Load Balancing Non-Uniform Parallel Computations
Xinghui Zhao
School of Engineering and Computer Science, Washington State University
14204 NE Salmon Creek Ave., Vancouver, WA 98686
Nadeem Jamali
Department of Computer Science,University of Saskatchewan
176 Thorvaldson Building, 110 Science Place, Saskatoon, Canada, S7N 5C9
Abstract
Dynamic load balancing is critical in achieving high per-formance in parallel systems, especially for applications with unpredictable workloads. Traditional load balancing approaches such as work-sharing and work-stealing often assume that the computations can be divided into smaller computations based on some granularity. These approaches do not scale when the computations are not dividable and their sizes are highly variant. In this paper, we present a novel approach – founded in the Actor model known for its programmability – for dynamically load-balancing non-uniform parallel computations. Specifically, our approach is to explicitly reason about resource requirements and com-mitments at run-time in order to makefine-grained schedul-ing decisions. We prototype our approach by extendschedul-ing an efficient Java implementation of Actors, ActorFoundry. We have also implemented a tuner which dynamically balances the resources used by the computations vs. those used by the reasoning mechanism, essentially balancing the quality of scheduling against the resources needed for achieving it. We propose a new benchmark – the Unbalanced Cobwebbed Tree (UCT) – to fairly compare our approach to existing approaches, which captures the non-uniform nature of com-putations. Experimental results show that despite the higher overhead of providing Actors’ programmability features, for a diverse enough set of computations, our approach outper-forms both work-sharing and work-stealing approaches, and shows better scalability.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
AGERE! ’13, October 27, 2013, Indianapolis, Indiana, USA.
Copyright is held by the owner/author(s). Publication rights licensed to ACM. ACM 978-1-4503-2602-5/13/10. . . $15.00.
http://dx.doi.org/10.1145/2541329.2541337
Categories and Subject Descriptors D.1.3 [software]: Pro-gramming Techniques—Concurrent ProPro-gramming; D.4.1 [software]: Operating Systems—Process Management
General Terms Performance, Languages,
Experimenta-tion
Keywords Actors, Java, JVM, Dynamic Load Balancing,
Programmability, Resource Control
1. Introduction
There has been a disconnect between the advances in lan-guages for programming concurrent systems, and the way in which high performance computing systems have been im-plemented. The reason often cited for this is the overhead of the heavier runtime system associated with higher-level languages, such as those loosely based on the Actor model. Where performance is key, this overhead has been consid-ered too high to be affordable. At the same time, the choice of lower-level languages has had important consequences. For instance, typically, only computations whichfit a fairly strict set of requirements are considered suitable for highly parallel execution: they should be neatly decomposable into relatively uniform-sized largely independent parts. A rela-tively small fraction of computations readily fit these re-quirements; others can be programmed – often not in the most natural ways – to conform to these requirements. Re-gardless, the programming tools available for writing soft-ware for taking advantage of massive parallelism tend to be primitive.
There is growing recognition today of the need to bal-ance performbal-ance against programmability. In that spirit, we asked the question: what really is the overhead of using an Actor based language for HPC? The easiest way to an-swer this question, by comparing performance of the com-peting solutions for traditional HPC-style computations, in our opinion, favours the existing solutions. The benchmarks typically used for comparing performance of such systems are designed to capture properties of the problems tradition-ally solved in parallel. Ourfirst step is to examine the pos-sibility of generalizing the benchmarks to capture properties
of a wider class of computations. We take a particular bench-mark, the Unbalanced Tree Search (UTS), and consider the types of computations whose properties it accurately cap-tures. Obviously, UTS attempts to maximize uncertainty; however, it implicitly makes some important assumptions about the granularity of computations and their relative size. The fact that visiting a node of a tree is the extent of compu-tation required before making the next scheduling decision, tilts the balance in favour of faster decisions against better decisions. It also makes the computation required for pro-cessing each node identical. Our change to the benchmark is to put substantial computations at each tree node, and allow them to be non-uniform. We refer to our benchmark as the Unbalanced Cobwebbed Tree Search, where cobwebs are the computations of various sizes.
We then propose a novel approach for dynamic load bal-ancing based on fine-grained resource reasoning. Instead of solving the problem from the perspective of partition-ing computations and assignpartition-ing workload to processors, we view the problem from the perspective of resource manage-ment and control, and achieve dynamic load balancing by ef-ficiently matching available resources against computations, and minimizing the amount ofexpiringresources.
The rest of this paper is organized as follows. Related work is reviewed in Section 2. Section 3 presents ourfi ne-grained resource management approach. Section 4 describes the evaluation methodology and presents experimental re-sults. Finally, Section 5 concludes the paper and proposes some future directions of this research.
2. Related Work
In this section, wefirst introduce the Actor model, and its implementations, then we review existing approaches for dy-namic load balancing, as well as in benchmark applications for evaluating those approaches.
2.1 Actors
The growth of multicore computers has made it imperative for application programmers to write concurrent programs. As a result, actor-oriented programming receives increas-ing attention. Actors are autonomous computational entities which communicate with each other using buffered, asyn-chronous, point-to-point messages. An actor encapsulates a state, a number of methods (which can change the state of the actor), and a thread of control. Actors are distributed over time and space. Each actor has a globally unique mail ad-dress, and it maintains a queue of the unprocessed messages it has received.
The messages in an actor’s message queue are processed one by one according to the order of arrival. While process-ing a message, an actor may carry out one of the three prim-itive actions:
•Create afinite number of new actors with some prede-fined behaviors. The creator actor knows the addresses of the new actors.
•Send messages to other actors. An actor can send a mes-sage to another actor only if it knows the name of the destination actor.
•Change the actor’s own state and be ready to process the next message.
Some of the actor-based languages include Erlang [4], SALSA [33], E language [1], Axum [23], and Ptolemy [14]. In addition to the novel languages based on the Actor model, there are also actor frameworks/libraries which are devel-oped using existing programming languages, such as C/C++ (Act++ [17], Broadway [31], Thal [19]), and Java (Scala Actor Library [12], Kilim [30], Actor Foundry [5], Actor Architecture [16]). Faithful implementations of the Actor model – such as Actor Foundry [5] and Actor Architec-ture [16] – implement all properties defined by actor se-mantics, including encapsulation, fair scheduling, location transparency, and mobility. Unlike these faithful implemen-tations, many actor-oriented frameworks compromise one or more semantic properties of the standard Actor model in order to achieve better performance, such as Scala [12], in which the only actor property being implemented is fair scheduling.
