ABSTRACT
CHAKRABORTY, ARPAN. A Biologically Inspired Active Vision Framework for Cognitive Agents. (Under the direction of Robert St. Amant.)
Visual perception facilitates a rich interface to the environment. In this research, we attempt to model it as an active process that organisms engage in, with the goal of operationalizing it in a computational framework. Our motivations lie in the ubiquitous evidence that natural evolution has managed to demonstrate effective solutions to the vision problem. While a growing community of early-vision researchers have started focusing on biologically-inspired approaches, current models do not provide a unifying theory for cognitive control of perception during a task.
An in-depth study of neurophysiological literature reveals a detailed body of knowledge that is as stunning as it is fragmented. We attempt to assimilate these facts into a functionally complete yet abstract model of visual perception. This informs our architectural approach to designing a framework for active vision that subscribes to a strong notion of biological plausibility.
The framework embodies the idea that the key to visual perception in biological systems lies in the complex interconnection of large numbers of simple neuronal processing units. Computational challenges of scale and novel solutions to deal with them are discussed. Applications of the resulting framework help demonstrate its versatility across tasks and its potential to serve as a means of modeling visual phenomena.
A tangible outcome of this work is a software bridge that allows a cognitive model to consume raw visual input generated by a standard psychophysical experimentation tool, and interact with it via emulated input devices. This enables modelers to use experiments in the same form as administered on humans, without the additional step of abstracting the interface which may subtly affect results.
©Copyright 2014 by Arpan Chakraborty
A Biologically Inspired Active Vision Framework for Cognitive Agents
by
Arpan Chakraborty
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina
2014
APPROVED BY:
James Lester Christopher Healey
Benjamin Watson Robert St. Amant
DEDICATION
To all the monkeys, cats, rodents and countlessdrosophila melanogaster flies that selflessly contributed their lives, literally, to human curiosity about visual perception — a product of
BIOGRAPHY
Arpan Chakraborty was born in Haldia, a small town in West Bengal, India. After primary education there, he attended Vishwa Bharati Public School, Noida, where he developed his interest in computing. He received his B.Tech. in Computer Science and Engineering from West Bengal University of Technology (WBUT), Kolkata, in 2008, and an M.S. in Computer Science from North Carolina State University (NCSU), Raleigh, in 2010. He has worked on fuzzy and non-monotonic logics at the Indian Statistical Institute (ISI), Kolkata, under the supervision of Dr. Kumar Sankar Ray, and is pursuing a doctoral degree focusing on computational modeling of visual perception at NCSU, advised by Dr. Robert St. Amant.
Arpan’s research interests include computer vision, cognitive modeling, human-computer interaction, common-sense reasoning and machine learning. He enjoys applying vision-based solutions to projects in various domains, including accessibility, embodied agents, robotics and augmented reality. He strongly believes in the importance of open source software in promoting innovation and contributes actively to several public repositories, some which are products of his dissertation research.
During his graduate career, he has taught an undergraduate course on Automata, Grammars and Computability Theory, and has co-authored a chapter on Link Analysis as part of a student-contributed textbook titledPractical Graph Mining with R(CRC Press), serving as a co-editor on the project as well. He has also co-authored a book chapter on Intelligent Interaction in Accessible Applications in A Multimodal End-2-End Approach to Accessible Computing (Springer). He has served as a student leader for the NCSU chapter of STARS (Students and Technology in Academia, Research and Service) that promotes broader participation in computing disciplines in the U.S., and is an active member of the NCSU IEEE Robotics Team.
ACKNOWLEDGEMENTS
I would first like to thank my advisor, Dr. Robert St. Amant, for his guidance and encouragement during my entire graduate career, and especially for his excellent comments that have helped distill my thoughts and shape this dissertation. I also appreciate the invaluable and honest feedback I’ve received from my dissertation committee members, Drs. James Lester, Christopher Healey, Benjamin Watson and Sharon Setzer, that has helped orient my research focus in a worthwhile yet feasible direction.
I have realized while writing this dissertation that it is the concerted effort of all the teachers and faculty that I have had the pleasure to learn from over the years, through grade school, college and graduate school, that has enabled me to meet this challenge. I am also grateful to my family and friends for all their support, encouragement and belief in my ability to successfully complete this journey.
I thank my friends from the Knowledge Discovery Lab, fellow students and others with whom I’ve had encouraging and stimulating discussions on a wide range of topics, some directly related to this dissertation and some influencing my work in subtle ways. This includes (but is not limited to) Sina, Thomas, Lloyd, Wei, Marivic, Srinath, Kyung Wha, Prairie Rose, Shea, Justis, Jeff, Daniel, David and Dr. Jae Yeol Lee. I would like to extend a special thanks to Trisha for her continual support, critique and encouragement throughout the writing of my dissertation.
My graduate school experience has been very hassle-free thanks to all the staff members in the Department of Computer Science who work tirelessly to ensure that administrative needs are taken care of in a timely fashion. I am also grateful to the department for supporting my research, along with Google, the Office of International Services (OIS) and the Science of Security Lablet (SoSL). Thanks to all the good folks at OIS who made my time there so memorable, and to my
TABLE OF CONTENTS
LIST OF TABLES . . . vii
LIST OF FIGURES . . . .viii
Chapter 1 Introduction . . . 1
1.1 Related work . . . 5
1.2 Motivation . . . 11
1.3 Challenges . . . 12
1.4 Contributions . . . 14
1.5 Application areas . . . 16
Chapter 2 Neurobiology of Visual Perception . . . 18
2.1 Attention and salience . . . 18
2.2 Fixations and saccades . . . 21
2.3 Neurophysiological processes . . . 22
2.4 A typical biological vision system . . . 25
Chapter 3 Functional Modeling . . . 38
3.1 Visual feature computation . . . 39
3.2 Feature abstraction . . . 40
3.3 Dynamic selection mechanism . . . 41
3.4 Inhibition and feedback . . . 41
Chapter 4 Integrated Cognition . . . 44
4.1 Overview of agents and environments . . . 44
4.2 Interdependence of perception and action . . . 46
4.3 Cognition and intelligence . . . 50
4.4 Existing cognitive architectures . . . 55
Chapter 5 Computational Framework . . . 57
5.1 Inspiration from neurobiology . . . 57
5.2 Visual attention and selective processing . . . 66
5.3 Integration with agents . . . 69
5.4 Input-output channels . . . 70
Chapter 6 Visual Tasks . . . 72
6.1 Change detection . . . 73
6.2 Scene structure description . . . 80
6.3 Salient object detection . . . 85
6.4 Image recognition . . . 88
Chapter 7 Conclusions. . . .108
7.1 Summary . . . 108
7.2 Research significance . . . 109
7.3 Future directions . . . 111
LIST OF TABLES
Table 2.1 Summary of components along the visual pathway and their connections . . . 37
Table 3.1 Simplified summary of categories of units and their properties . . . 43
Table 4.1 Everyday scenarios illustrating relative involvement of perception and action; high coupling is indicated with an asterisk (*) . . . 48
