Volume 2011, Article ID 845398,13pages doi:10.1155/2011/845398
Research Article
Uniqueness of the Level Two Bayesian Network
Representing a Probability Distribution
Linda Smail
New York Institute of Technology, College of Arts and Sciences, P.O. Box 840878, Amman 11184, Jordan
Correspondence should be addressed to Linda Smail,[email protected]
Received 29 June 2010; Accepted 8 November 2010
Academic Editor: Hana Sulieman
Copyrightq2011 Linda Smail. This is an open access article distributed under the Creative
Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Bayesian Networks are graphic probabilistic models through which we can acquire, capitalize on, and exploit knowledge. they are becoming an important tool for research and applications in artificial intelligence and many other fields in the last decade. This paper presents Bayesian networks and discusses the inference problem in such models. It proposes a statement of the problem and the proposed method to compute probability distributions. It also uses D-separation for simplifying the computation of probabilities in Bayesian networks. Given a Bayesian network
over a familyI of random variables, this paper presents a result on the computation of the
probability distribution of a subsetS of I using separately a computation algorithm and
D-separation properties. It also shows the uniqueness of the obtained result.
1. Introduction
Bayesian networks are graphical models for probabilistic relationships among a set of variables. They have been used in many fields due to their simplicity and soundness. They are used to model, represent, and explain a domain, and they allow us to update our beliefs about some variables when some other variables are observed, which is known as inference in Bayesian networks.
Given a Bayesian network1relative to the setXI Xii∈I of random variables, we are interested in computing the joint probability distribution of a nonempty subsetScalled targetofI.
Consequently there is a need to order and segment, if possible, these computations into several computations that are less intensive and more accessible to a parallel treatment. These segmentations are related to the graphic properties of the Bayesian networks.
This paper describes the computation of PS using a specific order described by a proposed algorithm, and the segmentations ofPS.
We consider discrete random variables, but the results presented here can be generalized to continuous random variables with the density ofXirelative to a finite measure μithe summations will be replaced by integrations relative to those measuresμi.
The paper is organized as follows.Section 2introduces Bayesian networks and Level two Bayesian networks. We, then, present in Section 3 the inference problem in Bayesian networks and the proposed computation algorithm. Section 4 outlines D-Separation in Bayesian networks and describes graphical partitions that will allow the segmentations of the computations of probability distributions.Section 5proves the uniqueness of the results obtained in Sections3and4.
2. Bayesian Networks and level two Bayesian networks
2.1. Bayesian Networks
A Bayesian networkBNis a family of random variablesXii∈Isuch that:
ithe setIis finite and endowed with a structure of a directed acyclic graphDAG, G, where, for eachi:
apiis the set of parents ofipi {j;j, i∈G}
beiis the set of children ofiei {j;i, j∈G}
cdiis the set of descendants ofidi {k;∃0, . . . , n0 i, n k, ∀s∈
{1, . . . , n}s−1, s∈G};
iifor eachi,Xiis independent ofXjj∈I−pi∪diconditional onXpifor more details
see, e.g.,1–5.
We know that this is equivalent to the equality
PIxI
i∈I
Pi/pixi/xpi, 2.1
where PI is the joint probability distribution of XI Xii∈I and Pi/pi is the probability
distribution ofXiconditional onXpi Xjj∈pi.
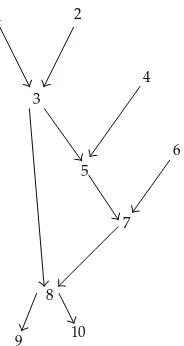
The joint probability distribution corresponding to the BN inFigure 1can be written as
PIx1, x2, x3, x4, x5, x6, x7, x8, x9, x10
P1x1P2x2P3/1,2x3/x1, x2P4x4P6x6
×P5/3,4x5/x3, x4P7/5,6x7/x5, x6P8/3,7x8/x3, x7P9/8x9/x8P10/8x10/x8.
1 2
3
4
5
6
7
8
[image:3.600.256.348.95.268.2]9 10
Figure 1: An example of a Bayesian network.
