IACSIT International Journal of Engineering and Technology, Vol.3, No.1, February 2011 ISSN: 1793-8236
85
Implementing a Decision Support Module in
Distributed Multi-Agent System for Task
Allocation Using Granular Rough Model
Abstract—A Multi-Agent System (MAS) is a branch of distributed artificial intelligence, composed of a number of distributed and autonomous agents. In MAS, an effective coordination is essential for autonomous agents to reach their goals. Any decision based on a foundation of knowledge and reasoning can lead agents into successful cooperation, so to achieve the necessary degree of flexibility in coordination, an agent requires making decisions about when to coordinate and which coordination mechanism to use. The performance of any MAS depends directly with the right decisions that the agents made. Therefore the agents must have the ability of making right decisions. In this paper, we propose a decision support module in a distributed multi-agent system, which enables any agent to make decisions needed for Task allocation problem; we propose an algorithm for Task Allocation Decision Maker (TADM) based on Granular Rough Model (GRM). Furthermore, a number of experiments were performed to validate the effectiveness of the proposed algorithm (TADM)); we compare the efficiency of our algorithms with recent frameworks. The preliminary results demonstrate the efficiency of our algorithms
Index Terms—Decision Making, Task allocation, Coordination Mechanism, Multi-Agent System (MAS), Rough Set, Granular Computing
I. INTRODUCTION
The notion of distributed intelligent systems (DIS) [1] has been a subject of interest for number of years. A Multi-Agent system (MAS) is one of the main areas in the DIS. Any Multi-agent system consists of several agents capable of mutual interaction, with heterogeneous capabilities, that cooperate with each others to pursue some set of goals, or to complete a specific task. MAS used to solve problems which are difficult or impossible for an individual agent or monolithic system to solve. Agents are autonomous programs which can understand an environment, take actions depending upon the current status of the environment using its knowledge base and also learn so as to act in the future. In order to solve complex problems agents have to cooperate and exhibit some level of autonomy. Agents cooperate with each other to solve large and complex collaborative problems. Because the majority of work is completed through distributing the tasks among
Sally M. El-Ghamrawy is with the Computers and Systems Department,Faculty of Engineering,Mansoura University, Egypt(email: [email protected])
Ali I. El-Desouky is with the Computers and Systems Department,Faculty of Engineering,Mansoura University, Egypt(email: [email protected])
MostafaSaleh is with the Computers and Systems Department,Faculty of Engineering,Mansoura University, Egypt
the cooperative agents, the decision support module is responsible on the most of the work. So the pros and cons in decision support module directly affect on the success of tasks completion and problem solving. In [2], we proposed a Distributed Multi-Agent Intelligent System (DMAIS,) a general purpose agent framework, in which several interacting intelligent agents cooperate with some auxiliary agents to pursue some set of goals or tasks that are beyond their individual capabilities. There are some modules must be considered in designing the Distributed Multi-Agent Intelligent System (DMAIS) that help in developing in the agent systems. There are many researches considered some modules when designing multi-agent systems (MAS) in different ways. Each autonomous agent in DMAIS must be able to decide how to behave in various situations, so in this paper our main concern is to propose an efficient decision support module that helps in the improvement of DMAIS performance.
Agents have attractive characteristics like: autonomy, reactivity, reasoning capability and social ability. These characteristics ensure that agent-based technologies are responsible for enhancing the decision support system capabilities beyond the capabilities of the old model. Any active decision support can be facilitated by the autonomy, reactivity and social ability of agents. Furthermore, the artificial view of agents can contribute towards stronger collaborative relationships between a human and a decision support system. These enormous interests of researchers in investigating the decision support in Multi-Agent Systems is due to the great benefits of combining the decision support technology and Agent-based technology with taking the advantage of the agent characteristics. In this sense, many researches [3-7] recognized the promise that agent -based technologies holds for enhancing DSS capabilities.
IACSIT International Journal of Engineering and Technology, Vol.3, No.1, February 2011 ISSN: 1793-8236
86 extended the work done in DMAIS [2] by proposing a Decision support module in it, this module is concerned about taking the right decisions needed to allocate a specific task to a specific agent, by using the Task Allocation Decision Maker sub-module (TADM). So we spotted on these decisions due to the great importance for them in the improvement of agents’ coordination in DMAIS framework. The rest of the paper is organized as following. Section 2 demonstrates the proposed decision support module. Section 3 discusses the related work on task allocation in Multi-agent Systems. An algorithm for the Task Allocation Decision Maker (TADM) is proposed in section 4, showing the scenario of our algorithm in allocating tasks to specific agent/s. section 5 shows the proposed granular rough model that used in TADM. Section 6shows the experimental evaluation and the results obtained after implementing the proposed algorithm. Section 7 summarizes major contribution of the paper and proposes the topics for future research.
II. DECISION SUPPORT MODULE
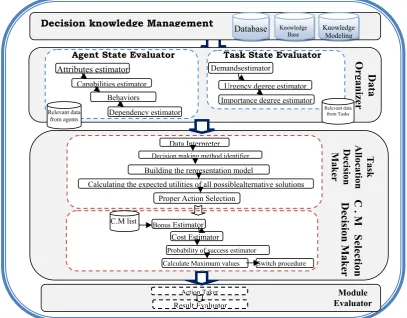
In the DMAIS framework [2], the decision support module takes the information collected in the coordination and negotiation module, as shown in fig 1, so that it can help in the decision support process.
Figure 1. The Decision Support Module in DMAIS Framework
Figure 2. Architecture of the Decision Support Module
The Decision support module is activated when a decision is needed from the agent, we concerned about two main decisions that the agent may face: (1) the decision needed to allocate a specific task to a specific agent, making an effective decision for the task allocation problem is a critical job for any multi-agent system; it helps our DMAIS framework to complete its tasks and missions through cooperation among agents. The Task Allocation Decision Maker sub-module (TADM) is responsible for making this decision. (2) The decision needed to select appropriate coordination mechanism, when agents need to coordinate with another agent/s to accomplish a specific task.
The decision support module contains four main phases,
as shown in figure 2, first is the decision knowledge management that contains:
• The database: contains the data that directly related to the decision problem (i.e. the performance measures, the values of nature states).
• The knowledge base: contains the descriptions for roles and structures of document and some knowledge of the problem itself, (i.e. Guide for how to select decision alternatives or how to interpret outputs).
• The knowledge modeling: is a repository contains the decision problem formal models and the algorithms and methodologies for developing outcomes from the formal models. Also contains different process models,
Decision knowledge Management Knowledge
Modeling
Knowledge Base
Database
Action Taker Result Evaluator
Ta
sk
Allo
cation
Decision
Ma
ker
Data Interpreter Decision making method identifier
Proper Action Selection Building the representation model
Calculating the expected utilities of all possiblealternative solutions
Data
Or
ganizer
Agent State Evaluator Attributes estimator
Capabilities estimator
Dependency estimator Behaviors
Task State Evaluator
Urgency degree estimator Demandsestimator
Importance degree estimator Relevant data
from agents
Relevant data from Tasks
C . M Selection
Decision Maker
Probability of success estimator C.M list
Cost Estimator
BonusEstimator
Calculate Maximum values Switch procedure
Module Evaluator
Reasoning Module
Communication Module Decision Support
Module
Planning Module Negotiation Module
Scheduling Module
M
anage
me
nt Module
IACSIT International Journal of Engineering and Technology, Vol.3, No.1, February 2011 ISSN: 1793-8236
87 each model is represented as a set of process and event objects.