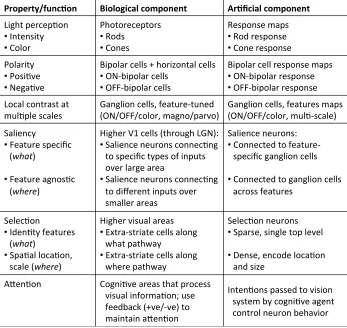
Table 5.1 Mapping from visual functions to biological and artificial components . . . 58
Table 6.1 Change blindness results summary . . . 79 Table 6.2 A sample output from the scene description agent showing relative coordinates
LIST OF FIGURES
Figure 1.1 Look! Do you see those tiny feet? . . . 2
Figure 1.2 Attentional maps generated using a saliency-based method [74] . . . 8
Figure 2.1 Cone densities in human retina . . . 19
Figure 2.2 Depiction of synaptic signal transmission . . . 24
Figure 2.3 Depiction of the human visual pathway . . . 27
Figure 2.4 Parts of the eye and retina . . . 28
Figure 2.5 Lateral Geniculate Nucleus (LGN) . . . 28
Figure 2.6 Retinal layers: Schematic diagram and micrograph . . . 30
Figure 2.7 Representative photoreceptor mosaic and density variation by eccentricity . . 32
Figure 2.8 Receptive field formation in V1 neurons . . . 33
Figure 2.9 Arrangement of orientation-sensitive cells in V1 . . . 34
Figure 2.10 Ocular dominance slabs and their relationship with orientation columns . . . 35
Figure 2.11 Connections from LGN terminating in different V1 layers [146] . . . 36
Figure 4.1 Classical notion of agent-environment interaction . . . 46
Figure 4.2 Three control scenarios for balancing an RC helicopter – which is more cognitive? 51 Figure 5.1 Structure of a Neuron . . . 59
Figure 5.2 Neuron membrane potential traces . . . 60
Figure 5.3 Synaptic gating . . . 61
Figure 5.4 Schematic diagrams of neuron receptive fields . . . 61
Figure 5.5 Simulated [144] and observed [118] receptive field shapes . . . 62
Figure 5.6 A sparse 5-layer hierarchical network depicting neuronal connectivity . . . 63
Figure 5.7 Interleaved hierarchy of different visual feature pathways . . . 64
Figure 5.8 Normally-distributed neurons showing sparse interconnections (blue layer is on top) . . . 65
Figure 5.9 Photoreceptor density by eccentricity in system retina . . . 65
Figure 6.1 Illustration of the flicker paradigm in change blindness research . . . 74
Figure 6.2 Harborside: One of the input image pairs . . . 76
Figure 6.3 Spatial sampling resolution for the two cases . . . 77
Figure 6.4 Visualized output of what the system perceives . . . 78
Figure 6.5 ‘Couple’ image . . . 79
Figure 6.6 A typical setup for the scene description task . . . 81
Figure 6.7 Test scene used for description task . . . 83
Figure 6.8 Scene reconstructed from description . . . 84
Figure 6.9 Salience maps generated from neuron activity . . . 86
Figure 6.10 Comparing salient object detection results: 1. Ma et al. [102], 2. Itti et al. [81], 3. Liu et al. [98], 4. Our framework . . . 87
Figure 6.11 Object images from the COIL-100 collection . . . 89
Figure 6.13 COIL-100 results (1 top-level neuron per feature) . . . 91
Figure 6.14 MDS layout of images (1 top-level neuron per feature) . . . 92
Figure 6.15 Sample image features computed on the COIL-100 dataset . . . 94
Figure 6.16 COIL-100 results: Varying top-level neurons per feature . . . 95
Figure 6.17 MDS layout of images (2 top-level neurons per feature) . . . 96
Figure 6.18 Image matches (highlighted with green rectangles) . . . 97
Figure 6.19 COIL-100 results: Logarithmic relationship to no. of training views . . . 98
Figure 6.20 Sample stimuli used by Zelinsky and Sheinberg [163] (top: parallel condition, bottom: serial) . . . 100
Figure 6.21 Mean reaction times for parallel and serial search, as a function of display size [163] . . . 101
Figure 6.22 Sample trial: Input stimuli generated by PsychoPy (left) and system output (right) . . . 102
Figure 6.23 Results: Mean reaction times by display size . . . 103
Figure 6.24 Revised results: Mean reaction times by display size . . . 105
Chapter
1
Introduction
Perception is a key ability that allows an organism to function intelligently in a given environment. It shapes experiences, informs cognitive processes and enables goal-directed action. In this role, perception is far from being an involuntary mechanism to generate and update an internal representation of the environment; instead, it is very much an active process mediated by situational awareness and highly coupled with task-specific actions. It is this realization that perception is an activity that agents engage in with a purpose, that allows us to begin to understand its underlying complexity and competency in a wide variety of tasks.
At the heart of this characterization is the concept of attention. It is both a necessity and a deliberate technique for successful interpretation of sensory information across different modalities. Attention helps us direct perceptual resources to relevant stimuli and avoid sensory overload. Even if we were not constrained by our processing capacity, it could be argued that only a small number of distinct stimuli are relevant at any given time. By limiting the set of items available to us for further analysis, attention makes the task of cognitive reasoning tractable.
our developmental period. In addition, as humans we tend to structure our environments to exploit what we know about our own attentional mechanism. Bright traffic signs, blaring fire alarms and pungent odors added to cooking gas are all too familiar instances of how we ensure that critical information about the environment is hard to miss. Even in everyday life, things like colored post-it notes, kitchen timers and bumps on the keyboard that assist touch-typing are part of an elaborate machinery that keeps us on track and helps us increase productivity.
We seem to have figured out effective ways of complementing our perceptual systems even though we are still learning how they work. In fact, from a qualitative perspective, we do understand some aspects of perception very well. There is subtle evidence in human natural language that indicates we are able to communicate notions related to perception in a succinct manner — notions that we find hard to articulate at length. An example:
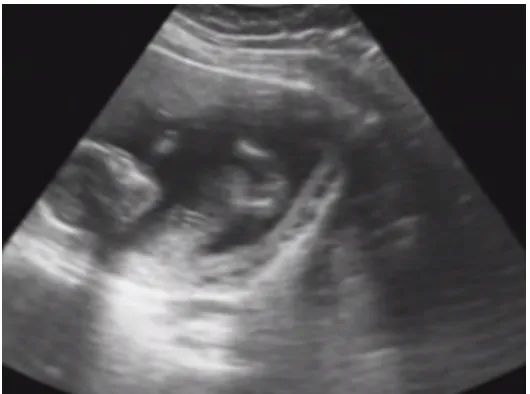
Mary was very excited the day she got her first ultrasound scan (Figure 1.1). She showed the sonogram to Cliff and said, “Look! Do you see those tiny feet? They are so cute!” Cliff squinted at the picture as he responded, “I think I see the head. Where should I look for the feet?”
Both speakers in the above conversation make a distinction between look and see. The former refers to the intentional act of directing one’s attention to a particular entity, and the latter captures the idea of perceptual realization — the point at which one has made sense of a sensory stimulus. In fact, the word ‘see’ is frequently found in popular usage to refer to the comprehension of abstract ideas, as in, “Do you see what I’m saying?” What makes it an effective choice for communication is its grounding in our shared perceptual experiences.
We have a lot to learn from natural language about perception. For instance, the term salience has long been used to capture the idea of relative importance — in a wide variety of domains, both technical and non-technical. The use of salience (or,saliency) as a concept in computational modeling of visual perception is relatively recent. Specifically, Itti et al. [81] describe visual saliency as the quality of a stimulus, at a particular location and scale, to stand out from its surrounding visual field in one or more observable feature dimensions. Interest in visual saliency detection has grown considerably in the last decade, with alternate formulations and more efficient computation of saliency maps being proposed [74, 63, 57]. These approaches to saliency computation are mainly bottom-up in nature. The top-down effect of attentional control is harder to operationalize as an explicit translation is required from intentions to computational formulations for low-level processing [121, 113].
