Network Oriented Junk Data Discovery for Digital Media Reviews
Narasimhulu K & Dr. Naimullah Khan
1Research scholar, Dept of CSE, Aligarh Muslim University
2Professor, Dept of CSE (R&D), Aligarh Muslim University
ABSTRACT: Nowadays, a massive part of
people depend upon available content
material cloth in social media in their
decisions. The opportunity that truly
everyone can depart an evaluation presents
a golden opportunity for spammers to jot
down unsolicited mail evaluations
approximately products and services for
specific interests. Identifying those
spammers and the spam content is a hot
subject matter of research and although a
large variety of research have been
completed presently within the course of this
end, but so far the methodologies positioned
forth despite the fact that slightly stumble on
direct mail reviews, and none of them show
the importance of each extracted feature
type. In this take a look at, we endorse a
completely unique framework, named
NetSpam, which makes use of junk mail
functions for modeling compare datasets as
heterogeneous information networks to map
unsolicited mail detection technique proper
into a category trouble in such networks.
Using the significance of spam functions
assist us to attain better outcomes in terms
of diverse metrics experimented on
actual-international overview datasets from Yelp
and Amazon web sites. The results display
that NetSpam outperforms the existing
strategies and amongst four lessons of
capabilities; alongside
assessment-behavioral, character-behavioral,
evaluation linguistic, man or
woman-linguistic, the primary sort of functions
plays higher than the alternative classes.
Key Terms: Social Media, Social Network,
Spammer, Spam Review, Fake Review,
Heterogeneous Information Networks.
INTRODUCTION
Online Social Media portals play an
influential position in data propagation that
is taken into consideration as an essential
supply for producers in their marketing
campaigns similarly to for customers in
choosing services and products. In the past
years, humans rely masses at the written
techniques, and advantageous/poor opinions
encouraging/discouraging them of their
preference of services and products. In
addition, written critiques additionally help
company carriers to enhance the great of
their products and services. These
evaluations therefore have come to be an
essential factor in fulfillment of a
commercial employer at the equal time as
first rate critiques can carry advantages for a
corporation, terrible evaluations can
possibly effect credibility and reason
economic losses. The reality that all of us
with any identification can go away
feedback as assessment, presents a tempting
opportunity for spammers to install writing
fake reviews designed to lie to customers’
opinion. These deceptive reviews are then
prolonged thru the sharing characteristic of
social media and propagation over the net.
The opinions written to change customers’
notion of the way accurate a product or a
carrier are taken into consideration as
unsolicited mail and are frequently written
in change for money As shown in [1], 20%
of the opinions in the Yelp internet site are
absolutely junk mail reviews. On the
opposite hand, a considerable amount of
literature has been published at the strategies
used to pick out junk mail and spammers in
addition to unique form of evaluation on this
problem be counted. These techniques may
be categorized into special classes; some
using linguistic patterns in text which might
be generally based totally on bigram, and
unigram, others are based on behavioral
styles that depend on functions extracted
from styles in customers’ behavior which
might be in most cases metadata primarily
based or maybe a few strategies using
graphs and graph-based algorithms and
classifiers. Despite this incredible deal of
efforts, many factors were neglected or
remained unsolved. One of them is a
classifier which could calculate function
weights that show every function’s level of
importance in figuring out unsolicited mail
opinions. The fashionable concept of our
proposed framework is to version a given
evaluation dataset as a Heterogeneous
Information Network and to map the
problem of junk mail detection into a HIN
magnificence hassle. In specific, we model
assessment dataset as a HIN in which
reviews are associated via awesome node
kinds (along with skills and customers). A
weighting set of rules is then employed to
calculate every function’s importance (or
weight). These weights are applied to
usage of every unsupervised and supervised
processes. To look at the proposed answer,
we used sample evaluate datasets from Yelp
and Amazon web sites. Based on our
observations, defining perspectives for
features (review-customer and
behavioral-linguistic), the categorized functions as
evaluate behavioral have more weights and
yield higher performance on spotting direct
mail reviews in both semi-supervised and
unsupervised strategies. In addition, we
showcase that the usage of special
supervisions which encompass 1%, 2.5%
and 5% or the use of an unmanaged method,
make no extraordinary model at the overall
performance of our method. We determined
that function weights can be introduced or
eliminated for labeling and as an end result
time complexity may be scaled for a
particular degree of accuracy. As the result
of this weighting step, we are able to use
fewer abilities with more weights to gather
better accuracy with less time complexity. In
addition, categorizing functions in 4
principal training (compare-behavioral,
client-behavioral, evaluation linguistic,
customer-linguistic), permits us to
apprehend how a good buy every category
of abilities is contributed to unsolicited mail
detection.