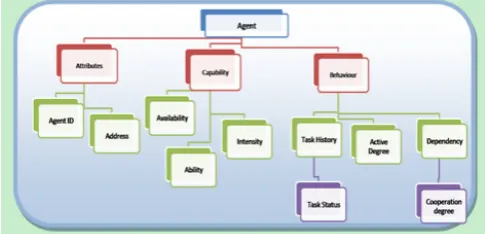
Second phase is the data organizer, which organizes agent’s attributes using the agent state evaluator and organizes task’s preferences by using task state evaluator The agent state evaluator estimates the attributes and capabilities of agents, in our work we concerned on specific attributes and characteristics of the agent that will help in the decision making procedure, as shown in fig 3, where:
Figure 3. Attributes, Capabilities and behaviors of Agents Agent attributes is defined as a tuple
<AgentID(A), Addrs(A)> (1)
Where AgentID(A) is the identity of the agent, Addrs(A) records the IP address of agent A.Agent Capability is defined as a tuple
<Availability(A), Ability(A), Intensity(A)> (2)
Where Availability(A) is the ratio of total number of successful agents, capable of accomplishing the task, to the total number of agents in the system,
AVLB(T)= SUC(A) / TOT (A) (3)
Ability(A) indicates number of agents capable of fulfilling the task.Intensity(A) refers to the number of tasks that the agents can accomplish per time unit.
Agent Behaviors is defined as a tuple
< Task History(A), Active degree(A), Dependency(A)> (4)
Where task history(A) stores the number of accomplished tasks that the agent(A) performed. Active degree(A) indicates the activity degree of a specific agent, this degree varies from agent to another according to many parameters (e.g. number of finished tasks, number of cooperation process).Agent Dependency(A) is concerned with the Cooperation Degree of an Agent(A) with respect to other agents in the system.
Third phase is divided into two main Sub-modules: (1)The Task Allocation Decision Maker (TADM) ,this sub-module will be discussed in details in the next sections, and (2) The Coordination Mechanism Selection Decision Maker (CMSDM), that takes the decision needed to select appropriate coordination mechanism, when agents need to coordinate with another agent/s to accomplish a specific task, it will be discussed in our future work. Both of them are responsible on making the proper decisions according to the input obtained from the Data organizer phase. The module evaluator phase is the fourth phase, it has two main goals: first, take the action that the third phase decided to be taken. Second, evaluate the results of taking this action.
III. RELATED WORK
The task allocation in Multi-Agent Systems represent a problem which occupied to a large extends the researchers
of decision support and artificial intelligence until our days. Tasks allocation is defined, in [8], as the ability of agents to self-organize in groups of agents in order to perform one or more tasks which are impossible to perform individually. In our context, it is a problem of assigning responsibility and problem solving resources to an agent. There are two main benefits for Minimizing task interdependencies in the coordination process between the agents: First, improving the problem solving efficiency by decreasing communication overhead among the agents. Second, improving the chances for solution consistency by minimizing potential conflicts. The issue of task allocation was one of the earliest problems to be worked on in Distributed Artificial Intelligence (DAI) research. In this sense, several authors studied the problem related to Task Allocation especially in MAS. The researches in task allocation can be classified in to two main parts, centralized and distributed, based on utility/cost functions.
pr pr su m ag to re op [2 co di am be be co ap op pr to ag to ex m m ag th th ag th sc de da fa an m
roposed an E rotocol based uitable for de multi-agent sys gents to alloca o commit u eallocation. I pportunities to 20] developed omplex task a istributing the mong all agen e generated in eing based o ooperation w ppropriate su ptimality. Che rotocol for dis
IV. TAS
The task allo o take the pro gents. The firs o take the de xecuting part o made independ The decision mainly concern gents, whethe hemselves or hemselves, the
gents which h he task, or part
cenario of allo
Figure First the cap efined, and al ata organizer acilitate the d
nd then we us metrics to obta
IACSI
Efficient Task d on the Con ealing with ta stems with a d ate tasks not o unfinished tas n this way, o achieve solu d a decentral allocation for e process of co nts based on t n the task allo on its Galo with other ag ub-task that eng and Well stributed task a
SK ALLOCATIO
ocation Decisi oper decisions st step in alloc ecision wheth or the entire ta dently by each ns needed for ned about allo er these agen not. If agen ey attempt to
have the appr t of the task, t ocating tasks to
e 4: The Proposed pabilities and lso the deman as an input decision maki sed the rough ain the decisio
IT International
k Allocation ntract Net ap ask allocation decentralized only to their n sks to their the agents ution of their t
lized and sca r Massive Mu omputing the the hypothesis ocation proces is Sub-Hiera gents, each a ensures the lman [21] use allocation.
ON DECISION M on Maker (TA s of allocating
cating tasks to her the agen ask. The alloc
agent the Task alloc ocating the ta nts can comp nts can’t ach give a decisio ropriate capab to those agent
o specific age
d algorithm used d behaviors o nds of tasks, i to the TADM ing process m
set theory fo on of allocatin
l Journal of Eng I
Protocol (ET pproach, but n problems in manner. It en neighbours bu r neighbours can have tasks Brahmi alable method ulti-Agent Sy optimal alloc s: non conflic sses. Indeed, w archy (GSH) agent chooses
global alloc ed a market b
MAKER (TADM
ADM) main g g tasks to the
o specific age nts are capab cation decision
cation problem asks to numb plete its task hieve the tas on to specify bilities and a s. Fig 4 depic ent/s in the TA
in TADM of agents mu
it’s taken from MThe metrics must be evalu or classifying ng tasks to ag
gineering and Te ISSN: 1793-823 88 TAP) more n P2P nables t also s for more et al. d for ystem, cation t will while and s the cation based M) goal is right ents is ble of ns are m are ber of ks by sk by other assign ts the ADM. ust be m the s that uated, these gent/s. Then first, capa all o the d task each taken the d then tasks acco
V. D as i subje lesse Mult capa view indic best sets mod the i must repre moti analy of u supp conc show conc supp algor mod echnology, Vol.3 36
n this decision , if the alloca abilities of age ver again, it m decision is to
priority must h agent, and d
n whether to decision is to
the coordina s must be dis ording to the a
TADM algorithm
1. Agent
2. AinCh
3. For ea
4. 5.
6. If tim
7. 8. 9. 10. 11. 12.
