From Psycholinguistic Modelling of Interlanguage in Second
Language Acquisition to a Computational Model
Montse Maritxalar
A r a n t z a D i a z de
Ilarraza
Maite Oronoz
Dept. of Computer
Dept. of Computer
Dept. of Computer
Languages and Systems.
Languages
and Systems.
Languages
and Systems.
Univ. of the Basque Country Univ. of the Basque Country Univ. of the Basque Country
649 postakutxa 20080
649 postakutxa 20080
649 postakutxa 20080
Donostia. Spain
Donostia. Spain
Donostia. Spain
j ipmaanm~si, ehu. es j ipdisaa@si, ehu. es j iboranm©si, ehu. es
A b s t r a c t
The present article demostrates the im- plementation of a psycholinguistic model of second language learners' interlanguage in an Intelligent Computer Assisted Lan- guage Learning (ICALL) system for study- ing second language acquisition. We have focused our work on the common interlan- guage structures of students at the same language level. The Interlanguage Level Model (ILM) is made up of these struc- tures.
In this paper we explain the conceptual model of ILMs, we present the experimen- tal method followed for collecting written materiM, we describe the output of the modelling tool, and finally some conclu- sions and future work are outlined.
1 I n t r o d u c t i o n
The main goal of this article is to show the imple- mentation of a psycholinguistic model of second lan- guage learners' interlanguage in an Intelligent Com- puter Assisted Language Learning (ICALL) sys- tem for studying second language acquisition. The ICALL system, and the computational model for representing interlanguage, have been designed after previous work on psycholinguistics, artificial intelli- gence, and computational linguistics. This article will be focused on the computational model of inter- language. Description of the ICALL system can be found in (Maritxalar et al., 1994).
The concepts transitional dialects (Corder, 1971) and approximate systems (Nemser, 1971) are pre- cursors to interlanguage (Selinker, 1972) (Selinker, 1992). Their aim was to define communicative and grammatical competence in second languages. All of them have these common features: a) a student's
discourse is i n d e p e n d e n t f r o m t h e n a t i v e l a n - g u a g e (L1) a n d t h e t a r g e t l a n g u a g e (L2) and it is the product of a s t r u c t u r e d l i n g u i s t i c s y s - t e m ; b) the linguistic system is v a r i a b l e during the learning process and it is v e r y s i m i l a r in s t u d e n t s o f t h e s a m e l a n g u a g e level, with the exception of some differences, results of a person's learning expe- rience. In our case, the above mentioned character- istics are the basis for modelling the interlanguage. For example, as the linguistic system is very simi- lar in students of the same level, we can infer that we will have an interlanguage model for each level. Therefore, in our ICALL system we find a mod- ule where the different Interlanguage Level Models (ILMs) of each language level are represented. Rep- resentation of the ILMs will be presented in this ar- ticle.
Our work is based on corpus analysis. At this moment we have focused on the implementation of the morphological and morphosyntactic competence at word level. Work at word level is important in our case because Basque is an agglutinative lan- guage with rich morphosyntactic information within words. We have studied texts written by Spanish students of Basque. We are aware of the limits of the modelling only taking into account written ma- terial. Spoken material could also be collected for a better modelling. However, as the computational tools we have for studying Basque are only for writ- ing studies, we have discarded the treatment of the spoken output of the learners.
In the next section we will explain the concep- tual model of ILMs by means of the KADS Domain Description Language (DDL) proposed in Schreiber (Schreiber et al., 1993). Next, we will give an idea of the experimental method used in order to col- lect written material and the top-down methodology used in order to model interlanguage in support of the selected corpora. After that, we will describe some of the implemented tools for modelling ILMs.
Martxalar, Diaz de Ilarraza ~ Maite Oronoz 50 Computational Model of Interlanguage
Montse Maritxalar, Arantza Dfaz de llarraza and Make Oronoz (1997) From Psycholingulstic Modelling of I n t e r l a n g u a g e in Second Language Acquisition to a Computational Model. In T.M. Ellison (ed.) CoNLL97:
Computational Natural Language Learning, ACL pp 50-59.
Then, we will describe the o u t p u t of the modelling tool, in order to compare the information given by the computational tool and the conceptual model of ILMs proposed before. Finally, some conclusions and future work are presented.
2
A C o n c e p t u a l M o d e l for
Interlanguage Level Models
In this section we show the psycholinguistic model for Interlanguage Level Models (ILMs). The ILMs characterise different grammars of the interlanguage the ideal learner can have for the second language at each language level. It must be noted that, al- though some linguistic structures are particular to each student, others are common to all students at the same level. These common structures are those which will be represented in the ILMs.
