2225
Classifying Various Clustering Techniques For
MANET
Ashish Chaturvedi, Dr. Ratish Agarwal, Dr. Sachin Goyal
ABSTRACT - The mobile ad-hoc network (MANET) is getting popularity now a days due to their adaptability and they can be conveyed at any area with no prior framework. However, mobile ad hoc network raise some new difficulties, when it is utilized in network that spread huge zone and contain an enormous number of portable nodes. Afterwards, different algorithm for clustering has been created. These clustering techniques are used to make the structure the system into gatherings of elements (node) called cluster. This creates a various leveled structure. Hear each cluster contains a uncommon element called clusterhead. Clusterhead is chosen on the particular measurement or a blend of measurements, for example; mobility, identity, weight, density, degree etc. mobile ad-hoc network have some disadvantage due to both attributes of the routing protocols and the transmission medium (low bandwidth, medium sharing, etc.).
Keywords- clusterhead, Clustering, MANET, gateway.
—————————— ——————————
1.
INTRODUCTION
A mobile ad-hoc network (MANET) is a continuously self-designing, framework less, remote system of mobile nodes. Every node in mobile ad-hoc network is allowed to move anyplace toward any path. Because of this, it frequently alter the direction of its connects to different device. mobile ad-hoc network can be immediately constructed without any prior foundations. Portable(mobile) nodes can speak with one another over remote channel. Nodes which are in one another's transmission range can legitimately convey and are in charge of powerfully finding one another. Routers are utilized for the correspondence of those nodes, those are not in coverage of transmitter node. Intermediate nodes are going to act as routers that hand-off packets produced by other node to their goal. These nodes regularly have vitality compelled that is, power of battery and nodes are allowed to join or leave the network. Clustering is a best way to solve heterogeneity of nodes, and it minimizes the measure of directing data that moves inside the network. Partitioning of mobile ad-hoc network‟s nodes virtually indifferent sub networks as indicated by topographical region in MANET is called clustering. This network (MANET) is the helpful course of action of a gathering of remote mobile nodes with no predefined framework depended on to keep the network associated. A gathering structure makes ad-hoc networks to look more stable and littler. Each mobile node From bunch communicate a requesting message to set up affiliation. If the member element changes its present cluster, at that point just the node which are remaining in comparing cluster are have to refresh the information, and there is no compelling reason to do the progressions by the full network.
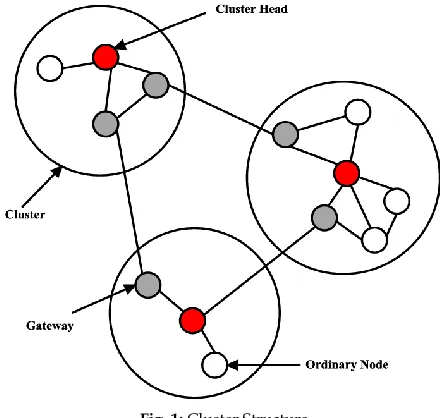
The clusterhead, members node, gateway nodes assumes a significant job in clustering where gateway nodes and clusterhead are the spine nodes in progressive mobile ad-hoc network. Clusterhead is a neighborhood organizer of cluster and Cluster Member is a customary node, which is neither a door node nor clusterhead. Cluster Gateway is a hub which is normal in at least two group and which furnishes bury cluster correspondence joins with to advances data between these cluster. Two sorts of correspondences are done in cluster.
Fig. 1: Cluster Structure
A. Intra cluster communication
In this communication, Clusterhead has only just 1-bounce availability with each member in a cluster. So clusterhead can communicate straightforwardly with cluster member however members are not ready to communicate legitimately with different individuals from same cluster.
B. Inter cluster communication
In this correspondence, utilization of routing protocol is done. Multi-point hand-off idea chooses the clusterhead by which the information packet will be forward. This system, _________________________________
Ashish Chaturvedi, Research Scholar, Department of CSE, UIT, RGPV, Bhopal(MP), [email protected]
Dr. Ratish Agarwal, Assistant Professor, Department of IT,UIT, RGPV, Bhopal (MP), [email protected]
2226 lessen the clog by limiting the quantity of sending nodes and
it spares the battery control of clusterhead.