13. If he
14. 15. 16. 17. Next 18. Xx: 19. Ai=Ch
20. If help
21. Ai= se
22. If re
23. 24. 25. 26. 27. 28. Else 29. AinCh 30. En Figure 5 GRANULA ecision-makin information a ectivity which er or greater
ti-Agent Sys abilities for so wpoint and ha
cate that the d take place in [23-25] and r del these vagu imperfect kno t be some kin esent any un ivated us to ysis the data i using Granular port module is cepts with usi ws the propos cepts used in port module, i
rithm. There del, each con
3, No.1, Februar
n is tested, it m ation cannot b ents and dema may encounter allocate the t be reviewed depend on th delay, reject o
allocate the ated agents m stributed amo
lgorithm in fig
t Ai randomly selec harge= Ai ach a(i) in G
Ai=Send re Ai=Wait res me waited > expired Exi En Ai=Receive Ai=Process Ai=Store re Max-value= elpfulness-value> M Ma No En heck (Nominated-ag pfulness-value(Ai)< end Response(Nom eply (Nominated-age AinC Else Ai= f Go to End i harge= Ai d if
: The Pseudo cod
AR COMPUTIN
ng is a difficul about incom h tend to be pr
degree. In a stems has olving the pr as no control decision makin
n a fuzzy env rough sets [26 ueness and un owledge. In de nd of support
ncertainty th use the GrC in decision su r Rough theo s to combine ing the benef sed Granular n Granular Ro is also outline are four ma ncept illustra
ry 2011
may be one of be done, in th ands of tasks r any kind of e
task to only d to check the his queue an or execute thi task to more must registere ong those coo
gure 5.
t task T
quest ( ) sponse( ) d time then
it for
nd if
e response( ) response( ) esponse() =0
Max-value then
ax-value = helpfulne ominated-agent= a(i)
nd if
gent( )) < Nominated-agent minated-agent)
ent) =1 then
Charge=
Nominated-find_scnd_highst( ) o xx
if
de for TADM algo
NG AND ROUG lt process due mpleteness, im
resent in real-addition, each incomplete roblem, thus i
on the system ng in Multi-Ag vironment. Th 6,27] have be
ncertainty, an ecision suppor to extract the hat might oc
models with upport module
ory in our pro the advantage fits of granula Rough Mod ough theory ed, to implem ain concepts ated in detai
f three decision his situation t
must be defin error. second
one agent, th e task queue f action must is task. Third, than one age d, and the su ordinated agen ess-value ) then -agent orithm
GH SETS THEOR e to factors, su mprecision, a life situations h agent in a information it has a limit m. These facto
gent System c heories of fuz en diagnosed nd manipulati
rt module, the knowledge a ccur. This fa
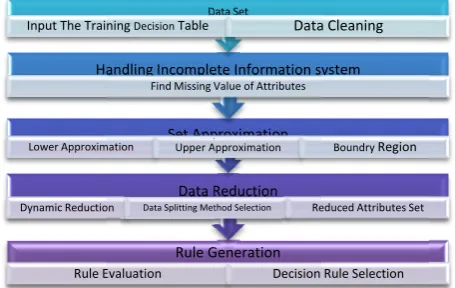
h RST tools e. The main go oposed decisi es of using RS ations. Figure del (GRM), t in the decisi ment the TAD used in GR
su Fi 1. Th sy th O kn sy of at in M by en in em at su ca sy at de c ac in gr gr in If fr cl by In if gi of in m I ubsections, sho
igure 6: Granular
.Decision Tab
The first pha he data set use ystem in which he agent recor
bjects are nowledge exp ystem can be f
Where A is f objects calle ttributes and V nformation fun Multi-Agent in
y attributes an ntries of the ta Rough set th nformation sys mpty finite se ttribute C and upervised lear alled decision ystem in the fo
Where C is ttributes that c ecision attrib
:U→ for ev chieved by ndiscernibility
ranulation me ranule of kn ndiscernibility
, ,
Where
f , ∈
om each oth lasses of th y .The not nformally, two f one cannot
iven set of att f the set ndiscernibility mathematically Rule E Dynamic Reductio Lower Approxim Ha Input The Trai
{ ) (
IND IS R =
IACSI
owing the alg
Rough Model (G
ble
ase in GRM m ed is represen h each row in rd) and each attracted by pression syste formulated as:
A , U, A
set of agents ed the univers V is called va nction. In ou nformation tab nd rows are lab able are attribu heory base on stem should b et of attributes
d decision attr rning) and in n table. A de orm is given b DT = {U, C s a non-emp characterizes a
bute or the ery c ∈ C, i means of is at the hea eans more de nowledge abo
relation ca
is called , then o her by attribu
e R-indiscer tion of indisce o objects in a distinguish be tributes. Henc of attribute
relation fo y an equivale Rule G Evaluation
Data R on Data Splitting Met
Set App
mation Upper A
andling Incomple Find Missing V
D ning DecisionTable
U ) x'
{(x, ∈ 2
IT International
orithms propo
GRM) Used in De
model presen nted in a table n the table rep column repre y Granular
em, a Multi-A :
A, V, f . . .
viewpoints, U se, A is non-e alue set of att ur context, ble, whose co beled by obje ute values.
philosophy o be expressed s A into two ribute D (this nformation sy ecision table by:
C ∪{D}, V} pty finite set
a decision cate e thematic is a value of
information art of rough s finable conce out a forest an be repre
the R-indisc bjects x and x utes from R. rnibility relat ernibility is fu
decision tabl etween them ce, indiscernib s under co or a given ence relation. Generation
Decision Reduction
thod Selection Re proximation Approximation ete Information s
Value of Attributes Data Set
Data
(x)
|∀c∈ Rc
l Journal of Eng I
osed within th
ecision Support M
nted is the dat called inform resents a case esents an attri rough theory Agent inform
. (1)
U is non-empt empty finite s tributes A and
is expressed olumns are la ects of interest
of classificatio by dividing o subsets cond
s process is c ystem in this
is an inform
. . set of cond egory and D∉ featuresuch attribute c. T n granulation
set theory. A ept. For R ⊆C
with respec sented as:
. cernibility rela x’ are indiscer
The equiva tion are den undamental to
le are indiscer on the basis bility is a fun onsideration.
attribute se . The equiva
Rule Selection educed Attributes Set
BoundryRegion
ystem a Cleaning
)} (x'
) = c
gineering and Te ISSN: 1793-823 89 hem. Module ta set. mation e (e.g. ibute. y as mation ty set set of d f is as a abeled t. The ons so non-dition called case mation
. (2) dition ∉ C is that his is n or
finer
C the ct to
. (3) ation. rnible alence noted RST. rnible of a nction The et is alence relat (xRx Tran prop whol the p and t the p the d For algor relat TAB Fo poss comp part the t samp as sh infor valu to h conc conc MAS incom prob U Th agen level their vario certa RST null (MV echnology, Vol.3 36
tion is a binar x for any obje nsitive (if xR posed in the p le MAS. Whe proposed deci
then the attrib process of taki decision attrib
the TADM a rithm, there tion:
,
BLEI :THE ATTR
or TADM alg ibilities: (1) pletely. (2) Th
of the task. ( task at all. A ple of decisio hown in table rmation system es for an obje andle these i cept is used in cept of a gran S.This becau mplete infor blem.
