Explicit and Implicit Acquisition of Opacity:
Initial Evaluations of A Dual-System Model of Grammar
William Thomas Jeffrey Carter
A thesis submitted to the faculty of the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Master of Arts in the Department of
Linguistics.
Chapel Hill 2018
Approved by:
A. Elliott Moreton
Katya Pertsova
ABSTRACT
William Carter: Explicit and Implicit Acquisition of Opacity (Under the direction A. Elliott Moreton)
Despite OT’s success, opaque alternations prove difficult to capture with constraints, and some
violate the theory’s formal restrictions. Here, I propose a novel account of opacity drawing upon
developments in psychology. Rather than one grammar, I propose a dual-system model with implicit
and explicit mechanisms, a domain-specific OT-like system and a domain-general rule-based system
respectively. While the implicit system can handle most linguistic patterns, special cases like opacity
require explicit acquisition. This predicts an advantage for explicit over implicit learning of opacity,
and that elusive substantive bias may manifest by isolating implicit learners.
In an artificial language experiment, participants learned opaque and transparent metathesis
patterns. Despite participants’ difficulty acquiring the patterns, analysis shows a positive effect of
explicit learning for opaque patterns. Additionally, implicit learners, but not explicit learners, show
higher performance for substantively motivated vs. non-motivated patterns. These results tentatively
ACKNOWLEDGEMENTS
Despite this work bearing my name, we all know that behind every thesis, there is a community
of support to which most credit and praise should rightfully be directed. For me, that community
spans far and wide, from the offices of Smith Building, and my family home in Wilmington, North
Carolina, to every person across the country with whom I have discussed this project.
In particular, I’d like to thank all of my classmates and professors in the Ling department at
UNC-Chapel Hill who made every class stimulating. From Ling 101, I knew that I wanted to devote
a life to the study of language as a mechanism, and every course thereafter has further cemented my
decision. Additionally, I would like to extend thanks to Joe Pater, Brandon Prickett, and Lisa Sanders
at UMass-Amherst who on more than one occasion provided stimulating feedback on my project as
it evolved.
I’d like to give special thanks to a set of individuals/groups without whom this project would
have never been possible. Firstly, I am indebted to the NSF for their grant, “Inside phonological
learning” (BCS 1651105) given to Elliott Moreton and Katya Pertsova, without which this thesis
would never have been. Thank you also to Katya Pertsova and Jen Smith, my committee members,
who always seemed able to pull a relevant paper out of a hat. It was their exciting “what-ifs” that
made the entire process so stimulating. Of course, I can’t thank enough Elliott Moreton, my adviser
for two theses now. Over the 5 years I have been at UNC, Elliott has always been a remarkable
source of positivity, inspiration, and at least one novel idiom everyday. His excitement for learning
and exploration is contagious, and it has no doubt made me a much better scholar today.
Finally, on a more personal note, I am so grateful for my family and friends who have been
incredibly patient with me over the last year or so. Yutong, your smile is healing, every day with you
brings me joy and peace, and I know that without you here, this thesis may have never been finished.
Mom, dad, and sister, your unconditional love and support, although sometimes baffling to me, is
something I cannot thank you enough for, and I know that I could never be where I am without you.
TABLE OF CONTENTS
LIST OF TABLES . . . ix
LIST OF FIGURES . . . xi
LIST OF ABBREVIATIONS . . . xii
1 INTRODUCTION . . . 1
2 BACKGROUND . . . 6
2.1 Formal Restrictions of Optimality Theory . . . 6
2.1.1 Harmonic Ascent . . . 6
2.1.2 Output-drivenness and Idempotency . . . 7
2.2 The Problem of Opacity . . . 9
2.2.1 Responses . . . 11
2.3 Explicit and Implicit Learning . . . 12
3 A DUAL-SYSTEM MODEL OF GRAMMAR . . . 16
3.1 The Model . . . 16
3.2 Model Predictions . . . 18
4 EXPERIMENT . . . 20
4.1 Conditions . . . 21
4.1.1 Target Patterns . . . 21
4.1.2 Learning Conditions . . . 22
4.1.3 Condition Summary . . . 24
4.2 Task Layout. . . 24
4.3 Stimuli . . . 27
4.3.1 Segmental Inventory . . . 27
4.3.2 Word Structure . . . 28
4.3.3 Triggering vs. Non-triggering Consonant Sequences . . . 29
4.3.4 Training Stimuli . . . 30
4.3.5 Testing Stimuli . . . 32
4.3.6 Stimulus Construction & Recording . . . 33
4.4 Post-experiment Questionnaire . . . 34
4.5 Participants . . . 35
4.6 Hypotheses . . . 36
5 ANALYSIS & RESULTS . . . 38
5.1 Overview . . . 38
5.2 Model 1: Self-reported Strategies and Test Accuracy . . . 40
5.3 Model 2: Experimenter-reviewed Strategies and Test Accuracy . . . 45
5.4 Models 3 and 4: Target Patterns, Learning Conditions, and Experimenter-reviewed Strategy-selection . . . 50
5.4.1 GLM-3, Implicit Learning . . . 50
5.4.2 GLM-4, Explicit Learning . . . 52
6 DISCUSSION & CONCLUSIONS . . . 55
6.1 Hypothesis I . . . 55
6.2 Hypothesis II . . . 57
6.3 Hypothesis III . . . 58
6.4 Conclusion & Future Steps . . . 59
A EXPERIMENT MATERIALS . . . 62
A.1 Prompts and Instructions . . . 62
A.2 Questionnaire . . . 64
A.3.1 Wordset 1 . . . 66
A.3.2 Wordset 2 . . . 68
B EXAMPLES OF DISPUTED STRATEGY REPORTS. . . 71
B.1 Training Intuition . . . 71
B.1.1 SR = true, ER = false . . . 71
B.1.2 SR = false, ER = true . . . 72
B.2 Testing Intuition . . . 72
B.2.1 SR = true, ER = false . . . 72
B.2.2 SR = false, ER = true . . . 73
B.3 Sought a Rule . . . 73
B.3.1 SR = true, ER = false . . . 73
B.3.2 SR = false, ER = true . . . 74
B.4 Stated a Rule . . . 74
B.4.1 SR = true, ER = false . . . 74
B.4.2 SR = false, ER = true . . . 75
C CODE . . . 76
LIST OF TABLES
2.1 Counter-feeding and Counter-bleeding Opacity . . . 10
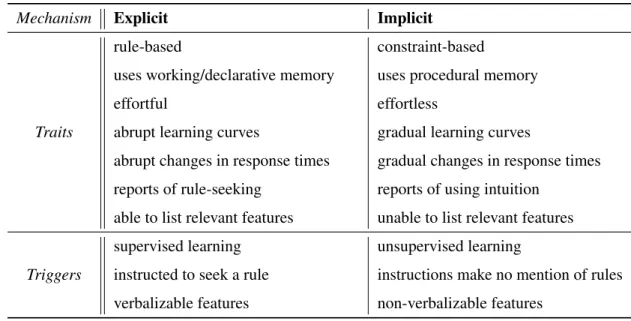
2.2 Traits of Explicit and Implicit Learning . . . 13
4.1 Target Pattern Conditions . . . 21
4.2 Target Pattern Properties . . . 22
4.3 Condition Summary . . . 24
4.4 Consonant phonemes for artificial languages . . . 28
4.5 Segment Classes . . . 28
4.6 CAlt. Seq. . . 29
4.7 NCSAlt. Seq. . . 29
4.8 NCNSAlt. Seq. . . 29
4.9 C-Pattern Training Stimuli . . . 30
4.10 NCS-Pattern Training Stimuli . . . 31
4.11 NCNS-Pattern Training Stimuli . . . 31
4.12 C-Pattern Test Stimuli . . . 32
4.13 NCS-Pattern Test Stimuli . . . 33
4.14 NCNS-Pattern Test Stimuli . . . 33
4.15 Participant Condition Assignments . . . 36
5.1 Proportion Correct by Experiment Condition . . . 38
5.2 GLM-1 Predictor Variables . . . 40
5.3 GEE Coefficient Estimates for GLM-1 . . . 41
5.4 GLM-1, Comparison of Explicit and Non-Explicit Learners for PatternC. . . 42
5.5 GLM-1, Comparison of Explicit and Non-Explicit Learners for all Patterns . . . 43
5.6 GLM-2 Predictor Variables . . . 45
5.8 GEE Coefficient Estimates for GLM-2 . . . 47
5.9 GLM-2, Comparison of Explicit and Non-Explicit Learners for all Patterns . . . 48
5.10 GLM-2, Comparison of Implicit and Non-Implicit Learners for all Patterns . . . 49
5.11 GLM-3 and GLM-4 Predictor Variables . . . 50
5.12 GEE Coefficient Estimates for GLM-3 . . . 50
5.13 GLM-3, Least-Squares Means Probability Estimates . . . 51
5.14 GEE Coefficient Estimates for GLM-4 . . . 52
LIST OF FIGURES
2.1 Taiwanese tone sandhi circle as attested by Zhang et al. (2006) . . . 7
2.2 Comparison of memory abilities of pattern learners, levelers, and non-learners (copied from Ettlinger et al. 2009) . . . 15
3.1 Dual-system model of grammar . . . 17
4.1 Explicit training format . . . 22
4.2 Implicit training format . . . 23
4.3 Task layout . . . 24
4.4 Training –W1andW2. . . 25
4.5 Training (E) – press Space to hear candidates . . . 26