The Actor model encapsulates objects along with threads of execution. Therefore, earlier actor frameworks usually use one-thread-per-actor implementation of actors, such as Scala [12] and Actor Architecture [16]. However, it turns out that in practice, one-thread-per-actor implementation of actors is not particularly efficient, because of the overhead caused by context-switching among actor threads. It is more efficient to have a pool of threads, where each thread pro-cesses messages for multiple actors in some order. Karmani et al. implemented this optimization strategy in the latest version of ActorFoundry [18], which has been shown to de-liver orders of magnitude better performance than its previ-ous version. Notably, for a Threadring benchmark, in which 10 million messages are processed by 503 actors, the opti-mization improves Actor Foundry’s performance from 695s to 10s, 17% faster than Scala (12s), which achieves good performance by compromising several semantic properties of the Actor model. In fact, the optimized ActorFoundry’s performance comes close to that of Erlang (7s), a program-ming language which supports Actor semantics.
The work presented in this paper used the optimized ActorFoundry as the underlying framework for supporting parallel computations.
2.2 Dynamic Load Balancing
Load balancing is the process of optimally redistributing workload of computations among available processors for improving performance of parallel systems [3]. The topic is
of growing interest again with the emergence of multicore architectures with the potential of dramatically increased scale of parallelism [13]. The best load balancing strategy to use for a computation depends on the nature of the compu-tation. When the amount of computation is known or can be accurately estimated in advance, static load balancing can be used. Although static load balancing is easy to implement, its effectiveness depends on accurate estimation of the compu-tations’ sizes. In most situations, however, workload needs to be redistributed over the course of the computation.
Dynamic load balancing takes into account the system state and redistributes workload as a computation pro-gresses. It has been shown that even very simple dynamic load balancing strategies – which only collect small amounts of system state information – can lead to significant perfor-mance gains [11]. Two different strategies are commonly used: work-sharing [20] [21] and work-stealing [7].
In work-sharing [21], processors share a global FIFO queue, which is used to place unassigned tasks. Under-utilized processors make requests for work, and are assigned thefirst available task in the task queue. Work-sharing is a centralized approach which utilizes a shared queue to facili-tate load balancing; therefore, it is believed to be suitable for shared memory systems [9].
Unlike work-sharing, work-stealing [7] takes a distributed approach. Each processor maintains a local task queue, and processes the tasks in the queue. An under-utilized processor attempts to obtain work from other processors’ queues (hence, the term “stealing”). Being decentralized, work-stealing is suitable for distributed systems. In addi-tion, because the responsibility for finding and migrating workload lies with the under-utilized processors, there is lit-tle overhead suffered by busy processors, leading it to be more stable. An investigation into the scalability of work-stealing [10] showed that work-work-stealing can be implemented efficiently. A number of variants of work-stealing have re-cently been developed and successfully utilized in large-scale distributed systems [10], grids [28], and multi-core clusters [29].
Besides the traditional work-sharing and work-stealing approaches, there are other load balancing approaches which organize the load balancing tasks into hierarchical struc-tures [36] to address scalability, and approaches designed for actor systems [8, 22].
Existing approaches on dynamic load balancing typically focus on partitioning and distributing uniform-sized work-load to processors. In this paper, we propose a different ap-proach based onfine-grained resource coordination and con-trol.
2.3 Benchmarks for Dynamic Load Balancing
A number of benchmarks have been proposed for evalu-ating the performance of dynamic load balancing mecha-nisms. The NAS parallel benchmark [6] is a set of numerical aerodynamic simulations developed for performance
eval-uation of highly parallel supercomputers. NAS consists of five parallel kernel benchmarks and three simulated applica-tion benchmarks. These benchmarks simulate the computa-tion and data movement characteristics of large-scale com-putationalfluid dynamics applications. Biomolecular simu-lations have also been used as load balancing benchmarks because of their dynamicity and the large scale of computa-tions involved. For example, NAMD [27] (nanoscale molec-ular dynamics), and Mol3D [26] are molecmolec-ular dynamics programs that simulate biomolecular systems. LBTest [36] is a synthetic benchmark in which a collection of objects are created based on customizable parameters, and these ob-jects communicate with each other, obtain data and carry out computations.
A benchmark which is of the most relevance to our work is the unbalanced tree search (UTS) benchmark [25]. UTS provides a function to create an unbalanced tree using a set of parameters, such as shape, depth, size, and imbalance (a measure of the variation in the size of its subtrees). The benchmark problem is the parallel exploration of the created tree. The performance of a load balancing scheme can then be evaluated by measuring the computation time of perform-ing an exhaustive search on the tree. The tree is constructed implicitly; that is, each node contains all information neces-sary to construct its children. However, a parent node must be visited before its children nodes. Since the tree could be highly unbalanced, there is a high variation in the sizes of the subtrees of a specific parent node. The variation presents challenges in performing an efficient search, and requires significant dynamic load balancing. This benchmark nicely captures the properties of applications that must navigate a large state space of unknown or unpredictable structure. Many search and optimization problems fall in this class of applications. The benchmark has been widely used recently and implemented using difference languages and architec-tures [24] [9].
Our interest in UTS stems from the fact that simple adap-tations to the benchmark lead to important generalizations necessary to capture properties of larger classes of applica-tions. We use such an adapted benchmark to fairly compare our dynamic load balancing approach with existing ones.
3. Fine-Grained Resource Management
To be precise about what we mean by parallel computations, we take them to be concurrent computations as defined by the Actor model [2].
Of the various Actor languages and libraries, we have chosen to implement our prototype in ActorFoundry [18]. ActorFoundry attempts to faithfully implement the Actor model, and has a modular design which makes the code uniquely accessible. More importantly, a simple optimiza-tion is known to bring ActorFoundry’s performance close that of Erlang’s [4], which is known to be the most efficient
actor1
FIFO Queue
worker1 worker2 worker3
Actor Scheduler
execute actors
actor2 actor3 actor4
Figure 1. ActorFoundry Scheduler
implementation of Actors. For these reasons, we use Actor-Foundry for our prototyping.
