Query Extension with Improved User Profiles for
User tailored Search taking Advantage over
Folksonomy Data
Mohammed Zubair Ali Khan1 MdAteeq Ur Rahman2, 1
Research Scholar, Dept. of Computer Science & Engineering, SCET, Hyderabad, India
2
Professor and Head, Dept. of Computer Science & Engineering, SCET, Hyderabad, India
Abstract: Query expansion has been widely adopted in web search as the simplest way of endeavour the anomaly of queries. customized search utilizing folksonomy knowledge has incontestible associate extreme vocabulary pair drawback that needs even more practical question growth ways. Co-occurrence statistics, tag-tag relationships and linguistics matching approaches ar among those favored by previous analysis. However, user profiles that solely contain a user’s past annotation data might not be enough to support the choice of growth terms, particularly for users with restricted previous activity with the system. we have a tendency to propose a unique model to construct enriched user profiles with the assistance of associate external corpus for customized question growth. Our model integrates the present progressive text illustration learning framework, called word embeddings, with topic models in 2 teams of pseudo-aligned documents. supported user profiles, we have a tendency to build 2 novel question growth techniques. These 2 techniques ar supported topical weights-enhanced word embeddings, and also the topical relevancy between the question and also the terms within a user profile severally. The results of associate in-depth experimental analysis, performed on 2 real-world datasets mistreatment completely different external corpora, show that our approach outperforms ancient techniques, as well as existing non-personalized and customized question growth ways.
Index Terms: Personalization, Information Search and Retrieval, Query Formulation, User profiles and alert services.
I. INTRODUCTION
Nowadays, the net is taking part in a big role in delivering data to users’ fingertips. an online page are often localized by a set universal resource locator, and displays the page content as time-varying photo. Among the common internet behaviors, internet revisitation is to re-find the antecedently viewed sites, not solely the page universal resource locator, however conjointly the page photo at that access timestamp [1]. A 6-week user study with twenty three participants showed nearly fifty eight of internet access belonged to internet revisitation [2]. Another 1-year user study involving 114 participants disclosed around four-hundredth of queries were re-finding requests [3]. in step with [4], on average, each second page loaded was already visited before by identical user, and therefore the quantitative relation of revisited pages among all visits ranges between 2 hundredth and seventy two. Psychological studies show that humans trust each long-term memory and LTM to recall data or events from the past. Human’s long-term memory receives and stores temporally dated episodes or events, along with their spatial-temporal relations, whereas human’s LTM, on the opposite hand, may be a structured record of facts, meanings, ideas and skills that one has nonheritable from the external world. linguistics data comes from accumulated long-term memory.
The most closely connected work of this study is reminder system [8], that unifies context and content to help net revisitation. It outlined the context of an internet page as different pages within the browsing session that right away precede or follow the present page, then extracted topic-phrases from these browsed pages supported the Wikipedia topic list. compared, the context data thought-about during this work includes interval, location and coinciding activities mechanically inferred from user’s laptop programs. rather than extracting content things from the complete online page as drained [8], we have a tendency to extract them from page segments displayed on the screen within the user’s read, and assign a probabilistic price to every extracted term supported user’s page browsing behaviors (i.e., dwell time and highlighting), additionally as page’s subject headings and term frequency-inverse document frequency (tf-idf), reflective user’s impression and odds of mistreatment the keyword as recall content cues.
Other closely connected work like [9], [10], [11] enabled users to go looking for contextually connected activities (e.g., time, location synchronal activities, meetings, music taking part in, interrupting telephone call, or perhaps alternative files or websites that were open at a similar time), and realize a target piece of data (often not semantically related) once that context was on. This body of analysis emphasizes episodic context cues in page recall. a way to grasp probably spectacular linguistics content cues from user’s page access behaviors, and utilize them to facilitate recall aren't mentioned. To tailor to individual’s net revisitation characteristics, likewise as human user’s context and content memory degradation nature, this study presents strategies to dynamically tune powerful parameters in building and maintaining probabilistic context and content reminiscences for recall.
II. RELATED WORKS
There is presently variety of analysis work performed within the space of bridging the gap between data Retrieval and on-line Social Networks (OSN). this can be principally done by enhancing the IR method with data coming back from social networks, a method known as Social Data Retrieval. the most question one may raise is What would be the advantages of victimization social data (no matter whether or not it's content or structure) into the data retrieval method and the way is that this presently done? With the growing range of efforts towards the mixture of IR and social networks, it's necessary to create a clearer image of the domain and synthesize the efforts during a structured and meaty method. This paper reviews completely different efforts during this domain. It intends to supply a transparent understanding of the problems moreover as a transparent structure of the contributions. additional exactly, we have a tendency to propose (i) to review a number of the foremost vital contributions during this domain to know the principles of SIR, (ii) a taxonomy to categories these contributions, and at last, (iii) associate analysis of a number of these contributions and tools with reference to many criteria, that we have a tendency to believe are crucial to style a good SIR approach. This paper is predicted to serve researchers and practitioners as a respect to facilitate them structuring the domain, position themselves and, ultimately, facilitate them to propose new contributions or improve existing ones.