4.6 Training (I) – press Space to hear correct answer . . . 26
4.7 Training (E) – choose F or J . . . 26
4.8 Training (I) – press Space to continue . . . 26
4.9 Vowel phonemes for artificial languages . . . 27
4.10 Word concatenation process . . . 29
5.1 Proportion Correct by Experiment Condition . . . 39
5.2 GLM-3, Least-Squares Means Probability Estimates . . . 51
LIST OF ABBREVIATIONS
AGL Artificial Gramar Learning
C Circular (Alternation)
DM Declarative Memory
E Explicit
ER Experimenter-reviewed
F FAITH
GEE Generalized Estimating Equation
GLM Generalized Linear Model
I Implicit
L1 First/Native Language
L2 Second Language
M MARKEDNESS
NCNS Non-circular Non-substantive (Alternation)
NCS Non-circular Substantive (Alternation)
OT Optimality Theory
PM Procedural Memory
CHAPTER 1
INTRODUCTION
At the core of phonological inquiry is the question of what cognitive mechanism(s) underlie(s)
our phonological grammars. Since the introduction of constraint-based Optimality Theory (Prince
and Smolensky, 2008) and similar models of grammar, we have seen the unification of previously
disparate fields of study in the domain of phonology, particularly synchronic phonology and typology.
Given a universal constraint set shared by all languages–both adult languageand child language (Gnanadesikan, 2004)–cross-linguistic differences are the result of unique rankings of said constraints,
and the complete set of all possible rankings denotes both the bounds and elements of the complete
human language typology. This notion of Factorial Typology (McCarthy, 2002), in its most radical
form, holds that every rankings is valid, and that ‘gaps’ are merely the result of chance.
However, at least two problems emerge from this conception of phonology: (1)Gaps
correspond-ing to formally-valid rankcorrespond-ings seem too widespread to be merely chance (Steriade, 2001; Pater, 1999),
and(2)Many attested opaque alternations escape efficient representation with constraints, while
some even violate the claimed formal restrictions of OT. With regard to the former issue, there have
been at least several proposals of OT-external factors, usually phonetic, which limit the patterns that
are formalized in the grammar. For example, Myers (2002) suggests that within the set of patterns
representable by constraints, only the subset of those patterns with real phonetic motivation emerge.
Similarly, Steriade’s (2001) P-Map proposes a bias which favors alternations involving minimal
perceptual change between the input and output.
By comparison, the problem of opacity is far more daunting for OT (Chomsky, 1994; Vaux
et al., 2008), and responses to this challenge have fallen into roughly two camps. On the one hand,
those who assume that opacity is ‘psychologically real’ have proposed modifications and additions
theory to account for particular types of opacity (Kirchner, 1996; Gnanadesikan, 1997; Moreton
and Smolensky, 2002; McCarthy, 2007, among others). Such modifications come with their own
afflictions, however, particularly with regard to learnability and typological overprediction.
The opposing camp questions the psychological reality of opacity, suggesting that it is not in
fact active in our grammars (Hooper, 1976; Mielke et al., 2003; Sanders, 2003; Kawahara, 2015),
and is instead the compounded result of multiple distinct (non-opaque) diachronic changes being
encoded in the lexicon. According to this theory, opaque patterns should not be productively applied
to novel forms, yet while some studies confirm this prediction (Zhang et al., 2006; Ettlinger, 2008;
Nagle, 2014), others suggest that speakersdoin fact generalize (Archangeli and Pulleyblank, 1994; Sumner, 2003; Ettlinger, 2008; Chuang et al., 2011). For those claiming that opacity is an illusion of
sorts, any case of productive opacity is a foil, and necessitates consideration of modifications to OT.
In this thesis, I propose that the dichotomy between psychologically ‘real’ and ‘unreal’ is overly
simplistic given what we know about human cognition in other domains. In particular, I question
the assumption that OT (or any similar constraint-based system) underliesallgrammar, and offer an alternative dual-system framework. In the psychology literature, the existence of (at least) two
modes of learning,explicitandimplicit1, is generally accepted, with measurable differences in their
associated behavior and outcomes (Ashby and Maddox, 2005; Newell et al., 2011; Moreton and
Pertsova, 2016). Central to this distinction is the idea that these two modes differ in their underlying
cognitive mechanisms in that implicit learning is cue-based (constraint-based) and unconscious,
while explicit learning is rule-based and conscious. Evidence for both mechanisms has been observed
in phonotactic learning, with the two systems being differentially utilized according to the type of
pattern being learned and the structure of the learning task (Moreton and Pertsova, 2016; Moreton
et al., 2017). In other words, it seems that multiple weapons are available in the acquisitional arsenal,
each with their own strong suits.
If we take seriously the possibility that constraint-based and rule-based learning mechanisms
coexist in the grammar apparatus, this invites the question of how the labor is divided. In formulating
a hypothesis, we should consider the advantages and disadvantages of each system2. As earlier 1The implicit-explicit distinction is one of many that have been proposed in the psychology literature (Evans, 2008). I
choose to use this terminology following Moreton and Pertsova (2016) for the sake of consistency.
2
mentioned, constraint-based theories like OT link together the phonological phenomena of individual
languages with cross-linguistic universals/tendencies, while earlier rule-based theories (Chomsky
and Halle, 1968) lack any encoding ofwhyan alternation occurs and provide no intrinsic reason why similar patters occur across unrelated languages. However, rule-based theories are unperturbed by the
problem of opacity facing OT. For they can either apply two or more rules in succession to produce
opaque phenomena, or they might simply generate a novel rule consisting solely of the UR→SR
mapping as in Two-Level Phonology (Koskenniemi, 1983; Antworth, 1991). These rules are often
relatively simple in logical structure (especially in the case of Two-Level Phonology), suggesting
that they would be easily acquired with an explicit mechanism (which shows a bias for acquiring
structurally simple rules), whereas a constraint-based system would falter. On the other hand, explicit
learning (utilizing declarative memory) requires conscious effort and has been shown to develop
with maturation while implicit learning (utilizing procedural memory) is unconscious, effortless, and
develops much earlier (Finn et al., 2016).
In light of these facts, I propose in this thesis that OT, as an implicit, constraint-based system
of grammar, forms the primary backbone of natural language given that it would require little to
no conscious effort and utilizes procedural memory which is known to be accessible to comparable
degrees by young children and adults. Accordingly, it bears the primary responsibility of accounting
for human-language typology. However, the nature of the constraint-based architecture makes
modeling opacity very difficult. Therefore, the remaining idiosyncratic, opaque patterns that arise
would then be accounted for either with explicit memorization, or with an explicit rule-based system
operating over abstract symbols. The reasons for hypothesizing the auxiliary status of an explicit
system (at least in natural L1 acquisition) include the need for greater effort on the part of the learner
and the fact that declarative memory is slower to develop (often not reaching full maturity until
adulthood).