I. RELATED WORK
In the remaining decade, a tremendous
variety of studies recognition on the trouble
of recognizing spammers and unsolicited
mail evaluations. However, since the hassle
is non-trivial and challenging, it stays far
from completely solved. We can summarize
our discussion about preceding research in 3
following categories
Linguistic-based Methods: This technique
extracts linguistic-based totally features to
find unsolicited mail critiques. Feng et al use
unigram, bigram and their composition.
Other studies use different capabilities like
pair wise capabilities (competencies among
two opinions; e.g. Content similarity),
percentage of CAPITAL terms in critiques
for finding junk mail critiques. Lai et al use
a probabilistic language modeling to spot
junk mail. This examine demonstrates that
2% of evaluations written on industrial
enterprise web sites are genuinely
unsolicited mail.
Behavior-based Methods: Approaches on
this group almost use reviews metadata to
extract capabilities; those which is probably
ordinary sample of a reviewer behaviors.
Feng et al consciousness on distribution of
spammers scores on distinctive products and
behavioral features and uses a supervised
technique to discover spammers on Amazon
and indicates behavioral features show
spammers’ identity higher than linguistic
ones. Xue et al use charge deviation of a
specific person and use a consider-aware
version to find the connection amongst
customers for calculating very last spamicity
score. Minnich et al use temporal and area
skills of customers to discover unusual
conduct of spammers. Li et al use some
fundamental functions (e.g. polarity of
reviews) and then run a HNC
(Heterogeneous Network Classifier) to find
out very last labels on Dianpings dataset.
Mukherjee et al almost engage behavioral
features like rate deviation, extremity and so
on. Xie et al additionally use a temporal
pattern (time window) to discover singleton
evaluations (opinions written just as quickly
as) on Amazon. Luca et al use behavioral
skills to expose growing competition
between agency’s results in very large
enlargement of junk mail reviews on
products.
Crawford et al shows using specific
magnificence approach want distinct range
of capabilities to achieve preferred overall
performance and propose techniques which
use fewer competencies to achieve that
overall performance and therefore endorse
to enhance their usual performance at the
same time as they use fewer capabilities
which leads them to have better complexity.
With this perspective our framework is
arguable. This study suggests using fantastic
methods in kind yield first rate overall
performance in terms of diverse metrics.
II. TECHNOLOGY
IMPLEMENTED
Existing system strategies can be
categorized into one of a kind classes; some
the usage of linguistic patterns in textual
content that are commonly based on bigram,
and unigram, others are based on behavioral
patterns that rely on features extracted from
patterns in users’ conduct which might be
within the most important meta data
primarily based totally or maybe some
techniques the usage of graphs and
graph-primarily based definitely algorithms and
classifiers. Existing device can be
summarized into 3 categories:
Linguistic-based definitely Methods,
Behavior-primarily based Methods and
Graph-primarily based Methods. Feng et al. Use
unigram, bigram and their composition.
Other research uses other functions like pair
wise features (capabilities among reviews;
CAPITAL phrases in opinions for finding
unsolicited mail critiques. Lai et al. used a
probabilistic language modeling to identify
spam. This take a look at demonstrates that
2% of opinions written on commercial
organization web sites are certainly junk
mail. Deeper analysis on literature display
that behavioral features work higher than
linguistic ones in term of accuracy they
yield.
