Frame-Based Continuous Lexical Semantics through Exponential Family
Tensor Factorization and Semantic Proto-Roles
Francis Ferraro and Adam Poliak and Ryan Cotterell and Benjamin Van Durme Center for Language and Speech Processing
Johns Hopkins University
{ferraro,azpoliak,ryan.cotterell,vandurme}@cs.jhu.edu
Abstract
We study how different frame annota-tions complement one another when learn-ing continuous lexical semantics. We learn the representations from a tensorized skip-gram model that consistently en-codes syntactic-semantic content better, with multiple 10% gains over baselines.
1 Introduction
Consider “Bill” in Fig. 1: what is his involve-ment with the words “would try,” and what does this involvementmean? Word embeddings repre-sent such meaning as points in a real-valued vec-tor space (Deerwester et al.,1990;Mikolov et al.,
2013). These representations are often learned by exploiting the frequency that the word cooccurs with contexts, often within a user-defined window (Harris, 1954;Turney and Pantel, 2010). When built from large-scale sources, like Wikipedia or web crawls, embeddings capture general charac-teristics of words and allow for robust downstream applications (Kim,2014;Das et al.,2015).
Frame semantics generalize word meanings to that of analyzing structured and interconnected la-beled “concepts” and abstractions (Minsky,1974;
Fillmore, 1976,1982). These concepts, or roles,
implicitlyencode expected properties of that word.
In a frame semantic analysis of Fig.1, the segment “would try” triggers the ATTEMPT frame, filling the expected roles AGENTand GOALwith “Bill” and “the same tactic,” respectively. While frame semantics provide a structured form for analyzing words with crisp, categorically-labeled concepts, the encoded properties and expectations are im-plicit. What does itmeanto fill a frame’s role?
Semantic proto-role (SPR) theory, motivated by
Dowty(1991)’s thematic proto-role theory, offers an answer to this. SPR replaces categorical roles
ATTEMPT
She said Bill would try the same tactic again.
[image:1.595.362.460.220.254.2]AGENT GOAL
Figure 1: A simple frame analysis.
with judgements about multiple underlying prop-erties about what is likely true of the entity fill-ing the role. For example, SPR talks about how likely it is for Bill to be a willing participant in the ATTEMPT. The answer to this and other simple judgments characterize Bill and his involvement. Since SPR both captures the likelihood of certain properties and characterizes roles as groupings of properties, we can view SPR as representing a type of continuous frame semantics.
We are interested in capturing these SPR-based properties and expectations within word embed-dings. We present a method that learns frame-enriched embeddings from millions of documents that have been semantically parsed with multiple different frame analyzers (Ferraro et al., 2014). Our method leverages Cotterell et al. (2017)’s formulation of Mikolov et al. (2013)’s popular skip-gram model as exponential family principal component analysis (EPCA) and tensor factor-ization. This paper’s primary contributions are: (i) enriching learned word embeddings with mul-tiple, automatically obtained frames from large, disparate corpora; and (ii) demonstrating these enriched embeddings better capture SPR-based properties. In so doing, we also generalize Cot-terell et al.’s method to arbitrary tensor dimen-sions. This allows us to include an arbitrary amount of semantic information when learning embeddings. Our variable-size tensor factoriza-tion code is available at https://github.com/ fmof/tensor-factorization.
