ISSN(Online): 2319-8753 ISSN (Print) : 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 6, Issue 10, October 2017
A Survey on- Probabilistic Static
Load-Balancing of Parallel Mining of Frequent
Sequences
Priyanka Nimbalkar1, Prof.S.G.Tuppad2
M.E Student.(CSE), Matsyodari Shikshan Sansthas College of Engineering and Technology,
Jalna, Maharashtra, India1
Assistant Professor, Matsyodari Shikshan Sansthas College of Engineering and Technology,
Jalna, Maharashtra, India2
ABSTRACT: Frequent sequence mining is well known and well studied problem in data mining. The output of the algorithm is used in many other areas like bioinformatics, chemistry, and market basket analysis. Unfortunately, the frequent sequence mining is computationally quite expensive. In this paper, we present a novel parallel algorithm for mining of frequent sequences based on a static load-balancing. The static load-balancing is done by measuring the computational time using a probabilistic algorithm. For reasonable size of instance, the algorithms achieve speedups up to =3/4 P where P is the number of processors. In the experimental evaluation, we show that our method performs significantly better than the current state-of-the-art methods. The presented approach is very universal: it can be used for static load-balancing of other pattern mining algorithms such as itemset/tree/graph mining algorithms.
KEYWORDS: Data mining, frequent sequence mining, parallel algorithms, static load-balancing, probabilistic
algorithms.
I. INTRODUCTION
Repeated pattern removal is an important data mining technique with a wide variety of mined patterns. The mined frequent patterns can be sets of items (item sets), sequences, graphs, trees, etc. Frequent sequence mining was first described in. The GSP algorithm presented in is the first to solve the problem of frequent sequence mining. As the repeated series removal is an extension of itemset mining, the GSP algorithm is an extension of the Apriorialgorithm . As a consequence of the slowness and memory consumption of algorithms described in other algorithms were proposed. These two algorithms use the so-called prefix-based equivalence classes (PBECs in short), i.e., represent the pattern as a string and partition the set of all patterns into disjoint sets using prefixes. There are two kinds of parallel computers: shared memory technology and distributed memory technology. Parallelizing on the shared memory technology is easier than parallelizing on distributed memory technology. Sampling technique that statically load-balance the computation of parallel frequent item set mining process, are proposed in these three papers, the so-called double sampling process and its three variants were proposed.
II. RELATED WORK
ISSN(Online): 2319-8753 ISSN (Print) : 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 6, Issue 10, October 2017
mining. Because the continuous arrangement mining is an augmentation of item set mining, the GSP calculation is an augmentation of the A priori calculation. The A priori and therefore the GSP calculations are expansiveness initial pursuit calculations. The GSP calculation endures with comparative problems because the A priori calculation: it's moderate and memory expenditure. As an outcome of the gradualness and memory utilization of calculations represented, totally different calculations were planned. [1]
The 2 noteworthy thoughts within the regular succession mining are those of Zaki and I. M. Pei and Han dynasty. These 2 calculations utilize the supposed prefix based sameness categories (PBECs in short), i.e., speak to the instance as a string and parcel the arrangement of all examples into disjoint sets utilizing prefixes. The 2 calculations vary simply within the knowledge structures won‟t to management the inquiry. The algorithms represented are fast. [2]
In any case, at the purpose once the consecutive calculation keeps running for an extremely long term there's a demand for parallel calculations. For instance, the one portrayed during this paper, there's a very regular likelihood to position a subjective continuous grouping mining calculation: section the arrangement of each single regular succession utilizing the PBECs. The PBECs are created, planned, and executed on the processors. Since the PBECs are planned once, static burden parity of the calculation is processed. This technique has one most well- liked standpoint: it counteracts rehashed colossal exchanges of data among hubs (the information is changed once among processors); what is a lot of, one hindrance: assessing the live of a PBEC may be a computationally troublesome issue. As of now, there do not m exist versatile parallelization’s of those calculations. [3]