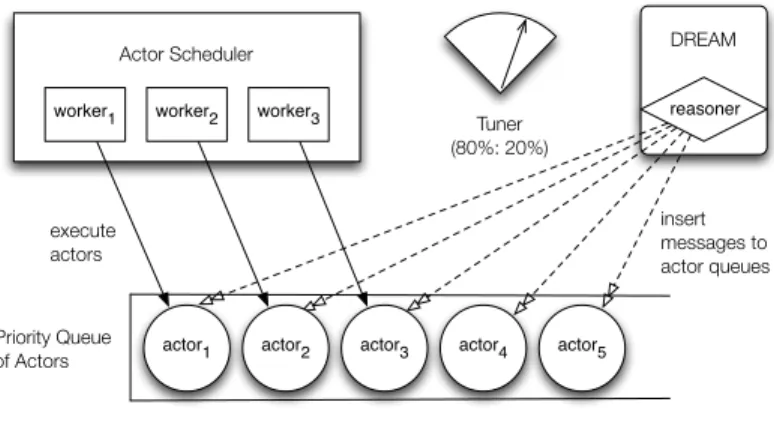
Because ActorFoundry delivers processor cycles to actors through the scheduler, the primary focus of our attention is its scheduling mechanism. As illustrated in Figure 1, Actor-Foundry schedules afixed number1 of native JVM threads
called workers, which in turn select from among the ac-tors waiting in awaiting queueto get a chance to execute. The waiting queue is shared by the worker threads. An ac-tor waits in this queue only when it has received a message in its ownmessage queue; at all other times, it is essentially dormant, and does not need to execute. Whenever a worker becomes free, it picks an actor from the waiting queue to execute. The waiting queue is a FIFO queue, and actors are placed in the queue according to the order in which they re-ceived thefirst messages in their own message queues. After dequeueing an actor from the waiting queue, a worker calls the actor’s continuation. The worker continues to execute the dequeued actor until all messages in its queue have been processed. After completing with one actor, the worker de-queues another actor and starts to execute it. ActorFoundry’s scheduler can be calledmessage-drivenin the sense that only actors which have messages in their queues get to be on the waiting queue; any other actors stay off of it. This naturally leads to a degree of load balancing.
We improve upon ActorFoundry’s load-balancing by re-ordering deliveries of messages in the system based on spe-cific criteria. In our previous work, we have shown that this approach can be effective in achieving timeliness goals of computations [35]; here, we show that a similar approach – prioritizing message deliveries based on bounded knowl-edge of the computations they would lead to – can also improve overall performance of the system even in the ab-sence of timeliness requirements. Particularly, we attempt to expedite delivery of the messages which would lead to computations which in turn would send messages of their
1The number of worker threads is increased at run time when found to be
insufficient for progress in the computation.
own; these messages are potential bottlenecks. This one-level lookahead is possible to achieve by maintaining infor-mation about the number of messages that the methods ex-ecuted by actors would send. We introduce a specialmeta actorto carry out the reasoning necessary for this ordering of messages. Each message in the system is trapped by the reasoner, which then determines whether it is a potential bot-tleneck. It maintains a Shortest Job First priority queue of such messages, ordering them on the basis of resources that the corresponding methods would take to execute. For now, we assume that the information about resource requirements is trivially made available by the programmer. In general, heuristic approaches may be used to obtain approximate in-formation automatically; this would typically happen in a pre-compilation phase, but could conceivably happen at run-time.
Additionally, we use a Tuner to perform meta-level re-source control. Because the reasoning mechanism consumes computational resources (amounting to the overhead), this tuner offers a means to balance the division of resources con-sumed by the computational actors and those concon-sumed by the reasoner. This is possible for us to do trivially on a single processor because we implement the reasoner as a separately scheduled meta-actor. The tuner’s division of resources can befixed in advance: it can be set to automatically react to observed progress of the computation, or it can be made available to a system operator in the form of atuning knob. In thefixed setting, the ratio between the processing power taken for the computation vs. that for the reasoning (e.g. 80%:20%) can be initialized at the beginning of the com-putation. Section 3.3 discusses one way in which the tuner can set itself reactively.
Figure 2 shows the architecture of the modified sched-uler. Installation of these mechanisms leads to two levels of control: afine-grained message scheduling for better per-formance, as well as a meta-level division of resources be-tween the reasoner and the actual computation being rea-soned about.
worker1 worker2 worker3 Actor Scheduler reasoner DREAM Tuner (80%: 20%) execute actors insert messages to actor queues Priority Queue
of Actors actor1 actor2 actor3 actor4 actor5
Figure 2. Integrating Deadline Reasoning into Actor-Foundry Scheduler
3.1 Resource Coordination Policy for Dynamic Load Balancing
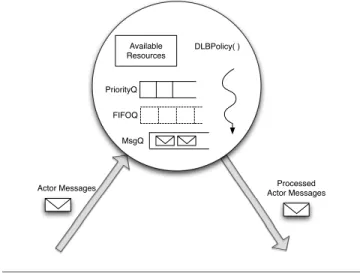
In Actor systems, computations are carried out by ac-tors when they process their messages. Processing a message may result in new messages being sent to other actors, which eventually trigger new computations. Therefore, scheduling the delivery of actor messages has a significant impact on the overall performance of a computation. To achieve bet-ter scheduling for message delivery in ActorFoundry, we have installed a reasoning mechanism into it which traps each actor message and delivers it according to the load bal-ancing requirements. The reasoning mechanism is based on DREAM [34], a model we previously developed for rea-soning about matching resources defined in time and space against computations with timeliness constraints. However, unlike in [35], where we reasoned about satisfying timeli-ness constraints, here we use it for dynamic load balancing. Figure 3 shows the composition of the reasoner, which we will refer to as the DREAM Reasoner (DR).
DLBPolicy( ) Available
Resources
PriorityQ FIFOQ
Actor Messages Actor MessagesProcessed MsgQ
Figure 3. DREAM Reasoner
The reasoner is a meta-actor. Just like every other (base) actor encapsulates a state, a number of methods to manip-ulate the state, and a thread of execution, so does the rea-soner. DR’s state is the record of resources available in the system. Note that resources are represented usingresource terms, which contain several key attributes of resources, such as type, density, time and location of existence (as specified in [34]), its methods are resource coordination policies (in this case, thedynamic load balancing policy (DLBPolicy)), andfinally, it has a thread of execution. Each base level asyn-chronous message sent by an actor arrives in DR’s message queue (MsgQ), and is subsequently delivered to the intended base level recipient actor, according to the resource coordi-nation policy.
