Learning to Translate in Real-time with Neural Machine Translation
Jiatao Gu†
, Graham Neubig♦
, Kyunghyun Cho‡
and Victor O.K. Li† †
The University of Hong Kong♦Carnegie Mellon University‡New York University
†
{jiataogu, vli}@eee.hku.hk ♦
gneubig@cs.cmu.edu
‡
kyunghyun.cho@nyu.edu
Abstract
Translating in real-time, a.k.a. simultane-ous translation, outputs translation words before the input sentence ends, which is a challenging problem for conventional ma-chine translation methods. We propose a neural machine translation (NMT) frame-work for simultaneous translation in which an agent learns to make decisions on when to translate from the interaction with a pre-trained NMT environment. To trade off quality and delay, we extensively ex-plore various targets for delay and design a method for beam-search applicable in the simultaneous MT setting. Experiments against state-of-the-art baselines on two language pairs demonstrate the efficacy of the proposed framework both quantita-tively and qualitaquantita-tively.1
1 Introduction
Simultaneous translation, the task of translating content in real-time as it is produced, is an im-portant tool for real-time understanding of spoken lectures or conversations (F¨ugen et al., 2007; Ban-galore et al., 2012). Different from the typical machine translation (MT) task, in which transla-tion quality is paramount, simultaneous translatransla-tion requires balancing the trade-off between transla-tion quality and time delay to ensure that users receive translated content in an expeditious man-ner (Mieno et al., 2015). A number of methods have been proposed to solve this problem, mostly in the context of phrase-based machine translation. These methods are based on asegmenter, which receives the input one word at a time, then decides when to send it to a MT system that translates each
1Code and data can be found athttps://github.
com/nyu-dl/dl4mt-simul-trans.
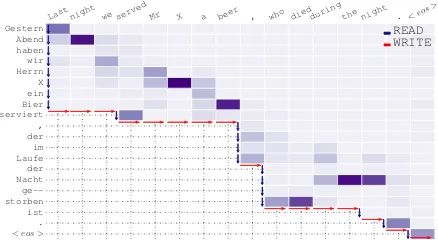
Last night we served Mr X a beer , who diedduring the night . < eos >
< eos >
. ist storben ge--Nacht der Laufe im der , serviert Bier ein X Herrn wir haben Abend
Gestern READ
WRITE
Figure 1: Example output from the proposed framework in DE → EN simultaneous transla-tion. The heat-map represents the soft alignment between the incoming source sentence (left, up-to-down) and the emitted translation (top, left-to-right). The length of each column represents the number of source words being waited for be-fore emitting the translation. Best viewed when zoomed digitally.
segment independently (Oda et al., 2014) or with a minimal amount of language model context (Ban-galore et al., 2012).
Independently of simultaneous translation, ac-curacy of standard MT systems has greatly im-proved with the introduction of neural-network-based MT systems (NMT) (Sutskever et al., 2014; Bahdanau et al., 2014). Very recently, there have been a few efforts to apply NMT to simultane-ous translation either through heuristic modifica-tions to the decoding process (Cho and Esipova, 2016), or through the training of an independent segmentation network that chooses when to per-form output using a standard NMT model (Satija and Pineau, 2016). However, the former model lacks a capability to learn the appropriate timing with which to perform translation, and the latter model uses a standard NMT model as-is, lack-ing a holistic design of the modellack-ing and learnlack-ing within the simultaneous MT context. In addition, neither model has demonstrated gains over
[image:1.595.307.526.222.342.2]ous segmentation-based baselines, leaving ques-tions of their relative merit unresolved.
In this paper, we propose a unified design for learning to perform neural simultaneous machine translation. The proposed framework is based on formulating translation as an interleaved sequence of two actions: READ andWRITE. Based on this,
we devise a model connecting the NMT system and these READ/WRITE decisions. An example
of how translation is performed in this framework is shown in Fig. 1, and detailed definitions of the problem and proposed framework are described in §2 and§3. To learn which actions to take when, we propose a reinforcement-learning-based strategy with a reward function that considers both qual-ity and delay (§4). We also develop a beam-search method that performs search within the translation segments (§5).
We evaluate the proposed method on English-Russian (EN-RU) and English-German (EN-DE) translation in both directions (§6). The quantita-tive results show strong improvements compared to both the NMT-based algorithm and a conven-tional segmentation methods. We also extensively analyze the effectiveness of the learning algorithm and the influence of the trade-off in the optimiza-tion criterion, by varying a target delay. Finally, qualitative visualization is utilized to discuss the potential and limitations of the framework.