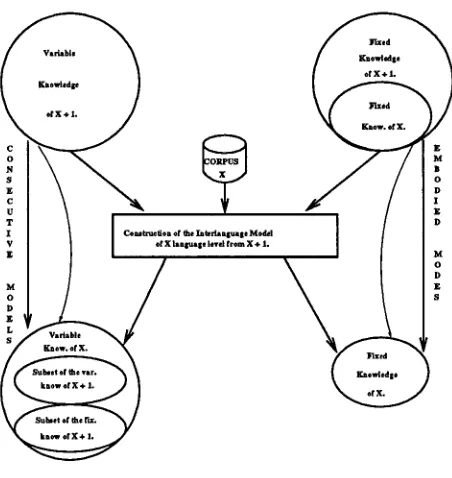
We represent ILMs by means of two different types of sequences of models: consecutive sequences and
embodied sequences. For each level, two different kinds of knowledge are represented: the variable knowledge, the knowledge the student is supposed to be learning; and, the fixed knowledge, the knowledge the learner has already acquired. T h e knowledge the language learners have acquired at a concrete level includes the knowledge acquired at previous levels. However, the knowledge they are learning at each level follows a different structure: each model from each level is independent from other levels, although intersections between knowledge at different levels t a n occur at times. T h e set of different variable language structures at each language level consists of consecutive sequences of models, while the set of fixed ones consists of embodied sequences (see Fig. 1). When we say fixed knowledge or variable knowl- edge we refer to the language structures the learners have in their interlanguage, without making any dis- tinction between the representation of correct and "incorrect" structures. When we specify interlan- guage all the language structures, right and "de- viant", are represented in the same way. It must be noted t h a t while a language structure used by high level learners can be considered deviant, the same structure in the case of beginners could be seen as correct at their level. For example a deviation at 10th level like avoiding the word ote 'could' (i.e. nor da? 'who is?' instead of nor ore da? 'who could be?' ) is not considered a deviation in lower levels of the language.
Language structures of the interlanguage are context-dependent (Selinker, 1992). Language learners create discourse domains as contexts for interlanguage development.
c
L
lg• e •
Fig 1. ~ t w ~ c t i o a d ~ l l.n te fla ngmlge ~ d d ef X from X * L
Such domains are constructed in connection with life experiences t h a t have importance for the learner, containing prototypical interlanguage forms associ- ated with the content area by the learner. Interlan- guage m a y be developing in one domain while at the same time it m a y be stabilised, or possibly fossilised, in another (Selinker, 1992). So, language structures of the interlanguage include information about con- text where they appear. Some structures appear in the interlanguage in specific contexts, however, oth- ers appear in any context. T h a t is why we can see, in the representation below t h a t structures can be context-dependent or context-independent. A first approximation of the representation (using DDL) for the ILMs is as follows:
s t r u c t u r e Interlanguage_Level_Models;
p a r t s :
models:
s e t ( i n s t ance(Interlanguage._Level_Model));
s t r u c t u r e Interlanguage_LeveLModel;
p a r t s :
fixed_knowledge:
s e t ( i n s t a n c e ( i n t e r l a n g u a g e _ x n o d e l ) ) ; c a r d i n a l i t y :
r a i n 0 m a x HIGHEST_LEVEL;
variable_knowledge:
s e t ( i n s t a n c e ( i n t e r l a n g u a g e _ m o d e l ) ) ;
c a r d i n a l i t y :
r a i n 0 m a x HIGHEST._LEVEL;
[image:2.596.294.520.121.360.2]s t r u c t u r e
interlanguage_model;
p a r t s :
structure_context_indep :
s e t ( i n s t a n c e
(interlanguage_structure_context_indep));
strueture_context_dep :
s e t ( i n s t a n c e
(interlanguage_structure_context_dep)); p r o p e r t i e s :
language_level:
i n t e g e r - r a n g e ( I ,
HIGHEST.LEVEL);
s t r u c t u r e
interlanguage_structure_context_indep ;
s u b t y p e - o f : interlanguage_structure,
s t r u c t u r e
interlanguage_structure_context_dep;
s u b t y p e - o f : interlanguage_structure,
s t r u c t u r e
interlanguage_structure;
s u b t y p e s :
interlanguage_strueture_context _indep, interlanguage_structure_context _dep; p a r t s :
phenomena:
set ( i n s t a n c e (linguistic_phenomenon));
conditions:
set ( i n s t a n c e (interlanguage_condition)); p r o p e r t i e s :
description:
s t r i n g ;eontextualization:
b o o l e a n ;deviation:
b o o l e a n ;stabilization:
function(stabilization of the rules associated to each phenomenon); a x i o m s :
If contextualization= False then conditions=<>.