Additionally, we prioritize a class of sub-computations which are likely to become bottlenecks. Recall that an ac-tor computes as a result of processing incoming messages, which ask for invocations of the actor’s methods. In this context, the methods which themselves send messages are potential bottlenecks if they are not processed early. We use a one-level lookup to identify messages which would invoke methods which would in turn send more messages, and pri-oritize delivery of the former messages to avoid material-izing of the bottlenecks. This is achieved by separating the messages received by DR into two queues: a priority queue (PriorityQ in Figure 3) ordering potential bottleneck mes-sages according to their resource requirements (mesmes-sages with lower requirements are released to their destinations sooner), and a FIFO queue (FIFOQ in Figure 3) which main-tains the arrival order of the remaining messages. Particu-larly, messages in PriorityQ are released before the messages in the FIFOQ.2This avoidance of bottlenecks has the affect
of creation of new messages sooner than it would happen if the messages were not prioritized. This leads to a greater likelihood of there always being enough messages to keep all processors busy, lowering the likelihood of processors be-coming idle.
The algorithm of the DLBPolicy in DR is shown in Al-gorithm 1. Each incoming message is placed in one of the waiting queues. If processing a message would result in cre-ating more workload, i.e., the message leads to the actor carrying outsend operations, the message is placed in the priority queue, which is sorted according to the resource re-quirements of the messages (lower rere-quirementsfirst). On the other hand, if the message does not lead to creation of new messages (and corresponding workload), it is placed in the FIFO queue.
The messages wait in the queues until they are released by the reasoner. The reasoner (DR) and the worker threads responsible for processing actor messages are scheduled in a scheduling cycle with predefined length,3 according to the
ratio determined by the tuner. The reasoner only releases enough messages to keep the processors busy for the up-coming scheduling cycle. Messages waiting in PriorityQ are released before release of any messages in FIFOQ, and mes-sages are released until all resources available in the next scheduling cycle have been allocated.
Note that holding the messages at the reasoner decreases the likelihood of resources being under-utilized because of the bottleneck messages. As a result of prioritized delivery of potential bottleneck messages (i.e., message which would lead to additional messages), additional workload is created sooner than it would be otherwise, reducing the likelihood of processors sitting idle.
2Note that this does not lead to starvation for messages waiting in FIFOQ,
because the computation isfinite and PriorityQ will eventually be empty.
3In the current implementation, the scheduling cycle is predefined by the
Algorithm 1DLBPolicy in DR
1: whilenot all MsgQ, PriorityQ, FIFOQ are emptydo 2: whileMsgQ is not emptydo/* there are unprocessed
messages */
3: dequeue thefirst message from MsgQmsg 4: ifmsgleads tosendoperationthen/* processing
msgcreates new workload */ 5: putmsgin PriorityQ 6: else
7: putmsgin FIFOQ
8: end if
9: Release Messages /* As shown in Algorithm 2 */
10: end while
11: Release Messages /* As shown in Algorithm 2 */ 12: ifMsgQ is empty and there are no resources available
in next scheduling cycle then
13: break
14: end if
15: end while
16: wake up actor computations /* terminate DR cycle */
Algorithm 2Release Messages
1: while there are resources available in next scheduling cycledo
2: ifPriorityQ is not emptythen
3: dequeue thefirst messagepriorityMsg 4: releasepriorityMsg
5: update available resources 6: else
7: ifFIFOQ is not emptythen
8: dequeue thefirst messageregularMsg 9: releaseregularMsg
10: update available resources 11: else 12: break 13: end if 14: end if 15: end while 3.2 System Architecture
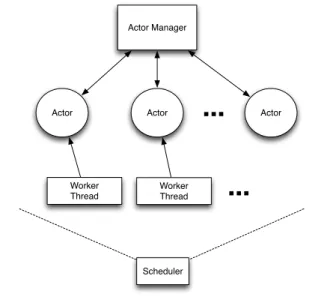
A prototype implementation of our dynamic load balanc-ing mechanisms has been developed by extendbalanc-ing the Ac-torFoundry Java library. AcAc-torFoundry supports distributed computations by supporting actors distributed across a num-ber of processor nodes. Actors can communicate with each other across node boundaries as well as migrate from one node to another.4 Figure 4 shows the architecture of an
in-stance of ActorFoundry node. TheActor Manageris respon-sible for keeping track of all the actors on the node, and a
4This is made possible by the fact that actors have globally unique names,
with mapping between the names and actual physical locations tracked using distributed name tables.
schedulerschedules all the worker threads which execute ac-tors. Scheduler Actor Manager Worker Thread
...
Actor Actor...
Worker Thread ActorFigure 4. System Architecture (ActorFoundry Node In-stance)
We refer to our extended system as AF-D (ActorFoundry with DREAM reasoning). The architecture of an instance of AF-D node is shown in Figure 5.
Scheduler Actor Manager DREAM Reasoner Worker Thread DREAM Thread
...
Actor Actor...
Worker Thread ActorFigure 5. System Architecture (AF-D Node Instance) TheActor Managerand theDREAM Reasoner(DR), to-gether serve the core runtime functions of an AF-D node. They are responsible for creating and scheduling new actors, as well as handling messages. Whether resource reasoning is enabled or not can be decided at the time of initiating the computations execution. If resource reasoning is enabled, every actor message which involves the local AF-D node is examined by DR as a reasoning request. Upon receiving a reasoning request, DR processes the request according to a specific resource coordination policy. The dynamic load balancing policy (DLBPolicy) previously described in Sec-tion 3.1 is an example of a resource allocaSec-tion policy.
Additionally, ActorFoundry’s scheduler has been rewrit-ten for AF-D to accommodate the DREAM Reasoner. A dedicated thread is used for carrying out the reasoning. The scheduler schedules this thread and the collection of worker threads in turn according to the ratio set by the tuner. The way in which ActorFoundry supports the actual execution of actors is essentially unchanged in AF-D.
3.3 Self-Tuning
We have implemented an adaptive version of tuning, which we call self-tuning. Consider an adaptive tuning policy where the meta scheduler begins by maintaining a 20%:80% ratio between resources for the reasoner versus the computa-tion, but is allowed to increase the resources for the reasoner to a maximum of 30%. We imagine three types of events which can trigger self-tuning. First, a reasoning too slow
event is triggered when reasoning about messages is taking so long that processors are idle. This trigger results in an in-crease in the ratio of resources provided to the reasoner. On theflip side, areasoning too fastevent is triggered when it is observed that the reasoner is releasing messages at a much faster rate than needed (i.e., can be processed). In this case, a greater portion of the resources can be diverted toward the actual computations. Finally, a third type of eventreasoning too costlycould be triggered if despite the threshold of 30% for reasoning being reached, the reasoning is not adequately fast for keeping processors busy. In other words, the reason-ing process is holdreason-ing actor messages for too long despite having significant share of system resources. One reaction to this event could be to simply give up on reasoning, and simply devote all resources to the computation itself, hop-ing for the best.5We used thefirst two of these in the work
presented here.
