International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2018 IJSRCSEIT | Volume 3 | Issue 1 | ISSN : 2456-3307
Novel BCC Method to Improve the Classification Performance in
Sparsely Labeled Networks
A. Anusha Nagalakshmi
1, Dr. R. Murugadoss
21PG Scholar, Department of MCA, St .Anns College of Engineering & Technology, Chirala, Andhra Pradesh,
India
2Professor, Department of MCA, St .Ann’s College of Engineering & Technology, Chirala, Andhra Pradesh,
India
ABSTRACT
Consider order of email messages with respect to regardless of whether they contain certain “email acts”, for example, a demand or a dedication. Demonstrate that abusing the successive relationship among email messages in a similar string can enhance email-act grouping. All the more particularly, portray another content order algorithm in light of a reliance organize based aggregate arrangement technique, in which the local classifiers are most extreme entropy models in view of words and certain social highlights. In this demonstrate that factually critical upgrades over a pack of-words pattern classifier can be acquired for a few, however not all, email-act classes. Performance changes acquired by aggregate arrangement seem, by all accounts, to be predictable crosswise over many email acts proposed by earlier speech act hypothesis.
Keywords : Text Classification, Speech Acts, Email Management, Machine Learning, Collective Classification.
I.
INTRODUCTION
One critical utilization of business related email is arranging and assigning shared undertakings and subtasks. To give astute computerized help to this utilization of email, it is attractive to have the capacity to consequently identify the reason for an email message for instance, to decide whether the email contains a demand, a dedication by the sender to play out some undertaking, or an alteration to a prior proposition. In a past work, we displayed test comes about on utilizing content grouping techniques to recognize such "speech acts" in email. In view of speculations of speech acts, and guided by investigation of a few email corpora, we characterized an arrangement of "email verbs" (e.g., Request, Deliver, Propose, Commit) and considered the issue of grouping messages with respect to regardless of whether they contain a particular verb.
Along these lines every verb turns into a paired content arrangement issue. (Note however that an email may contain a few verbs, so the parallel classes are not totally unrelated.) We likewise characterized an arrangement of "email noun", which are the objects of these verbs (for example one may Request Data, an Opinion, or an Activity), which were dealt with similarly. In our past work, messages were
grouped utilizing conventional content
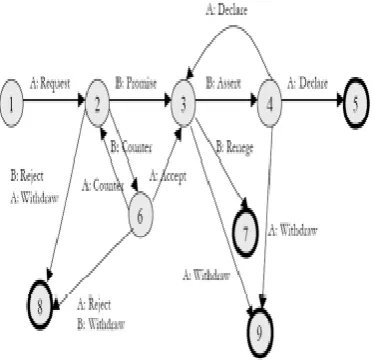
intrinsically successive, one would expect solid consecutive relationship in the "email-acts" related with a string of undertaking related email messages, and one may trust that abusing this consecutive connection among email messages in a similar string would enhance email-act characterization. The consecutive parts of business related collaborations and transactions have been examined by numerous past scientists. For instance, Winograd and Flores proposed the exceptionally powerful thought of activity arranged discussions in view of a specific scientific classification of linguistic acts; an outline of one of their structures can be seen in Figure1.
Fig 1: Diagram of a "Discussion for Action" Structure from Winograd and Flores.
We first demonstrate that successive connections do exist; further, that they can be encoded as "social highlights", and used to foresee the goal of email messages without utilizing printed highlights. We at that point consolidate these social highlights with literary highlights, utilizing an iterative aggregate characterization strategy. We demonstrate that this strategy creates a steady change on a few, yet not all, email acts.
II.
“EMAIL-ACTS” TAXONOMY AND
APPLICATIONS
Shaded nodess are the ones for which a classifier was built. A scientific categorization of speech acts connected to email correspondence (email-acts) has been depicted and spurred somewhere else.
As noted over, the scientific categorization was partitioned into verbs and noun, and each email message is spoken to by at least one verb-thing sets: for instance, an email proposing a gathering would have the names Propose, Meeting. The pertinent piece of the scientific classification is appeared in Fig 2. Briefly, a Request requests that the beneficiary play out some action; a Propose message proposes a joint movement (i.e., requests that the beneficiary play out some action and confers the sender); a Commit message commits the sender to some future strategy; Data is data, or a pointer to data, conveyed to the beneficiary; and a Meeting is a joint action that is obliged in time and (for the most part) space.
