LEABHARLANN CHOLAISTE NA TRIONOIDE, BAILE ATHA CLIATH TRINITY COLLEGE LIBRARY DUBLIN
OUscoil Atha Cliath The University of Dublin
Terms and Conditions of Use of Digitised Theses from Trinity College Library Dublin
Copyright statement
All material supplied by Trinity College Library is protected by copyright (under the Copyright and Related Rights Act, 2000 as amended) and other relevant Intellectual Property Rights. By accessing and using a Digitised Thesis from Trinity College Library you acknowledge that all Intellectual Property Rights in any Works supplied are the sole and exclusive property of the copyright and/or other I PR holder. Specific copyright holders may not be explicitly identified. Use of materials from other sources within a thesis should not be construed as a claim over them.
A non-exclusive, non-transferable licence is hereby granted to those using or reproducing, in whole or in part, the material for valid purposes, providing the copyright owners are acknowledged using the normal conventions. Where specific permission to use material is required, this is identified and such permission must be sought from the copyright holder or agency cited.
Liability statement
By using a Digitised Thesis, I accept that Trinity College Dublin bears no legal responsibility for the accuracy, legality or comprehensiveness of materials contained within the thesis, and that Trinity College Dublin accepts no liability for indirect, consequential, or incidental, damages or losses arising from use of the thesis for whatever reason. Information located in a thesis may be subject to specific use constraints, details of which may not be explicitly described. It is the responsibility of potential and actual users to be aware of such constraints and to abide by them. By making use of material from a digitised thesis, you accept these copyright and disclaimer provisions. Where it is brought to the attention of Trinity College Library that there may be a breach of copyright or other restraint, it is the policy to withdraw or take down access to a thesis while the issue is being resolved.
Access Agreement
By using a Digitised Thesis from Trinity College Library you are bound by the following Terms & Conditions. Please read them carefully.
Learning to A n n otate M usic Files using Content B ased
R etrieval System s and W avelet Packet A pproxim ations of
the Input Signals
M arco G rim aldi
A thesis su b m itted to th e U niversity of Dublin, T rinity College
in fulfillment of th e requirem ents for th e degree of
D octor of Philosophy
^TW ITY college
'
sLearning to A nn otate M usic Files using Content B ased
R etrieval System s and W avelet Packet A pproxim ations of
the Input Signals
A p p roved by
D eclaration
I, the undersigned, declare th a t this work has not previously been su b m itted to th is or any o ther University, an d th a t unless otherw ise stated , it is entirely my own work. T his thesis m ay be borrow ed or copied upon request w ith the perm ission of the L ibrarian, U niversity of Dublin, Trinity College.
T h e copyright belongs jo in tly to th e U niversity of D ublin, T rinity College an d M arco G rim aldi
1
J
Marco Grimaldi
Acknowledgement s
My m ost sincere g ra titu d e goes to Prof. P a d ra ig C unningham who has helped me greatly in the th ree years I spent a t th e C om puter Science D ep artm en t of T rinity College as P o st-G rad u ated S tudent. His su p p o rt, friendship and constcuit help in research and everyday life facilitated me in understzinding the new topics under study and to become p a rt of a to tally new environm ent.
A very special and personal th a n k goes to my family. My p arents and my sister have always encouraged me in taking th e right decision, even if it brought me far away from them .
A special th a n k goes to Lorcan Coyle an d Conor Hayes for th eir friendship. W ith o u t their dedication and help life would have been to ugh for an Italian w ith fairly bcusic English. To D arren and Conor, th a t ta u g h t me th a t music is not only som ething th a t com puters can somehow learn.
I also express my g ra titu d e to all my friends back in Italy for th eir su p p o rt and encourage m ent in this th ree years. Lucio, C hiara, Luca, G ianpiero, Daniele, Michele, A ndrea, C hristian, P a trizia and M arco are special persons th a t wellcommed me as I never left T rento. I owe a special acknow ledgem ent to A ndrea Ghizzi for th e endless discussions a b o u t alm ost every aspect of this research.
A final acknowledgem ent goes to th e people I m et in D ublin £md w ith which I shared good and bad m om ents: Jo h n L., Conor N., Donal, Mick, Sarah Jan e, P atrick , Derek, Ken, D eirdre, Nail, N adia, Alexei, A drian, C hristine, Janies, Colm, Elaine, Jennifer, Luca an d A ndrea. M any thanks to Derek and Ken for their help in the last couple of weeks before the subm ission: w ithout their su p p o rt it would have taken ages.
M a r co G rim a ld i
Abstract
This thesis presents an inter-disciplinary approach to th e problem of music p aram etrisatio n for inform ation representation and retrieval. Signal analysis an d m achine learning techniques are combined in th e context of music characterisation. T he vast am ount of music available electroni cally presents considerable challenges for inform ation retrieval. T his research focuses on fc-nearest neighbour classifiers for content base retrieval of music files. Classifiers th a t su p p o rt queiy by example are presented and evaluated. T he thesis presents a process for determ ining th e genre of a music file using a new set of descriptors. A recent techni(iue based on th e wavelet transform is the core techrii<iue used for characterisation: a discrete wavelet packet transform is applied to ob tain th e signal representation a t different decom position levels. Tim e and frequency features are ex tracted from these levels tak in g into account the specific re(iuirernents of music param etrisation; its tim e and frequency constraints.