Assigning a measure of salience to different regions within a visual field is one part of the attentional mechanism. Selection of one such region at a time for further processing is a hard problem as well. Usually, the most salient region in an image can be selected through mutual competition and/or iterative optimization. Current attentional models tend to perform this step after bottom-up processing has yielded a saliency map. This means, even if a higher-level agent had the explicit intention of focusing on a certain region and/or feature, a lot of extra computation would need to be performed and then discarded. It seems there is a need to formulate an integrated mechanism for attentional selection that allows bottom-up and top-down influences to interract, resulting in efficient computation.
a seamless world. After all, attention is most useful when it is judiciously allocated for short periods of time — so that relevant stimuli with brief presentations are not missed. In order to not get fixated on a single salient stimulus indefinitely, a perceptual system needs to incorporate a mechanism forinhibition. Limited attention span seems to be a consequence of such inhibition, and acts as a simple approach for cycling resources to focus on different environmental features. Inhibition may also work in other ways, for instance, to reduce the perceived salience of distractors when looking for a specific target. Although some of the current attentional models incorporate a mechanism for inhibition (e.g. to predict fixation locations in a sorted order), they rely on visual input being largely static, or at least from a constant viewing angle, and do not capture the temporal dynamics of inhibition by which inhibited regions return to their normal state.
The current state of saliency and attentional models serves as a strong foundation for the development of solutions to a broad set of vision problems [19]. However, key aspects of perception necessary for supporting end-to-end tasks and activities — especially temporal mechanisms — are not well-established. This motivates the development of a unifying framework that addresses these concerns. This dissertation looks into designing such a framework using a neuronal architecture inspired directly by biological vision systems [30]. The choice of fairly realistic neuronal units with temporal properties holds the key to solving some of the challenges highlighted above. Beyond detecting salience in images (and video streams), the framework enables us to perform a variety of visual tasks without making significant changes to the underlying implementation. One way of specifying task-specific constraints and intentions is via a structured interface that cognitive agents can interact with. This helps us understand how common low-level perceptual processes can be woven together using cognitive control to achieve seemingly complex high-level behavior, in both computational as well as biological systems.
valid here, as highlighted in Section 1.3. Some issues get resolved implicitly and new challenges surface. Most importantly, the way in which we deal with these problems becomes fundamentally different. Finally, we discuss how this work can lead to novel contributions to the field in Section 1.4.
1.1
Related work
Computational approaches to vision have had limited success in reflecting back upon natural visual processing. They are largely grounded in the nature of the hardware they must use for visual input, and algorithms that have been developed in the context of modern general-purpose computers. The majority of computer vision literature is based on the seminal works of David Marr and his colleagues [105, 104, 106] (see [130] for an overview of the field). These methods have been developed and refined with well-defined visual tasks in mind, such as image segmentation, object recognition, object tracking, face recognition, etc. Some mathematical constructs used in these procedures have an abstract relationship with natural visual processing, such as radial basis functions, scale-spaces, neural networks, et al. But the overall methods lay little stress on the objective of testing theories about how vision works in biological systems, favoring computational efficiency and accuracy instead. They do not embody a larger theory of cognition either, hence reasoning usually takes place in a separate layer, symbolic or connectionist, in most vision systems (see [82] for a critical review of computer vision research).
High-speed tracking of objects is another successful endeavor, with applications in sports, motion capture for the entertainment industry, surveillance and the military. Visual search, indexing and categorization are popular techniques used to deal with massive databases of images.
Machine vision Autonomous agents have benefited immensely from this progress, from industrial robots to those that operate in office, home and outdoor environments. Computer vision techniques such as SLAM (Simultaneous Localization And Mapping) [38], structure-from-motion [69] and stereo vision [120] help agents analyze their environment in enough detail to facilitate navigation and precise manipulation. Developments such as SIFT (Scale-Invariant Feature Transform) [99] and other feature or shape-based matching algorithms [12, 27, 14] provide decently accurate recognition capabilities.
If computer vision techniques are already so good, then why should we even bother with adopting biologically-inspired approaches? One key element that is common across a large body of work in computer vision is the fact that dynamic visual input is dealt with as a sequence of discrete frames. Some applications only need to deal with static images, in which case this approach works quite well (such as face and object recognition). Other visual tasks, especially those dealing with motion, need objects or structures to be analyzed across frames (e.g. tracking, SLAM, etc.). More often than not, these frames are first analyzed independent of each other. And then, information extracted across several frames is assimilated using external data structures, such as Kalman filters and probabilistic maps. As a result, achieving real-time performance is essentially a matter of speeding up the analysis of individual frames. This is achieved by a combination of reducing the resolution/simplifying the level of analysis, optimizing the major mathematical operations involved and using increasingly faster computing hardware.
are not able to perform well using computer vision algorithms that are otherwise quite accurate. This is especially true in mobile agents. And vision is not the only processing that an agent has to do; reasoning can become quite tedious when it involves planning and search. This is the main reason why we have to speed-up robot demonstration videos so often. In some cases, the real-time requirements imposed by an agent render some approaches unusable. These are indications that a technique that was initially developed for static images, and then evolved for a sequence of images, may not be the best approach to deal with dynamic visual input in a real-time context. In fact, thinking of visual input as a uniformly arranged grid of pixels or as a high-dimensional time-varying signal that is discretely sampled at regular intervals is an artifact of video recording and playback technology (for which it is a perfectly plausible approach). It should have no bearing on how visual information is processed.
Saliency-driven models As mentioned before, saliency is a term that has been used to refer to the uniqueness of an area of visual input along one or more feature dimensions [81, 154, 80]. Local features used for computing salience include intensity, variance, density, texture, orientation, etc. Contrasts along these dimensions are computed and combined to produce a saliency map. Local minima on this map refer to areas in the input array that are visual significant. The entire operation is performed at different scales to accomodate salient features of different sizes. This computational method is inspired by evidence from neurobiology that indicates the presence of feature-specific neurons in different areas in the brain, and with different receptive field sizes.
Figure 1.2: Attentional maps generated using a saliency-based method [74]
the scope of attentional shifts has been limited to areas within an ‘image’ that is being analyzed. Biological and real-world artificial systems, on the other hand, are exposed to a more complete world that in some sense is infinite. This creates a need for applying attention to actively sample different regions of the environment, not just within a constrained area.
A recent exhaustive comparison of saliency models with human fixation data revealed that performance of individual models varied considerably with datasets, although some consistently performed well [20]. This can be attributed to the fact that these models process different sets of feature channels, some of which could be more suitable for a particular category of images than others. The models that consistently performed better demonstrated good results across a greater number of feature channels.
One question this performance variation raises is what exactly do these models compute? [90] Without any cognitive influences or situational constraints, the models are somewhat free to define the exact metric they are tuned to under the umbrella term ‘salience.’ More importantly, investigations using specific visual tasks have indicated that low-level saliency is not adequate in correctly predicting human performance in certain tasks including change detection [140] and visual search [70]. Again, this is understandable as most of these saliency models do not include any top-down control mechanisms, and are thus unable to utilize task-specific instructions.
or resolution.