This dual-system proposal leads additionally to interesting predictions with regard to the
man-ifestation of substantive biases in language acquisition. To date, although there has been some
evidence of substantive bias3(e.g. Wilson, 2006b), a robust effect of substantive grounding remains elusive in artificial grammar learning experiments (Moreton and Pater, 2012). In the dual-system
3
approach, we might attribute these nonfindings to the conflation of explicit and implicit learners in
AGL experiments. Although the domain-generality/specificity of implicit mechanisms remains a
matter of debate, Conway and Christiansen (2005)4find that, although statistical (implicit) learning is available across sensory modalities,modality-specificconstraints affect learning outcomes. On the other hand, explicit learning is generally agreed to be domain-general, although familiarity with
reasoning about the target domain likely plays a role in learning. In the context of the dual-system
model considered here, this leads to the prediction that substantive bias manifests only in instances
where implicit learning mechanisms are applied, and that by identifying and restricting analysis to
implicit learners, substantive bias effects might be found.
To test these predictions, an AGL experiment was carried out which compares the learning
mechanisms that participants apply when faced with acquiring transparent and opaque phonological
patterns. Participants were trained on a pattern of segmental metathesis that was either unidirectional
(C1C2→C2C1) or circular (C1C2↔C2C1). Two unidirectional patterns, each corresponding to one half of the circular pattern, are considered, one being substantively motivated while the other is
not. Predictions were (1) that explicit learners would show strong advantages over implicit learners
for the opaque, circular metathesis pattern, but not necessarily for the unidirectional, transparent
metathesis patterns, and (2) that substantive bias would be observed solely among implicit learners.
Results indicate that although participants in each experiment condition did not perform above
chance on average, there were significant effects for generalized linear models fitted to their data
which bear on the above hypotheses. Significantly greater performance for explicit-learners over
non-explicit learners when acquiring circular metathesis supports hypothesis 1, although there are
mixed results regarding whether or not explicit learning lends a similar advantage when acquiring
the non-circular metathesis patterns.
Some evidence is found for substantive bias when comparing acquisition of the non-circular
substantive and non-circular non-substantive metathesis patterns. Specifically, results show sizable
differences in test accuracy for implicit learners ofNCSandNCNS, although not always in the direc-tion predicted by the comparative substantive grounding of the non-circular alternadirec-tions. However,
no such differences are found between explicit-learners in theNCSandNCNSpattern conditions.
4
Despite the mixed results of the AGL experiment carried out for this project, the results given
above do indicate some promise for dual-system models like the one proposed here. Certainly,
further refinement of the dual-system model and revised experiments are warranted to see whether
CHAPTER 2
BACKGROUND
2.1
Formal Restrictions of Optimality Theory
2.1.1 Harmonic Ascent
In OT, given that all phonological alternations are undertaken to satisfy highly-rankedMconstraints, they are all in other words motivated solely by the desire to reduce markedness in surface forms.
This property is known as Harmonic Ascent (Moreton, 1999; Prince, 1997; McCarthy, 2000), and
holds that for all alternationsA → B, formB must be less marked thanA. A formal definition paraphrased from Prince (1997) is provided in (1) below:
(1) Harmonic Ascent: Assume that there are onlyFandMconstraints, and that for every input there is a completely faithful candidate,A → A. If candidateA → B beats the completely faithful candidate, then it must have been preferred byM constraints, andB must therefore be less marked thanA.
In other words, OT has no place for ‘arbitrary’ or ‘workaholic’ alternations which bring about
either no substantial change in markedness or worse, an increase in markedness. With the constraint
of Harmonic Ascent alone, the range of possible grammars in OT is already drastically reduced, and
we are left only with those patterns which are motivated by the preference for unmarked structures.
In particular, Harmonic Ascent predicts that circular alternations of the formA→B→C . . . A
should be impossible (Moreton, 1999). This follows from the requirement that for any non-faithful
mapping, the winning candidate must be less marked than the purely faithful candidate, and so it must
However, there are in fact attested cases of circular alternations in natural language, the most
notable being tone sandhi circles in Southern Min languages (Zwicky et al., 1987; Barrie, 2006;
Zhang et al., 2006). In these languages, lexical tones undergo sandhi in non-final positions within
a tone sandhi domain. Below we see an attested tone circle from Taiwanese (as reported in Zhang
et al., 2006):
24
33
55
51
21
Figure 2.1: Taiwanese tone sandhi circle as attested by Zhang et al. (2006)
At first glance, the apparent existence of such circular chain shifts presents problems for the
framework of ‘classical’ OT (Moreton, 1999). This assumes, however, that such circular alternations
are actually encoded as productive patterns in the grammars of Southern Min speakers and that
these grammars are constraint-based. Zhang et al. (2006) find that Taiwanese speakers exhibit low
productivity for the alternations involved in the Taiwanese tone circle (2.1) when wug-tested with
novel words. These results suggest that the alternations are not represented in the speakers’ grammars
and are perhaps lexically coded (i.e. memorized) instead.
2.1.2 Output-drivenness and Idempotency
Later work on the formal constraints of OT have led to the proposal of two additional properties of
a classical OT grammar, namely those ofoutput-drivennessandidempotency(Magri, 2013, 2016, 2018; Tesar, 2011, 2014) which further constrain the range of potential grammars that a language
learner would be required to entertain.
Tesar’s (2011; 2014) proposal of output-drivenness stems from the observation that all alterations
of the underlying form are made to satisfyMconstraints and reduce markedness in the surface form. One important trait ofM constraints (as defined in classical OT) is that they are blind to the input and only make restrictions on surface forms. That is, phonological alternations in a classical OT grammar
utilize this notion of output-drivenness to facilitate the simultaneous learning of underlying forms
and constraint rankings through the constructions of output-driven maps. These maps consist of a
large network of all possible forms in an OT grammar with similarity relations among them.
In Tesar’s formulation of output-drivenness, similarity is determined by the number of featural
disparities between two forms (the more disparities, the less similar they are). By this formulation,
Tesar claims that it must be the case that ifA → X, andB is more similar toX thanAis toX, thenB →Xmust also be true. This follows from the property of conservativity in classical OT, by which the candidate consisting of the minimal sufficient changes to an input needed to satisfy theM
constraints will be the winner. Therefore, wereBa licit output,A→Bwould beatA→Xgiven that it applies fewer changes, resulting in fewerF violations.
Contained within Tesar’s output-driven maps is an intermediate condition ofidempotency(Magri, 2016, 2018) which requires that any form that is a winning output for any input must map faithfully
to itself. Given the grammatical mappingA→X, any input that is more similar toXmust also map toX. Of course, since identity constitutes maximal faithfulness, this necessarily implies that the mappingX →Xalso be licit.
(2) Idempotency: Given thatM constraints motivate the alteration of inputs to conform to restric-tions on licit surface forms, it follows that any formXthat is the output chosen for some input
With these two additional constraints on OT, it has been proposed that learners gain an advantage
when learning underlying forms (Tesar, 2011). As Tesar points out, the entailment relationship
between mappings on the basis of input-output similarity as detailed above allows a learner to reduce
the number of potential underlying forms that they need to test in order to arrive at the correct lexicon.
This works by deriving the contrapositive equivalent of the implication. That is1:
((A→X)∧(Sim(B, X)> Sim(A, X)))⇒(B →X)
m
(¬(B →X)∧(Sim(B, X)> Sim(A, X)))⇒ ¬(A→X)
In plain language, the contrapositive states that “IfBdoesnotmap toX, and if B and X are more similar than A and X, then A also does not map to X” (Tesar, 2011). Therefore, if one can determine
that one UR is invalid for a given target output, any other potential URs that are less similar to the
target output are immediately ruled out as well by the contrapositive implication given above, and
the learner need not consider them. With this restriction, learners can quickly reduce the hypothesis
space.
As Magri (2014) notes, the idealizations of idempotency and output-drivenness do not seem to
be universally upheld in natural language which seems to violate both properties in some instances.
In particular, opaque phonological patterns present undeniable counterexamples to these proposed
properties, and are noted as constituting the most formidable challenges to OT on the whole
(Mc-Carthy, 1996, 2007). In §2.2, I shall briefly review the notion of opacity and broadly outline previous
responses to the problems it poses.
2.2
The Problem of Opacity
Kiparsky (1973) defines opacity as an instance in which a phonological rule seemingly either (i)
applies outside of its environment, or (ii) does not apply in its expected environment. These two
events are known as over-application and under-application respectively.