2 Problem Definition
Suppose we have a buffer of input words X =
{x1, ..., xTs}to be translated in real-time. We
de-fine the simultaneous translation task as sequen-tially making two interleaved decisions: READor WRITE. More precisely, the translator READs a
source word xη from the input buffer in chrono-logical order as translation context, or WRITEs a
translated wordyτonto the output buffer, resulting in output sentenceY = {y1, ..., yTt}, and action
sequenceA = {a1, ..., aT}consists ofTs READs andTtWRITEs, soT =Ts+Tt.
Similar to standard MT, we have a measure Q(Y) to evaluate the translation quality, such as BLEU score (Papineni et al., 2002). For simulta-neous translation we are also concerned with the fact that each action incurs a time delay D(A). D(A)will mainly be influenced by delay caused by READ, as this entails waiting for a human
speaker to continue speaking (about0.3s per word for an average speaker), while WRITEconsists of
generating a few words from a machine
transla-Figure 2: Illustration of the proposed framework: at each step, the NMT environment (left) com-putes a candidate translation. The recurrent agent (right) will the observation including the candi-dates and send back decisions–READorWRITE.
tion system, which is possible on the order of mil-liseconds. Thus, our objective is finding an opti-mal policy that generates decision sequences with a good trade-off between higher qualityQ(Y)and lower delay D(A). We elaborate on exactly how to define this trade-off in§4.2.
In the following sections, we first describe how to connect theREAD/WRITEactions with the NMT
system (§3), and how to optimize the system to improve simultaneous MT results (§4).
3 Simultaneous Translation with Neural Machine Translation
The proposed framework is shown in Fig. 2, and can be naturally decomposed into two parts: envi-ronment (§3.1) and agent (§3.2).
3.1 Environment
Encoder:READ The first element of the NMT
system is the encoder, which converts input words X = {x1, ..., xTs} into context vectors H =
{h1, ..., hTs}. Standard NMT uses bi-directional
RNNs as encoders (Bahdanau et al., 2014), but this is not suitable for simultaneous processing as us-ing a reverse-order encoder requires knowus-ing the final word of the sentence before beginning pro-cessing. Thus, we utilize a simple left-to-right uni-directional RNN as our encoder:
hη =φUNI-ENC(hη−1, xη) (1)
Decoder:WRITE Similar with standard MT, we
[image:2.595.309.518.59.227.2]only reference the words that have been read from the input when generating each target word:
cη
τ =φATT(zτ−1, yτ−1, Hη)
zη
τ =φDEC(zτ−1, yτ−1, cητ) p(y|y<τ, Hη)∝exp [φOUT(zτη)],
(2)
where forτ,zτ−1andyτ−1represent the previous
decoder state and output word, respectively. Hη is used to represent the incomplete input states, whereHη is a prefix ofH. As theWRITEaction calculates the probability of the next word on the fly, we need greedy decoding for each step:
yτη = arg maxyp(y|y<τ, Hη) (3)
Note thatyτη, zτηcorresponds toHηand is the can-didate foryτ, zτ. The agent described in the next section decides whether to take this candidate or wait for better predictions.
3.2 Agent
A trainable agent is designed to make decisions A = {a1, .., aT}, at ∈ A sequentially based on observationsO = {o1, ..., oT}, ot ∈ O, and then control the translation environment properly.
Observation As shown in Fig 2, we concatenate
the current context vectorcητ, the current decoder statezτηand the embedding vector of the candidate word yητ as the continuous observation, oτ+η =
[cητ;zτη;E(yτη)]to represent the current state.
Action Similarly to prior work (Grissom II et al.,
2014), we define the following set of actions: • READ: the agent rejects the candidate and waits
to encode the next word from input buffer; • WRITE: the agent accepts the candidate and
emits it as the prediction into output buffer;
Policy How the agent chooses the actions based
on the observation defines the policy. In our set-ting, we utilize a stochastic policyπθ parameter-ized by a recurrent neural network, that is:
st=fθ(st−1, ot)
πθ(at|a<t, o≤t)∝gθ(st), (4)
where st is the internal state of the agent, and is updated recurrently yielding the distribution of the action at. Based on the policy of our agent, the overall algorithm of greedy decoding is shown in Algorithm 1, The algorithm outputs the translation result and a sequence of observation-action pairs.
Algorithm 1Simultaneous Greedy Decoding
Require: NMT systemφ, policyπθ,τMAX, input
bufferX, output bufferY, state bufferS.