Active vision The scope of perception is usually constrained by the requirements of an agent’s current activity. This idea has inspired a line of research under the umbrella term active vision, exemplified in the work of Ballard and his colleagues [8] who demonstrated the use of visual behaviors such as gaze control, fixation, foveation and vergence for anthropomorphic vision systems. We focus on this interdependence of action and perception in our work to make visual processing more situated and efficient.
Other approaches that perform visual processing without activity-specific constraints or explicit control over visual input are generally classified aspassive vision. One critical question to ask in the context of comparing active and passive vision is whether one has any advantage over the other. Clearly, passive vision wins in terms of simplicity of the approach, clear segregation of perception from action, and feasibility of implementation on current hardware systems. But the goal of vision is primarily to let an agent obtain a functionally useful understanding of its environment. For agents with active components, or which operate in dynamic environments, traditional passive approaches to vision are inadequate [3].
When trying to deal with dynamic visual input, a lot of complexity is introduced in passive methods due to the reformulation of static image analysis algorithms in an active context. The segregation between perception and action may not be vital either, as we later argue in Section 4.2. In fact, a theory for dealing with active vision must incorporate the idea of action within it. One such attempt has been Gibson’s ecological approach [53]. Although abstract in nature and arguably incorrect in certain specifics about visual phenomena [51], it does focus on very relevant ideas — mainly, the formulation of perception as the process of actively sampling information available at any location in the environment.
affordances. Differentiating himself from earlier concepts of demand, invitation and valence, Gibson stressed that affordances are always present, whether perceived by an agent or not. Thus, the role of perception is extended to not only understandingwhat there is in the environment, but also what can be done with it.
1.2
Motivation
Our goal is to formulate a framework for active vision that can be effectively used by artificial agents. Most existing computational vision techniques do not explicitly embody a concept of activity throughout stages of visual processing. As a result, they are either not suitable for dealing with naturally changing visual input or do not utilize the visual structure available in the environment to optimize computation [3, 6]. The dynamic nature of active vision, as opposed to passive vision, creates the need for a new way of looking at visual perception. In essence, the problem is not of signal processing but control of data acquisition [7]. Since biological beings seem to perform so well in this domain, we have decided to carefully study and take inspiration from them. Specifically, we intend to model some aspects of our framework on mammalian vision systems. We do not aim to design new computational hardware architectures to implement our ideas, but we do identify that as a possibility for future work.
We also wish to design agents that interact with the framework to accomplish specific visual tasks. Through these tasks, we plan to demonstrate the applicability of our framework across different contexts, and show explicitly the necessary mechanisms implemented in the framework that enable different visual functions. This serves as a foundation for explaining visual phenomena in terms of specific structures and processes, and the interaction of the visual system with cognitive control.
1.3
Challenges
In designing the framework, we have identified the following main challenges:
Highly dynamic visual input: The incoming visual information for an active system is inherently dynamic because of the possibility of both external as well as self motion. In addition, active vision employs actual gaze direction change as a means of focusing visual attention. The well-established approach of taking snapshots and performing passive vision on them doesn’t work well in these scenarios. In fact, most such approaches have an assumption of minimal motion. It is therefore a challenge to come up with a representation that affords the kind of active analysis that we want.
Integration of visual information: An active vision system can gather several discon-nected pieces of visual information over time. The issue then remains of integrating them to give a smooth and seamless picture of the environment. Our own eyes have mastered this capability, but we are yet to fully understand how they work. This integration is very important for any agent that needs to maintain a coherent sense of its surroundings. Some of this work must be performed at a higher-level, beyond the basic framework, but we must at least provide the cues necessary for such integration.
the structure of an artificial neuron, for instance, involves modeling each part (dendrites, axon, etc.) as well as its dynamic properties (such as action potential). Even then, their behavior barely reflects that of real neurons. Moreover, some aspects of connectivity and effects of electrochemical information flow are practically impossible to simulate artificially.
Real-time operation: It has been observed that the implemented framework can perform quite well on standard desktop hardware for simplistic tasks (such as identifying areas of high spatial and/or temporal variance). But as we add more capabilities to the system, the complexity of the structure as well as each individual unit increases significantly. We have already realized that simulating the functioning of each and every unit continuously is not possible in real-time. Therefore, a selective processing scheme is necessary. This will be even more important for mobile platforms where processing capabilities are typically limited.
Integration with motor systems and higher-level cognition: Enabling the percep-tual apparatus to control some movement, in order to affect what is perceived, is a central requirement of active vision. We must therefore address the issue of having a structured interface to motor systems, either real or virtual. The visual information extracted by our framework, as well as some control on perception, needs to be exposed to a higher-level cognitive system in a manner that does not break the perceptual grounding we achieve. But at the same time, we cannot assume the higher-level system to use the same kind of architecture as our vision framework.
1.4
Contributions
By applying techniques learned from the study of biological systems, we make the following contributions to computational modeling of early vision.
Realization of a theory of explicit attention in visual perception: Our approach to active vision has its basis in the general theory of attention. It is a manifestation of the theory grounded in perception, and can serve as a new model for evaluating hypotheses about visual attention. Using the interface to higher-level processes, our framework can be used to design and test different approaches/algorithms for controlling attention. Coupling with an external motor system can enable the exploration of perception-action strategies as well.
Biologically inspired neuronal architecture: Some computer vision systems do utilize active components, especially pan/tilt/zoom (PTZ) cameras, but their processing archi-tectures are mostly computational – not biologically inspired. The architecture proposed in our framework has its basis in biological systems, from overall connectivity down to the model of individual neurons. This is different from neural networks where each unit is significantly more simplified and generally does not hold state. There are systems that have implemented biological neuronal networks that are much more realistic compared to our framework (such as the Blue Brain Project [103]), but their focus has been on analyzing generic neuronal operation, not on enabling active vision for artificial agents.
Novel adaptive frameless processing technique: To further support the possibility of real-time operation, we introduce new mechanisms for adaptive processing of visual information. Keeping the overall structure constant, we vary the sampling rates of each neuronal unit based upon a salience measure, but with a randomized approach to prevent degeneration. This is similar to the concept of adaptive frameless rendering [157] for computer-generated graphics, but we are not aware of any equivalent mechanisms in the active computer vision literature.
Perceptual grounding through direct association with neurons: The neuronal units we present can hold state information, as opposed to traditional neural network units. They are also responsible for processing visual input. Our representation of the environment thus persists in these units. This is a unique formulation of representation and reasoning with visual input that addresses the problem of perceptual grounding. What our framework sees is not a simple flat visual array, but a multi-level structure. Parts of this structure can be sampled at different levels of detail to obtain a more traditional ‘picture’ of the current environment, but further cognitive processing can be performed
directly on the structure itself.
Support for cognitive control and modeling of visual tasks: We demonstrate how bottom-up saliency-driven attentional mechanisms can be modulated by top-down task-specific influences to precipitate efficient visual computation. Thus we provide a more realistic vision module for cognitive agents that explicitly separates internal states and processes from external instructions. The framework supports detailed modeling of vision-intensive tasks and is able to explain characteristics of human-like performance using properties of specific mechanisms.
emulated input devices. This enables modelers to use experiments in the same form as administered on humans, without the additional step of abstracting the interface which may subtly affect results.
In addition to the above, our framework also hints at a new approach towards processing any kind of sensory information in general. Thus, variations of the framework may be applicable for other modalities, such as touch, audition, etc. We also anticipate the possibility of expressing multimodal information within a single unified framework with a provision for modal interchange. Some of these ideas have been discussed in Chapter 7.