2.
C
LUSTERINGT
ECHNIQUE OFM
OBILEA
D HOCN
ETWORK2.1 clustering based on Identifier
An extraordinary ID is being apportioned for every node. Every node knows the ID of its everything neighboring node, and clusterhead assurance is done by following some particular models as given underneath
A. Lowest ID approach of clustering (LIC)
In LIC calculation, a mobile node having the littlest id is chosen as a clusterhead. Along these lines, the ids of the neighbors of a clusterhead will reliably be higher than the id of clusterhead. Node, which exists in the transmission scope of at least two clusterheads is known as a gateway node. Gateway node utilized for directing reason between at least two cluster. In this methodology, every hub has an unmistakable id. Intermittently, every node communicates the rundown of nodes that it can listen.
A node, which just hears neighboring nodes higher id than itself is called clusterhead.
The littlest id node that a node hears is its
clusterhead, except if the clusterhead node explicitly hands over its job as a clusterhead.
A node, which can hear in any event two clusterheads is known as a Gateway node. Something different, a hub is an ordinary node.
This algorithm just with the most reduced node ids which are simply arbitrarily doled out numbers without taking some other parameter of a node to be chosen as a clusterhead. Since the node's id don't changes with time, so the nodes with littler ids are bound to chose as clusterheads than the nodes, which have larger ids. Therefore, downside of most minimal ID approach is that sure nodes are vulnerable to control waste because of filling in as clusterhead for longer timeframes [1].
B. Max-Min D-Cluster Formation approach
This approach defined the cluster to an accumulation of nodes, which are up to d-bounces from their clusterhead node. Due to enormous number of nodes included, it is reasonable to give the nodes a chance to work non concurrently. Hear, the clock synchronization overhead is abstained from, giving extra preparing reserve savings. In this algorithm, the all out number of messages moved from every node is constrained to a multiple of d, which is the greatest number of jumps away good ways from the closest clusterhead, instead of n, which is the complete number of nodes in the network. This approach ensures decent controlled message unpredictability for this algorithm. Here d is information to the heuristic so there is an authority over the clusterheads decision or the clusterheads thickness in the network. The necessity of assets required at every hub is least, by utilizing two information structures and four basic
rules that keep up node's data over 2d rounds of correspondence. In this approach, nodes are candidate to be clusterhead dependent on their node id as opposed to some other parameter. On the off chance that a node X is a biggest node in the d-neighborhood of other node Y then node X will be chosen as a clusterhead, in spite of the fact that, node X may not be the biggest in its own d-neighborhood. This strategy gives a bettor trade of clusterheads as opposed to a shaky trade. This methodology limits the aggregate sum of data that must be traded between active clusterhead and another clusterhead[2].
2.2 Clustering based connectivity
C. Adaptive cluster load balancing technique
In case of HCC clustering technique, a clusterhead can be depleted it oversees an excessive number of mobile nodes.Issue of bottleneck emerge hear. Therefore, a new technique is derived, which use a hello message. In the event that a sending node is a clusterhead, at that point it will set the quantity of its represented member nodes as Option esteem in hello message.In the event that a sender node isn't a clusterhead or it is just uncertain then Option worth will again be set to 0. At the point when a clusterhead's Hello message demonstrates its ruled nodes number exceed an edge (maximum number of node, which can be managed by oneCH), no new node will be allow to join in this cluster. As Therefore, this can totally evacuate the clusterhead bottleneck problem and optimize the structure of cluster. This procedure adjusts the heap between different clusters. In this way, resource utilization and data move is appropriated among all clusters instead of few [3].
D. Adaptive Multihop Clustering(AMC)technique
2227 Nevertheless, this methodology does not manage clusterhead
race [4].