Some of issues in the implemented
generation are indexed underneath
The fact that anyone with any identity can leave comments as
review provides a tempting
opportunity for spammers to write
fake reviews designed to mislead
users’ opinion. These misleading
reviews are then multiplied by the
sharing function of social media and
propagation over the web.
Many aspects have been missed or
remained unsolved.
Previous works also aimed to address
the importance of features mainly in
term of obtained accuracy, but not as
a build-in function in their
framework (i.e., their approach is
dependent to ground truth for
determining each feature
importance).
III. PROPOSED TECHNOLOGY
The fashionable idea of our proposed
framework is to model a given examine
dataset as a Heterogeneous Information
Network (HIN) and to map the problem of
unsolicited mail detection right into a HIN
class trouble. In specific, we version
evaluate dataset as a HIN in which reviews
are related through specific node kinds
(consisting of features and customers). A
weighting set of rules is then hired to
calculate every function’s importance (or
weight). These weights are utilized to
calculate the final labels for opinions the
usage of both unsupervised and supervised
techniques. We endorse NetSpam
framework that could be a novel network
primarily based absolutely technique which
fashions evaluate networks as heterogeneous
information networks. The classification
step makes use of extraordinary metapath
kinds which might be contemporary in the
unsolicited mail detection area. A new
weighting approach for direct mail functions
is proposed to determine the relative
importance of every function and indicates
identifying spams from ordinary opinions.
NetSpam improves the accuracy compared
to the state of art work in terms of time
complexity, which surprisingly relies upon
to the type of features used to come to be
privy to a junk mail evaluation; as a end
result, using capabilities with more weights
will caused detecting fake reviews less
difficult with much less time complexity.
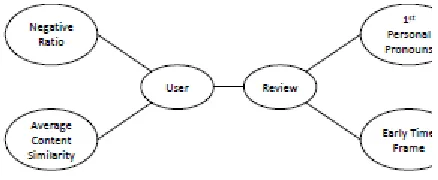
Fig 1: Example for Network Schema
Network Schema Definition: The next step
is defining network schema based totally on
a given listing of spam capabilities which
determines the features engaged in spam
detection. This Schema is standard
definitions of metapaths and show in general
how specific network components are
linked. For instance, if the list of functions
consists of NR, ACS, PP1 and ETF, the
output schema is as supplied in Fig 1.
Metapath Definition and Creation: As
mentioned in Section II-A, a metapath is
defined via a chain of members of the family
within the network schema. Table II
indicates all the metapaths used within the
proposed framework. As proven, the period
of person-based metapaths is 4 and the
duration of review based metapaths is two.
For metapath creation, we define an
extended version of the metapath concept
thinking about one-of-a-kind degrees of junk
mail fact. In particular, two opinions are
connected to every other if they share equal
fee. Hassanzadeh et al recommend a
fuzzy-primarily based framework and indicate for
spam detection, its miles better to apply
fuzzy good judgment for determining an
assessment’s label as spam or non-junk
mail. Indeed, there are exclusive tiers of
junk mail certainty. We use a step
characteristic to determine those levels. In
specific, given an assessment u, the stages of
junk mail fact for metapath Pl (i.e., function
l) is calculated as mpl u = bs_f (xlu) c s,
wherein s denotes the variety of degrees.
After computing mpl u for all reviews and
metapaths, critiques u and v with the same
metapath values (i.e., mpl u = mpl v) for
metapath Pl are connected to every different
through that metapath and create one link of
review network. The metapath fee among
The class a part of NetSpam includes steps;
(i) weight calculation which determines the
importance of every spam characteristic in
recognizing junk mail opinions, (ii) Labeling
which calculates the very last possibility of
each assessment being unsolicited mail.
