© 2018, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal | Page 1273
Mining Frequent itemset on temporal data
Miss. Argade Dipali Navnath
1, Prof. A. N. Nawathe
21Student, Dept of computer engineering, Amrutvahini college of engineering, Sangmner, Maharastra, India 2Professor, Dept. of computer engineering, Amrutvahini college of engineering, Sangmner, Maharastra, India
---***---Abstract -
In This paper we’re looking to increase theefficiencyof the frequent itemsets mining primarily based on temporalrecords. As styles will have in the both all or can be in some ofthe durations, we recommend a technique to limit time periods, that is called mining if frequent itemset by using time cubes.Our goal is growing an green algorithm for this mining with theaid of the use of the widely known FP growth algorithm a set ofrules. Temporal records have time associated records that affectsthe records mining. Existing strategies for purpose of findingfrequent itemsets do not forget that the datasets are static orconstant and the rules are applicable across the entire dataset.But, this is not the manifest while data is temporal. We proposea new density threshold to clear up the overestimating period of time periods and additionally find valid styles.
Key Words:Data mining, frequent itemset, frequent pattern, temporal data
1. INTRODUCTION
1.1 Data mining
Data mining is an method of extraction of records or facts from huge of data. The vital packages of facts mining is an analysis of transactional records. Database which starts off evolved from transactions in a high-quality marketplace, bank, branch shops and, etc., are all associated with time. These transactions are known as temporal database that is database that include time related statistics. There is important extension for frequent sample mining is we can add a temporal measurement. For instance, milk and eggs can be ordered together in eighty five percentages from all transactions among 7:30 and10:30 a.m. While their assist element in all database is 15 percent. In reality, thrilling styles are also related to particular time period .subsequently, the time at some stage in which they can be used is most crucial. The principal trouble is to locate valid time intervals at which the common patterns hold and invention of possible periodicities that patterns encompass. We are trying to develop an efficient algorithm to mine common patterns and their related time interval from the transactional database. We firstly present time cubes, a new method to do not forget time hierarchies inside the mining manner. Then a set of rules is designed based totally on the two thresholds, guide, and density as a main threshold. Frequent itemsets that are found and then those with neighboring timedurations are mixed.
1.2 Temporal Data
A temporal database uses statistics associated with time intervals. It has temporal statistics types and stores the information associated with past, gift and future time. The temporal database has two important attributes.
1) Valid Time 2)Transaction time.
The temporal data consist of valid time and transaction time. These two attributes are collected together to form bitemporal records. The valid time is an the time period at which case is true in actual time. Transaction time is an time period at which the reality saved in the database was recognized. Bi-temporal facts is the mixture of both Valid and Transaction Time. It may have time lines other than Valid Time and Transaction Time,like Decision Time, within the database. In this the database is known as as multi-temporal database because it opposed to a bi-multi-temporal database. But, this technique introduces greater complexities which includes handling the validity of keys.
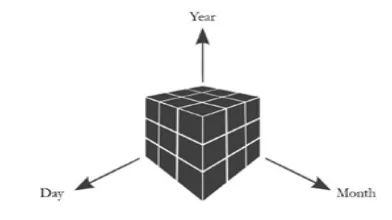
1.3 Time Cube
To locate valid time intervals at some point of which common patterns can preserve and to discover the viable periodicities that styles can encompass. For that purpose we implement to increase an efficient set of rules to mine common patterns and the associated time interval from transactional dataset. We firstly use the time cubes, a new approach to recollect time levels in the mining strategy. Then the new algorithm is designed for thresholds, help, and density as a specific threshold.The frequent itemsets are based and those with their neighboring time durations are combined.