The same interlanguage structure can be deviation=True at the X language level and deviation=False at the Y language level.
The value of
stabilization
is {rarely, sometimes, usually, always}The interlanguage structures we propose are com- posed of
linguistic phenomena
which occur under someconditions.
The properties of the interlanguage structures are:description
of the structure;contex-
tualization,
that is, context dependent or context in- dependent;deviation,
which marks if the structure must be considered deviant at the related language level and, finally,stabilization.
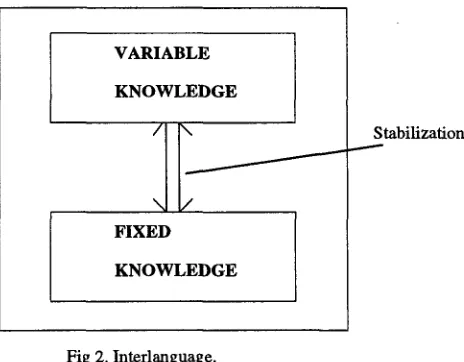
The stabilization property is a qualitative value
VARIABLE
K N O W L E D G E
/ \ Stabilization
\
FIXED
[image:3.596.316.548.103.284.2]K N O W L E D G E
Fig 2. Interlanguage.
which represents the acquisition level of the struc- ture for a particular language level. It is by means of this property that a language structure inside the student's interlanguage is considered fixed knowl- edge or variable knowledge. When the value of the stabilization property is
always
it means that the language structure has been assimilated by the learner and in the future it would be quite difficult making some changes. However, when the value israrely,
there is a high variability of the language structure, and, therefore, a good teacher (could be an ICALL system) should be able to help the learner to take away those structures in case they would not direct the student towards a target language.In the first approximation of the representation for the ILMs we have represented interlanguage struc- tures as a set of linguistic phenomena depending on interlanguage conditions. Now, we will explain those conditions, and, we will also describe the definition of linguistic rules and replacements which define the linguistic phenomena.
s t r u c t u r e
linguistic_phenomenon;
p a r t s :
rules:
s e t ( i n s t a n c e (linguistic_rule)) I set (tuple(replacement-rule); p r o p e r t i e s :
type:
f u n c t i o n ( t y p e of the rules or replacements associated to each phenomenon)
description:
s t r i n g ;global:
b o o l e a n ;lexical_entry:
set(instance(morpheme)); axioms:If global=False then lexical_entry = < >
s t r u c t u r e interlanguage_condition;
p a r t s :
linguistic_context:
s e t (instance(linguistic_condition));
non_linguistic_context:
s e t (instance(non.linguistic_condition));
Which kind of conditions must be considered in the interlanguage? We said above that, inside the interlanguage, language structures are context- dependent or context-independent (Selinker, 1992). Referring to context-dependent structures it is very i m p o r t a n t to differentiate between two types of con- texts: non-linguistic and linguistic.
Non-linguistic conditions are related to a discourse domain. Interlanguage varies depending on the do- main. T h e linguistic structures that we activate when writing a story are different to those we ac- tivate when we write scientific-technical texts (the- matic_conditions). Activity types, such as fielding questions, writing a letter, translating a sentence, conversing in a group etc. are also non-linguistic conditions.
Interlanguage forms can vary from one activity type to another, even though the discourse domain is the same. The activity types can be related to the structure of the whole text (text_conditions); in addition there are also some non-linguistic con- ditions (e.g. length of the sentence) related to a particular language structure in the text (struc- ture_conditions). For example, sometimes students mark agreement between verb and complements in small simple sentences, and, at the same time they forget it in long sentences. In our case, structure conditions are studied by means of the corpus; text conditions, however, are detected by means of inter- views with the teachers and learners.
