© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1068
“Named Entity Recognition using Tweet Segmentation”
Prof. Vikas Balasaheb Burgute
, Prof. A.K.Gupta
Professor , Department of Computer Engineering, JSPM’s ,JSCOE, Hadapsar Pune, Maharashtra, India.
Assistant Professor, Department of Computer Engineering, JSPM’s , JSCOE, Hadapsar Pune, Maharashtra, India.
---***---Abstract- Twitter has involved numbers of users to share and distribute current information, resulting in a huge amount of data produced per day. No. of private and public organizations have been reported to create and control targeted Twitter streams to gather and know users opinions about the organizations. However the complexity and hybrid nature of the tweets are always challenging for the Information retrieval and natural language processing. Targeted Twitter stream is normally constructed by filtering and rending tweets with certain criteria with the help proposed framework. By splitting the tweet into no. of parts Targeted tweet is then analyzed to know users opinions about the organizations. There is a promising need for early rending and categorize such tweet, and then it get preserved in two format and used for downstream application. The proposed architecture shows that, by dividing the tweet into number of parts the standard phrases are divided and filtered so the topic of this tweet can be good captured in the sub sequent processing of this tweet Our proposed system on large scale real tweets demonstrate the efficiency and effectiveness of our framework.
Keywords:-Wikipedia, Named Entity Recognition, Tweet Segmentation, HybridSeg, Twitter Stream.
1. INTRODUCTION
Twitter, as a new type of social media, has seen huge growth of recent years. It has attracted great benefit of both industry and academic[2][3]. Millions of users shares and spread more time for up-to-date information on twitter which tends to a big volume of data generate continuously and regularly. Many private and public organizations have been reported to watch the Twitter stream to gather and identify user‘s suggestion about the organizations. We can get highly useful business value from these tweets, so it is used to understand tweets language for a large body of text applications such as NER[1].
Twitter has become one of the most significant communication channels into its ability to provide the most up-to-date and interesting information. Considering more than 255 million monthly active users, and given the fact that more than 500 million tweets are sent per day, there lies a money for information extraction researchers and it attracts the attention to academics and organizations to get user interests.
2. Related Work
Both tweet segmentation and named entity recognition are considered important subtasks in NLP. Many existing NLP techniques heavily rely on linguistic features, such as POS tags of the surrounding words, word capitalization, trigger words (e.g., Mr., Dr.), and gazetteers. These linguistic features, together with effective supervised learning algorithms (e.g., hidden markov model (HMM) and conditional random field (CRF)), achieve very good performance on formal
text corpus [14], [15], [16]. However, these techniques experience severe performance deterioration on tweets because of the noisy and short nature of the latter. There have been a lot of attempts to incorporate tweet’s unique characteristics into the conventional NLP techniques.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1069
for named entity recognition in tweets. T-NER, a part of the tweet-specific NLP framework in [3], first segments named entities using a CRF model with orthographic, contextual, dictionary and tweet-specific features. It then labels the named entities by applying Labeled-LDA with the external knowledge base Freebase.2 The NER solution proposed in [4] is also based on a CRF model. It is a two stage prediction aggregation model. In the first stage, a KNN-based classifier is used to conduct word-level classification, leveraging the similar and recently labeled tweets. In the second stage, those predictions, along with other linguistic features, are fed into a CRF model for finer-grained classification. Chua et al. [19] propose to extract noun phrases from tweets using an unsupervised approach which is mainly based on POS tagging. Each extracted noun phrase is a candidate named entity. Our work is also related to entity linking (EL). EL is to identify the mention of a named entity and link it to an entry in a knowledge base like Wikipedia [20], [21], [22], [23]. Conventionally, EL involves a NER system followed by a linking system [20], [21]. Recently, Sil and Yates propose to combine named entity recognition and linking into a joint model [23]. Similarly, Guo et al. propose a structural SVM solution to simultaneously recognize mention and resolve the linking [22]. While entity linking aims to identify the boundary of a named entity and resolve its meaning based on an external knowledge base, a typical NER system identifies entity mentions only, like the work presented here. It is difficult to make a fair comparison between these two techniques. Tweet segmentation is conceptually similar to Chinese word segmentation (CSW). Text in Chinese is a continuous sequence of characters. Segmenting the sequence into meaningful words is the first step in most applications. State-of-the-art CSW methods are mostly developed using supervised learning techniques like perceptron learning and CRF model [24], [25], [26], [27], [28]. Both linguistic and lexicon features are used in the supervised learning inCSW. Tweets are extremely noisy with misspellings, informal abbreviations, and grammatical errors. These adverse properties lead to a huge number of training samples for applying a supervised learning technique. Here, we exploit the semantic information of external knowledge bases and local contexts to recognize meaningful segments like named entities and semantic phrases in Tweets. Very recently, similar idea has also been explored for CSW by Jiang et al. [28]. They propose to prune the search space in CSW by exploiting the natural annotations in the Web.
