DISTRIBUTED FRAMEWORK FOR DATA MINING AS A SERVICE ON PRIVATE CLOUD
Full text
Figure
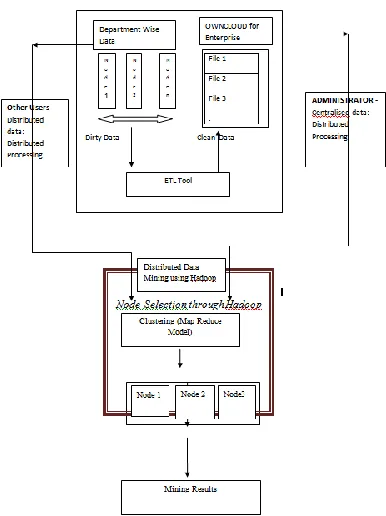
Related documents
Our Private CaaS is hosted within a client’s data centre and includes enterprise-class security, controls and performance guarantees as well as a REST-based application
Our study contributes to the understanding of intra-group divisions, by looking at political parties of ethnic minorities, as the main actors of electoral competition
përgjithshëm p.sh rrugët,liqejt,sheshet,mineralet etj. Është e ndaluar kontrata midis palëve kontraktuese kur njëra palë merr detyrim nga pala tjetër që të kryejë vepër
The hyperbolic case occurs when the extended map has no fixed point in L itself but has two fixed points at infinity: we examine this transformation in the half- space model H
particles smaller than 0.1 urn was not highly correlated with the mass concentration of particles with a diameter between 0.1 and 0.5 um (r = 0.51) (Peters etal., 1996), these
The Evaluator will place a check mark in the box for each numbered item completed correctly. The Firefighter will get three attempts to PASS
safety Health worker knows a child with AEFI should be given first aid; referred 70% 100% Health worker has AEFI contact information 65% 85% Health worker has working hub
Under core plus, an individual acquisition workforce member must attain the existing certification standards applicable to their respective functional career field.. This
