2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
A Decision Tree Model Based on Preference Cost Sensitive
Jian-hua LUO
1,a*, Yi-shan CHEN
1and Xin-hua ZHU
21Guilin Tourism University, Guilin, China
2Guangxi Normal University, Guilin, China
*Corresponding author
Keywords: Decision tree, Preference cost matrix, Classification.
Abstract. In view of the fact that the existing decision tree models have not considered the decision makers’ preference behaviors during the classification process, these models cannot predict the problems with obvious preference very well. Driven
by demand, this paper puts forward a new decision tree algorithm—a preference cost
sensitive decision tree (PCSDT). This algorithm introduces the preference degree and preference cost to decision tree. Then, we utilize the effective preference to construct a new attribute selection factor (ASF) and the class label distribution rule for a node. Finally, a preference sensitive decision tree with best preference degree is generated by adaptively adjusting the preference degree. Experiments have proved that the proposed method can guarantee better overall accuracy and performances than other traditional algorithms.
Introduction
The decision tree classification algorithm has been applied in the data mining area widely, due to its low complexity, rapid classification and strong scalability [1]. ID3[2], C4.5 [3] and CART [4] are the representatives of classical decision tree models. Based on these models, researchers have launched many constructive works around the attribute selection criteria[5-7] and pruning optimization algorithm[8-10],
etc.However, the decision tree technology is facing some problems, such as how to
reduce the cost of decision making[11-14]. Since cost-sensitive decision tree model was put forward by Charles Elkan in 2001[15], it has become a hot spot in the study of decision tree. However, an important cost type named preference cost doesn’t draw researchers’ attraction. If the preference cost isn’t taken into account during the process of decision making, it is infeasible to make a right decision in the preference-sensitive environment. In this paper, a new cost sensitive type called preference cost sensitive, is proposed. We propose the concept of preference degree and preference cost matrix, design a new attribute selection factor and the class label allocation criteria of a leaf node, and construct a preference cost sensitive decision tree model (PCSDT). Finally, the experimental results demonstrate that the new algorithms are feasible and effective.
Preference Cost Sensitive Decision Tree Model
Obtaining the Best Preference Degree
Because the preference degree influences the classification accuracy of the model, the
( )i
pref l value can’t be arbitrarily fixed. Assuming that the training dataset T has m
different classes labeled asl l1, ,...,2 lm, we set li as the preference class, and then the
weigh the accuracy of preference class and the overall classification accuracy
effectively, we design the algorithm to adjust thepref l( )i adaptively.
Take RC as the accuracy of preference class, it can be described as:
The number of preference class in the correct clas
Total number of prefe
sificat rence
RC io
s
n clas
= (1)
Assuming P delegates the overall accuracy of decision tree, F delegates the
harmonic mean of RCandP, then we can use F to reflect the overall index of the
decision tree comprehensively, which can be described as:
2 P RC
F
p RC
× × =
+ (2)
F can be regarded as the function of pref l( )i .
The algorithm of obtaining the best pref l( )i is as below.
① Presetting a fixed step length (such as 1), then we will obtain a series of
discrete values of pref l( )i , such as: 1, 2, 3…
② According to the different pref l( )i , the PCSDT model is generated, and Fis
calculated till RC=100%.
③ Finally, the pref l( )i corresponding to the maximum value of F is the best
preference degree.
In the process of searching for the best pref l( )i , a different step length may obtain a
different best pref l( )i . But as long as the step length is not large, the difference will be
small.
PCSDT Algorithm Based on Best Preference Degree
[image:2.612.119.495.477.720.2]According to the best preference degree, we can obtain a best PCSDT. The algorithm is as shown in Table 1.
Table 1. The Algorithm of the Best PCSDT. Prefs Tree (Instances, Build _Model, li, C)
Input: Training set: Instances ; Decision tree construction algorithm: Build _Model ; Preference class label: li; The preference cost matrix: C
Output: A preference cost sensitive decision tree.
1. Preset the preference degree of each class as 1, _ =0, _ =0, _ ( ) 1;i =
best RC best F best pref l
2. Set the step length of pref l( )i : Len; 3. While: best_RC≠100%
3.1Call Build_Model Insta( nces,pref l( )i,C) to build a temporary PCSDT; 3.2Get the RC, Pand F according to the formula (5) and (6)
3.3 if F: >best_F then
best_F=F;best_pref l( )i =pref l( )i ;best_RC=RC;
end if
3.4 pref l( )i =pref l( )i +Len ;
end While
4. Call Build_Model Instance best( s, _pref l( )i, C) to build a preference cost sensitive decision
The algorithm in Table 1 is used to form a preference cost sensitive decision tree. Step 1 and Step 2 initialize all parameters and step lengths. Step 3 is used to obtain the best value of these parameters. Step 3.1 is a function call. It can construct a temporary preference cost sensitive decision tree for the purpose of obtaining the best value of the parameters. The algorithm is as shown in Table 2.