Their experimental results show significant improvement by using simple local features.
3. LITERATURE REVIEW
“TwiNER: Named Entity Recognition in Targeted Twitter Stream “
[1]Chenliang Li, 2.Jianshu Weng 3.QiHe, Yuxia Yao, 4.Anwitaman Datta1, TwiNER: Named Entity Recognition in Targeted Twitter Stream This paper describes Twitter, as a new type of social media, has attracted great interests from both industry and academia. Many private and/or public organizations have been reported to monitor Twitter stream to collect and understand users opinions about the organizations. Nevertheless, it is practically infeasible and unnecessary to listen and monitor the whole Twitter stream, due to it extremely large volume. Therefore, targeted Twitter streams are usually monitored instead. Targeted Twitter stream is usually constructed by filtering tweets with user-defined selection criteria. There is also an emerging need for early crisis detection and response with such target stream
“Named Entity Recognition in Tweets:An Experimental Study”
[2]Alan Ritter, Sam Clark, Mausam and Oren Etzioni, Named Entity Recognition in Tweets: An Experimental Study, In this paper we identified named entity classification as a particularly challenging task on Twitter. Due to their terse nature, tweets often lack enough contexts to identify the types of the entities they contain. In addition, a plethora of distinctive named entity types are present, necessitating large amounts of training data. To address both these issues we have presented and evaluated a distantly supervised approach based on Labeled LDA, which obtains a 25 percent increase in F1 score over the co-training approach to Named Entity Classification suggested by Collins and Singer (1999) when applied to Twitter.
“User Interest Modeling in Twitter with Named Entity Recognition “
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1070
4. EXISTING SYSTEM
In Existing System, to improve part of speech tagging on tweet. Train a part of speech tagger by using CRF model with traditional and tweet-specific features. Brown clustering is applied in their work to deals with the ill-formed words.
Many existing Natural language processing techniques heavily rely on linguistic features, such as part of speech tags of the surrounding words, word capitalization, trigger words (e.g., Mr., Dr.), and gazetteers. These linguistic features, with effective SLA(supervised learning algorithms) (e.g., HMM (hidden markov model) and CRF(conditional random field), achieve very high and good performance on formal text corpus[2][4][5]. However, these techniques experience severe performance of degradation on tweets because of the noisy and short nature of the latter.
4.1 Approches To NER
In this section, some NER approaches are reviewed. A. Supervised methods It is class of algorithm that learns a model by looking to annotated training examples. Supervised learning algorithms for NER are Hidden Markov Model (HMM),Maximum Entropy Models (ME),and Decision Trees, Support Vector Machines (SVM) also Conditional Random Fields (CRF). These all are forms of the supervised learning approach it is typically consist of a system which reads a large corpus, memorizes lists of entities, and creates disambiguation rules based on discriminative features.
4.2 Hidden Markov Model
Hidden Markov Model is the recent model applied for solving Named Entity Recognition problem by Bikel et al. (1999). Bikel proposed a system IdentiFinderto understand named entities. In Identifier system only single label can be assigned to a each word in context. Therefore the model assigns to each word either one of the desired classes or the label NOT-A-NAME which means none of the desired classes".
4.3 Maximum Entropy based Model
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1071
4.4 Decision Trees
It is a tree structure used for make decisions at the nodes and obtain result the same leaf nodes. A path in the tree represent a sequence of decisions leading in to the classification at the leaf node of tree. Decision trees are attractive because the rules can be easily access from the tree of that node. It is a well-liked tool for guess and classification.
4.5 CRF Based Model
CRF Based Model proposed by Lafferty et al. (2001).Conditional random field model as a statistical modeling tool for pattern recognition and the machine learning using structured prediction. McCallum and Li (2003) developed feature induction method for conditional random field in NE.
4.6 SVM Based Model
SVM was first introduced by Cortes and Vapnik in 1995 which is based on the idea of learning a linear hyper plane that separate the positive example from the negative example by large margin. It suggests that the distance between the hyper plane and the point from either instance is maximum. Support vectors are points closest to hyper plane on either side.
4.7 Unsupervised Methods
There is problem with supervised algorithms is it required large number of features. For learning a good model, a robust set of features and large annotated corpus is required .Many languages don't have large number of annotated corpus available at their disposal. To deal with lack of annotated text across the domains and languages, unsupervised techniques for Named Entity Recognition have been proposed for this.