Contents
A c k n o w le d g e m e n ts iv
A b s tr a c t iv
L ist o f F ig u r e s x
L ist o f T a b les x ii
C h a p te r 1 I n tr o d u c tio n 1
1.1 Foreword ... 1
1.2 Problem context and m o tiv a tio n s... 2
1.3 Problem domain ... 3
1.4 Signal analysis ... 3
1.0 Lazy le a r n in g ... 4
1.5.1 Feature selection... 4
1.5.2 Ensemble techniques... 5
1.6 Thesis c o n tr ib u tio n s ... 5
1.7 Related p u b lic a tio n s ... 6
1.8 Structure of the t h e s i s ... 7
C h a p te r 2 T h e M u sic I n fo r m a tio n R e tr ie v a l P r o b le m a n d T h e C h a r a c te r isa tio n o f A u d io S ig n a ls 9 2.1 Foreword ... 9
2.2 Retrieving information from audio s i g n a l s ... 10
2.3 General fra m e w o rk ... 11
2.4 Audio features in the l i t e r a t u r e ... 12
2.4.1 Time domain f e a t u r e s ... 12
2.4.2 Frequency domain features ... 14
2.4.3 Psychoacoustic f e a t u r e s ... 16
2.5 The wavelet transform as an alternative analysis a p p ro a c h ... 19
2.6 S u m m a r y ... 20
C h a p te r 3 T h e W a v elet TV ansform : C h a r a c te r is a tio n o f M u sic S ig n a ls 21 3.1 Foreword ... 21
3.2 The elementary function: from a physical point of view ... 22
3.3 The windowed Fourier t r a n s f o r m ... 23
3.4 The wavelet tra n s f o rm ... 26
3.4.1 Multiresolution a p p r o x im a tio n ... 27
3.4.2 Mathematical properties of wavelet bases ... 30
3.5 Wavelet packet t r e e ... 33
3.5.1 Wavelet packet filter b a n k s ... 37
3.6 Extracting features using a wavelet packet tra n s fo rm ... 39
3.7 Shift in v aria n ce... 40
3.7.1 Feature definition... 41
3.8 T im e-featu re s... 42
3.8.1 Decomposition l e v e l ... 43
3.8.2 Number of sub-bands ... 46
3.9 F requency-features... 48
3.10 S u m m a r y ... 51
C h a p te r 4 fc-NN: In s ta n c e B ased C lassifiers 52 4.1 Foreword ... 52
4.2 Lazy and eager learning a lg o rith m s... 53
4.2.1 The fc-NN classifier... 55
4.2.2 Artificial Neural Networks: the two-layer p e r c e p tro n ... 56
4.3 Evaluation of the performance of a classifier ... 58
4.4 Feature s e le c tio n ... 59
4.4.1 Evaluation of the best feature s u b s e t ... 61
4.4.2 Search A lg o rith m s ... 63
4.5 Overfitting the d a t a ... 65
4.6 Feature selection based on information gain ratio... 67
4.6.1 Information g a i n ... 67
4.6.2 Information gain r a t i o ... 68
4.6.3 The proposed feature selection te c h n iq u e s ... 68
4.7 Ensemble te c h n iq u e s ... 69
4.7.1 Manipulating the training examples... 71
4.7.3 Manipulating the output targets... 72
4.7.4 Injecting randomness... 73
4.7.5 The proposed ensemble te c h n iq u e s ... 74
4.8 S u m m a r y ... 75
C h a p te r 5 C lassify in g A u d io F ile s by M u sic G e n re s 77 5.1 Foreword ... 77
5.2 Evaluation m e th o d o lo g y ... 78
5.3 Evaluation and d is c u s s io n ... 78
5.3.1 Bounding the number of time f e a tu r e s ... 79
5.3.2 Bounding the number of frequency f e a t u r e s ... 83
5.3.3 Combining time and frequency f e a t u r e s ... 86
5.3.4 Varying the number of classe s... 89
5.3.5 Varying the typology of c la s s e s ... 91
5.3.6 Applying artificial neural n e t s ... 92
5.4 Related w o r k ... 96
5.5 S u m m a r y ... 98
C h a p te r 6 U s e r T a ste P re d ic tio n b y U se r P ro filin g 100 6.1 Foreword ... 100
6.2 Smart Radio ... 101
6.3 Evaluation m eth o d o lo g y ... 102
6.4 Evaluation and d is c u s s io n ... 103
6.4.1 Unbalanced d a t a s e t s ... 103
6.4.2 Balanced datasets ... 105
6.5 Related w o r k ... I l l 6.6 S u m m a r y ... 114
C h a p te r 7 C o n clu sio n s a n d F u tu r e W o rk 115 7.1 Thesis summary ... 115
7.2 Thesis conclusions and c o n trib u tio n s... 116
7.3 Suggestions for future w o r k ... 118
7.3.1 Signal analysis and audio files c h a ra c te ris a tio n ... 118
7.3.2 Classification of audio signals by music g e n r e ... 119
A p p e n d ix A F e a tu re s 120
A p p e n d ix B D a ta s e ts 123
List of Figures
2.1 F ra m ew o rk o f a g en e ral re trie v a l s y s t e m ... 11
2.2 A u to c o rre la tio n fu n c tio n o f an h a rm o n ic s i g n a l ... 13
2.3 S p e c tro g ra m a n d tim e envelope o f a w a v e fo r m ... 15
2.4 T h e M el S cale [ 9 5 ] ... 17
3.1 H eisenberg Boxes for 2 differen t e le m e n ta ry f u n c ti o n s ... 23
3.2 T im e -F req u en c y tillin g defined by th e w indow ed F o u rie r t r a n s f o r m ... 24
3.3 G au ssian w indow s used in th e W F T ... 25
3.4 T im e-freq u en cy tillin g defined by th e w avelet t r a n s f o r m ... 27
3.5 D aubechies filter w ith 2 (a), 4 (b), 8 (c) a n d 16 (d) v anishing m o m e n ts ... 33
3.6 C h c iracterisatio n of th e tim e envelope of a s o u n d ... 34
3.7 Full w avelet p ack et t r e e ... 34
3.8 E x am p le of ad m issib le w avelet p ack et b in a ry t r e e ... 35
3.9 A dm issible tre e a n d H eisenberg Boxes for a given w avelet p ack et b a s i s ... 38
3.10 W avelet p ack et d eco m p o sitio n (a) a n d re c o n stru c tio n (b) 39
3.11 T im e -F e a tu re e x tra c tio n d i a g r a m ... 42
3.12 T h e sy n th e siz ed s i g n a l ... 44
3.13 Beat-histogram: j = 9, wavelet; D a u b 2 ... 45
3.14 Beat-histogram: j = 12, wavelet: D a u b 3 2 ... 45
3.15 Beat-histogram of a sample music f i l e ... 47
3.16 Prequency-features extraction d ia g ra m ... 49
3.17 F requency sp e c tru m o f th e sy n th e siz ed so u n d (figure 3 . 1 2 ) ... 50
4.1 P ro b le m space, so lu tio n space a n d m a p p in g f u n c t i o n ... 53
4.2 56 4.3 S chem a of a feedforw ard m u ltila y er (2 layers) p e r c e p t r o n ... 57
4.4 T h e filter a p p r o a c h ... 62
4.5 T h e w ra p p e r a p p r o a c h ... 62
4.7 F eature space decom position perform ed by feature sub-space based ensembles . . . 72
4.8 Solution space decom position perform ed by one-against-all (a) and round-robin (b) e n s e m b le s ... 73
5.1 Simple ^-NN (SKNN) perform ance using tim e -fe a tu re s ... 80
5.2 Round-robin ensemble (RRE) perform ance using t i m e - f e a t u r e s ... 81
5.3 O ne-against-all ensemble (OAE) perform ance using tim e - f e a tu r e s ... 82
5.4 F eature sub space beised ensemble (FSSE) perform ance using tim e-features . . . . 83
5.5 Accuracy curves of a simple fc-NN, R R ensem ble and OAE ensemble for 4 different signal representations. Only frequency features have been taken into account. . . . 84
5.6 Accuracy curves of a FSS ensemble varying the num ber of ensem ble m em bers. . . . 85
5.7 Accuracy curves of different classifiers varying th e num ber of nearest neighbours. . 87
5.8 Accuracy curves of FSS ensemble varying th e subspace dim ension... 87
5.9 Accuracy curves of FSS ensemble varying th e num ber of m em bers... 88
5.10 Accuracy curves of different classifiers train e d on a 5 class problem (d a taset Sclasses). 88 5.11 Accuracy curves of an FSS ensemble varying num ber of classes (music genres). . . 90
5.12 Accuracy curves of an FSS ensemble varying th e typology of th e classes (music genres). 91 5.13 SANN, RRANN and FSSANN on the 4classes d a t a s e t ... 93
5.14 SANN and RRANN on the Sclasses and dclasses d atase t ... 94
5.15 SANN and RRANN on the 7classes d a t a s e t ... 95
5.16 FSSANN on 3 different datasets {Sclasses, 6classes and T c l a s s e s )... 95
6.1 Perform ance of a fc-NN on unbalanced d a t a s e t s ... 103
6.2 Perform ance of a FSSE on unbsilanced d a te u se ts... 105
6.3 Perform ance of a A:-NN on balanced d atasets ... 106
6.4 Perform ance of a FSSE on balanced d atasets ... 108
6.5 Music preference by genre (User 17) ... 110
