International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 3, March 2014)
534
A Survey on Different Classifier in Speech Recognition
Techniques.
Shubhangi S. Jarande
1, Prof. Surendra Waghmare
2G.H. Raisoni College of Engineering and Management, Wagholi, Pune, India
Abstract—Speech Emotion Recognition is one of the most recent topic in the Human Computer Interaction field. Now a day’s natural communication plays an important role in our daily life, so in natural communication interface between human and computer, a computer have become integral part of our lives. For improving the interaction between human and computer currently work is going on.To accomplish this goal, a computer would have to be capable of differentiate its present situation and act in response differently depending on that observation. Some part of this process involves understanding a user’s emotional state.[2] To make human computer interaction more natural, computer should be able to recognize the emotional states same as that human does. For getting efficient system. The System depends on classifiers and type of feature extracted which are used for detection of Emotion. Most of the system’s basic objective is to detect the emotions like anger, happy, neutral, sadness. Selection of a good database is also important task.While classifying Emotional states MFCC and Energy is used for feature extraction .
Keywords—Emotion Recognition, Gaussian Mixture Model(GMM), Hidden Markov Model(HMM), Support Vector Machines(SVM), Probablistic Neural Network(PNN).
I. INTRODUCTION
Speech is a complex signal which contains information of speaker, messages, human voice, recordings etc. Speech recognition is the area which increase attraction within the Engineering field of speech signal processing and pattern recognition in recent year. By time varring vocal tract system speech is produced, which is excited by a time varying excitation source. On the other side Emotion considered as a mental state that arising immediately rather than mindful efforts. A different types of Emotion are present in speech. But, the problem is to cover the gap in between information that records by a microphone ,irrespective of emotions and to model the specific association. Those gap can be removed by narrowing down various emotions in few, like Happiness, Anger, Sadness, fear, Neutral. Emotional speech recognition system identifies emotional state of human being as well as physical state of human being from voice.
Emotion recognition system have focused in
Engineering field due to the various application like frustration detection, Amusement, etc. Due to various application emotion recognition system demanded more in Engineering field. One of the important task in speech recognition in Speech recognition system is a feature vector.From group of four feature vectors , its very difficult task to chose feature vector from them. Four groups are qualitative, Continious, Teager energy operation, spectral.
A speech is classified using pattern different methodologies like SVM, PNN, ANN, HMM, GMM, and lots of classifiers. Database creation is also very important for proper recognition of speech. Standard database also available . But, Our priority is getting efficient Emotion recognition system, we create our own database.
II. SPEECH EMOTION RECOGNITION SYSTEM
The Emotion recognition system’s block diagram is illustrated in Fig. 1. The basic block diagram contains five blocks which are Emotional Speech Input, Feature Extraction, Feature Selection, Classifier, Emotional Speech Output.
Figure.1: Basic Block Diagram of Emotion Recognition
Emotion recognition system identifies emotional state from voice or speech of human being . For recognizing the emotion required the in [9] depth analysis, for that first extracted the features from speech signal after that using classifier method for identify emotional state of Human being.
III. DIFFERENCE CLASSIFIER SELECTION
Classifier Selection
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 3, March 2014)
535
Classifers performs differently like some classifiers are efficient with certain type of class distribution and some classifiers deals with irrelevant features ,gives better results. Most of the advanced Researchers achieves recognition rates from 56% - 96%, whereas Human could hardly reach recognition rates to 60%.
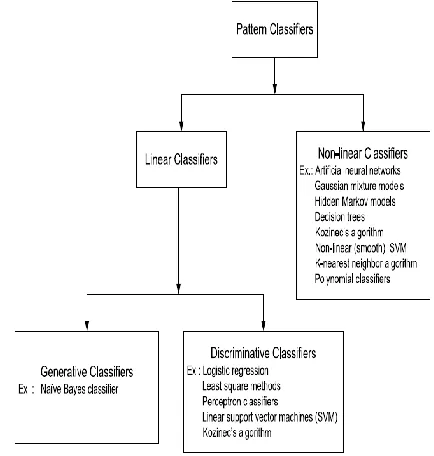
Several pattern classifiers are explored for developing speech systems like, emotion classification, speech recognition, speaker verification, speaker recognition and so on. Mainly classifiers are divided in two parts Linear classifier, Non-Linear classifier
Figure 2. Types of classifiers used for speech emotion recognition
In the above figure.2 Some nonlinear classifiers are present. From those nonlinear classifier some classifiers I used for doing Survey.