1: Initx1⇐X, h1←φENC(x1), H1← {h1} 2: z0←φINIT H1
, y0 ← hsi 3: τ ←0, η←1
4: whileτ < τMAX do
5: t←τ+η
6: yτη, zτη, ot←φ(zτ−1, yτ−1, Hη) 7: at∼πθ(at;a<t, o<t), S ⇐(ot, at) 8: ifat=READandxη 6=h/sithen 9: xη+1 ⇐X, hη+1←φENC(hη, xη+1) 10: Hη+1←Hη∪ {hη+1}, η ←η+ 1 11: if|Y|= 0thenz0←φINIT(Hη)
12: else ifat=WRITEthen
13: zτ ←zτη, yτ ←yτη 14: Y ⇐yτ, τ ←τ + 1
15: ifyτ =h/sithen break
4 Learning
The proposed framework can be trained using re-inforcement learning. More precisely, we use pol-icy gradient algorithm together with variance re-duction and regularization techniques.
4.1 Pre-training
We need an NMT environment for the agent to ex-plore and use to generate translations. Here, we simply pre-train the NMT encoder-decoder on full sentence pairs with maximum likelihood, and as-sume the pre-trained model is still able to generate reasonable translations even on incomplete source sentences. Although this is likely sub-optimal, our NMT environment based on uni-directional RNNs can treat incomplete source sentences in a manner similar to shorter source sentences and has the po-tential to translate them more-or-less correctly.
4.2 Reward Function
The policy is learned in order to increase a reward for the translation. At each step the agent will re-ceive a reward signalrtbased on(ot, at). To eval-uate a good simultaneous machine translation, a reward must consider both quality and delay.
Quality We evaluate the translation quality
us-ing metrics such as BLEU (Papineni et al., 2002). The BLEU score is defined as the weighted geo-metric average of the modified n-gram precision BLEU0, multiplied by the brevity penalty BP to
BLEU score is not a good metric at sentence level because being a geometric average, the score will reduce to zero if one of the precisions is zero. To avoid this, we used a smoothed version of BLEU for our implementation (Lin and Och, 2004).
BLEU(Y, Y∗) =BP·BLEU0(Y, Y∗), (5) whereY∗is the reference andY is the output. We decompose BLEU and use the difference of par-tial BLEU scores as the reward, that is:
rQt =
∆BLEU0(Y, Y∗, t) t < T BLEU(Y, Y∗) t=T (6)
whereYtis the cumulative output att(Y0 = ∅),
and ∆BLEU0(Y, Y∗, t) = BLEU0(Yt, Y∗) − BLEU0(Yt−1, Y∗). Obviously, ifat=READ, no new words are written into Y, yieldingrtQ = 0. Note that we do not multiply BP until the end of the sentence, as it would heavily penalize partial translation results.
Delay As another critical feature, delay judges
how much time is wasted waiting for the transla-tion. Ideally we would directly measure the actual time delay incurred by waiting for the next word. For simplicity, however, we suppose it consumes the same amount of time listening for one more word. We define two measurements, global and local, respectively:
• Average Proportion (AP): following the
def-inition in (Cho and Esipova, 2016), X, Y are the source and decoded sequences respectively, and we uses(τ)to denote the number of source words been waited when decoding wordyτ,
0< d(X, Y) = |X1||Y|X
τ
s(τ)≤1
dt=
0 t < T d(X, Y) t=T
(7)
dis a global delay metric, which defines the av-erage waiting proportion of the source sentence when translating each word.
• Consecutive Wait length (CW): in speech
translation, listeners are also concerned with long silences during which no translation oc-curs. To capture this, we also consider on how many words were waited for (READ)
consecu-tively between translating two words. For each action, where we initially definec0 = 0,
ct=
ct−1+ 1 at=READ
0 at=WRITE (8)
• Target Delay: We further define “target delay”
for bothdand c asd∗ and c∗, respectively, as different simultaneous translation applications may have different requirements on delay. In our implementation, the reward function for de-lay is written as:
rtD =α·[sgn(ct−c∗) + 1]+β·bdt−d∗c+ (9)
whereα≤0, β≤0.
Trade-off between quality and delay A good
simultaneous translation system requires balanc-ing the trade-off of translation quality and time delay. Obviously, achieving the best translation quality and the shortest translation delays are in a sense contradictory. In this paper, the trade-off is achieved by balancing the rewardsrt=rQt +rtD provided to the system, that is, by adjusting the co-efficientsα, βand the target delayd∗, c∗in Eq. 9.