TABLE II: DEC
U1 RT
a1 RTa1
1 1 1
2 1 1
3 1 1
4 1 1
5 1 1
hus somet nt can be incom
l of informati r local points o ous levels of ain formalism T.So there mus
attributes. In
VE) algorithm
3, No.1, Februar
ry relation ect x) or Sym Ry and yRz
previous chap en an agent n sion support m butes used in T
ing the decisio utes D = {d} algorithm, sup
are nine att
, ,
RIBUTES MEAN AND DEC
gorithm, the d The agent d he agent decid (3) The agent According to n table for TA 2.In real life ms. It means ct are missing incomplete in n second pha nulation beca use each age rmation or c
CISION TABLE
RT
a3 Rac1 R
1 1
1 1
1 1
1 1
1 2
times the mplete. The a ion granules t of view. Info f granularity. m of informatio
st be an algor this subsectio m is proposed
ry 2011
⊆ wh
mmetric (if xR z then xRz).
pter, suppose needs a decisi module propo TADM algorit on for TADM is illustrated i ppose deno tributes form
, , ,
NING FOR TASK CISION
decision can decides to al des that it can decides that task allocati ADM algorith e, there are lot that sometim g. RST introdu nformation sy
se of GRM m ause it gives ent in any M capabilities f
FOR TADM AL
Rac
2 Rac3 Rab1
1 1 1
1 2 1
1 3 1
1 1 1
1 2 1
informatio agents can be that is the mo rmation granu
Each agent on granulation rithm to deal on a Missing V d to handle th
hich is:Reflexi Ry then yRx) .In the DMA e U denotes t
ion to be take osed is activate thms to descri M algorithms a
in tables 1. otes the TAD m an equivale
, ,
KS AND AGENT
be one of thr llocate the ta n allocate only it can’t alloca ion situations hms is obtaine ts of incomple mes the attribu uced many wa ystems IIS. Th model using t
a great help MAS may h for solving t
LGORITHMS
Rab 2 Rab3
1 1
1 2
1 3
1 1
1 2
on for processed at t ost suitable fro ules can come
could exploit n engaging w with missing Value Estimat he IIS based
IACSIT International Journal of Engineering and Technology, Vol.3, No.1, February 2011 ISSN: 1793-8236
90 information granulation. Missing or null values will increase the uncertainty of information system and the induced rules will not be trusted. These missing values are represented by the set of all possible values for the attribute. To indicate such a situation, a distinguished value, a so-called null value is usually assigned to those attributes. Let , , is the information system, for every a
∈
A, there is a mappinga, a:U→ , where is called the value set of a. If
a∈Acontains a null value (will be denoted as *) for at least one attribute a ∈A, then is called an IIS, otherwise it is complete information systems. Recently, the researchers presented many ways to handle the IIS; these researches can be classified into two main approaches :(1) Indirectly handle the IIS(Data Reparation): This approach is to transforming an IIS to a complete system using estimation methods (probabilistic and statistical techniques). These estimation methods mainly work as estimating the null value based on the appearing frequency of other values with same attribute. The value gained by these methods maybe not archive the best efficiency to the classification of decision attribute because it changes the original information and lead to a lower support degree and confidence degree. That is to say, this approach is to replace unknown value of attributes by either specific subsets of values or statistical values [28-30]. (2) Directly handle the IIS (Model Extension): This approach is to extend the concepts of RST on complete information systems for handling IIS. It does not require the changes in the original system and still is capable of reducing dispensable knowledge efficiently. By using knowledge reduction that eliminates only the information which is not essential from the point of view of classification or decision making or by relaxing the requirement of indiscernibility relation of reflexivity, symmetry and transitivity, i.e., the indiscernibility relation is extended to inequivalence relations that can process IISs directly [31-35]. A Missing Value Estimator (MVE) algorithm is proposed, as shown in figure 7, to handle the IIS based on information granulation. Suppose that
, , is the IIS and let the attribute set isR ⊆C. Based on Kryszkiewicz , in order to deal directly with IIS we can define the tolerance relation as follows:
, ∈ |
∀
c ∈ R, c u c vc u c v . . . (4)
Let SIMR U express the information granular for the
biggest object satisfy the condition.Divide the information table into granules to i condition attributes. If the one of the i condition attribute values of the object is *, it will not be divided into any granules. Information granularity means we can observe and analysis the same problem from very different granularities. GQR is called the information
granularity of information system , , for the R ⊆C.
SIM U , SIM U , … . SIMR U| | . . . (5)
Then the definition of information granularity GQR will be:
GQR | | ∑| | |SIMR U | . . . (6)
Missing Value Estimator (MVE) Algorithm Based on Information Granulation
Input: Associate R c c c
I=1,2,……n where n is the number of condition attributes of information table
I c , c , … . . c
Output: Fill the missing values in the information table. 1. R R , R , … . . R
2. xx:
3. Calculate SIMR U
4. Calculate GQR
5. Foreach c in c
6. {
7. Select c= c
8. }
9. Next
10. Yy:
11. Foreach c in c
12. { Find c (U
13. Foreachc (U
14. X=Get CandValue(SIMR U )
15. Temp(k) = Get NullValue(c (U )
16. ForeachTemp(k)
17. Calculate Qulty(c) in Predct(d)
18. Next
19. MaxValueOf(Qulty(c))
20. Go to yy
21. }
22. Next
23. }
24. Next
25. Assign C = c , R c c, I=1,2….n , R={R , R , … . . R}
26. I I c
27. IfI then
28. Exit
29. Else
30. Go to mm
31. End if
Figure 7: The Pseudo Code of MVE Based on Information Granulation
2.Set Approximation
As mentioned in the introduction of RST, set approximation is the kernel concept in RST. The starting point of RST is the indiscernibility relation, generated by information about objects of interest. The indiscernibility relation is intended to express the fact that due to the lack of knowledge we are unable to discern some objects employing the available information. That means that, it is a must to consider clusters of indiscernible objects, as fundamental concepts of RST because there is no ability to deal with single objects. The equivalence classes of the indiscernibility relation are the basic building blocks from which sets of cases or objects can be assembled. Sets of interest to assemble in a supervised learning setting would typically be the sets of cases with the same value for the outcome variable. The set approximation concept add a great benefit in applying it in the decision support module , this is because any decision about the presence or absence of a given category is approximated by lower and upper approximation of decision concept.
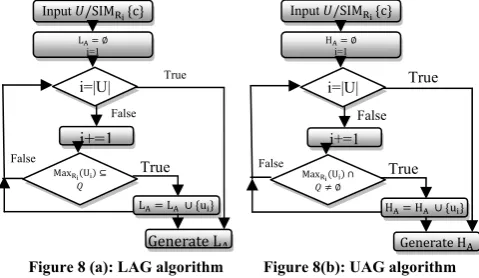
In this extension, a notion of granulation order is introduced by using the Granular rough theory, in third phase of GRM model, to propose a Lower approximation Generator (LAG) algorithm and Upper approximations Generator (UAG) algorithm, these approximations of a target set under a granulation order is defined in an incomplete information system. Suppose that , ,
is IIS and R
⊆
C. And as showed in the previous sub-section,SIMR U is a tolerance relation on U, It can be easily shown that:
SIMR U ∈ SIMR c . . . (7)
IACSIT International Journal of Engineering and Technology, Vol.3, No.1, February 2011 ISSN: 1793-8236
91
MaxR U is the maximal set of objects which are possibly indistinguishable by R with u. Let / denote the family sets | ∈ , the classification or the knowledge induced by R. A member MaxR U from
/ will be called a tolerance class or a granule of information. It should be noticed that, in general the tolerance classes in U/SIMR U do not constitute a partition of U, but they constitute a cover of U, i.e.,MaxR U for every u ∈ U , and ∈UMaxR U U .In an incomplete information system, a cover /SIMR U of U induced by the tolerance relation SIMR U , provides a granulation world
for describing a concept X. So a sequence of attribute sets
∈ 2 (n = 1, 2... N)can determine a sequence of granulation worlds, from the most rough one to the most fine one. Based on RST approximations, lower and upper approximations are generated under a granulation order in IIS in the proposed LAG and UAG algorithms, as shown in figure 8(a) and 8 (b), respectively.