1
2
5 6
3, 4
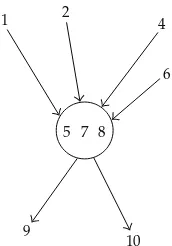
Figure 2: Level two Bayesian network.
2.2. level two Bayesian networks
We consider the probability distributionPI of a familyXii∈I of random variables in a finite spaceΩI i∈IΩi. LetIbe a partition ofIand let us consider a DAGGonI.
We say that there is a link fromJtoJwhereJandJare atoms of the partitionI ifJ, J∈ G. IfJ∈ I, we denote bypJthe set of parents ofJ, that is, the set ofJsuch that
J, J∈ G.
The probability PI is defined by the Level Two Bayesian network BN2, on I,
I,G,PJ/pJJ∈I, if for each J ∈ I, we have the conditional probability PJ/pJ, or the probability ofXJ conditioned by XpJ which, ifpJ ∅, is the marginal probabilityPJ,
so that
PIxI
J∈I
[image:3.600.257.343.319.444.2]The probability distributionPIassociated to the BN of level 2 inFigure 2can be written as
PIxI P1x1P2/1x2/x1P3,4/2x3, x4/x2P5/3,4x5/x3, X4P6/1,3,4x6/x1, x3, x4. 2.4
2.3. Close Descendants
We define the set of close descendants of a node J denoted cdJas the set of vertices containing the children of J and the vertices located on a path between J and one of its children.
In the example belowFigure 2, we have
cd1 {2,{3,4},6}{2,3,4,6}. 2.5
2.4. Initial Subset
For each subsetS, we denote bySthe initial subset defined byS, that is, the set consisting of Sitself and theSsuch that there is a path inGfromStoS.
We can identify this subset with the union of allSsuch thatSis an ancestor ofS For eachS, the Initial subsetSis a BN, in other words the restriction of a BN to an initial subset is a BN
PS
s∈S
Ps/ps. 2.6
In the example aboveFigure 2, we have
{6}{1,2,{3,4}}{1,2,3,4}. 2.7
3. Inference in Bayesian Networks
Consider the BN inFigure 1.
Suppose we are interested in computing the distribution ofSI− {3}, in other words all variables are in the targetSexceptX3.
By marginalizing out the variablesX3 from the joint probability distributionPI, the target distributionPScan be written as
PSx1, x2, x4, x5, x6, x7, x8, x9, x10
P1x1P2x2P4x4P6x6P7/5,6x7/x5, x6P9/8x9/x8
×P10/8x10/x8
x3
P3/1,2x3/x1, x2P5/3,4x5/x3, x4P8/3,7x8/x3, x7
P1x1P2x2P4x4P6x6P7/5,6x7/x5, x6P9/8x9/x8P10/8x10/x8αx1, x2, x4, x5, x7.
1 2 4
5
6
7 8
9
[image:5.600.257.343.96.219.2]10
Figure 3: Level two Bayesian network onS.
α is a function that depends on X1, X2, X4, X5, and X7 but has nothing to do with
P1,2,4,5,7joint probability distribution ofX1, X2, X4, X5, X7. By doing this we loose the structure of the BN.
If we do the marginalization as follow we obtainaccording to Bayes’ theorem:
PSx1, x2, x4, x5, x6, x7, X8, X9, X10
P1x1P2x2P4x4P6x6P9/8x9/x8P10/8x10/x8
×
x3
P3/1,2x3/x1, x2P5/3,4x5/x3, x4P7/5,6x7/x5, x6P8/3,7x8/x3, x7
P1x1P2x2P4x4P6x6P9/8x9/x8P10/8x10/x8P5,7,8/1,2,4,6x5, x7, x8/x1, x2, x4, x6.
3.2
In other wordsαx1, x2, x4, x5, x7P7/5,6x7/x5, x6 P5,7,8/1,2,4,6x5, x7, x8/x1, x2, x4, x6. Which providesSwith a structure of a level two Bayesian network shown inFigure 3. The variables used in the marginalization above, to keep a structure of a BN2, is the the set of close descendants defined above.
More general, if we have to sum out more than one variable there is a need to order the variables first. The aim of the inference will be to find the marginalization, or elimination, ordering for the arbitrary set of variables not in the target. This aim is shared by other node elimination algorithms like “variables elimination”6, “bucket elimination”7.
