of a Temp erature-aware Multicore-processor
Hidenori Sato Toshinori Sato
SeikoEpson Corporation PRESTO, JST
[email protected] [email protected]
Abstract|While lowersupply voltage is
eec-tive for energy reduction, it causes performance
loss. To mitigate the loss, weproposeto execute
only the part, which do es not have any inuence
onexecutionsp eed,withlow-speed. Weare
inves-tigating a multithreaded execution, named
Con-trail Architecture, which divides an instruction
stream into two streams. One is the sp eculation
stream, whichis the main partof a program and
where speculation is applied. The other is the
verication stream, which veries every sp
ecula-tion. The energy consumption is reduced by the
decreasein the executiontime inthe sp eculation
streamandbythelow-speedexecutioninthe
ver-ication stream. The paper willpresent our
pre-liminaryevaluationonenergyeciencyof a
Con-trailpro cessor.
I. Introduction
The increasing p opularity ofp ortable andmobile
computer platforms such as laptop PCs and smart
cell phones is a driving force in the investigation
of high-p erformance and p ower-ecient
micropro-cessors. As thecomputingp ower ofmicropro cessors
for mobile devices increases, however, their p ower
consumption alsoincreases. While p ower isalready
amajor design constraintin thearea ofmobile and
emb edded computer platforms, it has also become
alimitingfactoringeneral-purp osemicropro cessors.
Multicore-processor architecture is one of the
solu-tionsandit has b een already adoptedin emb edded
microprocessors[6,13, 25,28].
The energy consumed in a micropro cessor is the
product of its p ower consumption and execution
time. Thus, to reduce energy consumption, we
shoulddecreaseeither or bothof them. Power
con-sumptionin a CMOS digital circuit is governed by
theequation: P =P activ e +P l eak ag e (1) whereP activ e
isactive p owerand P
leak ag e
isleakage
p ower. The active p ower P
activ e
and gate delay t
pd aregivenby P activ e /fC l oad V 2 dd (2) t pd / V dd (V dd 0V t ) (3)
wheref is the clo ckfrequency, C
load
is theload
ca-pacitance, V
dd
is the supply voltage, and V
t is the
threshold voltage of the device. is a factor
de-p endent up on the carrier velocity saturation and is
around1.5 inmodern CMOS technology. Based on
Eq.(2),wecaneasilyndthatapower-supply
reduc-tion is the most eective way to lower power
con-sumption. However, Eq.(3) tells us that reductions
in the supply voltage increase gate delay, resulting
inaslowerclo ckfrequency,andthusdiminishingthe
computingp erformanceofthemicroprocessor. In
or-dertomaintainhightransistorswitchingsp eeds,itis
requiredthatthethresholdvoltageisprop ortionally
scaleddownwiththesupplyvoltage.
Ontheotherhand,theleakagep owercanb egiven
by P l eakage =I l eak ag e V dd (4) whereI leak ag e
istheleakagecurrent. The
subthresh-oldleakagecurrentI
leak ag e
isdominatedbythreshold
voltageV
t
in thefollowingequation:
I leak ag e /10 0 V t S (5)
whereSisthesubthresholdswingparameter. Thus,
lower thresholdvoltage leadsto increase
consumption.
In order to achieve high p erformance and low
power, we can exploit parallelism[3]. Two
identi-cal circuits are used in order to make each unit to
work at half the original frequency while the
origi-nal throughput is maintained. Since the speed
re-quirement for the circuit b ecomes half, the supply
voltagecan b e decreased. In this case, the amount
of parallelism can b e increased to further reduce
thetotal power consumption. Another kind of
par-allelism, which is thread level parallelism, is
uti-lizedforenergyreductionwithmaintainingpro cessor
performance[6]. Inthispap er,weprop osean
energy-ecientspeculativemulticore-pro cessor.
