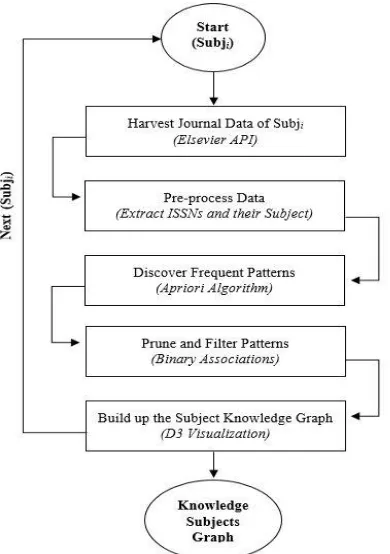
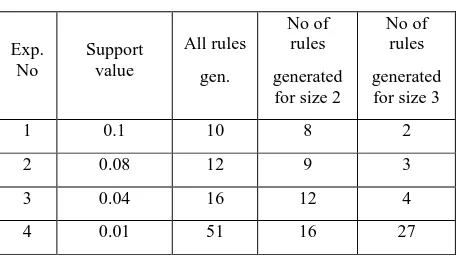
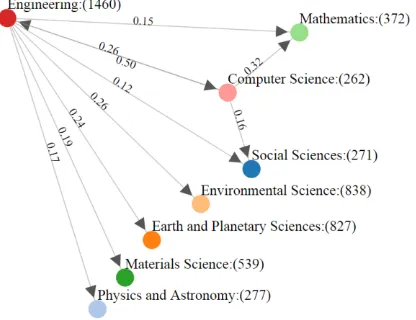
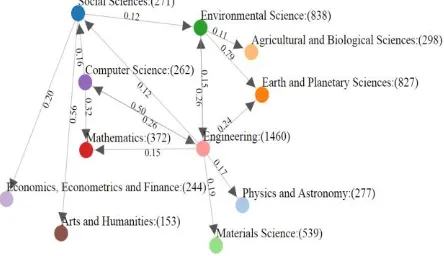
Building Knowledge Graphs based on Binary Associations between Research Topics using Apriori
Full text
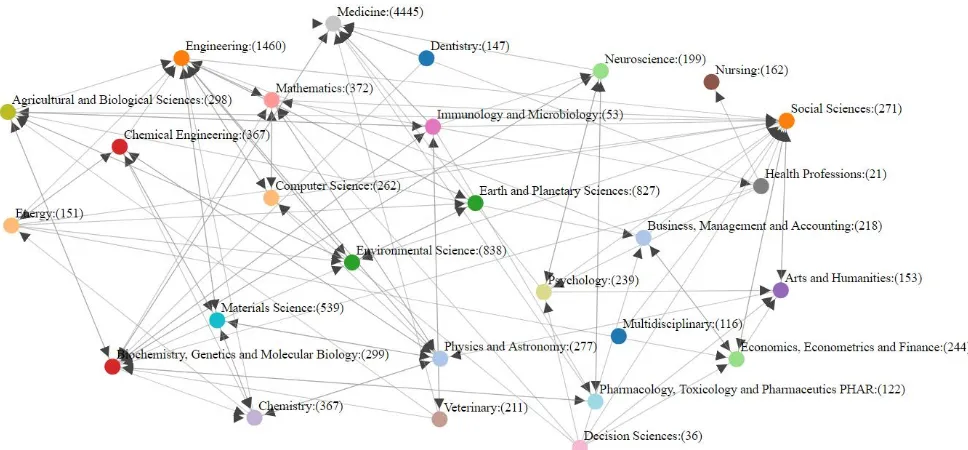
Figure
Related documents
This paper describes an experiment which aims to examine the effectiveness and efficiency of a Virtual Reality Modelling Language (VRML) building model compared with equivalent
RESEARCH Open Access Epstein Barr virus latent membrane protein 1 suppresses reporter activity through modulation of promyelocytic leukemia protein nuclear bodies Mark D Sides1, Gregory
This paper proposes a tolerant control for the open- circuit fault of the outer switches in three-level rectifiers (both 3L-NPC and T-type topologies) used in
In this paper, through the approach of solving the inverse scattering problem related to the Zakharov-Shabat equations with two potential functions, an efficient numerical algorithm
Conclusions: Repeated EA interventions have a time-dependent cumulative analgesic effect in neuropathic pain rats, which is closely associated with its regulatory effects on NK
Male sexual dysfunction after rectal cancer surgery: results of a randomized trial comparing mesorectal excision with and with- out lateral lymph node dissection for patients
The severity of preoperative neurologic compromise was higher in the fracture-disloca- tion than burst fracture, and the severity of neurologic com- promise at the final follow-up
CUAJ ? July August 2014 ? Volume 8, Issues 7 8 ? 2014 Canadian Urological Association Ryan Kendrick Flannigan, MD;* Geoffrey T Gotto, MD, FRCSC;? Bryan Donnelly, MD, FRCSC;? Kevin