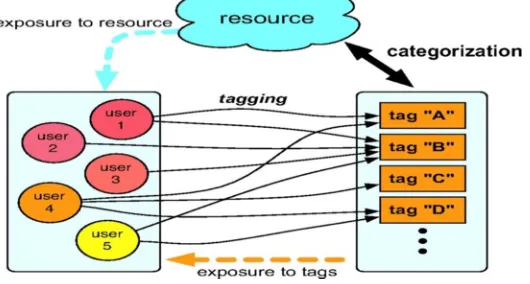
As a social service in internet 2.0, folksonomy provides the users the flexibility to save lots of and organize their bookmarks on-line with "social annotations" or "tags". Social annotations square measure prime quality descriptors of online pages' topics moreover nearly as good indicators of web users' interests.
we tend to propose a personalized search framework to utilize folksonomy for personalized search. Specifically, 3 properties of folksonomy, specifically the categorization, keyword, and structure property, square measure explored. within the framework, the rank of an online page is set not solely by the term matching between the question and the net page's content however also by the subject matching between the user's interests and also the web page's topics. within the analysis, we tend to propose associate degree automatic analysis framework supported folksonomy knowledge, that is ready to assist lighten the common high value in customized search evaluations. A series of experiments square measure conducted exploitation 2 heterogeneous knowledge sets, one crawled from Del.icio.us and also the different from Dogear. intensive experimental results show that our customized search approach will considerably improve the search quality.
III. EXISTING SYSTEM
IV. PROPOSED SYSTEM
We tackle the challenge of customized QE utilizing folksonomy information in a very novel approach by integration latent and deep linguistics. we tend to propose a unique model that integrates word embeddings with topic models to construct enriched user profiles with the assistance of associate degree external corpus.We suggest 2 novel customized QE techniques supported topical weights-enhanced word embeddings, and also the topical connectedness between the question and also the terms within a user profile. The techniques demonstrate considerably higher results than antecedently planned non-personalized and customized QE strategies.
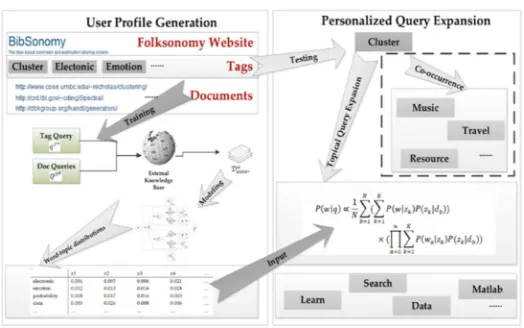
[image:3.612.172.434.188.352.2]V. SYSTEM ARCHITECTURE
Figure 1: System Architecture of the Proposed System
The formula encompasses a loose relationship to the k-nearest neighbor classifier, a preferred machine learning technique for classification that's usually confused with k-means as a result of the k within the name. One will apply the 1-nearest neighbor classifier on the cluster centers obtained by k-means to classify new knowledge into the present clusters. this can be called nearest center of mass classifier or Rocchio formula.
Figure 2: Collaborative Tag Concept
A. Module Description
In this project, we have three modules.
1) User Module
2) Personalization Module
3) Query Expansion Module
4) Information Search and Retrieval.
B. User Module
In this module, User profiles that contain solely a user’s past annotation data might not be enough to support the effective choice of growth terms, particularly for users United Nations agency have had restricted previous activity with the system. during this case, search personalization is performed on AN combination level. this kind of personalization involves the exploitation of usage data in an exceedingly collective manner wherever the search method is customized to the requirements of the various, instead of the precise wants of the individual. this could “inject” the temperament of different users rather than the present user, inflicting issues like question shift and/or interest shift. during this case, it's higher to counterpoint the user profile consistent with the precise wants of the actual user instead of borrow data from similar counterparts.
C. Personalization Module
Personalized QE tries to expand the first question (in folksonomies, once simulating user searches, tags area unit usually used as queries) with alternative terms/words from a user profile that facilitate to best represent the user’s actual intent, or manufacture a question that's additional possible to retrieve relevant documents. In customized search utilizing folksonomy information, researchers often think about completely different term relationships, as well as co-occurrence statistics, tag-tag relationships or the linguistics connection of 2 terms . all told of the higher than approaches, a user profile is typically required to represent the user’s interests in associate personalized manner. during this context, the information kept within the user profile is often past annotation information like tags and annotations from social bookmarking systems. The advantage of exploiting this kind information} is that it allows customized search systems to achieve made knowledge concerning their users’ interests and preferences owing to the wealth of knowledge that's offered on social websites. additionally, the maximum amount of the data shared on social websites is public then the utilization of this public content mustn't create a threat to users’ privacy.