6.6 Music preference by genre (User 18) ... 110
List of Tables
3.1 W avelet packet tree m atching music n o t e s ... 41
3.2 Time resolution [bpm| for different wavelet families and levels ... 44
3.3 Sub-band definition ... 46
3.4 Frequency bins matching musical s c a l e s ... 49
5.1 Classifiers accuracy using 12 tim e f e a t u r e s ... 84
5.2 Classifiers accuracy using 32 fre<juency f e a t u r e s ... 86
5.3 Confusion m atrix for a feature sub-set ensemble (e.g. 6 Rock tracks have been classified as Heavy M etal)... 89
5.4 Confusion m atrix for a feature sub-set ensemble train ed on a 6 class problem . . . . 90
5.5 Confusion m atrix for a feature sul:)-set ensemble train ed on a 7 class problem . . . . 90
5.6 Confusion m atrix for a feature sub-set ensemble train ed on d ata se t 5classes(b). For w ard hill-clirnbing search is applied 92 5.7 Confusion m atrix for a feature sub-set ensem ble train ed on dataiset 5classes(c). For ward hill-clirnbing search is applied 92 5.8 Accuracy of ANN, RRANN and FSSANN-50 on 4 different d a t a s e t s ... 96
5.9 Confusion m atrix presented by Tzanetakis et al. [ 7 2 ] ... 97
5.10 P ortion of th e results presented in [100] ... 97
6.1 /:-NN on unbalanced datasets: sam ple confusion m atrices ... 104
6.2 FSSE on unbalanced datasets: sam ple confusion m a t r i c e s ... 105
6.3 Accuracy of a fc-NN on balanced d a t a s e t s ... 107
Chapter 1
Introduction
1.1
Foreword
T he aim of this thesis is to combine signal analysis technicjues together w ith m achine learning m ethodologies in order to produce a system able to recognise music in a t least one of its dimensions: music genre (i.e Classical, Jazz, Rock, etc.).
M odern technology allows people to walk around with a huge am ount of music in their pockets. T he storage capacity of these new generation walkrnans is impressive: it is possible to record entire music collections in a few cubic centim etres. In this context, it is extrem ely useful to a n n o tate music files w ith descriptors in order to facilitate their retrieval. Given a set of rneaningfull descriptors ex tracted from signal analysis, a large music collection can be au tom atically an n o tated . C ontent retrieval of rrmsic files together w ith a query by example capability can be provided.
This work focuses on different predictors based on th e fc-nearest neighbour classifier (fc-NN). k-NNs derive th eir outcom e from th e definition of a sim ilarity m easure betw een item s; thus, a ranked list of objects sim ilar to a given query can be generated. A new set of descriptors is ex tracted thro u g h a wavelet packet analysis of th e music files. T he features cire evaluated in th e context of music genre and user ta s te prediction. Artificial neural nets, despite prohibiting context retrieval of inform ation, are introduced in order to b e tte r assess the predictiveness of th e proposed signal characterisation.
is a little b e tter th a n random . However, the evaluation seems to suggest th a t when th e user profile is biased tow ard a well defined genre, th e system is able to achieve reasonable accuracy. So, while we can classify music files by genre fairly well, we can not predict w hether or not people will like them .
1.2
Problem context and m otivations
The beginning of this new m illennium is characterised by a strong ap p e tite for content consum ption and distribution. T he new digital world rapidly grows its dem and for inform ation encapsulated in a variety of different forms. Audio and video stream s are continuously requested, delivered, shared and red istrib u ted am ong content providers and users. Since the first world wide known file-sharing system , N apster, the tools provided to th e users were m ainly tex tu al. G eneral purpose search engines rely on th e same tex tu al tools to access different kinds of inform ation. In fact, a t the beginning of th e In tern et, th e intrinsic lim itation of the m edium itself has forced the inform ation to circulate in form of w ritten te x t. W ith the co n stan t increase in th e capacity of th e In te rn e t to make people com m unicate and shcire inform ation in aiiy form, th e need for easier access, retrieve and consum ption of content grows extrem ely fast. W orld wide, a num ber of research initiatives a tte m p t to m eet the new needs by enabling th e use of nm ltirnedia resources across a wide range of networks and devices. In R&D divisions of p rivate com panies cus well as in academ ic research in stitutions a num ber of m ultim edia fram eworks and prototypes have been developed and deployed. C haracterisation and recognition of still images, speech, sound, music are ju st a few exam ples of the topics th a t m achine learners together w ith engineers and physicists try to tackle. Segm entation of au dio/visual stream s for au to m atic footage creation and content consum ption has been explored [671.
Mpeg-7 which concentrates on th e description of m ultim edia content. It enables quick and efficient searching, identification and processing of m ultim edia m aterial.
Research projects aim ed a t m ultim edia representation, like M O U M IR (M Odels for Unified M ul tim edia Inform ation Retrieval) [3] p ro ject, received (and continue to receive) enorm ous a tten tio n in academ ic institutions. A renewed interest in com bining different branches of science (signal analy sis, m achine learning, social science, physics, engineering, ...) reflects the need for m ultim edia d a ta p aram etrisatio n . In fact, m ultim edia m aterial request cmd availability is furtherm ore amplified by the existence of broad band In tern et connection, cheaply available for dom estic use. T he interest in nm ltim edia consum ption needs the developm ent of unified frjimeworks for th e retrieval of in form ation from unorganised databases; new p aram etric models for nm ltim edia d a ta records which combine inform ation from audio, video an d te x t stream s are the final objectives of m any of those research projects.
1.3
Problem dom ain
Since 1999, music has been one of the m ost requested and shared kind of n on-textual d a ta stream . N apster has shown to the world new possible developm ent directions b o th for business and re search. T he possibility of directly targ etin g the consum er w ithout th e need of m anufacturing and d istrib u tin g a physical product was, in fact, th e original appeal of digited music to the industry. U nfortunately, while the new opportunities given by file-sharing netw orks have been m ore th an happily welcomed by users, th e music in d u stry has shown incredible reluctance in em bracing the new technology and developing new business models. However, recently, new system s th a t meet user needs and copyright-holder dem and fiave been proposed by different com panies. T he Apple iTunes technology (togetlier w ith the iPod p o rtab le player) has certainly proved th a t music dis trib u tio n via In tern et is a prom ising area where business and technology investm ents can play an im p o rtan t role. Microsoft appears to be th e next big investor in th e on-line music distribution business. Phillips heus shown interest in Palm -held juke-box, where music p aram etrisatio n is used for enhancing th e user enjoym ent. In a scencu:io where a huge databcise of n on-textual inform a tion needs to be easily accessed for item retrieval, th e technology needs indeed to provide new ch aracterisation methodologies.
