Challenges Involved in Big Data Processing & Methods to Solve Big Data Processing Problems
Full text
Figure
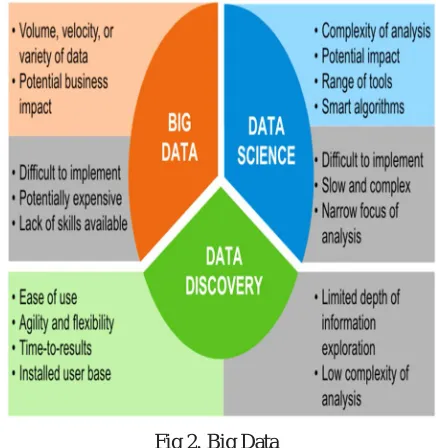
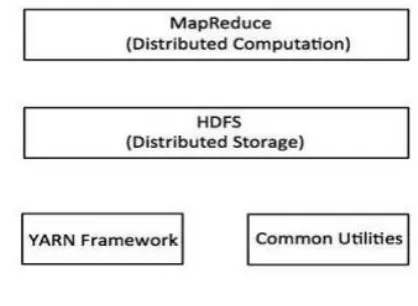
Related documents
Recently advocacy groups have put these two strands of the literature together to argue that locating affordable housing near TOD, by providing locations for low-income persons
Abstract: Tunable deflection of obliquely incident, linearly polarized terahertz waves is theoretically studied in a wide frequency range around 20 THz, by combining a thin slab
Structural limitations aside, the MNH Junction provides healthcare providers with a unique opportunity for uninterrupted patient care. Based on the relatively low risk-based
The data used in this analysis come from the Medicaid Statistical Information System (MSIS) Summary File maintained by the Centers for Medicare and Medicaid
With a view to strengthening relations among US allies in Asia, the new strategy documents for the first time call on Japan to pursue trilateral security cooperation among the
Whooping Crane ( Grus americana ) – endangered Interior Least Tern ( Sterna antillarum ) - endangered Black-capped Vireo ( Vireo atricapillus ) - endangered Piping Plover
The strength of public key cryptography utilizing Elliptic Curves relies on the difficulty of computing discrete logarithms in a finite field.. Diffie-Hellman key exchange
The fourth part of your submitted proposal should (1) state the auditor’s preference for whether the County or the auditor should prepare the majority of year-end adjusting