II. Contrail ProcessorArchitecture
To reduce the energy consumption, we divide an
executionofanapplicationintotwostreams. Oneis
calledthespeculationstreamandconsistsofthemain
part of the execution. However, it utilizes sp
ecula-tiontoskipseveralregionsoftheexecution. Inother
words,thenumberofinstructionsinthesp eculation
streamissmallerthanthatintheoriginalexecution,
resultingin energyreduction. Incontrast,the other
streamiscalledtheverication streamandsupp orts
the sp eculation stream by verifying each sp
ecula-tion. The key idea isthatthe speculativeexecution
in the original program translates its each critical
path into a non-critical one and we move it from
the sp eculation stream into the verication stream.
Hence, the verication stream can executeslowly if
thesp eculation isalmost successful. Wecan reduce
the clo ckfrequency ofthe components for the
veri-cation stream. Furthermore, the supply voltageis
alsoreduced. From these considerations, its energy
consumptionissignicantlyreduced. Wecoinedthis
techniqueContrailarchitecture[23].
A.Multicore-pro cessor mo del
Eachstreamexecutes as a thread ona
multicore-processor,eachpro cessingelement(PE)ofwhich
in-dependently works at the variable clo ck frequency
andsupplyvoltage[7,8,10]. Thespeculationstream
isexecutedonaPEinhigh-speedmo deandthe
veri-cationstreamisexecutedonotherPEsinlow-speed
mode. Intheidealcase,thatmeansthereareno
mis-predictions; the sp eculation stream nishes silently
inwhichamispredictionisdetectedin averication
stream, all threads from the misprediction p ointto
tail, including the speculation stream and any
ver-icationstreams, are squashed, andprocessor state
is recovered by the verication stream that detect
themisprediction. Andthen,thevericationstream
b ecomesthe sp eculationstream.
time
instructions
(a) original execution flow
easily predictable regions
(b) contrail processor (4PEs)
spawn new thread
verification stream
speculation stream
misprediction
squash
squash
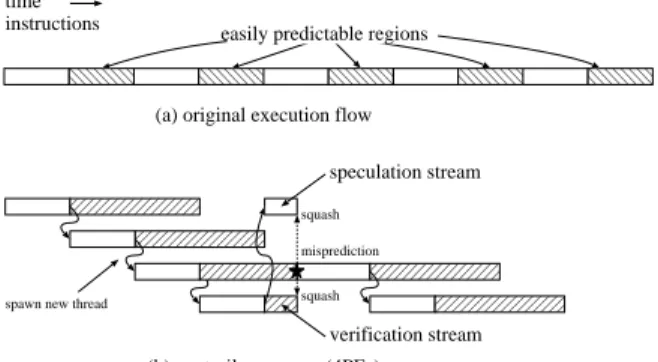
FIG.1 ExecutiononaContrailprocessor
Weexplainhow theprogram islogically executed
onaContrail pro cessor,using Figure1. Weassume
that half ofthe original execution of anapplication
is ideally predicted and is distributed uniformly as
explained in Figure 1(a). This is a reasonable
as-sumption, since it has b een rep orted that 59% of
dynamic traces can b e reused with the help of the
value prediction[20]. We alsoassume the clo ck
fre-quency for the verication PEs at half that for the
sp eculation PE. Under these assumptions, the
ex-ecution is divided into sp eculation and verication
streamsinaContrailpro cessorinadistributed
man-nerasdepictedinFigure1(b). Thepredictedregions
areskipp edinthesp eculationstreamandexecutein
theverication streams whileenlargingtheir
execu-tion time. Determining trigger p oints is based on
the condence information obtained from the value
predictor. When an easily predictable region is
de-tected, the head thread spawns a new sp eculation
stream on the next PE andit turns into a
verica-tionstream. Thus,theContrailpro cessorislogically
build as a ring-connected multicore-processor such
asMultiScalararchitecture[9],asshowninFigure2.