D. Query Expansion Module
illustration have additionally been adopted to expand the question in step with a user’s interaction with the system. it's price noting that in, folksonomy knowledge aren't used as a workplace as in different approaches, however rather used as associate degree external supply of data from that to extract linguistics categories that are side to internet search results. Moreover, terms during this approach ar still supported co-occurrence statistics instead of linguistics connection. projected a personalized QE framework supported the linguistics connection of terms within individual user profiles. A applied math tag-topic model is made to deduce latent topics from the user’s tags and labeled documents. This model is then accustomed determine the foremost relevant terms within the user model to the user’s question then use those terms to expand the question.
E. Information Search & Retrieval
Web users might not continually achieve success in employing a representative vocabulary once locating objects in a very system. Therefore, question growth tries to expand the terms of the user’s question with alternative terms, with the aim of retrieving additional relevant results. QE includes a long standing history in data Retrieval and net search. Among the varied QE approaches conferred in literature, some profit of implicit relevancy feedback, some use external sources, and a few implement linguistics QE. These techniques are typically nonuser targeted. There also are user-focused QE strategies. for instance, strategies that implicitly choose terms from the user profile, strategies that involve implicitly getting terms from the question logs and/or their associated clicked documents, and strategies requiring the user to expressly give relevancy feedback or perform interactive question growth.
VI. CONCLUSION
In this paper we have a tendency to study customized search through increased user profiles and customized question enlargement utilizing folksonomy information. we have a tendency to propose a completely unique model to make enriched user profiles. Our model integrates this progressive text illustration learning framework, called word embedding, with topic models in 2 teams of pseudo-aligned documents between user annotations and documents from the external corpus. supported these increased user profiles, we have a tendency to then gift 2 novel QE techniques. the primary technique approaches the matter by victimization topical weights-enhanced word embedding to pick the most effective doable enlargement terms. The second technique calculates the topical connection between the question and also the terms within a user profile. The planned models performed well on to realworld social tagging datasets made by folksonomy applications, delivering statistically important enhancements over non-personalized and customized representative baseline systems. we have a tendency to additionally show that our methodology works well for users with little, moderate and made amounts of historical usage information.We aim to analyze incorporating additional info into the latent linguistics model so as to capture additional correct user profiles. Future work will embody the analysis of various similarity models and weight schemes to be utilized in our models.
REFERENCES
[1] M. R. Bouadjenek, H. Hacid, and M. Bouzeghoub, Socialnetworks and information retrieval, how are they converging? A survey, a taxonomy and an analysis of social informationretrieval approaches and platforms, Information Systems, 2016, 56: 1-18
[2] S. Xu, S. Bao, B. Fei, Z. Su, and Y. Yu, Exploring folksonomy for personalized search, in Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval, Singapore, Singapore, 155-162, 2008
[3] G. Smith, Folksonomy: social classification, Blog article, August, 2004
[4] M. Bertier, R. Guerraoui, V. Leroy, and A.-M. Kermarrec, Toward personalized query expansion, in Proceedings of the Second ACM EuroSys Workshop on Social Network Systems, Nuremberg, Germany, 7-12, 2009
[5] C. Biancalana, F. Gasparetti, A. Micarelli, and G. Sansonetti, Social semantic query expansion, ACM Trans. Intell. Syst. Technol., 2013, 4(4): 1-43 [6] D. Zhou, S. Lawless, and V. Wade, Improving search via personalized query expansion using social media, Information Retrieval, 2012, 15(3-4): 218-242 [7] C. Biancalana and A. Micarelli, Social Tagging in Query Expansion: A New Way for Personalized Web Search, in Proceedings of the 2009 International
Conference on Computational Science and Engineering - Volume 04, 1060- 1065, 2009
[8] M. Bender, T. Crecelius, M. Kacimi, S. Michel, T. Neumann, J. X. Parreira, R. Schenkel, and G. Weikum, Exploiting social relations for query expansion and result ranking, in Proceedings of IEEE 24th International Conference on Data Engineering Workshop, 2008. ICDEW 2008, 501-506, 2008
[9] E. Agichtein, E. Brill, S. Dumais, and R. Ragno, Learning user interaction models for predicting web search result preferences, in Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, Seattle, Washington, USA, 3-10, 2006.