4.3 Reinforcement Learning
Policy Gradient We freeze the pre-trained
pa-rameters of an NMT model, and train the agent using the policy gradient (Williams, 1992). The policy gradient maximizes the following expected cumulative future rewards, J = Eπθ
hPT
t=1rt
i , whose gradient is
∇θJ =Eπθ
" T X
t0=1
∇θlogπθ(at0|·)Rt
#
(10)
Rt = PTk=t
h
rkQ+rD k
i
is the cumulative future rewards for current observation and action. In practice, Eq. 10 is estimated by sampling multi-ple action trajectories from the current policyπθ, collecting the corresponding rewards.
Variance Reduction Directly using the policy
gradient suffers from high variance, which makes learning unstable and inefficient. We thus em-ploy the variance reduction techniques suggested by Mnih and Gregor (2014). We subtract from Rt the output of a baseline networkbϕ to obtain
ˆ
Rt = Rt−bϕ(ot), and centered scale the re-ward as R˜t = √Rˆσt2−+b with a running average b
and standard deviationσ. The baseline network is trained to minimize the squared loss as follows:
Lϕ =Eπθ
" T X
t=1
kRt−bϕ(ot)k2
#
(11)
Algorithm 2Learning with Policy Gradient
Require: NMT systemφ, agentθ, baselineϕ
1: Pretrain the NMT systemφusing MLE; 2: Initialize the agentθ;
3: whilestopping criterion failsdo
4: Obtain a translation pairs:{(X, Y∗)}; 5: for(Y, S)∼Simultaneous Decodingdo 6: for(ot, at)inSdo
7: Compute the quality: rtQ; 8: Compute the delay: rtD; 9: Compute the baseline: bϕ(ot); 10: Collect the future rewards: {Rt}; 11: Perform variance reduction: {R˜t}; 12: Update:θ←θ+λ1∇θ[J−κH(πθ)] 13: Update:ϕ←ϕ−λ2∇ϕL
The overall learning algorithm is summarized in Algorithm 2. For efficiency, instead of updating with stochastic gradient descent (SGD) on a single sentence, both the agent and the baseline are opti-mized using a minibatch of multiple sentences.
5 Simultaneous Beam Search
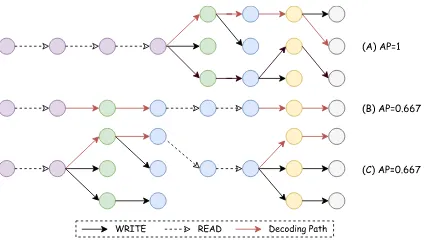
In previous sections we described a simultaneous greedy decoding algorithm. In standard NMT it has been shown that beam search, where the de-coder keeps a beam of k translation trajectories, greatly improves translation quality (Sutskever et al., 2014), as shown in Fig. 3 (A).
It is non-trivial to directly apply beam-search in simultaneous machine translation, as beam search waits until the last word to write down translation. Based on our assumptionWRITEdoes not cost
de-lay, we can perform a simultaneous beam-search when the agent chooses to consecutively WRITE:
keep multiple beams of translation trajectories in temporary buffer and output the best path when the agent switches to READ. As shown in Fig. 3
(B) & (C), it tries to search for a relatively better path while keeping the delay unchanged.
Note that we do not re-train the agent for simul-taneous beam-search. At each step we simply in-put the observation of the current best trajectory into the agent for making next decision.
6 Experiments
6.1 Settings
Dataset To extensively study the proposed
si-multaneous translation model, we train and evalu-ate it on two different language pairs:
“English-Figure 3: Illustrations of (A) beam-search, (B) si-multaneous greedy decoding and (C) sisi-multaneous beam-search.
German DE)” and “English-Russian (EN-RU)” in both directions per pair. We use the par-allel corpora available from WMT’152 for both
pre-training the NMT environment and learning the policy. We utilize newstest-2013 as the valida-tion set to evaluate the proposed algorithm. Both the training set and the validation set are tokenized and segmented into sub-word units with byte-pair encoding (BPE) (Sennrich et al., 2015). We only use sentence pairs where both sides are less than 50 BPE subword symbols long for training.
Environment & Agent Settings We pre-trained
the NMT environments for both language pairs and both directions following the same setting from (Cho and Esipova, 2016). We further built our agents, using a recurrent policy with 512 GRUs and a softmax function to produce the ac-tion distribuac-tion. All our agents are trained us-ing policy gradient usus-ing Adam (Kus-ingma and Ba, 2014) optimizer, with a mini-batch size of 10. For each sentence pair in a batch, 5 trajectories are sampled. For testing, instead of sampling we pick the action with higher probability each step.
