An Efficient Retargetable Simulator SIM A for ASIP DSE and Validation with RISC and VLIW based Processors
Full text
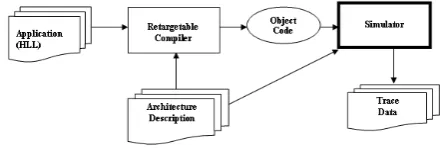
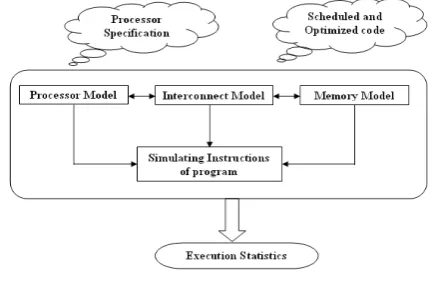
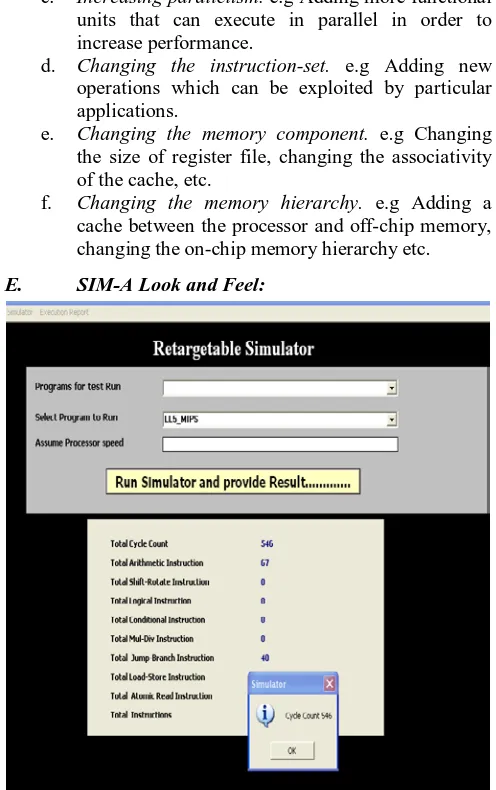
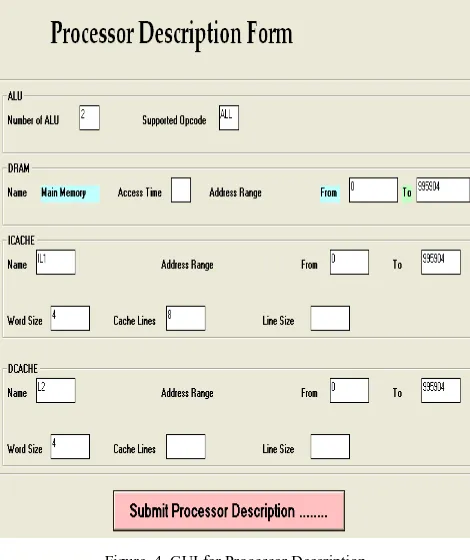
Figure

Related documents
between rainfall patterns and the spatial distribution of mangrove forests at study sites in 16.. Moreton Bay, southeast Queensland, Australia, over a 32-year period from 1972
If breastfeeding by itself doesn’t effectively remove the thickened inspissated milk, then manual expression of the milk, or the use of an efficient breast pump after feeds will
Planning for the 1999 Iowa Oral Health Survey began in the spring of 1999 and included personnel from the Dental Health Bureau of the Iowa Department of Public Health,
Linkedin profiles for free, of one ought to need an email address on any Linkedin account there just one click the find an email address in the Linkedin search results.. How to
[r]
Your signature indicates that you have discussed the above statements with your parents, understand the commitment you are endeavoring to make, and agree to the policies set forth
Please make sure to choose S - Study unless advised to choose otherwise. who are nominated for the Autumn and Spring semesters) will have to submit another application for
• AutoGOJA™ online job analysis system • TVAP™ test validation & analysis program • CritiCall™ pre-employment testing for 911 operators • OPAC™ pre-employment testing