Fig 2: Taxonomy of email-acts utilized as a part of trials.
the vicinity of 0.72 and 0.85 were gotten. The Kappa measurement is normally used to quantify the human between rater understanding. Its esteems ranges from - 1 (finish contradiction) to +1 (consummate assertion) and it is characterized as (A-R)/(1-R), where A is the experimental likelihood of concurrence on a class, and R is the likelihood of understanding for two annotators that name records aimlessly (with the exactly watched recurrence of each name). Mistake rate is a poor measure of performance for skewed classes, since low blunder rates can be gotten by basically speculating the greater part class. Kappa controls for this, since in a profoundly a skewed class, haphazardly speculating classes as per the recurrence of each class is fundamentally the same as continually speculating the lion's share class; consequently R in the equation will be near 1.0. Exactly, Kappa estimations on our datasets are typically firmly connected to the all the more broadly utilized F1-measure. A strategy for precise order of email into such classes would have numerous potential applications. For example, it could be utilized to enable an email client to track the status of
continuous joint exercises. Designation and
coordination of joint undertakings is a tedious and blunder inclined action, and the cost of mistakes is high: it isn't unprecedented that duties are overlooked, due dates are missed, and openings are squandered on account of an inability to appropriately track, assign, and organize subtasks. We accept such arrangement strategies which could be utilized to in part mechanize this kind of email movement following, in the sender's email customer and in the recipient's.
III.
THE CORPUS
In spite of the fact that email is pervasive, huge and sensible email corpora are once in a while accessible for examine purposes because of protection contemplations. The CSpace email corpus utilized as a part of this paper contains around 15,000 email messages gathered from an administration course at Carnegie Mellon University. The email utilized as a part of our tests began from working gatherings that
consented to arrangements to make certain parts of their email open to scientists. In this course, 277 MBA understudies, composed in around 50 groups of four to six individuals, ran reproduced organizations in various market situations over a 14-week time frame. The email has a tendency to be exceptionally errand situated, with many cases of undertaking appointment and arrangement. Messages were for the most part traded with individuals from a similar group. In like manner, we parceled the corpus into subsets as indicated by the groups for huge numbers of the examinations. The 1F3 group dataset has 351 messages add up to, while the 2F2 group has 341, and the 3F2 group has 443. In our analyses, we considered just the subset of messages that were in strings (as characterized by the answer to field of the email message), which lessened our genuine dataset to 249 messages from 3F2, 170 from 1F3, and 137 from 2F2. All the more exactly, all messages in the first CSpace database of observed email messages contained a parentID field, demonstrating the personality of the message to which the present one is an answer. Utilizing this data, we created a rundown of children messages (or messages produced in-answer to this one) to each message. A string subsequently comprises of a root message and every descendent message, and when all is said in done has the type of a tree, as opposed to a straight arrangement. In any case, most of the strings are short, containing 2 or 3 messages, and most messages have at most one kid. Contrasted with regular datasets utilized as a part of the social learning writing, for example, IMBd, WebKB or Cora, our dataset has a significantly littler measure of linkage. A message is connected just to its youngsters and its parent, and there are no connections between two unique strings, or among messages having a place with various strings.
IV.
EVIDENCE FOR SEQUENTIAL
CORRELATION OF EMAIL ACTS
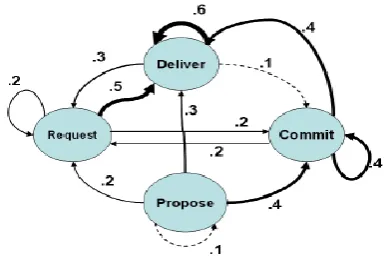
message, and the acts related with its children. The change chart in Figure 3 was gotten by processing, for the four most incessant verbs, the likelihood of the following message's email-act given the present message's act over every one of the four datasets. At the end of the day, a circular segment from A to B with mark p shows that p is the likelihood over all messages M that some offspring of M has name B, given than M has name A. Notice that an email message may have at least one email-acts related with it. A Request, for example, might be trailed by a message that contains a Deliver and furthermore a Commit. In this manner, the change outline in Figure 3 isn't a probabilistic DFA.
Fig 3: Transition Diagram for the four most basic particular verbs.
Convey and Request is the most successive acts, and they are additionally firmly coupled. Maybe because of the nonconcurrent idea of email and the generally high recurrence of Deliver, there is an inclination for nearly anything to be trailed by a Deliver message; in any case, Deliver is particularly basic after Request or another Deliver. Interestingly, a Commit is most likely after a Propose or another Commit, which concurs with natural and hypothetical thoughts of a transaction grouping. (Review that an email string may include a few people in a movement, every one of whom may need to focus on a joint activity.) A Propose is probably not going to tail anything, as they generally start a string. Roughly one can see the diagram above as epitomizing three likely kinds of verb arrangements, which could be depicted with the general articulations (Request, Deliver+), (Propose, Commit+, Deliver+), and (Propose, Deliver+).