Figure 8 (a): LAG algorithm Figure 8(b): UAG algorithm
Let Q is subset of U, Q
⊆
U , ∈ C, and /SIMR c ,thatdenote classification under granulation in IIS ,is defined as: /SIMR c= MaxR u , MaxR u … . , MaxR| | u|U| . . . (8)
The lower and upper approximation to Q fromU/SIMR c
is defined as:
lower R Q u ∈ U|MaxR u ⊆ Q . . . ……(9)
Upper R Q u ∈ U|MaxR u Q . . . (10)
The R-boundary region of Q from U/SIMR c equals the
difference between the upper and lower approximations.
R Q R Q . . . (11)
3. Data Reduction Phase
Attribute reduction can be viewed as the strongest and most characteristic results in RST to distinguish itself from other theories. Since, in real world it is difficult to identify all possible causal attributes, it will be necessary to establish a methodology to identify the critical attributes by eliminating redundant attributes using feature reduction or knowledge compression methods in rough set knowledge systems. This can be achieved by removing the attributes whose removal will not change the indiscernibility relation. Attribute reduction aims to find minimal subsets of attributes, each one of them has the same discrimination power as the entire attributes. A minimal subset of attributes that enables the same classification of elements of the universe as the whole set of attributes is called a reduction, if it cannot be further reduced without affecting the essential
information [36]. The RST provides different methods for finding which attributes separates one class or classification from another. RST generates reduced information table, which implies that the number of evaluation criteria is reduced with no information loss through rough set approach. And then, this reduced information is used to develop classification rules.
The main objective of this section is to propose an Attribute Reducts Generator algorithm ARG, based on information granulation, to be embedded in the fourth phase of GRM model. Based on RST, a lot of attributes reduction algorithms has been developed recently [37], which can be classified into two categories: (1) Attribute reduction from the view of algebra [38,39]. (2)Attribute reduction from the view of information [40,41]. Algebra view only focuses on the positive region of a decision system, while information view also tries to keep the distribution of inconsistent instances in attribute space besides that. In other words, information view restricts attribute reduction more rigorously. Therefore, a reducible attribute in information view is also reducible in algebra view, but not vice versa. The challenging issues of these methods are multiple computations for equivalent classes and huge number of objects.
Although algebra and information view’s definitions are different [39], both of them need to compute equivalent classes. To compute the equivalent classes, let the decision table is DT= (U, C ∪{D}, V) where d c is a distinguished attribute called decision. The value set of conditions c is
c , c , … . . c , the value set of decisions d is d , d , … . . d ,
and The value set of objects o is o , o , … . . o .The notation c o is used to represent the value of a condition attribute ci ∈ C for an object o ∈ U. Similarly, the notation
d o ) represents the value of the decision attribute d for an object o . The concept of indiscernibility relation is adopted to partition the object set U into disjoint subsets, this partition that includes o is denoted by o R, denoted by
U/R or INDR, as shown:
INDR U/R= o R/ ∈ U . . ………….. (12)
Where
o R/ o | c ∈ R c o . . . (13)
The equivalence classes based on the decision attribute are denoted byU/ d , as shown:
IND U/ d = o |o ∈ U . . . (14)
As described in equation (9) and (10), the objects in R Q
can be classified with certainty as members of Q on the basis of knowledge in R, while the objects in R Q can be only classified as possible members of Q on the basis of knowledge in R. Pos d is the positive region of the partition U/ d with respect to C, it can be defined as the set of all elements of U that can be uniquely classified to blocks of the partition U/ d .
Pos d Q∈U/ R Q . . …..…(15)
A reduct is a minimal subset of attributes from C that preserves the positive region and the ability to perform classifications as the entire attributes set C. A subset R ⊆ C is a reduct of C with respect to d, iff R is minimal, and:
PosR d PosC d . . …... ….... (16)
The core is the most important subset of attributes; it is
Input /SIMR c
LA
i=1
i=|U| True
False
i+=1
MaxRU ⊆ True
LA LA u
False
Generate LA
Input /SIMR c
HA
i=1
i=|U| True
False i+=1
MaxRU True
HA HA u
False
IACSIT International Journal of Engineering and Technology, Vol.3, No.1, February 2011 ISSN: 1793-8236
92 included in every reduct. The Core corresponding to this part of information cannot be removed without loss in the knowledge that can be derived from it, it can be defined as:
Core A, d RED A, d . . .………. (17)
Where RED A, d is the set of all reducts of A relative to
d.Decision Table DT=(U, C∩D), where U is a non-empty, finite set called the universal, C is condition attributes set, D is decision attributes set, R U’, C D , U’ U, R is called sub-decision table of DT. Let p DT denote the set of all sub-decision system of DT, F ⊆ DT is called aF family of decision tableDT, RED DT denotes the set which contains all reducts of decision table DT, and RED R denotes the set which includes allreducts of sub-decision table R.
A decision system at least exists one reduct, which is just itself, so the set of reduct is not empty. In many cases, a given decision table may exist several reducts, as it the case in our decision tables (table2). Each reduct can product a rule set, and it is difficult to justify which is the best rule set. Therefore it is a important to search the most stable reduct, dynamic reduct is proposed in this case. The Dynamic reduct of decision table DT, DR (DT, F), is describes as:
DR DT, F RED DT, d R∈FRED R, d . . . (18)
Any element of DR(DT, F) is called an F-dynamic reduct of DT, which describes the most stable reducts in decision table. From the definition of dynamic reducts, it follows that a relative reduct of DT is dynamic if it is also a reduct of all sub-tables from a given family F. This notation can be sometimes too restrictive, so there is a more general notion of dynamic reduct is applied, it is called (F, ε)-dynamic reducts, Where ε is the dynamic reduct threshold and it ranges 1 ≥ε≥ 0. The set DRε(A, F) of all (F, ε)-dynamic
reducts is defined by:
DR DT, F R ∈ RED DT, d : R∈F:R∈RED R,|F| 1 ε . . . (19) Significance of an attribute can be evaluated by measuring effect of removing the attribute from decision table. Let C and D be sets of condition and decision attributes respectively and let a be a condition attribute, i.e.,
C
a ∈ . The number γ(C,D) expresses a degree of
consistency of the decision table, or the degree of dependency between attributes C and D, or accuracy of approximation of U/D by C. If the attribute a removed, the coefficient γ (C ,D) must changes. The difference between
) ,
(C D
γ and γ (C −{a}, D) is normalized and the
significance of the attribute a, is defined as:
) , (
) }, { ( 1 )
, (
)) }, { ( ) , ( ( ) (
) ,
( C D
D a C D
C
D a C D C a
SigF CD γ
γ γ γ
γ − − = − −
=
. . . (20) It can be denoted by SigF a and it ranges
1 SigF(a)
0 ≤ ≤ . The more important is the attribute a, the
greater is the number SigF a . SigF DTJ, a denotes the
significance factor of attribute a within all attributes in sub-decision table DTJ. The Attribute Reducts Generator
algorithm ARG, shown in figure 9, used to generate reducts for our decision tables. The scenario of using this algorithm is: First, the reducts for the whole decision table DT are calculated by this algorithm. Then this decision table is randomly divided into new sub-systemDT , and the dynamic reducts are computed for each sub-table DT , using ARG algorithm too.