Physical interconnectsdo not necessarily followthe
logicaltop ology. Eachvericationstreamstaysalive
untilall instructionsinthe corresp ondingregion
re-movedfromthesp eculationstreamareexecuted.
D$
Data
path
I$
VP
Vdd/Clk
D$
Data
path
I$
VP
Vdd/Clk
D$
Data
path
I$
VP
Vdd/Clk
D$
Data
path
I$
VP
Vdd/Clk
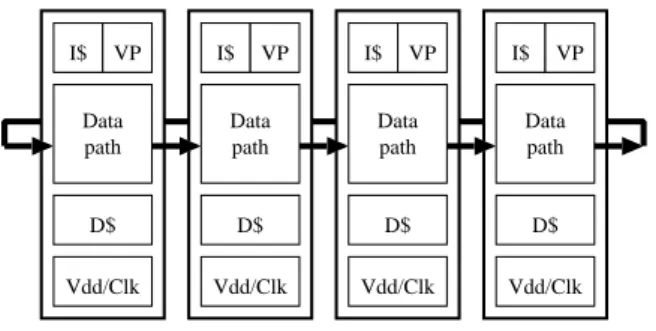
FIG.2 Contrailprocessor
Thecostofspawninganewthreadmightb elarger
thanthatofverifying avaluepredictionona
single-threadedprocessor. However,insingle-threaded
pro-cessormo del,onlydatapathalternatesbetween
high-speedandlow-speedmodes. The otherblo cks,esp
e-ciallyinstruction-supplyfront-end,shouldbealways
in high-speed mo de. This reduces the eect of the
variablefrequencyandvoltagecontroltechnique. On
the other hand, every comp onent of each pro cessor
corecanalternatetwomo desinmulticoremo del,and
thus improving energyeciency is exp ected. From
these observations, we determined to adopt
multi-threadedmo delratherthansingle-threaded mo del.
One of the dierences from the previously
pro-posed speculative multithreaded pro cessors is that
the Contrail pro cessor do es not require any
mecha-nismtodetectmemorydep endenceviolations. Since
the Contrail processor strongly relies on value
pre-diction, any memory dep endence violations cannot
occur. Instead, itsuers from value mispredictions.
Thissimplieshardwarecomplexity. Thisisbecause
value mispredictions can b e detected lo cally in an
PE, while detecting memory dep endence violations
requiresa complexmechanismsuchasARBor
Ver-sioningCache[9]. Anotherdierence fromthe
previ-ously prop osed pre-computing architectures[26, 30]
isthat the Contrail pro cessor architecturedoes not
rely on redundantexecution. In the ideal case, the
number of executedinstructions is unchanged.
An-otherdierenceisthatitstargetistheimprovement
inenergyeciencyinsteadofthat inp erformance.
B.Activep ower reduction
As shown in Figure 2, each PE has its
dedi-catedvoltage/frequencycontrollerandvalue
predic-tor. The p otential eect of the Contrail pro cessor
architecture onenergy-eciency isestimated as
fol-for the sp eculation PE. When we focus on active
p ower,energy consumption iscalculated as follows:
Forthesp eculation stream, energyconsumption b
e-comes half that of the original execution since the
number of instructions is reduced by half. In
con-trast, for the verication streams, the sum of every
execution time remains unchanged since the
execu-tion time ofeachinstruction increases doubly while
the totalnumber of instructions isreduced by half.
Its energy consumption is decreased by the
reduc-tion of the clo ck frequency and the supply voltage.
Based onEq.(2), itisreduced to 1
8
. Thus,the total
energysavingsis37.5%. Itistruethattheenergy
ef-ciencyofContrail pro cessorsdep ends onthe value
predictionaccuracyandthesizeofeachpredicted
re-gion. However,webelievethatthep otentialeectof
Contrailpro cessorsonenergysavingsissubstantial.