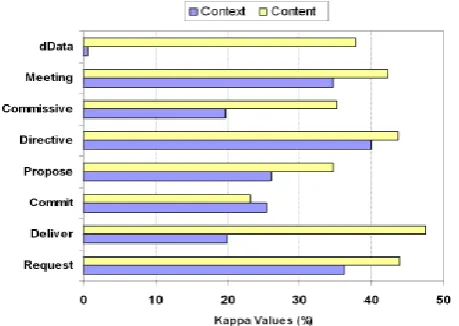
Fig 4: Kappa Values on 1F3 utilizing Relational (Context) highlights and Textual (Content) highlights.
V.
ITERATIVE CLASSIFICATION
5.1 The Algorithm :
To build a for all intents
and purposes helpful classifier that joins the
social "context" highlights with the printed
"content" highlights utilized as a part of
customary pack of-words content arrangement,
it is important to break the cyclic reliance
between the email acts in a message and the
email acts in its parent and youngsters
messages. Such a plan can not characterize each
message autonomously: rather classes must be
all the while allotted to all messages in a string.
Such aggregate order strategies, connected to
socially connected accumulations of information,
have been a dynamic territory of research for
quite a long while, and a few plans have been
proposed. For example, utilizing an iterative
method on a page dataset, Chakrabarti et al.
accomplished noteworthy enhancements in
performance looked at a non-social standard;
likewise, in a dataset of corporate data, Neville
and Jensen utilized an iterative order algorithm
that updates the test set inductions in view of
classifier certainty. Outlines of late social
characterization papers can be discovered
somewhere else. The plan we utilize is directed
by the attributes of the issue. Each message has
different twofold marks to allot, which are all
possibly interrelated. Further, despite the fact
that in the present paper we consider just
parent-youngster relations inferred by the
answer to handle, the social associations
between messages are possibly very rich for
instance, it may be conceivable to build up
associations between messages in view of
interpersonal organization associations between
beneficiaries too. We hence embraced a
genuinely effective model, in light of iteratively
re-allotting
email-act
names
through
a
procedure of measurable unwinding. At first, we
prepare eight greatest entropy classifiers (one
for each act) from a preparation set. The
highlights utilized for preparing are the words
on the email body, the words in the email
subject, and the social highlights recorded in
Table 1. These eight classifiers will be alluded to
as nearby classifiers.
The deduction technique used to appoint
email-act mark with these classifiers is as per the
following. We start by instating the eight classes
of each message arbitrarily (or as per some
other heuristic, as point by point underneath).
It mirrors the greatest pick up that could be conceded by utilizing the social highlights; consequently, it gives as an "upper bound" of what we ought to
anticipate from the iterative algorithm.
Notwithstanding Kappa, we report the all the more generally utilized F1 measurement. We likewise give the change in Kappa over the standard pack of-words technique, where it is important. For the Deliver act, this "upper bound" is negative: as it were, the nearness of the social highlights corrupts the performance of the pack of-words most extreme entropy classifier, notwithstanding when one accept the classes of every single other message in a string are known. The third piece of Table 3 shows the performance of the framework if the test set utilized the assessed marks (rather than the genuine names). Identically, it speaks to the performance of the iterative algorithm on its first emphasis. The furthest right piece of Table 3 demonstrates the performance acquired toward the finish of the iterative strategy. For each act, Kappa enhances because of following the iterative methodology. With respect to the sack of-words standard, Kappa is enhanced for everything except two acts, Deliver (which is again debased in performance) and Propose (which is basically unaltered.) The most elevated performance picks up are for Commit and Commissive.
5.3 Leave-one-team-out Experiments: In the initial trials, 3F2 was utilized as the preparation set, and 1F3 was the test set. As an extra test, marked information
for a fourth group, 4F4 group, which had 403 aggregate messages and 165 strung messages. We at that point performed four extra examinations in which information from three groups was utilized as a part of preparing, and information from the fourth group was utilized for testing. It ought to be stressed that the decision to test on email from a group not found in preparing makes the forecast issue more troublesome.
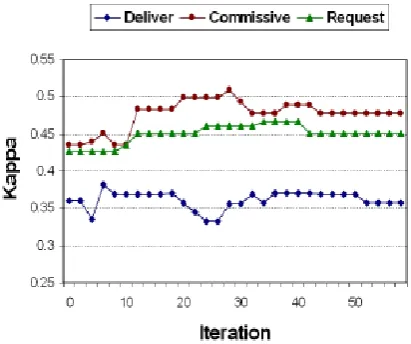
Fig 5: Kappa versus iteration on 1F3, using classifier strained on 3F2.
was gathered after all algorithm advancement was finished. In this way performance on 4F4 is an
imminent trial of the strategy. Encourage
examination proposes that the varieties in performance of the iterative plan are resolved generally by the particular email act included. Commissive, Commit, and Meet were enhanced most in the preparatory examinations, and Proposal and Deliver were enhanced minimum. The chart of Figure 7 demonstrates that the Commissive, Commit, and Meet are reliably enhanced by aggregate grouping strategies in the imminent tests also.