There are 2 varieties of parallel PCs: shared memory machines and disseminated memory machines. Parallelizing on the mutual memory machines is a smaller amount difficult than parallelizing on disseminated memory machines. The dynamic burden adjusting is straightforward on shared memory machines, because the instrumentation bolsters easy parallelization: the processors have entry to the whole info. For this work, disseminated memory machines, i.e., bunch of workstations, was utilized. Inspecting system that statically stack alter the calculation of parallel regular item set mining procedure, are planned; In these 3 papers, the supposed twofold testing procedure and its 3 variations were planned. This work amplifies the thought exhibited to parallel continuous grouping mining calculation. The twofold inspecting procedure is improved by presenting weights that speaks to the relative making ready time of the calculation for a particular PBEC. [4]
In the Load equalization necessary things are estimation of load, comparison of load, stability of various system, performance of system, interaction between the information sets, nature of labor to be transferred, choosing of information sets and lots of alternative ones to think about whereas developing such algorithm Sampling technique that statically load-balance the computation of parallel frequent item set mining method, are projected within the double sampling method is increased by introducing weights that represents the relative time interval of the algorithmic rule for a specific PBEC. Alternative algorithms were projected. [5]
The 2 major ideas within the frequent sequence mining are those of Zaki and architect and Han. These 2 algorithms use the alleged prefix primarily based equivalence categories (PBEC sin short), i.e., represent the pattern and partition the set of all patterns into disjoint sets exploitation prefixes. The 2 algorithms take issue only within the knowledge structures won‟t to management the search. The sequent algorithmic rule runs for too long there's a necessity for
parallel algorithms. Like the one delineate during this paper. There‟s a really natural chance to lay an arbitrary frequent
sequence mining algorithm: partition the set to fall frequent sequences exploitation the PBECs. [6]
ISSN(Online): 2319-8753 ISSN (Print) : 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 6, Issue 10, October 2017
information format, introduced for frequent item set mining. The pseudo-projected information is actually terribly the same as the vertical illustration of the information utilized in the Spade algorithm. Our technique uses the Prefix span algorithm and its operations as a base sequent algorithm. There‟s additionally AN algorithm that extends the tree
projection algorithm for mining of frequent things to sequences. [7]
III. EXISTING SYSTEM APPROACH
Ranking in the mobile App advertise refers to fraudulent or misleading exercises which have a motivation behind knocking up the Apps in the ubiquity list. To be sure, it turns out to be increasingly visit for App engineers to utilize shady means, for example, inflating their Apps' deals or posting fake App evaluations, to confer ranking fraud. While the significance of preventing ranking fraud has been broadly perceived, there is restricted comprehension and research in this area. Generally, the related works of this study can be assembled into three classifications. The First class is about web ranking spam Detection. In particular, the Web ranking spam refers to any deliberate activities which convey to chose website pages an unjustifiable ideal significance or importance. For example, we have concentrated on different parts of substance construct spam in light of the web and displayed various heuristic for distinguishing content based spam.
Disadvantages:-
1 ) Happens Fraud in Web Application.
2) Leader Board gets false rating surveys of client.
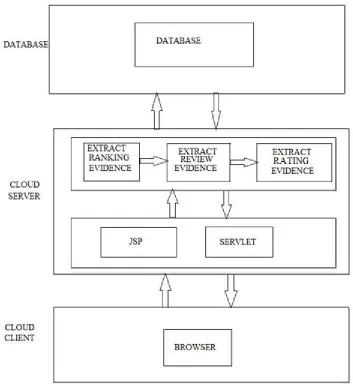
IV. PROPOSED SYSTEM ARCHITECTURE
1. We first propose a basic yet effective algorithm to recognize the main sessions of each App in light of its authentic ranking records. At that point, with the examination of Apps' ranking practices, we find that the fake Apps frequently have distinctive ranking examples in every leading session contrasted and typical Apps. In this way, we characterize some fraud evidences from Apps' historical ranking records, and create three capacities to concentrate such ranking based fraud evidences.