E. Highest connectivity clustering approach (HCC)
In this calculation, clusters are constructed based on the degree of connectivity. The level of a each node is gotten by computing its distance from different nodes. Each node communicates its node id to every one of those nodes, which are in its transmission extend. The node, which has most extreme number of neighbors (greatest degree), is chosen as a clusterhead and rests every one of the neighbors of that clusterhead become member node of that group, and can't further partake in the race of clusterhead process. clusterheads are not straightforwardly connected here, only one clusterhead per cluster is permitted in a solitary group. Any two nodes in a solitary bunch are all things considered two jump away in light of the fact that the clusterhead is straight forwardly associated with every one of its neighbor node in the cluster. The rate of changing clusterhead is very low in this algorithm but its throughput is also low. In this scheme, some resources are allocated in each cluster, which is shared among the individuals from that group so as the quantity of member nodes in a bunch are expanded than its throughput diminished. Because of these node movements, re affiliation tally of nodes is highthus; the most noteworthy degree node or current clusterhead can't be re-chosen to be a clusterhead regardless of whether it erase one of its neighbor [5].
F. K-hop connectivity ID clustering (KCONID)
It is a blend of two clustering calculations; first, one is Lowest ID otherone is highest degree heuristics. The fundamental reason for this calculation is to limit the absolute number of cluster made in the system. Clusterhed shaped the groups in the KCONID algorithm and all nodes at separation at most k-bounce far from clusterhead. Initially, a node communicates a message by by which clustering solicitation is send to every other node. We know that in highest degree heuristic, level of node just estimates availability for 1-bounce clusters yet this methodology sums up network for a k-jump neighborhood. thus, when k = 1 network is equivalent to node degree. Each node in the system is appointed with paired: (d, ID). Where d denotes node‟s availability and ID indicates node's distinguishing proof. Highest degree Node is elected as clusterhead. If there should arise an occurrence of equivalent availability, a node which has most reduced ID is chosen as clusterhead. he fundamental rationale of this calculation is that each node communicates its grouping activity, when all its k-bounce neighbors with bigger clusterhead need have done as such [6].
2.3 Mobiloty based clustering
G. Mobility based Metric Clustering Approach
In this calculation, mobility metric used as a basis for cluster creation. Versatile nodes which have low speed with respect to their neighbor nodes get the opportunity to chose as a clusterheads. Otherwise it pronounces itself to be a Cluster Member. The normal nearby speed of a node is estimated by
ascertaining the change of a speed of mobile node in respect to every one of its neighbors. A little change worth shows that this mobile node is less versatile as for its neighbors. Therefore, a mobile node low change esteems is elected as clusterhead. For maintaining cluster, clock is utilized to minimize the clusterhead change rate by abstaining from reclustering for alike contacts of two passing clusterhead. For maintenance of cluster, the versatility conduct of nodes isn't considered consistently so a clusterhead does not offers certification to support a low portability trademark in respect to its member node. This technique is effective only in MANET gathering versatility conduct, where a gathering of different mobile node travel with comparable speed and direction. Performance of this calculation lessens when node moves haphazardly [7].
H. Mobility based d-Hop Clustering Approach
This technique splits an ad hoc network into system into d-bounce groups, with the indentation to increase the flexibility of the cluster diameter, on the basis of mobility metric. This approach expects that every node can gauge its got signal quality. As such, a node can gauge its distance from its neighbors. Solid got signal quality infers closeness between two nodes. This technique needs to use five factor for its calculation- an approx estimation of the distance between nodes, variation of assessed separation after some time, thenear by security and estimation of mean separation. Relative portability of node compares to the distinction of the assessed separation of one node with other, at two progressive time instance. This parameter shows if two nodes move far from one another or in the event that they become nearer. The variety of evaluated separates between two nodes is figured out rather than determined by their physical distance, on the grounds that physical distance does not a precise proportion of closeness. As example, a node with low energy will send packets at limited power in this manner going about as a separated node from its physically closest neighbor. The variety of evaluated separation and the relative portability between two nodes are utilized to figure the neighborhood stability. Local stability is processed to choose some hub as clusterhead. Only a node can be elect as a clusterhead, in the event that it is found as the steadiest node among its neighborhood. Thus, a node will be the clusterhead, which have most minimal estimation of nearby stability among its neighbors [8].