1.4
Signal analysis
athernat-ics, physics and signal processing. It is a tool th a t enables the representation of the com ponent frequencies of th e object of interest w ith resolution m atching its scale. T he wavelet transform has received enorm ous a tte n tio n from very different research areas. Statistics, tim e series ancdysis, biological d a ta , image processing, de-noising and com pression are few exam ples of areas where the transform have been applied. In th e thesis, th e m athem atical properties of the discrete wavelet packet transform are used to m eet the need of tem po and harm ony chciracterisation of music: its nm ltiresolution capabilities are used to m eet th e tim e and frequency resolution needed. The discrete wavelet packet transform is applied to obtain th e signal representation a t different decom position levels. Tim e and frequency features are ex tracted from these levels tak in g into account the n a tu re of music.
1.5
Lazy learning
A. vciriety of sam ple music collections form the corpus exarninandi of a supervised learning problem . The k nearest neighbour (fc-NN), an instance based lazy clcissifier, is th e base predictor upon which a variety of learning technicjues are explored and deployed. T he fc-NN tcikes a straightforw ard approach for classification: th e learning process consists in sim ply storing th e presented d a ta . All instances correspond to points in an rt-dirnensional space and th e nearest neighbours are defined in term s of th e sta n d a rd Euclidean distance. T he prediction for an unseen object ((}uery) is inferred from th e class of th e nearest instances. Such a mem ory based predictor, despite its simplicity, enables th e retrieval of item s b£used on th e content. T he classifier retziins m em ory of local properties (nearest neighbours) of the problem space; it allows the calculation of a ranked list of item s th a t are sim ilar to a given query. Artificial neural nets - classifiers th a t are usually m ore powerful th a n simple fc-NNs - do not enable such a ranking to be generated.
1.5.1
F eature selectio n .
1.5.2
Ensem ble techniques.
One of th e m ost significant developm ent in th e m achine learning research a re a in recent years is the introduction of ensembles of classifiers. T he ensemble model can offer rem arkable im provem ents in accuracy and increased stability over single predictors. An ensemble is com posed of two elements: a set of properly tra in e d classifiers and Ein aggregation m echanism th a t composes the single pre dictions into a unicjue outcom e for th e given query. A variety of m ethods for building and training an ensemble of classifiers is presented in literatu re. M anipulating th e train in g exam ples or the input features together w ith th e reorganisation of the o u tp u t targ ets or injection of random ness are exam ples of different m ethodologies studied and proposed by different researchers.
The thesis proposes a direct com parison of the perform ance of different ensembles in classifying music item s by genre. Ensembles of classifiers th a t perform problem space decom position together with ensembles th a t perform solution space decom position are presented and evaluated. Feature selection based on inform ation gain ratio is explored an d its im pact on th e perform ance of simple classifiers an d ensem ble of classifiers is evaluated. In order to b e tte r assess th e capability of the proposed features in paxam eterising music item s for genre recognition and to b e tte r relate to th e literatu re, this work proposes eus well an evailuation using artificial neural nets as the bcise classifier. R ound-robin ensembles , together w ith feature sub-space based ensembles and “simple” m ultilayer perceptrons are evaluated. We will show th a t such classifiers b e tte r suit the recognition problem proposed. However th e gain in accuracy is paid for in term s of interpretability: any local inform ation ab o u t tfie problem space nearby th e given query is lost.
In th e last ch ap ter, th e thesis extends the p ararn etrisatio n of music item s from a genre prediction task to the m ore com plex and less straightforw ard problem of music ta s te prediction. M aintaining the sam e item p aram etrisatio n used for genre recognition and using fc-NN based predictors, the thesis analyses a num ber of user profiles recorded from a local on-line music stream ing service [4] th a t was available for the students of th e D epartm ent of C om puter Science a t T rinity College Dublin.
1.6
T hesis contributions
T he thesis contributes to th e problem of music p aram etrisatio n an d its application in m achine learning. T he thesis proposes a new set of features for m usic description th a t are obtained through a wavelet packet decom position of th e in p u t signal. T he work em phasises the adoption of feature selection m ethodologies and ensemble techniques for b e tte r generalisation. M oreover, it em phasises th a t ensembles m inim ise the possibility of overfitting.
tim e resolution of the wavelet packet decom position enables th e characterisatio n of the beat and tem po properties of music. By selecting a level of decom position suitable for frequency characterisation, music notes can be recognised and param etrised. By selecting a level of decom position suitable for tim e ch aracterisation, th e beat of th e song can be estim ated.
• T he thesis tackles the problem of dim ensionality reduction by im plem enting a feature se lection strateg y based on inform ation gain, according to th e w rapper m odel. T he im pact of forward hill-climbing and backw ard hill-climbing feature selection is evaluated by varying the clcussifier typology (simple or ensemble).
• T he thesis presents and exhaustive com parison of th e perform ance of th ree different ensemble techniques: one-against-all, round-robin a n d features sub-space ensembles based on the k-NN classifier. T he accuracy scores are com pared not taking into account an o priori defined num ber of features. The representation of th e music genre prediction problem is varied in or der to b o th minim ise overfitting issues and m axim ise the ability of th e different predictors to generalise. A variety of music databases are used to te st th e ability of th e given technique to generalise in different situations. In order to assess th e effectiveness of th e features proposed in describing music files for genre classification an d b e tte r com pare w ith th e literatu re, we propose an evaluation using artificial neural nets as base predictors. Simple two-layer percep>- trons and ensemble of m ultilayer perceptrons are evaluated and com pared. T he results show th a t artificial neural nets suit th e p a rticu lar classification problem , showing good results in generalising th e problem .
• T he thesis raises some issues deriving from th e non perfect definition of th e class (genre). It clearly shows th a t th e accuracy of the predictor is highly dependent on th e chosen classes.
• T he thesis evaluates the possibility of applying th e a A:-NN system for user ta ste prediction and recom m endation. Analysing the user profiles of an on-line radio available in the Com puter Science D epartm ent of the T rinity College (Sm art R adio), it presents an evaluation of ta ste prediction based on th e ability of recognising music genres. W hile th e general behaviour of th e predictors in this scenario is not excellent, it appears th a t th e classifiers succeed in the recognition when the music genre describes th e user taste.
1.7 Related publications
• M. G rim aldi, P. C unningham , E xperim enting w ith Music T aste P rediction by User Profiling, ACM W orkshop in M ultim edia, New York, NY, O ctober 2004.
• M. Grimaldi, P. Cunningham, A. Kokaram, An Evaluation of Alternative Feature Selec tion Strategies and Ensemble Techniques for Classifying Music, in Workshop in Multimedia Discovery and Mining, ECM L/PKDD03, Dubrovnik, Croatia, September 2003.
• C. Hayes, P. Cunningham, P. Clerkin, M. Grimaldi, Programme-driven music radio, Proceed ings of the 15th European Conference on Artificial Intelligence 2002, Lyons France. ECAI 2002, F. van Harmelen (Ed.): lOS Press, Am sterdam, 2002.
1.8
Structure of the thesis
C h a p te r 2: presents the problem of retrieving information from audio signals cus a research area. Moreover we introduce the general framework of a retrieval system, outlining its main characteristics. Finally we present a review of different features extracted from the audio signal and presented in the literature as key param eters used in different studies.