2 Frame Semantics and Proto-Roles Frame semantics currently used in NLP have a rich history in linguistic literature. Fillmore (1976)’s frames are based on a word’s context and prototyp-ical concepts that an individual word evokes; they intend to represent the meaning of lexical items by mapping words to real world concepts and shared experiences. Frame-based semantics have inspired many semantic annotation schemata and datasets, such as FrameNet (Baker et al.,1998), PropBank (Palmer et al.,2005), and Verbnet (Schuler,2005), as well as composite resources (Hovy et al.,2006;
Palmer,2009;Banarescu et al.,2012).1
Thematic Roles and Proto Roles These re-sources map words to their meanings through discrete/categorically labeled frames and roles; sometimes, as in FrameNet, the roles can be very descriptive (e.g., the DEGREE role for the AF -FIRM OR DENY frame), while in other cases, as in PropBank, the roles can be quite general (e.g., ARG0). Regardless of the actual schema, the roles are based on thematic roles, which map a predi-cate’s arguments to a semantic representation that makes various semantic distinctions among the ar-guments (Dowty, 1989).2 Dowty (1991) claims that thematic role distinctions are not atomic, i.e., they can be deconstructed and analyzed at a lower level. Instead of many discrete thematic roles,
Dowty(1991) argues forproto-thematic roles, e.g. PROTO-AGENT rather than AGENT, where dis-tinctions in proto-roles are based on clusterings of logical entailments. That is, PROTO-AGENTs of-ten have certain properties in common, e.g., ma-nipulating other objects or willingly participating in an action; PROTO-PATIENTs are often changed or affected by some action. By decomposing the meaning of roles into properties or expectations that can be reasoned about, proto-roles can be seen as including a form of vector representation within structured frame semantics.
3 Continuous Lexical Semantics
Word embeddings represent word meanings as el-ements of a (real-valued) vector space (Deerwester et al.,1990). Mikolov et al.(2013)’sword2vec methods—skip-gram (SG) and continuous bag of
1SeePetruck and de Melo(2014) for detailed descriptions on frame semantics’ contributions to applied NLP tasks.
2Thematic role theory is rich, and beyond this paper’s scope (Whitehead,1920;Davidson,1967;Cresswell,1973;
Kamp,1979;Carlson,1984).
words (CBOW)—repopularized these methods. We focus on SG, which predicts the context i
around a word j, with learned representationsci
andwj, respectively, asp(contexti | wordj) ∝
exp (c|iwj) = exp (1|(ciwj)),whereis the
Hadamard (pointwise) product. Traditionally, the context words i are those words within a small window of j and are trained with negative sam-pling (Goldberg and Levy,2014).
3.1 Skip-Gram as Matrix Factorization Levy and Goldberg (2014b), and subsequently
Keerthi et al.(2015), showed how vectors learned under SG with the negative sampling are, under certain conditions, the factorization of (shifted) positive pointwise mutual information. Cotterell et al. (2017) showed that SG is a form of ex-ponential family PCA that factorizes the matrix of word/context cooccurrence counts (rather than shifted positive PMI values). With this interpre-tation, they generalize SG from matrix to tensor factorization, and provide a theoretical basis for modeling higher-order SG (or additional context, such as morphological features of words) within a word embeddings framework.
Specifically,Cotterell et al. recast higher-order SG as maximizing the log-likelihood
X
ijk
Xijklogp(contexti|wordj,featurek) (1)
=X
ijk
Xijklog exp (1 |(c
iwj ak)) P
i0exp (1|(ci0 wjak)), (2)
where Xijk is a cooccurrence count 3-tensor of
wordsj, surrounding contextsi, and featuresk.
3.2 Skip-Gram asn-Tensor Factorization
When factorizing an n-dimensional tensor to in-clude an arbitrary number of L annotations, we replacefeaturekin Equation (1) andak in
Equa-tion (2) with each annotation typeland vectorαl
included. Xi,j,k becomes Xi,j,l1,...lL, representing
the number of times wordjappeared in contexti
with featuresl1throughlL. We maximize X
i,j,l1,...,lL
Xi,j,l1,...,lLlogβi,j,l1,...,lL
βi,j,l1,...,lL ∝exp (1|(ciwjαl1 · · · αlL)).
4 Experiments
se-mantic parses in order to improve the seman-tic content—specifically SPR-type information— within learned lexical embeddings. We utilize ma-jority portions of the Concretely Annotated New York Times and Wikipedia corpora fromFerraro et al. (2014). These have been annotated with three frame semantic parses: FrameNet fromDas et al. (2010), and both FrameNet and PropBank fromWolfe et al. (2016). In total, we use nearly five million frame-annotated documents.