A. Gaussian Mixture Model (GMM)
Gaussian Mixture Model is a pattern classifier which is used to build a Emotion recognition systems using extracted features. GMM is a matured method for density estimation and clustering. By using Multivariate Gaussian mixture [8] density they model the probability density function of observed data points. From the inputs , GMM
refines weights through expectation-maximization
algorithm. If model developed then apply conditional probabilities which can computes for test patterns.
[image:2.612.330.557.134.302.2]
Figure 3. Gaussian Mixture Model
According to [5] Gaussian mixture Model is parameterized probability density function, parameterized means covariance matrices, vectors and mixture weights from all components densities. This GMM allow set of input training vectors from database. In this GMM study 5 different emotional states and then features were extracted from the input waveforms. This extracted features added to
the database. By using Iteraction Expectation
[image:2.612.61.278.264.492.2]Maximization(EM) algorithm it estimates the probability of multivariate densities. Here some emotions misclassified using Confusion matrix. [5] Overall accuracy of GMM is 73.86%. Therefore, the Results of five emotional state are as follows.
Table I
Recognition Rate Of Emotions Using Gmm [5]
Emotion
State Happy Anger Neutral Sad Supprise
Happy 74.37 0 0 15.26 16.57
Anger 12.45 78.27 0 0 0
Neutral 0 0 26.89 26.89 0
Sad 0 0 75.26 75.26 9.56
Supprise 18.29 11.69 0 0 68.39
[image:2.612.328.562.487.589.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 3, March 2014)
536
[image:3.612.338.555.227.345.2]Only four emotions considered namely anger, happy, sad, neutral. Ones Model is completed, conditional probabilities can be computed for test patterns. Overall performance is observed 53-60% using GMM. The performance may be improved by using combined features. The Results of Emotion Classification performance is as shown below:
Table II
Emotion Classification Performance [8]
Emotion
State Anger Happy Neutral Sad
Anger 54 11 10 26
Happy 0 67 22 11
Neutral 6 5 52 37
Sad 20 15 4 61
B. Hidden Markov Model (HMM)
Hidden Markov Model is widely used in Speech Recognition System. Hidden Markov Model is also Known as First order markov chain whose states are hidden from the observer [5]. By using HMM classifier the used database creates samples that is Speech Samples are provide to HMM. Extracted features from input added to database. For calculating the rate of HMM the transition and Emission Matrix has been made which generate random sequence and Emission. By using Viterbi algorithm estimate state sequences probabilities. The results of HMM using five emotion state are as shown below. The overall accuracy of HMM is 72.65%.
Table III
Recognition Rate Of Emotion Using HMM [5]
Emotion
State Happy Angry Neutral Sad Surprise
Happy 74.14 0 0 12.19 15.57
Angry 16.29 82.49 0 0 0
Neutral 0 0 74 26 0
Sad 0 0 27.47 69.68 0
Surprise 10.28 20.32 0 0 67.39
According to Tin Lay New, Say Wei Popular features employed are statistics of fundamental frequency , Energy Contour, Duration of Silence And voice quality [14]. When more than two categories of emotions are to used then system degrades substantially.
[image:3.612.41.275.233.342.2]This method makes used of short time log frequency power coefficient (LFPC) to represent speech. Six different types of emotions recognized. The performance of the LFPC feature parameter is compared with that of Linear prediction cepstral coefficient (LPCC) & MFCC feature parameter which is commonly used in speech recognition systems .
Figure 4. Block diagram of the proposed system using HMM
The proposed Emotion Recognition System is as shown in Figure 4 .The speech signal is coded with 16 bits PCM and sampled at 22.05khz.The speech samples are segmented into frames.The fundamental frequency of Speech samples ranges from 100 to 200 Hz.Size of the window is 16ms which covers approximately two periods of fundamental frequency.Total number of frame is N. These frames processed depending on length of utterance. Feature vector is based on normalized LFPC for each frame [14]. In the training period , a codebook is construct by using feature vectors of all utterance. HMM model is developed for six Emotions seperatly.For reduced set of emotions classification used combined Emotion.Vector Quantization is used to convert feature vector to single code that represent the match of codebook entry. Then codes of each utterance is submitted to the HMM which clearly seen in the above block diagram. The Accuracy of proposed method is 78.1%
C. Probabilistic Neural Network(PNN)
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 3, March 2014)
[image:4.612.64.271.131.346.2]537
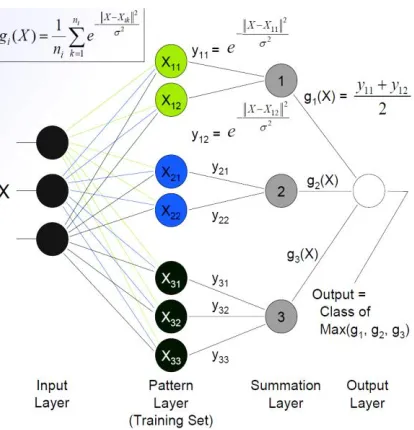
Figure 5: Probabilistic neural network architecture
They proposed a network tested on Persian one digit number datasheet and produced lower recognition rate compares to other classifier. MFCC features gives better performance compares to perceptual linear predictive [12]. They proposed method used Radial basis probabilistic neural network model which is developed from Radial basis Neural network. Because of common characteristics the signal is concurrently feed forwarded from input to output layer with absence of feedback connection. That helps to decrease disadvantages of these two models in some extent.