C h a p te r 3: introduces some notions useful to understand the principles of the wavelet tran s form. Starting with the concept of elementary function, we introduce the windowed Fourier trans form as a techni(jue useful to parametrise local properties of a general function /. The wavelet transform is illustrated aus a further improvement to the windowed transform. The mathematical properties of such a technique are presented as well as its rnultiresolution analysis capabilities.
C h a p te r 4; presents a review of some basic concepts of the branch of information science defined <is machine learning. Focusing on classification problems, we present the basic concepts of a lazy learner and an eager learner. The basic idea behind the two kind of predictors is presented; a classical example of lazy learner and instance bcise clcissifier - the fc-nearest neighbour classifier - is introduced and formally described. Feature weighting and feature selection are introduced as techniques to improve the performance of a fc-neaxest neighbours classifier. W ith particular attention to overfitting problems th at can derive from the learning process, we review the most popular techniques used for feature selection. In the last part of the chapter we introduce the concept of ensembles of classifiers and how this kind of predictor can alleviate loss in accuracy due to overfitting issues. The main methodologies applied to build an ensemble of classifiers are presented and the different techniques adopted in this work are illustrated. Moreover, the chapter briefly presents a particular kind of artificial neural network: the two-layer perceptron. Such a classifier is introduced in the context of b etter assess the predictiveness of the features presented in the previous chapter, given its capabilities of model non linear functional maps.
representations of th e sam e datab ase. Each representation differs in the num ber of peaks taken into account. T hrough a com parative analysis of the classifier perform ance, we bound the num ber of tim e and frequency features, thus trying to m inim ise the possible overfitting issues. T he best classifier is then tested on a num ber of different d a tasets in order to estim ate its ability in generalise th e given problem in different conditions. We show th a t a feature sub-space based ensemble of fc-NN outperform s the o th er kinds of ensembles in music genre classification. We present an evaluation of the ability of such an ensemble to generalise sim ilar problem s. By train in g the classifier on different d atasets vEu:ying th e num ber of genre taken into account, we show how th e perform ance degrades. Moreover we show the effect of the fuzziness in th e problem definition by varying the typology of classes (music genres) taken into account, while keeping co n stan t th e to ta l num ber of classes. Finally, in o rd er to b e tte r cissess th e effectiveness of th e features proposed in describing music files for genre classification, we propose an evaluation using artificial neuraJ nets as base predictors. R ound-robin ensembles and feature sub-space based ensembles to g eth er w ith simple neural nets are evaluated and com pared. T he results indicate th a t artificial neuraJ nets suit b e tte r the p articu lar classification problem .
C h a p t e r 6: extends the use of the signal approxim ation and ch aracterisation from genre clas sification to a m ore difficult problem : th e recognition of user taste. T he baaic idea is to try to recognise music preferences by applying instance based classifiers to user profiles. T he item s axe classified against th e user ta ste synthesized in his/fier personal profile. User profiles have been collected in a tim e span covering th ree years. Sm art Radio, a music recorim iender project, is the source of the d a ta se ts analysed in the chapter.
Chapter 2
The Music Information Retrieval
Problem and The Characterisation of
Audio Signals
2.1
Foreword
In recent years, the interest of the research community in indexing rrmltimedia data for retrieval purposes has grown considerably [67]. In fact, the exponentied growth of multimedia content in databases, broadcast, streaming media, etc. has generated new requirements for effectively accessing repositories of global information. Content extraction, indexing and retrieval cis a whole is one of the most active and fast-growing research areas. As we enter the digitzJ multimedia information era, tools th at enable an autom ated analysis are becoming indispensable to efficiently access, digest and retrieve information. There is the need to develop robust and reliable technicjues for modeling multimedia data. New scalable and content sensitive browsing algorithms are required to easily access the vast amount of available data.
Information retrieval, as a field, has existed for some time. Until recently, however, it focused its attention on understanding text information: how to extract key words from a document, how to summEirise a document or how to catalogue it. W ithin a multimedia document the semantics are embedded in different forms th a t usuedly complement each other [67]. For example, live coverage on TV about war actions convey information th a t is far beyond what we hear from the reporter. We can see the effects of bombing, soldiers in action, children crying while we hearing the reporter talking about, i.e, political issues. Therefore we have to analyse all type of data: image frames, sound tracks, texts, etc.
area. M oreover we introduce the general fram ew ork of a retrieval system , outlining its m ain characteristics. Finally, we present a review of different features ex tracted from th e audio signal and presented in the literatu re as key p aram eters used in different studies.
2.2
R etrieving inform ation from audio signals
A very p articu lar field of research for sem antic m eaning u n derstanding is th e music. A lthough m usic is a “m ono-m edia” docum ent, we perceive it in very different ways, depending on our ta s te and our m ood. In music, i.e., we hear the m elody of a p articu lar in stru m en t, or th e lyrics being sung while we appreciate the rh y th m of the song itself. As in the case of m ultim edia docum ents, we need to e x tra c t inform ation from such a m edia for browsing, cataloguing or classification. In fact, music encloses different kinds of inform ation. W hen we classify a piece of rmisic into a genre {as classic, pop, rock, jcizz ...) we have to consider different characteristics of th e p articu lar music: th e playing instrum ents, the style of th e perform er, th e rhythm ic sense expressed and much m ore. In scenarios like web broadcasted radios or web based music stores, consum ers have access to a rncussive am ount of d a ta , and a good characterisatio n of th e d a ta could allow a fcust or a b e tte r browsing process between item s.
Music inform ation retrieval (M IR) has trad itio n ally been divided in two m ain branches: sym bolic M IR and audio MIR. A symbolic representation of music such as M IDI describes item s in a sim ilar way to a musical score. A ttack, d u ratio n , volume, velocity an d in stru m en t type of every single note are available inform ation. Therefore, it is possible to access statistical m easure such as tem po estim ation and m ean key for each music item [71]. M oreover, it is possible to a tta c h to each item high-level descriptors such as in stru m en t type.
On the other hand, audio M IR deals w ith real world signals. Any feature needs to be ex tracted through signal analysis. In fact, ex tractin g a sym bolic representation from an a rb itra ry audio signal (polyphonic tran scrip tio n ) is Eui open research problem , solved only for sim ple exam ples [75, 77]. However, recent studies show th a t it is possible to apply signzil processing techniques to e x tra c t features from audio files and derive reasonably accu rate classification by genre [72, 74, 69, 100]. O ther im p o rtan t examples of signal processing techniques applied to the audio dom ain involve discrim ination between speech an d music [79]; tem po an d b eat estim ation [87, 72]; audio retrieval by exam ple [70].