1
(3) Given the rule,A→B/C D:
(i) Over-application: There are surfaceB’s outside the environmentC D. The rule seems to have applied without its necessary conditioning environment.
(ii) Under-application: There are surfaceA’s in the environmentC D. That is, the rule does not seem to have applied when it should have.
In other words, opacity emerges when a given rule does not appear to be surface-true in all cases.
Explanations for how opacity might emerge have generally focused upon the interaction of multiple
ordered rules applied serially to an input (McCarthy, 2007; Bakovic, 2011). The two primary types of
opacity that emerge from rule interactions are known as counter-feeding opacity and counter-bleeding
opacity. These two types are illustrated in Table 2.1 below with examples pulled from Bakovic (2011):
Table 2.1: Counter-feeding and Counter-bleeding Opacity
Step Rule Def. CF CB
UR /tue/ /tio/
Rule 1 t→tj/ [−back] — [tjio]
Rule 2 V →∅/ V [te] [tjo]
SR [te] [tjo]
Examples drawn from Bakovic (2011).
CF: Rule 2counter-feedsRule 1 (under-application)
CB: Rule 2counter-bleedsRule 2 (over-application)
In derivation CF,/tue/→[te], we see counter-feeding opacity where the application of Rule 2 creates the environment in which Rule 1 would apply had it not already applied prior to Rule 2. That
is, although Rule 2feedsRule 1 for the given input, Rule 2 appears to have no effect since it applies before the triggering environment is generated by Rule 2, and so the rules are incounter-feeding order. This manifests as the apparentunder-applicationof a rule.
However, Rule 1 applies before Rule 2 destroys the conditioning environment, and the two rules are
thus incounter-bleeding order.
In its manifestation, opacity obscures the identity of a phonological rule, namely the true identity
of the conditioning environment. From this, it follows that opacity presents significant obstacles to
the acquisition of phonology since a learner must somehow piece apart the definitions of individual
rules from their interactions. Although it is perhaps most easily definable in such terms, opacity is not
limited to a system formed of ordered rules, and can be understood in the context of constraint-based
OT (McCarthy, 1996, 2007).
Referring back to the notions of output-drivenness and idempotency, opacity is ultimately a
violation of these properties. By output-drivenness, an OT-grammar’s markedness constraints are
formulated solely as restrictions on surface forms, and cannot refer to the underlying form. In other
words, opaque processes cannot be reduced to the problem of minimally altering an input to satisfy
regular phonotactics. With opaque processes, it is necessary to know the correct underlying form
when calculating markedness violations of candidate SR’s.
Given the problems opacity poses to OT, much work has been dedicated to rectifying it with
what is otherwise a powerful and unifying theory of phonological grammar. In the next section
(§2.2.1), I shall briefly summarize such work.
2.2.1 Responses
Without modifications or extensions to classical OT, it seems that the theory is incapable of dealing
with opacity (as discussed in §2.1 and §2.2), and this has indeed led some to question it as a viable
theory of phonology (Chomsky, 1994; Vaux et al., 2008) given the prevalence of opacity across
natural languages. However, others have responded with modifications to OT that allow it to represent
opaque interactions (Kirchner, 1996; Gnanadesikan, 1997; Moreton and Smolensky, 2002; McCarthy,
2007, among others).
Others have questioned the extent to which opacity needs to be modeled in synchronic
gram-mar, suggesting that it might not be psychologically real for individual speakers (Hooper, 1976;
Mielke et al., 2003; Sanders, 2003; Kawahara, 2015). Members of this camp instead believe that
opacity is either (1) a productive pattern modeled by a single unordered rule (Hooper, 1976), or (2) a
Smolen-sky, 2008) whereby grammatical alternations are slowly lexicalized and two or more transparent
alternations are lexicalized sequentially to produce seemingly opaque forms (Sanders, 2003).
To determine the psychological reality of opaque patterns, a good first place to start is testing the
productivity of opaque phonology in natural language. If opaque processes are truly lexical artifacts,
then they should not be applied productively, and there is no need to model them in the grammar. If
wedofind a case of productive opacity, then this invites the question of how OT (or any theory of grammar) can model it.
Findings are mixed, and while some find that opaque interactions seem not to be productive
(Zhang et al., 2006; Ettlinger, 2008; Nagle, 2014; Kawahara, 2015), others have found that speakers
doseem to apply them productively (Archangeli and Pulleyblank, 1994; Ettlinger, 2008; Chuang et al., 2011). While we might attribute these mixed results to differing methodology, it perhaps raises
the question of whether the distinction between psychologically real vs. non-real is too simplistic.
With this distinction alone, any case of seemingly productive opacity is a point for those who suggest
extending classical OT to account for it, but as others have noted, proposed modifications prove
typologically overpredictive (Wilson, 2006a; Pater, 2016).
Given the above concern and the learnability guarantees of classical OT, it is a worthwhile
effort to explore other means of taking away from OT the responsibility of capturing productive
opacity (where it occurs). In the following section (§2.3), I shall review the explicit/implicit learning
distinction which, combined with a dual-system model of grammar, might do just that.
2.3
Explicit and Implicit Learning
Underlying previous work seeking to account for phonological opacity, is the assumption that
language-users are restricted to a single system of learning and/or implementing grammar. That is,
human grammar is modeled either solely with constraints, or solely with rules. However, it seems
that we have yet to arrive at a theory (or genus of theories) that performs universally better than
competing hypotheses respective to every facet of observed linguistic behavior. While derivational
rules lack any form of instrinsic motivation, they prove very capable of capturing opacity in a simple
language-specific phonology with broader typological patterns, opacity remains a formidable obstacle.
In other words, each theory of phonological grammar comes with its strengths and weaknesses.
While many linguists remain beholden to a single-system approach to grammar, psychologists
have come to posit multi-system models of cognition which capture the multiple ways in which
subjects have been observed to approach pattern-learning problems (Newell et al., 2011). Moreton
and Pertsova (2016) note that a widespread assumption in the AGL literature is that all participants
implement a common learning process, and that this assumption might obscure the behavior of
participants in analysis if they actually fall into sub-groups implementing different learning processes.
While numerous dual-/multi-system models exist in the psychology literature (Evans, 2008), I
follow the precedent of Moreton and Pertsova (2016) in distinguishing betweenimplicitandexplicit learning mechanisms. Explicit learning(also referred to as declarative learning) is thought of as effortful rule-based hypothesis testing carried out in the working memory, with the end-result being
a learned set of simple rules (Ashby and Maddox, 2005; Newell et al., 2011).Implicit learningis postulated to be effortless, unconscious, similarity-based, and carried out in procedural memory
(Ashby and Maddox, 2005; Newell et al., 2011). A summary list of attested characteristics of each
type of learning are given below in Table 2.2:
Table 2.2: Traits of Explicit and Implicit Learning
Mechanism Explicit Implicit
rule-based constraint-based
uses working/declarative memory uses procedural memory
effortful effortless
Traits abrupt learning curves gradual learning curves
abrupt changes in response times gradual changes in response times
reports of rule-seeking reports of using intuition
able to list relevant features unable to list relevant features
supervised learning unsupervised learning
Triggers instructed to seek a rule instructions make no mention of rules
The existence of at least two learning mechanisms poses the interesting question of what each
distinct system is responsible for learning. It could be that either system is applicable for a job, but
it is more likely that the systems exhibit distinct advantages depending upon the types of patterns
being learned and the structure of the learning task. With regard to language, for instance, we
know that natural language acquisition is largely unconscious, and can be carried out by even young
children, suggesting that it is carried out primarily with an implicit mechanisms. Furthermore, we
often find that speakers of a language are unaware of many of the phonological alternations they
apply automatically, and that they often struggle to reason consciously about phonological features in
their native language, suggesting that explicit mechanisms do not underly much of native language
acquisition.
Accordingly, Finn et al. (2016) find that whereas declarative memory (associated with explicit
learning) does not fully mature until adulthood, comparable degrees of procedural memory (associated
with implicit learning) are found in young children and adults, suggesting that it matures much earlier.
This provides evidence that the learning mechanisms accessible to young children are implicit and
constraint-based in nature, while explicit learning mechanisms develop later.