Baselines We compare the proposed methods
against previously proposed baselines. For fair comparison, we use the same NMT environment:
• Wait-Until-End (WUE): an agent that starts to
WRITEonly when the last source word is seen.
In general, we expect this to achieve the best quality of translation. We perform both greedy decoding and beam-search with this method.
• Wait-One-Step (WOS): an agent that WRITEs
after eachREADs. Such a policy is problematic
when the source and target language pairs have different word orders or lengths (e.g. EN-DE).
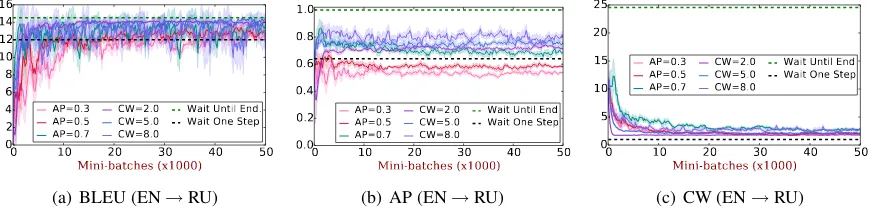
[image:5.595.308.520.58.178.2]0 10 20 30 40 50 Mini-batches (x1000)
02 4 6 8 1012 14 16
AP=0.3 AP=0.5 AP=0.7
CW=2.0 CW=5.0 CW=8.0
Wait Until End. Wait One Step
(a) BLEU (EN→RU)
0 10 20 30 40 50
Mini-batches (x1000) 0.0
0.2 0.4 0.6 0.8 1.0
AP=0.3 AP=0.5 AP=0.7
CW=2.0 CW=5.0 CW=8.0
Wait Until End Wait One Step
(b) AP (EN→RU)
0 10 20 30 40 50 Mini-batches (x1000)
0 5 10 15 20 25
AP=0.3 AP=0.5 AP=0.7
CW=2.0 CW=5.0 CW=8.0
Wait Until End Wait One Step
(c) CW (EN→RU)
Figure 4: Learning progress curves for variant delay targets on the validation dataset for EN → RU. Every time we only keep one target for one delay measure. For instance when using target AP, the coefficient ofαin Eq. 9 will be set0.
0.5 0.6 0.7 0.8 0.9 1.0
Average Proportion
12 13 14 15 16
BLEU
(a) EN→RU
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Average Proportion
6 8 10 12 14 16 18 20
BLEU
(b) RU→EN
0.6 0.7 0.8 0.9 1.0
Average Proportion
12 13 14 15 16 17 18 19
BLEU
(c) EN→DE
0.5 0.6 0.7 0.8 0.9 1.0
Average Proportion14
16
18
20
22
24
BLEU
[image:6.595.81.517.65.169.2](d) DE→EN
Figure 5: Delay (AP) v.s. BLEU for both language pair– directions. The shown point-pairs are the results of simul-taneous greedy decoding and beam-search (beam-size = 5) respectively with models trained for various delay targets: (J/: CW=8,N4: CW=5,♦: CW=2,I.: AP=0.3,HO: AP=0.5,: AP=0.7). For each target, we select the model that maximizes the quality-to-delay ratio (BLEUAP ) on the val-idation set. The baselines are also plotted (F: WOS FI: WUE,×: WID,+: WIW).
• Wait-If-Worse/Wait-If-Diff (WIW/WID): as
proposed by Cho and Esipova (2016), the al-gorithm first pre-READs the next source word,
and accepts thisREAD when the probability of
the most likely target word decreases (WIW), or the most likely target word changes (WID).
• Segmentation-based (SEG)(Oda et al., 2014):
a state-of-the-art segmentation-based algorithm based on optimizing segmentation to achieve the highest quality score. In this paper, we tried the simple greedy method (SEG1) and the greedy method with POS Constraint (SEG2).
6.2 Quantitative Analysis
In order to evaluate the effectiveness of our rein-forcement learning algorithms with different
re-ward functions, we vary the target delay d∗ ∈ {0.3,0.5,0.7} andc∗ ∈ {2,5,8}for Eq. 9 sepa-rately, and trained agents withαandβadjusted to values that provided stable learning for each lan-guage pair according to the validation set.