Extracting Counts The baseline extraction we consider is a standard sliding window: for each wordwj seen≥T times, extract all wordswitwo
to the left and right ofwj. These counts, forming a
matrix, are then used within standardword2vec. We also followCotterell et al.(2017) and augment the above with the signed number of tokens sepa-ratingwi andwj, e.g., recording thatwiappeared
two to the left ofwj; these counts form a 3-tensor.
To turn semantic parses into tensor counts, we first identify relevant information from the parses. We consider all parses that are triggered by the tar-get word wj (seen≥ T times) and that have at
least one role filled by some word in the sentence. We organize the extraction around roles and what fills them. We extract every wordwr that fills all
possible triggered frames; each of those frame and role labels; and the distance between fillerwrand
triggerwj. This process yields a 9-tensorX.3
Al-though we always treat the trigger as the “origi-nal” word (e.g., wordj, with vectorwj), later we consider (1) what to include fromX, (2) what to predict (what to treat as the “context” wordi), and (3) what to treat as auxiliary features.
Data DiscussionThe baseline extraction methods result in roughly symmetric target and surround-ing word counts. This is not the case for the frame extraction. Our target words must trigger some semantic parse, so our target words are actually target triggers. However, the surrounding context words are those words that fill semantic roles. As shown in Table1, there are an order-of-magnitude fewer triggers than target words, but up to an order-of-magnitudemoresurrounding words.
Implementation We generalize Levy and Gold-berg (2014a)’s and Cotterell et al. (2017)’s code
3Each record consists of the trigger, a role filler, the num-ber of words between the trigger and filler, and the relevant frame and roles from the three semantic parsers. Being au-tomatically obtained, the parses are overlapping and incom-plete; to properly formX, one can implicitly include special hNO FRAMEiandhNO ROLEilabels as needed.
windowed frame # target words 232404 35.9 (triggers)45.7(triggers) # surrounding 232 531 (role fillers)
[image:3.595.315.523.64.127.2]words 404 2,305(role fillers)
Table 1: Vocabulary sizes, in thousands, extracted from Fer-raro et al.(2014)’s data with both the standard sliding context window approach (§3) and the frame-based approach (§4). Upper numbers (Roman) are for newswire; lower numbers (italics) are Wikipedia. For both corpora, 800 total FrameNet frame types and 5100 PropBank frame types are extracted.
to enable any arbitrary dimensional tensor fac-torization, as described in §3.2. We learn 100-dimensional embeddings for words that appear at least 100 times from 15 negative samples.4 The implementation is available athttps://github. com/fmof/tensor-factorization.
MetricWe evaluate our learned (trigger) embed-dingswviaQVEC(Tsvetkov et al.,2015). QVEC uses canonical correlation analysis to measure the Pearson correlation between w and a collection
oforaclelexical vectorso. These oracle vectors
are derived from a human-annotated resource. For QVEC, higher is better: a higher score indicatesw more closely correlates (positively) witho.
Evaluating Semantic Content with SPR Mo-tivated by Dowty (1991)’s proto-role theory,
Reisinger et al.(2015), with a subsequent expan-sion by White et al.(2016), annotated thousands of predicate-argument pairs(v, a)with (boolean) applicability and (ordinal) likelihoods of well-motivated semantic properties applying to/being true of a.5 These likelihood judgments, under the SPR framework, are converted from a five-point Likert scale to a 1–5 interval scale. Be-cause the predicate-argument pairs were extracted from previously annotated dependency trees, we link each property with the dependency relation joiningv andawhen forming the oracle vectors; each component of an oracle vectorovis the unity-normalized sum of likelihood judgments for joint property and grammatical relation, using the inter-val responses when the property is applicable and discarding non-applicable properties, i.e. treating the response as 0. Thus, the combined 20 prop-erties of Reisinger et al. (2015) and White et al.
(2016)—together with the four basic grammatical
4In preliminary experiments, this occurrence threshold did not change the overall conclusions.