2.3
General framework
Audio inform ation retrieval system s - as general retrieval ones - show co n stan t characteristics in their stru ctu re, regardless of th e chosen features. T he basic idea consists in representing the item s in a feature space, where the features define the inform ation granularity represented in the space itself. Defining a sim ilarity m easure betw een features allows us to calculate the degree of sim ilarity am ong elem ents (figure 2.1). Briefly, we can represent the stru c tu re of an inform ation retrieval system as follows:
• Definition of feature space;
• Definition of sim ilarity m easure betw een elem ents.
feature space
transform
comp arison
transform
Database
Out com e
F ig u r e 2.1: Fram ew ork of a general retrieval system
Once these two requirem ents are fulfilled, it is possible to e x tract inform ation stored in a d atab ase via a query. For exam ple, it is possible to recognise different musical genres, or to sort a random list of item s based on the sim ilarity m easure, e.g. for browsing purposes. T h e quality of the response of the system will depend on different param eters. In general, its efficiency will depend on th e chosen features and on th e defined sim ilarity m easure. In fact, if th e selected features are not item descriptive, th e retrieval system will not be able to produce significant results. In the same way, if the sim ilarity m easure is not well defined m athem atically or does not tak e into account p articu lar sym m etries of th e feature space or border constraints, th e system response could lack precision.
[image:25.533.21.522.39.811.2]2.4
Audio features in the literature
Signal analysis techniques do not com pare directly pressure signals in order to estim ate the sim ilarity am ong different item s. T h a t is because a tim e dom ain com parison is not an exhaustive m ethodology in the context of similcirity. For exam ple, two signals representing spoken words can
from a two-dim ensional analysis space: th e tim e-frequency space. T his approach is justified from a psycho-acoustic point of view also. Many experim ents show th a t hum an aud ito ry system seems to analyse waveform directly focusing on changes in am plitude, loudness, frequency cind pitch [73, 98]. T he ear seems to perform tim e-frequency feature ex traction via a special m echanism in th e inner ear [73]. Volume properties, tim e envelop ex tractio n , frequency m apping, zero crossing ratio axe a few exam ples of features proposed and explored in the literatu re.
In th e next sections we present some exam ples of features applied in different studies. T he features we present are divided into four m ain categories: tim e domain features, frequency domain features, psychoacoustic features and rhythm ic features.
2.4.1
T im e d om ain featu res
V o lu m e T he m ost widely used an d easy to com pute feature is th e volume. It describes the loudness of th e signal and is used for silence detection and speech detection together w ith other features. T he com m on expression for volume calculation in the tim e dom ain is [67, 78[:
of the signal expressed in num ber of sam ples. T he volume is alternatively referred to as signal
Z e ro C r o s s in g R a t e Besides volume, the zero crossing ra te (ZCR) is an o th er widely used
m ost indicative an d robust m easures to discern unvoiced speech. Typically, unvoiced speech has be very different in th e tim e dom ain: differences between the kind of word being spoken, different kinds of speeiker (m ale, fem ale), different volume. In general, candidate features are calculated
w - i
( 2 . 1 )
where /[n ] is a discrete signal {f{t) will be used to denote an analogue signal) and N is the length
energy. Since th e volume of an audio signal depends on the gain value of the recording, in order to remove such a device-dependent condition, it is useful to norm alise it to th e m axim um value.
tem poral feature. ZCR, as th e words say, represents th e num ber of tim es th a t th e audio waveform crosses th e zero axis. Formally:
F
^ X ! \^^9n{f [n\ ) - s i gn{ f [ n - 1])| ( 2 .2 ) n = l
low volume but high ZCR. Using ZCR and volume together, one can avoid classifying low energy unvoiced speech as a silent section in a stream. [67, 74, 78].
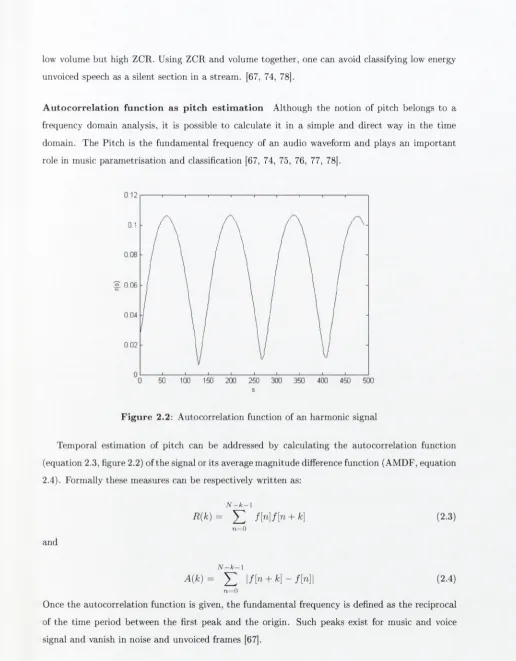
A u to c o r re la tio n fu n c tio n a s p itc h e s tim a tio n Although the notion of pitch belongs to a frequency domain analysis, it is possible to calculate it in a simple and direct way in the time domain. The Pitch is the fundamental frequency of an audio waveform and plays an im portant role in music param etrisation and clcissification [67, 74, 75, 76, 77, 78].
0,12
^ 0,06
0 04
002
100 150 200 250 300 350 400 450 500 S
F ig u re 2.2: Autocorrelation function of an harmonic signal
Temporal estimation of pitch can be addressed by calculating the autocorrelation function (equation 2.3, figure 2.2) of the signal or its average magnitude difference function (AMDF, equation 2.4). Formally these mezisures can be respectively written as:
N - k - l
R { k ) ^ f [n]f [n + k] (2.3)
n —0 and
N - k - l
A [ k ) = \f[n + k ] - f [ n ] \ (2.4)
n = 0
Once the autocorrelation function is given, the fundamental frequency is defined as the reciprocal of the time period between the first peak and the origin. Such peaks exist for music and voice signal and vanish in noise and unvoiced frames [67].
[image:27.533.8.524.19.680.2](music, noise, speech, n a tu ra l sounds ...) belonging to th e sam e stream [67, 69, 73, 74, 75]. De pending on the specific context, th e feature ex tractio n is perform ed for a few fram es or for a large subset of them . If this approxim ation enables us to efficiently process a huge am ount of sound d a ta , obtained from different sources, in music classification it can lead to errors or to a lack of precision. This point becomes clear if we consider th e following. A music genre m ay be recognised by way of th e musical key - characterised by specific frequencies - or th e m ean tem po a t which a p articu lar song is played. If we consider only a few seconds - fram es - out of several m inutes of a given song, we m ay e x tra c t features from only a p articu lar them e (chorus, bridge, etc.) of th e song. This fact m ay influence th e classification accuracy, p articularly in case of music genres where different sections are present. In this context, the error introduced by approxim ating the signal w ith frames is reduced as th e num ber fram es increases. The error will go to zero £is soon as we take into account enough frames.
Regardless of the choice of dividing th e signal in fram es (or shots) or considering it as a whole, the m athem atical expression of volume, ZCR and pitch (autocorrelation function and AMDF) rem ains th e same.
2.4.2
F requency d om ain featu res
As in th e case of tim e dom ain features, different sets of features can be ex tra c te d from th e signal, taking into account th e frecjuency dom ain. T hese features are ex tracted from the signal via a Fourier transform or a windowed Fourier transform (som etim es referred to as short tim e Fourier transform - S T F T ) analysis. Generally, frequency sta tistic s are calculated from the spectrogram of the signal. The spectrogram of a signal (figure 2.3) is defined as the square m agnitude of the windowed Fourier transform of th e signal itself;
(2.5)
E quation 2.5 gives th e spectrogram of a signal f { t ) , d enoted by S f { u , Q , in an tem poral interval centred on u and calculated for th e frequency In ch ap ter 3 we will present th e windowed Fourier transform in m ore detail.