Fig 6: Plot of benchmark Kappa (x-nodes) versus Kappa after iterative aggregate grouping was performed. Focuses over the specked line speak to a change. As a last synopsis of performance for each of the eight email acts, the Kappa esteem for every technique, arrived at the midpoint of over the four separate test sets. Predictable with the more nitty gritty examination above, there is a normal change in normal Kappa esteems for all the non-conveyance related acts, however a normal misfortune for Deliver and dData.
Fig 7: Performance change by gatherings of email-acts.
Gatherings were chosen in light of performance in the preparatory tests. One could likewise take each act independently, and consider the four test esteems as draws from a populace of working groups. This enables one to test the centrality of the change for a specific email act—however tragically, one has just four examples with which to appraise criticalness. With this test, the change in Commissive is huge with a two-followed test (p=0.01), and the change in Meeting is critical with a one-followed test (p=0.04). The change in Commit are not noteworthy (p=0.06 on a one-followed test). For no situation is a misfortune in performance measurably huge.
VI.
CONCLUSION
styles, and in our trials to date, information from one arrangement of groups is constantly used to learn email-act classifiers for another group. In future work we would like to ponder the relative benefit of preparing information acquired from different groups, and information got from the group whose email-acts are being anticipated. This is an essential inquiry, since it illuminates how much classifiers for email-acts are group or individual ward.
VII.
REFERENCES
[1]. D. Jensen, J. Neville and B. Gallagher. Why Collective Classification Inference Improves Relational Classification. Proceedings of the 10th ACM SIGKDD, 2004.
[2]. R.E. Kraut, S.R. Fussell, F.J. Lerch,and A. Espinosa. A. Coordination in Teams: Evidence from a Simulated Management Game. To appear in the Journal of Organizational Behavior. [3]. A. Leusky. Email is a Stage: Discovering People
Roles from Email Archives. ACM SIGIR, 2004. [4]. H. Murakoshi, A. Shimazu, and K. Ochimizu.
Construction of Deliberation Structure in Email
Communication. Pacific Association for
Computational Linguistics, 1999.
[5]. J. Neville and D. Jensen. Iterative Classification in Relational Data. AAAI-2000 Workshop on Learning Statistical Models from Relational Data. AAAI Press, 2000.
[6]. J. Neville, D. Jensen, and J. Rattigan. Statistical Relational Learning: Four Claims and a Survey. Workshop on Learning Statistical Models from Relational Data, 18th IJCAI, 2003.
[7]. F. Sha and F. Pereira. Shallow Parsing with Conditional Random Fields. Proceedings of the HLT-NAACL, ACM, 2003.
[8]. J. Carletta. Assessing Agreement on
Classification Tasks: The Kappa Statistic. Computational Linguistics, 22(2):249-254, 1996. [9]. V.R. Carvalho, W. Wu, W.W. Cohen and J.
Kleinberg. Predicting Leadership Roles in Email
Workgroups. Work in Progress,
http://www.cs.cmu.edu/˜vitor/publications.html .
[10].W.W. Cohen, V.R. Carvalho and T.M. Mitchell. Learning to Classify Email into “Speech Acts”. Proceedings of the EMNLP, Barcelona, Spain, July 2004.
[11].W.W. Cohen. Minorthird: Methods for
Identifying Names and Ontological Relations in Text using Heuristics for Inducing Regularities from Data. In http://minorthird.sourceforge.net, 2004.
[12].S. Chakrabarti and P. Indyk. Enhanced Hypertext Categorization Using Hypelinks. Proceedings of the ACM SIGMOD, Seattle , Washington, 1998.
[13].S. Geman and D. Geman. Stochastic Relaxation,
Gibbs Distributions and the Bayesian
Restoration of Images. IEEE Transactions on Pattern Analysis and MachineIntelligence, (6):721-741, 1984.
[14].D. Heckerman, D. Chickering, C. Meek, R. Rounthwaite, and C. Kadie. Dependency networks for inference, collaborative filtering and data visualization. Journal of Machine Learning Research, (1):49-75, 2000.
ABOUT AUTHORS:
A. Anusha NagaLakshmi is currently
pursuing her MCA in MCA