Recent studies regarding power consumption of
value predictors found that complex value
predic-tors are p ower-hungry[1, 19, 22]. One of the
solu-tions for reducing p ower consumed in value
predic-tors is using simple value predictors such as
last-value predictor[17, 22]. However, value prediction
isnot the onlytechnique for generatingsp eculation
stream. Other techniques are probably utilized for
this purpose, and the key idea b ehind the Contrail
architecturewillb e applied.
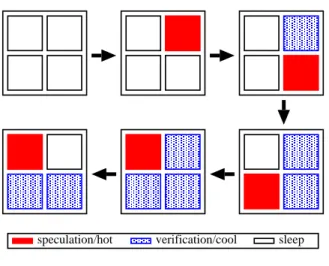
C.Temp erature awareness
The Contrail pro cessor has a go o d characteristic
on temp erature awareness[24]. Figure 3 is a
bird's-eyeview showing how the speculation and
verica-tionstreamsareexecutedonaConrailprocessorchip
consisting of four pro cessor cores. As you can see,
there is only one hot core and it is rotating. This
feature resemblesthe activitymigration[12]andthe
cluster hopping[4]. Because hot sp ots are rotating,
heatisdiusedoverthechipanditstemp eraturewill
b e down.
D.Leakagep owerconsideration
WhiletheContrailprocessorarchitecturehasgo o d
characteristics on active p ower reduction and
tem-p erature awareness, its leakage p ower consumption
might be increased since it has multiple cores. As
mentioned in the previous sections, only one core
sleep
speculation/hot
verification/cool
FIG.3 PErotation
fortheslowcores. Similarly,thethresholdvoltageof
transistorsfortheslowcorescanb eraised,resulting
inleakagereduction. There areseveral circuits
pro-posedtoreduceleakagecurrentbydynamically
rais-ingthethresholdvoltage,forexamplebymo dulating
bo dybiasvoltage[2,14,29]. Leakagep owerstrongly
dependsupontemp erature. Sinceitisexpectedthat
theContrailprocessorreduces chiptemp erature,its
leakagep owerwillbe alsoreduced. Fromthese
con-siderations, the Contrail processor's leakage power
consumption will be comparableto or even smaller
thanthatofasingle-coreprocessor.
I II. Evaluation
In our previous study[27], we evaluated the p
o-tentialoftheContrailpro cessoronenergyeciency
undertheassumptionofperfectvalueprediction. In
this pap er, we consider p enalties due to value
mis-predictions.
A.Metho dology
We implementedtheContrail pro cessor simulator
usingMASE/SimpleScalar/PISAto olset[15]. Its
in-struction set architecture (ISA) is based on MIPS
ISA. The baseline processor and each PE are a
2-way out-of-order execution pro cessor. Only fetch
bandwidth is 8-instruction wide. The number of
PEs on the Contrail pro cessor model is 4. In the
current simulator, the followings are assumed.
In-struction and data caches are ideal. Branch
pre-dictionisp erfect. Ambiguousmemory dep endences
arep erfectly resolved. Weuse a2K-entrylast-value
go odjobwithloadbalance. Consideringother
parti-tioningp olicies[18]isremainedfor thefuture study.
The interval is 32 instructions. This value is
deter-mined based on the previous study[27]. The
over-headonspawninganew thread is8cycles.
Weevaluateascalingforsupplyvoltageandclo ck
frequencybased onSAMSUN's ARM pro cessor[16].
The verication PEs work at lower frequency and
voltage(600MHz,0.7V),andthesp eculationPEand
thebaselinepro cessor workathigher frequencyand
voltage (1.2GHz, 1.1V). As mentioned ab ove,
leak-agep owerstronglydep endsup ontemp erature. Since
evaluation here is very preliminary, we should use
a p essimistic assumption. We use temp erature of
100C,wheretheleakagepowerisequaltotheactive
p ower[4]. This is a reasonable assumption, since it
isreported that theleakagep ower iscomparableto
theactivep owerinthefuturepro cesstechnologies[2].