c o n c e p t condition;
s u b t y p e s :
linguistic_condition, non_linguistic_condition; p r o p e r t i e s :
description: s t r i n g ;
c o n c e p t linguistic_condition;
s u b t y p e - o f : condition; p r o p e r t i e s :
word_level:
llst (part_of_speech, declension_case ... )
sentence_level: list (use_of_subordinates . . . )
c o n c e p t non_linguistic_condition;
s u b t y p e - o f : condition; s u b t y p e s :
textual_condition, thematic_condition;
c o n c e p t textual_condition
s u b t y p e - o f : non_linguistic_condition; p r o p e r t i e s :
text_conditions:
list (summary, formalJetter, translation . . . );
structure_conditions:
list(long_sentence_based, long_word_based, apl_place_lem, apl_place_mor . . . );
c o n c e p t thematic_condition
s u b t y p e - o f : non_linguistic_condition; p r o p e r t i e s :
type: (general, technical);
Linguistic conditions are studied by means of a corpus. In the corpus composed of texts written by high level and upper intermediate language students (350 texts collected between 1991 and 1995) we found linguistic influence in some language structures of the interlanguage. For instance, the presence of plurality of some components in the sentence can cause verbs to agree with such compo- nents, whether or not these must be in agreement with the verb (the phenomenon of plurality has also been observed in second language learners of French (Lessard et al., 1994)). Finally, we would like to claim that this way of putting linguistic structures in context could be applied similarly when modelling first languages.
After defining which kind of conditions must be taken into account when linguistiq phenomena are identified, we will see which type of linguistic rules can be found inside the phenomena.
It is usual t h a t language learners know only some linguistic rules corresponding to a particular linguis- tic phenomenon, and not all of them. In the case of language natives, however, they know, in most cases, all linguistic rules. T h a t is the reason for represent- ing explicitly in the student's interlanguage the set of linguistic rules related to the linguistic phenom- ena of the language structure. In other cases, as in natives, it should not be necessary to make their linguistic rules explicit as the linguistic phenomena define, implicitly, the set of linguistic rules.
In the same way, we could say t h a t linguistic rules identify the corresponding linguistic phenomenon,
however, it is necessary to make it explicit, as a linguistic phenomenon could be detected in a stu- dent's interlanguage, but the linguistic rules would not be identified until after some interactions with the student. The student model is dynamic, so, the language structures are also dynamic. Therefore, in the first interactions with the student a linguistic phenomenon can be detected inside the student's interlanguage before eliciting the corresponding linguistic rules. Next we shall define the structure of the linguistic rules.
s t r u c t u r e linguistic_rule;
s u b t y p e s : morphological_rule, syntactic_rule; p a r t s :
implemented_by: set (rule. identifier);
cardinality:
r a i n 1;conditions: s e t ( i n s t a n c e (interlanguage_condition)); p r o p e r t i e s :
type: {morph, syn};
description: s t r i n g ;
example: s t r i n g ;
stabilization:
{rarely, sometimes, usually, always};
In the experiments the teachers have identified three types of language phenomena in the students' interlanguage: first, simple interlanguage structures composed of a set of linguistic phenomena and lin- guistic rules; second, avoiding interlanguage struc- tures defined as linguistic rules t h a t the student usu- ally avoids; and, third, replacement language struc- tures where the learner uses a structure too often (or rarely) instead of using other structures (e.g. when a person uses the conjunction and all time and rarely uses structures such as however, nevertheless, thus ... ). Consequently, we can say t h a t there are relationships between linguistic rules of the in- terlanguage. T h a t is why structures which represent linguistic phenomena also have a set of replacement tuples, which represent the replacement relations be- tween linguistic rules.
3
Using Corpus Linguistics in order
to Model
Interlanguage
In this section we will explain first the experimen- tal method used in order to collect written material, and second the top-down methodology used in or- der to model interlanguage in support of the selected corpora. We model Interlanguage Level Models by means of automatic tools which use the collected material as input. It must be noted t h a t some in-
formation of the interlanguage models, for example text conditions (see section 2), are detected semiau- tomatically with the help of the teachers and learn- ers.
Before explaining modelling based on corpus anal- ysis, we would like to make some comments about the criteria for defining the corpus: we collected written material from different language schools (IRALE 1, ILAZKI) and grouped this material de- pending on some features of the texts such as, 1) the kind of exercise proposed by the teacher (e.g. abstract, article about a subject, letter . . . ) and 2) the student who wrote the text. Those are stu- dents with a regular attendance in classes and with different characteristics and motivations for learning Basque (e.g. different learning rates, different knowl- edge about other languages, mother tongue . .. ).
