // JavaScript code required for to track variable accesses
7 // (values come form input SUs)
8 String computationCode3 = ProvenanceAPI.buildString(
9 inputVars, computationCode1); 10 // Final result of computationCode3 is:
11 // "var channels$latitude$current-value = 42; 12 // Math.sqrt(channels$latitude$current-value)"
A function that builds such an input string is provided by the provenance class (see Subsec-tion 3.4.5). It requires as inputs the string with replaced aliases and a map with the variable names as keys and its current-value as value. Besides this, a map should be built including the variable names as keys, where each key is mapped to a SU. The value corresponding to a specific key in the map is a String containing the JSON representation (including the provenance information) of the SU. This information is required for the third step.
The second step of the integration is to use the modified Rhino implementation to execute the JavaScript code. This has to be done by using the Rhino API, instead of using the ScriptEngineManager class.
Listing 4 shows a small example how to use the Rhino API to execute a JavaScript code String in Java.
Listing 4: Rhino API
1 // Code to execute JavaScript code inside a Java program 2 // using the Rhino API
3 String js_code = "1+1";
4 Context cx = Context.enter();
5 Scriptable scope = cx.initStandardObject();
6 Object result = (Object)cx.evaluateSring(scope, js_code,"<COMPOSE>",1,null); 7 List<Provelement> provList = (List<Provelement>)result;
A function that encapsulates the call to Rhino is also provided by the provenance module (see Subsection 3.4.5). The type of the returned result-object for the modified Rhino im-plementation is a list of ”ProvenanceElements”. This list contains the data gathered during the program execution.
In the third step this list of ”ProvenanceElements” is passed together with the above mentioned map (which maps variables to a SU) to the buildProvenanceJSON function (see Subsection 3.4.5). This function returns a string that contains the provenance data for the new SU in JSON format. This has to be added to the JSON file of the new SU.
The first two steps have to be performed during the pre-filer, post-filter and at the calculation for the new current-value. The third step has only to be performed when a new SU is actually generated. The provenance data for the new SU will then build based on all the gathered provenance data(pre-filter,post-filer and current-value computation) since they all had influence on the new SU.
Read accesses that lead to no new SU are not handled by the currently integrated prototype. Situations where such data accesses can appear are direct accesses to a SU in the data base (not via a SO) or if the pre- or post-filer of an SO returns false. The decision to exclude
this from the current prototype was done in consultation with WP2. It is based on the fact that the Data Management Layer uses a Couchbase database as storage for the SU which is a NoSQL database. As a result, there would be no guaranty that no accesses would be lost due to the database properties. Support for such read accesses might be added in a later step depending on the performance impact of the current prototype and the requirements of the modules that use the provenance information.
3.4.5 Interfaces
This subsection describes the application programming interface (API) of the provenance module. The following Listings 5, 6, 7 and 8 show the three above mentioned functions together with the function to access the actual result of a computation. The previously mentioned calls are required for the integration with WP2 . The behaviour of these functions is described in Subsection 3.4.4. The String value named ”security metadata” shown in Listing 8 contains the replicated information returned by Identity Management during the registration of a SO, and it is used to extract attributes such as the owner of the SO (see Subsection 2.5.2). Additionally, all functions exposed in the provenance API are static (see Seection 3.4).
Listing 5: Rhino API ”buildString”
1 // Build input string containig variable declarations and inizialisations
2 String ProvenanceAPI.buildString(
3 Map<String, String> variableAndValue, //Maping variable names there value
4 String computation) //Single JavaScript statement
Listing 6: Rhino API ”executeWithProv” 1 // Execute code with the modified Rhino
2 List<Provelement> ProvenanceAPI.executeWithProv(
3 String code) //JavaScript statement together with
4 // variable declaration and inizialisation
Listing 7: Rhino API ”getResultValue” 1 // Returns the actual "return value" of the computation
2 Object ProvenanceAPI.getResultValue(
3 List<Provelements> provData) //Contains all information
4 // gathered during runtime
Listing 8: Rhino API ”buildProvenanceJSON” 1 // Convert provenance data into JSON format
2 String ProvenanceAPI.buildProvenanceJSON(
3 String securityMetaData, //Identity Management data for SO (JSON)
5 // gathered during runtime
6 Map<String, String> VarNameSuPath) //Maping between variable names and SU
3.5
What is being demonstrated
In the demo for the provenance prototype the following functionalities are demonstrated: • Generation of provenance data
• The advantage of runtime dependent provenance information will be illustrated by an example. The example will have similar structure like the one described in Section 3.2 (a >1?b:c). This will show that only actually (during runtime) accessed data will be added to the provenance information.