4. Evaluation
The context of our work presents challenges in evaluating it. Existing benchmarks assume lower-level language support, as well as assume that the computations to be solved are sim-ilar in character to those typically parallelized. Ourfirst step to facilitate a credible evaluation was to minimally adapt an existing benchmark to capture properties of a richer class of computations. However, that alone is insufficient because it does not in itself enable a fair comparison between existing approaches – particularly work-stealing and work-sharing – and our solution. There are two reasons for that. First, our solution builds on an implementation of Actors, which has a somewhat heavier footprint than that of the lower-level languages in which competing solutions are typically im-plemented. Although the principles of our solution – such
5In ongoing work, we have also tried reacting to this trigger by reducing the
frequency of reasoning. In other words, the reasoner would consider only a fraction of the messages for identification as possible bottlenecks (say, every other). Also consider that the reasoning would require more resources if code had to be automatically analyzed at runtime.
asfine-grained resource control – can easily transfer to low-level languages, the mechanisms we have developed cannot simply be plugged in to a different language. Not only would new mechanisms need to be implemented, it is not clear why it would be beneficial to do so: it is not trivial to program computations with non-uniform tasks without using higher-level language support. Second, implementing the compet-ing solutions in an Actor language would not lead to a fairer comparison either; they obviously do not need an Actor lan-guage, and will be put at a performance disadvantage by be-ing implemented in Actors.
4.1 Challenges
We considered four factors in making the comparison fair: the hardware and OS, the language of implementation of the mechanisms, construction of a benchmark, andfinally, the representation of the benchmark to the competing mecha-nisms. Although the hardware and OS did not present a chal-lenge, the other three did.
LanguageActorFoundry, into which we installed our mech-anisms, is a Java library. Although implementing work-stealing and work-sharing also in Java eliminated one source of unfairness, the overhead of ActorFoundry’s runtime mechanisms – such as for asynchronous message passing, and explicit management of actor states – remained. On the one hand, it is fair for our solution to suffer part of this dis-advantage. On the other hand, if we were to limit ourselves to the types of computations which can be solved using the competing approaches, there would be opportunities to opti-mize. Particularly, instead of creating actors at runtime, we could create them in advance.
BenchmarkThe Unbalanced Tree Search benchmark (UTS) nicely captures maximum uncertainty as the number of chil-dren of a node and the subtrees rooted at them are not known until the parent node is visited. At the same time, there are important assumptions and consequent biases implicit in its design, which are relevant to evaluation of our work. First, it assumes maximum uncertainty, which is rarely the case in real applications; typically, substantial computations take place between points in time where decisions must be made, affording some opportunity to reason. By not allowing time between decision points, UTS penalizes a mechanism that attempts to balance the time required for making decisions against the consequences of bad decisions. Second, because substantial computations are not modelled, nor are substan-tial differences between those computations. This leads to an assumption of uniform task sizes. That said, the design of UTS makes it relatively trivial to adapt it to eliminate these biases; our proposed benchmark, the Unbalanced Cob-webbed Tree (UCT) does exactly that by placing substantial computations at the nodes, and allowing the computations to be varied. Sizes of the computations follow a normal dis-tribution, with the mean and standard deviation provided as additional parameters at the time of the tree’s creating, along
with the parameters normally required for creating a UTS tree.
The benchmark problem is to traverse the computation tree, and carry out the computation at each node when the corresponding node is visited. As in the UTS benchmark, the nodes in the tree can be traversed in parallel and in any order, as long as a parent node is visited before its children nodes. The goal is to complete all computations in the tree as fast as possible.
Benchmark Representation The difference in
program-ming models requires a careful decision about how to rep-resent the benchmark problem to the competing approaches. For the Actors approach, we created an actor tree in advance, with the root actor executing the computation at the root of the problem tree, and so on. The computation was initiated by sending a message to the root actor, which communicated with its children by asynchronous message passing. For the competing approaches, we created an efficient data structure with each node specifying the task corresponding to the node and including pointers to the node’s children. Because the focus of our attention is the size of the computation rather than its content, in both cases, the computations carried out to complete the tasks are simply functions which execute for a number of cycles determined by a parameter value. This gives us a way of controlling exactly how much computa-tion is to be carried out.
4.2 Benchmark Implementation
We used UCT to compare the performance of four ap-proaches, including our approach (AF-D), ActorFoundry (AF) without the reasoning component, work-sharing [21] and work-stealing [7]. The former two are actor systems, and the latter two are popular existing approaches for dynamic load balancing. We compared these approaches in terms of the performance of carrying out the traversal computation for UCT with different parameters for tree creation.
At the time of creating a UCT tree, two types of param-eters need to be specified: tree parameters, and computation parameters. Tree parameters includesizeof the tree, which specifies the number of nodes in the tree, andshapeof the tree. Note that there are several shapes of the tree, such as
binomialtrees, andgeometrictrees [25]. In our experiments, we use binomial trees, in which each node may have either no children, orm(a predefined number) children. Tree rameters specify the attributes of the tree. Computation pa-rameters include information about the distribution of the computations’ sizes. In the implementation, we assume the sizes of computations follow a normal distribution, with pre-defined mean and standard deviation parameters. The com-putation at each node is a simple iterative addition compu-tation, and the sizes of computations vary in terms of the number of iterations.
In the actor-based approaches, The trees are generated in the following manner. First, the root actor is created, and its computation size is generated by a number generator
following a normal distribution with predefined mean and standard deviation. Then aCreateTreemessage is sent to the root actor, which triggers creation of the tree.
Algorithm 3Create Tree
1: determine whether this actor has children /* based on the tree parameters */
2: ifhasChildrenthen
3: determine number of childrenm/* based on the tree parameters */
4: fori=1 tomdo/* create children nodes */
5: determine size of the computation on node i/* based on the computation parameters */
6: create actori
7: record information of child nodei
8: send CreateTree message to actori/* tell childito create more nodes */
9: end for
10: end if
The algorithm of the CreateTree message is shown in Algorithm 3. Upon receiving the message, a node actorfirst determines whether it has children nodes; if it does, the node actor tries to create children nodes based on the creation parameters. Then the actor records the information about its children, andfinally sends theCreateTreemessage to all its child nodes. The creation process terminates when the tree reaches the predefined size.
The work-sharing and work-stealing approaches were implemented using Java threads. In both approaches, the threads (workers) received trees, read information contained in the nodes as the trees were traversed, and carried out the computations according to the information. Note that although we used Java threads, this approach can be im-plemented in other languages too. Because ActorFoundry is implemented using Java threads, we implemented the base-line approaches in Java threads, for fair comparison. In all approaches, the number of threads was set to be 8. These 8 threads carried out all the tasks.