I. Mobility Prediction-based Clustering (MPBC)
Algorithm
2228 clusterhead, and when two clusterheads moves toward one
another, one gives up its role of clusterhead. This technique provide longer lifetime for clusterhead, it gives the stable cluster as result[9].
J. Mobility aware highest degree (MobHiD) technique
This technique (MobHiD) combines the highest degree approach with mobility prediction of Mobile Host by information theory based technique. In this technique, Mobility forecast involves accurate prediction of future portability of mobile host dependent on neighboring stability. A mobile host with same arrangement of neighbors over a long term will make an increasingly steady cluster structure. Utilizing this thought, MobHiD register the versatility of a mobile host as stability of neighborhood. additionally dependent on most noteworthy degree calculation it makes one-bounce cluster of a little size, and mobile host having a most noteworthy degree as for its neighbor chose as clusterhead. The principle goal of this calculation is to give longer lifetime of the cluster structure[10].
2.4 Clustering with Low-Maintenance
K. Least Cluster Change (LCC) Algorithm
This technique gives significantly improvement over HCC and calculations to the extent the expense of cluster support is consider. Many of conventions in frequently executed grouping methodology and to fulfill a specific clusterhead characteristic, occasionally re-clustered. In HCC, the grouping procedure is executed intermittently to check the "neighborhood most elevated node degree" highlight of a clusterhead. At the point when a clusterhead gets a member node with higher degree, than it is compelled to surrender its clusterhead role. For example, visit re-clustering occurs when particularly using this technique.
LCC take two steps in clustering algorithm, cluster maintenance and cluster formation that is to be follow by LIC to elect clusterheads from various mobile node. Hare mobile node with most reduced ID in its neighborhood is chosen as clusterhead node. for this situation, Re-clustering is occasion driven and reduced. Re-clustering can only be done in two cases
When two clusterheads moves into the scope of one
another than one surrenders its clusterhead job.
When a mobile node can't contact any clusterhead,
than the group structure for the system is again worked by LIC.
Hence, LCC significantly increase the strength of a cluster by completely filling the necessity for a clusterhead. It generally conveys indicated qualities in its neighborhood. Be that as it may, it is mean in the subsequent re-clustering scenario, a single node's development can even now summon the opening cluster structure re-calculation and it brings about bigger correspondence overhead [11].
L. 3-hop between adjacent clusterheads approach
Another node is introduced in this algorithm, which is not in the range of any clusterheads, but this node is in the range of
some clustermembers. The mobile node having as tounding node degree among other nodein its neighborhood is chosen to be the first clusterhead. Nodes which are directly connected to this clusterhead called “cluster member”. A cluster member or direct neighbors of any clustermember which are “not specified” (node not is in any group yet),refuse filling in as a clusterhead. A node, which isn't declined clusterhead capacity, reported as another clusterhead when it has the most elevated node degree in its neighborhood. At the point when a mobile node comes to realize that it can't be in the administration of a clusterhead or it join another group as a part, yet some neighbor of this node is a clustermember of some other cluster, than it enter in the relating cluster as a visitor node or clusterguest.
For cluster support purpose, this method keeps the adjoining clusterheads in any event two hop away. So when two clusterheads enters in the scope of one another, than one surrenders its job of clusterhead. With the help of guest node, this algorithm, while re-clustering does not raise ripple effect. For another situation, when a mobile node moves out of the scopes all things considered, it can join another cluster as a visitor node/clusterguest on the off chance that it ready to achieve some cluster member of that group. So here, there is no compelling reason to make new cluster so as to secure such a single node as we do in LCC calculation. These calculations limit the quantity of cluster and furthermore dispose of pointless clusters[12].