The verication PEs exploit the bo dy bias
technol-ogy. Itisassumedthattheleakagep owerconsumed
bythePEs,wherereversebo dybiasisapplied,is
re-ducedby22[2]. And last,weassumethat the
leak-agepowerconsumed byidlePEsisnegligible.
We use CRC, FFT, and StringSearch from
MiBench suite[11] for this evaluation, b ecause our
primary interests are on emb edded applications.
MiBenchis developed for use in the contextof
em-b edded, multimedia, and communications
applica-tions. It contains image pro cessing,
communica-tions, and DSP applications. We use original input
les provided by University of Michigan. All
pro-gramsarecompiledbytheGNUGCCwiththe
opti-mizationoptionsspeciedbyUniversityofMichigan.
Eachprogram isexecutedtocompletion.
B.Results
Figure4showshowthelast-valuepredictorworks.
Each bar is divided into three parts. The b ottom
part indicates the p ercentage of instructions whose
value is correctly predicted. The middle part
indi-cates the p ercentagethat is mispredicted. Andthe
top part indicates the percentage that is not
pre-dictedduetolowcondence. Itisobservedthatthe
characteristicsstronglydep endup onprograms. The
only thing we can nd from the gure is that the
p ercentageofmisprediction issmall.
0%
20%
40%
60%
80%
100%
CRC
FFT
Ssearch
P
re
dic
tion a
cc
ur
ac
y
correct
miss-predicted
no-speculated
FIG.4 %Valuepredictionaccuracy
ready know that the last-value predictor has only
a few contributions on single-corepro cessor
perfor-mance. The is same for the Contrail processor,
while p erformance improvement is not the goal of
thisarchitecture. The combination ofvalue
predic-tionandmultithreadingarchitectureachievesthe
im-provementofaround10% inp erformance.
75%
80%
85%
90%
95%
100%
CRC
FFT
Ssearch
Rel
at
iv
e ex
ecu
tio
n cy
cl
es
FIG.5 Relativeexecutioncycles
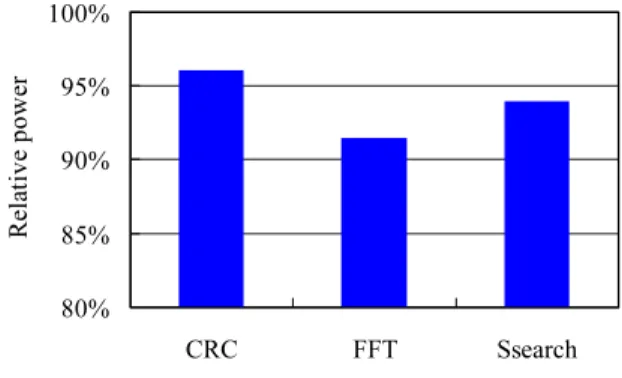
Figure 6 shows the relative power consumption.
Eachbar isdividedintothree parts. The lowerand
upper parts indicatethe average active andleakage
power, respectively. It should b e noted that p ower
consumed by the value predictor is not considered.
The consideration is remained for the future study.
As you can see, p ower consumption is slightly
in-creased. This is b ecause the execution cycle is
re-duced by speculation. From Figures 5 and 6, it is
observedthe cycle reduction rate islarger than the
powerincreaserate. Thus,energyconsumptionis
re-duced. The results are verydierentfrom those for
other low p ower architectures, whichachieve power
reductionat thecost ofperformanceloss.