The main idea of all these algorithms is to find the best way to sum over a set of variables from a list of factors one by one. An ordering of these variables is required as an input. The computation depends on the ordering elimination; different elimination ordering produce different factors.
The algorithm we proposed to solve this problem is called the “Successive Restrictions Algorithm” SRA 8. SRA is a goal-oriented algorithm that tries to find an efficient marginalizationeliminationordering for an arbitrary joint distribution.
xi
xi−1 xi+1
a
xi
xi−1 xi+1
b
xi xi
xi−1 xi+1
xi−1
xi+1
[image:6.600.186.421.100.191.2]c
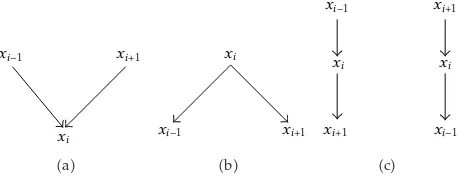
Figure 4:aA converging connexion.bA diverging connexion.cA serial connexion.
the structure of Bayesian Network of Level Two. This was possible using the notion of close descendants.
The principle of the algorithm was presented in details in8.
4. D-Separation and Computations in a Bayesian Network
We have introduced an algorithm which makes possible the computation of the probability distribution of a subset of random variablesXss∈Sof the initial graph. It is also possible to use the SRA to compute any probability distribution of a set of variablesXAconditionally to another subsetXBPA|B.
This algorithm tries to achieve the target distribution by finding a marginalization ordering that takes into account the computational constraints of the application. It may happen that, in certain simple cases, the SRA would be less powerful than the traditional methods 6, 9–13, but it has the advantages of adapting to any subset of nodes of the initial graph, and also to present in each stage interpretable result in terms of conditional probabilities, and thus technically usable.
In addition to the SRA we propose, especially for large Bayesian networks, to segment the computations into several less heavier computations that could be carried independently. These segmentations are possible using the D-separation.
4.1. D-Separations and Classical Results
Consider a DAGI, G. A chain is a sequencex0, . . . , xnof elements ofI such that for all
i≥1,xi−1, xi∈Gorxi, xi−1∈G.
x1, . . . , xn−1are called intermediate nodes on this chain.
On an intermediate node xi a chain can have three connexions as illustrated in
Figure 4.
LetI, Gbe a DAG,S⊆I,aandbbe distinct nodes inS. A chain betweenaandbis d-separated bySif there is an intermediate nodexsatisfying one of the two properties:
ix∈Sand the connection is, onx, serial or diverging,
iix /∈Sand the connection is converging onx.
Classic Result 1
IfAandBare d-separated byS. then the variablesXA andXBare independent conditional onXS.
4.2. Notions
Given a subsetCofI.
Markov Blanket. FCof a subsetCis made of the parents ofC, the children ofC
and the variables sharing a child withC.
Markov Boundary ofC.MC C∪FC
Close Descent ofC.TCis the set of all close descendants of the elements inCother
that those inCitself.
Exterior Roots ofC.RCis the set of the parents of the elements ofC∪TCother
that those inC∪TCitself.
As we can see on the following example:
1
3
7 9
12
13 10, 14
FC {1,10,14,12,9},MC {3,7,1,10,14,12,9},T3,7 {10,14,12},R3,7
{1,9}.
Classic Result 2
XC is d-separated from the rest of the variables conditional on the Markov blanket ofC. The proof of these two results and other results related to D-separation can be found in11.
4.3. Moral and Hypermoral Graphs
1 2
3
4 5
6
7
8
9
10
a
1
2
3 4
5
6
7
8
9
10
[image:8.600.173.426.101.265.2]b
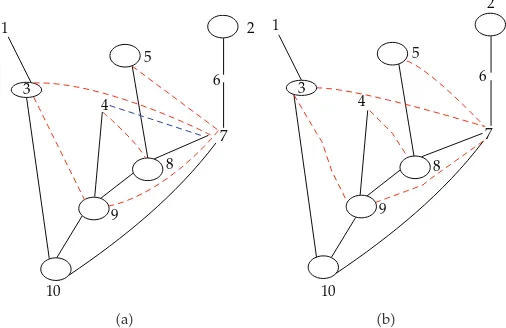
Figure 5: Hypermoral and Moral Graphs.