Actor-based ApproachesIn work-sharing, load balancing is achieved through a globally shared task queue. After a UCT tree is created, the benchmark computation is initiated by enqueuing the root node of a UCT tree to the task queue, and creating a predefined number of worker threads. Each worker thread tries to obtain a node from the task queue. Once a node is dequeued, the worker thread enqueues the child nodes, if there are any, and then carries out the com-putation specified in the node. When a workerfinds the task queue to be empty, it sleeps for some time, and then checks again (in case other workers have generated more nodes in the queue). The computation terminates when the task queue is empty and all worker threads are sleeping. Note that work-sharing requires a globally shared task queue and is suitable for shared memory processors.
Algorithm 4Worker Thread in Work Sharing 1: whiletruedo
2: iftaskQ is not emptythen
3: dequeue thefirst nodemyT askfrom taskQ 4: ifmyT askhas childrenthen
5: enqueue all the children nodes
6: end if
7: carry out the computation /* according to the com-putation size specified in nodemyT ask*/ 8: else/* taskQ is empty */
9: sleep for some time /* wait for other workers to generate more nodes */
10: end if
11: end while
Work StealingWork-stealing is different from work-sharing in that there is no global task queue shared by all workers. Instead, each worker has its own task queue, and processes the tasks in the local queue until it becomes empty. However, when a worker’s own queue becomes empty, it tries to steal tasks from the queues of other workers, and then processes these tasks. The benchmark computation for work-stealing is initiated by creating a predefined number of worker threads and their local task queues, and enqueuing the root node of a UCT tree into the task queue of one of the workers. Each worker enqueues children of the node it is processing into its own queue; however, these child nodes can be stolen by another worker. The computation begins with all except one worker trying to steal tasks, and terminates when all workers are trying to steal tasks from others, and all the task queues are empty. Because work-stealing does not require a globally shared task queue, it can be used in systems without shared memory.
Algorithm 5Worker Thread in Work Stealing 1: whiletruedo
2: ifmyQ is not emptythen
3: dequeue thefirst nodemyT askfrom myQ 4: ifmyT askhas childrenthen
5: enqueue all the children nodes to myQ
6: end if
7: carry out the computation /* according to the com-putation size specified in nodemyT ask*/ 8: else/* taskQ is empty */
9: keep checking other queues and try to steal a node 10: enqueue the stole node to myQ
11: end if
12: end while
DiscussionNote that in both work sharing and work steal-ing approaches (shown in Algorithm 4 and 5), the code for the computations is mixed with the code for the approach of load balancing, which increases the complexity of program-ming. However, using our approach can eliminate the
prob-lem. In our approach, the code for computations is shown in Algorithm 6, and the code for load balancing is shown in Al-gorithm 1. The fact that computation code is well separated from the code of load balancing simplifies the task of pro-grammers, enhances modularity, and supports reusability of the code.
Algorithm 6Traverse
1: carry out the computation /* based on the computation size */
2: ifhasChildrenthen
3: fori=1 tomdo
4: send Traverse message to childi/* traverse childi */
5: end for
6: end if
4.3 Experimental Results
Experiments were carried out to evaluate our approach of dy-namic load balancing based onfine-grained resource coordi-nation. The experiments were run on an Apple Xserve with two 2.8GHz Quad-Core Intel Xeon processors (8 cores), 8GB memory and 12MB L2 cache. The number of worker threads in all approaches was set to be 8. We created bino-mial trees with parameterm=5, that is to say, each node in the tree either had no children, or 5 children. For each ex-periment instance, all four approaches were executed on the same UCT tree for comparison. Note that for each experi-ment setting, we executed the experiexperi-ment 15 times, and the results presented in this section are the average results of the 15 runs.
The first set of experiments evaluated the performance of the four approaches with increasing average computation size in the tree. In these experiments, the size of the tree was set to be 100, and the standard deviation of computa-tion sizes was 50. The results are shown in Figure 6. The computation time for traversing an UCT tree is linear with respect to the average computation size in the tree, for all four approaches. Compared to a pure Java implementation of the work-sharing and work-stealing approaches, both ac-tor systems have extra overhead. However, the overhead ap-pears to stay constant as the average computation size in-creases. In addition, our approach (AF-D) outperforms Ac-torFoundry when the average computation size is larger than 500ms. It shows that the resource reasoning in AF-D better balances the workload, to the extent that there is a perfor-mance gain which more than makes up for the reasoning mechanism’s overhead. Table 1 shows the average number of tuning events triggered in the experiments involving AF-D.
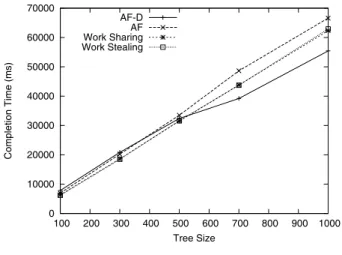
The second set of experiments investigated the scalability of the four approaches in terms of the tree size. In these experiments, the average computation size was 500ms, and the standard deviation was 100. The experimental results are
0 2000 4000 6000 8000 10000 12000 14000 100 200 300 400 500 600 700 800 900 1000 Completion Time (ms)
Average Computation Size (ms) AF-D
AF Work Sharing Work Stealing
Figure 6. Performance Vs. Computation Size
(Tree-Size=100, StdDev=50)
Table 1. Tuning Events Triggering Vs. Computation Size Comp. Size Reasoning too fast Reasoning too slow
100 15.5 7.5
300 19.1 8.2
500 26.2 14.1
700 33.9 39.8
1000 48.2 43.1
shown in Figure 7. Compared to ActorFoundry and the two traditional approaches, AF-D suffers from some overhead initially; however, it eventually exhibits better scalability as the tree size grows larger than 500. In other words, the performance gain of the reasoning exceeds the overhead it causes. 0 10000 20000 30000 40000 50000 60000 70000 100 200 300 400 500 600 700 800 900 1000 Completion Time (ms) Tree Size AF-D AF Work Sharing Work Stealing
Figure 7. Performance Vs. Tree Size (AveCompSize = 500, StdDev = 100)
Table 2 shows the average number of tuning events trig-gered in the AF-D experiments.