2. We further propose two sorts of fraud evidences in view of Apps' evaluating and survey history, which mirror some anomaly designs from Apps' historical rating and audit records. In Ranking Based Evidences, by breaking down the Apps' verifiable ranking records, we watch that Apps' ranking practices in a main occasion dependably fulfill a particular ranking example, which comprises of three distinctive ranking stages, to be specific, rising stage, keeping up stage and retreat stage.
3. In Rating Based Evidences, particularly, after an App has been distributed, it can be evaluated by any client who downloaded it. Without a doubt, client rating is a standout amongst the most vital elements of App advertisement. An App which has higher rating may draw in more clients to download and can likewise be ranked higher in the leader board. In this manner, rating control is additionally an imperative viewpoint of ranking fraud.
4. In Review Based Evidences, other than appraisals, the majority of the App stores likewise permit clients to compose some printed remarks as App surveys. Such audits can mirror the individual recognitions and use encounters of existing clients for specific mobile Apps. To be sure, survey control is a standout amongst the most vital viewpoints of App ranking fraud.
ADVANTAGES OF PROPOSED SYSTEM
1. The proposed structure is versatile and can be reached out with other domain produced evidences for ranking fraud detection.
ISSN(Online): 2319-8753 ISSN (Print) : 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 6, Issue 10, October 2017
3. To the best of our insight, there is no current benchmark to choose which leading sessions or Apps truly contain ranking fraud. In this way, we create four natural baselines and welcome five human evaluators to validate the adequacy of our approach Evidence Aggregation based Ranking Fraud Detection (EA-RFD).
ISSN(Online): 2319-8753 ISSN (Print) : 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 6, Issue 10, October 2017
V. CONCLUSION
We built up a ranking fraud recognition framework for mobile Apps. In particular, we initially demonstrated that ranking fraud happened in leading sessions and gave a technique to mining leading sessions for each App from its verifiable ranking records. At that point, we distinguished ranking based evidences, rating based proofs and survey based proofs for recognizing ranking fraud. Also, we proposed a optimization based accumulation strategy to coordinate every one of the evidences for assessing the validity of leading sessions from mobile Apps. A one of a kind point of view of this approach is that every one of the proofs can be demonstrated by factual speculation tests, subsequently it is anything but difficult to be reached out with different evidences from space learning to recognize ranking fraud. At last, we approve the proposed framework with broad tests on true App information gathered from the Google Play store.
REFERENCES
[1]Ee-Peng Lim, Viet-An Nguyen,Nitin Jindal, Bing Liu, Hady W. Lauw,”Detecting Product Review Spammers using Rating Behaviors”, CIKM’10,
October 26–30, 2010.
[2] Y. Ge, H. Xiong, C. Liu, and Z.-H. Zhou, “A taxi driving frauddetection system,” in Proc.IEEE 11th Int. Conf. Data Mining, 2011,pp. 181–190. [3] N. Jindal and B. Liu, “Opinion spam and analysis,” in Proc. Int.Conf. Web Search Data Mining, 2008, pp. 219–230.
[4] A. Klementiev, D. Roth, and K. Small, “An unsupervised learningalgorithm for rank aggregation,” in Proc. 18th Eur. Conf. Mach.Learn., 2007, pp. 616–623.
[5] H. Zhu, E. Chen, K. Yu, H. Cao, H. Xiong, and J. Tian, “Mining personal context-aware preferences for mobile users,” in Proc. IEEE 12th Int. Conf. Data Mining, 2012, pp. 1212–1217.
[6] S. Xie, G. Wang, S. Lin, and P. S. Yu, “Review spam detection via temporal pattern discovery”, in Proc. 18th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2012, pp. 823–831.
[7] A. Ntoulas, M. Najork, M. Manasse, and D. Fetterly, “Detecting spam web pages through content analysis,” in Proc. 15th Int. Conf. World Wide Web, 2006, pp. 83–92.
[8] G. Shafer, A Mathematical Theory of Evidence. Princeton, NJ, USA: Princeton Univ. Press, 1976.
[9] K. Shi and K. Ali, “Getjar mobile application recommendations with very sparse datasets,” in Proc. 18th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2012, pp. 204–212.