• The generated JSON files will be shown. These files include the used operation like sqrt or addition to calculate the values.
4
Future directions
In the following subsections the future work for Identity Management, and Data Provenance is described.
4.1
Additional attributes
A direction to extend Identity Management in the future is to let users define additional attributes associated to them or the entities they administer. An example to show the usefulness of such attributes is given below:
Lets assume there is a well known company developing sensors called ”MySensor.Co”, and COMPOSE users are starting to notice these sensors have an extraordinary precision, and therefore they start choosing them over others. As a result, companies deploying service objects in COMPOSE will want to be able to specify that their sensor is developed by a particular brand (such as ”MySensor .Co”). In order to support this, users should be able to create arbitrary additional attributes which represent such concepts.
For the sake of the argument, lets say that users start specifying additional attributes called ”device brand” with the value ”MySensor. Co”, and their devices are chosen; it won’t be long until some users start tagging COMPOSE Service Objects with such attributes, even though their sensors are not really manufactured by ”MySensor .Co”, taking advantage of the name of the sensor company.To prevent this, a ’generic’ (up to some extent) mechanism should be provided to enable authorities to manage such additional attributes. In the partic-ular given example, this should be achieved by assigning some entity as the authority which approves that an entity is able to place an additional attribute named ”device brand” with the value ”MySensor .Co”.
If Compose Identity Management were to implement the extension to support additional attributes, it would be required to answer many questions; for example, who can define the authority responsible for approving a certain value for a given attribute?. Which would be a suitable policy language to represent the verification of an authority once a Principal attempts to change or approve some attribute value? How to solve policy conflicts between authorities?.
Since there is not a specific requirement for supporting Additional Attributes in COM-POSE at the moment, and due to the complexity of the posed questions, the necessity of the implementation of such mechanisms (additional attributes) is still under investigation.
4.2
Provenance
The extension and refinement of the current provenance prototype can have multiple direc-tions and aspects in the future. The impact of provenance collection, mainly with respect to performance (runtime and persistent memory consumption), of the current prototype on the data layer (WP2) has to be examined. This could lead to adjustments to the prove-nance data representation, and collection mechanisms. These modifications are foreseen at
the moment, and therefore, are already shortly addressed in Subsection 3.4.2. Another issue that will be addressed in the future is data provenance between services respectively.
As shown in Section 3.2 there are plenty of possibilities to use provenance data. For instance, provenance could be used for debugging and auditing purposes. Additionally, the usability of provenance information for policy enforcement could also be addressed in the future. Some possible use-cases are already mentioned in Section 3.2. Also, provenance could support trust and reputation mechanisms in COMPOSE. Another possibility would be to investigate the different kinds of information flow policies that could be defined using provenance information.
References
[1] Vlad Trifa and Iker Larizgoitia. Design of the object virtualization specification. COM-POSE Deliverable D2.1.1, October 2013.
[2] Daniel Schreckling, Juan David Parra, Marko Vujasinovic, Alessio Gugliota, and Rizwan Asghar. Security requirements and architecture for compose. COMPOSE deliverable D5.1.1, 11 2013.
[3] Vincent C Hu, Karen Scarfone, Rick Kuhn, and Kenneth Sandlin. Guide to Attribute Based Access Control ( ABAC ) Definition and Considerations DRAFT NIST Special Publication 800-162 Guide to Attribute Based Access Control ( ABAC ) Definition and Considerations.