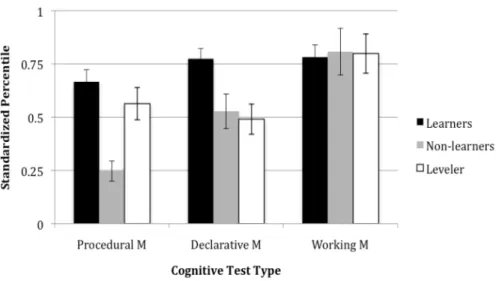
Ettlinger et al. (2009) compared participants’ acquisition of an artificial grammar featuring
transparent and opaque forms with their performance on battery tests of procedural and declarative
memory. Participants were divided based upon their learning behavior into three groups: (1)learners, who acquired both opaque and transparent forms, (2)levelers, who acquired only transparent forms, and (3)non-learners, who failed to acquire either set of forms. Compared with non-learners, learners and levelers both showed higher performance on procedural memory. Learners and levelers are
distinguished by higher declarative memory performance on the part of learners, suggesting that
Figure 2.2: Comparison of memory abilities of pattern learners, levelers, and non-learners (copied from Ettlinger et al. 2009)
To summarize, the evidence discussed here, including psychological literature and AGL studies,
points to the existence of multiple learning mechanisms with substantive differences between them.
This thesis considers the explicit/implicit distinction. Implicit learning is unconscious, effortless,
likely constraint-based, dependent upon procedural memory, and accessible to young children.
Explicit learning is conscious, effortful, dependent upon declarative memory, becomes accessible
with maturation, and it is likely rule-based. In the context of transparent vs. opaque phonology,
learners accessing declarative memory show an advantage in acquiring opaque forms, while showing
access of procedural memory indistinguishable from that of learners acquiring only transparent forms
(Ettlinger et al., 2009). With all of these points in mind, we are able to make specific predictions
CHAPTER 3
A DUAL-SYSTEM MODEL OF GRAMMAR
In this section, I introduce my proposed dual-system model of grammar and its predictions with
regard to phonological learning. Rather than subscribing to a solely constraint-based or rule-based
account of phonology, I propose that both systems are utilized in the acquisition and modeling of
target patterns.
3.1
The Model
As discussed in §2.3, a wealth of literature supports the existence of explicit and implicit learning
modes (Ashby and Maddox, 2005; Evans, 2008; Newell et al., 2011; Finn et al., 2016; Moreton and
Pertsova, 2016; Moreton et al., 2017), and AGL experiments confirm that both modes are utilized in
phonological learning (Moreton and Pertsova, 2016; Moreton et al., 2017). The implementations
of these explicit and implicit modes have been hypothesized to be rule-based and constraint-based
respectively (Moreton and Pertsova, 2016; Moreton et al., 2017). In the history of phonological
theory, we have seen both rule-based models (e.g. Chomsky and Halle, 1968), and more recently,
constraint-based models (e.g. Prince and Smolensky, 2008), each with their own strengths and
weaknesses. While OT clearly encodes the motivation for phonological alternations in its constraints,
OT in its simplest form struggles to account for opaque interactions. While rule-based phonology
excels in capturing opaque interactions, it does not encode the motivation for an alternation and
makes no typological predictions.
Given this and evidence for multiple learning modes, rather than restricting ourselves to one
model, I propose a synthesis of these two models into a dual-system approach to grammar. In essence,
the idea is that learners can access both a rule-based explicit mechanism and a constraint-based
likely include the comparative development of the two mechanisms (Finn et al., 2016), the learning
environment/task, and the nature of the target pattern (Ashby and Maddox, 2005; Moreton and
Pertsova, 2016; Moreton et al., 2017).
In natural first language acquisition, I propose that the implicit mechanism (OT) dominates given
that declarative (explicit) memory is undeveloped early in life (Finn et al., 2016). As learners age
and their declarative memory develops, they may come to rely more and more upon the explicit
systems, especially if the critical period hypothesis holds and aging limits our access to the implicit
mechanism (DeKeyser and Larson-Hall, 2005; Lichtman, 2012). Further support for a primary
OT-like grammar comes from the fact that implicit learning requires little/no effort and is carried out
unconsciously (§2.3). Target pattern Target pattern Target pattern Task type Task type Task type Strategy selector Strategy selector Strategy selector
I E I E I E
PM DM PM DM PM DM
Initial state Childhood Adulthood
Gr
ammar
PM= Procedural memory,DM= Declarative memory,I= Implicit learning mechanism,E= Explicit learning mechanism
Figure 3.1: Dual-system model of grammar
Figure 3.1 above illustrates the proposed dual-system model where target patterns can be
acquired by multiple means. In the initial state, only the implicit mechanism is accessible due to
the undeveloped state of a child’s declarative memory. As the child ages, however, the declarative
memory develops (represented by a darkening arrow), and the child becomes able to engage in
explicit phonological acquisition. Depending upon the validity of the critical period hypothesis
(contrasting views from DeKeyser and Larson-Hall, 2005; Lichtman, 2012), access to procedural
As for the issue of strategy selection, I do not propose that it is a conscious decision, but rather
that environmental factors like the learning format and target pattern bring about mental states that
might favor one strategy or the other. Erickson (2008) tested adult’s ability to perform two tasks
involving the visual categorization of stimuli in 1-D and 2-D patterns (in the same two dimensional
stimulus space). Participants completed these tasks in repeated alternation, and Erickson finds that
more successful learners showed evidence of task-switching costs. That is, high-scoring participants
do not use only one learning mechanism for both tasks, but rather they select a mechanism according
to the structure of the pattern/stimuli. In the case of linguistics, we might propose that language
learners are similarly able to identify the dimensional complexity of an alternation early in the
learning process and choose their strategy accordingly.
3.2
Model Predictions
With my conception of a dual-system grammar put forth, let us consider its behavioral predictions in
the context of phonological acquisition. The primary concern of this thesis is the problem of opacity,
and the dual-system model overcomes it parsimoniously by supplementing an OT-like implicit
learning mechanism with a rule-based explicit mechanism which has no difficulty with opacity.
When faced with opaque patterns, a learner is forced to access their explicit learning mechanism if
they are to acquire the pattern successfully. In other words, we should find a significant advantage on
the part of explicit learners over implicit learners on novel opaque alternations. Furthermore, if it is
true that the strategy selection mechanism is sensitive to the characteristics of a pattern, then we may
also see that opaque patterns lead to higher rates of explicit strategies (independent of the type of
learning task).
The dual-system model is also relevant to the question of substantive bias in language acquisition
and whether it exists (Wilson, 2006b; Moreton and Pater, 2012). Despite the difficulty of finding
evidence for robust substantive bias effects (Moreton and Pater, 2012, for a review of findings), it
seems unlikely that the substance of a pattern (just beyond its logical complexity) plays no role
in acquisition. One advantage of OT (over rules) is the substantive content of constraints, which
makes strong typological predictions favoring patterns that simplify forms and/or ease articulation.
regarding substantive bias effects are not encouraging. However, knowing that explicit and implicit
mechanisms are both utilized in phonological learning (Moreton and Pertsova, 2016), we should first
separate participants into groups by their learning style and investigate substantive bias factored by
learning mechanism. The prediction of the dual-system model is that substantive bias should become
visible when implicit-learner data are isolated. In previous studies, the conflation of implicit and
explicit learners has perhaps masked true substantive bias effects, and it seems the case that laboratory
experiments often prompt higher rates of explicit strategies (Moreton and Pertsova, 2016; Glewwe,
2017). As for why we wouldn’t see substantive bias effects among explicit learners, this follows
from the explicit mechanism being domain-general. To summarize, the small set of predictions made
by the dual-system model are as follows:
(4) Some predictions of the Dual-System Model
(i) Opaque phonological interactions cannot be acquired implicitly, and require explicit learn-ing to acquire successfully
(ii) When faced with opaque phonological alternations, participants are driven to attempt explicit learning at higher rates than when faced with transparent phonology
CHAPTER 4
EXPERIMENT
To test the predictions of the dual-system model with regard to phonological opacity and
substantive bias, an AGL experiment was carried out in which participants were tasked with
ac-quiring a metathesis pattern triggered by word-concatenation and restrictions on licit sequences
of[+voice]/[−voice]obstruents. Participants were told that they were learning words in an alien language, and object-to-word mappings were used to reinforce the word-learning setting. The reasons
for choosing to test segmental metathesis include the simplicity of designing opaque patterns and
previous experiments showing participants’ ability to acquire metathesis patterns in a lab setting
(Finley, 2017). The experiments consisted of a training block followed by a test block which tested
generalization of the learned pattern to novel segment sequences.