Learning Curves As shown in Fig. 4, we plot
0
5
10
15
20
25
Consecutive Wait Length
2
4
6
8
10
12
14
16
18
BLEU
1.0 1.5 2.0 2.5 3.0 3.5
12.012.5
13.013.5
14.014.5
15.015.5
16.0
Figure 6: Delay (CW) v.s. BLEU score for EN →RU, (J/: CW=8,N4: CW=5,♦: CW=2,I
.: AP=0.3, HO: AP=0.5,: AP=0.7), against the baselines (F: WOSF: WUE,+: SEG1,×: SEG2).
Quality v.s. Delay As shown in Fig. 5, it is
clear that the trade-off between translation quality and delay has very similar behaviors across both language pairs and directions. The smaller delay (AP or CW) the learning algorithm is targeting, the lower quality (BLEU score) the output translation. It is also interesting to observe that, it is more diffi-cult for “→EN” translation to achieve a lower AP target while maintaining good quality, compared to “EN→”. In addition, the models that are op-timized on AP tend to perform better than those optimized on CW, especially in “→EN” transla-tion. German and Russian sentences tend to be longer than English, hence require more consecu-tive waits before being able to emit the next En-glish symbol.
v.s. Baselines In Fig. 5 and 6, the points closer
to the upper left corner achieve better trade-off performance. Compared to WUE and WOS which can ideally achieve the best quality (but the worst delay) and the best delay (but poor quality) re-spectively, all of our proposed models find a good balance between quality and delay. Some of the proposed models can achieve good BLEU scores close to WUE, while have much smaller delay.
Compared to the method of Cho and Esipova (2016) based on two hand-crafted rules (WID, WIW), in most cases our proposed models find better trade-off points, while there are a few ex-ceptions. We also observe that the baseline models have trouble controlling the delay in a reasonable area. In contrast, by optimizing towards a given target delay, our proposed model is stable while maintaining good translation quality.
We also compared against Oda et al. (2014)’s
state-of-the-art segmentation algorithm (SEG). As shown in Fig 6, it is clear that although SEG can work with variant segmentation lengths (CW), the proposed model outputs high quality translations at a much smaller CW. We conjecture that this is due to the independence assumption in SEG, while the RNNs and attention mechanism in our model makes it possible to look at the whole history to decide each translated word.
w/o Beam-Search We also plot the results of
si-multaneous beam-search instead of using greedy decoding. It is clear from Fig. 5 and 6 that most of the proposed models can achieve an visible in-crease in quality together with a slight inin-crease in delay. This is because beam-search can help to avoid bad local minima. We also observe that the simultaneous beam-search cannot bring as much improvement as it did in the standard NMT set-ting. In most cases, the smaller delay the model achieves, the less beam search can help as it re-quires longer consecutiveWRITEsegments for
ex-tensive search to be necessary. One possible so-lution is to consider the beam uncertainty in the agent’s READ/WRITEdecisions. We leave this to
future work.
6.3 Qualitative Analysis
In this section, we perform a more in-depth analy-sis using examples from both EN-RU and EN-DE pairs, in order to have a deeper understanding of the proposed algorithm and its remaining limita-tions. We only perform greedy decoding to sim-plify visualization.
EN→RU As shown in Fig 8, since both En-glish and Russian are Subject-Verb-Object (SVO) languages, the corresponding words may share the same order in both languages, which makes si-multaneous translation easier. It is clear that the larger the target delay (AP or CW) is set, the more words are read before translating the correspond-ing words, which in turn results in better transla-tion quality. We also note that very earlyWRITE
commonly causes bad translation. For example, for AP=0.3 & CW=2, both the models choose to WRITEin the very beginning the word “The”,
which is unreasonable since Russian has no arti-cles, and there is no word corresponding to it. One good feature of using NMT is that the more words the decoder READs, the longer history is saved,
[image:7.595.76.290.66.195.2]The cost of thecampaignisbasicallybeingpaid by my salary as a sen--ator .< eos >
< eos >
. deckt ge--ator Sen--als alt Geh--mein durch genommen Grunde im werden Kampagne die f¨ur Kosten
Die READ
WRITE
(a) Simultaneous Neural Machine Translation
The cost of thecampaignisbasicallycoveredby my salary as a sen--ator .< eos >
< eos >
. deckt ge--ator Sen--als alt Geh--mein durch genommen Grunde im werden Kampagne die f¨ur Kosten
Die READ
WRITE
[image:8.595.81.519.65.195.2](b) Neural Machine Translation
Figure 7: Comparison of DE→EN examples using the proposed framework and usual NMT system respectively. Both the heatmaps share the same setting with Fig. 1. The verb “gedeckt” is incorrectly translated in simultaneous translation.