Table 2. The Algorithm of a Temporary PCSDT.
_ ( , ( )i , C)
Build M odel Instances pref l
Input: Training set: Instances ; Preference degree of preference class: pref l( )i ; The preference cost matrix: C;
Output: A temporary PCSDT 1. Create the root node N;
2. If Instances==NULLreturn N=failure;
3. If all samples of the training set belong to the same class, then use the class to mark N; 4. If attribute list_ ==NULL return N as a leaf node marking by formula (3)
5. for each candidate attribute from attribute list_
select the split attribute SplitA from attribute list_ according to the formula (4); Mark N by SplitA;
end for
6. for each value of SplitA
Grow a branch SplitA=SplitAifrom nodeN; UpdateInstances;
7. If Instances==NULL
create a leaf node marking by formula (3) ; 8. else call Build_Model Insta( nces,pref l( )i , C);
9. Return a temporary PCSDT
The algorithm in Table 2 is used to construct a temporary PCSDT. Steps 1 to 4 are the process of initialing a decision tree. Step 5 is used to select the best split attribute. Step 6 calls the function recursively for the purpose of forming a subtree of the decision tree.
Experiments and Analysis
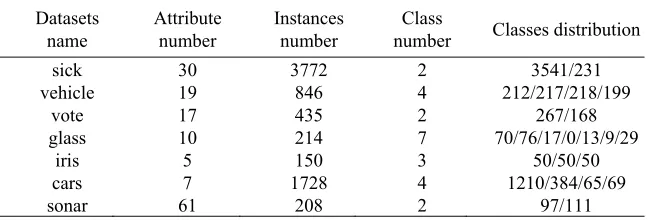
[image:3.612.145.469.579.689.2]In this section, we set up experiments to validate the rationality of our proposed methodology—preference cost-sensitive classification in various scenarios. All experimental datasets were selected from UCI machine learning repository. The details were shown in the following Table 3. All experiments adopted the method of “10-fold cross-validation” and we took their average as the final result.
Table 3. Experimental Datasets.
Datasets name
Attribute number
Instances number
Class
number Classes distribution
sick 30 3772 2 3541/231
vehicle 19 846 4 212/217/218/199
vote 17 435 2 267/168
glass 10 214 7 70/76/17/0/13/9/29
iris 5 150 3 50/50/50
cars 7 1728 4 1210/384/65/69
Impact of Preference Degree and Preference Cost on PSCDT
Take Iris as an example, the detail information about the dataset is shown in Tab.3. Iris has three classes: setosa, versicolor, virginica. Set virginica as the preference class. First, we study the impact of preference degree on decision tree without considering preference cost and set the following preference cost matrix:
0 1 1 1 0 1 1 1 0
C
=
[image:4.612.130.480.145.337.2]The experiment results are shown in Fig. 1.
Figure 1. The Impact of Preference Degree on Accuracy without Preference Cost.
As what we can see from Fig. 1: With the increase of the preference degree, the accuracy of preference class (RC) increases gradually and comes to the maximum of 100%. While the overall accuracy of the decision tree (P) decreases gradually, reaching a minimum of 0.77. When the preference degree takes 30, it reaches the peak, and then begins to decrease. So, 30 is the best preference degree at this time.
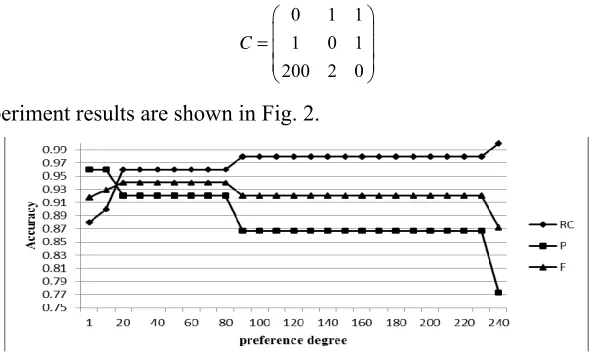
It denotes that we can get the best decision tree by adjusting the preference degree. Next, we study the impact of preference degree on decision tree when taking preference cost into consider and set the preference cost matrix as below:
0 1 1
1 0 1
200 2 0 C
=
The experiment results are shown in Fig. 2.
Figure 2. Impact of Preference Degree on Accuracy with Preference Cost.