M. Passive clustering (PC)
In passive approach of clustering, a mobile node can be in any of the four after position: introductory, clusterhead, customary node and gateway. Every mobile node remain in 'introductory' position toward the start. Just a node, which is in "introductory" state must be chosen as clusterheads. At the point when a potential clusterhead having "starting" state needs to send something, similar to a flood search, it report itself as a clusterhead by piggybacking its momentum position in the packet. Neighbors node comes to know the clusterhead guarantee by watching the "group position" in the packet, and afterward record the Clusterhead ID and message getting time. A mobile node which gets a case from only one clusterhead turns into a common node, and a mobile node which gets more cases turns into a gateway node. This methodology does not send any unequivocal message about clustering to keep up the cluster structure, so here every node have the obligation regarding refreshing its very own cluster position by keeping a clock. At the point when a common node does not get any parcel from its clusterhead for a given timeframe, its position again changed to "initial “position [13].
2.5 Energy-Efficient Clustering
N. Flexible Weighted Clustering Algorithm dependent
on Battery Power
2229 status by broadcasting a message and makes list of its
neighbors. The clusterhead decision depends on the nodes mobility, weight amount of the nodes degree, battery power remain in node and sum of separation to the majority of its neighbor nodes. The element having least weight is chosen as clusterhead. This calculation plays out the cluster upkeep when, a node goes outside from its group go or clusterhead battery power diminishes to a predefined esteem (threshold). Principle inconvenience of this calculation is that it builds the network traffic while clusterhead decision processes going on, which debases the network's general execution [14].
O. A multicast power greedy clustering (MPGC)
algorithm
This algorithm depends on heuristic to decrease the power use. This calculation has three stages: recruiting, beacon and greedy phase. In beacon phase, each node inform its neighbor nodes about its essence by sending a reference point signal with the high power and get data about neighboring nodes. In greedy phase, every node sends a clusterhead announcement message with vital power expected to achieve its closest neighbor node, and after that, it broadens its capacity level methodically until it ranges to all neighbors. In recruiting stage, every node contains residual power estimation of its neighbor node. On the off chance that a node "i" has the most astounding lingering power among all its neighboring node, at that point "i"is chose as clusterhead. Multicast power greedy clustering increases organize lifetime, however it requires some more stride to make the architecture of clusters, which expands consumption of bandwidth and network traffic [15].
P. Power aware connected dominant set
This algorithm reduces the size of a commanding set without changing its capacity. It is an vitality efficient approach for clustering. The non-required mobile nodes are expelled from the ruling set in order to save their power consumption for servicing as clusterheads. Internal mobile nodes of abominating set absorb higher battery power than the outside node of a dominating set. It happens because internal mobile nodes of dominating set do extra work, including updates of routing information and relay of information parcel. Hence Subsequently, it is needful to diminish the power utilization of mobile node in a dominating set. In this technique, Energy level (el) factor is used to elect a clusterhead instead of nodeID. A mobile node can be expelled from the overwhelming set when one or two dominating neighbors cover its nearest neighbor set, and furthermore simultaneously it has less residual power than the ruling neighbors. This plan do not provide the great distinction of power consumption among clusterheads and other ordinary nodes, since its primary goal is to reduce size of dominating set as opposed to balancing the degree of power utilization among every mobile nodes. Subsequently, mobile nodes of dominating set are still likely spend their capacity at a quicker rate [16].
2.6 Weight based Clustering
Q. A Flexible Weight Based Clustering Algorithm
(FWCA)
In this approach, blend of measurements with various loads is utilized to construct clusters. The basic parameters, which are required to elect a clusterhead, level of a node, mobility of a node remaining, transmission power, battery power. In FWCA, the size of cluster must not be exceeding a pre-characterized edge limit. In cluster upkeep stage, instead of the mobility of a node it utilizes the cluster limit and the connection lifetime because the connection dependability metric influences the race of a clusterhead with the weight, which is same as the weight in node mobility metric [17].