We codified the texts of the corpora following a prefixed notation (e.g. ill0as) showing the language school (e.g. il, ILAZKI), the language level, the learner's code, and the type of exercise proposed (e.g. s, summary). The last feature is what we have called text condition in section 2. At the same time, a database for gathering the relevant informa- tion about the students' learning process was de- veloped. We retrieved such information from inter- views with the students and the teachers (Andueza et al., 1996). The corpus collected from 1990 to 1995 is made up of 350 texts. This corpus has been di- vided in subsets depending on the language level. At the moment we have defined three language levels of study t h a t we call low, intermediate, and high levels. Before designing and implementing the automatic tools, three different studies of corpora during 90/91 (i.e. 50 texts semiautomatically analysed), 93/94 (i.e. 20 texts semiautomatically analysed), and 94/95 (i.e. 100 texts semiautomatically analysed) were carried out. These studies were done, in the first case, by teachers who didn't know the students, and in the other two cases by teachers who knew the students. In the first two cases the work lasted two months. In the third case, however, texts were col- lected every week from September until June, and two teachers worked five hours per week on study- ing the corpora during the 94/95 academic year. The language learners had five hours of language classes per week, and they wrote one composition every week or every fortnight.
For modelling interlanguage at different language levels we use a top-down methodology, t h a t is, we start from the modelling of high levels and con- tinue to lower ones (see Fig 1). The reasons for
11RALE and ILAZKI: schools specialised in the teach- ing of Basque
a top-down methodology are t h a t most computa- tional tools for Basque we have (lemmatiser, spelling checker-corrector, morphological d i s a m b i g u a t o r . . . ) can be easily adapted for high language levels; be- sides, usually computational tools for analysing writ- ten texts of high language levels are more robust than those of low levels and, finally, there usually is more written material at high levels than at low ones.
We have a u t o m a t i c a l l y analysed subsets of cor- pora in intermediate and high levels. Choosing a text as a unit of study, groups of sixteen texts have been deeply and automatically studied.
T h e steps we followed using the tools we have adapted in order to build the interlanguage model for each N language level were:
i. Design of the lexical database for the Nth lan- guage level.
2. Selection of the corpus (CORPUS-N) and sub- sets of CORPUS-N to be used in the next steps. This selection is based on the criteria, explained before, for collecting material.
3. Definition of the morphology and morphosyntax based on a subset of CORPUS-N.
4. Identification of the fixed knowledge and the variable knowledge, considering the contexts de- fined in section 2.
(a) Evaluation of the reliability of the model using other subsets of CORPUS-N. (b) Evaluation of the results by a language
teacher of N level.
For example, in studies of high language mod- elling, a teacher evaluated the results at word level, t h a t is, the type of rules detected and the contexts where they were applied. T h e evaluation was suc- cessful, even though in some cases the perception of the teacher was not the same as the results inferred from the automatic study of the corpora (e.g. in the opinion of the teacher the students are used to delet- ing the h letter more usually than adding it. This phenomenon has not been detected in the results of the corpus).
4
Implementation
We have adapted tools previously developed in our computational linguistic group during the last ten years. These tools are: the Lexical Database for Basque (EDBL) (Agirre et al., 1994), the morpho- logical analyser based on the Two-Level Morphology (Agirre et al., 1992), the lemmatiser (Aldezabal et
al., 1994) and some parts of the Constraint G r a m - mar for Basque (Alegria et al., 1996) (Karlsson et hi., 1995).
We have two main reasons for adapting these tools:
. Some of the deviant linguistic structures used by second language learners are different to those native Basque speakers use. T h e context of application, i.e. structure conditions at word level of some rules, are not the same in both cases. Moreover, we need to add some new rules to have one rule for each linguistic structure, and we also need some of these rules in order to detect deviant linguistic phenomena, e.g. loan words from Spanish (see section 4.1).
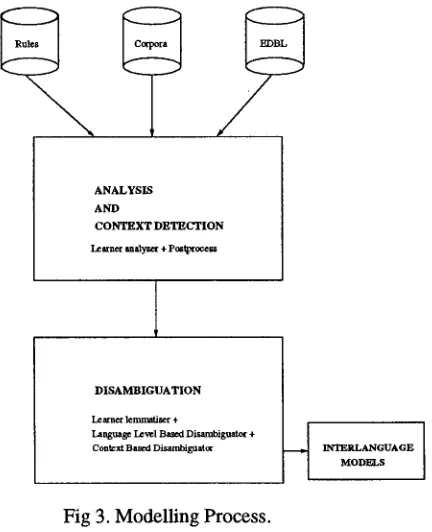
. In the original tools, the context of application of the rules remained ambiguous. As we ex- plained in section 2, the context of application is i m p o r t a n t to us for modelling the g r a m m a t - ical competence of the students, so we disam- biguate such contexts by means of our adapted tools (see section 4.2). In the figure below we can see a scheme of the way in which we have used these adapted tools (Diaz et al., 1997):
A N A L Y S I S A N D
C O N T E X T D E T E C T I O N Learner saalyselt + P , ~ o c e s s
D I S A M B I G U A T I O N
La~ttet lemrmliser ÷
Language Lavel Based Disambiguato~ ÷
Context Based Disambiguator INTERLANGUAGE
[image:6.596.302.518.426.692.2]1HODI~S
Fig 3. Modelling Process.