5 We use the training portion of http:
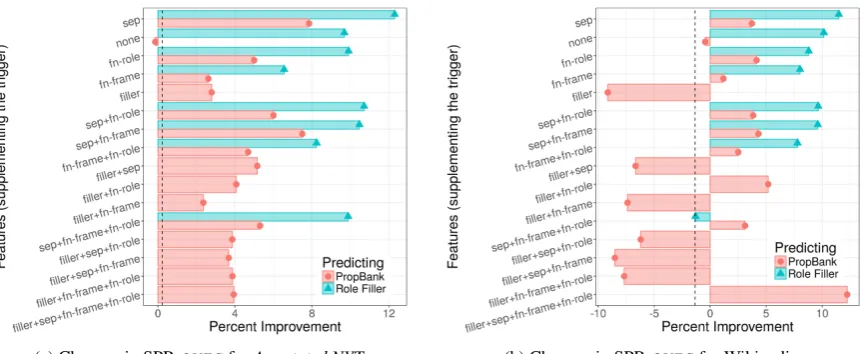
(a) Changes in SPR-QVECforAnnotated NYT. (b) Changes in SPR-QVECfor Wikipedia.
Figure 2: Effect of frame-extracted tensor counts on our SPR-QVECevaulation. Deltas are shown as relative percent changes vs. theword2vecbaseline. The dashed line represents the 3-tensorword2vecmethod ofCotterell et al.(2017). Each row represents an ablation model: sepmeans the prediction relies on the token separation distance between the frame and role filler,fn-framemeans the prediction uses FrameNet frames,fn-rolemeans the prediction uses FrameNet roles, and
fillermeans the prediction uses the tokens filling the frame role. Read from top to bottom, additional contextual features are denoted with a+. Note whenfilleris used, we only predict PropBank roles.
relations nsubj, dobj, iobj and nsubjpass—result in 80-dimensional oracle vectors.6
Predict Fillers or Roles? Since SPR judgments are between predicates and arguments, we predict the words filling the roles, and treat all other frame information as auxiliary features. SPR annotations were originally based off of (gold-standard) Prop-Bank annotations, so we also train a model to pre-dict PropBank frames and roles, thereby treating role-filling text and all other frame information as auxiliary features. In early experiments, we found it beneficial to treat the FrameNet annotations ad-ditively and not distinguish one system’s output from another. Treating the annotations additively serves as a type of collapsing operation. Although
X started as a 9-tensor, we only consider up to 6-tensors: trigger, role filler, token separation be-tween the trigger and filler, PropBank frame and role, FrameNet frame, and FrameNet role.
Results Fig. 2 shows the overall percent change for SPR-QVEC from the filler and role predic-tion models, on newswire (Fig.2a) and Wikipedia (Fig. 2b), across different ablation models. We indicate additional contextual features being used with a+: sepuses the token separation distance between the frame and role filler, fn-frame uses FrameNet frames,fn-roleuses FrameNet roles, filler uses the tokens filling the frame
6 The full cooccurrence among the properties and rela-tions is relatively sparse. Nearly two thirds of all non-zero oracle components are comprised of just fourteen properties, and only thensubjanddobjrelations.
role, and none indicates no additional informa-tion is used when predicting. The 0 line represents a plain word2vecbaseline and the dashed line represents the 3-tensor baseline ofCotterell et al.
(2017). Both of these baselines are windowed: they are restricted to a local context and cannot take advantage of frames or any lexical signal that can be derived from frames.
Overall, we notice that we obtain large improve-ments from models trained on lexical signals that have been derived from frame output (sep and none), even if the modelitself does not incorpo-rate any frame labels. The embeddings that predict the role filling lexical items (the green triangles) correlate higher with SPR oracles than the em-beddings that predict PropBank frames and roles (red circles). Examining Fig.2a, we see that both model types outperform both theword2vecand
Cotterell et al.(2017) baselines in nearly all model configurations and ablations. We see the highest improvement when predicting role fillers given the frame trigger and the number of tokens separating the two (the green triangles in theseprows).