4.8. Semi-Supervised Methods
Semi supervised learning algorithms use both labeled and unlabeled corpus to create their own hypothesis. Algorithms typically start with little amount of seed data set and create more hypotheses using bigger amount of unlabeled corpus.
5. PROPOSED SYSTEM
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1072
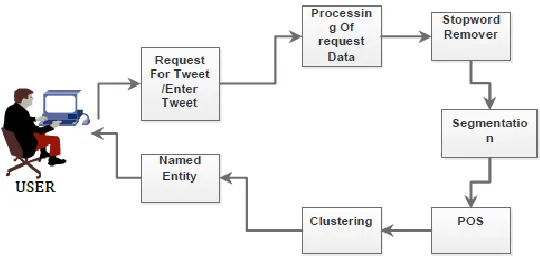
Fig. 1. Architecture of HybridSeg
User module is designed for the user interaction with the system. Collecting Twitter Data After the successful involvement of user module, this module starts where it is connected to the twitter API for the purpose of collection of Twitter data for further process. Preprocessing This module takes input as Twitter collected data, preprocess on it with the help of Open natural language processing with the following steps,
Stop word Removal Lemmatization
Sentence segmentation Tokenization
part-of- Named entity extraction
5.1 Clustering
The clustering based document summarization performance greatly depends on three main terms: (1)cluster ordering (2)clustering Sentences (3) selection of sentences from the clusters. The aim of this study is to discover out the appropriate algorithms for sentence clustering, cluster ordering and sentence selection having a winning sentence clustering based various-document summarization system.
5.2 Summarization
Document summarization can be an vital solution to reduce the information overload problem on the web. This type of summarization capability assist users to see in quick look what a collection is about and provides a new mode of organize a large collection of information. The clustering-based method to multi-document text summarization can be useful on the web because of its domain and language independence nature.
5.3 Ranking
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1073
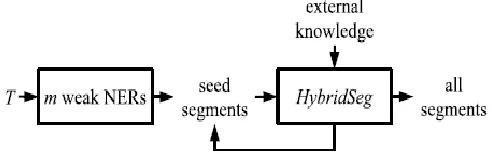
5.4 Tweet Segmentation by HybridSeg
[image:6.612.179.425.148.225.2]
Fig. : The iterative process of HybridSeg
HybridSegWeb learns from global context only, (Helps To Identify Meaningful segment) HybridSegNER
HybridSegNGram learns from global context and local context through local collocation, HybridSegIter learns from pseudo feedback iteratively. (Extract More Meaningful segment)
5.6 ALGORITHM _
Preprocessing Algorithm: Step 0: Start
Step 1: Login/New registration.
Step 2: Input - User request for Specific Tweets.
Step 3: Retrieve the Tweets for that specific request Recognition
Step 4: Analysis - – Remove Stop words from the output tweets – Find out Stickiness Count of tweets for Segmentation Segment – Apply the POS on tweets – Proceed for NER.
Step 5:Results is NER that maintain semantic Meaning Of the Tweets Step 6: Apply SVM
Step 7: Output NER with the polarity index Step 8: stop
6. MATHEMATICAL MODEL SYSTEM
U = { s, L(s) , Q(s), Pr(s) , C(s) } Where,
s = segment
L (s) = length normalization
Q (s) = the segment's presence in Wikipedia
Pr (s) = the segment's phraseness or the probability of s being a phrase based on global and local contexts. C (s) = The stickiness of s
As an application of tweet segmentation, propose and evaluate two segment-based Named Entity Recognition algorithms. Both these algorithms are unsupervised in nature and take tweet segments as input[6]. One algorithm exploits co-occurrence of named entities in targeted Twitter streams by applying RW (random walk) with the acceptance that named entities are more likely to co-occur together. The other algorithm utilizes POS(Part-of-Speech ) tags of the constituent words with segments.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1074
y(s)=eQ(s) * ps.
In this equation, eQ(s) carries the same semantic. It indicates that the segment that frequently appears in Wikipedia as an anchor text is more expected to be a named entity. With the weighting y(s), the top K segments are chosen as named entities[3][5]. Named Entity Recognition by POS Tagger: Due to the short nature of tweets, the affable property may be weak. The second algorithm then explores the POS tags in tweets for NER by considering noun phrases as named entities using segments instead of a word as a unit.
A segment may show in different tweets and its ingredient words may be assigned to different POS tags in these tweets. calculate approximately the likelihood of a segment being a noun phrase by considering the part of speech tags of its ingredient words of all appearances.