1.5
Application areas
We envisage two main categories of applications for our framework:
Perceptual component for cognitive agents: Cognitive agents, especially those op-erating in the physical world, will benefit from having a perceptual component designed specifically for active use. Possible configurations for such systems include stationary manipulators, anthropomorphic designs, mobile ground-based robots, unmanned aerial vehicles, surveillance cameras, etc. In order to have the framework function as designed, there is the need for such systems to employ some physical control over directing visual attention – either by moving a part of their body (such as mounted camera platforms) or by moving the entire body (in fixed camera designs).
Virtual agents that are designed to interact with humans via visual input, such as gestures, will also find the framework useful. Some aspects of human-human interactions are embodied in perceptual actions that we take. For instance, when someone points in a certain direction we realize they are telling us to look that way. These basic behaviors can be encoded by coupling our framework with relevant motor systems.
Cognitive modeling and evaluation: As mentioned in Section 4.4, cognitive modeling researchers need a stronger and more generic model of perception to evaluate human-computer interfaces. This will be possible with our framework by passing the rendered interface as input to the system. We will then be able to study various low-level visual aspects of an interface, such as relative contrast, visual appeal, clutter, attention switches, etc., with a strong perceptual basis.
Chapter
2
Neurobiology of Visual Perception
Neurophysiological facts about visual perception paint a very fascinating yet mysterious picture of information processing in biological systems. We discuss here elements that we believe make a significant contribution to the efficacy of this sensory modality. A description of high-level ideas is presented, followed by an in-depth analysis of the various components that make up a typical biological vision system. We summarize the functional aspects of these components that inspire our modeling of visual perception.
2.1
Attention and salience
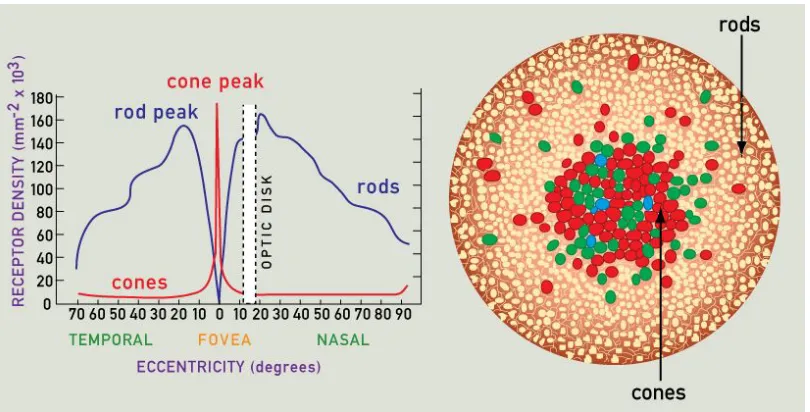
Visual attention in humans and most other animals is a necessity because of the foveal nature of our eyes. There is a substantially higher density of cone photoreceptor cells in the fovea. In human eyes, approximately 50% of the optic nerve fibers carry information from the fovea which only covers about 1% of the retina. The illusion that we can see everything as a uniform high-acuity picture is maintained by frequent shifts of attention, once every few seconds, and a yet unexplained process of integration.
region has fewer cones (big bright cells with dark outline) and more rods (which are responsible for low-light vision, and are not sensitive to color). Figure 2.1b presents a distribution of cones over the human retina obtained from clinical studies. Note that the distribution is highly asymmetric, and varies from person to person, but the general pattern of decreasing density with eccentricity remains (see [91] for anatomical detail of the human retina).
(a) Foveal vs. peripheral regions magnified [131] (b) Isodensity contours [36]
Figure 2.1: Cone densities in human retina
Covert and overt attention The psychology literature provides evidence for two kinds of attention in humans. Overt attention refers to the action we take to foveate an item of interest, i.e. to make its image fall on the central part of the retina. This is essential for us to see the item with enough visual acuity that enables fine-grained recognition. Reading text is a good example of a scenario where we sequentially shift overt attention from one word to the next. Words that are further away from our center of focus appear blurry and cannot be understood. We use overt attention to focus on practically everything that we need to see, sometimes glancing at items for a fraction of a second, while sometimes lingering on for a while.
Clinical experiments have revealed another kind of attention that deals with focusing on an item of interest within the field of view, but not in the foveated region. This is known as covert attention (some primates also show this behavior [139], and it is possibly true for other animals as well). The best known example of this phenomenon is looking through the corner of an eye. This proves that even if we are physically looking in one direction, we can voluntarily force our mind to focus in some other direction. This can be useful in scenarios where we must focus on one item while also watching out for a probable change elsewhere.
2.2
Fixations and saccades
Active vision can be described, from a motor perspective, to be an alternating sequence of fixations and saccades. A fixation is the act of maintaining overt attention on some item or region in the visual field. A saccade is the act of changing the fixated location to somewhere else. Note that both fixation and saccade involve oculomotor movements, but in different ways.
When we are fixated on a point, we may need to rotate our eyeballs to compensate for other movement such as moving our heads and/or bodies, or movement of the point itself. This movement, known as vestibulo-ocular reflex (VOR), is generally smooth and is meant to keep the point of interest centered within the eye’s foveal region as best as possible. This process may be interrupted due to sudden movements of the point relative to the eye, but fixation is usually regained without the need for a saccade. When we need to change the point of fixation – either to re-acquire a lost fixation point or to move to a new one (an object that grabs our attention/something that one intentionally looks at) – our visuomotor system initiates a saccade. The oculomotor muscles, in this case, perform a programmed (or stereotyped), ballistic movement. If necessary, neck muscles may also be activated to move the head. And consequently, the body may also move to relieve stress on muscles and joints. During a saccade (in fact, a little before saccadic movement begins), visual processing is temporarily suspended till the saccade is complete and the eye comes to rest (with respect to the newly fixated point). This is known as saccadic suppression. The phenomenology of a saccade, including the neurophysiology of saccade execution and effects such as saccadic suppression of displacement, have been studied in detail [37, 138].
and longer sequences of saccades as well, but the duration of saccades (and consequently, of suppression) varies – sometimes exhibiting distinguishable classes of behavior [34].
Transsaccadic integration Our eyes work with the rest of our visual perception apparatus to give us a seamless picture of our environment. This seems quite a difficult task given the fact that we move about freely in the environment. On top of that, frequent saccadic movements in arbitrary directions are the norm, resulting in a continuously changing image being formed on the retina. Transsaccadic integration is the process of maintaining a coherent representation of the world across continuous bodily movement, fixations and saccades.
When we are fixated on a point, that point serves to be a reference or origin for the current coordinate system in use. When we perform a saccade, the new point becomes the new reference, and the location of the last fixated point is transformed to match the new coordinate system. An exception to this may occur when we move away from a less significant point of fixation – that less significant point may not be transformed (and hence not remembered), instead, the last significant point is re-transformed. This process of transformation is still a mystery, but some clues as to how it works have been discovered [13] (see [79, 37] for clinical results and discussion).