M e d ia n f r e q u e n c y T he m edian frequency can be calculated from th e spectrogram as follows:
(2.6, th e m edian frequency is usually referred to as centroid frequency and is a m easure of the spectral brightness [72, 78, 94[.
500&1
& c V 3 CT S u.
m ■
i
liiTime (s)
0.847982
0.299
-041614
0 0.847982
Time (s)
F i g u r e 2.3: Spectrogram an d tim e envelope of a waveform
D W { u )
f M [ ^ , u]dS,
T he b an d w id th is used for speech, music, noise or n atu ra l signal classifications [67, 78, 94]. (2.7)
S p e c t r a l r o ll- o f f T he roll-off is ano th er widely used p aram eter ex tracted form a frequency do m ain analysis [72, 90, 94]. It is defined aus th e frequency Rt below which 85% of the spectrum m agnitude is co n cen trated . Defining Mu[^] ais the m agnitude of the Fourier transform a t fram e u and frequency interval the roll-off can be calculated as follows:
f i t N
^ A / [ e , u ] = 0 . 8 5 - ^ A f [ ^ , i,u\ (2.8)
U= 1 U—1
Roll-off is a m easure of th e changes in th e sp ectral shape varying the frequency interval.
S p e c t r a l flu x T he spectral flux [72, 90, 94] is defined cus the square difference between the norm alised m agnitudes of successive spectral distributions:
F . = ^ (iV „ [ e ] - 7 V „ _ i[ ^ ] ) 2 (2.9) C=i
P itch A lthough the notion of pitch is presented in section 1.2.1 , here we show how th e funda m ental frequency m apping of a waveform can characterise a music piece. As presented in [76|, the following algorithm allows to retrieve efficiently music item s. It is to be noted th a t frequency d eter m ination can be perform ed by analysing directly th e spectrogram or calculating the autocorrelation function.
1. D eterm ine th e lowest frequency appearing in the sp ectru m w ith am plitude above a certain threshold: f i .
2. Check if a correlated frequency (a fifth, fourth, m ajor or m inor th ird ) above / i appears in the sound:
/x = ^ / i , i = 2, ...,5 I
3. If yes /o = 7/0,
4. otherw ise fo — f i
-Pfeifer et al. [76| show fiow it is possible to efficiently characterise music for identification purposes w ith only one feature. Tzanetakis et al. [6 8] d em o n strate th a t a ch aracterisation of music involving th e estim ation of the pitch histogram [6 8] can be successfully applied to nmsic genre classification.
Aside from the presented ones, o ther different features are proposed in th e literatu re. Fea tu res developed to overcome different kinds of issues and achieve defined objectives are presented. Volume dynam ic change (VDC) or volume sta n d a rd deviation (VSTD) [67, 78] are two exam ples.
M ost fre<iuency features are defined sta rtin g from th e signal energy and from its spectrogram . T his fact implies th a t th ere could be a linear dependency between different features: some features can have sim ilar behaviour an d hence be red u n d an t [80]. However, the dependency can also be ascribed to p articu lar sym m etries or correlations in the in p u t signal. In th e case of music signals the dependency am ong features is furtherm ore am plified by th e n a tu re of music itself: n on-stationary harm onic signals. T he musical note th a t we perceive is com posed by a fundam ental frequency and a num ber of high and low harm onics. As we illu strate in ch ap ter 4, am ensem ble of classifiers can be m odelled in order to take advantage of this characteristic correlation am ong descriptors. In fact, since th e harm onics are the fingerprint of an instrum ent, a fine description of the signed can enhance its representation in the feature space.
2.4.3
Psychoacoustic features
an d engineers to co n cen trate on audible features and ignore less im p o rtan t characteristics of the given phenom enon. G enerally speaking, the hum an ear can usually hear sounds in the range 20 Hz to 22 kHz w ith a frequency resolution, in the m iddle range, of ab o u t 2 Hz: changes in pitch sm aller th a n 2 Hz can n o t be perceived.
A num ber of different studies in the literatu re take the psychoacoustic approach in o rd er to simplify th e signed description w ithout loosing im p o rta n t inform ation [96, 67, 95]. In th e next p arag rap h , we describe some of the m ost widely used psychoacoustic features presented in the literatu re.
M e l F r e q u e n c y C e p s t r a l C o e ffic ie n ts Mel Frequency C epstral Coefficients (M FCCs) [96] have been th e dom inant features used in speech recognition applications [67, 95]. T heir success and their ad o p tio n in a variety of different studies is due to th e ability of M FCCs to represent th e speech am p litu d e sp ectru m in a com pact form. T he Mel scale m aps th e real frequencies into th e pitch perceived by th e hum an au d ito ry system . T h e hum an au d ito ry system does not respond in a linear fashion to stim uli centred a t different frequencies. In order to sim ulate this p articu lar p ro p erty of th e hum an eeir, the Mel scale is linear below IkHz and logarithm ic above (figure 2.4).
3
C
3 c
frequency [Hz]
F ig u r e 2.4: The Mel Scale [95]
T he Mel C epstraJ Coefficients are obtain ed from the input signal using a num ber of successive tra n sfo rm atio n s:
• th e input waveform is converted into fram es of sm all length (typically 20ms), in which the signal can be considered statio n ary ;
• a discrete Fourier transform is applied to each frame;
• th e pha^se inform ation is discarded and the logarithm of the am plitude spectrum retained;
• a discrete cosine transform is applied to th e obtain ed M el-spectral vectors. This is done in
order to decorrelate th e M el-spectral vector com ponents.
Using this technique, aboiit 13 coefficients are obtained from each fram e.
C onsidering typical psychoacoustic param eters, other features Ccin be derived from th e input signal. In th e following we give th e definition of the concept of loudness, sharpness and roughness.
L o u d n e s s T he m ost basic p aram eter is loudness, also called "L au th eit". T he loudness is a m easure of th e sound level perception. T he symbol for loudness is N, and th e u n it is "sone". By definition, a sone has th e loudness of a 1 kHz tone a t 40 dB.
S h a r p n e s s T he sensation of sharpness is given in th e unit "acum ". One acuni corresponds to the perception of sharpness caused by band-pass noise a t 1 kHz w ith a level of 60 dB eind a bandw idth
of 200 Hz. T h e sensation of sharpness is generally produced by high-frequency sound com ponents.
R o u g h n e s s R oughness is the perception of the tem poral envelope m odulation in the range 20-150 Hz. T he roughness is generally considered to be the prim ary com ponent of musical dissonance.
An estim atio n of these p aram eters can be calculated according to different models [90, 99]. M oreover, some tool-boxes are available to perform psychoacoustic analysis of waveforms and for ex tractio n of features according to different au d ito ry representations [97].
2 .4 .4
R h y th m featu res
O ther interesting features concerning m usic classification are obtained by analysis of the rh y th m of th e in p u t signal. In th e literatu re, some researchers have focused th eir atte n tio n on m ethodologies for tem p o estim atio n and b eat analysis. T he notion of tem po and b eat is intuitive, b u t is som ew hat
difficult to define. It is clear to everyone w hat is th e rhythm ic sense expressed by a music piece, b u t its m ath em atical definition is not sim ple to form ulate. As proposed by Scheirer et al. [87], th e b e a t of a piece of m usic can be defined as th e sequence of equally spaced phenom enal impulses th a t define a tem p o for th e music. In this section we present two different approaches to tem po and b eat estim atio n in music: th e first one based on bandpass filters and banks of parallel comb
filters[87], th e second one on wavelet signal decom position and tim e envelope derived statistics[72].