6.1 NER by Random Walk:
The first Named Entity Recognition algorithm is based on the inspection that a named entity often co-occurs with other named entities in a batch of tweets[9]. Based on this observation, build a segment graph. A node in this graph is a segment identified by HybridSeg.. A random walk model is then applied to the segment graph. Let rs be the stationary probability of segment s after applying random walk, the segment is then weighted by y(s)=eQ(s)*ps . In this equation, eQ(s) carries the same semantic. It indicates that the segment that frequently appears in Wikipedia as an anchor text is more expected to be a named entity. With the weighting y(s), the top K segments are chosen as named entities[3][5].
6.2 Named Entity Recognition by POS Tagger :
Due to the short nature of tweets, the affable property may be weak. The second algorithm then explores the POS tags in tweets for NER by consider noun phrases as named entities using segment instead of word as a unit. A segment may show in different tweets and its ingredient words may be assign to different POS tags in these tweets. calculate approximately the likelihood of a segment being a noun phrase by considering the POS tags of its ingredient words of all appearances. In proposed system, we are going to resolve this overhead of users by combining twitter dataset which is gathered under one roof whether the tweets are positive or negative. User does not need to checks it manually. And another thing is that the positive and negative results will be displayed percentage.
7. CONCLUSIONS AND FUTURE WORK
This paper presents a prototype which supported continuous tweet stream summarization. A tweet streams clustering algorithms to compress tweets into clusters and maintains them in an online fashion. The topic evolution can be detected automatically, allowing System to produce dynamic timelines for tweet streams by using Local and Global Context.
Tweet segmentation assists in staying the semantic meaning of tweets, which consequently benefits of downstream applications, e. g.,NER. Segment-based known as entity recognition methods achieves much better correctness than the word-based alternative.
The future scope of this project is to be adding support for hash tags, Live connectivity to twitter data can be achieved and use of Big-Data for scalability.
ACKNOWLEDGMENT
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 1075
REFERENCES
[1] C. Li, J. Weng, Q. He, Y. Yao, A. Datta, A. Sun, and B.-S. Lee,"Twiner: Named entity recognition in targeted twitter stream," inProc. 35th Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2012,pp. 721–730.
[2] C. Li, A. Sun, J. Weng, and Q. He, "Exploiting hybrid contexts for tweets segmentation," in Proc. 36th Int. ACM SIGIR Conf. Res.Develop. Inf. Retrieval, 2013, pp. 523–532.
[3] A. Ritter, S. Clark, Mausam, and O. Etzioni, "Named entity recognition in tweets: An experimental study," in Proc. Conf. Empirical Methods Natural Language Process., 2011, pp. 1524–1534.
[4] X. Liu, S. Zhang, F. Wei, and M. Zhou, "Recognizing named entities in tweets," in Proc. 49th Annu. Meeting Assoc. Comput. Linguistics:Human Language Technol., 2011, pp. 359–367.
[5] X. Liu, X. Zhou, Z. Fu, F. Wei, and M. Zhou, "Exacting social events for tweets using a factor graph," in Proc. AAAI Conf. Artif. Intell., 2012, pp. 1692–1698.
[6] A. Cui, M. Zhang, Y. Liu, S. Ma, and K. Zhang, "Discover breaking events with popular hashtags in twitter," in Proc. 21st ACM Int. Conf. Inf. Knowl. Manage., 2012, pp. 1794–1798.
[7] A. Ritter, Mausam, O. Etzioni, and S. Clark, "Open domain event extraction from twitter," in Proc. 18th ACM SIGKDD Int. Conf. Knowledge Discovery Data Mining, 2012, pp. 1104–1112.
[8] X. Meng, F. Wei, X. Liu, M. Zhou, S. Li, and H. Wang, "Entity-centric topic-oriented opinion summarization in twitter," in Proc. 18th ACM SIGKDD Int. Conf. Knowledge Discovery Data Mining,
[9] Z. Luo, M. Osborne, and T. Wang, "Opinion retrieval in twitter," in Proc. Int. AAAI Conf. Weblogs Social Media, 2012, pp. 507–510.
[10] X. Wang, F. Wei, X. Liu, M. Zhou, and M. Zhang, "Topic sentiment
analysis in twitter: a graph-based hashtag sentiment classification approach," in Proc. 20th ACM Int. Conf. Inf. Knowl. Manage.,2011, pp. 1031–1040.
[11] K.-L. Liu, W.-J. Li, and M. Guo, "Emoticon smoothed language models for twitter sentiment analysis," in Proc. AAAI Conf. Artif. Intell., 2012, pp. 1678–1684.