[image:1.595.332.528.613.723.2]
© 2018, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal | Page 1274 2. Literature Survey
Association rule mining become firstly proposed through [2]. It has the two phases, finding itemsets which are common and then producing association policies. The important and tedious piece of the set of rules is coming across common itemsets and then generating affiliation regulations is direct. Thusly, in our writing survey, we recall association rules the same as common itemset mining. Many examinations were done to expand affiliation regulations in various approaches. Classification association rule mining [10] , area-primarily base on affiliation rule [13] , fuzzy association rule [12], The generalized affiliation rule [13] are some of research regions on this subject. From those expansions, the time function of the transactions has been attracted several researchers to find frequent itemsets after some time. There are a few kind of tremendous styles, whilst time trait is taken into consideration. We plan to audit the most applicable researches to our Examination. The trouble of finding affiliation rule that is to display standard cyclic range after some time was firstly proposed by using Ozden etal.Then two new algorithms had been exhibited, consecutive algorithm moreover, interleaved set of rules, to discover hourly, each day, week after week, and so forth., patterns. Some elimination strategies likewise used for progress the overall performance of algorithms. It must be noticed that by means of their strategy, every periodic rule holds in each cycle with no any exception. In any case, all matters taken into consideration, patterns arent best. Along those strains, Han et al. Proposed incomplete periodic example mining in temporary database. Founded association policies imply working in some however all no longer all focuses in time. The work to find out purchaser characterized temporal patterns in affiliation rules. Using calendar variable based math became proposed for explaining styles which are interesting. But it requires clients in advance facts to symbolize calendar articulations. In [7], Ale and Rossi proposed a system for finding regulations over a selected time of time that is smaller than the complete database. The lifestyles time of each aspect changed into applied to represent time interims. The idea of worldly bolster was added out of the blue and algorithm from the sooner was changed to comprise time. Li et al. [5],proposed a system to find association rule that holds in all or a in some while interims. Rather than utilizing cyclic or consumer given calendar algebraic articulations, calendar schema is utilized to restriction the large time interims. Since matters have exceptional presentation intervals, algorithm revolutionary-partition-miner algorithm became proposed for finding out patterns in the databases. The primary thought of PPM is to first partition the database in mild of show times of factors and afterwards steadily collect the occurrence of every candidate itemset primarily based on the intrinsic partitioning properties. Its important that presentation time of things in and is the same as life time of things in [6]. The investigation of and was additionally expanded , considering the importance of time interims. Utilizing a similar concept explained in [6] and, algorithm segmented progressive filter was introduced in
this for first portion database in subdatabases in such a way that things in every subdatabase can have either beginning time or completion time. At that point, for each subdatabase, SPF stepwise filters candidate itemsets with cumulative filtering edges forward or the backward in time. Lee whats more, Lee [28] additionally utilized calendar polynomial math to find association rules. Because of individual has a tendency to be uncertain, fuzzy set hypothesis incorporated to help the constructions of the wanted time interims. This can be like crafted, yet it can more adaptable just because of fuzzy sets and fuzzy administrators. Results demonstrate that its performance beat from earlier techniques. Investigate the past examinations to cure disadvantage of the algorithms. The TWAIN Algorithm was displayed to discover association rules that are truant when the entire scope of database is assessed inside and out. Mahanta et al. [8] displayed a way which is prepared to mine various styles of periodic patterns which could exist in a brief dataset. The portion is not needed to specify intervals earlier. The set operations known as set superim-position turned into applied for putting away intervals related to aspect units. Adhikari et al. Stronger the investigation of [8] by providing information shape for placing away and overseeing patterns. They additionally brought some changes to the algorithm to decorate the performance. Proposed an green set of rules for coming across fuzzy cyclic association regulations. They researched that problem of coming across standard time interims, i.E., the periodicity. To conquer the problems of finding precise time intervening time, fuzzy calendar became proposed. Their technique scan the database at maximum twotimes to find out association rules and related eras. Applied genetic set of rules to find out worldly association rules out of the blue. Genetic set of rules became applied to on the equal time search the rule of thumb area and worldly area.
4. FP-FROWTH ALGORITHM
Here we are using Fp-growth algorithm FP tree algorithm, which use to identify frequent patterns in the area of Data Mining. I'm sure! After this tutorial you can draw a FP tree. This algorithm consists of four steps,
4.1 Calculate Minimum support
By applying following formula we are calculating the minimum support,
Support(X)= N(X)cube /(N) cube
Where |N(X, Y )Cube| is the number of transactions which contains both X and Y in that time interval.
