Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1284
A Survey on High Dimensional Data Classification in Booster
Balne Sridevi & V.Sandeep Kumar
1
Assistant Professor, Department of CSE, Balaji Institute of Technology & science, Warangal District, Telangana, India.
2
M.Tech Student, Department of CSE, Balaji Institute of Technology & science, Warangal District, Telangana, India.
ABSTARCT—Classification issues
determined in high dimensional information with small number of perception are for the most part getting to be plainly basic in particular microarray information. In the season of last two times of years, many efficient order standard models and furthermore Feature Selection (FS) calculation which isalso alluded as FS method have fundamentally been proposed for higher expectation exactnesses. In spite of the fact that, the result of FS calculation identified with foreseeing exactness will be shaky over the varieties in thought about trainingset, in high dimensional information. In this paperwe show a most recent assessment measure Q-measurement that incorporates the soundness of the chose highlight subset in consideration to expectation precision. At that point we will propose the standard Booster of a FS calculation that lifts the fundamental estimation of the favored Q-measurement of the calculation connected. In this way consider on manufactured information and 14 microarray informational indexes demonstrates that Booster helps the estimation of Q-insights as well as likewise the expectation exactness of the calculation connected.
I. INTRODUCTION
The nearness of high dimensional information is becoming more regular in numerous down to earth applications such as information mining,
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1285 dimensional issues have used forward
determination strategy however not considered in reverse end technique since it is illogical to execute in reverse end process with gigantic number of highlights.
II. LITERATURE SURVEY
In the time of 2014, the creators Y. Wang, L. Chen, and J.- P. Mei. uncovered a paper titled "Incremental fluffy bunching with different medoids for expansive information" and portray into the paper, for example, a basic system of data examination, gathering expect a basic part in finding the essential case structure introduced in unlabeled data. Gathering counts that need to store each one of the data into the memory for examination get to be particularly infeasible when the dataset is excessively immense, making it impossible to be secured. To deal with such broad data, incremental batching philosophies are proposed. The point by point issue definition, updating rules assurance, and the start to finish examination of the proposed IMMFC are given. Trial looks at on a couple of tremendous datasets that join veritable malware datasets have been driven. IMMFC defeats existing incremental cushioned bundling approaches the extent that gathering precision and energy to the demand of data. These results demonstrate the enormous ability of IMMFC for immense data examination. Grouping is proposed, for naturally investigating potential bunches in dataset. This uses directed arrangement way to deal with accomplish the unsupervised bunch investigation. Combination of bunching and fluffy set hypothesis is nothing be that as it may, fluffy grouping, which is fitting to deal with issues with loose limits of bunches. A fluffy lead based arrangement framework is a
unique instance of fluffy demonstrating, in which the yield of framework is fresh and discrete. Fluffy demonstrating furnishes high interpretability and permits working with uncertain information. To investigate the groups in the information designs, FRBC annexes some haphazardly created helper examples to the issue space. It at that point utilizes the fundamental information as one class and the assistant information as another class to count the unsupervised grouping issue as a regulated grouping one.
Feature Selection
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1286 Figure 1: Three approaches of Feature
Selection
Filter based feature selection Algorithm:
Taking off the features on a few measures (criteria) go under the filter approach of feature selection. In the filter based element determination approach, the decency of a featureis assessed utilizing statistical or inherent properties of the dataset. Considering these properties, a feature is decreed as the most reasonable feature and is selected for machine learning or data mining applications. A portion of the normal methodologies of feature selection are Fast Correlation Based Filter, (FCBF) Correlation based Feature Selection (CFS)
Wrapper based feature selection
Algorithms:
In the wrapper approach of feature selection, subset of feature is created and decency of subset is assessed utilizing some classifier.
Embedded based feature selection
Algorithms:
In this approach, some classifier is utilized to rank features in the dataset. Based on this rank, a feature is selected for the required application. SVM-RFE is one of the implanted feature selection approaches A new proposal for feature selection In this paper we propose Q-statistics to evaluate the performance of an FS algorithm with a classifier. Q-statistic is a hybrid measure to check the prediction accuracy of the features being selected. Then we also propose a Booster on the selected feature subset from a given FS algorithm. Booster is introduced to obtain several data sets
from the original data set by resampling on sample space. To obtain different feature subsets, FS algorithm is applied on resampled data sets which is given by Booster. Here the Booster boosts not only the value of Q-statistics but also the prediction accuracy of the classifier applied.