L E A R N E R ANALYSER = T h e adapted morpho- logical analyser (detection of structural contexts).
P O S T P R O C E S S = Context detection tool (detec- tion of structural contexts and linguistic contexts).
L E A R N E R L E M M A T I S E R = The adapted lem- matiser.
L A N G U A G E L E V E L BASED DISAMBIGUA- T O R = Disambiguator for each language level (Based on the number of rules in each interpreta- tion).
C O N T E X T BASED D I S A M B I G U A T O R = Dis- ambiguator for each language level.
(Based on subsets of the Constraint G r a m m a r for Basque + disambiguation rules based on the context of application).
I N T E R L A N G U A G E M O D E L S = I n t e r l a n - g u a g e L e v e l M o d e l s ( I L M s )
4.1 R e d e s i g n i n g t h e a u t o m a t a
As we said above, the original morphological anal- yser was based on the Two-Level Morphology. The implementation of the morphophonological rules were made by the automata. In the original anal- yser we had 30 automata: 11 of them were used for analysing standard words, but their activation was never detected; the other 19 which represented a deviation were identified but the type of deviation remained unknown. Moreover, the context of appli- cation remained ambiguous.
In the adapted analyser we find 59 automata, which represent 59 different types of phenomena (these are codified as we can see in the table below). We have modified the a u t o m a t a of the morphological analyser in order to detect which rules have been ap- plied and the contexts (structure conditions) where they have been activated. We have also made some changes in the module of the analyser which recog- nised the a u t o m a t a . The number of a u t o m a t a has increased due to the addition of new rules for de- tecting new deviations of language learners and to the division of some original a u t o m a t a in others that detect, in a more specific way, some morphologicM phenomena which are very interesting for the study of second language acquisition. An example will il- lustrate this fact:
Rules in the original analyser
h:0 = > R : = ( + : = ) + _
(Rule for standard phenomenon)
h : 0 = > I V : V - - ( 0 : * ) : ] _ V : V (Rule for deviant phenomenon)
T h e application of the rule for standard phe- nomenon is not detected, however, the competence error represented in the rule for deviant phenomenon is identified even though the context of application remains ambiguous]
Rules in the adapted analyser
h:0 = > R:= ( + : = ) + _
(LEDEH: Delete the H LEtter at the End of the root)
h:0 = > V:V _ V:V
i(LEDAH: Delete the H L E t t e r Anywhere in the word)
h:0 = > ( 0 : * ) : _ V:V
(LEDBH: Delete the H L E t t e r at the Beginning of the root)
All three rules of the interlanguage and the con- text of application are detected when they have been activated. We repeat the same a u t o m a t a three times and mark as negative in each a u t o m a t o n the states which correspond to the activation of the rule.]
4.2 R u l e s i n t h e i r Linguistic C o n t e x t
Experiments and interviews with experts lead us to see the need of identifying the linguistic context where a morphological rule (for s t a n d a r d or deviant phenomenon) is applied. We identify this context by adding to the adapted morphological analyser
(Learner_Analyser) some characteristics such as the place ( l e m m a / m o r p h e m e ) where the rule is applied, the length of the word and the type of the last letter (vowel/consonant) of the root (Postprocess).
We have two main aims in mind:
1. Disambiguate unlikely interpretations of a word (Context..Based_Disambiguator).
There are two ways to do this:
* Discarding interpretations in which a mor- phological rule has been applied in a part of the word ( l e m m a / m o r p h e m e ) where it never ap- pear in real life examples. For example, the deviant word *analisis has two interpretations
(analisi/analisiz): the rule to add an s at the end of the l e m m a / the replacement of z by s in the morpheme. T h e second interpretation is not possible for high language level students, so we discard it at such level.
* Discarding interpretations in which a morpho- logical rule is applied within an unusual part of speech. T h e rule t h a t detects the replacement of t by d is a good example of this. T h e rule is never used in verbs starting with d. After dis- carding all interpretations of the words, where the replacement rule has been applied and the part of speech is a verb, the n u m b e r of interpre- tations in the analysis of the word is reduced to a half.
2. Refine the model of the student's Interlanguage (Language_Level_Based_Disambiguator).
A word changes into another one quite differ- ent as a result of the application of an excessive number of rules who represent deviant phenom- ena. From the study of the corpora, we can de- termine the exact number of possible deviation rules for an interpretation that makes sense at each language level. At the moment, we have determined it for some levels (i.e. the highest) and we are working on the others.