B a n d p a s s f ilte r s a n d p a r a l l e l c o m b f ilte r s fo r t e m p o e s t i m a t i o n A ccording to Scheirer et
al. [87], th e in p u t signal (music or audio waveform) is divided into six bands using a filter-beink. For each of these sub bands th e am plitude envelope is calculated and its derivative taken. Each envelope derivative is passed on to ano th er filter-bank of tuned resonators-, in each resonator filter-
frequency matches the rate of periodic modulation of the envelope derivative. The output of these resonator filter banks is summed across frequency sub bands. By analysing the output from each resonance channel of the summed resonator filter banks, the strongest periodic signal component
may be determined. The frequency of the resonator with the maximum intensity output is selected as signal tempo.
W a v e le t sig n a l d e c o m p o s itio n a n d tim e e n v e lo p e d e riv e d s ta tis tic s Referring to chapter 3 for an introduction to the wavelet transform, in this paragraph we present the algorithm proposed by Tzanetakis et al. [72] for rhythm estimation. The rhythm feature set is based on detecting
the most salient periodicity of the signed. The signed is first decomposed into a number of octave frequency bands using a discrete wavelet transform. Following this decomposition, the time domain amplitude envelope of each band is extracted separately. The envelopes of each band are then summed together and an autocorrelation function is computed. The peaks of the autocorrelation
function correspond to the various periodicities of the signal envelope. The first five peaks of the autocorrelation function are detected and their periodicities in beats per minute are calculated and added to a beat histogram. The prominent peaks of the final histogram are use<l as the basis for the rhythm feature set definition.
2.5
The wavelet transform as an alternative analysis approach
The wavelet transform is a signal analysis technique [81j th a t is becoming the basic methodology in many applications dealing with signal processing. In general, the wavelet transform is a tool able to process an input signal and analyse its component frequencies at a tunable resolution. Such a technique ha*s been applied successfully to a variety of domains: from statistics to time series analysis; from biological d ata to signal and image processing. In fact, the application areais th at mostly benefit from a wavelet analysis and firstly dem onstrated the validity of such a technique
are signal de-noising-nosing and compression [81]. The wavelet approach has been explored in knowledge discovery in databcises as well: an interesting survey on wavelet applications in data- mining hcus been recently published by Li et al. [101].
Chapter 3 contains cin exhaustive introduction to the wavelet transform and its physical and
m athem atical properties. In this section we briefly discuss some research presented in the literature th a t takes advantage of such an approach.
As anticipated and described above, the wavelet transform is the primary technique used by Tzanetakis et al. [72] to extract information about the tem po/beat of a song. Taking advantage
of the possibility to approximate the signal at different resolutions (matching the music octaves), the authors dem onstrated the usefulness of such an approach in music genre classification.
freciuencies of an audio signal tends to provide b e tte r accuracy in classification of music item s by
genre. T he au th o rs com pare different sets of features, obtained using different m ethodologies: Mel
C epstral Coefficients, zero crossing ratio, spectral roll-off, rhythm ic features, pitch estim ation, etc.
By train in g different classifiers, they d em o n strate th a t a ch aracterisation of th e music signal based
on a wavelet approxim ation hcus a huge im pact on th e perform ance of th e evaluated classifiers.
However, it is im p o rtan t to note th a t th e wavelet transform , regardless of its m athem atical and
physical properties, is ju st an o th er signal analysis technique used to obtain th e spectrogram of a
signal. S tartin g from this approxim ation, it is possible to e x tract features like th e ones presented
in th e previous sections: i.e. the au to co rrelatio n functions of any of the wavelet sub-bands (chapter
3) can be obtained applying straightforw ardly equation 2.3 (as shown by Tzanetakis et al [72] ).
T heoretically, any of th e presented features can be obtained sta rtin g from a wavelet approxim ation
of th e in p u t signal.
2.6
Sum m ary
In th is ch ap ter we introduced the research area usually referred to cus Music Inform ation Retrieval.
Stcu:ting from the general definition of a retrieval system , we introduced some of th e features
presented in the literatu re. Features based on th e analysis of th e tim e properties of the signal as well
as features derived form a frequency dom ain p aram etrisatio n are presented. T he psychoacoustic
approach to the ch aracterisation of an audio signal is illu strated together w ith some of the m ost
im p o rta n t features used. Moreover, we outlined th e possibility of param eterising th e tem po and the
beat of a musical signal in two different ways. As illu strated in section 3.4, th e wavelet transform ,
a relatively novel technique for signal analysis, presents interesting characteristic th a t can suit the
need of good frequency and tim e resolution for music characterisation. In th e next chapter we
introduce th e m athem atical and physical properties of the wavelet transform . Moreover, we will
describe how to im plem ent a wavelet packet transform th a t suits th e physical and m athem atical
Chapter 3
The Wavelet Transform:
Characterisation of Music Signals
3.1
Foreword
In th e signal processing dornciin, the Fourier transform (F T ) is a well-known m athem atical tool
th a t enables th e ex tractio n of the com ponent frequencies of a given function f { t ) . As shown in the
previous chapter, the F T is the base technifjue on which frequency features are ex tracted from the
signal. A draw back of th e F T is th a t a Fourier analysis im plicitly assum es th a t th e given signal is
tim e invariant. The F T is a linear tim e invariant o p erato r th a t decom poses a signal of finite energy
(such as th e hum an voice or the sound of an in stru m en t) over a sinusoidal wave of frecjuency u>:
/
+ 00f { t )e - ^^dt (3.1)
- O O
Since th e su p p o rt of the sinusoidal waves cover th e whole real plane, th e obtained inform ation axe
a global “m ix”, of th e signal local characteristics and its general properties. This fact implies th a t
th e Fourier transform is not a good m ath em atical model to param etrise local features of / .
In th e real world, signcils are characterised by tim e tran sien t cmd frequency tran sien t events
ra th e r th a n sta tio n ary waves covering the whole tim e space. T h e hum an aud ito ry system is usually
more sensitive to tran sien t events them sta tio n a ry stim uli. For exam ple, after a few m inutes
in a noisy room we ceaise to pay a tten tio n to th e surrounding sounds, b u t a sudden silence or
a sudden variation of the noise volume can stim u late ou r a tten tio n . Music is a succession of
notes, or m ore generally frequencies, of different d u ratio n and repeated in tim e. A lineeir tim e
invariant approxim ation is not an ap p ro p riate way to analyse such a signal: we need transform s
th a t decom pose the signal over elem entary functions th a t are able to reveal the local properties of
th e sound.





![Table 3.2: Time resolution [bpm] for different wavelet families and levels](https://thumb-us.123doks.com/thumbv2/123dok_us/1371449.670550/58.533.9.520.21.744/table-time-resolution-bpm-different-wavelet-families-levels.webp)