Source AP=0.3 AP=0.7 CW=2 CW=8 The The The The
people p-- i-- ent the p-- ol-- s
, , p-- riv--
as ers
I as I
heard я слышал Люди , Люди in , как я слышал
the как
countryside в в я слышал
, ,
want сельской местности сельской в как я
a местности слышал
Government сельской
that , в is местности сельской not
made хочу ,
up правительство местности
of хочу
thi-- , ,
eves хотят правительство
. ,
<eos> которое не производится
во-- ров . , чтобы правительство , которое не в-- меши-- вается в во-- ры .
, которое не является состав-- ной частью во-- ров .
хотят , чтобы
правительство , которое не в-- меши-- вается в во-- ры .
Summary BLEU=39/ AP=0.46 BLEU=64/AP=0.77 BLEU=54/CW=1.76 BLEU=64/CW=2.55
Figure 8: Given the example input sentence (leftmost column), we show outputs by models trained for various delay targets. For these outputs, each row corresponds to one source word and represents the emitted words (maybe empty) after reading this word. The corresponding source and target words are in the same color for all model outputs.
DE→EN As shown in Fig 1 and 7 (a), where we visualize the attention weights as soft align-ment between the progressive input and output sentences, the highest weights are basically along the diagonal line. This indicates that our simul-taneous translator works by waiting for enough source words with high alignment weights and then switching to write them.
DE-EN translation is likely more difficult as German usually uses Subject-Object-Verb (SOV) constructions a lot. As shown in Fig 1, when a sen-tence (or a clause) starts the agent has learned such policy toREADmultiple steps to approach the verb
[image:8.595.77.525.267.563.2]simultane-ous translator achieves almost the same translation with standard NMT except for the verb “gedeckt” which corresponds to “covered” in NMT output. Since there are too many words between the verb “gedeckt” and the subject “Kosten f¨ur die Kam-pagne werden”, the agent gives up reading (oth-erwise it will cause a large delay and a penalty) andWRITEs “being paid” based on the decoder’s
hypothesis. This is one of the limitations of the proposed framework, as the NMT environment is trained on complete source sentences and it may be difficult to predict the verb that has not been seen in the source sentence. One possible way is to fine-tune the NMT model on incomplete sen-tences to boost its prediction ability. We will leave this as future work.
7 Related Work
Researchers commonly consider the problem of simultaneous machine translation in the scenario of real-time speech interpretation (F¨ugen et al., 2007; Bangalore et al., 2012; Fujita et al., 2013; Rangarajan Sridhar et al., 2013; Yarmohammadi et al., 2013). In this approach, the incoming speech stream required to be translated are first recognized and segmented based on an automatic speech recognition (ASR) system. The translation model then works independently based on each of these segments, potentially limiting the quality of translation. To avoid using a fixed segmentation algorithm, Oda et al. (2014) introduced a trainable segmentation component into their system, so that the segmentation leads to better translation quality. Grissom II et al. (2014) proposed a similar frame-work, however, based on reinforcement learning. All these methods still rely on translating each seg-ment independently without previous context.
Recently, two research groups have tried to ap-ply the NMT framework to the simultaneous trans-lation task. Cho and Esipova (2016) proposed a similar waiting process. However, their wait-ing criterion is manually defined without learnwait-ing. Satija and Pineau (2016) proposed a method sim-ilar to ours in overall concept, but it significantly differs from our proposed method in many details. The biggest difference is that they proposed to use an agent that passively reads a new word at each step. Because of this, it cannot consecutively de-code multiple steps, rendering beam search diffi-cult. In addition, they lack the comparison to any existing approaches. On the other hand, we
per-form an extensive experimental evaluation against state-of-the-art baselines, demonstrating the rela-tive utility both quantitarela-tively and qualitarela-tively.
The proposed framework is also related to some recent efforts about online sequence-to-sequence (SEQ2SEQ) learning. Jaitly et al. (2015)
pro-posed a SEQ2SEQ ASR model that takes
fixed-sized segments of the input sequence and outputs tokens based on each segment in real-time. It is trained with alignment information using super-vised learning. A similar idea for online ASR is proposed by Luo et al. (2016). Similar to Satija and Pineau (2016), they also used reinforcement learning to decide whether to emit a token while reading a new input at each step. Although shar-ing some similarities, ASR is very different from simultaneous MT with a more intuitive definition for segmentation. In addition, Yu et al. (2016) recently proposed an online alignment model to help sentence compression and morphological in-flection. They regarded the alignment between the input and output sequences as a hidden variable, and performed transitions over the input and out-put sequence. By contrast, the proposedREADand WRITEactions do not necessarily to be performed
on aligned words (e.g. in Fig. 1), and are learned to balance the trade-off of quality and delay.