© 2018, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal | Page 1275 proposed to solve these problems, The density of a time
interval is calculated as follows:
A=N/NBTc
Density = α × A (4)
[image:3.595.316.552.171.317.2]where N is the total number of records or transactions, NBTC is the number of basic time cubes, therefore, A is the averagetransaction per BTC.
Table -1: Sample database after minimum support 4.2 Find frequency of occurrences
Now time to find the frequency of occurrence of each item in the Database table. For example, item A occurs in row 1,row 2,row 3,row 4 and row 7. Totally 5 times occurs in the Database table. You can see the counted frequency of occurrence of each item in Table 2.
Item Frequency Priority
A 5 3
B 6 1
C 3 5
D 6 2
E 4 4
Table -2: Sample database after minimum support
4.3 Prioritize the items
In Table-2 we can see the priority of each item according to its frequency of occurrence. Item B got the highest priority (1) due to its highest number of occurrences. At the same time you have opportunity to drop the items which not fulfill the minimum support requirement. For instance, if Database contains F which has frequency 1, then you can drop it. Some people display the frequent items using list instead of table. The frequent item list for the above table will be B: 6, D: 6, A: 5, E: 4, C: 3.
4.4 Order the items according to priority
[image:3.595.54.268.201.348.2]As you see in the Table 3 new column added to the Table 1. In the Ordered Items column all the items are queued according to its priority, which mentioned in the in Table 2. For example, in the case of ordering row 1, the highest priority item is B and after that D, A and E respectively.
Table-3: New version of table 1
5: ALGORITHM
Algorithm 5.1: Algorithm for mining frequent itemsets with time cubes (TCs).
Input: Database (D), Min sup, Min den, Basic Time
Cube (BTC)
Output: Set of frequent itemsets
1) Large1-gen (D, BTC) 2) For (K = 2, LK -1 = ∅, K + +) 3) CK = Candidate - gen(LK - 1) 4) For all candidates CT C ∈ CK
5) Count Sup(CT C ) 6) End for {4}
7) For all time hierarchies 8) LK = {CT C ∈ CK |sup(CT C ) ≥ min sup ∧ P(TC) ≥ min den}
9) End for {7}
10) End for {2}
11) Output = output ∪ LT C
Algorithm 5.2: Algorithm for mining Large1 itemsets. Input: Database (D), Min sup, Min den, Basic Time Cube (BTC)
Output: L1
1) D = ∪DB T C s
2) L1 = ∅
3) For all items X ∈ I
4) For all DB T C s ∈ D
5) Count support of X 6) End for
7) TC = ∅
[image:3.595.44.242.471.612.2]© 2018, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal | Page 1276 10) TC = TC ∪ BTC
11) Else
12) L1 = L1 + XT C
13) TC = ∅ 14) End if {9}
15) End for {8}
16) End for{3}
17) Output = L
Algorithm 5.3: Algorithm for candidate generation
Input: LK -1 Output: CK
1) CK = ∅
2) For all pairs of Li, Lj ∈ LK -1 3) Cand = Li Lj
4) If|Cand| = K
5) Put Cand into CK
6) End if 7) End for{3}
8) Output = CK
6. SYSTEM ANALYSIS
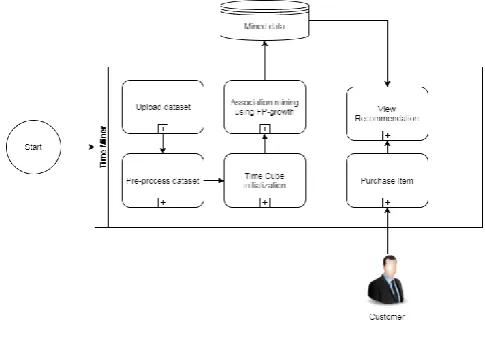
The below figure shows the actual flow of our system,
Fig.1:System flow
A. Step 1: Upload dataset
In this step we are going to upload the dataset to the system which contains the time stamping database.
B. Step 2:Pre-process Dataset
In this step we are performing the preprocessing task on the dataset that is data cleaning. The preprocessing task is done to reduce the time required for the execution.
C. Step 3: Time cube initialization
In this step the time cube formation is performed. That means we decide on which basis we have to perform the analysis. It can be Weekly, Monthly, Yearly basis.