con-1 foresaw 2 figuring 3 alleviated 4 craved 5 jeopardized 6 pondered 7 kidded 8 constituted 9 uttering 10 forgiven 1 pioneered 2 scratch 3 complemented 4 competed 5 consoled 6 tolerated 7 resurrected 8 sweated 9 fancies 10 concocted 1 containing 2 contains 3 manufactures 4 contain 5 consume 6 storing 7 reproduce 8 store 9 exhibiting 10 furnish 1 anticipate 2 anticipating 3 anticipates 4 stabbing 5 separate 6 intimidated 7 separating 8 separates 9 drag 10 guarantee 1 invent 2 document 3 documented 4 invents 5 documents 6 aspire 7 documenting 8 aspires 9 inventing 10 swinging 1 produces 2 produce 3 produced 4 prized 5 originates 6 ridden 7 improves 8 surround 9 surrounds 10 originating producing Filler | sep
producing PropBank | sep invented
Filler | sep
invented PropBank | sep anticipated
Filler | sep
[image:5.595.79.290.70.229.2]anticipated PropBank | sep
Figure 3: K-Nearest Neighbors for three randomly sampled trigger words, from two newswire models.
textual features. We hypothesize this is due to the significantly increased vocabulary size of the Wikipedia role fillers (c.f., Tab. 1). Note, how-ever, that by using all available schema informa-tion when predicting PropBank, we are able to compensate for the increased vocabulary.
In Fig. 3 we display the ten nearest neighbors for three randomly sampled trigger words accord-ing to two of the highest performaccord-ing newswire models. They each condition on the trigger and the role filler/trigger separation; these correspond to theseprows of Fig.2a. The left column of Fig.3
predicts the role filler, while the right column pre-dicts PropBank annotations. We see that while both models learn inflectional relations, this qual-ity is prominent in the model that predicts Prop-Bank information while the model predicting role fillers learns more non-inflectional paraphrases.
5 Related Work
The recent popularity of word embeddings have inspired others to consider leveraging linguistic annotations and resources to learn embeddings. Both Cotterell et al. (2017) and Levy and Gold-berg(2014a) incorporate additional syntactic and morphological information in their word embed-dings. Rothe and Sch¨utze(2015)’s use lexical re-source entries, such as WordNet synsets, to im-prove pre-computed word embeddings. Through generalized CCA, Rastogi et al. (2015) incorpo-rate paraphrased FrameNet training data. On the applied side, Wang and Yang (2015) used frame embeddings—produced by training word2vec on tweet-derived semantic frame (names)—as ad-ditional features in downstream prediction.
Teichert et al.(2017) similarly explored the re-lationship between semantic frames and thematic proto-roles. They proposed using a Conditional Random Field (Lafferty et al., 2001) to jointly and conditionally model SPR and SRL. Teichert et al. (2017) demonstrated slight improvements in jointly and conditionally predicting PropBank (Bonial et al., 2013)’s semantic role labels and
Reisinger et al.(2015)’s proto-role labels. 6 Conclusion
We presented a way to learn embeddings enriched with multiple, automatically obtained frames from large, disparate corpora. We also presented a QVEC evaluation for semantic proto-roles. As demonstrated by our experiments, our extension ofCotterell et al.(2017)’s tensor factorization en-riches word embeddings by including syntactic-semantic information not often captured, result-ing in consistently higher SPR-based correla-tions. The implementation is available athttps: //github.com/fmof/tensor-factorization.
Acknowledgments
This work was supported by Johns Hopkins Uni-versity, the Human Language Technology Cen-ter of Excellence (HLTCOE), DARPA DEFT, and DARPA LORELEI. We would also like to thank three anonymous reviewers for their feedback. The views and conclusions contained in this pub-lication are those of the authors and should not be interpreted as representing official policies or en-dorsements of DARPA or the U.S. Government.
References
Collin F. Baker, Charles J. Fillmore, and John B. Lowe. 1998. The berkeley framenet project. In Proceed-ings of the 36th Annual Meeting of the Associa-tion for ComputaAssocia-tional Linguistics and 17th Inter-national Conference on Computational Linguistics - Volume 1. Association for Computational Linguis-tics, Stroudsburg, PA, USA, ACL ’98, pages 86–90.
https://doi.org/10.3115/980845.980860.
Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. 2012. Abstract meaning representation (amr) 1.0 specification. InParsing on Freebase from Question-Answer Pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Lan-guage Processing. Seattle: ACL. pages 1533–1544. Claire Bonial, Kevin Stowe, and Martha Palmer. 2013.
the 2nd Workshop on Linked Data in Linguistics (LDL-2013): Representing and linking lexicons, ter-minologies and other language data. Association for Computational Linguistics, Pisa, Italy, pages 9 – 17.
http://www.aclweb.org/anthology/W13-5503. Greg N Carlson. 1984. Thematic roles and their role in
semantic interpretation. Linguistics22(3):259–280. Ryan Cotterell, Adam Poliak, Benjamin Van Durme, and Jason Eisner. 2017. Explaining and general-izing skip-gram through exponential family princi-pal component analysis. InProceedings of the 15th Conference of the European Chapter of the Associa-tion for ComputaAssocia-tional Linguistics. Valencia, Spain. Maxwell John Cresswell. 1973.Logics and languages. London: Methuen [Distributed in the U.S.A. By Harper & Row].
Dipanjan Das, Nathan Schneider, Desai Chen, and Noah A Smith. 2010. Probabilistic frame-semantic parsing. In Human language technologies: The 2010 annual conference of the North American chapter of the association for computational lin-guistics. Association for Computational Linguistics, pages 948–956.
Rajarshi Das, Manzil Zaheer, and Chris Dyer. 2015.
Gaussian lda for topic models with word em-beddings. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Con-ference on Natural Language Processing (Vol-ume 1: Long Papers). Association for Computa-tional Linguistics, Beijing, China, pages 795–804.
http://www.aclweb.org/anthology/P15-1077. Donald Davidson. 1967. The logical form of action
sentences. In Nicholas Rescher, editor,The Logic of Decision and Action, University of Pittsburgh Press. Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, and Richard Harshman. 1990. Indexing by latent semantic analysis. JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE41(6):391–407.
David Dowty. 1991. Thematic proto-roles and argu-ment selection. Language67(3):547–619.
David R Dowty. 1989. On the semantic content of the notion of thematic role. In Properties, types and meaning, Springer, pages 69–129.
Francis Ferraro, Max Thomas, Matthew R. Gormley, Travis Wolfe, Craig Harman, and Benjamin Van Durme. 2014. Concretely Annotated Corpora. In
4th Workshop on Automated Knowledge Base Con-struction (AKBC).
Charles Fillmore. 1982. Frame semantics. Linguistics in the morning calmpages 111–137.
Charles J Fillmore. 1976. Frame semantics and the na-ture of language*. Annals of the New York Academy of Sciences280(1):20–32.
Yoav Goldberg and Omer Levy. 2014. word2vec explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722.
Zellig S Harris. 1954. Distributional structure. Word
10(2-3):146–162.
Eduard Hovy, Mitchell Marcus, Martha Palmer, Lance Ramshaw, and Ralph Weischedel. 2006. Ontonotes: the 90% solution. InProceedings of the human lan-guage technology conference of the NAACL, Com-panion Volume: Short Papers. Association for Com-putational Linguistics, pages 57–60.
Hans Kamp. 1979. Events, instants and temporal ref-erence. In Semantics from different points of view, Springer, pages 376–418.
S. Sathiya Keerthi, Tobias Schnabel, and Rajiv Khanna. 2015. Towards a better understanding of predict and count models. arXiv preprint arXiv:1511.0204.
Yoon Kim. 2014. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Lan-guage Processing (EMNLP). Association for Com-putational Linguistics, Doha, Qatar, pages 1746– 1751.http://www.aclweb.org/anthology/D14-1181.
John D. Lafferty, Andrew McCallum, and Fernando C. N. Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and label-ing sequence data. In Proceedings of the Eigh-teenth International Conference on Machine Learn-ing. Morgan Kaufmann Publishers Inc., San Fran-cisco, CA, USA, ICML ’01, pages 282–289.
http://dl.acm.org/citation.cfm?id=645530.655813.