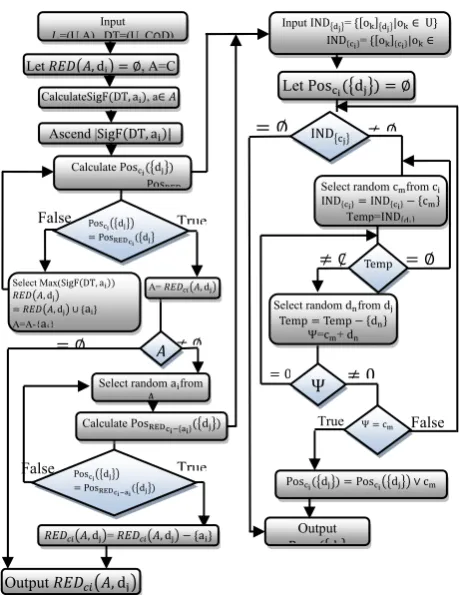
Figure 9: The Attribute Reducts Generator Algorithm (ARG) The above algorithm generates RED A, d , is the set of all reducts of A relative to d by incrementally removing the least informative attribute from it till there is no change in the value of dependency function. The positive region of c with respect to d, Pos d , is also calculated to help in generating the reducts of our decision tables.
4. Rule Generation Phase
The basic notations of rule generation concept are introduced in the fifth phase of the GRM model. The rules generation based on granular rough theory, is the output of this model. According to the condition attributes of decision table, the rules are generated. However, not all condition attributes may need to be checked in the sense that some condition attributes are essential to classify and the other attributes are redundant. When the reduced decision table = {U, C ∪D, V} is obtained from the previous phase. Once reducts are found, generating a set of decision rules from this decision table can be an easy process. Every reduced decision table describes some decisions (actions, results etc.), when some conditions are satisfied. In other words, each row of the decision table specifies a decision rule which determines decisions in terms of conditions [41]. A decision rule expressed as a logical statement: IF
conjunction of elementaryconditionsTHEN disjunction of elementary decisions. The decision rule constructed is denoted from a subset B ⊆ C of condition attribute, the set D of decision attributes and an object x ∈ U by (B, x) → (D, x), or in short B D. Decision table is a finite set of “if ... Then” decision rules. With every decision rule three coefficients are associated: the certainty, the coverage, and the strength factors of the rule. These factors are well-known criteria for evaluating decision rules. The
Supp B D) is the support of the decision rule B D
and defined as:
Supp B D | x B d | . . . (21)
False True
True False
Input =(U A) DT=(U C D)
Select random afrom
A
Let , d , A=C
CalculateSigF DT, a , a∈
Ascend |SigF DT, a |
PosRED
Calculate Pos d
Pos d PosRED d
A= , d
, d , d ai Select Max(SigF DT, a
A=A-{a}
Calculate PosRED d
Pos d PosRED d
, d = , d a
Output , d
0 0
False True
Pos d Pos d c
Input IND = o |o ∈ U IND = o |o ∈
IND IND c
Select random c from c
Temp=IND
Let Pos d
Output
P d IND
Temp
Temp Temp d
Select random dfrom d
Ψ=c + d
Ψ
ce th an co th de By cl th ch nu co cl ea str ar ru in of de w th w co su sa co po w w th or co pe ea m w ef of fo su re pe de in
For any deci ertainty, its in he property D
nd is defined a Cer For any deci overage, its in he property B
efined as follo Cov Where the s y checking v lassify all disc hose correct haracterized b umber of obje overed by the lass. If the rule ach possible d
ronger rules a re shorter and ule can be defi
σ B D
The strength nterpreted eith
f truth. More eterministic f with decision a heorem [42] a without referr oefficients can ubjective asse atisfy Bayes’ onsists in upd osterior proba when data beco
VI. To evaluate with Efficient T he Greedy Dis
rder to validat ompare it wi erformed; each ach experime metrics are eva which can be de The Efficien fficiency of fin f tasks. The ollows:
Where: uccessfully fin equired for acc erforming TA efined setting nvestigate the
IACSI
ision rule B
nterpreted as t in the set of as:
r(B D
sion rule B
nterpreted as t in the set of o ows:
v(B D
et d: is the d values of all cernible eleme
decision cla by the stren ect satisfying t rule, and belo e is approxim decision class are more gene
less specializ ined as:
S B D | |
h, certainty her as probabi eover, they flow distribut algorithms. Th and its applic ring to its
n be comput essment. It is formula. Ba dating prior pr abilities, whic ome available. EXPERIM the performa Task Allocatio stributed Alloc te the effectiv th ETAP and h experiment ent to evalua aluated the E efined as follo ncy Ratio is nished tasks a efficiency of
is nishing the ta complishing th ADM algorith
s. The unit o effects of TA
IT International
D, the degr the frequency f objects havin
S B D | B| . .
D, the degre the frequency objects having
S B D | | . .
decision class l condition a ents in a give asses. Every ngth. The str
the condition p onging to the
ate, the streng separately. G eral because th zed. The stren
. . . (24) and coverag ilities (objectiv
can be also tion in flow his leads to a n cations in rea
probabilistic ted from the s shown that ayesian infere robabilities by ch express up .
MENTS EVALU
ance of TADM on Protocol E cation Protoco veness of TAD
d GDAP two has its own g ate the exper Efficiency Rat
ows:
the ratio be and the total e f a task can
/
the reward sk.
he task. Run T hm in the ne of Run Time ADM, and com
l Journal of Eng I
ree Cer(B
y of objects ha ng the proper
. (22) ee Cov(B
y of objects ha the property
. (23) s such that x attributes, we en decision tab
decision ru rength means part of the rul
suggested dec gth is compute Generally spea heir condition ngth of the dec
ge factors ca ve), or as a d interpreted graphs assoc new look on B asoning from c character.
data or can these coeffic ence methodo y means of da pdated know
UATION M, we compa TAP [18] and ol (GDAP) [1 DM algorithm o experiment oal and setting riment results tio and Run T
etween summ efficiency exp n be calculate
. . . (25) ds gained
is the reso Time is the tim etwork under
is millisecond mpare it with E
gineering and Te ISSN: 1793-823
93
D) of aving rty D,
D) of aving D, its
∈ Di. e can ble to ule is s the e, i.e. cision ed for aking, parts cision an be degree as a ciated Bayes’ data, The be a cients ology ata to wledge are it d with 9]. In m and ts are gs. In s two Time, mation pected ed as from ources me of r pre-d. To ETAP and prov impl at 3 Ethe desig other prop settin In demo comp and follo The the s 360. Fr agen high conti Fi ETA can b more many comm cons proc GDA W syste perfo In test how perfo GDA envir of ag tasks echnology, Vol.3 36
GDAP, a mu vide a testi lemented on a
00GHz, with ernet 512Mbp gned, in whic r,the generatio posed in [22].
ngs have to be
n Experiment
onstrate the pare it with E
figure 11, u ows: The aver number of ag specific test.