5
The Output of the Modelling Tool
In this section we will show an example of an inter- language structure in order to see the relationship between the output of the modelling tool and the description of interlanguage structures explained in the conceptual model.
In this example we will see a detected linguistic phenomenon in the corpus of high level learners. The description of the phenomenon is: "when learners want to construct relative clauses and the last letter
of the verb is t, for example dut (auxiliary verb for
composed verbs), when adding the suffix -.._n for con- structing relative clauses, the t is replaced by d and
the a letter is added. That is, dut + -n = dudan".
e.g. Ikusi dudan haurra atsegina da. 'The boy
who I have seen is nice.'
Ikusi duda_n haurra atsegina da.
I have seen who boy the nice is.
This example shows that Basque syntactic infor- mation is found inside the word. That is why in the modelling of the LC_I linguistic condition (see the example) the REL feature (relative clause) is at word level, and not at sentence level.
An example of the output of the modelling tool:
(interlanguage_structure IE_i (phenomena (LF_i)) (conditions (LC_i TC_3)) (description ?)
(contextualization True) (deviation False) (stabilization usually))
(linguistic_phenomenon LF_I (rules (LEAIA_i LERATDI_i)) (type (morph))
(description ?) (global False) (lexical_entry <>))
(linguistic_rule LEAIA_i (implemented_by (9))
(conditions (LC_I TC_I TC_3)) (type morph)
(description
"Add the A LEtter Inside the word" (example " dudan ")
(stabilization usually))
(linguistic_rule LERATDi_I (implemented.by (8))
(conditions ( LC_I TC_2 TC_3)) (type morph)
(description
"Replace T by D Anywhere in the word") (example "dudan")
(stabilization usually))
(textual_condition TC_i (text_conditions < > )
(structure_conditions (apl_place_mor)) (description
"rule applied in the morpheme"))
(textual_condition TC_3 (text_conditions < > )
(structure_conditions (end_word_t))
(description "the last letter of the word is t"))
(linguistic_condition LC_i (wordAevel (V REL)) (sentence_level < > )
(description "verb for relative clause"))
(textual_condition TC_2 (text_conditions <:>)
(structure_conditions (apl_placeAem)) (description "rule applied in the lemma"))
In the process of modelling, first, we identify the linguistic rules, second, we detect groups of linguistic rules which occur in the same context and define the linguistic phenomenon, and last, the interlanguage structure is identified.
If we compare this output with the conceptual model given in section 2, we can see how the in- formation needed is reached automatically, except the description of the linguistic phenomenon and the interlanguage structure (see question marks in the example). Such information will be completed by the psycholinguist who will use the ICALL system. The information given by the psycholinguist will be reused in future modellings.
6 C o n c l u s i o n s a n d F u t u r e W o r k
The presented work proves that the implementation of psycholinguistic models of interlanguage is viable from the adaptation of the linguistic-computational tools we have for the automatic study of Basque. Modelling at word level is important in our case be- cause Basque is an agglutinative language with rich morphosyntactic information within words.
The results obtained using the developed tools for language learning studies provide us statistical in- formation about phenomena that teachers and psy- cholinguistics knew by intuition. Therefore, we can say that corpus analysis is a good technique for mod- elling ILMs.
In the near future we will develop new tools in or- der to model each student's knowledge. The detec- tion of contexts will be improved in order to identify contexts related to the characteristics of the particu- lar learners. Moreover we will work on the detection of interlanguage structures at sentence level . Field studies have been carried out in this sense (Mar- itxalar et al., 1993) (Andueza et al., 1996). At the moment, we are studying some aspects of the mor- phosyntax and syntax for L2, taking as a basis the results obtained in Andueza (Andueza et al., 1996), where in a final test the hypothesis obtained in the study carried out in the 94/95 academic year were contrasted with the students. In this work, we also analysed the reasons for using some language struc- tures in addition to the detection of their context. We plan in the future to add to the system such knowledge about the diagnosis of structures.
Finally, we would like to remark that together with the experiments explained in the article, two environments are being prepared in the ICALL sys- tem: the Knowledge Acquisition Subsystem and the Learning Process Subsystem. The Knowledge Ac- quisition Subsystem helps language teachers to make hypotheses about, among others, the reasons stu-
dents have for using deviant language structures. The Learning Process Subsystem guides users in their learning process giving hints according to their language level.
7 A c k n o w l e d g e m e n t s
This work is being developed in the framework of a research project sponsored by the University of the Basque Country and the Government of the Province of Gipuzkoa. The authors would like to thank both Institutions.