Similar to previous experiments in the Concept Lab program (UNC & UMass), experiment
conditions were varied both by the types of pattern being learned, and the structure of the training
task. Participants were randomly assigned one of three target patterns: (1) Circular metathesis of the
formAB↔BA, (2) substantively motivated non-circular metathesis of the formAB→BAwhere the alternation reduces markedness, and (3) substantively unmotivated non-circular metathesis of the
formBA→AB1where the change increases markedness. Of these patterns, circular metathesis is
opaque and violates the property of Harmonic Ascent (§2.1.1) and idempotency (§2.1.2), whereas
the non-circular patterns are both transparent. By comparing the performance of different types of
learners (explicit and implicit), we can test the prediction that explicit rules/memorization facilitates
the acquisition of opaque phonology.
1
4.1
Conditions
4.1.1 Target Patterns
In this task, participants were instructed to learn how to concatenate two simple CVC words in
order to represent concept conjunction. For example, given/W1/=“cat” and/W2/=“dog”, then /W1+W2/=“cat and dog”. All concatenated words will thus have the structure[CV C.CV C]. Alternations are triggered to satisfy restrictions on allowableCCsequences, and depend upon the target pattern condition assigned to the participant:
Table 4.1: Target Pattern Conditions
Pattern Abbreviation Rule(s) Examples
Circular C [+voice]A[−voice]B→BA
[−voice]A[+voice]B→BA
/kib.tug/→[kit.bug] /tap.bik/→[tab.pik]
Non-circular
substantive NCS [−voice]A[+voice]B→BA /kib.tug/→[kit.bug]
Non-circular
non-substantive NCNS [+voice]A[−voice]B→BA /sEv.piz/→[sEp.viz]
The three target patterns used in the experiment are listed in Table 4.1. The circular pattern (C)
can be described in plain English as “if neighboring consonantsAandBdiffer in voice, switch their order”. This pattern is inevitably opaque since the application of one half of the pattern looks like an
underapplication of the other half. Therefore, it should be incredibly difficult to model in OT, and is
expected to present difficulty for implicit learners. On the other hand, both non-circular conditions
(NCS and NCNS) are entirely transparent and obey the formal restrictions of OT. We can predict that
the NCS pattern,[−voice]A[+voice]B→BA, is substantively motivated since it alters the output to better conform to the sonority sequencing principle (have sonorous codas and nonsonorous onsets).
Table 4.2: Target Pattern Properties
Pattern OT-valid? Substantively motivated?
Explicit advantage
Implicit advantage
C 7 7 3 7
NCS 3 3 ? 3
NCNS 3 7 ? 7
4.1.2 Learning Conditions
In addition to assigning participants a target pattern, one of two learning tasks was also assigned
randomly to each participant. These tasks were designed to encourage either implicit or explicit
learning.
Explicit
In the explicit task, participants received instructions that sometimes the sounds in the concatenated
form undergo change, and that there is a rule they can find that will them to accurately predict when
these changes occur2. In the training portion of the experiment, participants were forced to choose between two candidates for the correct concatenated form of two words (do/don’t metathesize), and
received feedback on whether their choice was correct or incorrect. All of these factors are known to
encourage access of the explicit learning mechanism (§2.3, Figure 2.2).
Hear W1 Hear W2 Hear candidates Receive feedback Hear correct answer 1000ms Press Space Choose
F or J
500ms 1000ms
Figure 4.1: Explicit training format
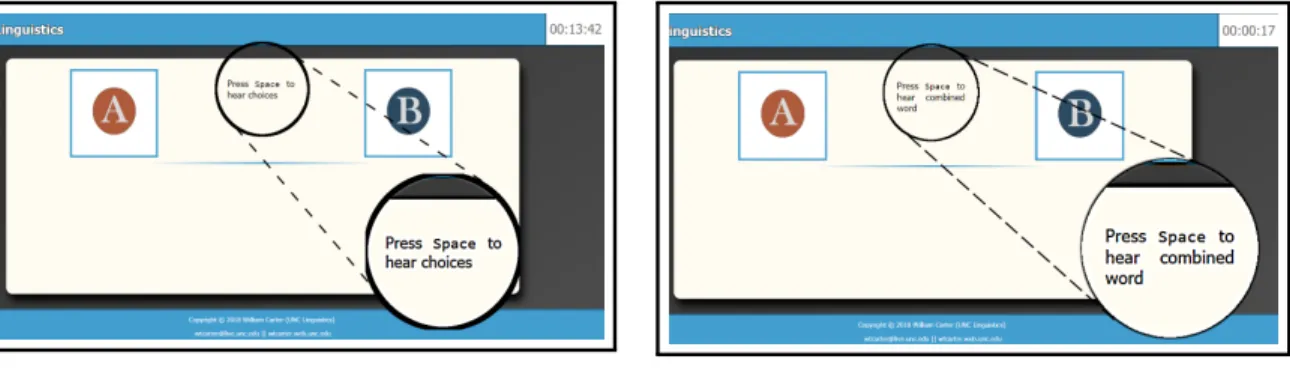
The trial format for the explicit learning condition is shown above in Figure 4.1. First, participants
heardW1 andW2 with 1000ms of silence between the recordings. Next, they were instructed to press Space in order to hear the candidate realizations of/W1+W2/(also with 1000ms between them). Participants were finally instructed to press either F for candidate one, or J for candidate
2
two. If correct, participants heard a delightful ‘ding’, and if wrong, participants heard a disappointed
‘wah-wah’. Regardless of their answer, participants then heard the correct answer again after 500ms
of silence, and moved onto the next trial after an additional 1000ms of silence.
Implicit
In the implicit task, participants received instructions that sometimes the sounds in the concatenated
form undergo change, and to pay attention to the recordings which will show them how to combine the
words correctly3. Unlike participants in the explicit task, no mention was made of a potential pattern for them to learn. They were specifically instructed to use their intuition. In the training portion of
the experiment, participants made no decisions, and were only given the correct concatenated form
for each stimulus item. Both of these factors are known to encourage access of the implicit learning
mechanism (§2.3, Figure 2.2).
Hear
W1
Hear
W2
Hear
W1W2
Hear
W1W2
1000ms Press
Space
1000ms
1500ms
Figure 4.2: Implicit training format
The trial format for the implicit learning condition is shown above in Figure 4.2. First,
partici-pants heardW1andW2with 1000ms oof silence between the recordings. Next, they were instructed to press Space in order to hear the correct realization ofW1+W2two times with an intervening 1000ms of silence. Participants then moved on to the next trial after 1500ms of silence.
3
4.1.3 Condition Summary
Each participant received a randomly selected combination of target pattern (Table 4.1) and learning
condition (Table 4.1.2), meaning that the experiment had a total of 6 conditions in a2×3design (3 patterns by 2 learning conditions).
Table 4.3: Condition Summary
T P
C NCS NCNS
Explicit E-C E-NCS E-NCNS Implicit I-C I-NCS I-NCNS P=Pattern type
T=Task type
4.2
Task Layout
The AGL experiment consisted of three phases: (1) a practice phase, (2) a training/learning phase,
and (3) a testing/generalization phase. In the practice phase, participants were familiarized with the
trial structure by completing 2 trials with basic English words—[pear, melon] and [apple, lemon]. In
the training phase, participants completed 72 learning trials (either explicit or implicit trials according
to their assigned learning condition, §4.1.2). In the testing phase, participants completed 48 test
trials.
Training trials
Testing trials Practice
trials
×2 ×72 ×48
4.2.1 Trial Formats
Training Trials
The format of each training/practice trial was as presented in §4.1.2. At the beginning of a training
trial, participants were presented with two objects, and the words corresponding to each object were
played for them with 1000 ms of intervening silence (Figure 4.4).