The number
Figure 10: The rom figure 10 nts is increasin her and more inually descen igure 11 show AP when the n
be noticed tha e agents in th y reallocatio munication ov sumption of
ess and keep AP relies on n
Figure 11: T While TADM a
ems, and th ormance is fas
n Experiment
the influence different aver ormance of T AP, as shown
ronment and gent’s team i s are 50 and
3, No.1, Februar
ulti-agent syste ing platform a 6 Pc’s with h 3GB of Ra ps. A networ ch most agent on of this netw . For each e e specified.
t 1: The main scalability ETAP and GD using same e
rage number o gents range fro The number
of resources t
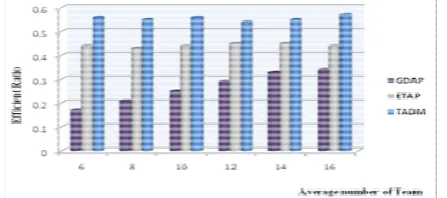
e Efficient Ratio o 0, it is show ng, the Efficie stable than o nding with the ws the Run T numberof age at ETAP spen he network, on steps wh
verhead rising GDAP is st ps a lower lev
eighbouring a
The Run Time on avoid these tw his experimen ster than that o
t 2: The main e of team gro rage number o TADM) and n in figure 12
settings, as f is fixed at 8. d 30 separate
ry 2011
em has been m. The who an Intel Penti am, connected rk of cooper t team are co work can follo experiment, th
n goal of this e of TADM DAP, as show nvironment a of agent’s tea om 100 to 60
of tasks is ra types is range
on different numb wn that when ency Ratio of
of ETAP and e increasing o Time of TAD
nts in the net nds more time this is becau hich results g. On the othe teady during vel than ETA agents only.
different number wo drawbacks nt shows th of GDAP and n goal of this e ouping on TA of agent’s team
compare it w 2 and figure follows: The a
The numbe ely. The aver
implemented ole system
ium 4 process d with netwo rative agents nnected to ea ow the approa here are unifi
experiment is algorithm a wn in figure and settings, am is fixed at
0, depending ange from 60 e from 10 to 60
ber of agents the number TADM is mu d GDAP that
f agents. DM, GDAP a
twork change. e when there a use ETAP ma in time a er hand, the tim
the entire t AP, this becau
r of agents from the rece hat the TAD d ETAP.
experiment is ADM (i.e. sho
m influences t with ETAP a 13, using sam average numb er of agents a
re re re TA an ta th be al pe re nu th ET ne re st co al us th th pr G w on al de m al an (T ta
esources for e esources requi esources types
Figure 12: The
Figure 12 d ADM is much nd ETAP. GD ask allocation he agent.On th
ecause it relie lso other age erformance an esults ensures
Figure 13: T
The Run Ti umber of agen hat the Run Ti
TAP has to eighbours ar eallocation ste eady due to ould decrease llocation proce
But TADM ses any other a he steps taken he time and rocess. So thi GDAP and ETA
VII. In this pape which enables
n two main llocate a spec ecision need mechanism. A llocation in M n algorithm TADM) is pr asks to specific
IACSI
each type is ired by each s is 5.
e Efficient Ratio o
demonstrated h higher and DAP performa in GDAP is o he other hand es not only o ents if needed
nd more stabl and validates
The Run Time on
ime of GDA nts’ team is d me of ETAP o reallocate
e insufficien eps and more its consideri the time and ess.
takes the ben agent if neede n to allocate t
communicatio is is why TA AP.
CONCLUSIO
er, a decision any agent to m
decisions: fir cific task to ded to sele And a survey Multi-agent Sy for the Task roposed show
c agent/s. a G
IT International
30 and the a task is also 3
on different numb
that The Ef more stable t ance is very l only depending d, ETAP has b on neighbours
d. The TADM le than GDAP
our algorithm
different number
AP, ETAP, TA depicts figure
is higher than tasks when nt this lead
time spending ing for only
communicatio
nefits of agen ed, and in the the task which on cost durin ADM has bett
ON AND FUTU n support mo make decision rst, is the d
a specific a ect appropri y of recental ystems is disc k Allocation wing the scen Granular Rough
l Journal of Eng I
average numb 30. The numb
ber of agent’s tea
fficiency Rati than that of G ow this is bec g on neighbou better perform s of the agent M has the h P and ETAP, m.
r of agents’ team
ADM in diff 13. It’s obvi n that of GDA n resources
to increase g. While GDA
neighbours w on cost during
nt’s team and same time red h lead to dec ng task alloc ter Run Time
URE WORK
odule is prop ns needed, foc ecision neede agent. Second iate coordin lgorithms in cussed. In add n Decision M nario of alloc
h Model (GR
gineering and Te ISSN: 1793-823 94 ber of ber of am io of GDAP cause urs of mance t, but higher these ferent ously P. As from e the AP is which g task d also duces crease cation e that posed cused ed to d, the nation task dition Maker cating RM) is prop of T cond scala plan mech we i fram [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] echnology, Vol.3 36
posed to gener TADM.Finall ducted, in abilityadvanta to propose hanism select ntend to prop mework.
Gruver, W., “Tec Systems”, IEEE A. El-Desouky Decision Suppo International C WORLDCOMP’ T. Bui and J. Le support systems” 237.
S.D. Pinson, J.A support system f vol. 20 1, 1997, p Song Qiang, Li Multi-agent Inte pp.572-575, 201 Engineering and Rustam and Bija framework and a 41, Sept., 2004, p Wang Fuzhong Distribution Ne dcabes, pp.214-Distributed Com and Science, 201 Tosic, P.T., Agh Formation For T In: Ishida, T., G (LNAI), vol. 344 X. Zheng and S cooperative agen Autonomous Ag 559–566, Estoril S. Kraus, O. S uncertain heter International Co Systems (AAMA Pinedo, M., “Sch Hall, 1995. Davis, R., and S problem solving, R. McAfee, and Economic Litera K. Lerman and electronic marke Multi-Agent Sys July 2000. IEEE O. Shehory and coalition formati S. Abdallah and theoretic model Multiagent Syst Netherlands, July P. V. Sander, D. algorithm for e International Co Systems (AAMA 2002.
M. D. Weerdt, Y social networks Multiagent Syst Hawaii, USA, M Dayong Ye, Qua Efficient Task A pp.11-18, 2009 Distributed Proce ZakiBrahmi, M Agents Based-D Approach Pro M Cheng, J., andW distributed imp Computational E D. J. Watts and networks. Nature Liu Yunxiang, S Triangular norms
3, No.1, Februar
rate the rules ly, a prelim ndicating age comparing e new algor tion in the de pose a coordin
REFERE
chnologies and A MTT-Chapter Pr and S. El-Gham ort Multi-Agent Conference on
’08 July14-17, 20 ee,“An agent-bas ”Decision Suppo
A. Louca and P for strategic plan pp. 35–51. ingxia Liu, "Th elligent Decision 10 Second Inter Applications, 20 an, “Pluralistic mu
an empirical test, pp. 883-898. g, "A Decision
twork Planning -218, 2010 Ni mputing and App 10
ha, G.A.: Maxim Task Allocation in asser, L., Nakash 46, pp. 104–120. S. Koenig. React nts. In Proceeding gents and Multiag , Portugal, May 2 Shehory, and G rogeneous infor onference on Au AS 2003), pages 1 heduling: Theory
mith, R., “Neogi ,” Artificial Intell d J. McMillan, “ ature, 25, 699–738 d O. Shehory. ets. In Proceeding stems, pages 167 Computer Societ d S. Kraus. Met on. Artificial Inte V. Lesser. Mode l. In Proceeding tems (AAMAS y 2005.