2.3
Neurophysiological processes
Here we briefly discuss the low-level neurophysiological processes that are behind the phenomena outlined above. These processes are common to other sensory modalities, and the nervous system in general.
multiple dendrites that receive signals from other neurons (input). The structure and chemical composition of a neuron results in an electrical potential difference between the inside and outside of the cell, calledmembrane potential. Normally, theresting potential of a human neuron is about −70mV (the matter inside the cell is less positively charged). A complex process of ion exchange (N a+,K+, Ca2+ etc.) mediated by channels across the otherwise impermeable cell membrane maintains ion concentrations (and hence the membrane potential) in a dynamic equilibrium. This equilibrium can be skewed, and potentially broken, by stimulation of the neuron. Depending on the type, function and location of a neuron, it can be stimulated in several ways, such as mechanical pressure and vibrations (neurons sensitive to touch, stress, sound, etc.), chemical reactions with external agents (sense of smell, taste, etc.), light irradiation (photoreceptors on the retina), as well as by other connected neurons.
its level of excitation.
Figure 2.2: Depiction of synaptic signal transmission
Neural activation When we think of some “thing” (can be an object/person, or more generally, a concept), a visual representation (if one exists) appears in our mind’s eye. This is a result of the activation of some neuron (or group of neurons) that store the perceptual representation/properties of that “thing”. Such response is not necessarily limited to the visual domain; for instance, when we think of a song, it is as if we can hear it play. Depending upon the nature and complexity of what we are thinking of, we recall some specific aspect/part of the perceptual experience - a certain canonical view of an object, the face of a person, the repeating chorus or unique solo of a song. We often experience a concept in more than one modality concurrently, reinforcing each other, in some sense. This type of activation is usually subtle in nature.
This is caused by the act of perceiving something that we have prior knowledge of. The combination of perceptual properties that were initially associated with the it (or subsequently revised) are stored in neurons (perhaps in a distributed scheme). When the same properties show up again, those specific neurons are re-activated. This isperceptual activation. This form of activation is stronger in terms of neural response due to external stimuli, hence a perceived image is more distinct compared to a conceived image.
2.4
A typical biological vision system
Visual pathway
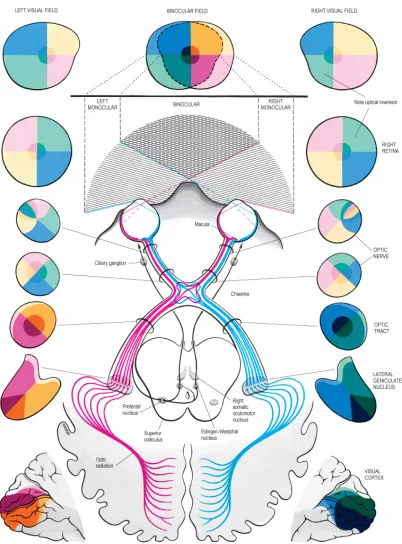
The primary visual pathway begins with the eyes and leads to the visual cortex at the back of the brain, as shown in Figure 2.3. This diagram also depicts portions of the visual field that are sampled by each eye, with a considerable zone of binocular overlap, and traces spatial aspects of the visual information as it flows to visual cortex. A lens in each eye helps form a focused but inverted image of the external world on the retina. This is only the first transformation that visual information is subjected to by the system.
Retinal sensing begins with photoreceptors, where photons of incoming light are converted into neuronal signals. These signals travel through layers of different types of neurons within the retina, getting manipulated and filtered along the way, and finally stimulate ganglion cells that form the topmost layer of retinal neurons. The axons from ganglion cells exit the retina through a point at the back of the eyeball called theoptic disc and constitute the optic nerve. The optic disc is a region of the retina that does not have any photoreceptors in it, and therefore manifests itself as a blind spot (this is not normally perceived by us because surrounding neurons ‘fill in’ the missing visual information). Luckily, the optic disc is located slightly off-center, sparing the foveal region that is responsible for high visual acuity. This is depicted in Figure 2.4, along with other parts of the eye responsible for image formation. Note that ganglion cells, like most higher-level neurons along the pathway, use action potentials for communication because of the longer distance their axons need to traverse (graded potentials attenuate easily and are only useful over very short distances).
(a) Lateral view of the eye (b) Frontal view of the retina
Figure 2.4: Parts of the eye and retina
different layers grouped into two sets, namely,magnocellular (‘M’, with large receptive fields), and parvcellular (‘P’, with small receptive fields). These two sets of layers form the basis of branches in the visual pathway by the same name, which eventually play different roles in perception.
(a) Section showing LGN layers (b) Schematic: Axon terminations
Figure 2.5: Lateral Geniculate Nucleus (LGN)
magnocellular layers) imply that they consist of a significantly larger number of axon terminations. Since these axons come from ganglion cells with small receptive fields that are found mostly in the central region of the retina, this distribution is an evidence of the disproportionately dense representation of the fovea with respect to the rest of the visual field. Also note that at each LGN, axons from the two eyes —ipsilateral (‘i’, from the same side) andcontralateral (‘c’, from the opposite side) — interleave in a non-uniform arrangement. The local layout of neurons within these interleaved layers is such that signals from both eyes retain their spatial integrity. This allows subsequent neurons along the visual pathway to essentially sample the same region of the visual field from both eyes, enabling binocular vision. In Figure 2.3, visual field representations on the two sides depict these transformations.
Retinal layers
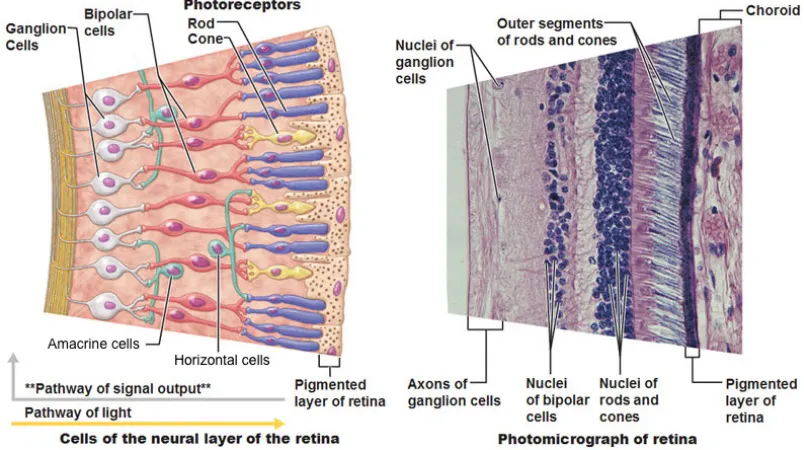
Anatomy of the retina is a fascinating subject of study. The first unusual fact is that the layers of the retina are ordered in a way that would be contrary to one’s intuition — the photoreceptors are located away from the direction of light at the back of the retina, while higher layers of neurons are located in front, and thus in between the light source and photoreceptors. This is shown in Figure 2.6. One purpose of this organization seems to be the replenishment of photoreceptors that undergo physiological change as part of their function. Their outer segments contain discs filled with opsins (a group of light-sensitive proteins) that are continually shed and need to be replaced.
Figure 2.6: Retinal layers: Schematic diagram and micrograph
response. The combined function of horizontal and bipolar cells is to create small center-surround receptive fields that boost contrast and reduce sensitivity to diffuse light. They also help maintain color constancy and adapt to different light levels — horizontal cells compute a baseline value over a localized region and bipolar cells respond to the difference from that baseline.
There are different types of bipolar cells with varying response characteristics and photorecep-tor affinity. Some are excited by phophotorecep-torecepphotorecep-tor activation whereas others are inhibited; some only connect with particular types of rods or cones. These characteristics effectively create multiple low-level feature channels. Bipolar cells transmit signals to retinal ganglion cells, also via graded potentials. There are intermediate neurons called amacrine cells that regulate information flow at this interface just like horizontal cells at the previous interface; their roles, however, are not very well understood.