D. Step 4: Association mining using FP-Growth
In this step we perform a association mining on the data. For that purpose we use the FP-Growth algorithm.
E. Step 5: View Recommendation
After applying association mining the user get the mined data. Now user can view the recommendation and also can purchase the item according to recommendation.
7. RESULT ANALYSIS
Criteria Existing system Proposed system
Data Type Static Dynamic
Algorithm Apriori Fp-Grwth
Execution
Time More time less time
Storage
structure Array based Tree-based
Memory
Utilization Large Memory Large memory
Database
size Sparse/dense Large/medium dataset Operational
[image:4.595.39.282.378.551.2]modes Analytical Recommendation
Table 4: Result analysis.
CONCLUSION
© 2018, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal | Page 1277 ACKNOWLEDGEMENT
Any strive at any degree can’t be satisfactorily completed without support and steering of learned people. I would love to take this possibility to increase my deep felt gratitude to everybody who’ve been there at each step for my help. First and essential, I would like to express my large gratitude to Prof. A. N. Nawathe for her constant guide and motivation that has advocated me to come up with this Paper. I could also like to thank Prof. S. K. Sonkar for continuously motivating me and for giving me a danger to construct this sort of creative work.I am extremely thankful to all of us for presenting country of the art centers I take this possibility to thank all professors of branch for providing the beneficial guidance and timely encouragement which helped me to finish this work more expectantly.I am also very grateful to circle of relatives, friend and mates who’ve rendered their entire hearted help always for the successful of completion of my work .
REFERENCES
[1] Mazaher Ghorbani and Masoud Abessi A New Methodology for Mining FrequentItemsets on Temporal Data, 0018-9391 © 2017 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission
[2] J. Han, M. Kamber, and J. Pei,Data Mining: Concepts and Techniques, Amsterdam, The Netherlands: Elsevier, 2011.
[3] R. Agrawal, T. Imieli nski, and A. Swami, Mining association rules between sets of items in large databases ,ACM SIGMOD Rec., vol. 22, no. 2, pp. 207216, 1993.
[4] T. Mitsa,Temporal Data Mining, Boca Raton, FL, USA: CRC Press, 2010.
[5] Y. Li, P. Ning, X. S. Wang, and S. Jajodia,,Discovering calendarbased temporal association rules, Data Knowl. Eng., vol. 44, no.2, pp. 193218, 2003.
[6] R. Agrawal and R. Srikant,Mining sequential patterns, in Proc. IEEE 11th Int. Conf. Data Eng., 1995, pp. 314.
[7] J. M. Ale and G. H. Rossi, An approach to discovering temporal association rules, in Proc. ACM Symp. Appl.
Comput.-vol. 1, 2000, pp. 294300.
[8] Y. Xiao, Y. Tian, and Q. Zhao,Optimizing frequent time-window selection for association rules mining in a temporal database using a variable neighbourhood search, Comput. Oper. Res., vol. 52, pp. 241250, 2014.
[9] A. K. Mahanta, F. A. Mazarbhuiya, and H. K. Baruah,Finding calendarbased periodic patterns, Pattern Recognit. Lett., vol. 29, no. 9, pp. 1274 1284, 2008.
[10] B. Liu,W. Hsu, and Y. Ma,Integrating classification and association rule mining, in Proc. 4th Int. Conf. Knowl. Discovery Data Mining, 1998, pp. 8086.
[11] L. T. Nguyen, B.Vo, T.-P. Hong, and H. C. Thanh,,Car-miner: An efficient algorithm for mining class-association rules, Expert Syst. Appl., vol. 40, no. 6, pp. 23052311, 2013.
[12] Y.-L. Chen and C.-H. Weng, Mining fuzzy association rules from questionnaire
[13] J. Han and Y. Fu, Discovery of multiple-level association rules from large databases, in Proc. 21st Int. Conf. Very Large Data Bases, 1995, pp. 420431.
[14] R. Srikant and R. Agrawal, Mining generalized association rules, in Proc. 21st Int. Conf. Very Large Data Bases, 1995, pp. 407 19.