Table 2. Tuning Events Triggering Vs. Tree Size Tree Size Reasoning too fast Reasoning too slow
100 39.8 42.2
300 38.7 45.1
500 65.3 57.8
700 69.9 67.3
1000 80.2 65.5
The third set of experiments investigated the relationship between the performance of the approaches and the standard deviation of the computation sizes in the tree. In these ex-periments, the size of the tree was set to be 100, and the average computation size in the tree was set to be 500ms. As shown in Figure 8, although AF-D suffers from significant overhead for lower standard deviations, as the variance in computation sizes increases, the performance gains result-ing from better placements exceed the cost of the reason-ing. Specifically, when the standard deviation is larger than 300ms – threefifths of the average size of all computations – AF-D outperforms both work-sharing and work-stealing. Work-sharing also outperforms work-stealing for standard deviation exceeding 300ms. When bottlenecks present them-selves, in work-sharing, worker threads only need to check the global task queue; in comparison, in work-stealing, each work threads needs to check all task queues trying to steal tasks from other threads, leading to substantial overhead.
The performance of AF-D in these experiments is partic-ularly noteworthy in the context that it comes along with the programmability advantages of using Actors. In other words, programmability does not always have to come at the ex-pense of performance. 6000 6500 7000 7500 8000 8500 50 100 150 200 250 300 350 400 450 500 Completion Time (ms)
Standard Deviation of Computation Size AF-D
AF Work Sharing Work Stealing
Figure 8. Performance Vs. Standard Deviation (TreedSize = 100, AveCompSize = 500)
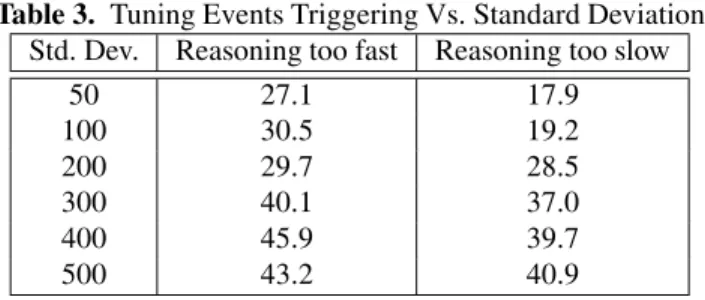
Table 3 shows the average number of tuning events trig-gered in the AF-D experiments.
Table 3. Tuning Events Triggering Vs. Standard Deviation Std. Dev. Reasoning too fast Reasoning too slow
50 27.1 17.9 100 30.5 19.2 200 29.7 28.5 300 40.1 37.0 400 45.9 39.7 500 43.2 40.9
5. Conclusion
Dynamic load balancing is key to achieving high perfor-mance in parallel systems. Existing approaches for dynamic load balancing assume that computations can be divided evenly into subcomputations, and try to redistribute these subcomputations among processors. However, computa-tions are often made up of non-uniform sized subcompu-tations, and evenly partitioning them is non-trivial. As the balance between performance and programmability contin-ues to shift in favour of need for better programmability – largely in response to the growing complexity of modern computer systems – we feel that programmers should not have to reorganize parallel applications less naturally purely for better performance.
In this paper, we introduce our approach to dynamic load balancing, which installs fine-grained resource reasoning mechanisms into ActorFoundry, an efficient Java implemen-tation of the Actor model. Particularly the system tracks available resources and attempts to match them against dis-tributed computations so as to minimize expiration – i.e., failure in utilization – of resources. Additionally, we have implemented a tuner, for explicitly – and automatically – balancing resource use between the reasoning mechanisms and the computations being reasoned about.
For fairly comparing our approach with existing ap-proaches, we adapted the popular Unbalanced Tree Search (UTS) benchmark to have substantial computations at nodes. We believe that lack of substantial computations at the nodes in UTS unduly biases it in favour of mechanisms with-out substantial reasoning. However, even highly dynamic computations are rarely all dynamic and no computation. In other words, real computations afford a greater opportunity for reasoning – between placement decisions – than is af-forded by UTS. By having substantial computations at the nodes, and by having them vary, we were able to compare the performance of our approach to dynamic load balancing in comparison to existing ones for computations with this type of variance.
Our experimental results show that our reasoning based approach significantly outperforms both work-sharing and
work-stealing as the sub-computations become more varied in their size.
Work is ongoing in a number of directions. First, we are exploring different dimensions along which we might try to balance the use of resources between the reasoning for load balancing and carrying out the actual computations. For example, the current implementation uses afixed one-step lookahead to search for potential bottleneck messages. The reason for not looking deeper is essentially the cost; and sometimes even a one-step lookahead may be too costly, par-ticularly if processing of messages rarely leads to creating of new messages. Allowing a system operator intimately aware of the program’s properties to manually tune the depth of lookahead would reduce overhead. In future work, we will also look into the runtime approaches such as introspection. Second, besides performance, under some circumstances, prompt response is also critical for a computation. For ex-ample, in natural disaster monitoring and detecting systems – such as earthquake simulation [32] and weather event mon-itoring (as we discussed in [15]) – high priority computa-tions can dynamically emerge necessitating urgent action. We want to extend the work described in this paper to ad-dress such emergent priorities while pursuing overall perfor-mance goals of computations. Finally, we are examining the possibility of distributing the reasoner in AF-D.
References
[1] The E Language, 2000.http://www.erights.org/elang.
[2] G. Agha. Actors: A Model of Concurrent Computation in
Distributed Systems. MIT Press, 1986.
[3] G. Andrews, D. Dobkin, and P. Downey. Distributed Alloca-tion with Pools of Servers. InProc. of the 1st ACM SIGACT-SIGOPS Symp. on Principles of Distributed Computing, pages 73–83, 1982.
[4] J. Armstrong. Programming Erlang: Software for a Concur-rent World. Pragmatic Bookshelf, 2007.
[5] M. Ashley. The Actor Foundry: A Java-based Actor Program-ming Environment. Technical report, Open Systems Labora-tory, University of Illinois at Urbana-Champaign, 1998. [6] D. Bailey, E. Barszcz, J. Barton, D. Browning, R. Carter,
L. Dagum, R. Fatoohi, P. Frederickson, T. Lasinski, R. Schreiber, H. Simon, V. Venkatakrishnan, and S. Weer-atunga. The NAS Parallel Benchmarks Summary and Prelim-inary Results. InProceedings of the 1991 ACM/IEEE Confer-ence on SuperComputing, pages 158 –165, 1991.
[7] R. Blumofe and C. Leiserson. Scheduling Multithreaded Computations by Work Stealing. Journal of the ACM, 46(5): 720–748, 1999.