RESULTS:
In this section, we compare NetSpam from
one of a kind attitude and evaluate it with
two other processes, Random approach and
SPeaglePlus. To examine with the primary
one, we've got evolved a network in which
opinions are related to each other randomly.
Second technique use a well known
graph-primarily based set of rules referred to as
“LBP” to calculate final labels. Our
observations display NetSpam, outperforms
those present methods. Then evaluation on
our remark is accomplished and finally we
are able to take a look at our framework in
unsupervised mode. Lastly, we inspect time
complexity of the proposed framework and
the effect of camouflage method on its
performance.
Accuracy: Above sections present the
overall performance in phrases of the AP
and AUC. As it’s proven in all of the 4
datasets NetSpam outperforms SPeaglePlus
specially whilst variety of functions growth.
In addition exceptional supervisions haven't
any massive effect at the metric values
Results additionally show the datasets with
higher percentage of spam critiques have
better overall performance due to the fact
when fraction of junk mail reviews in a sure
dataset will increase, probability for a
overview to be a spam assessment will
increase and as a result greater spam
evaluations could be categorized as junk
mail opinions and within the end result of
AP measure which is particularly dependent
on junk mail percentage in a dataset. On the
opposite hand, AUC measure does now not
fluctuate too much, because this metric isn't
always depending on junk mail evaluations
percentage in dataset, but at the very last
sorted list which is calculated based at the
very last junk mail opportunity.
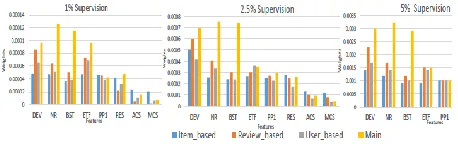
Fig 2: Features weights for NetSpam framework
on different datasets using different supervisions
Feature Weights Analysis: Next we
discuss about features weights and their
involvement to determine spamicity. First
we inspect how much AP and AUC are
dependent on variable number of features.
Then we show these metrics are different for
the four feature types explained before (RB,
UB, RL and UL). To show how much our
work on weights calculation is effective,
first we have simulated framework on
several run with whole features and used
most weighted features to find out best
combination which gives us the best results.
Fig. 3: Regression graph of features vs. accuracy (unsupervised) for Main dataset.
The Impact of Camouflage Strategy: One
of the challenges that direct mail detection
techniques face is that spammers regularly
write non-direct mail reviews to cover their
real identity referred to as camouflage. For
example they write advantageous opinions
for correct restaurant or horrific evaluations
for low-pleasant ones; ultimately each junk
mail detector system fails to select out this
kind of spammers or at least has some
problem to identify them. In the previous
research, there is one of kind strategies for
managing this trouble. For instance the
possibility that a wonderful overview
written by using way of a spammer and
placed this assumption in its compatibility
matrix. In this look at, we tried to deal with
this problem by way of way of the usage of
weighted metapaths. In unique, we
anticipate that regardless of the reality that
an evaluation has a totally little cost for a
positive characteristic, it's far taken into
consideration in feature weights calculation.
Therefore, instead of thinking about
metapaths as binary standards, we take 20
values which denoted as s. Indeed, if there's
a camouflage its affection might be reduced.
As we defined in Section III-C in such
issues it is better to recommend a fuzzy
framework, in preference to the use of
bipolar values (zero; 1).