Omer Levy and Yoav Goldberg. 2014a. Dependency-based word embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Association for Computational Lin-guistics, Baltimore, Maryland, pages 302–308.
http://www.aclweb.org/anthology/P14-2050.
Omer Levy and Yoav Goldberg. 2014b. Neural word embedding as implicit matrix factorization. In Ad-vances in neural information processing systems. pages 2177–2185.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jef-frey Dean. 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Marvin Minsky. 1974. A framework for representing knowledge. MIT-AI Laboratory Memo 306.
Martha Palmer, Daniel Gildea, and Paul Kingsbury. 2005. The proposition bank: An annotated corpus of semantic roles. Computational linguistics31(1):71– 106.
Miriam R. L. Petruck and Gerard de Melo, ed-itors. 2014. Proceedings of Frame Seman-tics in NLP: A Workshop in Honor of Chuck Fillmore (1929-2014). Association for Com-putational Linguistics, Baltimore, MD, USA.
http://www.aclweb.org/anthology/W14-30.
Pushpendre Rastogi, Benjamin Van Durme, and Ra-man Arora. 2015. Multiview LSA: Representation Learning via Generalized CCA. In Proceedings of the 2015 Conference of the North American Chap-ter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Denver, Colorado, pages 556–566. http://www.aclweb.org/anthology/N15-1058.
Drew Reisinger, Rachel Rudinger, Francis Ferraro, Craig Harman, Kyle Rawlins, and Benjamin Van Durme. 2015. Semantic proto-roles. Transactions of the Association for Computational Linguistics (TACL)3:475–488.
Sascha Rothe and Hinrich Sch¨utze. 2015. Autoex-tend: Extending word embeddings to embeddings for synsets and lexemes. In Proceedings of the 53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International Joint Conference on Natural Language Processing (Vol-ume 1: Long Papers). Association for Compu-tational Linguistics, Beijing, China, pages 1793– 1803.http://www.aclweb.org/anthology/P15-1173. Karin Kipper Schuler. 2005. Verbnet: A
broad-coverage, comprehensive verb lexicon .
Adam Teichert, Adam Poliak, Benjamin Van Durme, and Matthew Gormley. 2017. Semantic proto-role labeling. In AAAI Conference on Artificial Intelli-gence.
Yulia Tsvetkov, Manaal Faruqui, Wang Ling, Guil-laume Lample, and Chris Dyer. 2015. Evalua-tion of word vector representaEvalua-tions by subspace alignment. In Proceedings of the 2015 Con-ference on Empirical Methods in Natural Lan-guage Processing. Association for Computational Linguistics, Lisbon, Portugal, pages 2049–2054.
http://aclweb.org/anthology/D15-1243.
Peter D Turney and Patrick Pantel. 2010. From fre-quency to meaning: Vector space models of se-mantics. Journal of artificial intelligence research
37:141–188.
William Yang Wang and Diyi Yang. 2015. That’s so annoying!!!: A lexical and frame-semantic em-bedding based data augmentation approach to au-tomatic categorization of annoying behaviors us-ing #petpeeve tweets. InProceedings of the 2015
Conference on Empirical Methods in Natural Lan-guage Processing. Association for Computational Linguistics, Lisbon, Portugal, pages 2557–2563.
http://aclweb.org/anthology/D15-1306.
Aaron Steven White, Drew Reisinger, Keisuke Sak-aguchi, Tim Vieira, Sheng Zhang, Rachel Rudinger, Kyle Rawlins, and Benjamin Van Durme. 2016.
Universal decompositional semantics on univer-sal dependencies. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computa-tional Linguistics, Austin, Texas, pages 1713–1723.
https://aclweb.org/anthology/D16-1177.
Alfred North Whitehead. 1920. The concept of na-ture: the Tarner lectures delivered in Trinity College, November 1919. Kessinger Publishing.