Ganglion cells have strong center-surround receptive fields. This is a direct result of the underlying photoreceptor mosaic (Figure 2.7) and distribution of bipolar cell characteristics. Ganglion cells that receive inputs from the same effective feature channel in both their central and surround regions compute local contrast in that space, whereas those that receive inputs from one channel in the center and one or more other channels in the surround region compute color-opponent values. This naturally random self-organization is effective because of sheer scale — for instance, the human retina contains around 80–110 million rods and 4–5 million cones feeding signals through about 36 million bipolar cells that ultimately converge onto 1–2 million ganglion cells [48]. This results in high-level feature channels that cover the entire visual field quite well, although there are intrinsic variations such as reduced color sensitivity in the peripheral region due to near absence of cones.
Figure 2.7: Representative photoreceptor mosaic and density variation by eccentricity
cells outputs ultimately travel to the visual cortex through the LGN, where feedback pathways implement top-down influences, we are able to filter stimuli based on desired scale in addition to other features.
Primary visual cortex
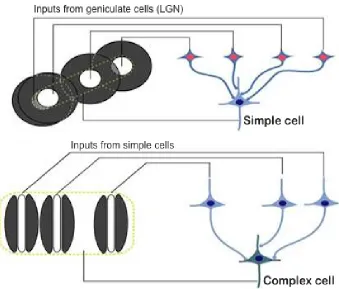
The primary visual cortex, or area V1, is a portion of the brain where processing of further derived features starts taking place. It is also the level at which origins of feedback pathways have been observed. There are primarily two types of cells here that compute visual features.
Figure 2.8: Receptive field formation in V1 neurons
Complex cells While a simple cell is sensitive to a particular location in the visual field, this other type of cortical neuron pools together inputs from simple cells with the same orientation preference over a larger region, resulting in receptive fields that are less spatially sensitive yet retain strong orientation preference (Figure 2.8). A variety of complex cells exhibit end inhibition, i.e. they are more sensitive to corners in their receptive fields than edges passing through — they are understood to be a result of combining inputs from antagonistic simple cells.
as one would naively expect. Continuous iso-orientation contours meet at points of singularity to form pinwheels [18]. Figure 2.9b is a color-coded image showing this arrangement, captured directly using optical imaging of the visual cortex with a highly sensitive camera while gratings of different orientations were presented.
(a) Orientation columns (b) Pinwheels formed by iso-orientation contours [18]
Figure 2.9: Arrangement of orientation-sensitive cells in V1
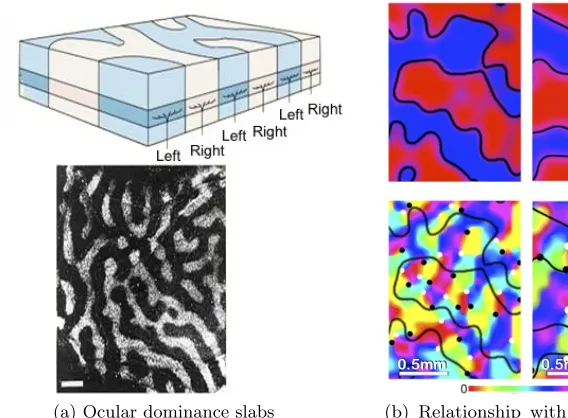
Ocular dominance slabs Recall that the LGN receives inputs from both eyes, and these are forwarded to V1. Investigation into the relative sensitivity of V1 neurons to one eye or the other has uncovered a non-random self-organization in this aspect as well [16]. Figure 2.10a depicts the interleaved clusters of cortical surface regions that form ocular dominance slabs and how these extend down through the layers of V1. Iso-orientation contours and ocular dominance slabs have an interesting relationship [162]. As shown in Figure 2.10b, orientation pinwheel centers (marked with white and black dots) usually lie within ocular dominance slabs, with the slab boundaries roughly perpendicular to the contours.
(a) Ocular dominance slabs (b) Relationship with orientation columns [162]
Figure 2.10: Ocular dominance slabs and their relationship with orientation columns
by Figure 2.11, axons from different LGN layers terminate at different depths within V11. Also illustrated are feedback pathways from V1 back to LGN — these are essential for passing down feature preferences that alter the image we perceive by inhibiting channels we are not interested in, and effectively boosting desired ones. In addition to these feedback connections, the visual cortex also has lateral connections — they play an important role in executing mutual competition for attention.
Visual properties other than orientation, such as color and texture, are also represented within V1 layers. Corresponding neurons are interleaved between orientation sensitive columns and are organized in either columns or blobs. The proper characterization of the structure of these channels is an active topic of research.
1Besides magnocellular (M) and parvocellular (P), a thirdkoniocellular (K) pathway also originates in V1.
Figure 2.11: Connections from LGN terminating in different V1 layers [146]
Summary
Table 2.1: Summary of components along the visual pathway and their connections
Component Layer/neurons Property/func3on Recep3ve field sizes Connec3ons
Re#na
Photoreceptors
(rods, cones) Light intensity, color Tiny
Bipolar cells Local contrast, adapta#on Small
Ganglion cells Contrast, color-‐opponency Vary by type
Lateral Geniculate Nucleus (LGN)
Magnocellular cells Relay ganglion cell outputs, separate pathways
Large
Parvocellular cells Small
Primary Visual Cortex (V1)
Simple cells Edges, orienta#on (local)
Vary by V1 layer Complex cells Orienta#on (less loca#on-‐sensi#ve)
Complex cells with
end inhibi#on Corners, ends of edges
Higher-‐level
Chapter
3
Functional Modeling
The summary of biological vision components presented in Section 2.4 forms the basis for our functional model of visual perception. We extract out certain characteristics that we believe are critical for successful operation and versatility across applications.
The use of simple processing units in a hierarchical organization allows efficient attentional control and abstraction of features.
Local contrast is an effective technique for adaptive salience computation.
Varying receptive field sizes enable approximate multiscale analysis; for systems with a high enough density of units, this approximation ends up being very precise.
Interleaving, not separation, should be the organizational mantra; it provides a unified mechanism for spatial selection across feature channels.
Active processing units that maintain (and change) state over time introduce an additional dimension of variability.
Inhibitory feedback can help prevent unnecessary processing; this is effective only when computation is distributed across units. Inhibition of entire feature channels can prevent detection of relevant changes, and is hence not recommended.
In designing a computational framework, one can apply one or more of these characteristics fairly independently. In the remainder of this chapter, we discuss how these ideas can be applied to visual processing stages.
3.1
Visual feature computation
Visual features can be treated as real-valued outputs from populations of processing units. In a hierarchical architecture, features can be computed at different levels, with higher layers utilizing the outputs from lower layers. One side-effect of this organization is that simple features are computed faster compared to complex ones. This is generally not a problem as salient simple features often result in useful priming.
Feature layers need not be well-separated. When interleaved, they may produce cross-talk/interference, leading to the dominance of one feature over others when it is more salient. Again, this is not a drawback — in fact, it can be thought of as part of a distributed selection mechanism that simplifies the task by performing some filtering at each layer.