R e f e r e n c e s
Eneko Agirre, Ifiaki Alegria, Xabier Arregi, Xa- bier Artola, Arantza Diaz de Ilarraza, Montse Maritxalar, Kepa Sarasola and Miriam Urkia. 1992. XUXEN: A spelling checker/corrector for Basque based on Two-Level Morphol- ogy. In
Proceedings off the Third Conference
ANLP(ACL),
pages 119-125, Trento, Italy.Eneko Agirre, Xabier Arregi, Jose Mari Arriola, Xa- bier Artola and Jon Mikel Insausti. 1994. Eu- skararen Datu-Base Lexikala (EDBL)
Internal
Report. UPV/EHU/LSI/TR 8-94,
Computer Science Faculty: University of the Basque Country.Izaskun Aldezabal, Ifiaki Alegria, Xabier Artola, Arantza Diaz de Ilarraza, Nerea Ezeiza, Koldo Gojenola, Itziar Aduriz and Miriam Urkia. 1994. EUSLEM: Un lematizador/etiquetador de textos en euskara. In
Proceedings of the X.
Conference SEPLN,
C6rdoba, Spain.Ifiaki Alegria, Jose Mari Arriola, Xabier Artola, Arantza Diaz de Ilarraza, Koldo Gojenola, Montse Maritxalar and Itziar Aduriz. 1996. A Corpus-Based Morphological Disambiguation Tool for Basque. In
Proceedings of the XII.
Conference SEPLN,
Sevilla, Spain.A. Andueza, Arantza Diaz de Ilarraza, Montse Mar- itxalar, Josune Martiarena and Ifiaki Pikabea. 1996. Hizkuntza baten Ikaskuntza Prozesuari buruzko landa lana. Sistema Informatiko adi- mendun baten oinarria. In
Internal Report.
UPV/EHU/LSI/TR 8-96,
Computer Science Faculty: University of the Basque Country.S. Bull. 1994. Student Modelling for Second Lan- guage Acquisition. In
Computers 8J Education
23,
pages 13-20.!
S. Corder. 1971. Idiosyncratic dialects and error analysis. In
International Review of Applied
Linguistics 9,
pages 147-159.Arantza Diaz de Ilarraza, Montse Maritxalar and Maite Oronoz. 1997. Reusability of Language Technology in support of Corpus Studies in an CALL Environment. In
Language Teaching
and Language Technology Conference,
Gronin- gen, The Netherlands.F. Karlsson, A. Voutilainen, J. Heikkil/i and A. Anttila. 1 9 9 5 . Constraint Grammar: a language-independent system for parsing un- restricted text. Mouton de Gruyter.
G. Lessard, D. Maher and I. Tomek. 1994. Mod- elling Second Language Learner Creativity. I n
Journal of Artificial Intelligence in Education
5(4).,
pages 455-480.Montse Maritxalar and Arantza Dfaz de Ilarraza. 1993. Integration of Natural Language Tech- niques in the ICALL Systems Field: The treat- ment of incorrect knowledge. In
Internal Re-
port. UP V/EHU/LSI/TR 9-93,
Computer Sci- ence Faculty: University of the Basque Coun- try.Montse Maritxalar and Arantza Dfaz de Ilarraza. 1994. An ICALL System for Studying the Learning Process. In
Computers in Applied
Linguistics Conference.
Iowa State University.Montse Maritxalar and Arantza Dfaz de Ilar- raza. 1996a. Hizkuntza baten Ikaskuntza- Prozesuan zeharreko Tartehizkuntz Osaketa: Sistema Informatiko baten Diseinurako Azter- keta Psikolinguistikoa. In
Internal Report.
UPV/EHU/LSI/TR 7-96,
Computer Science Faculty: University of the Basque Country.Montse Maritxalar and Arantza Dfaz de Ilarraza. 1996b. Modelizaci6n de la Competencia Gra- matical en la Interlengua basada en el An£1isis de Corpus. In
Proceedings of the XII. Confer-
ence SEPLN,
Sevilla, Spain.W. Nemser. 1971. Approximate Systems of Foreign Language Learners. In
International Review of
Applied Linguistics 9,
pages 115-123.G. Schreiber, B. Wielinga and J. Breuker. 1993. KADS: A Principled Approach to Knowledge- Based System Development. Academic Press.
L. Selinker. 1972. Interlanguage In
International
Review of Applied Linguistics 10.,
pages 209- 231.L. Selinker. 1992. Rediscovering interlanguage. Lon- don:Longman.