When input is given, first layer computes distance from training input vector and input vector and the results shows that how close input vector is to a training vector. Second layer sums these input and forms net output and last competive transfer function on the output of second layer takes the maximize of these probabilities and produce 0 for other class and 1 for that class.
They proposed segmentation system relay on the neural network to formulate the decision to which speaker, examined segment belong [13]. The system has two phase the training phase and testing or segmentation phase. The speech samples must be pre-processed in in both the phases. The Pre-processing includes framing,windowing and feature extraction. This is achieved in the stages which is described in the following subsection. Figure shows the phases of system and the stages of each phase.
Figure 6: The phases and stages of the proposed segmentation system.
[image:4.612.334.549.138.327.2]The proposed system use TIMIT database for evaluation purpose. The Emotion Recognition System examined in three different categories. In that each category speaker of different sex participating and best performance with a minimum average percentage of false segmentation that is 18.09% [11]. To improve that Sliding window used twice for moving along all the output of neural network. This helps a lot for improvement that is PFS reduce approximately 66% for different sex and 52% for same sex. Window size first time 3 and second time 5 gives best result.
Table IV
The Results For The Segmentation System [11]
Category Max PFS(%)
Min PFS(%)
Average PFS(5%)
Male-Male 31.8309 11.4971 22.8088
Female-Female 31.0738 16.6656 23.7910
Male-Female 24.105 12.0422 18.0936
D. Support Vector Machine (SVM)
[image:4.612.326.559.489.606.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 3, March 2014)
538
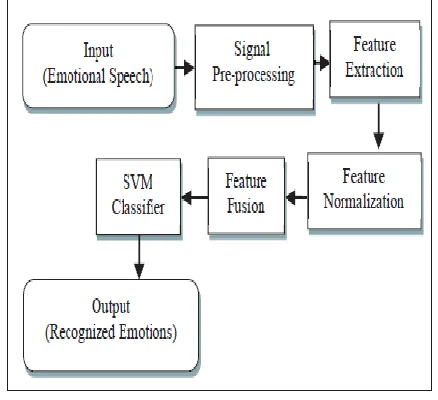
Feature normalization means by using statistical method the statistical features are calculated for each and every window of a specified number of frames. By combining features a different training model is developed. At last Support Vector Machine is use as Emotion Classifier for classification purpose.
Figure 7. Speech Emotion Recognition System.
Auther attempts to recognize the speech & classify the speech from three language database [3]. These three database are Berline, Japan & Thai. This proposed method provides highest accuracy by using combined features. The Results are as shown in the below:
Table V
Confusion Matrix For The Feature Set F0 + Energy+ Mfcc Of Japan Emotion Database.[3]
Emotio ns
An gr y
Bor ed
Disg ust
Fe ar
Hap py
Na tur al
Sad
Angry 10
0 0 0 0 0 0 0
Bored 0 95 0 0 0 5 0
Disgust 0 0 85 0 10 5 0
Fear 0 0 0 95 5 0 0
Happy 0 5 5 5 90 0 0
Natural 0 0 5 0 0 90 0
[image:5.612.58.277.210.410.2]Sad 0 0 0 0 0 0 100
Table VI
Confusion Matrix For The Feature Set F0 + Energy+ Mfcc Of Thai Emotion Database [3]
Emotion s
Angr y
Disgus t
Fea r
Happ y
Sa d
Surprris e
Angry 96.5 3.5 0 0 0 0
Disgust 3.5 95.5 0 0 1 0
Fear 0.5 0 98.5 0 0.5 0.5
Happy 0.5 0 0 99.5 0 0
Sad 0 1.5 0 0 98 0.5
Surprris
e 0 0 0 0 0 100
Support vector machine is an effectual approach for pattern recognition. The basic concept of SVM is here presented. In SVM approach, the basic aim is to determine hyperplane or decision boundry [7]. The hyperplane’s objective is to separate two classes of input data points. This Hyperplane is shown in figure. Where margine is M, which is the distance from the Hyperplane to the nearest point for both classes of data points.The data points separated two types are Linearly seperable and non-linearly seperable.SVM classifier placed the decision boundry by using maximal margine among all possible hyper planes.