Moral Graph
Given a DAGI, G
its associated moral graph is the undirected graphI, Gm, whereGmis the set
iof pairs{i, j}such thati, j∈Gorj, i∈G,
iiof pairs{i, j}such thatiandjhave a child in common.
In a similar way, we define what we call the hypermoral graph defined as follow:
Hypermoral Graph
Given a DAGI, G
its associated hypermoral graph is the undirected graphI, Ghm, whereGhmis the set:
iof pairs{i, j}such thati, j∈Gorj, i∈G,
iiof pairs{i, j}such thatiandjhave a close descendant in common.
InFigure 5, there is a link between 4 and 7 in the hypermoral graph because they share
9 as a close descendant.
4.4. Moral and Hypermoral Partitions
The moral graph helps defining the moral partition as follow.
iWe call aS-moral partition the partition ofS−S, denotedPmS−S, defined by the
equivalence relation∼S−S, wherex∼S−Symeans “ there exists a chain fromxtoy, inS−S,
not blocked byS.”
1
2
3
4 5
6
7
8
9
10
1 2
3 4
5 6
7
8
9
10
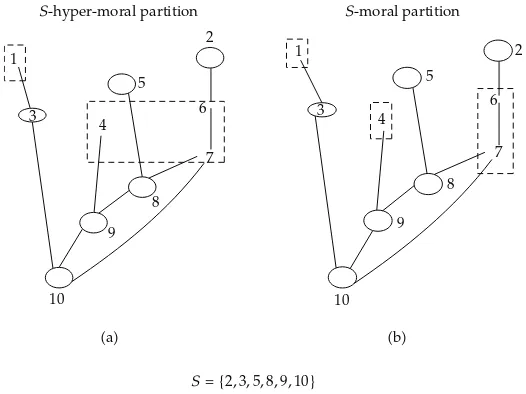
S={2,3,5,8,9,10}
(a) (b)
[image:9.600.168.431.97.294.2]S-hyper-moral partition S-moral partition
Figure 6:aPhm
S TheS-hypermoral partition.bP
m
S TheS-moral partition.
In a similar way we define the hypermoral partition.
ii We call anS-hypermoral the partition of S −S, denoted Phm
S−S, defined by the
equivalence relation≈S−S, wherex≈S−Sy means “there exists a chain, in the hypermoral
graphGhm, connectingxtoywithout an intermediate node inS”. As Illustrated inFigure 6.
4.5. Results
The following results show the possibility of segmenting the computation of the probability distributionPS.
Theorem 4.1. Let I, G, PI be a BN, and let S be a subset of I. Let Phm
S−S be the S-hypermoral
partition ofS−Sand letKbe the set of elements ofSwhich are not close descendants of any element
ofS−S, that is,K{k∈S, ∀y∈S−S, k /∈cdy}. Then,
PS
k∈K Pk/pk
C∈Phm S−S
PTC/RC, 4.1
where
PTC/RC
C
i∈C∪TC
Pi/pixi/xpi. 4.2
The proof of the theorem can be found in14.
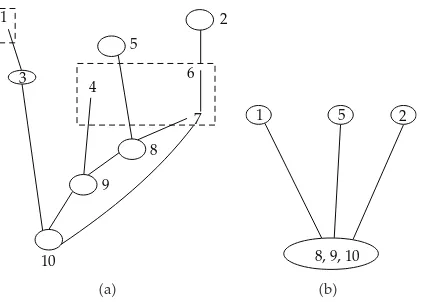
Theorem 4.2. The setQsof singletons{k}, wherek∈K(ifK /∅), and of subsetsTC∩S, where
1 2
3
4 5
6
7
8
9
10
a
1 5 2
8, 9, 10
[image:10.600.197.408.94.245.2]b
Figure 7:aPhm
S theS-Hypermoral Partition.bBN2 RepresentingPS.