III. EFFICIENCY OF BOOSTE
There are two ideas in Booster to mirror the two spaces. The first is the shape, Booster'sequivalent of a customary array[6] a limited arrangement of components of a specific information compose, open through files. Not at all like exhibits, shapes require not really be rectangular for accommodation we will, for the occasion, accept that they are. Shapes serve, from the calculation creator's perspective, as the fundamental placeholders for the calculation's information: input-, yield , and moderate values are put away inside shapes. As we will see later on, this does not really imply that they arerepresented in memory that way, yet the calculation planner is permitted to think so.It presents the impact of s-Booster on precision and Q-measurement against the first s's. Classifier utilized here is NB.
A. BOOSTER BOOST S ACCURACY
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1287 powerless student is characterized to be a
classifier which is just marginally related with the genuine arrangement what's more, a solid student is a classifier that is self-assertively all around corresponded with the genuine grouping. Learning calculations that transform an arrangement of frail students into a solitary solid student is known as boosting.
B. BOOSTER BOOSTS Q-STATISTIC
Q static hunt calculation creates arbitrary memory arrangements and seeking after to enhance the congruity memory to acquire ideal arrangement an ideal subset of instructive highlights. Every performer novel term is a measurement of the seek space. The arrangements are assessed by the wellness work as it is utilized to get an ideal congruity worldwide Ideal arrangement. Amicability seek calculation plays out The wellness work is a kind of assessment criteria used to assess arrangements. At every cycle the wellness work is figured for every HS arrangement. At long last, the arrangement, which has a higher wellness esteem is the ideal arrangement . We utilized mean supreme distinction as wellness work in HS calculation for FS system utilizing the weight plot as target work for each position.
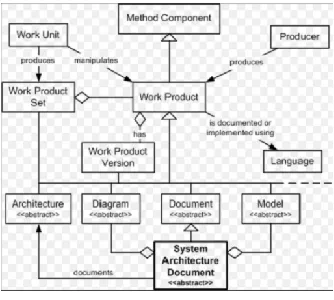
IV. SYSTEM ARCHITECTURE
A well-planned data classification system makes essential data easy to find and retrieve. This can be of particular importance for and written procedures and guidelines for data classification should define what categories and criteria the organization will use to classify data and specify the roles and responsibilities of employees within the organization regarding. Once a data-classification scheme has been
created, security standards that specify appropriate handling practices for each category and storage standards that define the requirements should be addressed. To be effective, a classification scheme should be simple enough that all employees can execute it properly. Here is an example of what a data classification.
Fig 2. system design
V. SIMULATION RESULTS
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1288 having a global minimum at a vector which lies
on one of the two coordinates.
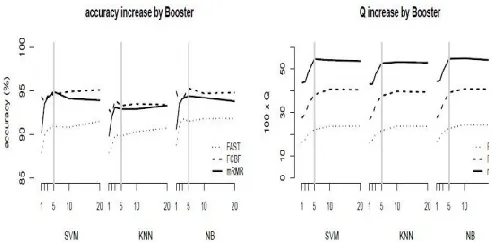
Fig 3.Accuracy and Q-statistic of s-Boosterb for b = 1; 2; 3; 5; 10; and 20 (x-axis). Each value is the average over the 14 data sets. s-Booster1 is s. The grey vertical line is for b = 5.
VI. CONCLUSION
We expected a measure Q-measurement to evaluate the execution of a Feature Selection calculation. Q-measurement the accounts both for the solidness of chose include subset and the forecast exactness. The paper proposed here is for the Promoter to support the execution of a present FS calculation. Experimentation with engineered information and 14 microarray information sets has shown that the suggested Booster upgrades the expectation precision and the Q-measurement of the three doubtlessly comprehended Feature Selection calculations: FAST, FCBF, and mRMR. In like manner we take in see that the order strategies connected to Booster don't have much impact on forecast precision and Q-insights. The Performance of mRMR-Booster be showed up close be unprecedented together in the expectation exactness along with Q-measurement This was analyzed with the goal of if a FS calculation is capable however couldn't get unrivaled in the superior in exactness or the Q-insights for a
few specific information, Booster of the Feature Selection calculation will support the execution. On the off chance that a FS calculation itself isn't gainful, Booster will in all probability be not able secure high execution. The execution of Booster depends upon the performanceof FS calculation connected.
Balne Sridevi currently working as an Assistant Professor in CSE Department at BALAJI INSTITUTE OF TECHNOLOGY & SCIENCE, Narsampet, Warangal and has 13+ years of experience in Academic. Research areas include Information Security, Mobile and Cloud computing, Data Mining, Network Security etc.