[4] Lingyu Wang, Duminda Wijesekera, and Sushil Jajodia. A logic-based framework for attribute based access control. In Proceedings of the 2004 ACM Workshop on Formal Methods in Security Engineering, FMSE ’04, pages 45–55, New York, NY, USA, 2004. ACM.
[5] IsabelF. Cruz, Rigel Gjomemo, Benjamin Lin, and Mirko Orsini. A constraint and attribute based security framework for dynamic role assignment in collaborative envi-ronments. In Elisa Bertino and JamesB.D. Joshi, editors, Collaborative Computing: Networking, Applications and Worksharing, volume 10 of Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, pages 322–339. Springer Berlin Heidelberg, 2009.
[6] E. Yuan and J. Tong. Attributed based access control (abac) for web services. InWeb Services, 2005. ICWS 2005. Proceedings. 2005 IEEE International Conference on, pages –569, July 2005.
[7] Niklas Broberg and David Sands. Paralocks: Role-based information flow control and beyond. In Proceedings of the 37th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL ’10, pages 431–444, New York, NY, USA, 2010. ACM.
[8] Dieter Gollmann. Computer Security. John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester West Sussex, England, 2006.
[9] Robert Kleinfeld and Lukasz Radziwonowicz. Functional requirements and specification of open marketplace developers api. COMPOSE Deliverable D6.1.1, October 2013. [10] Cloudfoundry user account and authentication (uaa) server. https://github.com/
cloudfoundry/uaa. Accessed: 2014-03-30.
[12] Openid connect. http://openid.net/connect/. Accessed: 2014-03-30.
[13] Simple cloud identity management: Core schema 1.0. http://www.simplecloud.
info/. Accessed: 2014-03-30.
[14] Bosh release for a ssl proxy. https://github.com/cloudfoundry-community/
sslproxy-boshrelease. Accessed: 2014-04-10.
[15] Setup internal ssl communication. https://github.com/
cloudfoundry-collaboration/vcap/wiki/Setup-internal-SSL-communication.
Accessed: 2014-03-30.
[16] Setup internal ssl communication. https://github.com/cloudfoundry-attic/vcap/
pull/101. Accessed: 2014-03-30.
[17] Pivotal web services forums: Ssl certificate for custom domain. http://support.run.
pivotal.io/entries/24453417-SSL-certificate-for-custom-domain. Accessed:
2014-03-30.
[18] Api keys. https://developers.google.com/console/help/new/
#generatingdevkeys. Accessed: 2014-03-30.
[19] Kiran-Kumar Muniswamy-Reddy, David A Holland, Uri Braun, and Margo I Seltzer. Provenance-aware storage systems. In USENIX Annual Technical Conference, General Track, pages 43–56, 2006.
[20] David Carrera and Alvaro Villalba. Design of the object composition specification and components. COMPOSE deliverable D2.3.1, 10 2013.
[21] David FC Brewer and Micheal J Nash. The chinese wall security policy. 1989.
[22] Christoph Bier. How usage control and provenance tracking get together-a data protec-tion perspective. InSecurity and Privacy Workshops (SPW), 2013 IEEE, pages 13–17. IEEE, 2013.
[23] The llvm compiler infrastructure. http://llvm.org/. Accessed: 2014-04-17.
[24] Chris Lattner and Vikram Adve. Llvm: A compilation framework for lifelong program analysis & transformation. In Code Generation and Optimization, 2004. CGO 2004. International Symposium on, pages 75–86. IEEE, 2004.
[25] Alon Zakai. Emscripten: an llvm-to-javascript compiler. In Proceedings of the ACM international conference companion on Object oriented programming systems languages and applications companion, pages 301–312. ACM, 2011.
[26] Rhino hacker guide. http://ringojs.org/documentation/rhino_hacker_guide. Ac-cessed: 2014-04-17.