5. Unique Partition
We have seen in the last two sections that the application of the SRA for the computation ofPS provides a structure of BN2, and that the use of D-Separations properties allows the segmentation of the computation ofPSand provides also a structure of a level two Bayesian network on S. In fact the two obtained structures are same, this results is giving by the following theorem.
Theorem 5.1. The following two sets.
1The subsetsTC∩S, whereC∈ Phm
S−S.
2The setQsof singletons{k}, wherek∈K(ifK /∅)
constitute a unique partition defining a BN2 onS.
Interpretation
This theorem indicates that the level two Bayesian network, characterizing the probability distributionPS, obtained by application of the SRA, is unique independently of the choices done while running the algorithm. This unique partition is constituted of sets of the two types 1 and 2 mentioned above.
Proof. Let us show that the partition of the targetSconsists of the subsets of types 1 and 2 as
mentioned above in the theorem, in other words consists ofTC∩SwhereC∈ PShm−S, and
{k}for allk∈K.
AsSis a BN-containingS, without a loss of generality, we can limit ourselves to the case whereSI.
The application of the SRA for the computation ofPSrequires marginalizing out the set of variables of S I −S following a specific order. Let try to show that the obtained partition by application of the SRA is same mentioned above.
Let us proof this result by induction on the cardinality ofS.
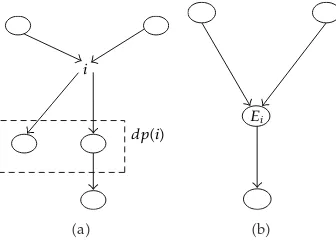
Let us assume that CardS 1. In this caseShas only one element,S{i}.
dp(i i
)
a
Ei
[image:11.600.215.383.98.219.2]b
Figure 8:a: fraction of a BN before marginalizing outi. b fraction of a BN2, onS, obtained after
summing outi.
k1 kr T(Cm)
T(C1) in−ℓ
a
dp(in−ℓ)
k1, . . . , kr, T(C1), . . . , T(Cm)
b
Figure 9:a: fraction of a BN2 onA.b: BN2 obtained ater summing outin−.
The BN2 resulting from this marginalization is formed of the new nodeEialong with all other remaining nodes, in other words all the{k}such thatk ∈I−i1∪cdi1 S−Ei, which is shown inFigure 8.
On the other side, since CardS 1,Phm
S is constituted of a unique equivalent class, C{i}, so, by definition, the partition ofSis constituted of
1TC∩Scdi∩Icdi,
2all other nodes, in other words the nodesk∈Ksuch that
Kk∈S, ∀y∈S−S, k /∈cdyI−i∪cdi S−cdi S−TC. 5.1
This shows the result in this first case.
[image:11.600.152.446.273.434.2]What justify the proof by induction is that once the marginalizing out in, . . . , in−1 these last elements will not interfere in the next steps of marginalizing outin−, . . . , i1.
The result is right till step means that we dispose on A S∪ {i1, . . . , in−}, of a partition that contains the subsets{TC∩S}forC ∈ Phm
A−A, and the nodes {k}such that
k ∈ I− C∈Phm
A−AC∪TC,i.e.,k ∈ A− C∈PAhm−ATC, whereP
hm
A−A is theS-hypermoral
partition associated toA.
Showing the result for1 means to find a partition ofS∪ {i1, . . . , in−−1}constituted of subsets of type 1 et 2 mentioned above.
On one hand, let’s first try to find the partition obtained by application of the SRA. We know that, the marginalization ofin− creates a new node,Ein−, which contains the close
descendants ofin− in the BN2 onAEin−cdin−, shown byFigure 9.
So if we writeJ {k1, . . . , kr}, the set ofKsuch that for allj ∈ {1, . . . , r},kj∩Ein−/∅
andL{C1, . . . , Cm}, the set ofPAhm−Asuch that for alls∈ {1, . . . , m},TCs∩cdin−/∅. In this case, the partition ofBA−{in−}S∪{i1, . . . , in−−1}is constituted of the new nodeEin− cdin− L∪J, and all the other nodes that are left isolated, in other words all
the nodesk∈K−Jand all the{TC∩A}whereC∈Phm
A−A−L. If we writeK Phm
A−A−L∪K−Jso the partition ofBby application of the SRA
is composed of the following two types of sets:
1TC∩Acdin− Ein− L∪J,
2all other isolated nodes, that is, the nodes ofK.