Figure 4.4: Training –W1andW2
Once participants heardW1 andW2, they were instructed to press Space in order to move on in the trial (Figures 4.5 and 4.6). In theE learning condition, participants were then given two candidates for the correct concatenation ofW1 andW2, a faithful candidate and a metathesizing candidate presented with an intervening 1000 ms of silence (Figure 4.7), after which they were asked
to press F (to choose candidate 1) or J (to choose candidate 2). In theI learning condition, pressing Space led to the presentation of the correct concatenation form repeated twice by the ‘alien’
Figure 4.5: Training (E) – press Space to hear candidates
Figure 4.6: Training (I) – press Space to hear correct answer
After making a choice in theElearning condition, participants then received feedback in the form of a positive ‘ding’ or a negative ‘wah-wah’ sound. After 500 ms, they were then played the
correct answer followed by 1000 ms of silence before moving on to the next trial.
In theIlearning condition, after hearing the two repetitions of the correct concatenated form, participants were instructed to press Space to move on to the next trial (Figure 4.8). Upon pressing
Space, participants moved on to the next trial after 1500 ms of silence.
Figure 4.7: Training (E) – choose F or J Figure 4.8: Training (I) – press Space to con-tinue
Testing Trials
After completing 72 training trials, participants moved onto the testing phase of the experiment. Prior
to beginning the testing trials, participants were given instructions on how the testing trials differed
from those they had seen in training (see Appendix A for complete instructions). In particular, they
for properly combiningW1andW2. In addition, participants were told that they would receive no feedback on whether they were correct or incorrect.
Each of the 48 testing trials was formatted almost identically to explicit training trials (see Figure
4.1) with the only difference being the removal of feedback. The 500 ms of silence between response
and playing the correct form was added to the 1000 ms resulting in a total of 1500 ms of silence
between testing trials.
4.3
Stimuli
4.3.1 Segmental Inventory
All artificial languages consisted of an identical segmental inventory. Languages were based in a
six-vowel system[A, E, i, o, u, 2]. It should be noted that/o/was pronounced as a diphthong,[oU], as in General American English. Although this created a slight asymmetry in the features of the
vowel system4, making the phonemic inventory as familiar as possible was of higher importance (so
that learners would be able to tend to the alternation straight away).
i
o
A E
u
2
Figure 4.9: Vowel phonemes for artificial languages
The consonant inventory available to the artificial languages consisted entirely of 12 obstruent
segments (since nasals/liquids/etc. can’t bear a voicing contrast in English). The consonant inventory
is shown in Table 4.4 below.
4
Table 4.4: Consonant phonemes for artificial languages
LABIAL ALVEOLAR
ALVEO-PALATAL VELAR
plosive p b t d Ù Ã k g
fricative f v z S
Segments can be grouped into three classes. In addition to the vowel group, henceforth denoted
V, consonants are divided into[+voice],D, and[−voice],T classes. These classes are important, for all target patterns are triggered by illegal sequences of[±voice]consonants.
Table 4.5: Segment Classes
Class Abbr. Members
[+voice] D [b v d z à g]
[−voice] T [p f t S Ù k]
Vowels V [A i u E o 2]
4.3.2 Word Structure
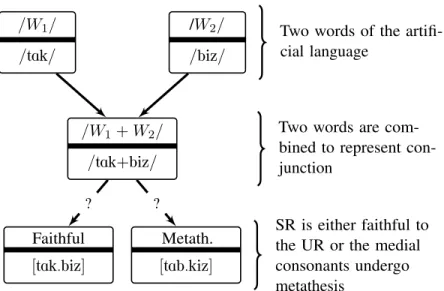
In the target artificial languages, all words are of the formCV C. When two words,W1andW2, are concatenated,W1+W2, the resulting word’s structure isCV C.CV C, which denotes the conjunction ‘W1 andW2’. Through concatenation, a word-medial consonant cluster is created. Clusters can be classified into four categories according to the voicing of the first and second consonant: DD,
/W1/ /tAk/
/W2/ /biz/
/W1+W2/ /tAk+biz/ Faithful [tAk.biz] Metath. [tAb.kiz] ? ?
Two words of the artifi-cial language
Two words are com-bined to represent con-junction
SR is either faithful to the UR or the medial consonants undergo metathesis
Figure 4.10: Word concatenation process
4.3.3 Triggering vs. Non-triggering Consonant Sequences
What subset of consonant sequences (DD,DT,T D,T T) triggers metathesis depends upon the target pattern condition. In theCpattern conditions, bothT DandDT sequences trigger metathesis (while
T T andDDsequences are realized faithfully). The circularity of this target pattern should be clear since the output of metathesizedDT orT Dresult in the other ‘illegal’ form. In theN CSpattern conditions, onlyT Dsequences trigger metathesis which reduces overall markedness by satisfying the sonority sequencing principle. Finally, in theN CN Spattern conditions, onlyDT sequences trigger metathesis, therebyincreasingthe overall markedness of the concatenated form.
Tables 4.7 – 4.9: Alternating Consonant Sequences
Table 4.6:CAlt. Seq.
C2
D T
C1 D
T
Table 4.7:NCSAlt. Seq.
C2
D T
C1 D
T
Table 4.8:NCNSAlt. Seq.
C2
D T
C1 D
T
4.3.4 Training Stimuli
In training, participants received a total of 72 word-pairs (i.e. 72 trials). Stimuli were divided
evenly between triggering and non-triggering consonant sequences, meaning 36 of each category
interspersed in random order. Whenever the triggering or non-triggering category contains more than
one type of consonant sequence (e.g. DT andTDboth trigger metathesis in theCtarget pattern), then the 36 instances were evenly divided amongst the component sequence types.
As the word medial consonant sequences are the only relevant factor for the target metathesis
patterns, description of the stimuli will focus mainly upon these sequences from this point forward.
Given 6 segments in each of the two consonant segment classes,DandT, there are a total of 36 possible consonant sequences for each sequence type. Of these 36, participants were given a subset in
training as shown in Tables 4.9 – 4.11. The distribution of training stimuli was designed to minimize
the ability of participants to utilize single-segment-level alternation frequencies alone to ‘learn’ the
target pattern.
Table 4.9:C-Pattern Training Stimuli
C2
D T
b d v à z g k S ٠f t p
C1
D
b ¶ ¶ ¶ À À À
d ¶ ¶ ¶ À À À
v ¶ ¶ ¶ À À À
à ¶ ¶ ¶ À À À
z ¶ ¶ ¶ À À À
g ¶ ¶ ¶ À À À
T
k À À À ¶ ¶ ¶
S À À À ¶ ¶ ¶
Ù À À À ¶ ¶ ¶
f À À À ¶ ¶ ¶
t À À À ¶ ¶ ¶
p À À À ¶ ¶ ¶
Alternations b.k ↔ k.b ×1 b.Ù ↔ Ù.b ×1 b.t ↔ t.b ×1 d.S ↔ S.d ×1 d.f ↔ f.d ×1 d.p ↔ p.d ×1 v.k ↔ k.v ×1 v.Ù ↔ Ù.v ×1 v.t ↔ t.v ×1 Ã.S ↔ S.Ã ×1 Ã.f ↔ f.Ã ×1 Ã.p ↔ p.Ã ×1 z.k ↔ k.z ×1 z.Ù ↔ Ù.z ×1 z.t ↔ t.z ×1 g.Ù ↔ Ù.g ×1 g.f ↔ f.g ×1 g.p ↔ p.g ×1
In Table 4.9, each cell denotes an underlyingC1C2 sequence. Training sequences are denoted with either aÀfor alternation-triggering sequences or a¶for non-triggering sequences. All sequence
Table 4.10:NCS-Pattern Training Stimuli
C2
D T
b d v à z g k S ٠f t p
C1
D
b ¶ ¶ ¶ ¶
d ¶ ¶ ¶ ¶
v ¶ ¶ ¶ ¶
à ¶ ¶ ¶ ¶
z ¶ ¶ ¶ ¶
g ¶ ¶ ¶ ¶
T
k Á Á Á ¶ ¶
S Á Á Á ¶ ¶
Ù Á Á Á ¶ ¶
f Á Á Á ¶ ¶
t Á Á Á ¶ ¶
p Á Á Á ¶ ¶
Alternations k.b → b.k ×2 k.v → v.k ×2 k.z → z.k ×2 S.d → d.S ×2 S.Ã → Ã.S ×2 S.g → g.S ×2 Ù.b → b.Ù ×2 Ù.v → v.Ù ×2 Ù.z → z.Ù ×2 f.d → d.f ×2 f.Ã → Ã.f ×2 f.g → g.f ×2 t.b → b.t ×2 t.v → v.t ×2 t.z → z.t ×2 p.d → d.p ×2 p.Ã → Ã.p ×2 p.g → g.p ×2
For theNCS-pattern, alternation-triggering stimuli consisted entirely ofT Dsequences, with two examples of each triggering sequence presented to participants (totaling 36 triggering stimuli). The
36 non-triggering stimuli were divided evenly among the three remaining sequence categories with
12 stimuli in each category. The training stimuli for theNCNS-pattern were distributed similarly with the only difference being thatDT sequences comprised all alternation-triggering stimuli.