IV. CONCLUSION AND
FUTURE WORK
This study introduces a novel spam
detection framework namely NetSpam based
on a metapath concept as well as a new
graph-based method to label reviews relying
on a rank-based labeling approach. The
performance of the proposed framework is
evaluated by using two real-world labeled
datasets of Yelp and Amazon websites. Our
observations show that calculated weights
by using this metapath concept can be very
effective in identifying spam reviews and
leads to a better performance. In addition,
we found that even without a train set,
NetSpam can calculate the importance of
each feature and it yields better performance
in the features’ addition process, and
performs better than previous works, with
only a small number of features. Moreover,
after defining four main categories for
features our observations show that the
reviews behavioral category performs better
than other categories, in terms of AP, AUC
as well as in the calculated weights. The
results also confirm that using different
supervisions, similar to the semi-supervised
method, have no noticeable effect on
determining most of the weighted features,
just as in different datasets. For future work,
metapath concept can be applied to other
problems in this field. For example, similar
framework can be used to find spammer
communities. For finding community,
reviews can be connected through group
spammer features and reviews with highest
similarity based on metapth concept are
known as communities. In addition, utilizing
the product features is an interesting future
related to spotting spammers and spam
reviews. Moreover, while single network
has received considerable attention from
various disciplines for over a decade,
information diffusion and content sharing in
multilayer networks is still a young research.
Addressing the problem of spam detection in
such networks can be considered as a new
research line in this field.
V. REFERENCES
[1]. G. Wang, S. Xie, B. Liu, and P. S.
Yu. Review graph based online store review
spammer detection. IEEE ICDM, 2011.
[2]. Y. Sun and J. Han. Mining
Heterogeneous Information Networks;
Principles and Methodologies, In ICCCE,
2012.
[3]. A Mukerjee, V. Venkataraman, B.
Liu, and N. Glance. What Yelp Fake Review
Filter Might Be Doing?, In ICWSM, 2013.
[4]. S. Feng, L. Xing, A. Gogar, and Y.
Choi. Distributional footprints of deceptive
product reviews. In ICWSM, 2012.
[5]. Y. Sun, J. Han, X. Yan, P. S. Yu, and
T. Wu. Pathsim: Meta path-based top-k
similarity search in heterogeneous
information networks. In VLDB, 2011.
[6]. Y. Sun and J. Han. Rankclus:
integrating clustering with ranking for
heterogeneous information network analysis.
In Proceedings of the 12th International
Conference on Extending Database
Technology: Advances in Database
Technology, 2009.
[7]. C. Luo, R. Guan, Z. Wang, and C.
Lin. HetPathMine: A Novel Transductive
Classification Algorithm on Heterogeneous
Information Networks. In ECIR, 2014.
[8]. R. Hassanzadeh. Anomaly Detection
in Online Social Networks: Using Data
mining Techniques and Fuzzy Logic.
Queensland University of Technology, Nov.
2014.
[9]. M. Luca and G. Zervas. Fake It Till
You Make It: Reputation, Competition, and
Yelp Review Fraud., SSRN Electronic
Journal, 2016.
[10]. E. D. Wahyuni and A. Djunaidy.
Fake Review Detection from a Product
Review Using Modified Method of Iterative
Computation Framework. In Proceeding
MATEC Web of Conferences. 2016.
[11]. M. Crawford, T. M. Khoshgoftaar,
and J. D. Prusa. Reducing Feature set
Explosion to Facilitate Real-World Review
Sapm Detection. In Proceeding of 29th
International Florida Artificial Intelligence
Research Society Conference. 2016.
[12]. N. Jindal and B. Liu. Opinion spam
[13]. F. Li, M. Huang, Y. Yang, and X.
Zhu. Learning to identify review spam.
Proceedings of the 22nd International Joint
Conference on Artificial Intelligence; IJCAI,
2011.
[14]. G. Fei, A. Mukherjee, B. Liu, M.
Hsu, M. Castellanos, and R. Ghosh.
Exploiting burstiness in reviews for review
spammer detection. In ICWSM, 2013.
[15]. A. j. Minnich, N. Chavoshi, A.
Mueen, S. Luan, and M. Faloutsos.
Trueview: Harnessing the power of multiple
review sites. In ACM WWW, 2015.
[16]. A Viswanath, M. Ahmad Bashir, M.
Crovella, S. Guah, K. P. Gummadi, B.
Krishnamurthy, and A. Mislove. Towards
detecting anomalous user behavior in online
social networks.
[17]. H. Li, Z. Chen, B. Liu, X. Wei, and
J. Shao. Spotting fake reviews via collective