On the other hand, let’s now try to determine the partition ofBA− {in−}using the D-Separation properties.
We have onAa partition composed of nodes{TC∩A}whereC∈ Phm
A−A, and all nodes{k}such thatk∈A− C∈Phm
A−ATC.
SinceBA− {in−}, and no descendant ofin−is ini1, . . . , in−−1,by definition of the hierarchical order, so only one equivalent subset is associated, PhmB−B {{in−}}, it results by definition, the partition ofB S∪ {i1, . . . , in−−1}is composed of the following types of subsets:
1TC∩B T{in−} cdin− Ein− L∪J,
2all other isolated nodesRsuch that
R{r∈B, ∀s∈B−B, r /∈cds}. 5.2
So we haveRB−in−∪cdin− A−cdin− A−Ein−A−L∪J K.
This shows that this partition is same partition obtained by application of the SRA.
References
1 F. V. Jensen, An Introduction to Bayesian Networks, UCL Press, 1999.
2 F. V. Jensen, S. L. Lauritzen, and K. G. Olesen, “Bayesian updating in causal probabilistic networks by
local computations,” Computational Statistics Quarterly, vol. 5, no. 4, pp. 269–282, 1990.
3 P. Spirtes, C. Glymour, and R. Scheines, Causation, Prediction, and Search, vol. 81 of Lecture Notes in
Statistics, Springer, New York, NY, USA, 1993.
4 G. Dan and J. Pearl, “Axioms and algorithms for inferences involving conditional independence,”
5 D. Heckerman, “A tutorial on learning with Bayesian networks,” in Learning in Graphical Models, M. Jordan, Ed., MIT Press, Cambridge, Mass, USA, 1999.
6 N. L. Zhang and D. Poole, “A simple approach to bayesian network computations,” in Proc. of the
Tenth Canadian Conference on Artificial Intelligence, pp. 171–178, 1994.
7 R. Dechter, “Bucket elimination: a unifying framework for probabilistic inference,” in Uncertainty in
Artificial Intelligence, pp. 211–219, Morgan Kaufmann, San Francisco, Calif, USA, 1996.
8 L. Smail and J. P. Raoult, “Successive restrictions algorithm in Bayesian networks,” in Proceedings of
the International Symposium on Intelligent Data Analysis (IDA ’05), A. F. Famili et al., Ed., vol. 3646 of Lecture Notes in Computer Science, pp. 409–418, Springer, Berlin, Germany, 2005.
9 R. G. Cowell, A. P. Dawid, S. L. Lauritzen, and D. J. Spiegelhalter, Probabilistic Networks and Expert
Systems, Statistics for Engineering and Information Science, Springer, New York, NY, USA, 1999.
10 R. E. Neapolitan, Probabilistic Reasoning in Expert Systems, A Wiley-Interscience Publication, John
Wiley & Sons, New York, NY, USA, 1990.
11 J. Pearl, Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference, The Morgan
Kaufmann Series in Representation and Reasoning, Morgan Kaufmann, San Francisco, Calif, USA, 1988.
12 P. H´ajek, T. Havr´anek, and R. Jirouˇsek, Uncertain Information Processing in Expert Systems, CRC Press,
Boca Raton, Fla, USA, 1992.
13 G. Shafer, Probabilistic Expert Systems, vol. 67 of CBMS-NSF Regional Conference Series in Applied
Mathematics, SIAM, Philadelphia, Pa, USA, 1996.
14 L. Smail, “D-separation and level two Bayesian networks,” Artificial Intelligence Review, vol. 31, no. 1–
Submit your manuscripts at
http://www.hindawi.com
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Mathematics
Journal ofHindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation http://www.hindawi.com
Differential Equations
International Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Mathematical PhysicsAdvances in
Complex Analysis
Journal of Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Optimization
Journal ofHindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Combinatorics
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
International Journal of
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Journal of
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Function Spaces
Abstract and Applied Analysis
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporation http://www.hindawi.com Volume 2014
The Scientific
World Journal
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Discrete Mathematics
Journal ofHindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014