R. Weighted clustering algorithm (WCA)
In this calculation, clusterhead is elected based on various factor such as number of nodes it can deal with, transmission control, battery power and mobility. To stay away from correspondences overhead, the clusterhead race is possibly done by node mobility when the present dominant set can not cover every one of the node. To guarantee that clusterheads won't be over-burden a predefined limit worth is utilized which demonstrates the complete number of nodes can be taken care of by clusterhead. Clusterheads are selected on the basis of weight estimation of every node. The weight related to a node n is characterized as:
Wn = w1 Δn + w2 Dn +w3Mn +w4 Pn --- (1) The node, which has least weight worth, is elected as a clusterhead. The weight factor is picked in such a way like- w1 + w2 + w3 + w4 = 1. Where Mn is the proportion of mobility. it is utilized for calculating the normal running rate of each node during a predefined timespan T. Δn denotes the degree distinction. Δn is gotten by first figuring the quantity of neighbors of each node. The after effect of this estimation is known as degree of a node n (dn). For balancing the load, the degree contrast Δn is computed like- |dn - δ | for every node n, where δ is a pre-characterized edge esteem. Dn is the complete aggregate some of good ways from a node to all its neighboring nodes. Pn is the time, spended by a node being as a clusterhead. Pn is a consumption of battery power has been devoured by a node. The clusterhead race strategy completes when every one of the node become either a clusterhead or a member node of any clusterhead [18].
S. Weight based adaptive clustering algorithm
(WBACA)
this approach of WBACA depends on the accessibility of position data given by Global Positioning System (GPS). This approach considers some parameters for electing a node as clusterhead. These parameters are transmission control, transmission rate, mobility, degree of node and battery power. Every node is appointed by a weight which demonstrates its capacity for playing clusterhead job. The node having littlest weight is chosen as the clusterhead. The total weight of a node „N‟ is calculated by following equation:
2230 Where wl, w2, w3, w4.Andw5 are the weight factors, which
corresponds to the accompanying framework parameters: - M denotes node‟s Mobility, Tx indicates Transmission power, B denotes Battery power, D denotes difference in Degree, and T denotes rate of Transmission. Further This calculation don't permit two clusterheads to be one-bounce away of one another. A node called gateway node connects overlapping clusters and all other ordinary nodes are at one hop away from their clusterheads [19].
3.
CONCLUSIONS
In this paper, we have contemplated various clustering approaches, by which mobile ad-hoc network can be composed in a various leveled way, and presents their principle qualities. These clustering algorithms mostly focus on various issues like network lifetime, cluster stability, energy utilization of mobile node and support of cluster. Among every one of the algorithms written above, joined metrics based clustering approach is good because it gives the higher stability and minimum number of cluster.
REFERENCES
[1] Gerla, Mario, and Jack Tzu-Chieh Tsai. "Multicluster, mobile, multimedia radio network." Wireless networks 1, no. 3 (1995): 255-265.
[2] Amis, Alan D., Ravi Prakash, Thai HP Vuong, and Dung T. Huynh. "Max-min d-cluster formation in wireless ad hoc networks." In Proceedings IEEE INFOCOM 2000. Conference on Computer Communications. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No. 00CH37064), vol. 1, pp. 32-41. IEEE, 2000.
[3] Li, Fei, Shile Zhang, Xin Wang, Xiangyang Xue, and Hong Shen. "Vote-based clustering algorithm in mobile ad hoc networks." In International Conference on Information Networking, pp. 13-23. Springer, Berlin, Heidelberg, 2004.
[4] Ohta, Tomoyuki, Shinji Inoue, and Yoshiaki Kakuda. "An adaptive multihop clustering scheme for highly mobile ad hoc networks." In The Sixth International Symposium on Autonomous Decentralized Systems, 2003. ISADS 2003., pp. 293-300. IEEE, 2003.