[8] T. Desell, K. E. Maghraoui, and C. A. Varela. Load balancing of autonomous actors over dynamic networks. InProceedings of the Hawaii International Conference on System Sciences, HICSS-37 Software Technology Track, pages 1–10, 2004. [9] J. Dinan, S. Olivier, G. Sabin, J. Prins, P. Sadayappan, and
C.-W. Tseng. Dynamic Load Balancing of Unbalanced Com-putations Using Message Passing. InIEEE International
Sym-posium on Parallel and Distributed Processing (IPDPS 2007), pages 1 –8, 2007.
[10] J. Dinan, D. Larkins, P. Sadayappan, S. Krishnamoorthy, and J. Nieplocha. Scalable Work Stealing. InProceedings of the Conference on High Performance Computing Networking, Storage and Analysis, pages 1–11, 2009.
[11] D. Eager, E. Lazowska, and J. Zahorjan. Adaptive Load shar-ing in Homogeneous Distributed Systems.IEEE Transactions on Software Engineering, 12(5):662–675, 1986.
[12] P. Haller and M. Odersky. Actors that Unify Threads and Events. In A. Murphy and J. Vitek, editors, Coordination Models and Languages, Lecture Notes in Computer Science, pages 171–190. 2007.
[13] S. Hofmeyr, C. Iancu, and F. Blagojevi´c. Load Balancing on Speed. InProceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 147–158, 2010.
[14] C. Hylands, E. Lee, J. Liu, X. Liu, S. Neuendorffer, Y. Xiong, Y. Zhao, and H. Zheng. Overview of the Ptolemy Project. Technical report, University of California, Berkeley, 2003. [15] N. Jamali and X. Zhao. A Scalable Approach to Multi-Agent
Resource Acquisition and Control. InProc. of the 4th Intl. Conf. on Autonomous Agents and Multiagent Systems, pages 868–875, 2005.
[16] M.-W. Jang. The Actor Architecture Manual. Technical report, Open Systems Laboratory, University of Illinois at Urbana-Champaign, 2004.
[17] D. Kafura. ACT++: Building a Concurrent C++ with Actors.
Journal of Object-Oriented Programming, 3:25–37, 1990. [18] R. K. Karmani, A. Shali, and G. Agha. Actor Frameworks
for the JVM Platform: A Comparative Analysis. In Proc. of the 7th Intl. Conference on the Principles and Practice of Programming in Java, 2009.
[19] W. Kim. ThAL: An Actor System for Efficient and Scalable Concurrent Computing. PhD thesis, University of Illinois at Urbana-Champaign, 1997.
[20] W. Leinberger, G. Karypis, V. Kumar, and R. Biswas. Load Balancing Across Near-Homogeneous Multi-Resource Servers. InProceedings of the 9th Heterogeneous Computing Workshop (HCW 2000), pages 60–72, 2000.
[21] H.-C. Lin and C. Raghavendra. A Dynamic Load-Balancing Policy with a Central Job Dispatcher (LBC). IEEE Transac-tions on Software Engineering, 18(2):148–158, 1992. [22] K. E. Maghraoui, T. Desell, B. K. Szymanski, and C. A.
Varela. The Internet Operating System: Middleware for adap-tive distributed computing.International Journal of High Per-formance Computing Applications (IJHPCA), Special Issue on Scheduling Techniques for Large-Scale Distributed Plat-forms, 20(4):467–480, 2006.
[23] Microsoft Corporation. Axum Programming Language, 2008. [24] S. Olivier and J. Prins. Scalable Dynamic Load Balancing Us-ing UPC. InProceedings of the 37th International Conference on Parallel Processing (ICPP 2008), pages 123–131, 2008. [25] S. Olivier, J. Huan, J. Liu, J. Prins, J. Dinan, P. Sadayappan,
and C.-W. Tseng. UTS: An Unbalanced Tree Search
Bench-mark. In G. Almsi, C. Cascaval, and P. Wu, editors,Languages and Compilers for Parallel Computing, volume 4382 of Lec-ture Notes in Computer Science, pages 235–250. 2007. [26] D. Pattou and B. Maigret. MOL3D, A Modular and
Inter-active Program for Molecular Modeling and Conformational Analysis: I – Basic Modules. J. Mol. Graph., 6(2):112–121, 1988.
[27] J. Phillips, R. Braun, W. Wang, J. Gumbart, E. Tajkhorshid, E. Villa, C. Chipot, R. Skeel, L. Kal´e, and K. Schulten. Scal-able Molecular Dynamics with NAMD.Journal of Computa-tional Chemistry, 26:1781–1802, 2005.
[28] J.-N. Quintin and F. Wagner. Hierarchical Work-Stealing. In
Proceedings of the 16th International European Conference on Parallel and Distributed Computing (EuroPar 2010): Part I, pages 217–229, 2010.
[29] K. Ravichandran, S. Lee, and S. Pande. Work Stealing for Multi-Core HPC Clusters. InProceedings of the 17th Interna-tional European Conference on Parallel and Distributed Com-puting (EuroPar 2011): Part I, pages 205–217, 2011. [30] S. Srinivasan and A. Mycroft. Kilim: Isolation-Typed Actors
for Java. InProceedings of the 22nd European Conference on Object-Oriented Programming (ECOOP 2008), pages 104– 128, 2008.
[31] D. Sturman and G. Agha. A Protocol Description Language for Customizing Failure Semantics. InProceedings of the 13th Symposium on Reliable Distributed Systems, pages 148–157, 1994.
[32] I. Takeuchi. Towards an Integrated Earthquake Disaster Sim-ulation System. InProceedings of the 1st International Work-shop on Synthetic Simulation and Robotics to Mitigate Earth-quake Disaster, 2003.
[33] C. Varela and G. Agha. Programming Dynamically Reconfi
g-urable Open Systems with SALSA.ACM SIGPLAN Notices,
36:20–34, 2001.
[34] X. Zhao and N. Jamali. Temporal Reasoning about Resources for Deadline Assurance in Distributed Systems. In Proceed-ings of ICDCS Workshop on Assurance in Distributed Systems and Networks, 2010.
[35] X. Zhao and N. Jamali. Supporting Deadline Constrained Distributed Computations on Grids. In Proceedings of the 12th IEEE/ACM International Conference on Grid Comput-ing, pages 165–172, 2011.
[36] G. Zheng, E. Meneses, A. Bhatel, and L. Kal. Hierarchical Load Balancing for Charm++ Applications on Large Super-computers. InProceedings of the 39th International Confer-ence on Parallel Processing Workshops (ICPPW 2010), pages 436–444, 2010.