Peleshchuk, and efficient task a onference on Au AS 2002), page
Y. Zhang, and T. . In Proceeding tems (AAMAS May 2007.
anBai, Minjie Zha llocation Protoco IEEE Internati essing with Appli Mohamed Gammo Decentralized and Massive Multi-Age
ellman, M. , “Th plementation of Economics, 12, 1–
S. H. Strogatz. C e, 393:440–442, 1 Sun Jigui, Fuzzy s, Journal ofJlin U
ry 2011
that help in t minary exper that TA g to most rece rithm for th cision suppor nation module
ENCES
Applications of Di resentation, Water mrawy. A Framew t Intelligent S
Artificial Int 008, Las Vegas, N sed framework fo ort Systems ,vol.
P. Moraitis, “A nning,” Decision
he Implement of n Support Syste rnational Confer 010
ulti-agent decisio , ” Information &
n Support Syst Based on Mu inth Internationa plications to Bu
mal Clique Based n Large-Scale M hima, H. (eds.) M Springer, Heidelb tion functions fo gs of 7th Internati gent Systems (AA 2008
. Taase. Coaliti rmation. In Pr utonomous Agen 1–8, Melbourne, y, Algorithms and
itiation as a meta ligence, 20, 63–1 “Auctions and b 8, 1987.
Coalition forma gs of 4th Internati 7–174, Boston, M
ty.
thods for task a elligence, 101:16 eling task allocati gs of 4th Auto 2005), pages
d B. J. Grosz. A allocation. In P utonomous Agen es 1191–1198, B
. Klos. Distribute gs of 6th Auto 2007), pages 5
ang, Khin Than W ol for P2P Multi-a
ional Symposium ications, 2009. oudi, MalekGhe d Scalable Compl ents System. ACI heWALRAS algor general equili –24 ,1998. Collective dynam 1998
logic and fuzzy University(Scied,
the performan riment is th
ADMhas t
ent systems. W he coordinati rt module. Al e in our DMA
istributed Intellig rloo, Canada, 200 work for Distribu
ystem. The 20 telligence ICAI Nevada, USA.
or building decis 25 , 1999, pp.2
distributed decis n Support System
f Blackboard-Ba em," iccea, vol. rence on Compu
on support system & Management, v
tem for Logist ulti-agent System al Symposium usiness, Engineer
d Distributed Gro Multi-Agent System
MMAS 2005. LN berg (2005). or task allocation
ional Conference AMAS 2008), pa
ion formation w roceedings of nts and Multiag Australia, July 20 d Systems”, Prent
aphor for distribu 00, 1983. bidding,” Journal
ation for largesc ional Conference Massachusetts, US
allocation via ag 5–200, May 1998 ion using a decis omous Agents a
719–726, Utrec
scalable, distribu Proceedings of nts and Multiag Bologna, Italy, J
ed task allocation omous Agents a 500–507, Honolu
Win, ZhiqiShen, " agent Systems," i m on Parallel a
enima: Cooperat lex Task Allocat IIDS 2010: 420-4
rithm: A converg ibrium outcome
mics of small wor
reasoning based ,) vol.41 No.1 20
IACSIT International Journal of Engineering and Technology, Vol.3, No.1, February 2011 ISSN: 1793-8236
95 [24] L.A. Zadeh, Toward a restructuring of the foundations of fuzzy logic
(FL), Abstract of BISC Seminar, Computer Science Division, EECS, University of California, Berkeley, 1997.
[25] L.A. Zadeh, Fuzzy sets, Information and Control, 8:338-353 (1965). [26] Z. Pawlak, “Rough Sets”, International Journal of Computer and
Information Sciences, Vol.11.p.341-356, (1982) .
[27] Z.Z. Shi, Z. Zheng, Z.Q. Meng. Image Segmentation- Oriented Tolerance Granular Space Model. IEEE International Conference on Granular Computing, 26- 28 Aug. 2008,Hangzhou, 566-571. [28] M.R. Chmielewski, J.W. Grzymala-Busse, N.W. Peterson, S. Than,
The rule induction system LERS - A version for personal computers, Found. Comput. Decision Sci. 18 (3/4) (1993) 181-212..
[29] Grzymala-Busse J W, Hu M. A comparison of several approaches to missing attribute values in data mining. In Proceedings of the Second International Conference on Rough Sets and Current Trends in Computing (RSCTC’2000). Lecture Notes in Computer Science, Berlin: Springer, 2001, 2005: 378–385
[30] Grzymala-Busse J W. Rough set strategies to data with missing attribute values. In: Proceedings of the Workshop on Foundations and New Directions in Data Mining, associated with the 3rd IEEE International Conference on Data Mining, 2003, 56–63
[31] Wang G Y. Extension of rough set under incomplete information systems. Journal of Computer Research and Development, 2002, 39(10): 1238–1243 (in Chinese)
[32] Wang G Y. Domain-oriented data-driven data mining based on rough sets. In: Proceedings of International Forum on Theory of GrC from Rough Set Perspective (IFTGrCRSP2006), 2006, 46–46.
[33] Kryszkiewicz M. Rough set approach to incomplete information systems. Information Sciences, 1998, 112(1): 39–49
[34] Xiaoping YangAn Improved Model of Rough Sets on Incomplete Information Systems, 2009.
[35] Wang G Y. Rough Set Theory and Knowledge Acquisition. Xi’an: Xi’an Jiaotong University Press, 2001, 38–39 (in Chinese)
[36] Wang,G.Y., Zhao,J., An,J.J., Wu,Y.: Theoretical Study on Attribute Reduction of Rough Set Theory: in Algebra View and Information View. Third International Conference on Cognitive Informatics. (2004) 148-155
[37] Bosse, E., Jousseleme, A.L., Grenier, D.: A new distance between two bodies of evidence. In: Information Fusion, vol. 2, pp. 91–101 (2001) [38] 3. Elouedi, Z., Mellouli, K., Smets, P.: Assessing sensor reliability for
multisensor data fusion within the transferable belief model. IEEE Trans. Syst. Man cyben. 34(1), 782–787 (2004)
[39] Fixen, D.: The modified Dempster-Shafer approach to classification. IEEE Trans. Syst. Man Cybern. A 27(1), 96–104 (1997); In: Workshop of Data Mining, the 3rd International Conference on Data Mining, Melbourne, Florida, vol. 5663
[40] 5. Modrzejewski, M.: Feature selection using rough sets theory. In: Proceedings of the 1th International Conference on Machine Learning, pp. 213–226 (1993)
[41] A. Skowron, C. Rauszer: The discernibility matrices and functions in information systems, in: R. Słowiński (ed.), Intelligent Decision Support. Handbook of Applications and Advances of the Rough Set Theory, Kluwer Academic Publishers, Dordrecht, 1992, 311-362 [42] Bayes' Theorem Revised – The Rough Set View, Lecture Notes in