[5] Agarwal Ratish, and Dr Motwani. "Survey of clustering algorithms for MANET." arXiv preprint arXiv:0912.2303 (2009)
[6] Nocetti, Fabian Garcia, Julio Solano Gonzalez, and Ivan Stojmenovic. "Connectivity based k-hop clustering in wireless networks." Telecommunication systems 22, no. 1-4 (2003): 205-220.
[7] Basu, Prithwish, Naved Khan, and Thomas DC Little. "A mobility based metric for clustering in mobile ad hoc networks." In Proceedings 21st International Conference on Distributed Computing Systems Workshops, pp. 413-418. IEEE, 2001.
[8] Er, Inn Inn, and Winston Khoon Guan Seah. "Mobility-based d-hop clustering algorithm for mobile ad hoc networks." In 2004 IEEE Wireless Communications and Networking Conference (IEEE Cat. No. 04TH8733), vol. 4, pp. 2359-2364. IEEE, 2004.
[9] Ni, Minming, Zhangdui Zhong, and Dongmei Zhao. "MPBC: A mobility prediction-based clustering scheme for ad hoc networks." IEEE Transactions on Vehicular Technology 60, no. 9 (2011): 4549-4559.
[10] Kumar, T., R. Muthu Kumar, and N. Shanthi. "Review of Mobility Aware Clustering Scheme in Mobile Adhoc Network." In International Conference on Research Trends in Computer Technologies (ICRTCT-2013), pp. 19-24. 2013.
[11] Chiang, Ching-Chuan, Hsiao-Kuang Wu, Winston Liu, and Mario Gerla. "Routing in clustered multihop, mobile wireless networks with fading channel." In proceedings of IEEE SICON, vol. 97, no. 1997, pp. 197-211. 1997. [12] Yu, J. Y., and Peter HJ Chong. "3hbac (3-hop between adjacent clusterheads):
a novel non-overlapping clustering algorithm for mobile ad hoc networks." In 2003 IEEE Pacific Rim Conference on Communications Computers and
Signal Processing (PACRIM 2003)(Cat. No. 03CH37490), vol. 1, pp. 318-321. IEEE, 2003.
[13] Kwon, Taek Jin, Mario Gerla, Vijay K. Varma, Melbourne Barton, and T. Russell Hsing. "Efficient flooding with passive clustering-an overhead-free selective forward mechanism for ad hoc/sensor networks." Proceedings of the IEEE 91, no. 8 (2003): 1210-1220.
[14] Hussein, AbdulRahman H., Amer O. Abu Salem, and Sufian Yousef. "A flexible weighted clustering algorithm based on battery power for mobile ad hoc networks." In 2008 IEEE international symposium on industrial electronics, pp. 2102-2107. IEEE, 2008.
[15] Alinci, Mirjeta, Evjola Spaho, Algenti Lala, and Vladi Kolici. "Clustering algorithms in MANETs: a review." In 2015 Ninth International Conference on Complex, Intelligent, and Software Intensive Systems, pp. 330-335. IEEE, 2015.
[16] Wu, Jie, Fei Dai, Ming Gao, and Ivan Stojmenovic. "On calculating power-aware connected dominating sets for efficient routing in ad hoc wireless networks." Journal of communications and networks 4, no. 1 (2002): 59-70. [17] El-Bazzal, Zouhair, Michel Kadoch, Basile L. Agba, Francois Gagnon, and
Maria Bennani. "A flexible weight based clustering algorithm in mobile ad hoc networks." In 2006 International Conference on Systems and Networks Communications (ICSNC'06), pp. 50-50. IEEE, 2006.
[18] Chatterjee, Mainak, Sajal K. Das, and Damla Turgut. "An on-demand weighted clustering algorithm (WCA) for ad hoc networks." In Globecom'00-IEEE. Global Telecommunications Conference. Conference Record (Cat. No. 00CH37137), vol. 3, pp. 1697-1701. IEEE, 2000.