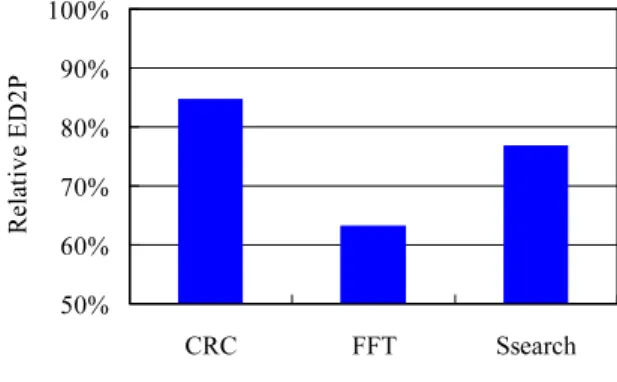
Figure 7 shows Energy-Delay 2
pro duct (ED 2 P). 2
0%
20%
40%
60%
80%
100%
120%
CRC
FFT
Ssearch
R
ela
tive
powe
r
active
leakage
FIG.6 Relativepowerconsumption
p erformanceand energy. The vertical lineindicates
ED 2
Prelativetothatofthebaselinesingle-core
pro-cessor. Itisobservedthattheimprovementof25%in
ED 2
Pis achievedon average. As mentioned above,
the misprediction p enalties are included in the
re-sults. Wehaveseen from Figure4thatthe
percent-age of correct prediction is small. In addition, we
haveseen from Figure 6 that p owerconsumption is
increased. Nonetheless, the Contrail pro cessor
im-provesenergyeciency. Thisisanotable
character-isticofthis architecture.
50%
60%
70%
80%
90%
100%
CRC
FFT
Ssearch
R
ela
tive
ED2P
FIG.7 Relativeenergy-delay 2
product
As we have already seen in Figure 5, the
Con-trail pro cessor achieves performance improvement,
whichis notits primary target. If performance
im-provement is not required, we slow down clock
fre-quency and further reduce power. This is
hierar-chicalfrequency control. Global control signal
uni-formly throttles every lo cal clock, which originally
hastwomo des;high-sp eedmo deforthesp eculation
PEandthelow-sp eedoneforvericationPEs. Since
di-asshown in Figure 8 if wecould ideallycontrolthe
global clock. While this technique do es not aect
energy, thep owerreduction isdesirable for
temper-atureawareness.
80%
85%
90%
95%
100%
CRC
FFT
Ssearch
R
ela
tive
powe
r
FIG.8 Powerreductionviafrequencycontrol
IV. Summary
It is exp ected that multithreading and
dual-power functionalunitsare keytechniquesforenergy
reduction[21]. We have proposed such an
energy-ecient sp eculative multicore-processor. Our
pro-posed architecture exploitsthread level parallelism,
resulting in mitigating p erformance loss caused by
thesupplyvoltagereduction. Inthispap er,weshow
preliminary evaluation results of the Contrail
pro-cessor. We found that the Contrail pro cessor has a
potentialofapproximately25%ED 2
Psavingswhile
processorp erformanceisslightlyimproved.
References
[1] R. Bhargava, et al., \Latency and energy aware value
predictionforhigh-frequencyprocessors,"16thInt.Conf.
onSup ercomputing,2002.
[2] S.Borkar,\Microarchitectureanddesignchallengesfor
gigascaleintegration,"37thInt.Symp.on
Microarchitec-ture,Keynote,2004.
[3] A.P.Chandrakasan,etal.,\Minimizingp ower
consump-tionindigitalCMOScircuits,"Pro c.IEEE,83(4),1995.
[4] P.Chaparro,etal.,\Thermal-eectiveclustered
microar-chitecture,"1stWorkshoponTemperatureAware
Com-puterSystem,2004.
[5] L.Co drescu,etal.,\Ondynamicsp eculativethread
par-titioningandtheMEM-slicingalgorithm,"8thInt.Conf.
on ParallelArchitectures and Compilation Techniques,
1999.
[6] M. Edahiro, et al., \A single-chip multi-processor for
smartterminals,"IEEEMicro,20(4),2000.
[7] M.Fleischmann,\LongRunp owermanagement,"white
pap er,TransmetaCorporation,2001.
[8] D.Flynn, \Intelligentenergymanagement: anSoC
de-Publishers,2003.
[10] S. Go chman, et al., \The Intel Pentium M pro cessor:
microarchitecture and p erformance," IntelTech. Jour.,
7(2),2003.