Figure 8 :Separation of two classes by SVM
[image:5.612.337.539.443.608.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 3, March 2014)
539
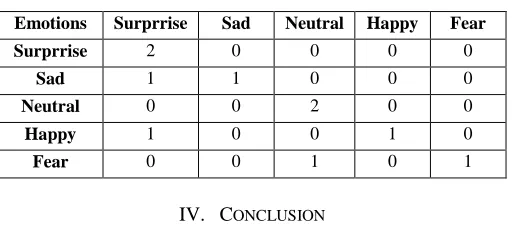
[image:6.612.42.299.183.296.2]Our Own Results of Support Vector Machine is 70%. Confusion Matrix for the feature set Energy +MFCC is
Table VII
Confusion Matrix For The Feature Set Energy +MFCC
Emotions Surprrise Sad Neutral Happy Fear
Surprrise 2 0 0 0 0
Sad 1 1 0 0 0
Neutral 0 0 2 0 0
Happy 1 0 0 1 0
Fear 0 0 1 0 1
IV. CONCLUSION
In this paper, Recent work of Speech Emotion Recognition System is discussed. Used of different classifier are reviews. Appropriate selection of classifier and feature extraction method used from the emotional speech . By using mix features gives better results. Future work is to increase accuracy of Speech recognition System using Hybrid classifier Technique.
REFERENCES
[1] Yongjin Wang and Ling Gaun, “An Investigation Of Speech Based Human Emotion Recognition”,2014 IEEE 6th Workshop on
Multimedia Signal Processing.
[2] Dipti D. Joshi, Prof. M.B. Zalte,“Speech Emotion Recognition:A Review”,IOSR International Joural Of Electronics and Communication Engineering(IOSR-JECE), ISSN 2278-2834,ISBN:2278-8735,Volume 4, Issue4,PP 34-37.(Jan-Feb. 2013) [3] Thapanee Seehapoch, Sartra Wongthanavasu ,“Speech Emotion
Recognition Using Support Vector Machine ”,978-1-4673-4853-9/13, 2013 IEEE.
[4] A Milton, S.Sharmy Roy, S.Tamil Selvi PhD, “ SVM Scheme for Speech Emotion Recognition using MFCC Feature”, International Journal of computer Application (0975-8887),volume 69-no.9,May 2013
[5] Akshay S. Utane, Dr.S.L.Nalbalwar,“Emotion Recognition Through Speech Gaussian Mixture Model And Hidden Markov Model”, ISSN:2277 128X, Volume 3, Issue4, April 2013.
[6] Shashidhar G. Koolagudi, K.Sreenivasa Rao, “ Emotion Recognition from Speech: a review”,Int J Speech Thenol(2012).
[7] Bhoomika Panda, Debananda Padhi, Kshamamayee Dash,Prof.Sanghamitra Mohanty “Use of SVM Classifier & MFCC in Speech Emotion Recognition System”, ISSN Volume 2, Issue 3, March 2012.
[8] Nitin Thapliyal, Gargi Amoli,“Speech based Emotion Recognition with Gaussian Mixture Model”, ISSN:2278-1323, International Journal of advance Research in Computer Engineering & technology, Volume 1, Issue5, July 2012.
[9] Prof. Sujata Pathak, Prof . Arun Kulkarni, “Recognizing emotions from Speech”,978-1-4244-8679-3/11/$26.00, 2011 IEEE.
[10] M.E. Ayadi, M. S. Kamel, F. Karray, “ Survey on Speech Emotion Recognition:Features, Classification Schemes, And Databases”, Pattern Recognition 44, PP.572-587,2011.
[11] Jia Rong, Gang Li, Yi-Ping Phoebe Chen,“Acoustic feature selection for automatic emotion recognition from speech”, Elsevier, Information Processing and Manegement volume 45(2009). [12] Raymond Low and Roberto Togneri, “ Speech Recognition Using
Probabilistics Neural Network”,Department of Electrical and Electronics Engineering, University Of western Australia.
[13] Dr.Ahmed Maamoon Alkababji, “Segmentation of conversational Speech Using Probabilistic Neural Network”, Computer Engineering Department,University Of Mosul,Iraq,Volume 18,No.3.
![Table II Emotion Classification Performance [8]](https://thumb-us.123doks.com/thumbv2/123dok_us/8703334.880044/3.612.338.555.227.345/table-ii-emotion-classification-performance.webp)