8 Conclusion
We propose a unified framework to do neural si-multaneous machine translation. To trade off qual-ity and delay, we extensively explore various tar-gets for delay and design a method for beam-search applicable in the simultaneous MT setting. Experiments against state-of-the-art baselines on two language pairs demonstrate the efficacy both quantitatively and qualitatively.
Acknowledgments
References
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-gio. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Srinivas Bangalore, Vivek Kumar Rangarajan Srid-har, Prakash Kolan, Ladan Golipour, and Aura Jimenez. 2012. Real-time incremental speech-to-speech translation of dialogs. InProceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Hu-man Language Technologies, pages 437–445. Asso-ciation for Computational Linguistics.
Kyunghyun Cho and Masha Esipova. 2016. Can neu-ral machine translation do simultaneous translation?
arXiv preprint arXiv:1606.02012.
Christian F¨ugen, Alex Waibel, and Muntsin Kolss. 2007. Simultaneous translation of lectures and speeches. Machine Translation, 21(4):209–252.
Tomoki Fujita, Graham Neubig, Sakriani Sakti, Tomoki Toda, and Satoshi Nakamura. 2013. Sim-ple, lexicalized choice of translation timing for si-multaneous speech translation. InINTERSPEECH.
Alvin Grissom II, He He, Jordan Boyd-Graber, John Morgan, and Hal Daum´e III. 2014. Dont until the final verb wait: Reinforcement learning for si-multaneous machine translation. InProceedings of the 2014 Conference on Empirical Methods in Nat-ural Language Processing (EMNLP), pages 1342– 1352, Doha, Qatar, October. Association for Com-putational Linguistics.
Navdeep Jaitly, Quoc V Le, Oriol Vinyals, Ilya Sutskeyver, and Samy Bengio. 2015. An on-line sequence-to-sequence model using partial con-ditioning.arXiv preprint arXiv:1511.04868.
Diederik Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Chin-Yew Lin and Franz Josef Och. 2004. Auto-matic evaluation of machine translation quality us-ing longest common subsequence and skip-bigram statistics. InProceedings of the 42nd Annual Meet-ing on Association for Computational LMeet-inguistics, page 605. Association for Computational Linguis-tics.
Yuping Luo, Chung-Cheng Chiu, Navdeep Jaitly, and Ilya Sutskever. 2016. Learning online alignments with continuous rewards policy gradient. arXiv preprint arXiv:1608.01281.
Takashi Mieno, Graham Neubig, Sakriani Sakti, Tomoki Toda, and Satoshi Nakamura. 2015. Speed or accuracy? a study in evaluation of simultaneous speech translation. InINTERSPEECH.
Andriy Mnih and Karol Gregor. 2014. Neural vari-ational inference and learning in belief networks.
arXiv preprint arXiv:1402.0030.
Yusuke Oda, Graham Neubig, Sakriani Sakti, Tomoki Toda, and Satoshi Nakamura. 2014. Optimiz-ing segmentation strategies for simultaneous speech translation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Lin-guistics (Volume 2: Short Papers), pages 551–556, Baltimore, Maryland, June. Association for Compu-tational Linguistics.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting on association for compu-tational linguistics, pages 311–318. Association for Computational Linguistics.
Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Andrej Ljolje, and Rathinavelu Chengal-varayan. 2013. Segmentation strategies for stream-ing speech translation. InProceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 230–238, Atlanta, Georgia, June. Association for Computational Lin-guistics.
Harsh Satija and Joelle Pineau. 2016. Simultaneous machine translation using deep reinforcement learn-ing. Abstraction in Reinforcement Learning Work-shop, ICML2016.
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2015. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909. Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014.
Sequence to sequence learning with neural net-works. InAdvances in neural information process-ing systems, pages 3104–3112.
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforce-ment learning. Machine learning, 8(3-4):229–256. Mahsa Yarmohammadi, Vivek Kumar
Rangara-jan Sridhar, Srinivas Bangalore, and Baskaran Sankaran. 2013. Incremental segmentation and decoding strategies for simultaneous translation. In
IJCNLP, pages 1032–1036.