Vol 1, No 6 (2013)
Full text
Figure
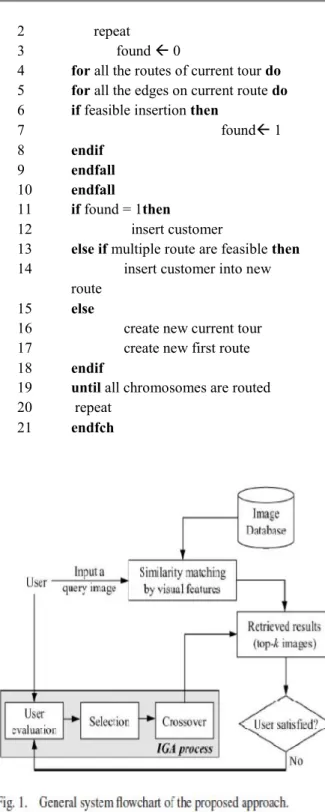
Related documents
As the Rule Verification in Creating module detects the conflicts of rules on device, the Creating Conflict Detection (CCD) compares the rule with the other related rules in
Here, we present the combined results of a multi-proxy and statistical approach to enhance the understanding of the modern sedimentation of Lake El’gygytgyn by analyzing a set
Because they are so widely appreciated, I need not belabor these empirical points. Unless our ability to predict future harm is relatively accurate, the case in favor of any system
Aims and objectives: Aim of this study is to detect NS1 antigen, anti-dengue Ig M antibody by ELISA and Immunochromatography (ICT) methods from a single serum
Hence, this map could be an alternative option for estimating historical N fertilizer inputs in global model studies, although the N dose in our map is based on a simple
The resulting global 0.05 ◦ monthly precipitation climatol- ogy, the Climate Hazards Group’s Precipitation Climatology version 1 (CHPclim v.1.0, doi:10.15780/G2159X), is shown
Quantitative data will be used to define the model and conduct mediation analysis of each translational phase.. Qualitative data will expand on, challenge, and confirm survey