Table 4.11: NCNS-Pattern Training Stimuli
C2
D T
b d v à z g k S ٠f t p
C1
D
b ¶ ¶ Á Á Á
d ¶ ¶ Á Á Á
v ¶ ¶ Á Á Á
à ¶ ¶ Á Á Á
z ¶ ¶ Á Á Á
g ¶ ¶ Á Á Á
T
k ¶ ¶ ¶ ¶
S ¶ ¶ ¶ ¶
Ù ¶ ¶ ¶ ¶
f ¶ ¶ ¶ ¶
t ¶ ¶ ¶ ¶
p ¶ ¶ ¶ ¶
4.3.5 Testing Stimuli
Of interest in this experiment is the ability of participants to extend the learned pattern to novel
stimuli. Novel stimuli were generated with the same segmental inventory and structure as the training
stimuli, but used novel medial consonant sequences that participants had not yet seen. Like with the
training stimuli, alternation-triggering and non-triggering stimuli were balanced 50-50. There were a
total of 48 test trials, meaning that participants saw 24 triggering word pairs and 24 non-triggering
word pairs in testing. The selected consonant sequences are given in Tables 4.12 – 4.14
Table 4.12: C-Pattern Test Stimuli
C2
D T
b d v à z g k S ٠f t p
C1
D
b ¶ ¶ À À
d ¶ ¶ À À
v ¶ ¶ À À
à ¶ ¶ À À
z ¶ ¶ À À
g ¶ ¶ À À
T
k À À ¶ ¶
S À À ¶ ¶
Ù À À ¶ ¶
f À À ¶ ¶
t À À ¶ ¶
p À À ¶ ¶
Alternations b.S ↔ S.b ×1 b.f ↔ f.b ×1 d.k ↔ k.d ×1 d.Ù ↔ Ù.d ×1 v.S ↔ S.v ×1 v.p ↔ p.v ×1 Ã.k ↔ k.Ã ×1 Ã.t ↔ t.Ã ×1 z.f ↔ f.z ×1 z.p ↔ p.z ×1 g.Ù ↔ Ù.g ×1 g.t ↔ t.g ×1
In the C-pattern conditions, participants saw 12 instances of each sequence-type category. Testing sequences are denoted with either aÀfor alternation-triggering sequences or a¶for
Table 4.13:NCS-Pattern Test Stimuli
C2
D T
b d v à z g k S ٠f t p
C1
D
b ¶ ¶
d ¶ ¶
v ¶ ¶ ¶ ¶
à ¶ ¶ ¶ ¶
z ¶ ¶
g ¶ ¶
T
k Á Á ¶
S Á Á ¶
Ù Á Á ¶ ¶
f Á Á ¶ ¶
t Á Á ¶
p Á Á ¶
Alternations S.b → b.S ×2 f.b → b.f ×2 k.d → d.k ×2 Ù.d → d.Ù ×2 S.v → v.S ×2 p.v → v.p ×2 k.Ã → Ã.k ×2 t.Ã → Ã.t ×2 f.z → z.f ×2 p.z → z.p ×2 Ù.g → g.Ù ×2 t.g → g.t ×2
Table 4.14:NCNS-Pattern Test Stimuli
C2
D T
b d v à z g k S ٠f t p
C1
D
b ¶ Á Á
d ¶ Á Á
v ¶ ¶ Á Á
à ¶ ¶ Á Á
z ¶ Á Á
g ¶ Á Á
T
k ¶ ¶
S ¶ ¶
Ù ¶ ¶ ¶ ¶
f ¶ ¶ ¶ ¶
t ¶ ¶
p ¶ ¶
Alternations b.S → S.b ×2 b.f → f.b ×2 d.k → k.d ×2 d.Ù → Ù.d ×2 v.S → S.v ×2 v.p → p.v ×2 Ã.k → k.Ã ×2 Ã.t → t.Ã ×2 z.f → f.z ×2 z.p → p.z ×2 g.Ù → Ù.g ×2 g.t → t.g ×2
4.3.6 Stimulus Construction & Recording
A common set of stimuli was recorded for all experiment conditions, and each target pattern condition
artificial language’s inventory. Care was taken to balance the frequencies of filler segments between
triggering and non-triggering stimuli so as to prevent effects of the filler segments on participants’
responses. The complete list of recorded stimuli is available in Appendix A.
All stimuli were recorded in one session by the author, a linguist with phonetics experience, in
a soundproof booth. For recording, Praat (Boersma and Weenink, 2016) running on a Lenovo X1
Carbon laptop at a sample rate of 44100 Hz was used. After recording, individual stimulus files were
generated using an automatic stimulus extractor and coder praatscript (see Appendix C for script).
During extraction of stimuli, the praatscript also normalized the average intensity for each file to 70
dB. The stimulus audio files were then converted to both.mp3and.oggfile formats for maximum browser compatibility.
4.4
Post-experiment Questionnaire
After completing the training and testing portions of the experiment, participants were asked to
complete a questionnaire detailing their strategies in the experiment and some demographic data.
The purpose of this questionnaire was to gather more detailed evidence of participants’ learning
strategies (e.g. did they actually use a rule in testing?), confirm participants’ use of headphones,
and to allow testing for potential effects of demographic factors like education or foreign language
experience on learning strategies/performance. The full questionnaire is included in Appendix A.
(5) Collected demographic data
– Age
– Gender
– Handedness
– Education
– Native language
– Other language ex-perience (up to L4)
– L2-L4 proficiency
– Linguistics experi-ence
Using the questionnaire, both self-reported and experimenter-reviewed learning strategies were
generated. Self-reported learning strategies were taken from participants’ selection of check-boxes in
the questionnaire. For example:
(6) How did you approach the learning task? Check all that apply:
memorized words⇐(Explicit) took notes⇐(Excluded)
Participants could be classified as both implicit and explicit learners simultaneously. Learners
specifying that they used their intuition in training and/or testing were coded assr.tr.implicit = 1
andsr.te.implicit = 1respectively. Learners specifying that they sought or used a rule were
coded assr.tr.explicit = 1andsr.te.explicit = 1respectively.
Experimenter-reviewed coding of participant strategies was carried out by reviewing participants’
explanations of their strategies and any rules that they proposed. If participants mentioned “intuition”
or “gut-feelings”, they were coded aser.tr.implicit = 1orer.te.implicit = 1. If
participants mentioned looking for a pattern or a rule, or if they proposed a pattern, then they
were coded aser.seeker = 1. If participants proposed a rule or mention a pattern regarding
when to metathesize or “switch segments around”, then they were coded as er.stater = 1.
Finally, if participants proposed thecorrectrule for their pattern condition, then they were coded as
er.finder = 1. All variables listed in this and the previous paragraph were initialized to0, and
were only changed to1according to the stated conditions.Participants who mentioned that they took
notes were excluded from analyses5.
4.5
Participants
Participants for this study were recruited and compensated anonymously through Amazon Mechanical
Turk, a task crowdsourcing platform with thousands of registered workers around the world6. MTurk allows for the specification of demographic restrictions when posting a task, and so the following
qualifications were required:
(7) Participant Qualifications
(1) US Resident
(2) Has completed at least 100 previous tasks
(3) Has earned at least 95% approval on completed tasks
(4) Has not participated in this experiment before
5
although one might make the case that note-taking corresponds to an extreme form of explicit learning.