It shows that after joining the preference cost, the movements of RC and P have
no change, but F changes. F1 denotes the F without preference cost, and F2 denotes
[image:4.612.158.456.465.643.2]Figure 3. The Comparison of F1 and F2.
We can see from Fig. 3: The fluctuation range of F2 is slowly and steady, which
shows that the join of preference cost makes the whole situation smoother. The best preference cost before joining the preference cost is 30, but it becomes 20 after joining the preference cost. It indicates that preference cost can avoid excessive preference and make the decision tree reach the optimal in advance.
We only report the results on Iris because of the page limit, but the results on other datasets are similar to it. In summary, we can conclude that the additions of preference degree and preference cost are reasonable and necessary, and that the best preference degree exists and can be found by our method.
Comparison of PCSDT Tree with C4.5 Tree
[image:5.612.114.263.509.674.2]The C4.5 algorithm is recognized as the baseline algorithm of decision tree. We compare the PCSDT generated from Part 3.1 with the C4.5 decision tree built on Iris. The comparison results are shown in Table 4.
Table 4. The Accuracy of PCSDT and C4.5. Algorithm Virginia Accuracy Overall Accuracy F
C4.5 0.90 0.92 0.910
PCSDT 0.96 0.92 0.940
Table 4 shows that the accuracies of the preference class and F have been improved higher in the PCSDT algorithm, while the overall accuracy is the same. Fig. 4 is an intuitive expression of the experiment. Comparing Fig.4(a) and Fig.4(b), it’s obvious that the node “Versicolor” in Fig.4(b) is further broken down. This indicates the reason why the accuracy of the PCSDT tree is higher than the C4.5 tree.
[image:5.612.124.500.519.674.2]
Conclusions
Our work reveals a new insight for cost-sensitive classification in machine learning and data mining. We propose a preference cost sensitive decision tree model. First, the article analyzes the preference cost sensitive issues, defines preference degree and preference cost and gives the concept of preference cost sensitive learning (PSL). Then, it describes a method to determine the best preference degree by self-adaption designs an attribute selection factor based on effective preference and constructs a preference cost sensitive decision tree model (PCSDT). The significant improvements have been observed in our extensive experimental study. Experiments show that PCSDT can not only achieve a high accuracy prediction for the preference class but also ensure a good overall accuracy.
Acknowledgment
This work has been supported by the National Natural Science Foundation of China (No.61462010, 61363036)
References
[1] Guang Li, Yadong Wang, Xiaohong Su. The Decision Tree Classification Mining
Keeping Privacy, Acta Electronica Sinica. 38.1(2010)204-212.
[2] Quinlan J. R. Induction of Decision Trees, Machine Learning. 1.1(1986) 81-106.
[3] Quinlan J. R. C4.5 Programs for Machine Learning, Morgan Kaufmann, San
Mateo, California (1992).
[4] L. Breiman, J. H. Friedman, R. A. Olshen, C. J. Stone. Classification and
Regression Trees, Wadsworth, Belmont(1984).
[5] Qin Ze, Wei Jianzhong. Selecting Test Attributes Criterion in CSL,
Microcomputer Information. 24.33(2008)288-289, 248.
[6] Liu Xingyi. Splitting Attribute Selection Method Based on Cost Performance,
Journal of Computer Applications. 29.3(2009)839-842.
[7] M. Dashand, H. Liu. Feature Selection for Classification Intelligent Data Analysis.
l.3(1997)31-156.
[8] Xu Jing, Liu Xu-min, Guan Yong, Dong Rui. Pruning Algorithm of Decision Tree Based on Condition Misclassification, Computer Engineering. 36.23(2010)50-52. [9] Xu Xianghua, Zhu Jie, Guo Qiang. Decision tree dynamic pruning method based on minimum description length in speech recognition, Acta Acustica. 31.4(2006)370-376.
[10] Terry Windeatt, Gholamreza Ardeshir. An Empirical Comparison of Pruning Methods forEnsemble Classifiers, Electronic Edition. (2001)208-217.
[11] Yiqun Liu, Min Zhang, Shaoping Ma. Network based on improved decision tree algorithm to determine key resources page, Web Key Resource Page Judgment Based on Improved Decision Tree Algorithm, Journal of Software. 11(2005)104-112.
[13] Turney P. Cost-sensitive classification, Empirical evaluation of a hybrid genetic decision tree induction algorithm, Journal of Artificial Intelligence Research (JAIR). 2(1995) 369-409.
[14] Susan Lomax, Sunil Vadera. A Survey of Cost-Sensitive Decision Tree Induction Algorithms, ACM Compute Surv,45, 2, 35 page (2013).