Interleaving is also helpful in drawing specific attention to a region of importance with otherwise low salience. E.g., when we underline a word in a sentence, we use a linear edge detection feature channel to select the appropriate region which would otherwise have salience no different than its surroundings; once selected, other feature channels (such as those responsible for reading) automatically experience a higher activation in that region by virtue of being spatially co-located.
what features indicate its salience. An important result of this mechanism for spatial selectivity is that a combination of feature channels can together highlight a whole object that may be composed of visually disparate parts.
Ultimately, units with spatial sensitivity form another feature channel that is subject to the same attentional process of selection and inhibition, encoding in memory, and cognitive reasoning. This provides a unified basis for extracting visual as well as spatial features from a given stimulus.
Varying receptive field sizes of spatial units enable coarse and fine localization. Again, having them interleaved in the same layer can help direct attention to detail by first capturing focus at a coarse scale.
3.2
Feature abstraction
Assimilation of features into values useful for cognitive processing is an important part of the perceptual process. It is even more critical in case of hybrid computational systems where the cognitive reasoning layers do not subscribe to the same architectural concepts as the vision system.
One simple way to deal with this is to design top-level units that translate output from the vision system into a form that is compatible with the desired reasoning system. Top-level spatial units can indicate where salient features are present while other top-level units can encode what features are salient and to what degree. This is illustrated later in Figure 5.7.
By separating spatial features from others we enable cognitive processes to focus on locations independent of features and vice versa. Alternating focus can help fine-tune attention and boost feature activation to reveal detail.
3.3
Dynamic selection mechanism
The problem at hand is how do we go from a field of potential stimuli to one that reaches the cognitive level of processing? A popular approach is to generate activation maps of each feature channel (or one combined) and find the region with maximum activation. This process is made complex by the need for multi-scale sensitivity, i.e. it does not suffice to treat activation values at each point separately, nor can we use a fixed sizedwindow to find cumulative activation of each portion of the field. Popular computational strategies to address this include structured as well as random window sampling with non-maximal suppression [2] and winner-take-all networks [137].
Depending on the desired level of accuracy, such computational steps can be quite expensive, precluding real-time operation in most cases. In fact, having generated an activation map through multi-scale feature sensitive units, this process of re-estimating a relevant scale seems like a repetitive exercise. We believe that the selection mechanism should be inherent in the network used for feature computation.
This is where temporal dynamics play an important role. Specifically, instead of treating individual units as one-pass feature computation kernels, we need to model them as active elements, each with a process that updates an internal state or value over time and an event mechanism to send signals to other units. Such units respond to changes in inputs by varying temporal properties of their outputs (typically, firing rate in case of spiking neurons [52]).
Higher-level units can perform summarization over regions of the visual field using a weighted population average. These selection units can then send a signal when an appropriate threshold has been crossed. The first of such units in a layer to signal becomes theselected unit.
3.4
Inhibition and feedback
the same layer or processing stage.
When a selection unit sends a signal (to some higher layer) establishing its primacy, it also needs to send inhibitory signals to all other peer selection units in the same feature channel. Non-selected units can then enter a finite period of suppression during which the selected unit (and its indicated stimulus feature) is evaluated. Upon expiration of the suppression period, all
units become legible for signaling again.
The suppression mechanism need not be binary in nature — it can be a weighing factor such that high activation even during a suppression period can cause an override and a signal that interrupts current processing. This is extremely useful in ensuring that critical changes in the environment are detected in a timely fashion to enable appropriate response. The possibility of distractions occurring is an unintended result of a soft suppression approach. But when combined with top-down feedback, distractions can be eliminated (or at least minimized) by specifying feature preferences.
Lateral inhibition can thus help solve the problem of deciding which unit captures higher-level resources. Even with a finite suppression period for other units, there is a very probable chance that this selection mechanism degenerates into a single fixation if the one selected unit maintains high saliency. Although this can be desirable in a limited variety of tasks, in general this would be a debilitating restriction for perception. This calls for a method of self inhibition or inhibition of return that would prevent the same unit from being selected repeatedly. A means of operationalizing this concept is for the selected unit to enter a refractory period (much like biological neurons) during which it does not signal again. Other units with high activation, even if not higher than the presently selected unit, get a chance to be selected during this period.
Table 3.1: Simplified summary of categories of units and their properties
Feature units Salience units Selection units
Purpose Compute features Estimate salience Drive attention
Signaling frequency High Medium Low
Refractory period
(self inhibition) Short Short Long
Inhibitory signals
to other units – – Lateral
Chapter
4
Integrated Cognition
One of the goals of our modeling of visual perception is to enable cognitive agents to have a principled means of rich interaction with the environment. Towards this purpose, it is necessary to first define what we mean by ‘cognitive agents,’ the activities that we intend to support, as well as the nature of integration between our computational framework and higher-level cognitive processes.
4.1
Overview of agents and environments
The termagency essentially conveys a sense of empowerment, although its concrete meaning can vary according to context. In our present discussion, it refers to the ability of an entity to take some action in the environment in which it exists. This definition of agency entails a number of different concepts such as ‘environment’ and ‘action,’ and raises several questions about what drives an agent’s behavior, how it interacts with the environment and what it knows about its own existence.
but we have also seen the development of systems with a comprehensive set of abilities. Such systems are necessary for most agents that need to function in real-world environments. Although there are successful research programmes that have supported the case for purely behavioral and reactive agents with non-trivial emergent qualities, in this chapter we limit ourselves to the discussion of cognitive agents – those that have explicit mechanisms for reasoning and carry out actions based on both sensory inputs as well as higher-level intentions.
Robots are the most common and prototypical examples of real-world cognitive agents. They are seen as brand ambassadors of A.I. Many have been built over the years with different purposes and varying degrees of autonomy. Some are good at locomotion, some have excellent manipulating components, while others are designed to interact with humans by mimicking actions, or to learn to converse using natural language. All these designs fit the well-established agent-environment paradigm where the environment varies with the agent – it can be a two-dimensional area for navigation, a six-two-dimensional parameter space for manipulation, a world of other agents to interact with, etc.
A diverse set of scenarios can be considered for agent-environment decomposition. A smart CCTV monitoring system may require the ability to choose what to focus on and follow – such an agent would only be partially connected to the real world. A software help system can be an interactive agent that understands a user’s current context and proactively presents relevant information. Here, the agent is indirectly connected to the real world in the sense that it can observe the user’s actions within the software system. A search engine crawler may need some intelligence to decide what links to follow and how to rank websites. Such an agent has little to do with the world as we know it and does not require any real sense of time, but its environment (here, the World Wide Web) is potentially as real to it as the physical world is to a robot.
4.2
Interdependence of perception and action
Perception is understood as the process of extracting meaningful information out of sensory inputs in order to enable intelligent action. This definition does not preclude perception itself from involving some action. Although we often like to simplify an agent’s design by delineating its perceptual and motor components, it does not always transfer well to practical systems. One dangerous consequence of this differentiation is to conclude that perception must be a passive process. It is imperative to let go of such a strict distinction and adopt a more inclusive approach towards thinking about perception and action.
Figure 4.1: Classical notion of agent-environment interaction
![Figure 1.2:Attentional maps generated using a saliency-based method [74]](https://thumb-us.123doks.com/thumbv2/123dok_us/1248043.1157447/20.612.217.412.269.483/figure-attentional-maps-generated-using-saliency-based-method.webp)

![Figure 2.11:Connections from LGN terminating in different V1 layers [146]](https://thumb-us.123doks.com/thumbv2/123dok_us/1248043.1157447/48.612.216.416.69.369/figure-connections-lgn-terminating-dierent-v-layers.webp)