[11] M. R.Guthaus,etal., \MiBench: afree,commercially
representativeembedded b enchmark suite," 4th
Work-shoponWorkloadCharacterization,2001.
[12] S.Heo,etal.,\Reducingp owerdensitythroughactivity
migration," Int. Symp. on LowPower Electronics and
Design,2003.
[13] S.Kaneko,etal.,\A600MHzsingle-chipmultiprocessor
with4.8GB/sinternalsharedpip elinedbusand512kB
internalmemory,"Int.SolidStateCircuitsConf.,2003.
[14] T.Kuro da,etal.,\A0.9V,150MHz,10mW,4mm 2
,2-D
discrete cosine transform core pro cessor with
variable-threshold-voltagescheme,"Int.SolidStateCircuitConf.,
1996.
[15] E.Larson,etal.,\MASE:Anovelinfrastructurefor
de-tailedmicroarchitecturalmo deling,"Int.Symp.on
Per-formanceAnalysisofSystemsandSoftware,2001.
[16] M.Levy,\SamsungtwistsARMpast1GHz,"
Micropro-cessorrep ort,16(10),2002.
[17] M.H.Lipasti,etal.,\Valuelo calityandloadvalue
pre-diction",7thInt.Conf.onArchitecturalSupp ortfor
Pro-grammingLanguagesandOp erationSystems,1996.
[18] P. Marcuello, et al., \Thread partitioning and value
predictionfor exploitingsp eculative thread-level
paral-lelism,"IEEETrans.Comput.,53(2),2004.
[19] R.Moreno,etal.,\Ap owerp ersp ectiveofvaluesp
ecu-lationfor sup erscalarmicropro cessors,"18thInt. Conf.
onComputerDesign,2000.
[20] M. L. Pilla, et al., \Predicting trace inputs with
dy-namic trace memoization: determining sp eedup upp er
b ounds,"10th Int.Conf.on ParallelArchitecturesand
CompilationTechniques,WorkinProgress,2001.
[21] J.Rattner, \Electronics in the Internet age," 10th Int.
Conf.on ParallelArchitecturesandCompilation
Tech-niques,Keynote,2001.
[22] N.B.Sam,etal.,\Ontheenergy-eciencyofsp eculative
hardware,"Int.Conf.onComputingFrontiers,2005.
[23] T. Sato, et al., \Contrail pro cessors for converting
high-p erformanceintoenergy-eciency,"10thInt.Conf.
onParallel Architecturesand Compilation Techniques,
WorkinProgress,2001.
[24] T.Sato, \Future directions of pro cessor architecture,"
6thInt.WorkshoponInnovativeArchitectureforFuture
GenerationHigh-Performance Pro cessors and Systems,
Panel, http:www.mickey.ai.kyutech.ac.jp/~tsato/
cosmos/papers/iwia03panel.pdf,2003.
[25] T. Shiota,et al., \A51.2GOPS, 1.0GB/s-DMA
single-chipmulti-processorintegratingquadruple8-wayVLIW
pro cessors,"Int.SolidStateCircuitsConf.,2005.
[26] K.Sundaramoorthy,etal.,\Slipstreampro cessors:
im-provingb othp erformance andfaulttolerance"9th Int.
Conf.on ArchitecturalSupp ort forProgramming
Lan-guagesandOp eratingSystems,2000.
[27] Y.Tanaka,eyal.,\Thep otentialinenergyeciencyof
asp eculativechip-multiprocessor,"16thSymp.on
Par-allelisminAlgorithmsandArchitectures,2004.
[28] S.Torii,etal.,\A600MIPS120mW70Aleakage
triple-CPUmobileapplicationpro cessorchip,"Int.SolidState
CircuitsConf.,2005.
[29] Transmeta Corp., \LongRun2 technology," http://
www.transmeta.com/longrun2/.
[30] C. Zilles, et al., \Master/slave sp eculative